java 自定义json解析注解 复杂json解析 工具类
java 自定义json解析注解 复杂json解析 工具类
目录
- java 自定义json解析注解 复杂json解析 工具类
- 1.背景
- 2、需求-各式各样的json
- 一、一星难度json【json对象中不分层】
- 二、二星难度json【json对象中出现层级】
- 三、三星难度json【json对象中存在数组】
- 四、四星难度json【json对象中数组中存在层级】
- 五、五星难度json【json对象中包含数组、且选择是存在底层级跳转到高层级的】
- 六、利用自定义注解和配置类解析
- 1.自定义注解类
- 2.自定义注解对应解析工具类
- 如果业务中json的key出现了 > 这种特殊符合(并且前后带空格的)可以替换。如下:
- 七、实战 某个业务场景的一段json
1.背景
为什么要写这个自定义注解,因为需求需要处理一批比较复杂的json(如果只有一个,直接手动写代码解析就好),众所周知批量且类似的工作,最好抽象出来。这也符合编程的风格,不重复造轮子,但是需要造轮子。【前面铺垫比较长,如果需求比较复杂的json可以直接划到最下面,粘贴自定义注解类 和 自定义注解解析工具类】
2、需求-各式各样的json
一、一星难度json【json对象中不分层】
需要的字段也恰好是对应上的
json
{
"name": "wuyuanshun",
"sex":"男"
}或
[
{
"name": "wuyuanshun",
"sex":"男"
},
{
"name": "liuyuanshun",
"sex":"男"
}
]
java对象
@Data
public class Bean {private String name;private String sex;}
解析方法
public class JsonUtil {public static final ObjectMapper mapper = new ObjectMapper();public static <T> T fromJson(String json, Class<T> clazz) {requireNonNull(json);requireNonNull(clazz);try {return mapper.readValue(json, clazz);} catch (IOException e) {throw new RuntimeException(e);}}/*** json数组转java对象* @param json* @param valueType* @param <T>* @return* @author: wuyuanshn*/public static <T> List<T> jsonArrayToObjectList(String json, Class<T> valueType) {try {//解析JSONArray redisJsonArray = JSONArray.parseArray(json);List<T> redisList = new ArrayList<>(redisJsonArray.size());//封装for (int i = 0; i < redisJsonArray.size(); i++) {T item = mapper.readValue(redisJsonArray.getString(i), valueType);redisList.add(item);}//返回return redisList;} catch (Exception e) {return null;}}public static void main(String[] args) {String json="xxx";Bean bean = fromJson(json, Bean.class);System.out.println(bean);String jsonList="[xxx,xxx]";List<Bean> beanList = jsonArrayToObjectList(jsonList, Bean.class);System.out.println(beanList);}
}
二、二星难度json【json对象中出现层级】
难度加大一些,比如,出现了层级
json
{
"name": "wuyuanshun",
"sex":"男","like":{"title":"羽毛球","level":1,"time":1672402865000
}
}
简单解析的话,我们可以再新建一个Like对象,如:
@Data
public class Like {private String title;private Integer level;private Long time;
}
然后再bean里加上Like对象即可:
java对象
public class Bean {private String name;private String sex;private Like like;
}不过需求真的会那么简单,我就不需要写这个文章了。像闯关一下,让我们提升难度,
比如我需要的对象是要同一层级的(如下),要存在一起(比如存数据库表)。当然我们也可以建Like对象再通过代码导入到同一层级。不过我们可以让他简单一些(正题开始了):
对应解析java对象
@Date
public class Bean {@JsonAnalysisProperty("name")private String name;@JsonAnalysisProperty("sex")private String sex;@JsonAnalysisProperty("like > title")private String likeTitle;@JsonAnalysisProperty("like > level")private Integer likeLevel;@JsonAnalysisProperty("like > time")private Long likeTime;
}
对应解析的bean【自定义注解@JsonAnalysisProperty在文章最下面 目录六】
- name 单层级直接获取
- like > title 多层级 用 > 隔断取下一层级内容 【注意 > 前后有空格】
*测试方法【之后每个测试用测方法】
public static void main(String[] args) {//jsonString json = "{xxxxxxxxxxx}";//自定义对象Bean bean = new Bean();JsonAnalysisPropertyConfig.setObjectByJsonAnalysis(bean,json);System.out.println(bean);}
}
三、三星难度json【json对象中存在数组】
需求取出姓名、性别、爱好名称(like > title)、语文分数。
{"name":"wuyuanshun","sex":"男","like":{"title":"羽毛球","level":1,"time":1672402865000},"examination_results":[{"subject":"数学","date":"2023-01-29","score":98.5},{"subject":"语文","date":"2023-01-29","score":98.5},{"subject":"英语","date":"2023-01-29","score":98.5}]
}
对应解析java对象
@Date
public class Bean {@JsonAnalysisProperty("name")private String name;@JsonAnalysisProperty("sex")private String sex;@JsonAnalysisProperty("like > title")private String likeTitle;@JsonAnalysisProperty("like > level")private Integer likeLevel;@JsonAnalysisProperty("examination_results >> \"subject\":\"语文\" > score")private Double chineseScore;
}
>> 代表之后是数组中的内容,直到"key": "value"这种选择器结束。如果数组到选择器key:value中还有层级,原来的层级( > )需要换成 (>>),如四星难度json。【注意 >> 前后有空格】
- examination_results >> “subject”:“语文” 找到examination_results数组中key:value为"subject":"语文“的json对象
- > score 继续在json对象层级里找到score的值98.5
四、四星难度json【json对象中数组中存在层级】
{"purchase_crowd":{"interact_data":[{"index_value":{"index_display":"有互动人数","value":{"value":44,"unit":"number"},},"show_list":[{"display":"首购人数占比","value":{"value":0.5909090909090909}}]},{"index_value":{"index_display":"无互动人数"},"show_list":[{"display":"xxx占比","value":{"value":0.02}},{"display":"首购人数占比","value":{"value":0.4444444444444444}}]}]}
}对应解析java对象
@Date
public class Bean {@JsonAnalysisProperty(defaultValue = "0",value = "purchase_crowd > interact_data >> index_value >> \"index_display\":\"有互动人数\" > value > value") @ApiModelProperty("有互动人数") private String purchaseCrowdInteractDataPeopleNumberInteracting;}
- defaultValue = “0” 是如果json解析中没找到这个字段添加的默认值。
- interact_data >> index_value >> “index_display”:“有互动人数” 这一段都是在数组中选择某一个key:value,来定位自己要找的json对象。找到key:value后,默认在当前层级继续向下选择
- value > value 找到值44。
五、五星难度json【json对象中包含数组、且选择是存在底层级跳转到高层级的】
json同上
如 需求是取index_display 为 "有互动人数"的数组中的 ‘收购人数占比’ value数值、和取index_display 为 "无互动人数"的数组中的‘收购人数占比’value数值
对应解析java对象
@Date
public class Bean {@JsonAnalysisProperty(defaultValue = "0",value = "purchase_crowd > interact_data >> * index_value >> \"index_display\":\"有互动人数\" > show_list >> \"display\":\"首购人数占比\" > value > value") @ApiModelProperty("有互动人数-首购人数占比") private String purchaseCrowdInteractDataPeopleNumberFirstPurchaseRatio;@JsonAnalysisProperty(defaultValue = "0",value = "purchase_crowd > interact_data >> * index_value >> \"index_display\":\"无互动人数\" > show_list >> \"display\":\"首购人数占比\" > value > value") @ApiModelProperty("无互动人数-首购人数占比") private String purchaseCrowdNotInteractDataPeopleNumberFirstPurchaseRatio;
}
自定义注解的逻辑就是像指针一样根据注解中的路由去寻找字段
符号 “ * ” 代表记录指针位置层级,等找到对应的key:value时,返回之前保存的层级。【注意 * 前后有空格】
- interact_data >> * index_value >> “index_display”:“无互动人数” 中的 * 号记录了找到key:value后从 interact_data到 index_value这层开始选择可以继续选择【index_value、show_list】,及通过之前的选择选中了下图中绿色区域。
- > show_list >> “display”:“首购人数占比” 继续从show_list数组中找到对应的key:value(黄色区域)
- > value > value 继续从‘首购人数占比’层级往下寻找 到0.4444…。

六、利用自定义注解和配置类解析
public static void main(String[] args) {//jsonString json = "{xxxxxxxxxxx}";//自定义对象Bean bean = new Bean();JsonAnalysisPropertyConfig.setObjectByJsonAnalysis(bean,json);System.out.println(bean);}
}
1.自定义注解类
package com.wuyuanshun.annotation;import java.lang.annotation.Documented;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;/*** @program: wys-service* @description: 自定义json解析注解* @author: wuyuanshn* @create: 2022-12-26 17:12**/@Target({java.lang.annotation.ElementType.ANNOTATION_TYPE, java.lang.annotation.ElementType.FIELD, java.lang.annotation.ElementType.METHOD, java.lang.annotation.ElementType.PARAMETER})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface JsonAnalysisProperty {/*** 正常层级选择*/String SPLIT_DEFAULT = " > ";/*** 下层级是数组内元素*/String SPLIT_DEFAULT_ARRAY = " >> ";/*** 数组内 选择返回的层级 默认是最后(最深层)的节点*/String SELECT_ARRAY_DEFAULT_ARRAY = "* ";/*** 核心字段** @return*/String value();/*** 类型 默认0* 1 多层级【后续可以改为枚举类型】** @return*/int type() default 0;/*** 分隔符** @return*/String split() default SPLIT_DEFAULT;/*** 数组内 选择返回的层级 默认是最后(最深层)的节点** @return*/String selectArrayOne() default SELECT_ARRAY_DEFAULT_ARRAY;/*** 标记为数组** @return*/String splitArray() default SPLIT_DEFAULT_ARRAY;/*** 是否忽略** @return*/boolean ignore() default false;/*** 默认值** @return*/String defaultValue() default "";
}2.自定义注解对应解析工具类
package com.wuyuanshun.annotation;import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.StringUtils;import java.lang.reflect.Field;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** @program: wys-service* @description: 自定义json解析注解 工具类* @author: wuyuanshn* @create: 2022-12-26 18:38**/
@Slf4j
public class JsonAnalysisPropertyConfig {public static final ObjectMapper mapper = new ObjectMapper();static Pattern GROUP_INDEX_PATTERN = Pattern.compile("\"([\\u4E00-\\u9FA5A-Za-z0-9_]+)\"[ ]*:[ ]*\"([\\u4E00-\\u9FA5A-Za-z0-9_%&',,+!@#^*《》【】\\-()。;=?$\\x22]+)\"");/*** 根据注解解析 对象中的所有** @param t* @param json* @param <T>*/public static <T> void setObjectByJsonAnalysis(T t, String json) {List<Field> fieldList = getFieldList(t.getClass());for (Field field : fieldList) {setAnalysisProperty(field, t, json);}}/*** 解析对象** @return*/public static List<Field> getFieldList(Class<?> clazz) {List<Field> fieldList = new ArrayList<>();while (clazz != null) {fieldList.addAll(new ArrayList<>(Arrays.asList(clazz.getDeclaredFields())));clazz = clazz.getSuperclass();}Field[] fields = new Field[fieldList.size()];fieldList.toArray(fields);return fieldList;}/*** 根据注解解析 对象中的单个字段** @param field* @param t* @param json* @param <T>*/public static <T> void setAnalysisProperty(Field field, T t, String json) {try {JsonAnalysisProperty annotation = field.getAnnotation(JsonAnalysisProperty.class);if (annotation == null || StringUtils.isEmpty(json)) {return;}//一、 验证参数//忽略boolean ignore = annotation.ignore();String split = annotation.split();String splitArray = annotation.splitArray();String selectArrayOne = annotation.selectArrayOne();String defaultValue = annotation.defaultValue();if (ignore) {return;}field.setAccessible(true);//字段内容Object fieldValue = field.get(t);//有默认值 先这设置默认值 防止后续报错 设置不上(字段没有内容的情况下 再设置默认值)if (!StringUtils.isEmpty(defaultValue) && StringUtils.isEmpty(fieldValue)) {setField(field, t, defaultValue);}//默认-核心字段String codeValue = annotation.value();if (StringUtils.isEmpty(codeValue)) {return;}//二、 处理数据JsonNode jsonNode = mapper.readTree(json);String[] codeValueList = codeValue.split(split);for (int i = 0; i < codeValueList.length; i++) {String codeValueItem = codeValueList[i];if (StringUtils.isEmpty(codeValueItem)) {continue;}//剔除多余空格codeValueItem = codeValueItem.trim();//判断是否是数组 是则处理数组 选择节点JsonNode jsonNodeItem = analysisSplitArrayMax(jsonNode, codeValueItem, splitArray, selectArrayOne);//是选择数组 跳过if (jsonNodeItem != null) {jsonNode = jsonNodeItem;continue;}jsonNode = jsonNode.get(codeValueItem);}String text = jsonNode.asText();//设置值
// field.set(t, text);setField(field, t, text);//如果为空 且有默认值 设置默认值if (StringUtils.isEmpty(text) && !StringUtils.isEmpty(defaultValue) && StringUtils.isEmpty(fieldValue)) {setField(field, t, defaultValue);}} catch (Exception e) {String error = null;try {StackTraceElement[] stackTrace = e.getStackTrace();StackTraceElement stackTraceElement = stackTrace[0];error = e + "\r\n " + stackTraceElement;} catch (Exception exception) {log.error("JsonAnalysisPropertyConfig setAnalysisProperty exception error {}", e, exception);}log.error("JsonAnalysisPropertyConfig setAnalysisProperty field {} error {}", field, error);}}/*** 设置字段值 不同类型** @param field* @param t* @param value* @param <T>*/public static <T> void setField(Field field, T t, String value) {try {Object obj = value;Class<?> type = field.getType();if (type.equals(String.class)) {
// field.set(t, obj);} else if (type.equals(Long.class)) {obj = Long.parseLong(value);} else if (type.equals(Integer.class)) {obj = Integer.parseInt(value);} else if (type.equals(Boolean.class)) {obj = Boolean.parseBoolean(value);} else if (type.equals(BigDecimal.class)) {obj = new BigDecimal(value);} else if (type.equals(Double.class)) {obj = Double.parseDouble(value);} else if (type.equals(Float.class)) {obj = Float.parseFloat(value);}
// else if (type.equals(Date.class)) {
// obj = DateUtils.getDate(value);
// }//其他类型可以在这里添加field.set(t, obj);} catch (Exception e) {log.error("JsonAnalysisPropertyConfig setField 赋值字段失败 field {}; t {}; value {}", field, t, value, e);}}/*** 判断是否是数组,如果是 接着处理** @param jsonNode* @param codeValueItem* @param splitArray*/public static JsonNode analysisSplitArray1(JsonNode jsonNode, String codeValueItem, String splitArray) {//判断是否是数组if (codeValueItem.startsWith(splitArray)) {String key;String value;//查看是否需要选择json数组中的某一个Matcher matcher = GROUP_INDEX_PATTERN.matcher(codeValueItem);if (matcher.find()) {key = matcher.group(1);value = matcher.group(2);} else {return null;}Iterator<JsonNode> elements = jsonNode.elements();//遍历找出对应的数组itemwhile (elements.hasNext()) {JsonNode next = elements.next();String getValue = next.get(key).asText();if (!StringUtils.isEmpty(getValue) && getValue.equals(value)) {return next;}}}return null;}/*** 判断是否是数组,如果是 接着处理** @param jsonNode* @param codeValueItem* @param splitArray*/public static JsonNode analysisSplitArray2(JsonNode jsonNode, String codeValueItem, String splitArray) {//判断是否是数组if (codeValueItem.contains(splitArray)) {String[] keyList = null;keyList = codeValueItem.split(splitArray);//一、平级选择String codeNext = keyList[0];jsonNode = jsonNode.get(codeNext);//二、数组选择Iterator<JsonNode> elements = jsonNode.elements();String key;String value;//查看是否需要选择json数组中的某一个Matcher matcher = GROUP_INDEX_PATTERN.matcher(codeValueItem);if (matcher.find()) {key = matcher.group(1);value = matcher.group(2);} else {//匹配不到筛选key value 但是包含数组 按第一哥个返回(认为数组中只有一个JsonNode 或者取第一个【顺序保证的前提下】)if (elements.hasNext()) {return elements.next();}//取不到数据 认为不是数组return null;}//遍历找出对应的数组itemwhile (elements.hasNext()) {JsonNode next = elements.next();//判断是否需要深层选择if (keyList.length > 2) {for (int i = 0; i < keyList.length; i++) {//跳过最后一个 认为最后一个是key value//跳过第一个 第一个事平级选择if (i == 0 || i == keyList.length - 1) {continue;}next = next.get(keyList[i]);}}String getValue = next.get(key).asText();if (!StringUtils.isEmpty(getValue) && getValue.equals(value)) {return next;}}}return null;}/*** 判断是否是数组,如果是 接着处理** @param jsonNode* @param codeValueItem* @param splitArray* @param selectArrayOne*/public static JsonNode analysisSplitArrayMax(JsonNode jsonNode, String codeValueItem, String splitArray, String selectArrayOne) {//判断是否是数组if (codeValueItem.contains(splitArray)) {String[] keyList = null;keyList = codeValueItem.split(splitArray);//一、层级选择String codeNext = keyList[0];jsonNode = jsonNode.get(codeNext);//二、数组选择Iterator<JsonNode> elements = jsonNode.elements();String key;String value;//查看是否需要选择json数组中的某一个Matcher matcher = GROUP_INDEX_PATTERN.matcher(codeValueItem);if (matcher.find()) {key = matcher.group(1);value = matcher.group(2);} else {//匹配不到筛选key value 但是包含数组 按第一哥个返回(认为数组中只有一个JsonNode 或者取第一个【顺序保证的前提下】)if (elements.hasNext()) {return elements.next();}//取不到数据 认为不是数组return null;}//遍历找出对应的数组itemwhile (elements.hasNext()) {JsonNode next = elements.next();JsonNode returnNext = null;//判断是否需要深层选择if (keyList.length > 2) {for (int i = 0; i < keyList.length; i++) {//跳过最后一个 认为最后一个是key value//跳过第一个 第一个事平级选择if (i == 0 || i == keyList.length - 1) {continue;}String keyItem = keyList[i];if (keyItem.startsWith(selectArrayOne)) {keyItem = keyItem.replace(selectArrayOne, "");returnNext = next;}next = next.get(keyItem);}}String getValue = next.get(key).asText();if (!StringUtils.isEmpty(getValue) && getValue.equals(value)) {//是否选择返回层级if (returnNext != null) {return returnNext;}return next;}}}return null;}public static void main(String[] args) {String a = "aasddd@@\"key_\" :\"value值(asdd,。a)\"";Matcher matcher = GROUP_INDEX_PATTERN.matcher(a);if (matcher.find()) {String key = matcher.group(1);String value = matcher.group(2);System.out.println("key = " + key);System.out.println("value = " + value);/* key = key_value = value值(asdd,。a)*/}String json = "{\n" +"\"name\": \"wuyuanshun\",\n" +"\"sex\":\"男\",\n" +"\"like\":{\n" +"\t\"title\":\"羽毛球\",\n" +"\t\"level\":1,\n" +"\t\"time\":1672402865000\n" +"},\n" +" \"examination_results\":[\n" +" {\n" +"\t\"subject\":\"语文\",\n" +"\t\"date\":\"2023-01-29\",\n" +"\t\"score\":98.5\n" +" }, {\n" +"\t\"subject\":\"数学\",\n" +"\t\"date\":\"2023-01-29\",\n" +"\t\"score\":98.5\n" +" }, {\n" +"\t\"subject\":\"英语\",\n" +"\t\"date\":\"2023-01-29\",\n" +"\t\"score\":98.5\n" +" }\n" +"]\n" +"}";Bean bean = new Bean();setObjectByJsonAnalysis(bean,json);System.out.println(bean);}
}如果业务中json的key出现了 > 这种特殊符合(并且前后带空格的)可以替换。如下:
@JsonAnalysisProperty(defaultValue = "0",value = "purchase_crowd > interact_data >> * index_value >> \"index_display\":\"有互动人数\" > show_list >> \"display\":\"首购人数占比\" > value > value")@ApiModelProperty("成交人群分析-有互动人数-首购人数占比") private String purchaseCrowdInteractDataPeopleNumberFirstPurchaseRatio;
//替换为
@JsonAnalysisProperty(split = " 》 ", splitArray = " 》》 ", selectArrayOne= "** ", defaultValue = "0",value = "purchase_crowd 》 interact_data 》》 ** index_value 》》 \"index_display\":\"有互动人数\" > show_list 》》 \"display\":\"首购人数占比\" 》 value 》 value")@ApiModelProperty("成交人群分析-有互动人数-首购人数占比") private String purchaseCrowdInteractDataPeopleNumberFirstPurchaseRatio;
七、实战 某个业务场景的一段json
{"purchase_crowd":{"interact_data":[{"index_value":{"index_display":"有互动人数","index_name":"","value":{"value":44,"unit":"number"},"change_value":{"value":0.4943820224719101,"unit":"ratio"}},"show_list":[{"display":"粉丝占比","name":"","value":{"value":0.8636363636363636,"unit":"ratio"}},{"display":"首购人数占比","name":"","value":{"value":0.5909090909090909,"unit":"ratio"}}]},{"index_value":{"index_display":"无互动人数","index_name":"","value":{"value":45,"unit":"number"},"change_value":{"value":0.5056179775280899,"unit":"ratio"},},"show_list":[{"display":"粉丝占比","name":"","value":{"value":0.6888888888888889,"unit":"ratio"}},{"display":"首购人数占比","name":"","value":{"value":0.4444444444444444,"unit":"ratio"}}]}]}
}
对应解析java对象
@JsonAnalysisProperty(defaultValue = "0", value = "purchase_crowd > interact_data >> index_value >> \"index_display\":\"有互动人数\" > value > value")@ApiModelProperty("成交人群分析-有互动人数")private String purchaseCrowdInteractDataPeopleNumberInteracting;@JsonAnalysisProperty(defaultValue = "0", value = "purchase_crowd > interact_data >> index_value >> \"index_display\":\"有互动人数\" > change_value > value")@ApiModelProperty("成交人群分析-有互动人数占比")private String purchaseCrowdInteractDataPeopleNumberRatio;@JsonAnalysisProperty(defaultValue = "0", value = "purchase_crowd > interact_data >> * index_value >> \"index_display\":\"有互动人数\" > show_list >> \"display\":\"粉丝占比\" > value > value")@ApiModelProperty("成交人群分析-有互动人数-粉丝占比")private String purchaseCrowdInteractDataPeopleNumberFansDataRatio;@JsonAnalysisProperty(defaultValue = "0", value = "purchase_crowd > interact_data >> * index_value >> \"index_display\":\"有互动人数\" > show_list >> \"display\":\"首购人数占比\" > value > value")@ApiModelProperty("成交人群分析-有互动人数-首购人数占比")private String purchaseCrowdInteractDataPeopleNumberFirstPurchaseRatio;@JsonAnalysisProperty(defaultValue = "0", value = "purchase_crowd > interact_data >> index_value >> \"index_display\":\"无互动人数\" > value > value")@ApiModelProperty("成交人群分析-无互动人数")private String purchaseCrowdNotInteractDataPeopleNumber;@JsonAnalysisProperty(defaultValue = "0", value = "purchase_crowd > interact_data >> index_value >> \"index_display\":\"无互动人数\" > change_value > value")@ApiModelProperty("成交人群分析-无互动人数占比")private String purchaseCrowdNotInteractDataPeopleNumberRatio;@JsonAnalysisProperty(defaultValue = "0", value = "purchase_crowd > interact_data >> * index_value >> \"index_display\":\"无互动人数\" > show_list >> \"display\":\"粉丝占比\" > value > value")@ApiModelProperty("成交人群分析-无互动人数-粉丝占比")private String purchaseCrowdNotInteractDataPeopleNumberFansDataRatio;@JsonAnalysisProperty(defaultValue = "0", value = "purchase_crowd > interact_data >> * index_value >> \"index_display\":\"无互动人数\" > show_list >> \"display\":\"首购人数占比\" > value > value")@ApiModelProperty("成交人群分析-无互动人数-首购人数占比")private String purchaseCrowdNotInteractDataPeopleNumberFirstPurchaseRatio;相关文章:
java 自定义json解析注解 复杂json解析 工具类
java 自定义json解析注解 复杂json解析 工具类 目录java 自定义json解析注解 复杂json解析 工具类1.背景2、需求-各式各样的json一、一星难度json【json对象中不分层】二、二星难度json【json对象中出现层级】三、三星难度json【json对象中存在数组】四、四星难度json【json对象…...

类的 6 个默认成员函数
文章目录一、构造函数1. 构造函数的定义2. 编译器生成的构造函数3. 默认构造函数4. 初始化列表5. 内置成员变量指定缺省值(C11)二、析构函数1. 析构函数的定义2. 编译器生成的析构函数3. 自己写的析构函数的执行方式三、拷贝构造函数1. C语言值传递和返回值时存在 bug2. 拷贝构…...
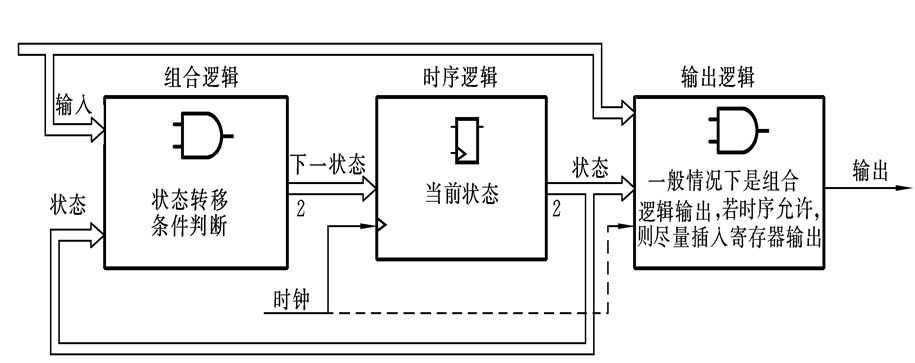
基于Verilog HDL的状态机描述方法
⭐本专栏针对FPGA进行入门学习,从数电中常见的逻辑代数讲起,结合Verilog HDL语言学习与仿真,主要对组合逻辑电路与时序逻辑电路进行分析与设计,对状态机FSM进行剖析与建模。 🔥文章和代码已归档至【Github仓库…...
6年软件测试经历:成长、迷茫、奋斗
前言 测试工作6年,经历过不同产品、共事过不同专业背景、能力的同事,踩过测试各种坑、遇到过各种bug。测试职场生涯积极努力上进业务和技术能力快速进步过、也有努力付出却一无所得过、有对测试生涯前景充满希望认为一片朝气蓬勃过、也有对中年危机思考不…...

OpenMMLab AI实战营第五次课程
语义分割与MMSegmentation 什么是语义分割 任务: 将图像按照物体的类别分割成不同的区域 等价于: 对每个像素进行分类 应用:无人驾驶汽车 自动驾驶车辆,会将行人,其他车辆,行车道,人行道、交…...

【软考】系统集成项目管理工程师(二十)项目风险管理
一、项目风险管理概述1. 风险概念2. 风险分类3. 风险成本二、项目风险管理子过程1. 规划风险管理2. 识别风险3. 实施定性风险分析4. 实施定量风险分析5. 规划风险应对6. 控制风险三、项目风险管理流程梳理一、项目风险管理概述 1. 风险概念 风险是一种不确定事件或条件,一旦…...
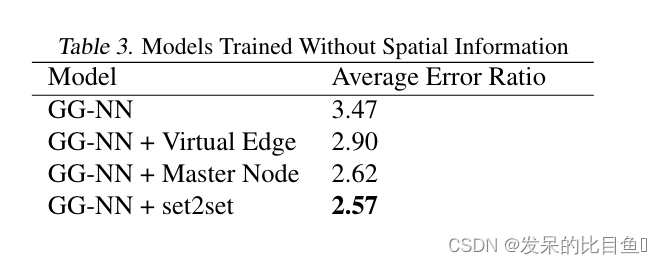
2017-PMLR-Neural Message Passing for Quantum Chemistry
2017-PMLR-Neural Message Passing for Quantum Chemistry Paper: https://arxiv.org/pdf/1704.01212.pdf Code: https://github.com/brain-research/mpnn 量子化学的神经信息传递 这篇文献作者主要是总结了先前神经网络模型的共性,提出了一种消息传递神经网络&am…...
)
Python:每日一题之全球变暖(DFS连通性判断)
题目描述 你有一张某海域 NxN 像素的照片,"."表示海洋、"#"表示陆地,如下所示: ....... .##.... .##.... ....##. ..####. ...###. ....... 其中"上下左右"四个方向上连在一起的一片陆地组成一座岛屿…...
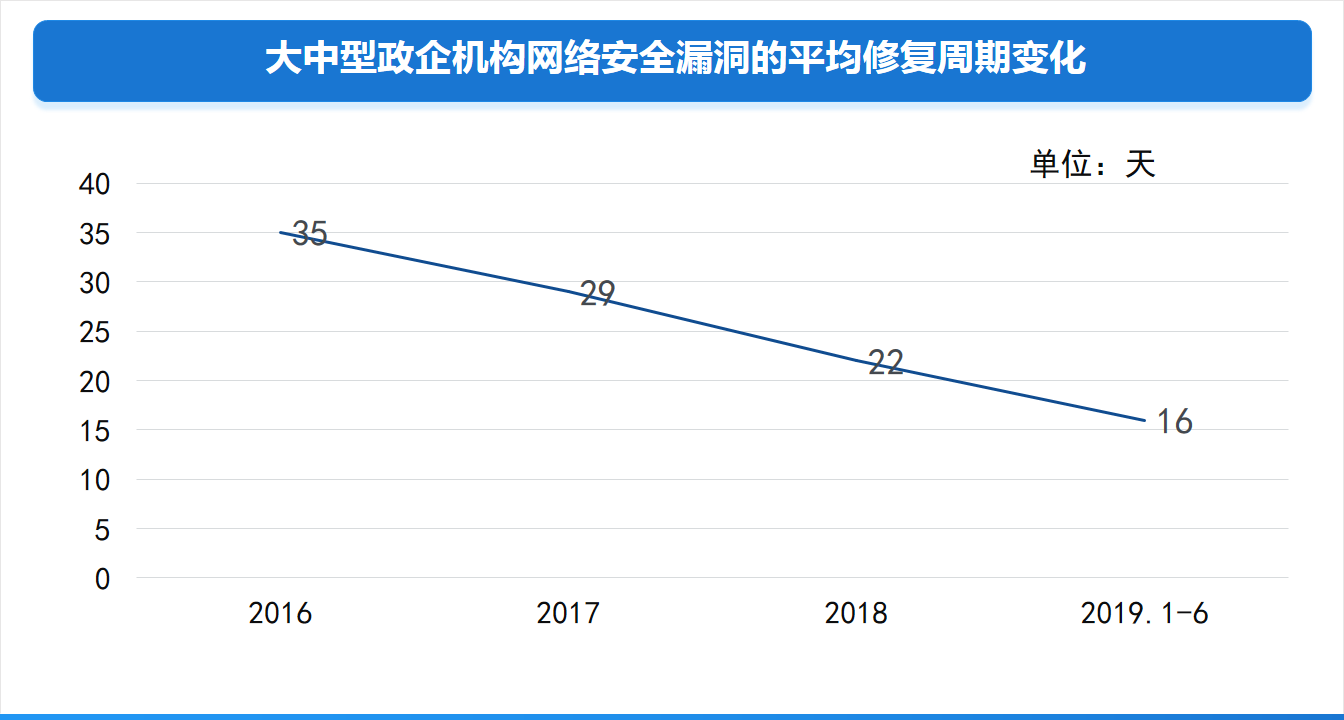
企业级安全软件装机量可能大增
声明 本文是学习大中型政企机构网络安全建设发展趋势研究报告. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 研究背景 大中型政企机构是网络安全保护的重中之重,也是国内网络安全建设投入最大,应用新技术、新产品最多的机构…...

为什么要用频谱分析仪测量频谱?
频谱分析仪是研究电信号频谱结构的仪器,用于信号失真度、调制度、谱纯度、频率稳定度和交调失真等信号参数的测量,可用以测量放大器和滤波器等电路系统的某些参数,是一种多用途的电子测量仪器。从事通信工程的技术人员,在很多时候…...
Python环境搭建、Idea整合
1、学python先要下载什么? 2、python官网 3、idea配置Python 4、idea新建python 学python先要下载什么? python是一种语言,首先你需要下载python,有了python环境,你才可以在你的电脑上使用python。现在大多使用的是pyt…...

HTTP请求返回304状态码以及研究nginx中的304
文章目录1. 引出问题2. 分析问题3. 解决问题4. 研究nginx中的3044.1 启动服务4.2 ETag说明4.3 响应头Cache-Control1. 引出问题 之前在调试接口时,代码总出现304问题,如下所示: 2. 分析问题 HTTP 304: Not Modified是什么意思? …...

【GD32F427开发板试用】使用Arm-2D显示电池电量
本篇文章来自极术社区与兆易创新组织的GD32F427开发板评测活动,更多开发板试用活动请关注极术社区网站。作者:boc 【虽迟但到】 由于快递的原因,11月份申请的,12月1日才收到GD32F427开发板。虽然姗姗来迟,但也没有减少…...

TS第二天 Typesrcipt编译
文章目录自动编译tsconfig.json配置选项include 比较重要excludeextendsfilescompilerOptions 比较重要自动编译 手动模式:每次ts文件修改完,手动编译一次 tsc 01.ts监视模式:ts文件修改完,自动监视编译 tsc 01.ts -w编译所有文…...
基于C#制作一个飞机大战小游戏
此文主要基于C#制作一个飞机大战游戏,重温经典的同时亦可学习。 实现流程1、创建项目2、界面绘制3、我方飞机4、敌方飞机5、子弹及碰撞检测实现流程 1、创建项目 打开Visual Studio,右侧选择创建新项目。 搜索框输入winform,选择windows窗体…...
git修改历史提交(commit)信息
我们在开发中使用git经常会遇到想要修改之前commit的提交信息,这里记录下怎么使用git修改之前已经提交的信息。一、修改最近一次commit的信息 首先通过git log查看commit信息。 我这里一共有6次commit记录。 最新的commit信息为“Merge branch ‘master’ of https:…...
代码解析工具cpg
cpg 是一个跨语言代码属性图解析工具,它目前支持C/C (C17), Java (Java 13)并且对Go, LLVM, python, TypeScript也有支持,在这个项目的根目录下: cpg-core为cpg解析模块的核心功能,主要包括将代码解析为图,core模块只包括对C/C/Ja…...

Linux虚拟机部署Java环境-Jdk-Mysql
Linux虚拟机部署 author hf 1.安装 电脑安装x-shell工具,然后使用堡垒机基础控件windows版进行安装扫描,最后点击自动检测,保证能扫描到X-shell工具的安装路径 使用堡垒机登录快照夏选择工具点击Xshell进行连接 查看linux版本 root:~# ca…...

每日学术速递2.9
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 Subjects: cs.CV、cs.AI、cs.LG、cs.IR 1.Graph Signal Sampling for Inductive One-Bit Matrix Completion: a Closed-form Solution(ICLR 2023) 标题:归纳单比特矩阵完成的图信号采样&am…...

【Linux】进程优先级 | 进程的切换 | 环境变量详解
🤣 爆笑教程 👉 《看表情包学Linux》👈 猛戳订阅 🔥 💭 写在前面:我们先讲解进程的优先级,探讨为什么会存在优先级,以及如何查看系统进程、进程优先级的修改。然后讲解进程的切…...

告别枯燥理论!用eNSP模拟一次家庭/小型办公室无线组网:从AC配置、AP上线到手机连接全流程
告别枯燥理论!用eNSP模拟一次家庭/小型办公室无线组网:从AC配置、AP上线到手机连接全流程 想象一下这样的场景:周末在家办公时,手机突然提示"Wi-Fi信号弱";小型会议室里,同事们抱怨视频会议卡顿。…...

茉莉花插件:重塑你的中文文献研究新范式
茉莉花插件:重塑你的中文文献研究新范式 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 作为一名学术研究者ÿ…...

开源AI智能体记忆服务:构建持久化共享记忆中枢
1. 项目概述:为AI智能体构建持久化共享记忆中枢 如果你正在构建或使用基于LangGraph、CrewAI、AutoGen这类框架的多智能体系统,或者你厌倦了每次与Claude、Cursor等AI助手开启新会话时都要重复解释项目背景,那么你很可能正面临一个核心痛点&…...

数据中心网络跃迁:25GbE以太网如何以创造性破坏重塑技术路径
1. 从技术演进到范式跃迁:我眼中的“创造性破坏”风暴我是在上世纪90年代末来到这里的,那是一个技术浪潮奔涌的年代。我亲眼见证了录像带从VHS到DVD,再到如今的云DVR和视频流媒体的完整迭代;也目睹了通信设备从固定电话到功能手机…...

iPhone 5c中国遇冷复盘:产品定价、市场预期与战略博弈的深度解析
1. 项目概述:一次关于市场预期的“误判”复盘2013年秋天,苹果公司发布了被外界普遍视为“专为新兴市场打造”的iPhone 5c。这款拥有多彩聚碳酸酯外壳的手机,在发布前就被贴上了“廉价iPhone”的标签,尤其是针对像中国这样庞大且正…...

EDA工程师成长与验证技术演进:从算法到芯片的实践闭环
1. 从算法到芯片:一位EDA工程师的成长路径解析在半导体这个行当里待久了,你会发现,那些真正能把工具做“透”、把流程理“顺”的人,往往自己就亲手“焊”过板子、调过RTL、追过时序违例。Prakash Narain的故事,就是一个…...

SVG 滤镜:全面解析与高效应用
SVG 滤镜:全面解析与高效应用 引言 SVG(可缩放矢量图形)作为一种广泛使用的图形格式,因其具有高度的可缩放性和跨平台性而备受青睐。SVG 滤镜作为 SVG 的一项强大功能,能够实现丰富的图形效果,提升图形的表…...

AI时代下,泳装行业的内容竞争正在被重新定义
北京先智先行科技有限公司持续推进人工智能产业应用,构建了“先知大模型”“先行 AI 商学院”“先知 AIGC 超级工场”三大核心产品体系,并围绕先知大模型私有化部署、先知 AIGC 超级工场、AI 训练师、先知人力资源服务、先知产业联盟等核心业务方向&…...

Void Memory:为AI智能体构建持久记忆的轻量级解决方案
1. 项目概述:为AI智能体构建持久记忆的“记忆锚”如果你和我一样,长期与Claude Code、Cursor这类AI编程助手并肩作战,一定对那个令人沮丧的瞬间不陌生:你花了半小时向它详细解释了一个复杂项目的架构、你的编码偏好、刚刚踩过的坑…...

Flutter中如何显示异步数据
在开发Flutter应用时,处理异步操作是非常常见的任务之一。许多时候,我们需要将异步操作的结果展示在用户界面上,比如从服务器获取数据或执行一些耗时的计算。本文将通过一个具体的实例,展示如何在Flutter中使用FutureBuilder来处理和显示异步数据。 问题背景 假设我们有一…...