MongoDB教程-8
ObjectId
在之前的所有章节中,我们一直在使用MongoDB的Object Id。在本章中,我们将了解ObjectId的结构。
ObjectId是一个12字节的BSON类型,具有以下结构-- 1.
前4个字节代表自unix epoch以来的秒数
接下来的3个字节是机器标识符
接下来的2个字节是进程ID
最后3个字节是一个随机的计数器值
MongoDB使用ObjectIds作为每个文档的_id字段的默认值,它是在创建任何文档的时候产生的。ObjectId的复杂组合使得所有的_id字段都是唯一的。
创建新的ObjectId
要生成一个新的ObjectId,请使用下面的代码 --
>newObjectId = ObjectId()
上述语句返回了以下唯一生成的id−
ObjectId("5349b4ddd2781d08c09890f3")
代替MongoDB生成ObjectId,你也可以提供一个12字节的id --
>myObjectId = ObjectId("5349b4ddd2781d08c09890f4")
创建一个文档的时间戳
由于_id ObjectId默认存储4字节的时间戳,在大多数情况下,你不需要存储任何文档的创建时间。你可以使用getTimestamp方法获取一个文档的创建时间------。
>ObjectId("5349b4ddd2781d08c09890f4").getTimestamp()
这将以ISO日期格式返回该文件的创建时间。
ISODate("2014-04-12T21:49:17Z")
将ObjectId转换为字符串
在某些情况下,你可能需要ObjectId的值为字符串格式。要将ObjectId转换为字符串,请使用下面的代码 -
>newObjectId.str
上面的代码将返回Guid的字符串格式------。
5349b4ddd2781d08c09890f3
Map Reduce
根据MongoDB文档,Map-reduce是一种数据处理范式,用于将大量的数据浓缩成有用的聚合结果。MongoDB使用mapReduce命令进行map-reduce操作。MapReduce通常用于处理大型数据集。
MapReduce命令
以下是基本的mapReduce命令的语法----。
>db.collection.mapReduce(function() {emit(key,value);}, //map functionfunction(key,values) {return reduceFunction}, { //reduce functionout: collection,query: document,sort: document,limit: number}
)map-reduce函数首先查询集合,然后对结果文件进行映射,发出键值对,再根据有多个值的键进行还原。
在上面的语法中--
map是一个javascript函数,它将一个值与一个键进行映射,并发射出一个键值对
reduce是一个javascript函数,用于减少或分组所有具有相同键的文件。
out指定map-reduce查询结果的位置
query指定选择文档的可选选择标准
sort指定了可选的排序标准
limit指定了可选的返回的最大文件数。
使用MapReduce
考虑下面这个存储用户帖子的文档结构。该文档存储了用户的用户名和帖子的状态。
{"post_text": "tutorialspoint is an awesome website for tutorials","user_name": "mark","status":"active"
}现在,我们将在我们的帖子集合上使用mapReduce函数来选择所有的活动帖子,根据用户名对它们进行分组,然后使用以下代码计算每个用户的帖子数量------。
>db.posts.mapReduce( function() { emit(this.user_id,1); }, function(key, values) {return Array.sum(values)}, { query:{status:"active"}, out:"post_total" }
)上述mapReduce查询输出的结果如下 -
{"result" : "post_total","timeMillis" : 9,"counts" : {"input" : 4,"emit" : 4,"reduce" : 2,"output" : 2},"ok" : 1,
}结果显示,共有4个文档与查询相匹配(status: "active"),map函数发出了4个有键值对的文档,最后reduce函数将有相同键值的映射文档归为2个。
要看这个mapReduce查询的结果,请使用查找操作符--
>db.posts.mapReduce( function() { emit(this.user_id,1); }, function(key, values) {return Array.sum(values)}, { query:{status:"active"}, out:"post_total" }).find()上述查询给出了以下结果,表明用户tom和mark都有两个处于活动状态的帖子 -
{ "_id" : "tom", "value" : 2 }
{ "_id" : "mark", "value" : 2 }
以类似的方式,MapReduce查询可用于构建大型复杂的聚合查询。使用自定义的Javascript函数可以利用MapReduce,它是非常灵活和强大的。
文本搜索
从2.4版本开始,MongoDB开始支持文本索引来搜索字符串内容内部。文本搜索使用词干技术,通过丢弃像a、an、the等词干的停顿词来寻找字符串字段中的指定词。目前,MongoDB支持大约15种语言。
启用文本搜索
最初,文本搜索是一个实验性的功能,但从2.6版本开始,该配置被默认启用。
创建文本索引
考虑在post集合下的以下文件,其中包含帖子文本及其标签------。
> db.posts.insert({"post_text": "enjoy the mongodb articles on tutorialspoint","tags": ["mongodb", "tutorialspoint"]
}
{"post_text" : "writing tutorials on mongodb","tags" : [ "mongodb", "tutorial" ]
})
WriteResult({ "nInserted" : 1 })我们将在post_text字段上创建一个文本索引,这样我们就可以在我们的帖子的文本中进行搜索了。
>db.posts.createIndex({post_text:"text"})
{"createdCollectionAutomatically" : true,"numIndexesBefore" : 1,"numIndexesAfter" : 2,"ok" : 1
}使用文本索引
现在我们已经在post_text字段上创建了文本索引,我们将搜索所有文本中含有tutorialspoint一词的帖子。
> db.posts.find({$text:{$search:"tutorialspoint"}}).pretty()
{"_id" : ObjectId("5dd7ce28f1dd4583e7103fe0"),"post_text" : "enjoy the mongodb articles on tutorialspoint","tags" : ["mongodb","tutorialspoint"]
}上述命令返回的结果是,在其帖子文本中有tutorialspoint一词的文件 -
{ "_id" : ObjectId("53493d14d852429c10000002"), "post_text" : "enjoy the mongodb articles on tutorialspoint", "tags" : [ "mongodb", "tutorialspoint" ]
}删除文本索引
要删除一个现有的文本索引,首先使用以下查询找到索引的名称
>db.posts.getIndexes()
[{"v" : 2,"key" : {"_id" : 1},"name" : "_id_","ns" : "mydb.posts"},{"v" : 2,"key" : {"fts" : "text","ftsx" : 1},"name" : "post_text_text","ns" : "mydb.posts","weights" : {"post_text" : 1},"default_language" : "english","language_override" : "language","textIndexVersion" : 3}
]
>从上面的查询中得到你的索引名称后,运行以下命令。这里,post_text_text是索引的名称。
>db.posts.dropIndex("post_text_text")
{ "nIndexesWas" : 2, "ok" : 1 }正则
正则表达式在所有语言中都经常被用来搜索任何字符串中的模式或单词。MongoDB也提供了正则表达式的功能,使用$regex操作符进行字符串模式匹配。MongoDB使用PCRE(Perl Compatible Regular Expression)作为正则表达式语言。
与文本搜索不同,我们不需要做任何配置或命令来使用正则表达式。
假设我们在一个名为post的数据库中插入了一个文件,如下图所示
> db.posts.insert(
{"post_text": "enjoy the mongodb articles on tutorialspoint","tags": ["mongodb","tutorialspoint"]
}
WriteResult({ "nInserted" : 1 })使用regex表达式
下面的regex查询可以搜索到所有含有字符串tutorialspoint的帖子 -
> db.posts.find({post_text:{$regex:"tutorialspoint"}}).pretty()
{"_id" : ObjectId("5dd7ce28f1dd4583e7103fe0"),"post_text" : "enjoy the mongodb articles on tutorialspoint","tags" : ["mongodb","tutorialspoint"]
}
{"_id" : ObjectId("5dd7d111f1dd4583e7103fe2"),"post_text" : "enjoy the mongodb articles on tutorialspoint","tags" : ["mongodb","tutorialspoint"]
}
>同样的查询也可以写成--
>db.posts.find({post_text:/tutorialspoint/})
使用不区分大小写的regex表达式
为了使搜索不区分大小写,我们使用$options参数,其值为$i。下面的命令将寻找有tutorialspoint这个词的字符串,不管是小写还是大写------。
>db.posts.find({post_text:{$regex:"tutorialspoint",$options:"$i"}})该查询返回的结果之一是以下文件,该文件在不同情况下包含tutorialspoint一词--
{"_id" : ObjectId("53493d37d852429c10000004"),"post_text" : "hey! this is my post on TutorialsPoint", "tags" : [ "tutorialspoint" ]
} 对数组元素使用regex
我们也可以在数组领域使用regex的概念。当我们实现标签的功能时,这一点尤其重要。因此,如果你想搜索所有标签以tutorial(或tutorial或tutorialpoint或tutorialphp)开头的帖子,你可以使用以下代码
>db.posts.find({tags:{$regex:"tutorial"}})
优化正则表达式查询
如果文档字段是有索引的,查询将利用索引值来匹配正则表达式。与正则表达式扫描整个集合相比,这使得搜索的速度非常快。
如果正则表达式是一个前缀表达式,那么所有的匹配都要以某个字符串字符开始。例如,如果正则表达式是^tut,那么查询就必须只搜索以tut开头的字符串。
GridFS
GridFS是MongoDB的规范,用于存储和检索大型文件,如图像、音频文件、视频文件等。它是一种存储文件的文件系统,但其数据被存储在MongoDB集合中。GridFS有能力存储文件,甚至超过其文件大小的限制(16MB)。
GridFS将文件分成几块,并将每块数据存储在一个单独的文档中,每块最大尺寸为255k。
GridFS默认使用两个集合fs.files和fs.chunks来存储文件的元数据和分块。每个块由其唯一的_id ObjectId字段来识别。fs.files作为一个父文件。fs.chunks文档中的files_id字段将块链接到它的父文档。
以下是fs.files集合的一个样本文件----。
{"filename": "test.txt","chunkSize": NumberInt(261120),"uploadDate": ISODate("2014-04-13T11:32:33.557Z"),"md5": "7b762939321e146569b07f72c62cca4f","length": NumberInt(646)
}该文件指定了文件名、块状大小、上传日期和长度。
以下是fs.chunks文件的一个样本 -
{"files_id": ObjectId("534a75d19f54bfec8a2fe44b"),"n": NumberInt(0),"data": "Mongo Binary Data"
}
将文件添加到GridFS
现在,我们将使用GridFS的put命令来存储一个MP3文件。为此,我们将使用Mongofiles.exe工具,它存在于MongoDB安装文件夹的bin文件夹中。
打开你的命令提示符,导航到MongoDB安装文件夹的bin文件夹中的mongofiles.exe,然后输入以下代码
>mongofiles.exe -d gridfs put song.mp3
在这里,gridfs是数据库的名称,文件将被存储在其中。如果该数据库不存在,MongoDB将自动创建一个新的文件。Song.mp3是上传文件的名称。要在数据库中看到该文件的文档,你可以使用查找查询----。
>db.fs.files.find()
上述命令返回了以下文件 -
{_id: ObjectId('534a811bf8b4aa4d33fdf94d'), filename: "song.mp3", chunkSize: 261120, uploadDate: new Date(1397391643474), md5: "e4f53379c909f7bed2e9d631e15c1c41",length: 10401959
}我们还可以使用前面查询中返回的文档id,使用以下代码查看fs.chunks集合中与存储文件相关的所有块
>db.fs.chunks.find({files_id:ObjectId('534a811bf8b4aa4d33fdf94d')})在我的例子中,查询返回了40个文件,这意味着整个MP3文件被分成了40块数据。
封顶集合是固定大小的循环集合,它遵循插入顺序,以支持创建、读取和删除操作的高性能。所谓循环,是指当分配给集合的固定大小用完时,它将开始删除集合中最古老的文档,而不提供任何明确的命令。
如果更新导致文档大小增加,封顶的集合就会限制对文档的更新。由于有上限的集合是按照磁盘存储的顺序来存储文档的,它可以确保文档的大小不会增加磁盘上分配的大小。封顶集合最适合于存储日志信息、缓存数据或任何其他高容量数据。
创建封顶集合
为了创建一个有上限的集合,我们使用普通的createCollection命令,但是将capped选项设为true,并指定集合的最大尺寸(字节)。
>db.createCollection("cappedLogCollection",{capped:true,size:10000})除了集合大小,我们还可以使用max参数−限制集合中的文档数量
>db.createCollection("cappedLogCollection",{capped:true,size:10000,max:1000})如果要检查集合是否有上限,请使用以下isCapped命令−
>db.cappedLogCollection.isCapped()
如果有一个现有的集合,你打算将其转换为封顶,你可以用下面的代码来做 --
>db.runCommand({"convertToCapped":"posts",size:10000})这段代码将把我们现有的集合帖子转换为一个有上限的集合。
查询封顶的集合
默认情况下,在一个封顶的集合上的查找查询将以插入的顺序显示结果。但是如果你想以相反的顺序检索文件,请使用排序命令,如下代码所示
>db.cappedLogCollection.find().sort({$natural:-1})关于有上限的集合,还有几个重要的点值得了解
我们不能从一个封顶的集合中删除文档。
在一个封顶的集合中没有默认的索引,甚至在_id字段上也没有。
当插入一个新的文档时,MongoDB不需要在磁盘上寻找一个位置来容纳新的文档。它可以盲目地在集合的尾部插入新的文档。这使得在有上限的集合中的插入操作非常快。
同样地,在读取文档时,MongoDB会按照磁盘上的相同顺序返回文档。这使得读取操作变得非常快。
自增
MongoDB并不像SQL数据库那样有开箱即用的自动递增功能。默认情况下,它使用12字节的ObjectId作为_id字段的主键来唯一地识别文档。然而,在某些情况下,我们可能希望_id字段有一些自动递增的值,而不是ObjectId。
由于这不是MongoDB的默认功能,我们将通过使用MongoDB文档中建议的计数器集合以编程方式实现这一功能。
使用计数器集合
考虑下面这个产品文档。我们希望_id字段是一个自动递增的整数序列,从1,2,3,4开始一直到n。
{"_id":1,"product_name": "Apple iPhone","category": "mobiles"
}为此,创建一个计数器集合,它将跟踪所有序列字段的最后一个序列值。
>db.createCollection("counters")
现在,我们将在计数器集合中插入以下文件,以productid为其键 -
> db.counters.insert({"_id":"productid","sequence_value": 0
})
WriteResult({ "nInserted" : 1 })
>字段sequence_value记录了该序列的最后一个值。
>db.counters.insert({_id:"productid",sequence_value:0})
创建Javascript函数
现在,我们将创建一个函数getNextSequenceValue,它将把序列名称作为其输入,将序列号增加1并返回更新的序列号。在我们的例子中,序列名称是 productid。
>function getNextSequenceValue(sequenceName){var sequenceDocument = db.counters.findAndModify({query:{_id: sequenceName },update: {$inc:{sequence_value:1}},new:true});return sequenceDocument.sequence_value;
}使用Javascript函数
我们现在将在创建一个新文档时使用函数getNextSequenceValue,并将返回的序列值指定为文档的_id字段。
使用下面的代码插入两个样本文件--
>db.products.insert({"_id":getNextSequenceValue("productid"),"product_name":"Apple iPhone","category":"mobiles"
})
>db.products.insert({"_id":getNextSequenceValue("productid"),"product_name":"Samsung S3","category":"mobiles"
})正如你所看到的,我们已经使用getNextSequenceValue函数来设置_id字段的值。
为了验证该功能,让我们使用find命令来获取文件 --
>db.products.find()
上述查询返回以下具有自动递增的_id字段的文件 -
{ "_id" : 1, "product_name" : "Apple iPhone", "category" : "mobiles"}
{ "_id" : 2, "product_name" : "Samsung S3", "category" : "mobiles" }相关文章:

MongoDB教程-8
ObjectId 在之前的所有章节中,我们一直在使用MongoDB的Object Id。在本章中,我们将了解ObjectId的结构。 ObjectId是一个12字节的BSON类型,具有以下结构-- 1. 前4个字节代表自unix epoch以来的秒数 接下来的3个字节是机器标识符 接下来的2…...

Redis 理论部分
前面写了很多redis项目,今天在通过redis的理论加深redis的了解,顺便做个总结 Redis 理论部分 1.redis 速度快的原因 纯内存操作单线程操作,避免频繁的上下文切换以及资源争用的问题,多线程需要占用更多的cpu资源采用非阻塞I/O多…...

Android—Monkey用法
文章目录 Monkey知识 Monkey知识 介绍 Monkey是Android中的一个命令行工具,可以运行在模拟器里或实际设备中。它向系统发送伪随机的用户事件流(如按键输入、触摸屏输入、手势输入等),实现对正在开发的应用程序进行压力测试。Monkey测试是一种为了测试软…...

几个影响 cpu cache 性能因素及 cache 测试工具介绍
》内核新视界文章汇总《 文章目录 1 cache 性能及影响因素1.1 内存访问和性能比较1.2 cache line 对性能的影响1.3 L1 和 L2 缓存大小1.4 指令集并行性对 cache 性能的影响1.5 缓存关联性对 cache 的影响1.6 错误的 cacheline 共享 (缓存一致性)1.7 硬件设计 2 cpu cache benc…...
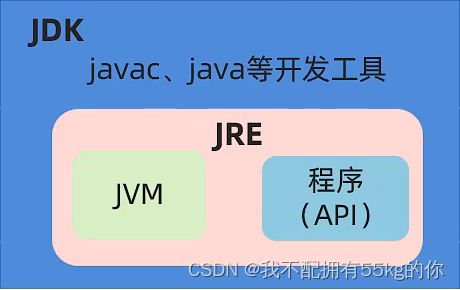
Java从入门到精通(二)· 基本语法
Java从入门到精通(二) 基本语法 一 变量 1.字面量 计算机是用来处理数据的,字面量就是告诉程序员:数据在程序中的书写格式。 特殊的字符: \n 表示换行, \t 表示一个制表符,即一个tab 2.变量…...
之 面向云原生环境的安全体系)
云安全攻防(三)之 面向云原生环境的安全体系
面向云原生环境的安全体系 根据云原生环境的构成,面向云原生环境的安全体系可包含三个层面的安全体制,它们分别是容器安全、编排系统安全和云原生应用安全,下面,我们逐步来讲解这三点: 容器安全 容器环境࿰…...
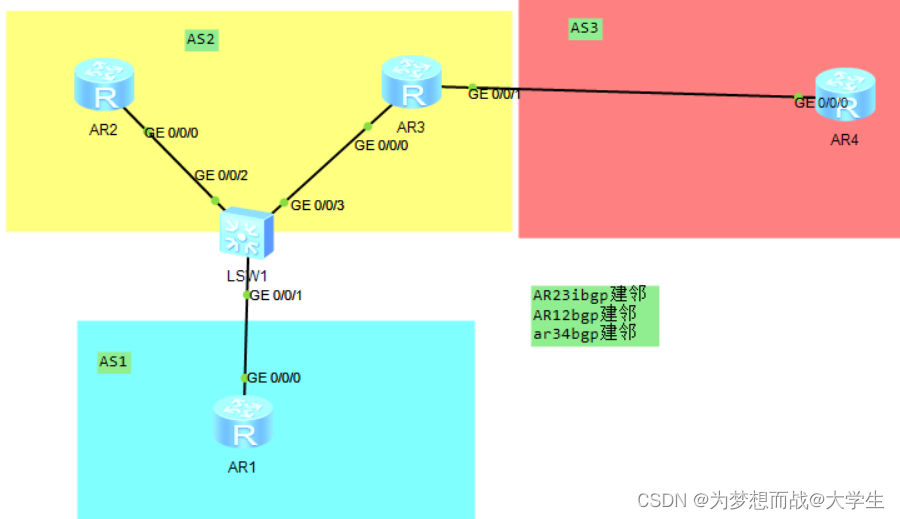
BGP汇总和破解水平分割
一,BGP的宣告问题 在BGP协议中每台运行BGP的设备上,宣告本地直连路由在BGP协议中运行BGP协议的设备来宣告,通过IGP学习到的,未运行BGP协议设备产生的路由; 在BGP协议中宣告本地路由表中路由条目时,将携带本…...
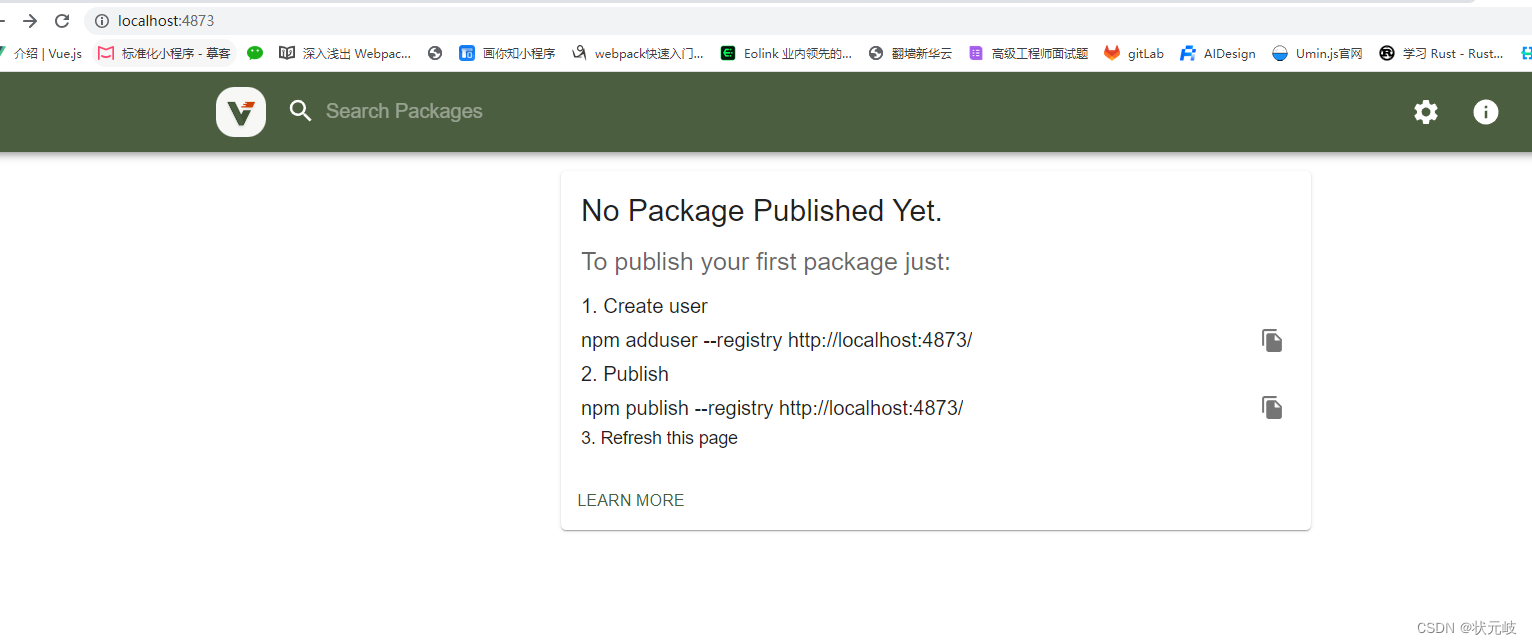
BUG:pm2启动verdaccio报错:Invalid or unexpected toke
输入命令: pm2 state verdaccio 问题描述: pm2 logs verdaccio报错翻译:数据格式错误 导致我呢提原因,没有找到运行文件, 发现问题:因为命令默认查找verdaccio是去系统盘查找。 解决方式 1:…...

Zookeeper笔记
为什么要使用Zookeeper dubbo需要一个注册中心,而Zookeeper是我们在使用Dubbo是官方推荐的注册中心 Zookeeper介绍 Zookeeper的集群机制 Zookeeper是为了其他分布式程序提供服务的,所以不能随便就挂了。Zookeeper的集群机制采取的是半数存活机制。也…...
【视觉SLAM入门】5.1. 特征提取和匹配--FAST,ORB(关键点描述子),2D-2D对极几何,本质矩阵,单应矩阵,三角测量,三角化矛盾
"不言而善应" 0. 基础知识1. 特征提取和匹配1.1 FAST关键点1.2 ORB的关键点--改进FAST1.3 ORB的描述子--BRIEF1.4 总结 2. 对极几何,对极约束2.1 本质矩阵(对极约束)2.1.1 求解本质矩阵2.1.2 恢复相机运动 R , t R,t R,…...

【能量管理系统( EMS )】基于粒子群算法对光伏、蓄电池等分布式能源DG进行规模优化调度研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
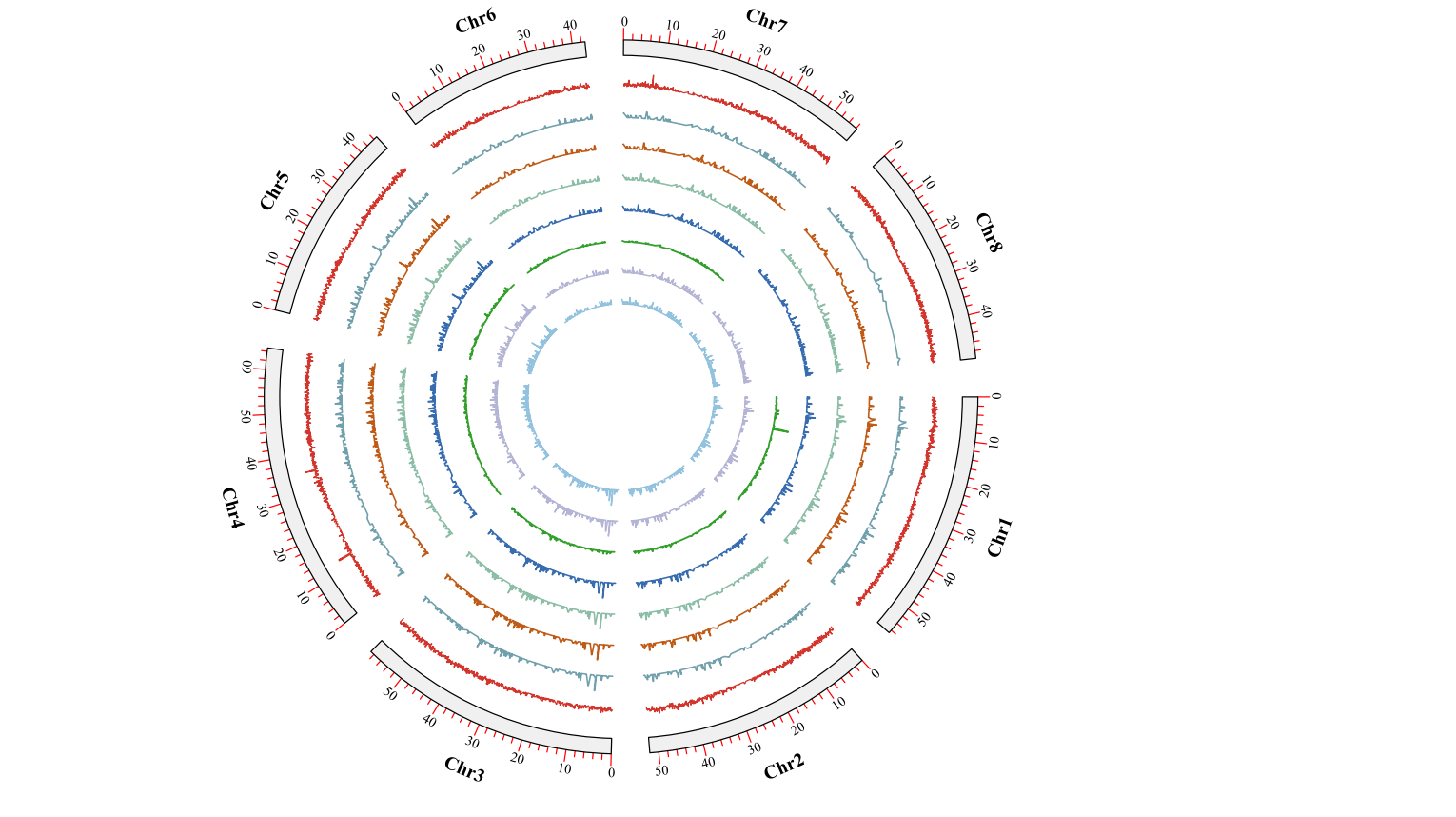
绘制Circos基因圈图
写在前面 昨天在绘制Circos圈图,已经隔了2年左右没有做这类的图了。这时间过得真是快,但是文章和成果依旧是没有很明显的成效。只能安慰自己,后面的时间继续加油吧!关于Cirocs图的制作,我从刚开始到现在都是是使用TBt…...

openGauss学习笔记-26 openGauss 高级数据管理-约束
文章目录 openGauss学习笔记-26 openGauss 高级数据管理-约束26.1 NOT NULL约束26.2 UNIQUE约束26.3 PRIMARY KEY26.4 FOREIGN KEY26.5 CHECK约束 openGauss学习笔记-26 openGauss 高级数据管理-约束 约束子句用于声明约束,新行或者更新的行必须满足这些约束才能成…...

学习React(四)
学习React(四) componentWillMount(被放弃使用)rendercomponentDidMountshouldComponentUpdate(nextProps,nextState)componentWillUpdate(被放弃使用)componentDidUpdatecomponentWillReceiveProps&#x…...

如何将单体项目拆分成微服务
1、如何将单体项目拆分成微服务 如何拆分微服务?其实对不同的业务项目场景,对应有不同的拆分方案。需要项目人员详细的分析项目需求、团队现状、业务边界、业务逻辑等方方面面,拆分的粒度既不能过细,也不能过粗,需要把…...
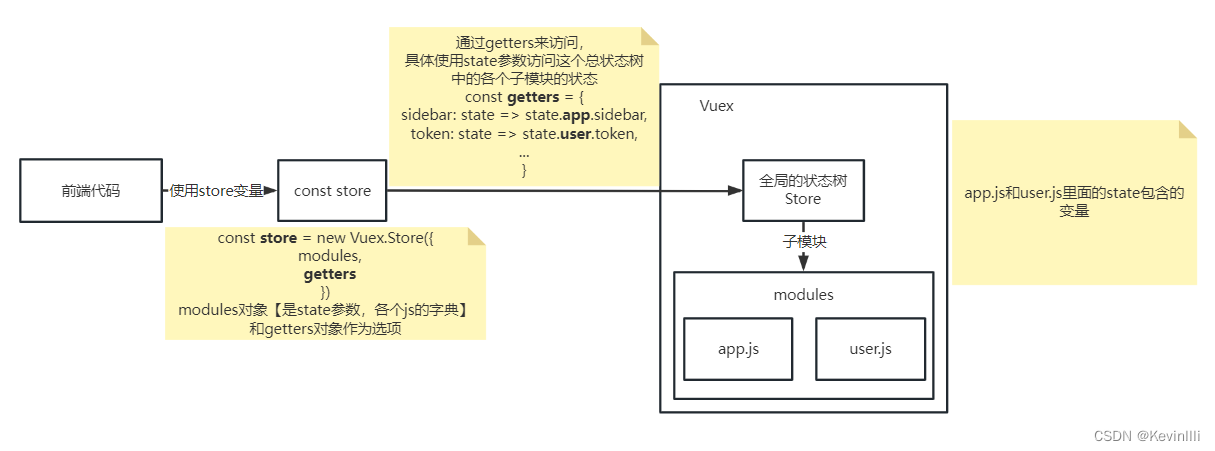
【Vue框架】Vuex状态管理
前言 在上一篇 【Vue框架】Vue路由配置 结尾时说到store.js,在代码里new Vuex.Store()传入了getters对象;本篇专门针对getters的内容进行整理。 1、getters.js 1.1 代码 // 用于存储获取状态的方法 const getters {// 这里的state参数,是…...
Linked List
文章目录 链表定义专业术语代码链表分类常见算法链表创建和常用算法 链表总结 链表 补充知识 typedef 给类型换名字,比如 typedef struct Student {int sid;char name[100];char sex; }ST;//ST就代表了struct Student //即这上方一大坨都可以用ST表示 //原先结构体…...

javascript数组基础
文章和代码已经归档至【Github仓库:https://github.com/timerring/front-end-tutorial 】或者公众号【AIShareLab】回复 javascript 也可获取。 文章目录 数组的基本使用定义数组和数组单元访问数组和数组索引数据单元值类型数组长度属性操作数组 数组:(…...
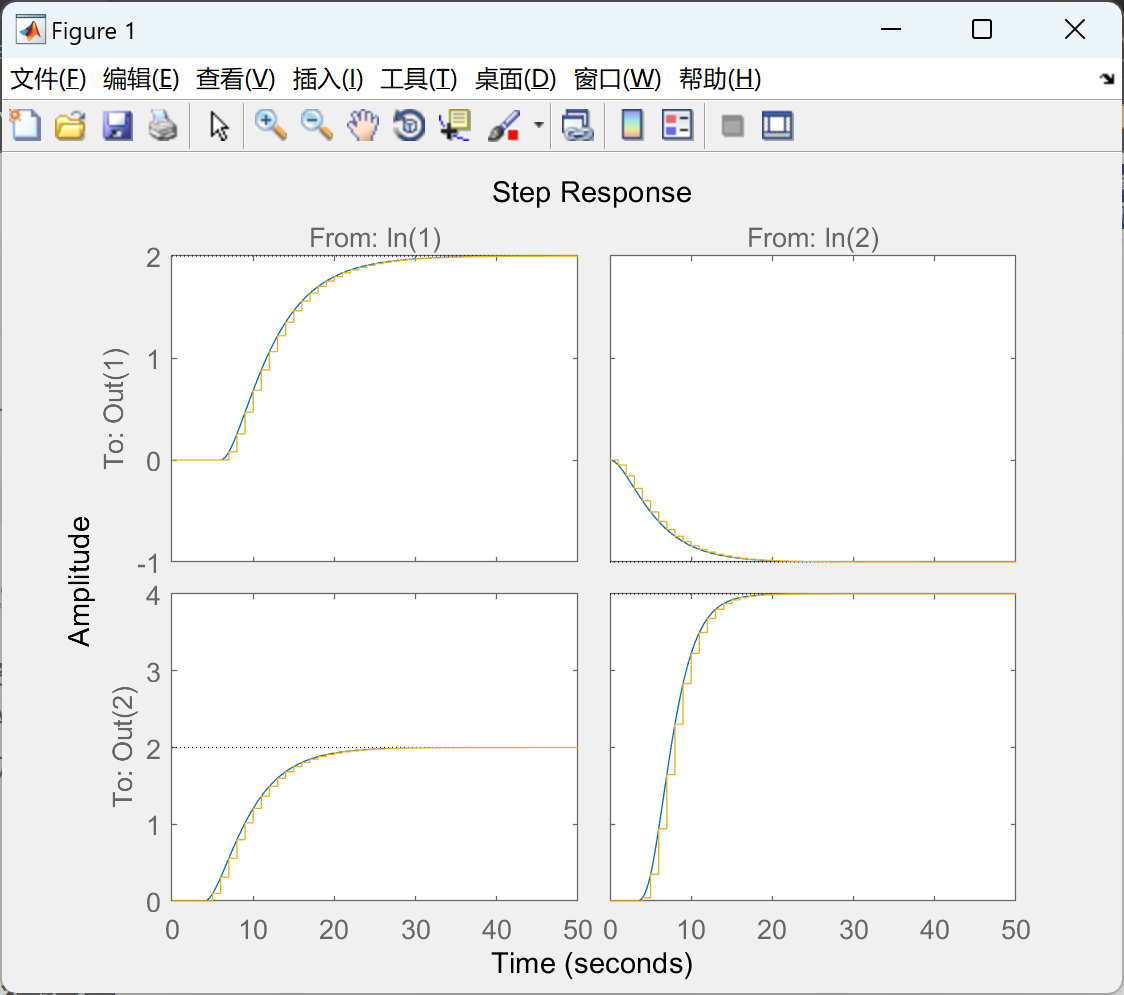
【模型预测控制MPC】使用离散、连续、线性或非线性模型对预测控制进行建模(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Golang之路---01 Golang VS Code创建项目
Golang VS Code创建项目 代码组织 Golang使用包和模块来组织代码,包对应到文件系统就是文件夹,模块就是xxx.go的go源文件。一个包中会有多个模块,或者多个子包。 早期使用的是gopath来管理项目,不方便,比较麻烦&…...
)
告别复杂推导!用PyTorch 2.0手把手实现Reptile算法(附完整代码与对比实验)
告别复杂推导!用PyTorch 2.0手把手实现Reptile算法(附完整代码与对比实验) 元学习(Meta-Learning)作为机器学习领域的前沿方向,近年来在少样本学习、快速适应新任务等场景展现出巨大潜力。然而,…...
,法务已验证)
企业采购必读:ElevenLabs合同中6处关键条款陷阱(含地域限制、转授权失效、审计权模糊等),法务已验证
更多请点击: https://intelliparadigm.com 第一章:企业采购必读:ElevenLabs合同中6处关键条款陷阱(含地域限制、转授权失效、审计权模糊等),法务已验证 地域限制条款的隐性封锁效应 ElevenLabs服务协议第…...
)
py每日spider案例之某website之xin东方选课搜索接口(难度一般 扣取代码即可)
加密位置: 逆向接口参数: 逆向接口: const g = globalThis; g.window = g; g.self = g; g.location = {<...

智能卡通信调优实战:手把手教你用逻辑分析仪抓取并解析ISO7816 PPS协商过程
智能卡通信调优实战:手把手教你用逻辑分析仪抓取并解析ISO7816 PPS协商过程 在嵌入式系统和智能卡应用开发中,通信稳定性往往是项目成败的关键。当你的智能卡设备频繁出现通信中断、数据丢失或速率不达标时,问题很可能隐藏在协议协商阶段。IS…...

【独家首发】ElevenLabs尚未官方支持的希伯来文增强模式:基于phoneme-level微调的48小时快速部署方案
更多请点击: https://intelliparadigm.com 第一章:希伯来文语音合成的技术挑战与ElevenLabs生态定位 希伯来文是一种自右向左(RTL)书写的辅音音素文字,其语音合成面临多重语言学与工程学挑战:元音符号&…...

Windows上的革命性文件系统:WinBtrfs完整指南与实用教程
Windows上的革命性文件系统:WinBtrfs完整指南与实用教程 【免费下载链接】btrfs WinBtrfs - an open-source btrfs driver for Windows 项目地址: https://gitcode.com/gh_mirrors/bt/btrfs WinBtrfs是一个开源的Windows驱动程序,为Windows用户带…...

Horos:免费开源医学影像软件,3D医疗图像处理的终极指南
Horos:免费开源医学影像软件,3D医疗图像处理的终极指南 【免费下载链接】horos Horos™ is a free, open source medical image viewer. The goal of the Horos Project is to develop a fully functional, 64-bit medical image viewer for OS X. Horos…...

观察使用 Token Plan 套餐后月度模型调用成本的变化趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用 Token Plan 套餐后月度模型调用成本的变化趋势 作为一名中小型项目的开发者,管理大模型 API 的调用成本是项目…...

在macOS上运行Windows应用:为什么传统方案失败而Whisky成功
在macOS上运行Windows应用:为什么传统方案失败而Whisky成功 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 你是否曾经面临这样的困境:手头有一款必须使用的W…...
)
LabelImg标注的YOLO格式txt坐标转换保姆级教程(附Python代码)
LabelImg标注的YOLO格式坐标转换实战指南:从原理到Python实现 在计算机视觉项目中,数据标注是模型训练前的关键步骤。LabelImg作为一款开源的图像标注工具,支持生成YOLO格式的标注文件。然而,许多开发者在实际应用中发现ÿ…...