可以写进简历的kafka优化-----吞吐量提升一倍的方法
冲突
在看到项目工程里kafka 生产端配置的batch.size为500,而实际业务数据平均有1K大小的时候;我有点懵了。是的,这里矛盾了;莫非之前的作者认为这个batch.size是发送的条数,而不是kafka生产端内存缓存记录的大小? 实际业务数据有1K大小;那么正式环境的生产端岂不是没有用到kafka缓存池带来的好处。
最近也正在了解并解读kafka生产端源码,被kafka的设计所折服时;恼人的现实和美好的理论存在巨大的矛盾, 引起了我的怀疑和推测。怎么办?先和技术领导沟通下吧。
在请教过技术领导为什么这里设置为500时,获得了一个非预期的回答:“这个项目已经稳定运行5年了,也没什么问题呀”; 想必大家也遇到过类似的情况吧~~
想要说服领导,更改这个不是最优的设置,需要拿出更多的证据。如何去做了?
求证之路
为了验证batch.size 为500不是最优的(其实是为了验证kafka发送端用缓存池还是不用缓存池的区别)。写了两个对比不超过10行代码的kafka生产端代码。
第一个case是:发送固定100W消息量。对比batch 500B 和16K 两者的耗时,GC次数,GC耗时等的对比
第二个case是:在固定时间内。对比batch 500B和16K两者发送消息量,GC次数,GC耗时等的对比
当然msg大小为业务大小固定1KB。
具体代码如下
case1: 发送固定100W消息量,耗时,GC等信息对比
java 发送端代码
long begin = System.currentTimeMillis();
for(int j=1000;j>0;j--){for(int i=0;i<1000;i++){kafkaProducerTest.send(topic,msg);}kafkaProducerTest.flush();//每发送1000次,sleep 500毫秒try {Thread.sleep(500);} catch (InterruptedException e) {throw new RuntimeException(e);}
}
long end = System.currentTimeMillis();
log.info("cast time:" + (end-begin));
监控工具: jstat
使用了JVM 原生的GC 监控工具对GC次数和耗时进行监控
命令如下
jstat -gcutil pid 1000
输出:主要是看YGC,YGCT,FGC,FGCT,GCT
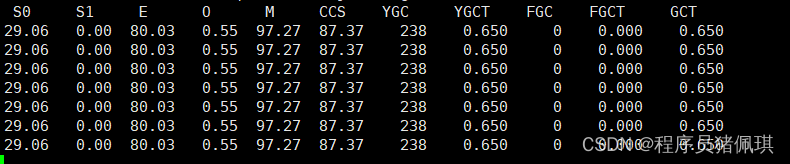
统计结果

为了减小误差,每个batch.size,都测试了两遍,取平均值做为底数。
从统计结果可看到
- 使用了缓存池,比不使用,耗时减少了64.51%。(这里减了500*1000,是为了减少sleep(500)的影响),吞吐量也就提高了一倍
- 使用了缓存池,比不使用,GC次数降低了27%,GC耗时减少了39%
数据还蛮符合事先猜测:吞吐量,GC次数,GC耗时;在使用了缓存池后都比不使用要优异
case2 持续3分钟,两者发送消息量的统计,GC等信息统计
java代码
long maxTime = 3 * 60 * 1000l;while (true){for(int i=0;i<1000;i++){kafkaProducerTest.send(topic,msg);}count ++;kafkaProducerTest.flush();//发送1000条,sleep 10毫秒try {Thread.sleep(10);} catch (InterruptedException e) {throw new RuntimeException(e);}//只跑maxTimeif(System.currentTimeMillis() - begin > maxTime){break;}
}
log.info("count:" + count);
统计结果
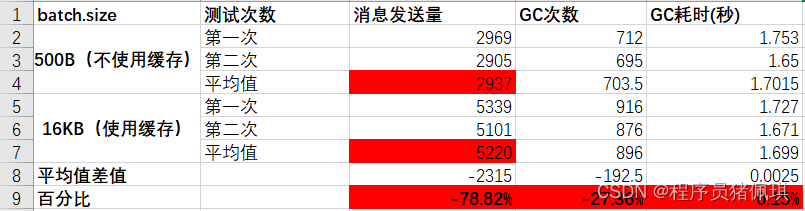
从统计结果可看到
- 使用了缓存池,比不使用缓冲池;消息发送量提高了78%。即在相同时间内,使用缓冲池,能提高1倍以上的吞吐量
- 使用了缓存池,比不使用缓冲池;GC次数大概提高了27%,而GC耗时基本相同。
总结
从上面的统计来看,如果想要提高发送消息吞吐量,请尽量使用缓存池。你的项目中,真的使用了缓存池吗?
曾经解读过kafka生产端内存模型的设计;以及由kafka内存池模型设计,联想到多年前初学java时的认知。始终感觉有点偏向理论,这篇算出一个对之前理论性设计的论证,实际实践后的数据证据吧。如果要用一句话来总结这次的感悟和行动,想借用陆游的一句大家都很熟悉的绝句来描述:纸上得来终觉浅,绝知此事要躬行。
参考资料:
https://blog.csdn.net/chenhcao628/article/details/108038172 《jstat -gcuti命令分析 》
https://juejin.cn/post/7259300929026916409 《读kafka生产端源码,窥kafka设计之道(下)》
https://juejin.cn/post/7259300929026916409 《java内存管理 美好的期望与现实的残酷》
《深入理解Kafka:核心设计与实践原理》
《kafka源码》
相关文章:
可以写进简历的kafka优化-----吞吐量提升一倍的方法
冲突 在看到项目工程里kafka 生产端配置的batch.size为500,而实际业务数据平均有1K大小的时候;我有点懵了。是的,这里矛盾了;莫非之前的作者认为这个batch.size是发送的条数,而不是kafka生产端内存缓存记录的大小&…...

JavaScript中,for in 和for of的区别
for in 遍历的是数组的索引(即键名),而 for of 遍历的是数组元素值(即键值)。for...in 循环出的是 key,for...of 循环出的是 value 推荐在循环对象属性的时候使用 for...in,在遍历数组的时候的时…...

计算机毕设 深度学习手势识别 - yolo python opencv cnn 机器视觉
文章目录 0 前言1 课题背景2 卷积神经网络2.1卷积层2.2 池化层2.3 激活函数2.4 全连接层2.5 使用tensorflow中keras模块实现卷积神经网络 3 YOLOV53.1 网络架构图3.2 输入端3.3 基准网络3.4 Neck网络3.5 Head输出层 4 数据集准备4.1 数据标注简介4.2 数据保存 5 模型训练5.1 修…...

vue3 axios接口封装
在Vue 3中,可以通过封装axios来实现接口的统一管理和调用。封装后的接口调用更加简洁,代码可维护性也更好。以下是一个简单的Vue 3中axios接口封装的示例: 1.首先,安装axios和qs(如果需要处理复杂数据)&am…...

誉天程序员-2301-3-day08
4. 书籍管理实现CURD 这个结构比较复杂,是有一套复杂的机制,注意它们之间的关系和控制实现。 新增和修改怎么复用对话框 对话框中的数据,表格中展现的数据,临时记录正在操作的数据统一联动起来 单条删除怎么传递数据&am…...

Python爬虫(1)一次性搞定Selenium(新版)8种find_element元素定位方式
selenium中有8种不错的元素定位方式,每个方式和应用场景都不一样,需要根据自己的使用情况来进行修改 8种find_element元素定位方式 1.id定位2.CSS定位3.XPATH定位4.name定位5.class_name定位6.Link_Text定位7.PARTIAL_LINK_TEXT定位8.TAG_NAME定位总结 …...

前端(十一)——Vue vs. React:两大前端框架的深度对比与分析
😊博主:小猫娃来啦 😊文章核心:Vue vs. React:两大前端框架的深度对比与分析 文章目录 前言概述原理与设计思想算法生态系统与社区支持API与语法性能与优化开发体验与工程化对比总结结语 前言 在当今快速发展的前端领…...
三分钟白话RocketMQ系列—— 核心概念
目录 关键字摘要 Q1:RocketMQ是什么? Q2: 作为消息中间件,RocketMQ和kafka有什么区别? Q3: RocketMQ的基本架构是怎样的? Q4:RocketMQ有哪些核心概念? 总结 RocketMQ是一个开源的分布式消…...

递归竖栏菜单简单思路
自己的项目要写一个竖栏菜单,所以记录一下思路吧,先粗糙的实现一把,有机会再把细节修饰一下 功能上就是无论这个菜单有多少层级,都能显示出来,另外,需要带图标,基于element-plus写成࿰…...

组件化、跨平台…未来前端框架将如何演进?
前端框架在过去几年间取得了显著的进步和演进。前端框架也将继续不断地演化,以满足日益复杂的业务需求和用户体验要求。从全球web发展角度看,框架竞争已经从第一阶段的前端框架之争(比如Vue、React、Angular等),过渡到…...
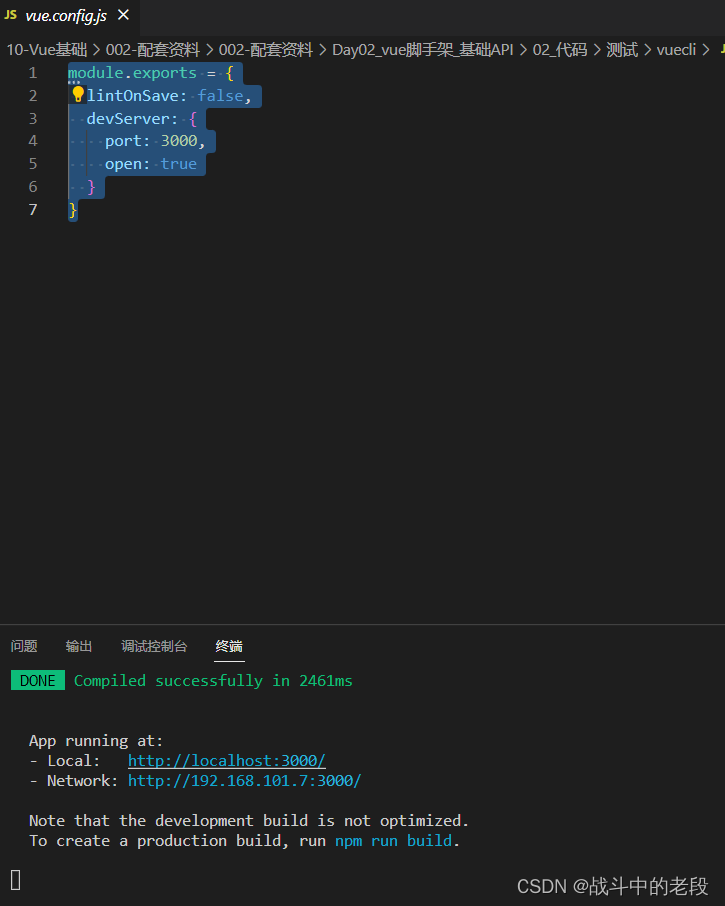
vue 修改端口号
在根目录创建一个vue.config.js文件夹 module.exports {lintOnSave: false,devServer: {port: 3000,open: true} }运行后...

hive的metastore问题汇总
1. metastore内存飙升 1 问题 metastore内存飙升降不下来; spark集群提交的任务无法运行, 只申请到了dirver的资源; 2 原因 当Spark任务无法获取足够资源时,因为任务无法继续进行,不能将元数据从Metastore返回给任务 后,这些元数据暂存在…...
【phaser微信抖音小游戏开发003】游戏状态state场景规划
经过目录优化后的执行结果: 经历过上001,002的规划,我们虽然实现了helloworld .但略显有些繁杂,我们将做以下的修改。修改后的目录和文件结构如图。 game.js//小游戏的重要文件,从这个开始。 main.js 游戏的初始化&a…...

字符串性能优化
String 对象作为 Java 语言中重要的数据类型,是内存中占据空间最大的一个对象。高效地 使用字符串,可以提升系统的整体性能。 来一到题来引出这个话题 通过三种不同的方式创建了三个对象,再依次两两匹配,每组被匹配的两个对象是否…...
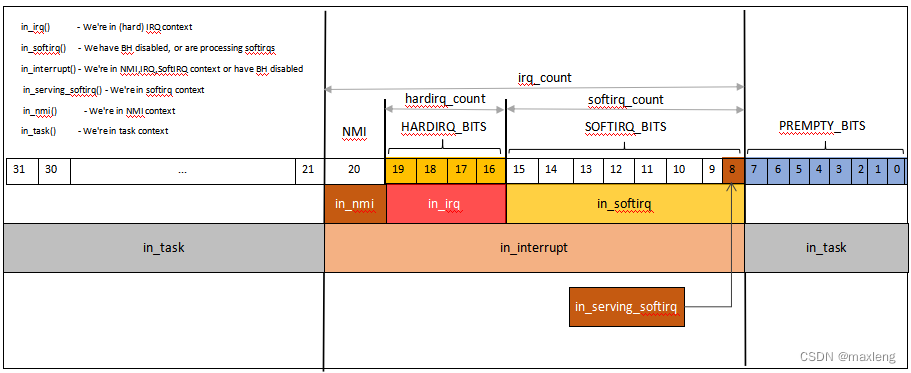
从零开始理解Linux中断架构(23)中断运行临界区和占先调度
Linux在内核中定义了6种运行临界区。 in_interrupt in_interrupt在驱动中使用频率最高的函数了,in_interrupt()就是指示Core是否正在中断处理中,包含了硬中断,软中断运行临界区。如果在中断处理中,则不能调用__do_softirq执行软中断处理。硬中断中不可调度不可中断,所有…...
Gymnasium--CartPole的测试基于DQN)
(3)Gymnasium--CartPole的测试基于DQN
1、使用Pytorch基于DQN的实现 1.1 主要参考 (1)推荐pytorch官方的教程 Reinforcement Learning (DQN) Tutorial — PyTorch Tutorials 2.0.1cu117 documentation (2) Pytorch 深度强化学习 – CartPole问题|极客笔记 2.2 pytorch官方的教程原理 待续,这两天时…...
利用sklearn 实现线性回归、非线性回归
代码: import pandas as pd import numpy as np import matplotlib import random from matplotlib import pyplot as plt from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LinearRegression# 创建虚拟数据 x np.array(r…...
Java课题笔记~ MyBatis入门
一、ORM框架 当今企业级应用的开发环境中,对象和关系数据是业务实体的两种表现形式。业务实体在内存中表现为对象,在数据库中变现为关系数据。当采用面向对象的方法编写程序时,一旦需要访问数据库,就需要回到关系数据的访问方式&…...
Activity的自启动模式
以下内容摘自郭霖《第一行代码》第三版 文章目录 Activity的自启动模式1.standard(默认)2.singleTop3.singleTask4.singleInstance Activity的自启动模式 启动模式一共有4种,分别是standard、singleTop、singleTask和singleInstance&#x…...

53数组的扩展
数组的扩展 扩展运算符Array.from()Array.of()实例方法:copyWithin()实例方法:find(),findIndex(),findLast(),findLastIndex()实例方法:fill()[实例方法:entries(),keys() 和 valu…...
,仅开放48小时下载)
【独家首发】ElevenLabs未公开马拉地语音素映射表(含Devanagari Unicode对照),仅开放48小时下载
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs马拉地语音素映射表的发现背景与战略价值 ElevenLabs 作为前沿语音合成平台,其多语言支持能力持续扩展,但官方文档中并未公开马拉地语(Marathi)…...

C语言入门指南:从核心概念到实战项目,掌握指针与内存管理
1. 项目概述:一份写给新手的C语言全景地图“长文预警,比较全面的C语言入门笔记!”——这个标题背后,是一位老码农(比如我)在某个深夜,面对无数初学者在C语言入门路上反复踩坑、四处寻找零散资料…...

向量寄存器文件优化:Register Dispersion技术解析
1. 向量寄存器文件的技术挑战与优化背景在处理器架构设计中,向量寄存器文件(Vector Register File, VRF)作为向量处理单元(VPU)的核心组件,承担着存储和管理向量数据的关键任务。传统VRF设计通常采用固定数…...

2025 上海 GEO 优化公司最新权威推荐:技术领航者与合作指南
一、核心关键词GEO 优化、生成式引擎优化、AI 搜索流量、上海 GEO 公司、本地服务 GEO、跨境 GEO、DeepSeek 排名优化、豆包排名优化、装修行业 GEO、B2B 获客优化、全域 AI 营销、合规 GEO 服务二、GEO 简介及上海市场现状分析1. GEO 核心定义GEO(Generative Engin…...

[Cesium] 数字孪生实践 | 超图插件打通UE4/Unity三维GIS管线全解析
1. 数字孪生与三维GIS技术融合的现状 数字孪生技术正在改变我们理解和构建物理世界的方式。简单来说,数字孪生就是通过数字化手段,在虚拟空间中创建一个与真实世界完全对应的"双胞胎"。这个数字化的双胞胎可以实时反映真实世界的状态ÿ…...

基于代理建模与系统仿真的唐代政治制度数字重构
1. 项目概述与核心价值最近在开源社区里,我注意到一个名为“Tang-Political-System”的项目,它的名字直译过来是“唐代政治制度”。作为一个对历史、制度设计以及开源协作模式都抱有浓厚兴趣的开发者,这个项目立刻引起了我的注意。它并非一个…...
)
Vivado工程文件太大?三步教你用Tcl脚本实现源码“瘦身”与备份(附完整命令)
Vivado工程瘦身实战:Tcl脚本驱动的源码管理与协作优化 在FPGA开发领域,Vivado工程文件的体积膨胀问题一直是开发者面临的痛点。一个中等规模的项目经过几次综合与实现后,工程目录轻松突破数百MB并不罕见。这不仅占用宝贵的存储空间ÿ…...

PTA数据结构实战:层次遍历巧解二叉树叶结点输出
1. 从问题理解到解题思路 第一次看到PTA上这道二叉树题目时,我也被题目描述唬住了。题目要求按从上到下、从左到右的顺序输出所有叶结点,这不就是典型的层次遍历(BFS)应用场景吗?但仔细分析输入格式后,我发…...

Windows下Carla编译启动卡在75%?别急着重装,先检查这个隐藏的压缩包
Windows下Carla编译启动卡在75%?别急着重装,先检查这个隐藏的压缩包 当你满怀期待地在Windows上完成Carla的编译,输入make launch命令后,进度条却在75%处戛然而止,弹出一个冰冷的"Fatal error"对话框——这…...

Minecraft服务器技能管理自动化:mcpskills-cli命令行工具实战指南
1. 项目概述与核心价值最近在折腾一些自动化脚本,特别是涉及到Minecraft服务器管理和技能系统的时候,发现很多操作还是得手动进后台敲命令,或者依赖一些图形化面板,效率上总感觉差了点意思。直到我发现了alibiinformationsuperhig…...