【图像分类】CNN+Transformer结合系列.2
介绍几篇利用CNN+Transformer实现图像分类的论文:CMT(CVPR2022),MaxViT(ECCV2022),MaxViT(ECCV2022),MPViT(CVPR2022)。主要是说明Transformer的局限性,然后利用CNN的优势去弥补和结合。
CMT: Convolutional Neural Networks Meet Vision Transformers, CVPR2022
论文:https://arxiv.org/abs/2107.06263
代码:https://github.com/ggjy/cmt.pytorch
解读:【图像分类】2022-CMT CVPR_說詤榢的博客-CSDN博客
CVPR22 |CMT:CNN和Transformer的高效结合(开源) - 知乎 (zhihu.com)
简介
Vision Transformer 已成功应用于图像识别任务,因为它们能够捕获图像中的远程依赖关系。然而,Transformer 和CNN在性能和计算成本上仍然存在差距,Transformer在patch化图像构建远程依赖时,容易破坏局部结构信息,降低其性能。
本文目标是将CNN的优点结合到Transformer中,以解决上述问题。提出了一个全新的架构CMT,基于层级结构(stage-wise)的transformer,引入卷积操作进行细粒度特征提取,同时也设计了独特的模块层次化提取局部和全局特征。利用transformer来捕获远程依赖关系,并利用 CNN 对局部特征进行建模。在ImageNet基准测试和下游任务上的实验表明了该方法在精度和计算复杂度方面的优越性。

CMT方法
- 首先,输入 Image 进入 CMT Stem,利用卷积进行特征提取并减小图像尺寸。
- 然后,输入由CMT Block堆叠成的4个stage中。
- 最后经过全局平均池化 + 全连接 + softmax 进行分类。

CMT block
包括三部分:a local perception unit (LPU) 局部感知单元, a lightweight multi-head self-attention (LMHSA) module 轻量级多头注意力, and an inverted residual feed-forward network (IRFFN) 反向残差前馈网络。
LPU:采用3x3的深度分离卷积,将卷积的平移不变形引入Transformer模块,并利用残差连接稳定网络训练。
![]()
LMHSA: 利用两个kxk的深度分离卷积分别对Key和Value的生成进行降采样处理,获得两个相对较小的特征K’和V’,节省计算量和显存。
![]()

![]()
IRFFN:在两层全连接层之间加入了深度可分离卷积层.


网络架构
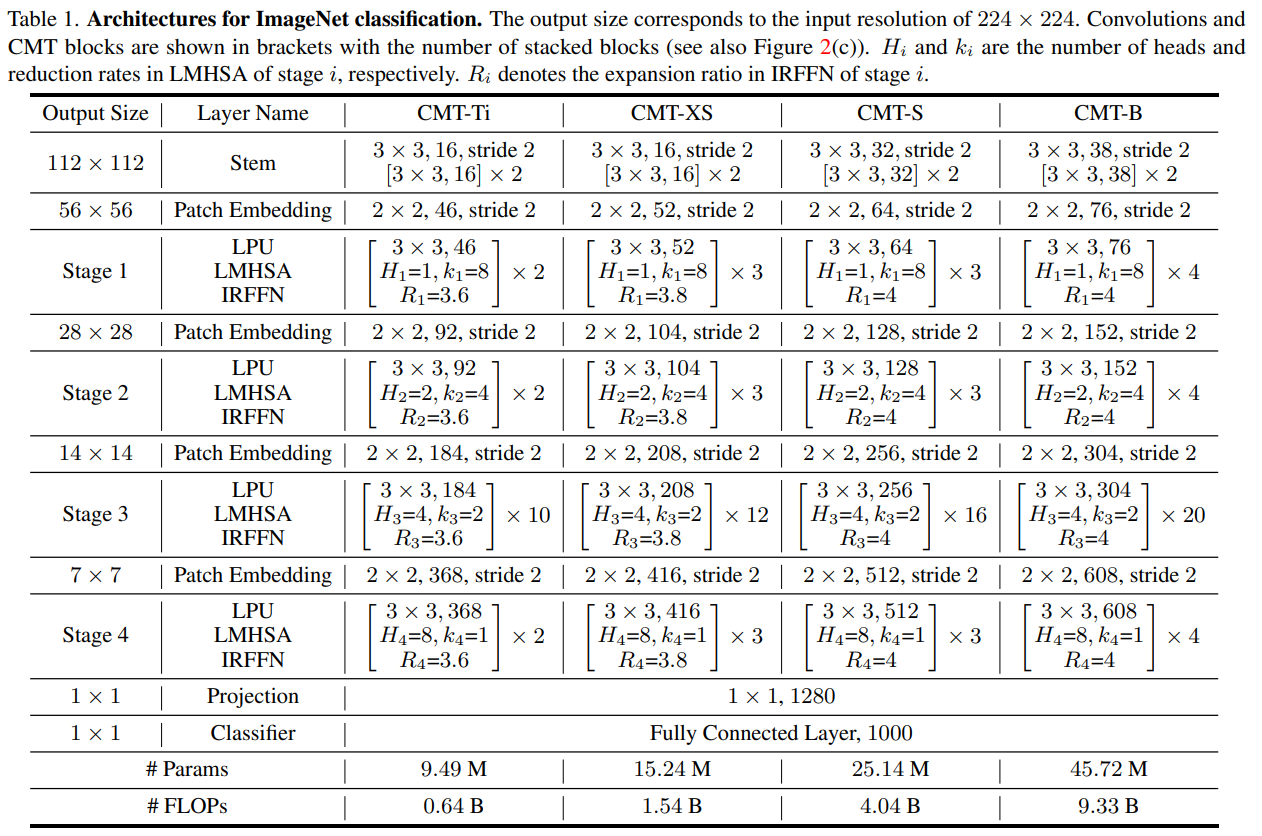
CMT网络主要由CMT(Conv) Stem,四个下采样层,四个Stage,池化层和全连接分类器组成,其中每个Stage由若干个CMT Block堆叠构成。具体结构如表1所示,其中Hi和ki 分别是轻量级多头注意力模块的头部数量和下采样率,Ri是反向残差前馈网络中间层通道的扩增倍数。
实验
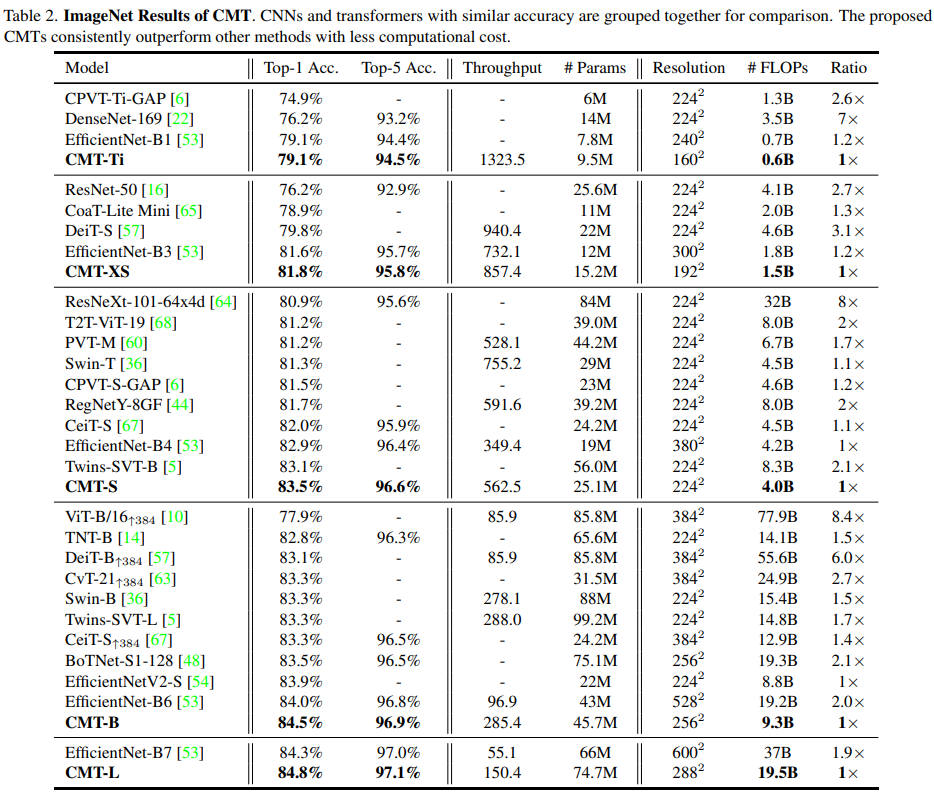
MaxViT: Multi-Axis Vision Transformer, ECCV2022
论文:https://arxiv.org/abs/2204.01697
代码:https://github.com/google-research/maxvit
解读:【图像分类】2022-MaxViT ECCV_图像分类最新模型_說詤榢的博客-CSDN博客
MaxViT: Multi-Axis Vision Transformer - 知乎
简介
由于自注意力的机制对于图像大小方面缺乏可扩展性,限制了它们在视觉主干中的应用。本文提出了一种高效的可拓展的全局注意,该模型包括两个方面:阻塞的局部注意和拓展的全局注意。这些设计选择允许在任意输入分辨率上进行全局-局部空间交互,仅具有线性复杂度。作者通过将该注意模型与卷积有效结合,并简单的将这些模块堆叠,形成了了一个分层的视觉主干网络MaxVit。值得注意的是,MaxVit能在整个网络中看到全局甚至是在早期的高分辨率的阶段。在分类任务上,该模型在ImaegNet 1K上达到86.5%的 top-1准确率,在imageNet-21K上纪进行预训练,top-1准确率可以达到88.7%。
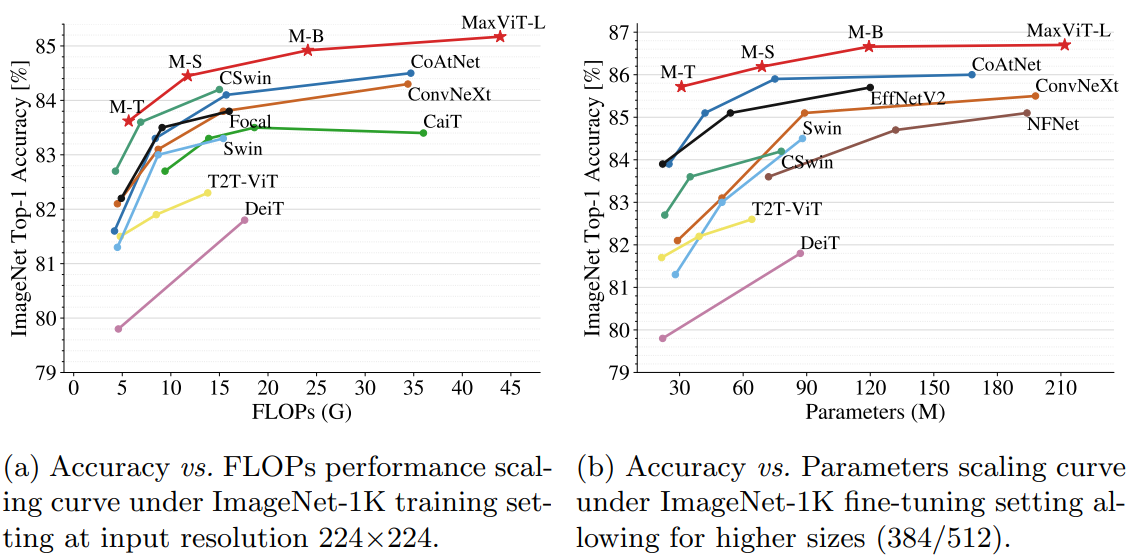
动机
研究发现,如果没有广泛的预训练,ViT在图像识别方面表现不佳。这是由于Transformer具有较强的建模能力,但是缺乏归纳偏置,从而导致过拟合。
一个有效的解决方法就是控制模型容量并提高其可扩展性,在参数量减少的同时得到性能的增强,如Twins、LocalViT以及Swin Transformer等。这些模型通常重新引入层次结构以弥补非局部性的损失,比如Swin Transformer通过在移位的非重叠窗口上应用自我注意。但在灵活性与可扩展性得到提高的同时,由于这些模型普遍失去了类似于ViT的非局部性,即具有有限的模型容量,导致无法在更大的数据集上扩展(ImageNet-21K、JFT等)。
综上,研究局部与全局相结合的方法来增加模型灵活性是有必要的。然而,如何实现对不同数据量的适应,如何有效结合局部与全局计算的优势成为本文要解决的目标。
本文设计了一种简单而有效的视觉骨干,称为多轴Transformer(MaxViT),它由Max-SA和卷积组成的重复块分层叠加。
- MaxViT是一个通用的Transformer结构,在每一个块内都可以实现局部与全局之间的空间交互,同时可适应不同分辨率的输入大小。
- Max-SA通过分解空间轴得到窗口注意力(Block attention)与网格注意力(Grid attention),将传统计算方法的二次复杂度降到线性复杂度。
- MBConv作为自注意力计算的补充,利用其固有的归纳偏差来提升模型的泛化能力,避免陷入过拟合。
MaxViT方法
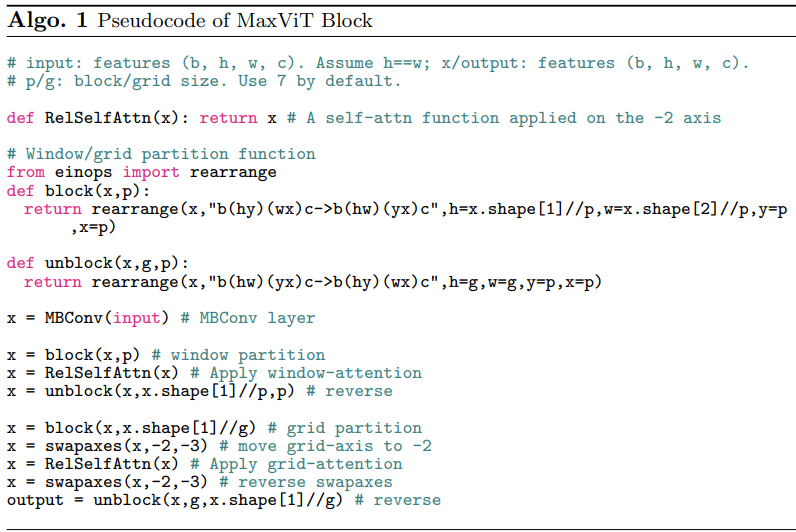
本文引入了一种新的注意力模块——多轴自注意力(multi-axis self-attention, MaxSA),将传统的自注意机制分解为窗口注意力(Block attention)与网格注意力(Grid attention)两种稀疏形式,在不损失非局部性的情况下,将普通注意的二次复杂度降低到线性。由于Max-SA的灵活性和可伸缩性,我们可以通过简单地将Max-SA与MBConv在分层体系结构中叠加,从而构建一个称为MaxViT的视觉 Backbone,如图2所示。
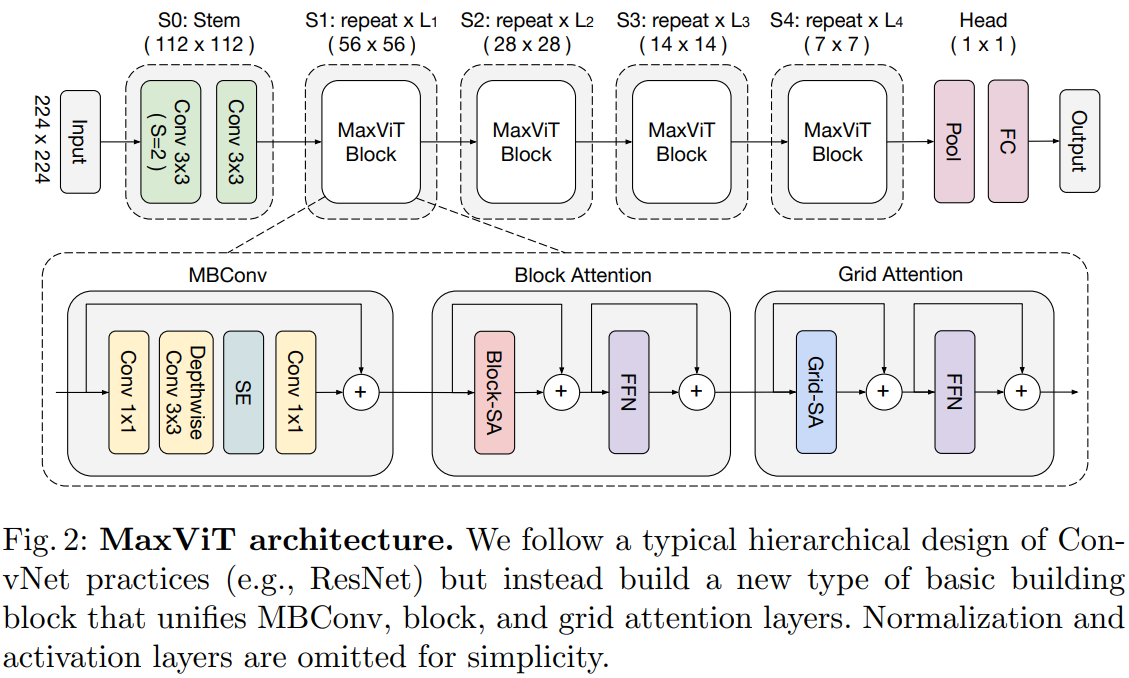
Multi-axis Attention
与局部卷积相比,全局相互作用是自注意力机制的优势之一。然而,直接将注意力应用于整个空间在计算上是不可行的,因为注意力算子需要二次复杂度,为了解决全局自注意力导致的二次复杂度,本文提出了一种多轴注意力的方法,通过分解空间轴得到局部(block attention)与全局(grid attention)两种稀疏形式。
Block attention
对于输入特征(H,W,C),先转化为张量以表示划分为不重叠窗口,其中每个窗口大小为p*p,最后在每个窗口执行计算自注意力。
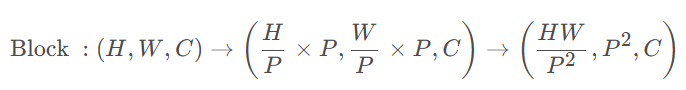
代码:
def block(x,window_size):B,C,H,W = x.shapex = x.reshape(B,C,H//window_size[0],window_size[0],W//window_size[1],window_size[1])x = x.permute(0,2,4,1,3,5).contiguous()return xdef unblock(x):B,H,W,C,win_H,win_W = x.shapex = x.permute(0,3,1,4,2,5).contiguous().reshape(B,C,H*win_W,H*win_W)return xclass Window_Block(nn.Module):def __init__(self, dim, block_size=(7,7), num_heads=8, mlp_ratio=4., qkv_bias=False,qk_scale=None, drop=0., attn_drop=0.,drop_path=0., act_layer=nn.GELU ,norm_layer=Channel_Layernorm):super().__init__()self.block_size = block_sizemlp_hidden_dim = int(dim * mlp_ratio)self.norm1 = norm_layer(dim)self.norm2 = norm_layer(dim)self.mlp = Mlp(dim, mlp_hidden_dim, act_layer=act_layer, drop=drop)self.attn = Rel_Attention(dim, block_size, num_heads, qkv_bias, qk_scale, attn_drop, drop)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self,x):assert x.shape[2]%self.block_size[0] == 0 & x.shape[3]%self.block_size[1] == 0, 'image size should be divisible by block_size'# self.block_size = 7,也就是按照7×7大小的window划分。out = block(self.norm1(x),self.block_size)out = self.attn(out)x = x + self.drop_path(unblock(self.attn(out)))out = self.mlp(self.norm2(x))x = x + self.drop_path(out)return x
Grid attention
局部注意模型难适用于大规模的数据集。又提出一种稀疏的全局自注意力机制,grid attention(网格注意力机制)。
不同于传统使用固定窗口大小来划分特征图的操作,grid attention 使用固定的G × G ,均匀网格将输入张量网格化为, 此时 得到自适应大小的窗口
, 最后在G × G 上使用自注意力计算。需要注意, 通过使用相同的窗口p × p和网格G × G , 可以有效平衡局部和全局之间的计算 (且仅具有线性复杂度)。

注意:遵循Swin Transformer中窗口设置大小,P = G = 7 P=G=7P=G=7。本文提出的Max-SA模块可以直接替换Swin注意模块力,具有完全相同的参数和FLOPs数量。并且,它享有全局交互能力,而不需要 masking, padding, or cyclic-shifting,使其更易于实现,比移位窗口方案更可取。
代码:
class Grid_Block(nn.Module):def __init__(self, dim, grid_size=(7,7), num_heads=8, mlp_ratio=4., qkv_bias=False,qk_scale=None, drop=0., attn_drop=0.,drop_path=0., act_layer=nn.GELU ,norm_layer=Channel_Layernorm):super().__init__()self.grid_size = grid_sizemlp_hidden_dim = int(dim * mlp_ratio)self.norm1 = norm_layer(dim)self.norm2 = norm_layer(dim)self.mlp = Mlp(dim, mlp_hidden_dim, act_layer=act_layer, drop=drop)self.attn = Rel_Attention(dim, grid_size, num_heads, qkv_bias, qk_scale, attn_drop, drop)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self,x):assert x.shape[2]%self.grid_size[0] == 0 & x.shape[3]%self.grid_size[1] == 0, 'image size should be divisible by grid_size'grid_size = (x.shape[2]//self.grid_size[0], x.shape[3]//self.grid_size[1])# grid_size 是网格窗口的数量,x.shape[2]//self.grid_size[0] = H // G。out = block(self.norm1(x),grid_size)out = out.permute(0,4,5,3,1,2).contiguous()out = self.attn(out).permute(0,4,5,3,1,2).contiguous()x = x + self.drop_path(unblock(out))out = self.mlp(self.norm2(x))x = x + self.drop_path(out)return x
Multi-Axis attention与Axial attention区别:
不同于 Axial attention, 在 Axial attention 中 首先使用列注意力(column-wise attention),然后使用行注意力( row-wise attention) 来计算全局 注意力,相当于的计算复杂度,然而 Multi-Axis attention 则先采用局部注意力 (block attention), 再使用稀疏的全局注意力 (grid attention), 这样的 设计充分考虑了图像的 2D 结构,并且仅具有O(N)的线性复杂度。

MBConv
为了获得更丰富的特征表示,首先使用逐点卷积进行通道升维,在升维后的投影空间中进行Depth-wise卷积,紧随其后的SE用于增强重要通道的表征,最后再次使用逐点卷积恢复维度。可用如下公式表示:

对于每个阶段的第一个MBConv块,下采样是通过应用stride=2的深度可分离卷积( Depthwise Conv3x3)来完成的,而残差连接分支也 应用pooling 和 channel 映射:
![]()
MBConv有以下特点:
- 采用了Depthwise Convlution,因此相比于传统卷积,Depthwise Conv的参数能够大大减少;
- 采用了“倒瓶颈”的结构,也就是说在卷积过程中,特征经历了升维和降维两个步骤,并利用卷积固有的归纳偏置,在一定程度上提升模型的泛化能力与可训练性。
- 相比于ViT中的显式位置编码,在Multi-axis Attention则使用MBConv来代替,这是因为深度可分离卷积可被视为条件位置编码(CPE)。
网络架构和变体

伪代码:

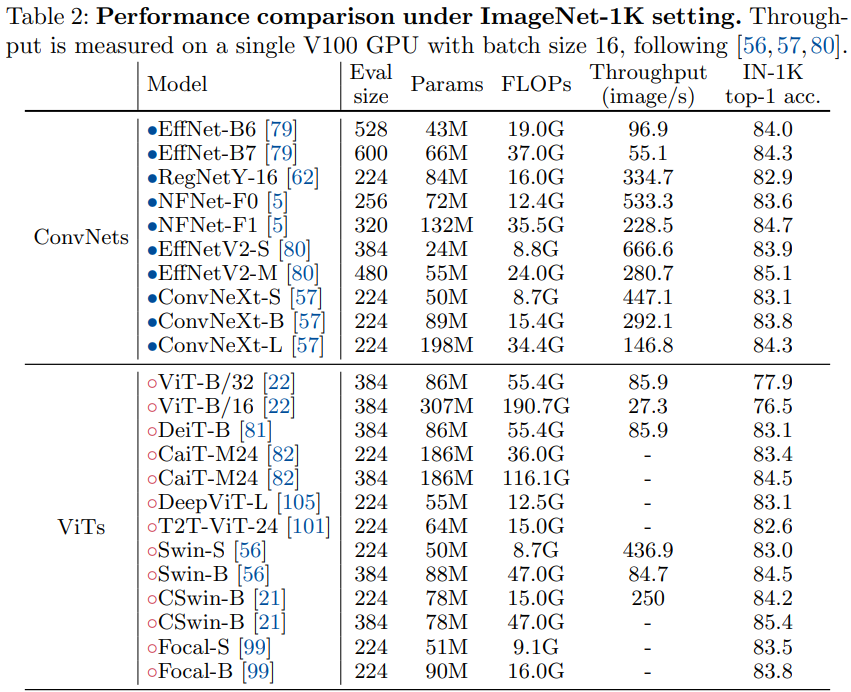
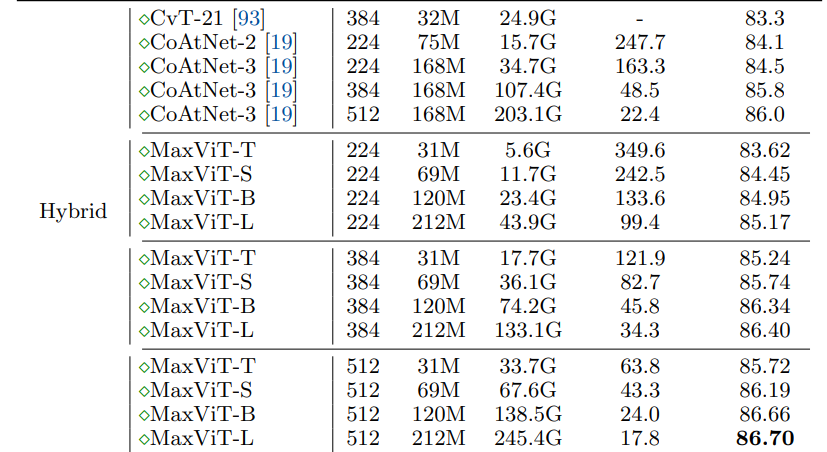
实验
UniFormer: Unifying Convolution and Self-attention for Visual Recognition, TPAMI2023
论文:https://arxiv.org/abs/2201.09450
代码:https://github.com/sense-x/uniformer
解读:【图像分类】2022-UniFormer IEEE_2022年图像分类外文文献_說詤榢的博客-CSDN博客
ICLR2022+TPAMI2023 UniFormer 卷积与自注意力的高效统一 - 知乎 (zhihu.com)
简介
对image和video上的representation learning而言,有两大痛点:
- local redundancy: 视觉数据在局部空间/时间/时空邻域具有相似性,这种局部性质容易引入大量低效的计算。
- global dependency: 要实现准确的识别,需要动态地将不同区域中的目标关联,建模长时依赖。
现有的两大主流模型CNN和ViT,往往只关注解决问题之一。convolution只在局部小邻域聚合上下文,天然地避免了冗余的全局计算,但受限的感受野难以建模全局依赖。而self-attention通过比较全局相似度,自然将长距离目标关联,但ViT在浅层编码局部特征十分低效(如下图所示)。

在ViT的浅层,都仅会倾向于关注query token的邻近token。要知道attention矩阵是通过全局token相似度计算得到的,这无疑带来了大量不必要的计算。相较而言,convolution在提取这些浅层特征时,无论是在效果上还是计算量上都具有显著的优势。
本文提出 UniFormer (Unified transFormer),便旨在以Transformer的风格,有机地统一convolution和self-attention,发挥二者的优势,同时解决local redundancy和global dependency两大问题,实现高效的特征学习。效果显著。

UniFormer方法
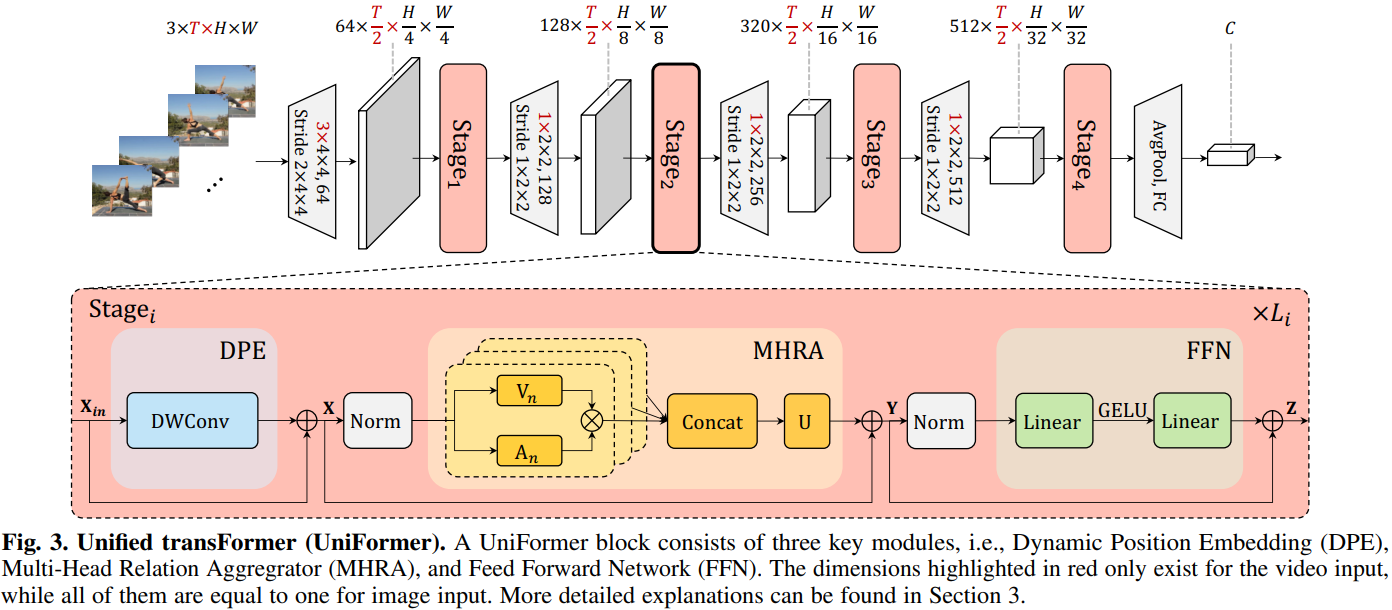
模型整体框架如上所示,借鉴了CNN的层次化设计,每层包含多个Transformer风格的UniFormer block。每个UniFormer block主要由三部分组成,动态位置编码DPE、多头关系聚合器MHRA)及Transformer必备的前馈层FFN。

MHRA

与多头注意力相似,将关系聚合器设计为多头风格,每个头单独处理一组channel的信息。每组的channel先通过线性变换生成上下文token ,然后在token affinity
的作用下,对上下文进行有机聚合。
Local MHRA
在网络的浅层,token affinity应该仅关注局部邻域上下文,这与convolution的设计不谋而合。将局部关系聚合设计为可学的参数矩阵:
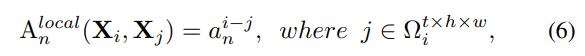
其中 为anchor token,
为局部邻域
任一token,
为可学参数矩阵,
为二者相对位置,表明token affinity的值只与相对位置有关。
Global MHRA
在网络的深层,需要对整个特征空间建立长时关系,这与self-attention的思想一致,因此通过比较全局上下文相似度建立token affinity:
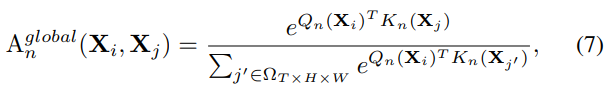
UniFormer在网络的浅层采用local MHRA节省了冗余计算量,使得网络在深层可以轻松使用联合时空注意力,从而可以得到更具辨别性的特征表达。
Dynamic Position Embedding
ViT往往采用绝对或者相对位置编码,但绝对位置编码在面对更大分辨率的输入时,需要进行线性插值以及额外的参数微调,而相对位置编码对self-attention的形式进行了修改。为了适配不同分辨率输入的需要,论文采用了卷积位置编码设计动态位置编码:
![]()
其中DWConv为零填充的的深度可分离卷积。
- 卷积对任何输入形式都很友好,也很容易拓展到空间维度统一编码时空位置信息。
- 深度可分离卷积十分轻量,额外的零填充可以帮助每个token确定自己的绝对位置。
网络架构

轻量化的UniFormer
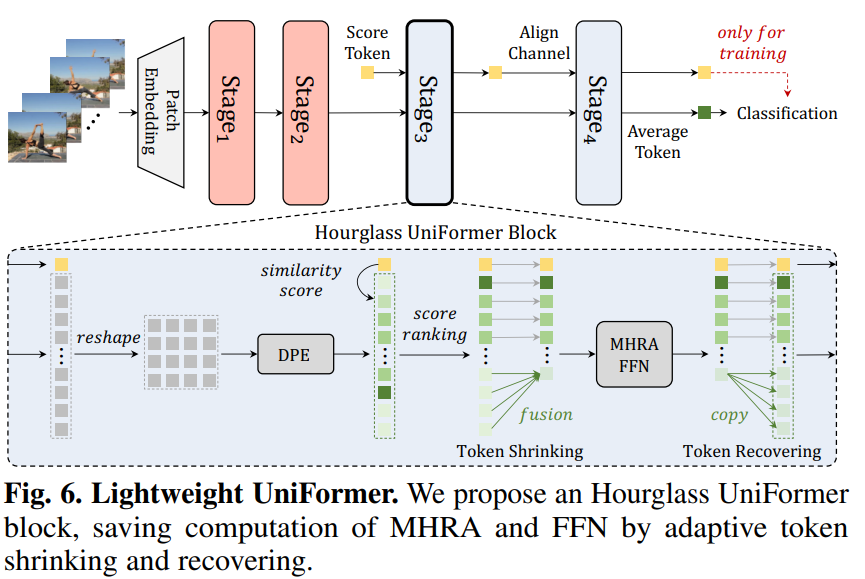
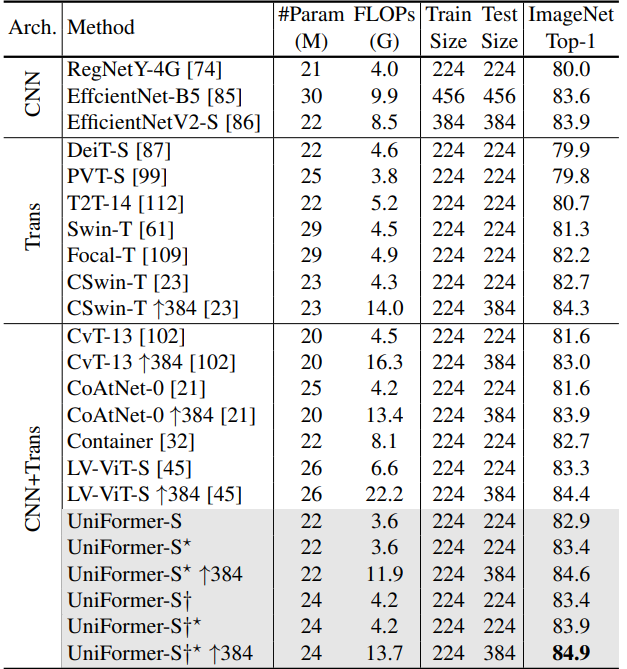
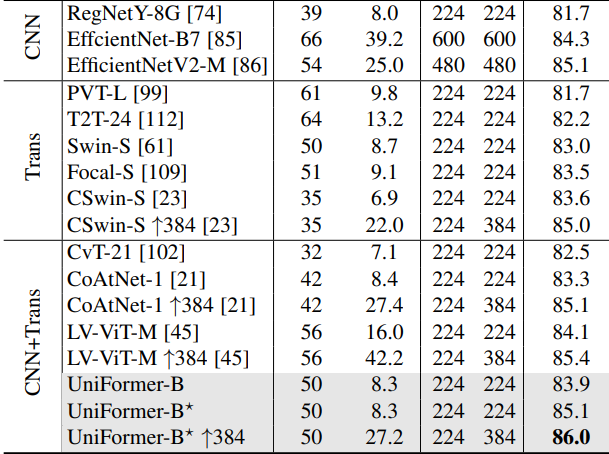
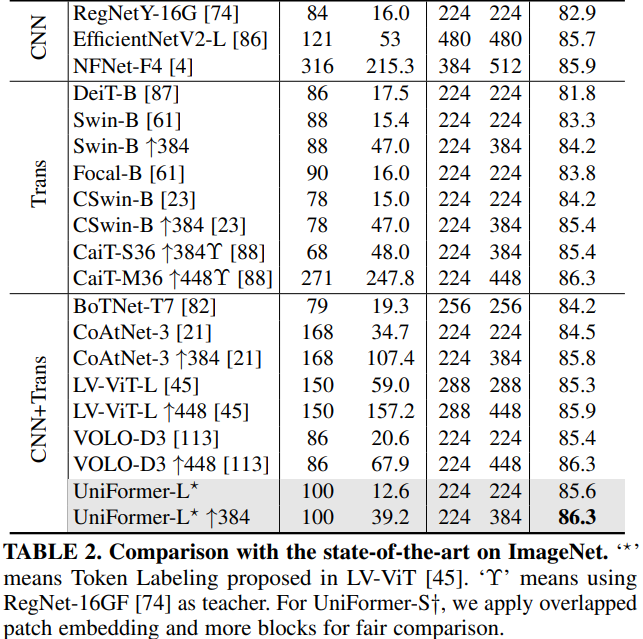
实验
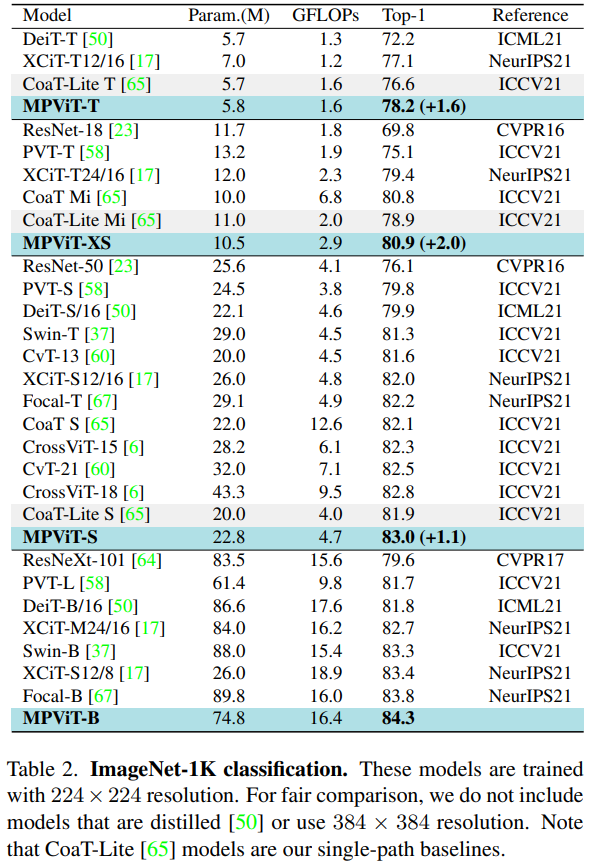
MPViT: Multi-Path Vision Transformer for Dense Prediction, CVPR2022
论文:https://arxiv.org/abs/2112.11010
代码:https://github.com/youngwanLEE/MPViT
解读:【图像分类】2022-MPViT CVPR_cvpr 2022图片分类_說詤榢的博客-CSDN博客
【CVPR2022】MPViT : Multi-Path Vision Transformer for Dense Prediction - 知乎 (zhihu.com)
简介
这项工作以不同于现有Transformer的视角,探索多尺度path embedding与multi-path结构,提出了Multi-path Vision Transformer(MPViT)。
- 通过使用 overlapping convolutional patch embedding,MPViT同时嵌入相同大小的patch特征。然后,将不同尺度的Token通过多条路径独立地输入Transformer encoders,并对生成的特征进行聚合,从而在同一特征级别上实现精细和粗糙的特征表示。
- 在特征聚合步骤中,引入了一个global-to-local feature interaction(GLI)过程,该过程将卷积局部特征与Transformer的全局特征连接起来,同时利用了卷积的局部连通性和Transformer的全局上下文。
因此本文作者将重点放在了图像的多尺度多路径上,通过对图片不同尺度分块及其构成的多路径结构,提升了图像分割中Transformer的精确程度。
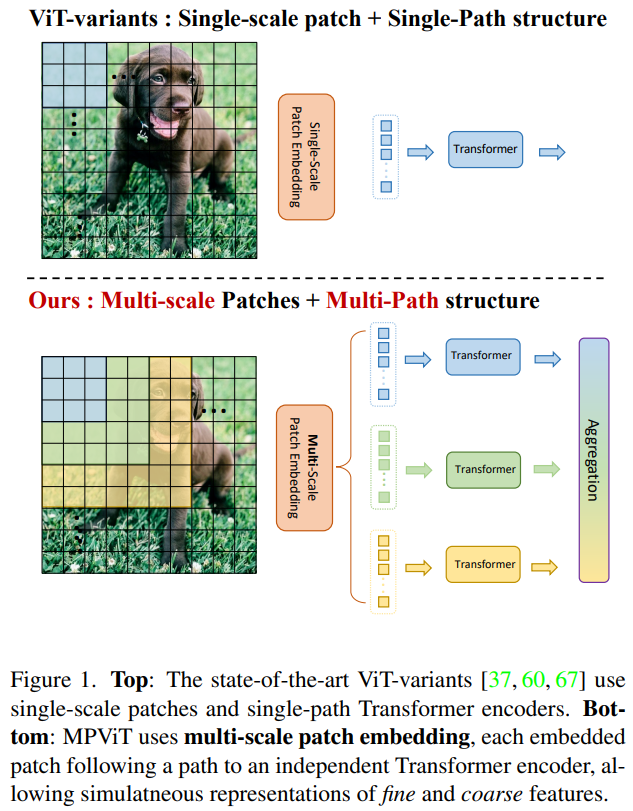
本文有三个贡献:
- 提出了一个具有多路径结构的多尺度嵌入方法,用于同时表示密集预测任务的精细和粗糙特征。
- 提出了全局到本地特征交互(GLI),同时利用卷积的局部连通性和Transformer的全局上下文来表示特征。
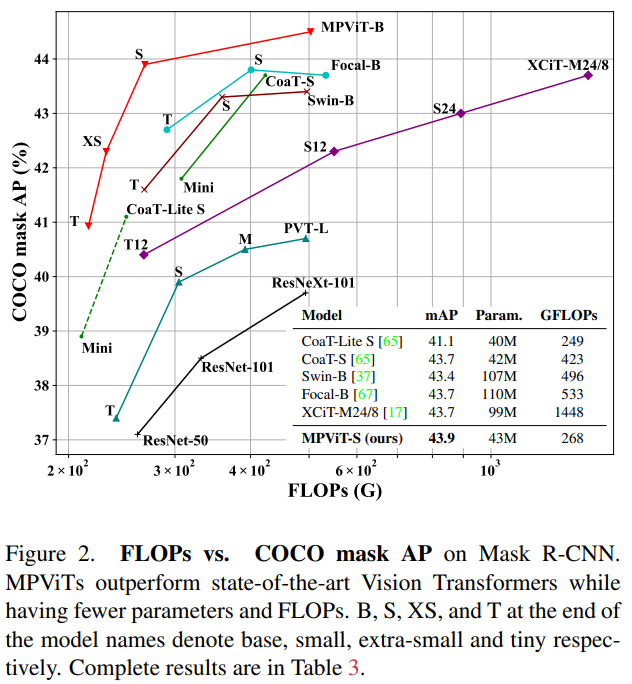
- 性能优于最先进的vit,同时有更少的参数和运算次数。
MPViT方法
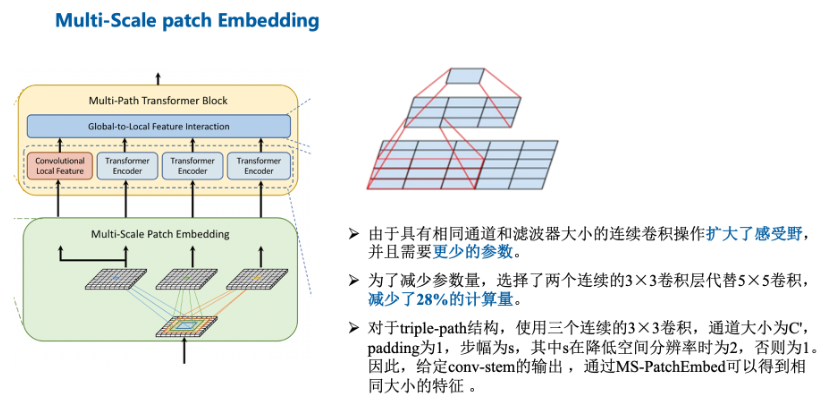
首先利用Conv-stem对输入图像做卷积提取特征;再依次经过四个MS-PatchEmbed 和 MP-Transformer Block,逐层减小特征尺度,最后实现分类。
最先进的ViT使用单尺度的patch embedding和单路径transformer编码器
- MPViT通过重叠卷积将相同大小的特征和不同大小的patch的同时嵌入。
- 将多尺度patch嵌入,通过重叠卷积将其拉平成为不同尺寸的token,在适当调整卷积的填充/步幅后产生具有相同序列长度的特征。
- 然后,来自不同尺度的token被通过多条路径独立并行送到Transformer编码器中,执行全局自我关注。
- 然后聚合生成的特征,从而在相同的特征级别上实现精细和粗略的特征表示。
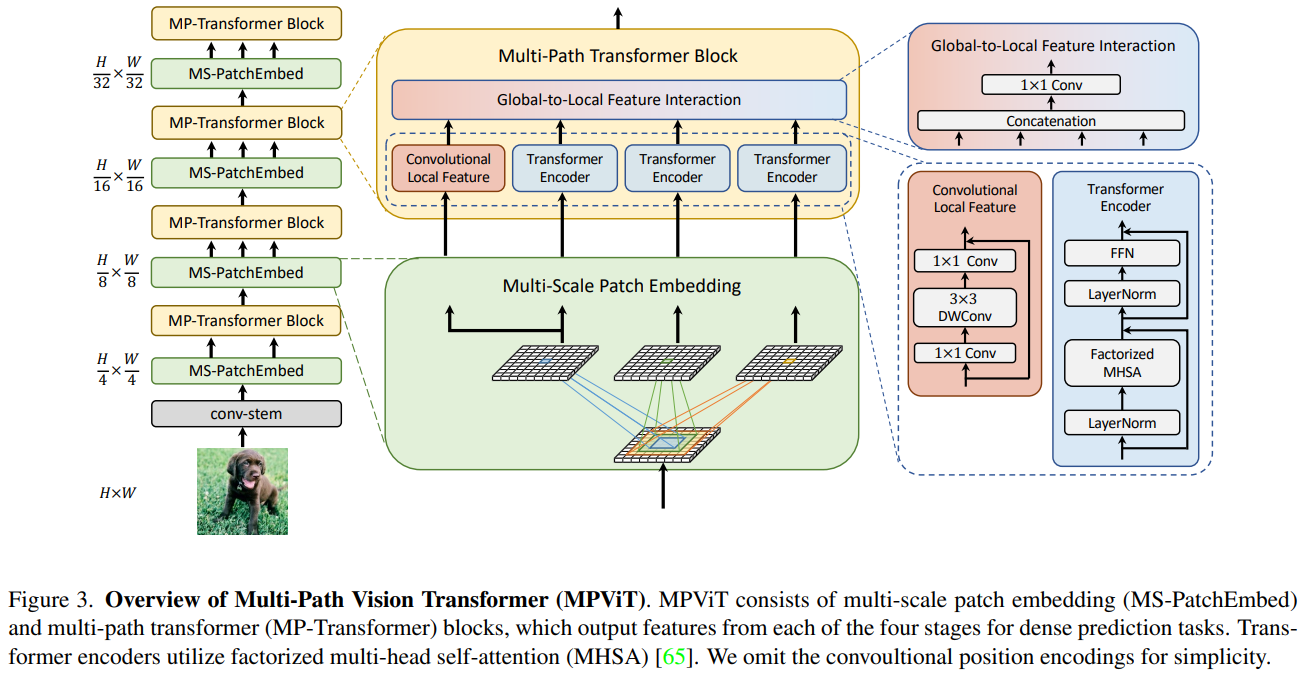
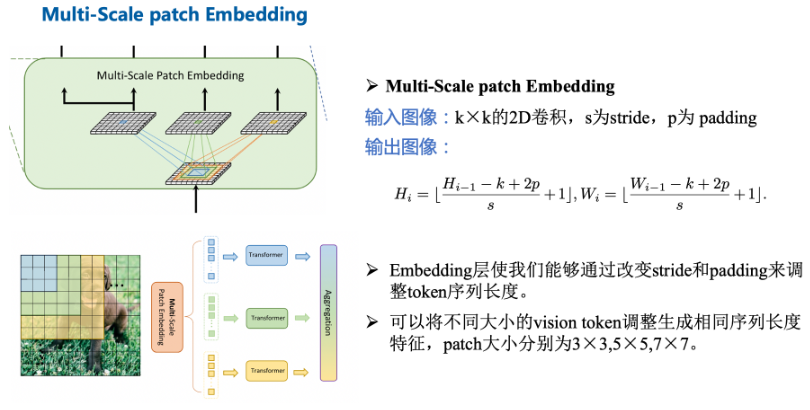
Multi-Scale Patch Embedding:
使用3*3卷积构成不同大小的感受野来得到不同尺度的特征信息。
- 由于堆叠同尺寸卷积可以提升感受野且具有更少的参数量,选择两个连续的3×3卷积层构建5×5感受野,采用三个3×3卷积构建7×7感受野。
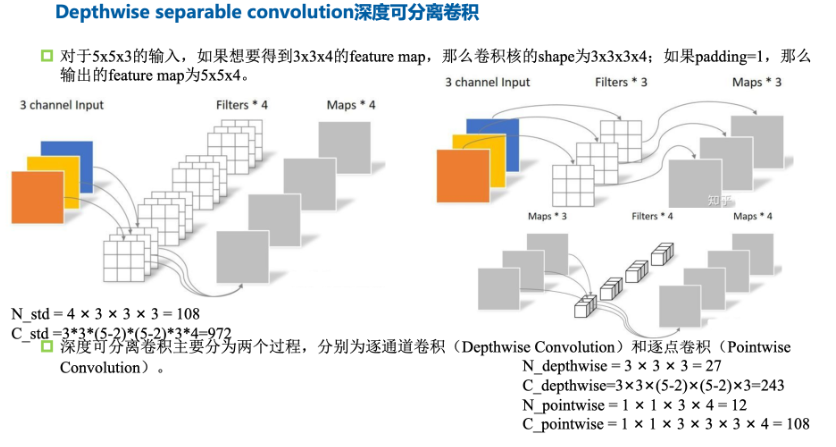
- 为了减少模型参数和计算开销,采用3×3深度可分离卷积,包括3×3深度卷积和1×1点卷积。
- 每个卷积之后都是Batch Normalization 和一个Hardswish激活函数。
接着,不同大小的token embedding features 分别输入到transformer encoder中。
Multi-path Transformer:
- Transformer中的self-attention可以捕获长期依赖关系(即全局上下文),但它很可能会忽略每个patch中的结构性信息和局部关系。
- 相反,cnn可以利用平移不变性中的局部连通性,使得CNN在对视觉对象进行分类时,对纹理有更强的依赖性,而不是形状。
因此,MPViT以一种互补的方式将CNN与Transformer结合起来。
在多路径的特征进行自注意力(局部卷积)计算以及全局上下文信息交互后,所有特征会做一个Concat经过激活函数后进入下一阶段。
Transformer可以关注到较远距离的相关性,CNN能更好地对图像的局部上下文特征进行提取,论文进行互补。
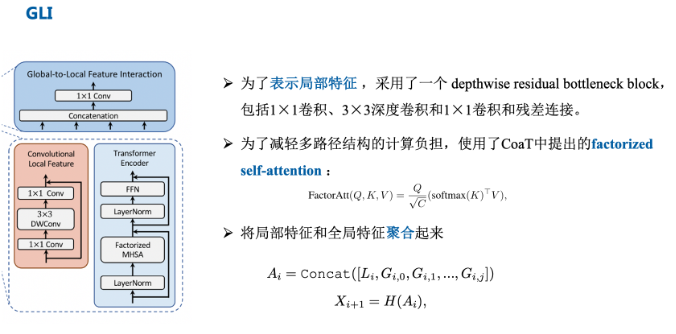
Transformer: 由于每个图像块内作者都使用了自注意力,并且存在多个路径,因此为了减小计算压力,作者使用了CoaT中提出的有效的因素分解自注意(将复杂度降低为线性)
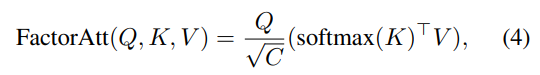
CNN: 为了表示局部特征 L,采用了一个 depthwise residual bottleneck block,包括1×1卷积、3×3深度卷积和1×1卷积和残差连接。在三个Transformer模块的左侧存在一个卷积操作,其实就是通过卷积的局部性,将图像的局部上下文引入模型中,多了这些上下文信息可以弥补Transformer对于局部语义理解的不足。
Global-to-Local Feature Interaction
将局部特征和全局特征聚合起来:通过串联来执行。
对输入特征做了一个Concat并进行了1×1卷积,该模块同时输入了存在远距离关注的Transformer以及提取局部上下文关系的卷积操作,因此可以认为就是对本阶段提取到的图像全局以及局部语义的特征融合,充分利用了图像的信息。


网络架构

实验




相关文章:
【图像分类】CNN+Transformer结合系列.2
介绍几篇利用CNNTransformer实现图像分类的论文:CMT(CVPR2022),MaxViT(ECCV2022),MaxViT(ECCV2022),MPViT(CVPR2022)。主要是说明Transformer的局限性&#x…...
用于毫米波天线的新型无卤素超低传输损耗多层电路板R-5410
3月3日消息,松下公司宣布,其工业解决方案公司已经实现了R-5410的商业化,这是一种无卤素、超低传输损耗的多层电路板(MLCB)材料,适用于毫米波天线。将于2021年3月开始量产。 毫米波雷达是汽车、通信等行业的…...

java数据算法-汉诺塔
1、有三根相邻的柱子,标号为A,B,C。 2、A柱子上从下到上按金字塔状叠放着n个不同大小的圆盘。 3、现在把所有盘子一个一个移动到柱子C上,并且每次移动同一根柱子上都不能出现大盘子在小盘子上方。 题解步骤 1、当n1时; 将1号从A移动到C即…...

[QT编程系列-35]:数据存储 - JSON格式配置数据的存储与通知
目录 1. QJsonObject 2 QJsonDocument 3 JSON本文格式 4. JSON示例 5. JASON配置文件示例 1. QJsonObject QJsonObject 是Qt的类之一,用于表示 JSON 对象。 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式࿰…...

【Spring】Spring 中事务的实现
目录 1.编程式事务(手动编写代码)2.声明式事务(利用注解)2.1 Transactional作用范围2.2 Transactional参数说明2.3 Transactional工作原理 3.Spring 中设置事务隔离级别3.1 事务四大特性ACID3.2 事务的隔离级别3.2 Spring中设置事…...
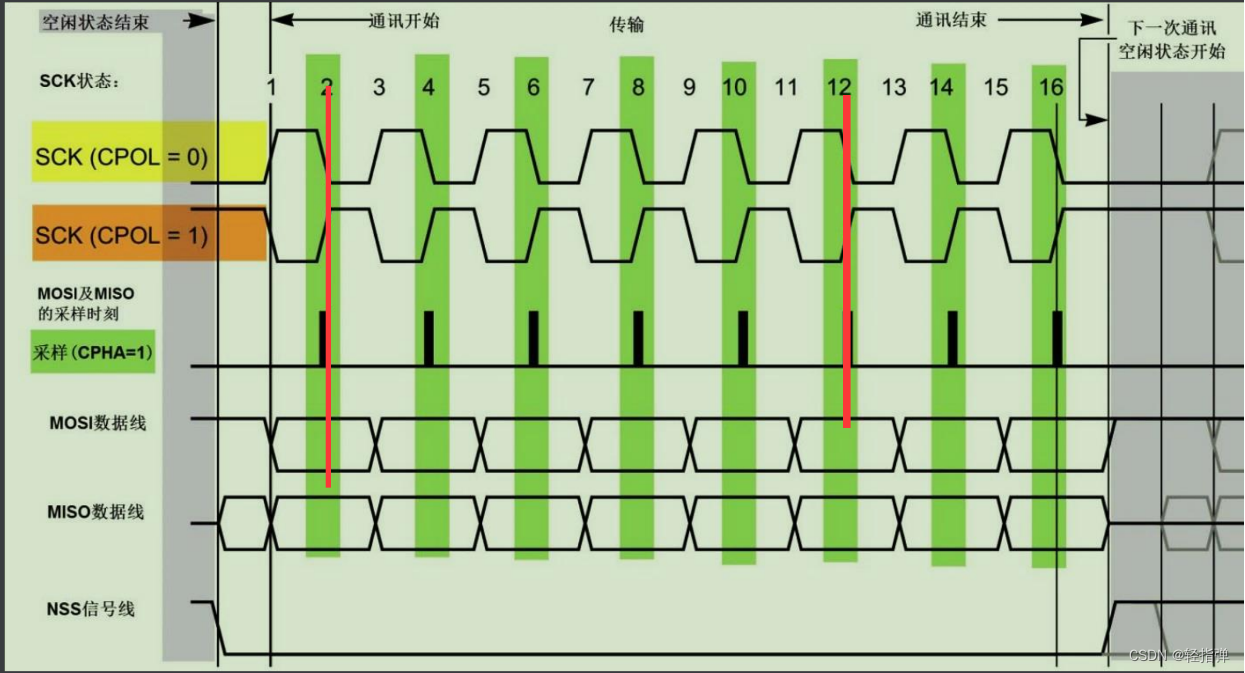
Linux 学习记录60(ARM篇)
Linux 学习记录60(ARM篇) 本文目录 Linux 学习记录60(ARM篇)一、SPI总线1. 概念2. 硬件连接 二、SPI总线协议三、SPI总线通信模式四、对比IIC总线和SPI总线1. 相同点2. 不同点 思维导图 一、SPI总线 1. 概念 1、SPI总结是Motorola首先提出的全双工三线/四线同步串行总线 2、采…...
尚硅谷大数据项目《在线教育之采集系统》笔记002
视频地址:尚硅谷大数据项目《在线教育之采集系统》_哔哩哔哩_bilibili 目录 P032 P033 P033 P034 P035 P036 P032 P033 # 1、定义组件,为各组件命名 a1.sources r1 a1.channels c1 a1.sinks - k1# 2、配置sources,描述source a1.sour…...

校园跑腿小程序功能分享
提起校园跑腿小程序大家都不陌生,尤其是对上大学的伙伴们来说,更是熟悉得不能再熟悉了,和我们的生活息息相关,密不可分。 对于现在的年轻人来说,网购是非常简单和方便的一种购物方式,随之快递也会越来越多。在我们国家…...
PHP8的变量-PHP8知识详解
昨天我们讲解了PHP8的常量,今天讲解PHP8的变量。常量有定义常量和预定义常量,变量呢?那就没有定义变量了,那叫给变量赋值,但是还是有预定义变量的。下面就给大家讲解什么是变量、变量赋值及使用及预定义变量。 一、什么…...
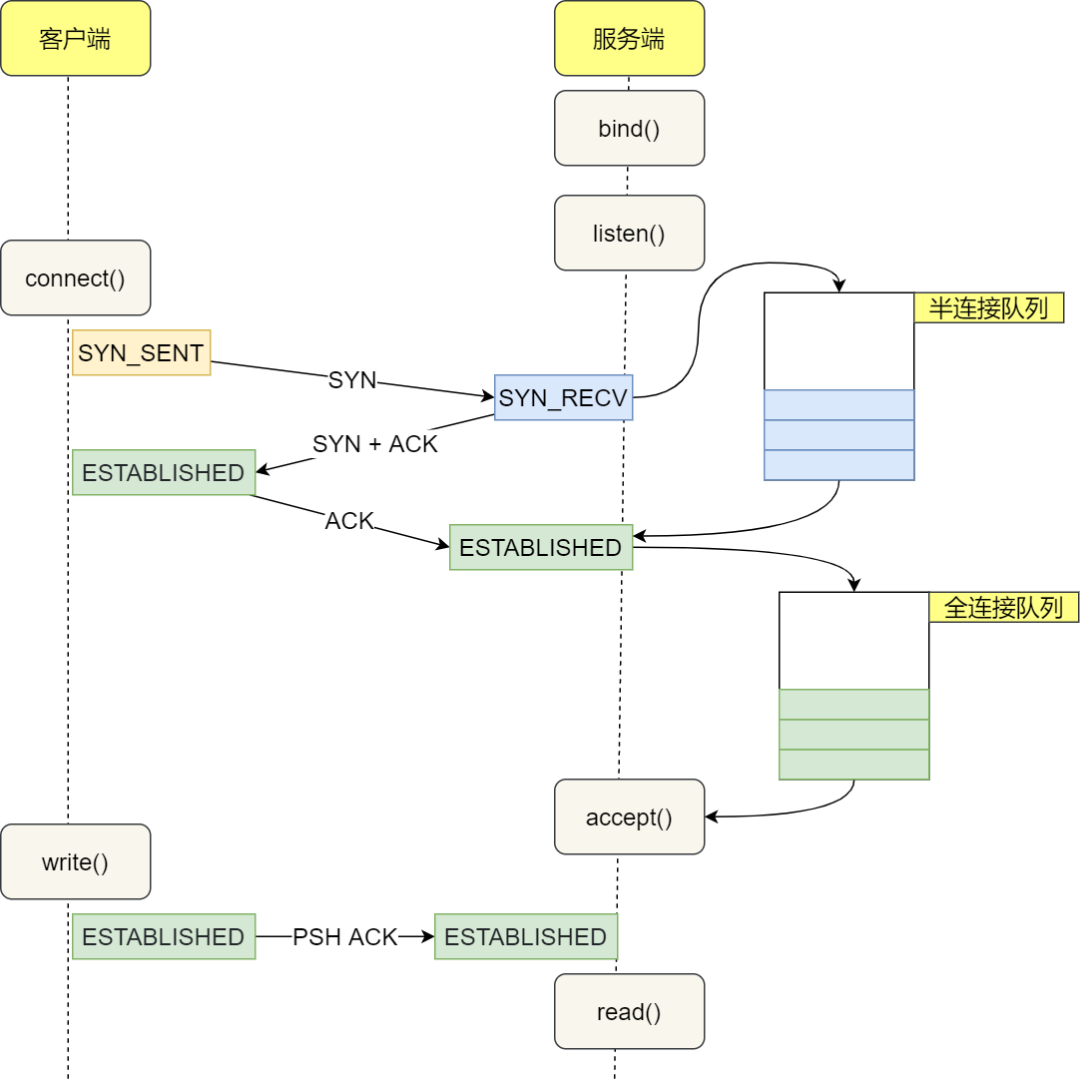
图解TCP 三次握手和四次挥手的高频面试题(2023最新版)
大家好,最近重新整理了一版 TCP 三次握手和四次挥手的面试题(2023最新版)。 ----- 任 TCP 虐我千百遍,我仍待 TCP 如初恋。 巨巨巨巨长的提纲,发车!发车! img TCP 基本认识 TCP 头格式有哪些…...
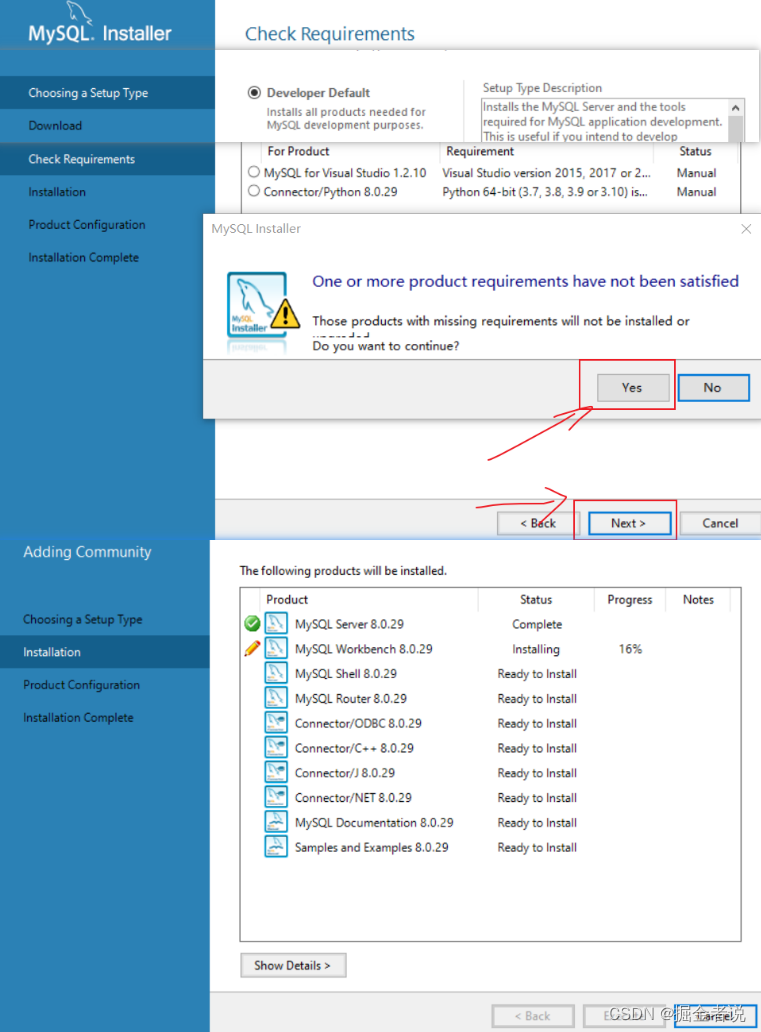
【mysql】Win10安装配置MySQL8.0简要
下载 MySQL官网下载安装包 安装...

SQL SERVER使用发布订阅同步数据库遇到的坑
可能遇到的各种坑 1.在执行 xp_cmdshell 的过程中出错。调用 ‘CreateProcess’ 失败,错误代码: ‘5’ 网上有各种解决办法,包括改本地安全策略,将sql server服务的网络权限改为本机系统,改cmd用户的读写权限,退出360…...
3个命令定位CPU飙高
top 指令找出消耗CPU最厉害的那个进程的pid top -H -p 进程pid 找出耗用CPU资源最多的线程pid printf ‘0x%x\n’ 线程pid 将线程pid转换为16进制 结合jstack 找出哪个代码有问题 jstack 进程pid | grep 16进制的线程pid -A 多少行日志 jstack 进程pid | grep 16进制的线程…...
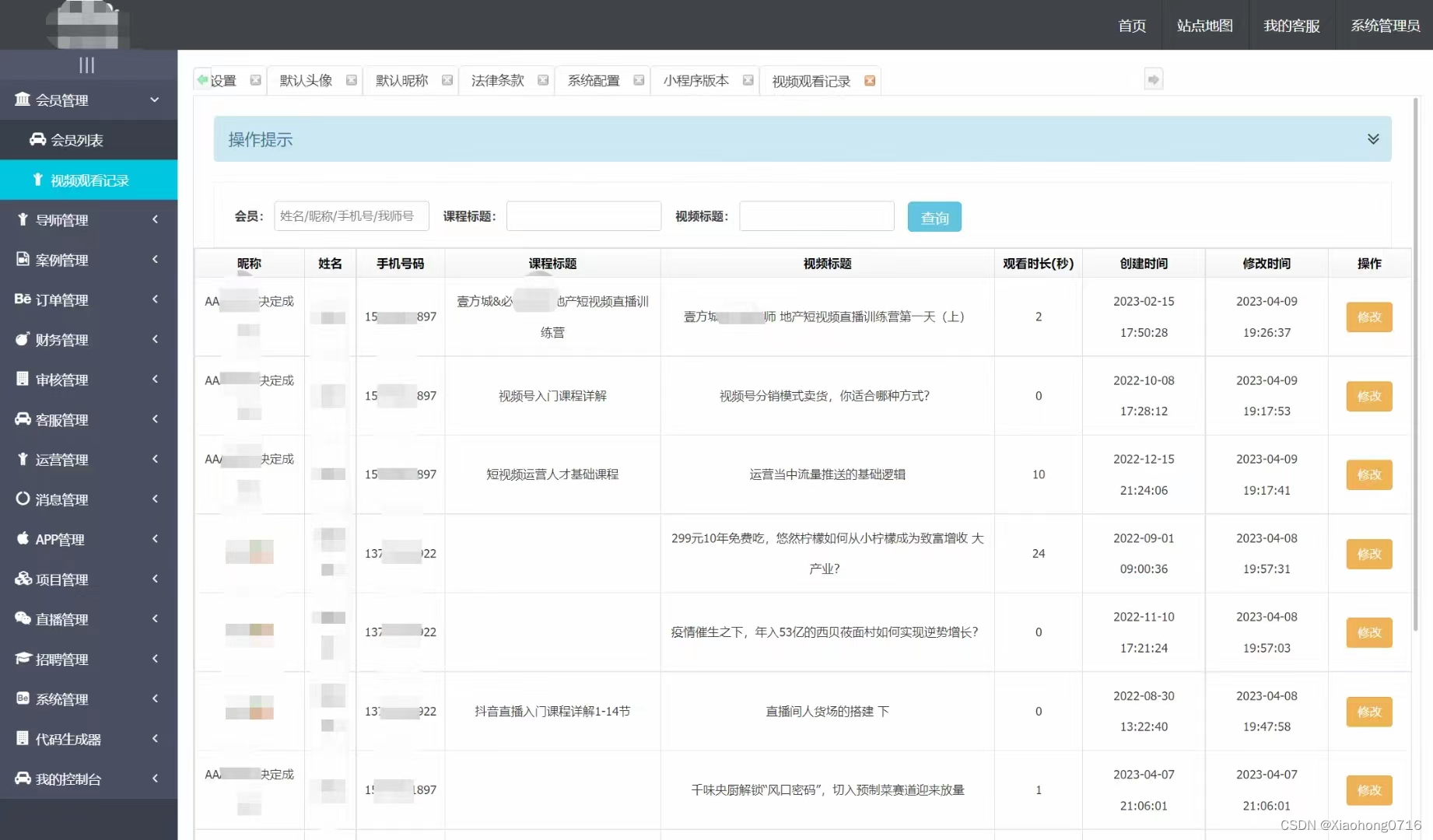
Java版知识付费 Spring Cloud+Spring Boot+Mybatis+uniapp+前后端分离实现知识付费平台免费搭建
提供职业教育、企业培训、知识付费系统搭建服务。系统功能包含:录播课、直播课、题库、营销、公司组织架构、员工入职培训等。 提供私有化部署,免费售后,专业技术指导,支持PC、APP、H5、小程序多终端同步,支持二次开发…...
使用多数据源dynamic-datasource-spring-boot-starter遇到的问题记录
记录使用多数据源dynamic-datasource-spring-boot-starter遇到的问题: 1、工程启动失败 缺少clickhouse连接驱动,引入对应的maven依赖 <!--ck连接驱动--><dependency><groupId>ru.yandex.clickhouse</groupId><artifactId>…...

构建语言模型:BERT 分步实施指南
学习目标 了解 BERT 的架构和组件。了解 BERT 输入所需的预处理步骤以及如何处理不同的输入序列长度。获得使用 TensorFlow 或 PyTorch 等流行机器学习框架实施 BERT 的实践知识。了解如何针对特定下游任务(例如文本分类或命名实体识别)微调 BERT。为什么我们需要 BERT? 正…...
⛳ Java多线程 一,线程基础
线程基础 ⛳ Java多线程 一,线程基础🐾 一,线程基础💭 1.1,什么是程序,进程,线程🏭 1.2,什么是并行和并发👣 1.3,线程使用的场景🎨 1.…...
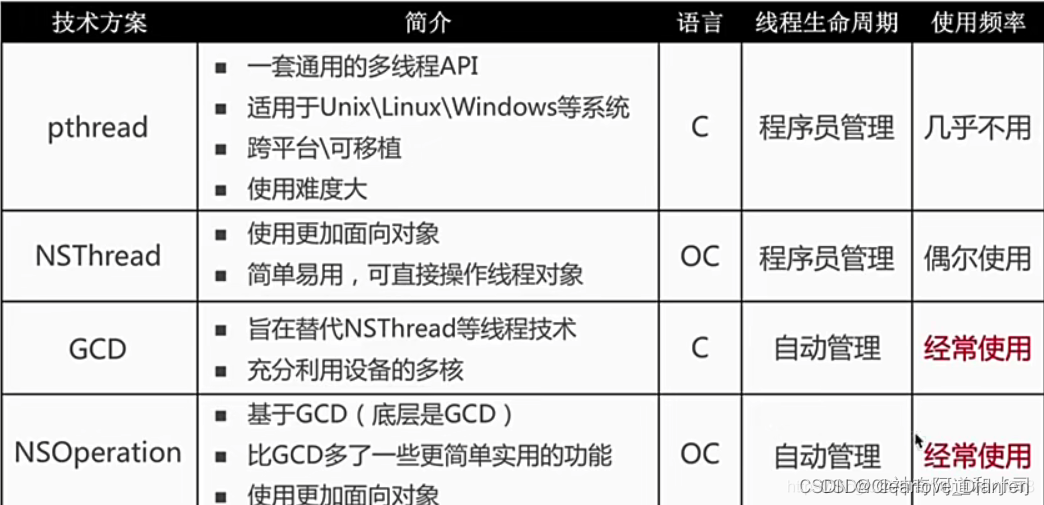
【iOS】多线程 锁问题总结
文章目录 前言1. 你理解的多线程优点缺点 2. atomic 和 nonatomic 的区别及其作用3. GCD的队列类型 - 三种队列类型4. GCD的死锁问题5. 多线程之间的区别和联系6. 进程和线程?进程间的通信方式线程间的通信方式 6. iOS的线程安全手段如何保证 前言 iOS 锁和多线程的…...

Pytorch深度学习-----神经网络之池化层用法详解及其最大池化的使用
系列文章目录 PyTorch深度学习——Anaconda和PyTorch安装 Pytorch深度学习-----数据模块Dataset类 Pytorch深度学习------TensorBoard的使用 Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Co…...
Docker啥是数据持久化?
文章目录 数据持久化数据卷相关命令创建读写数据卷创建只读数据卷数据卷共享数据卷容器实现数据卷共享nginx实现数据卷共享nfs总结 Dockerfile持久化Dockerfile方式docker run总结 数据持久化 在容器层的 UnionFS(联合文件系统)中对文件/目录的任何修…...

避开这些坑!用AD5934测量从3Ω到100kΩ阻抗的实战经验与校准技巧
避开这些坑!用AD5934测量从3Ω到100kΩ阻抗的实战经验与校准技巧 在精密阻抗测量领域,AD5934作为一款高集成度的阻抗转换芯片,凭借其宽频带扫描能力和数字解调技术,成为从生物传感器到材料分析等多个领域的核心器件。但实际应用中…...

Chrome扩展开发实战:打造浏览器侧边栏ChatGPT助手
1. 项目概述:一个让ChatGPT常驻浏览器侧边栏的利器如果你和我一样,每天的工作和学习都离不开浏览器,并且频繁地与ChatGPT对话来获取灵感、润色文案或者调试代码,那么你肯定对在无数个标签页之间来回切换感到厌烦。每次都要打开一个…...

AI智能体任务编排框架:从概念到实战的Mission Control指南
1. 项目概述:为AI智能体打造一个“任务控制中心”最近在折腾AI智能体(Agent)的开发,发现一个挺普遍的问题:当你想让多个智能体协同工作,或者想让单个智能体执行一系列复杂、有依赖关系的任务时,…...
)
告别混乱信号!用CANdb++ Editor从零搭建汽车CAN网络DBC文件(保姆级图文教程)
告别混乱信号!用CANdb Editor从零搭建汽车CAN网络DBC文件(保姆级图文教程) 在汽车电子开发领域,CAN总线如同神经脉络般贯穿整车系统。我曾参与过一个新能源整车项目,由于早期缺乏规范的DBC文件,不同ECU厂商…...

终极指南:使用Python开源工具破解百度网盘限速,实现高速免费下载
终极指南:使用Python开源工具破解百度网盘限速,实现高速免费下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的下载速度而烦恼…...

iOS越狱终极指南:解锁iPhone隐藏功能的3个关键步骤
iOS越狱终极指南:解锁iPhone隐藏功能的3个关键步骤 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址: ht…...

解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南
解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 还在为《崩坏:星穹铁道》中重复的…...

解密VideoDownloadHelper:开源浏览器插件的智能视频提取技术
解密VideoDownloadHelper:开源浏览器插件的智能视频提取技术 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 当你在浏览微博、秒拍…...
)
中文长文本语音崩溃?ElevenLabs API超时/截断/静音突变?20年语音架构师紧急发布的6行容错重试+分段重对齐代码(已验证10万+字符稳定输出)
更多请点击: https://intelliparadigm.com 第一章:中文长文本语音崩溃的根因诊断与现象复现 中文长文本语音合成(TTS)在处理超长段落(如 >3000 字)时频繁出现进程中断、内存溢出或静音输出,…...

Mantic.sh:AI驱动的智能命令行工具,让自然语言生成终端命令
1. 项目概述:一个为开发者打造的智能终端伴侣 如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你一定对效率有着近乎偏执的追求。敲命令、查日志、管理进程、部署服务……这些重复且琐碎的操作…...