C++ | 哈希表的实现与unordered_set/unordered_map的封装
目录
前言
一、哈希
1、哈希的概念
2、哈希函数
(1)直接定址法
(2)除留余数法
(3)平方取中法(了解)
(4)随机数法(了解)
3、哈希冲突
4、闭散列及其实现
(1)闭散列的查找
(2)闭散列的插入
(3)闭散列的删除
5、开散列及其实现
(1)开散列的查找
(2)开散列的插入
(3)开散列的删除
(4)其他函数
6、开散列与闭散列的一些其他问题
(1)对于自定义类型成员无法确定位置
(2)模素数优化
二、unordered_set与unordered_map的封装
前言
前面我们学习了unordered_set、unordered_map的使用,这里我们从底层来看看这两个容器,并对其封装,再封装之前,我们需要清楚者两个容器的底层是哈希结构,我们首先自己实现一个哈希表,再拿这个哈希表对容器进行封装;
一、哈希
1、哈希的概念
前面的二叉搜索树我们想找到一个值就必须对这个值从根节点开始依次比较,知道找到这个数或者找到空姐点指针;但是我们想通过一种一 一映射的思想以最快的速度找到我们想要的值,这种将我们的关键码与位置建立关系的思想,我们称之为哈希;举个例子;
题目链接
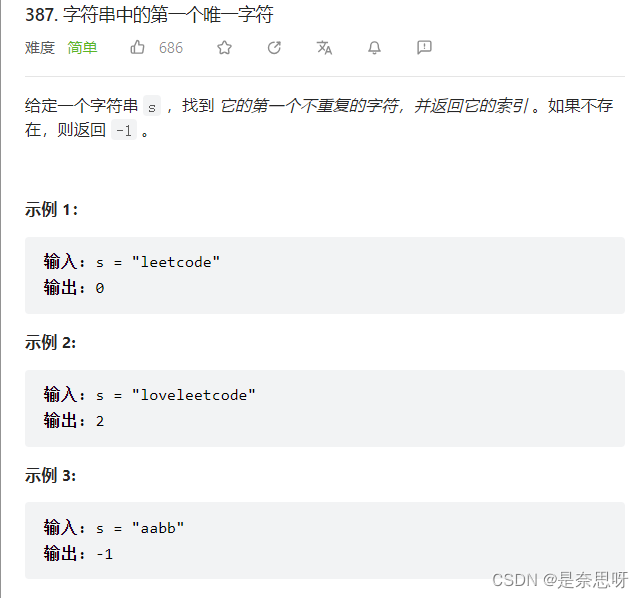
如上述这道题目,我们想要找出只出现一个只出现一次的字符,我们怎么处理呢?我们之前可通过类似计数排序的思想,将每个字母映射一个数字下标的位置(题目有说只会出现小写字母);如我们创建一个大小为26的数组,并都初始化为0,a映射到数组0下标的位置,b映射到数组1下标的位置,这样依次映射我们可以映射到下标25,z的位置;然后遍历字符串,每遇到一个字符,就将该字符对应的下标的数组值+1;如遇到a,我们将0下标对应的数组值+1;这样的思想也就是我们哈希的思想;
2、哈希函数
哈希函数就是将我们关键码转化成对应的哈希值,上述题目中将小写字母转换成0到26这一过程我们就可以理解成我们用哈希函数将小写字母转换成特定的哈希值;接下来我们来看看了解一下常见的哈希函数;
(1)直接定址法
所谓直接定址法就是去关键码作为哈希地址,如来了一个3,我们就将3放进数组下标为3的位置,来了一个13,就将13放进数组13的位置;

但是这种方法有一个明显的缺陷,我们要是我们的数据并不是集中分布的呢?假如有三个数据,分别为3,5,10007;那么我们是不是要开辟10007这么大的空间存放数据呢??因此我们不使用这种方法;
(2)除留余数法
我们在得到一个关键码时,我们将它余上某个数字得到储存位置;这种方法就是我们的除留余数法;我们后面实现哈希表就是采用这种方法;例如,还是上述三个数据,3,5,10007;

我们将上述的值依次余上一个10,得到的余数就是对应的位置;后面还有一个写方法,我们了解即可;
(3)平方取中法(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;
再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址
(4)随机数法(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。
当然还有很多很多的方法,大家感兴趣可以自行搜索;
3、哈希冲突
在上述不同方法中,仍然会出现一些特殊状况,其中有一种被称为哈希冲突,如下图所示;
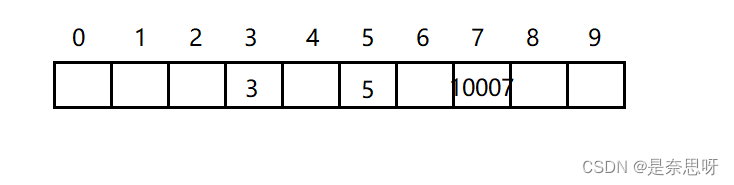
上图采取的是除留取余法,目前数据存储并没有什么问题,但是接下来,当我们想存入一个13,这是我们对其取10的余数,即为3,但是此时我们3的位置已经存储了一个数据了,那这时我们应该怎么存储这个数据呢?这种存储数据位置冲突的现象就是我们的哈希冲突;那么如何解决这种哈希冲突呢?没错,就是我们接下来的闭散列和开散列两种方法;
4、闭散列及其实现
闭散列也叫开放定址法,当发生哈希冲突的时候,我们将当前数据存储到“下一个”位置存储;关于这下一个位置,我们有几种不同的定义;可以是+1的位置,也可以每次都加不同的数,主要看实现者想如何实现;以下我们依次分析;
首先,我们分析一下,我们想实现我们的闭散列有哪些困难;
1、我们开辟一块空间后,当来了一个关键码以后,我们通过特定的算法函数,将这个关键码转换成我们的位置,然后我们需要查看数组的这个位置是否存储了数据,那我们如何确定这个位置是否存储了数据呢?
2、当我们删除一个元素后,我们应该如何表明该数据被删除了呢?
我们可以将数组中存储一个结构化数据,而不是单个数据,结构化数据包括我们存储的数据,以及数据的状态,这里我设置了三种状态,分别是EMPT(此位置为空),EXIST(此位置有数据),DELETE(此位置目前没数据了,被删除了)
注意:这里可能有很多同学看不懂这里为什么要设置DELETE这种状态,删除一个数据直接设置成EMPTY不可以吗?这里我们需要考虑删除的情况;假设如下;
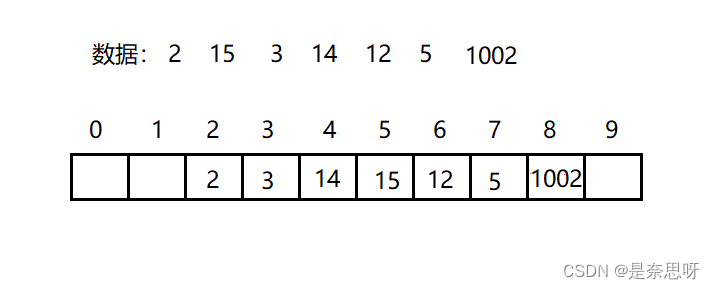
此时插入了数据如上图所示,我们使用的下一个位置是+1;我们查找数据的逻辑是先算出位置值,我们算出存入hashi中,然后我们从hashi位置开始查找,如果不是我们要查找的数值,我们就找下一个位置,知道我们加到的那个位置的值为EMPTY状态为止;这时,如果我们删除数据的逻辑是将数据对应位置设置为EMPTY就有坑了,假设我们删除15,此时下标5这个位置被设置成EMPTY,然后我们接着想查找12,我们从算出hashi值2,从2开始查找,发现不等于12,接着探测下一个位置下标3的值,对比还是不相等,一直到下标5的位置时,我们发现下标5为EMPTY状态,停止查找,可是我们数据明明存储在这个哈希表中;所以两个状态是不够的!
根据如上分析,我们写出闭散列的大体框架,如下所示;
namespace ClosedHash
{// 状态表示enum State{EMPTY,EXIST,DELETE};// 哈希表中数据存储类型template<class K, class V>struct HashDate{std::pair<K, V> _kv;State _state = EMPTY;};// 哈希表template<class K, class V>class HashTable{public:private:std::vector<HashDate<K, V>> _hash_table;size_t _n = 0; // 哈希表中元素个数};
}(1)闭散列的查找
闭散列的查找需要先算出hashi,这里是余上这个vector的size;这里采用的是一次探测,即不断+1;
HashDate<K, V>* find(const K& key){if (_n == 0){return nullptr;}size_t hashi = key % _hash_table.size();size_t i = 1;size_t index = hashi;// 若查找位置不为空,继续往后找while (_hash_table[index]._state != EMPTY){if (_hash_table[index]._state == EXIST && _hash_table[index]._kv.first == key){return &_hash_table[index];}else{// 下一个探测index = hashi + i;index %= _hash_table.size();i++;}// 防止都是DELETE状态造成死循环if (index == hashi)break;}return nullptr;}(2)闭散列的插入
插入的代码中,关于哈希碰撞时,我们可以选择一次探测,也可以选择二次探测;这里插入时,需要考虑扩容问题,这里涉及到什么时候扩容,关于什么时候扩容,我们这里引入了负载因子这一概念;
负载因子 = 元素个数 / size;
所以这里需要控制除零错误,第一次进去必须扩容;还有我们这的负载因子一般控制在0.7到0.8左右;大了就哈希碰撞的几率大,空间利用率高,搜索效率低;小了就哈希碰撞几率低,空降利用率低,搜索效率高;
bool insert(const std::pair<K, V>& kv){if (find(kv.first))return false;// 是否需要扩容if (_hash_table.size() == 0 || _n * 10 / _hash_table.size() == 7){int newsize = _hash_table.size() == 0 ? 10 : _hash_table.size() * 2;HashTable<K, V> tmp;tmp._hash_table.resize(newsize);for (auto& e : _hash_table){tmp.insert(e._kv);}_hash_table.swap(tmp._hash_table);}size_t hashi = kv.first % _hash_table.size();size_t i = 1;size_t index = hashi;// 若插入位置发生冲突,则继续探测while (_hash_table[index]._state == EXIST){// 一次探测index = hashi + i;// 二次探测//index = hashi + i * i;i++;index %= _hash_table.size();}_hash_table[index]._kv = kv;_hash_table[index]._state = EXIST;_n++;return true;}(3)闭散列的删除
bool erase(const K& key){auto pos = find(key);if (pos == nullptr)return false;pos->_state = DELETE;_n--;return false;}5、开散列及其实现
开散列又叫链地址法(开链法),当我们得到一个关键码时,我们将这个关键码求出对应的地址,我们称对应地址所在位置为一个哈希桶,我们将这个数据以链表的形式挂在对应的哈希桶下面;如下图所示;
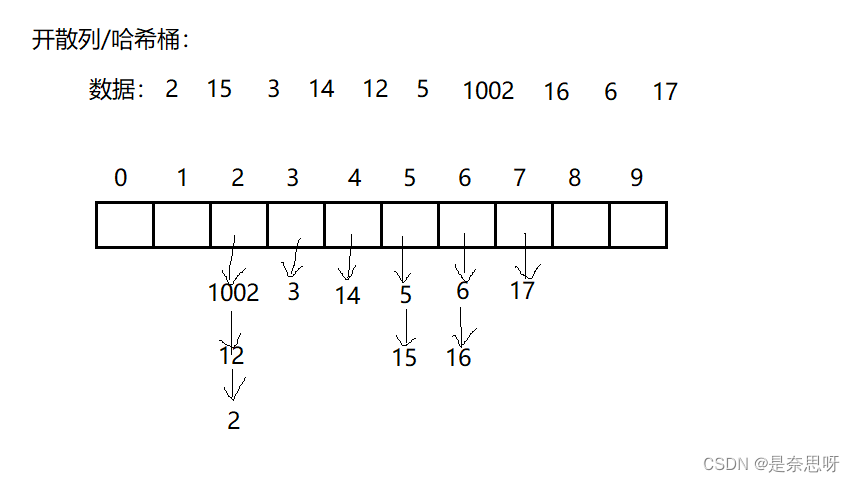
不难看出,每个哈希桶下面挂着发生哈希冲突的值,实际上,我们的unordered_set与unordered_map同样也是使用开散列的哈希桶进行封装;;我们根据上述,同样也可以实现出开散列类的基本结构,如下所示;
namespace OpenHash
{template<class K, class V>struct HashNode{typedef HashNode<K, V> Node;HashNode(const std::pair<K, V>& kv):_kv(kv),_next(nullptr){}std::pair<K, V> _kv;Node* _next = nullptr;};template<class K, class V>class HashBucket{public:typedef HashNode<K, V> Node;private:std::vector<Node*> _hash_table;size_t _n = 0; // 存储的元素个数};
}(1)开散列的查找
查找并无难度,我们仅仅只需要算出对应的hashi,然后在对应桶下面的单链表中查找即可;
Node* find(const K& key){if (_hash_table.size() == 0)return nullptr;size_t hashi = key % _hash_table.size();Node* cur = _hash_table[hashi];while (cur){if (cur->_kv.first == key)return cur;cur = cur->_next;}return nullptr;}(2)开散列的插入
开散列同样也要考虑扩容问题,开散列的负载因子我们可以略微增加,因为开散列的哈希碰撞几率明显降低了,这里我们把负载因子设置为了1;
bool insert(const std::pair<K, V>& kv){// 扩容if (_hash_table.size() == 0 || _n * 10 / _hash_table.size() == 10){int newsize = _hash_table.size() == 0 ? 10 : _hash_table.size() * 2;HashBucket<K, V> tmp;tmp._hash_table.resize(newsize, nullptr);for (auto& cur : _hash_table){// 将该链表下所有结点放入新表中while (cur){Node* next = cur->_next;size_t hashi = cur->_kv.first % tmp._hash_table.size();// 头插入新表中cur->_next = tmp._hash_table[hashi];tmp._hash_table[hashi] = cur;cur = next;}}_hash_table.swap(tmp._hash_table);}// 插入size_t hashi = kv.first % _hash_table.size();Node* newnode = new Node(kv);if (_hash_table[hashi] == nullptr){_hash_table[hashi] = newnode;}else{// 头插newnode->_next = _hash_table[hashi];_hash_table[hashi] = newnode;}_n++;return true;}(3)开散列的删除
这里需要注意头删的特殊处理;
bool erase(const K& key){Node* pos = find(key);if (pos == nullptr)return false;size_t hashi = key % _hash_table.size();Node* prev = nullptr;Node* cur = _hash_table[hashi];while (cur){if (cur->_kv.first == key){// 头删if (prev == nullptr){_hash_table[hashi] = cur->_next;}else // 中间尾部删除{prev->_next = cur->_next;}delete cur;return true;}else{prev = cur;cur = cur->_next;}}return false;}(4)其他函数
这里需要实现拷贝构造,因为vector里存的成员是链表,对于链表,我们要进行深拷贝,不然会内存泄露;
// 默认构造HashBucket():_n(0){}// 拷贝构造HashBucket(const HashBucket<K, V>& hb){// 深拷贝if (this != &hb){_hash_table.resize(hb._hash_table.size(), nullptr);for (size_t i = 0; i < hb._hash_table.size(); i++){Node* cur = hb._hash_table[i];Node* copytail = nullptr;while (cur){Node* newnode = new Node(cur->_kv);if (_hash_table[i] == nullptr){_hash_table[i] = newnode;copytail = newnode;}else{copytail->_next = newnode;copytail = copytail->_next;}cur = cur->_next;}}}}// 赋值重载(现代写法)HashBucket<K, V>& operator=(HashBucket<K, V> hb){_hash_table.swap(hb._hash_table);std::swap(_n, hb._n);return *this;}// 析构函数~HashBucket(){clear();}size_t size(){return _n;}void clear(){for (size_t i = 0; i < _hash_table.size(); i++){Node* cur = _hash_table[i];while (cur){Node* del = cur;cur = cur->_next;delete del;}_hash_table[i] = nullptr;}}6、开散列与闭散列的一些其他问题
(1)对于自定义类型成员无法确定位置
前面不管是开散列还是闭散列,我们在求取hashi的时候,我们都是直接求余数的,假如我们的key是string类型呢?那不就都会报错吗?所以,此时我们必须多提供一个模板参数,也就是我们unordered_set/unordered_map第三个模板参数Hash,这个参数就是我们可以传入一个仿函数,控制如何将key转换成size_t类型;
// 增加后的模板列表template<class K, class V, class HashFunc = Hash<K>>class HashBucket//增加的默认Hash函数template<class K>struct Hash{size_t operator()(const K& key){return key;}};// 特化template<>struct Hash<std::string>{// BKDRHashsize_t operator()(const std::string& s1){size_t hash = 0;for (auto ch : s1){hash = hash * 31 + ch;}return hash;}};关于字符串哈希算法下面有一篇博客进行了详细介绍,上述代码就是采用其中之一的BKDRHash; 字符串哈希函数
(2)模素数优化
经过研究发现,除留余数法最好模上一个素数,这样哈希冲突的概率比较低;因此,我们可以在每次扩容时,我们取比当前容量大两倍的一个素数,因此有了以下代码;
size_t GetNextPrime(size_t prime){const int PRIMECOUNT = 28;static const size_t primeList[PRIMECOUNT] ={53ul, 97ul, 193ul, 389ul, 769ul,1543ul, 3079ul, 6151ul, 12289ul, 24593ul,49157ul, 98317ul, 196613ul, 393241ul, 786433ul,1572869ul, 3145739ul, 6291469ul, 12582917ul,25165843ul,50331653ul, 100663319ul, 201326611ul, 402653189ul,805306457ul,1610612741ul, 3221225473ul, 4294967291ul};size_t i = 0;for (; i < PRIMECOUNT; ++i){if (primeList[i] > prime)return primeList[i];}return primeList[i];}
我们每次扩容直接调用这个函数即可拿到扩容的大小;
二、unordered_set与unordered_map的封装
这两个容器的封装与我们map、set封装差不多,我们修改一下我们之前写的哈希表,然后进行封装即可;代码提交至gitee中;有兴趣的可以查看;
容器封装代码
相关文章:
C++ | 哈希表的实现与unordered_set/unordered_map的封装
目录 前言 一、哈希 1、哈希的概念 2、哈希函数 (1)直接定址法 (2)除留余数法 (3)平方取中法(了解) (4)随机数法(了解) 3、哈…...
【漏洞挖掘】Xray+rad自动化批量漏洞挖掘
文章目录 前言一、挖掘方法二、使用步骤工具安装使用方法开始挖掘 总结 前言 自动化漏洞挖掘是指利用计算机程序和工具来扫描、分析和检测应用程序、网络和系统中的安全漏洞的过程。这种方法可以帮助安全专家和研究人员更高效地发现和修复潜在的安全威胁,从而提高整…...

Swagger UI教程 API 文档和Node的使用
在团队开发中,一个好的 API 文档可以减少很多交流成本,也可以使一个新人快速上手业务。 前言 swagger ui是一个API在线文档生成和测试的利器,目前发现最好用的。为什么好用?Demo 传送门 支持API自动生成同步的在线文档 这些文档可…...

P5691 [NOI2001] 方程的解数
[NOI2001] 方程的解数 题目描述 已知一个 n n n 元高次方程: ∑ i 1 n k i x i p i 0 \sum\limits_{i1}^n k_ix_i^{p_i} 0 i1∑nkixipi0 其中: x 1 , x 2 , … , x n x_1, x_2, \dots ,x_n x1,x2,…,xn 是未知数, k 1 ,…...

rust里用什么表示字节类型?
在Rust中,字节可以使用 u8 类型来表示。 u8 是一个无符号8位整数类型,可以表示0到255之间的值,对应于一个字节的范围。 以下是一个示例,演示了如何声明和使用字节: fn main() {let byte: u8 65; // 表示字母A的ASCI…...
CMake简介
文章目录 为什么需要头文件为什么 C 需要声明头文件 - 批量插入几行代码的硬核方式头文件进阶 - 递归地使用头文件 CMake什么是编译器多文件编译与链接CMake 的命令行调用为什么需要库(library)CMake 中的静态库与动态库CMake 中的子模块子模块的头文件如…...
[threejs]相机与坐标
搞清相机和坐标的关系在threejs初期很重要,否则有可能会出现写了代码,运行时一片漆黑的现象,这种情况就有可能是因为你相机没弄对。 先来看一下threejs中的坐标(世界坐标) 坐标轴好理解,大家只需要知道在three中不同颜色代表的轴…...

Qt信号与槽机制的基石-MOC详解
引入 上篇讲到了信号与槽就是实现的观察者模式,那具体如何生成映射表就是moc做的事情。 一、moc简介 1. moc的定义 moc 全称是 Meta-Object Compiler,也就是“元对象编译器”,它主要用于处理C源文件中的非标准C代码。Qt 程序在交由标准编…...

关于单体架构缓存刷新实现方案
背景 如果各位看官是分布式项目应该都采用分布式缓存了,例如redis等,分布式缓存不在本次讨论范围哈;我个人建议是,如果是用户量比较大,建议采用分布式缓存机制,后期可以很容易前后到分布式服务或微服务。 …...

洞悉安全现状,建设网络安全防护新体系
一、“网络攻防演练行动“介绍 国家在2016年发布《网络安全法》,出台网络安全攻防演练相关规定:关键信息基础设施的运营者应“制定网络安全事件应急预案,并定期进行演练”。同年“实战化网络攻防演练行动”成为惯例。由公安部牵头࿰…...
spring中怎么通过静态工厂和动态工厂获取对象以及怎么通过 FactoryBean 获取对象
😀前言 本章是spring基于XML 配置bean系类中第4篇讲解spring中怎么通过静态工厂和动态工厂获取对象以及怎么通过 FactoryBean 获取对象 🏠个人主页:尘觉主页 🧑个人简介:大家好,我是尘觉,希望…...
)
三元组表实现矩阵相加(数据结构)
代码: 含注释,供参考 #include <stdio.h> #include <stdlib.h>typedef struct {int row,col,value;//分别为行数,列数,数值 } Triple; typedef struct {int len;//非零数值的个数Triple data[200]; } TSMatrix;void…...

ChinaJoy 2023微星雷鸟17游戏本震撼发布:搭载AMD锐龙9 7945HX首发8499元
ChinaJoy 2023展会中微星笔记本再次给大家带来惊喜,发布了搭载AMD移动端16大核的旗舰游戏本:雷鸟17,更重要的这样一款旗舰性能的游戏本,首发价8499元堪称当今游戏本市场中的“性价比爆款”! 本着和玩家一同制霸游戏战场…...

各种运算符
算术运算符 1.双目运算符 */%:从左到右优先级依次降低 一些注意事项: 1若a/b都为整型那么结果也为整型,如果ab其中有一个为实型,结果则为实型 求余运算符注意事项: 1运算对象必须为整数 2运算结果的整数跟左边数字的…...
yolov3-tiny原理解析及代码分析
前言 从去年十一月份开始学习yolo神经网络用于目标识别的硬件实现,到现在已经六个月了。一个硬件工程师,C/C基础都差劲的很,对照着darknet作者的源码和网上东拼西凑的原理讲解,一点一点地摸索。刚开始进度很慢,每天都…...

深入了解Redis-实战篇-短信登录
深入了解Redis-实战篇-短信登录 一、故事背景二、知识点主要构成2.1、短信登录2.1.1、生成随机短信验证码引入maven依赖生成验证码 2.1.2、实现登录校验拦截器2.1.3、基于Redis实现短信登录2.1.3.1、发送验证码时存入Redis2.1.3.2、登录时校验验证码 2.1.4、解决状态登录刷新的…...
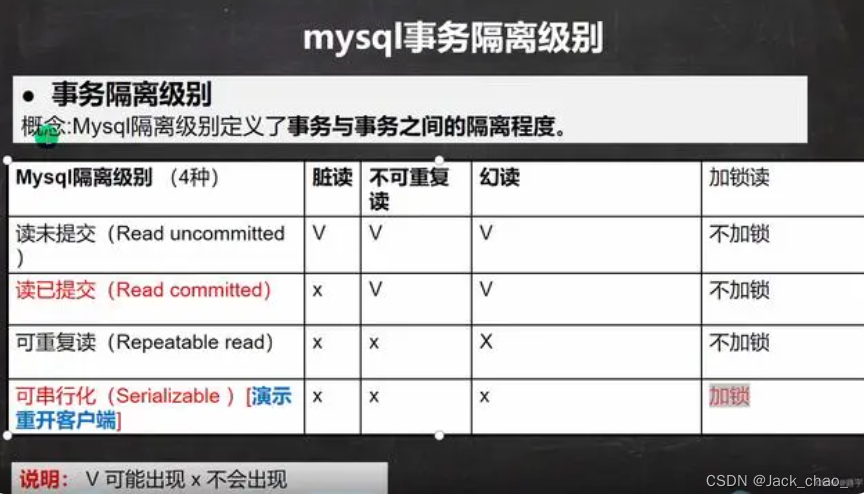
Mysql的锁
加锁的目的 对数据加锁是为了解决事务的隔离性问题,让事务之前相互不影响,每个事务进行操作的时候都必须先加上一把锁,防止其他事务同时操作数据。 事务的属性 (ACID) 原子性 一致性 隔离性 持久性 事务的隔离级别 锁…...

【EI/SCOPUS征稿】2023年算法、图像处理与机器视觉国际学术会议(AIPMV2023)
2023年算法、图像处理与机器视觉国际学术会议(AIPMV2023) 2023 International Conference on Algorithm, Image Processing and Machine Vision(AIPMV2023) 2023年算法、图像处理与机器视觉国际学术会议(AIPMV2023&am…...
Go语言性能优化建议与pprof性能调优详解——结合博客项目实战
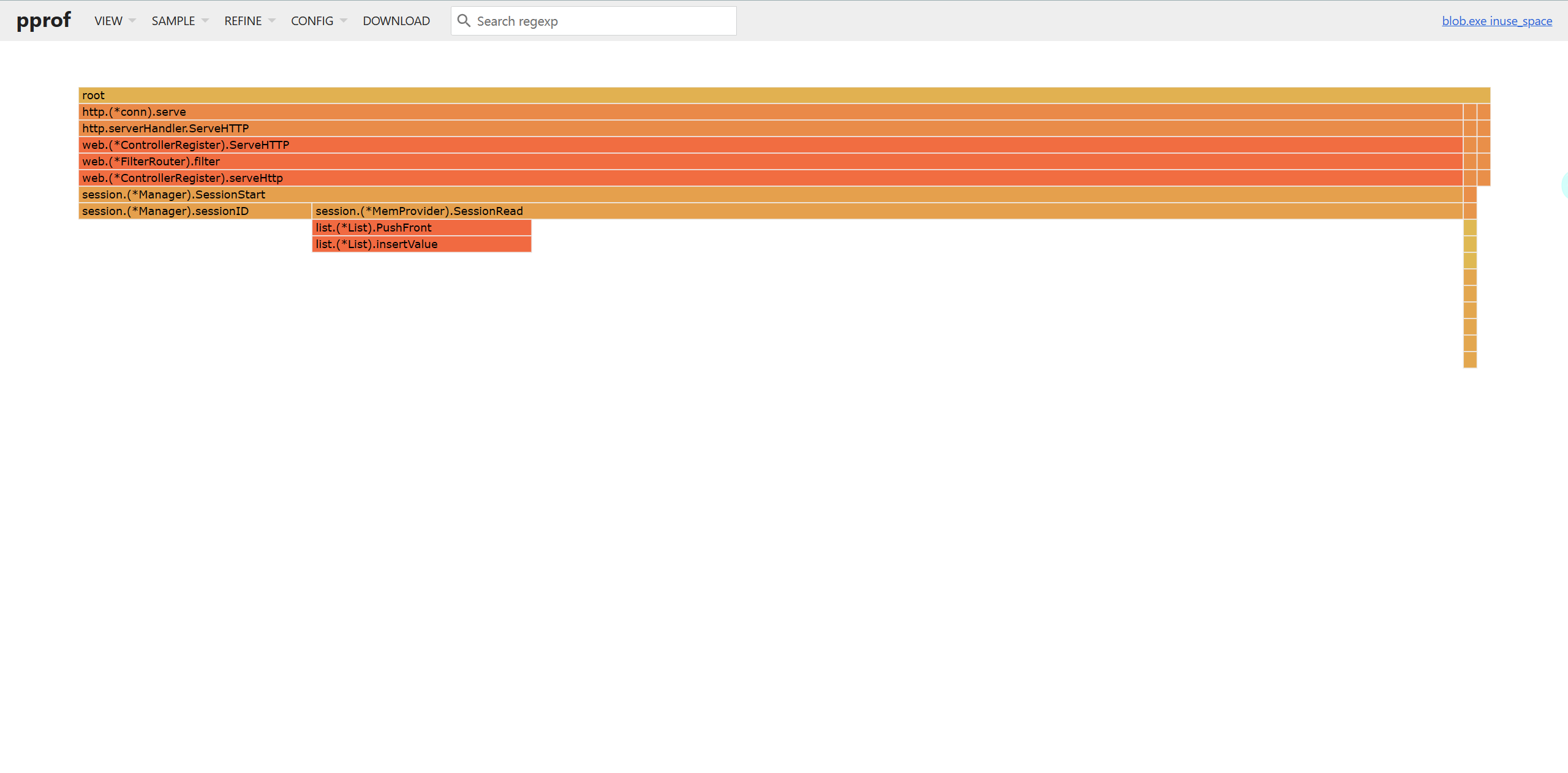
文章目录 性能优化建议Benchmark的使用slice优化预分配内存大内存未释放 map优化字符串处理优化结构体优化atomic包小结 pprof性能调优采集性能数据服务型应用go tool pprof命令项目调优分析修改main.go安装go-wrk命令行交互界面图形化火焰图 性能优化建议 简介: …...
)
K阶斐波那契数列(数据结构)
代码: 注意k阶斐波那契序列定义:第k和k1项为1,前k - 1项为0,从k项之后每一项都是前k项的和 例如:k2时,斐波那契序列为:0,1,1,2,3,5,8,13... k3时,斐波那契序列为:0,0,…...

Mac应用卸载不干净?Pearcleaner帮你彻底清理,释放存储空间
Mac应用卸载不干净?Pearcleaner帮你彻底清理,释放存储空间 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾发现,…...

Office RibbonX Editor:零编程定制Office界面的终极免费开源工具
Office RibbonX Editor:零编程定制Office界面的终极免费开源工具 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribb…...

抖音下载神器:3步轻松搞定无水印批量下载完整教程
抖音下载神器:3步轻松搞定无水印批量下载完整教程 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...
)
告别命令行!用VSCode插件一键搞定ESP-IDF环境(ESP32/S3保姆级教程)
告别命令行!用VSCode插件一键搞定ESP-IDF环境(ESP32/S3保姆级教程) 当一块崭新的ESP32开发板躺在桌面上时,许多开发者会陷入两难:既渴望体验这款低功耗Wi-Fi/蓝牙双模芯片的强大性能,又对繁琐的环境配置望而…...

钡特电源 VF3-12S03P 与金升阳 WRF1203P-2WR3 同属工业高可靠:封装引脚与可靠性对比
在工业控制、通信终端及仪器仪表等领域,工业 DC-DC 电源模块作为核心供电单元,其性能稳定性与设计标准化程度,直接影响整机设备的长期可靠运行。随着国内电子产业自主化进程加快,国产直流电源模块在技术研发、工艺制造及标准适配层…...

Cortex-M7 WIC模块移除的影响与工程实践
1. Cortex-M7中移除WIC的影响解析在嵌入式系统设计中,Cortex-M7处理器的WIC(Wakeup Interrupt Controller)模块是一个值得深入探讨的组件。作为一位从事ARM架构开发多年的工程师,我经常遇到客户询问关于WIC配置的问题。这个看似简…...

UE5蓝图与C++权力边界:编辑器独占与全栈覆盖解析
1. 这不是“选哪个更好”,而是“谁在什么时候说了算”在UE5项目组里,我见过太多次这样的场景:美术同学改完一个材质参数,发现蓝图里调用的函数突然不生效了;程序刚写完一套C Actor逻辑,策划在编辑器里拖拽组…...

量子计算如何革新自然语言处理的语义分析
1. 量子计算与自然语言处理的交叉探索量子计算与自然语言处理的结合正在开辟一个全新的研究领域。作为一名长期关注量子计算应用的从业者,我见证了这项技术从理论构想逐步走向实际验证的过程。量子计算利用量子比特(qubit)的叠加态和纠缠特性…...

GPT-4的1.8万亿参数与2%稀疏激活原理揭秘
1. 项目概述:参数规模与稀疏激活的真相拆解“GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去两年在技术社区反复刷屏,常被当作AI算力爆炸的佐证,也常被误读为“模型只用了一丁点参数,所以还有…...
:含12个领域专属风格锚点模板与冲突检测CLI工具)
NotebookLM风格一致性密钥库(仅限首批200位AI架构师开放获取):含12个领域专属风格锚点模板与冲突检测CLI工具
更多请点击: https://kaifayun.com 第一章:NotebookLM风格一致性密钥库的演进逻辑与核心价值 NotebookLM 风格的一致性密钥库并非传统密码学密钥管理系统的简单复刻,而是面向语义化知识协作场景深度重构的基础设施。其演进逻辑根植于三个关键…...