Spring Data Elasticsearch - 在Spring应用中操作Elasticsearch数据库
Spring Data Elasticsearch
文章目录
- Spring Data Elasticsearch
- 1. 定义文档映射实体类
- 2. Repository
- 3. ElasticsearchRestTemplate
- 3.1 查询相关特性
- 3.1.1 过滤
- 3.1.2 排序
- 3.1.3 自定义分词器
- 3.2 高级查询
- 4. 索引管理
- 4.1 创建索引
- 4.2 检索索引
- 4.3 修改映射
- 4.4 删除索引
- 5. 异常处理
- 6. 性能优化
- 7. 应用案例
- 8. Spring Data Elasticsearch优势
Spring Data Elasticsearch为文档的存储,查询,排序和统计提供了一个高度抽象的模板。使用Spring Data ElasticSearch来操作Elasticsearch,可以较大程度的减少我们的代码量,提高我们的开发效率。
要使用Elasticsearch我们需要引入如下依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId><version>2.1.7.RELEASE</version>
</dependency>
还需要在配置文件中增加如下配置
spring:elasticsearch:rest:# elasticsearch server的地址uris: 192.168.0.102:9200# 连接超时时间connection-timeout: 6s# 访问超时时间read-timeout: 10s
1. 定义文档映射实体类
类比于MyBatis-Plus可以定义实体类去映射数据库中的表中的数据,使用Spring Data Elasticsearch时,我们也可以通过定义一个实体类映射ES索引中的文档。
@Data
@Document(indexName = "goods", shards = 1, replicas = 0)
public class Goods {// 商品Id skuId _id@Idprivate Long id;@Field(type = FieldType.Keyword, index = false)private String defaultImg;// elasticsearch 中能分词的字段,这个字段数据类型必须是 text!keyword 不分词!@Field(type = FieldType.Text, analyzer = "ik_max_word")private String title;@Field(type = FieldType.Double)private Double price;@Field(type = FieldType.Long)private Long tmId;@Field(type = FieldType.Keyword)private String tmName;@Field(type = FieldType.Keyword)private String tmLogoUrl;@Field(type = FieldType.Long)private Long firstLevelCategoryId;@Field(type = FieldType.Keyword)private String firstLevelCategoryName;@Field(type = FieldType.Long)private Long secondLevelCategoryId;@Field(type = FieldType.Keyword)private String secondLevelCategoryName;@Field(type = FieldType.Long)private Long thirdLevelCategoryId;@Field(type = FieldType.Keyword)private String thirdLevelCategoryName;// 商品的热度! 我们将商品被用户点查看的次数越多,则说明热度就越高!@Field(type = FieldType.Long)private Long hotScore = 0L;// 平台属性集合对象// Nested 支持嵌套查询@Field(type = FieldType.Nested)private List<SearchAttr> attrs;}
/*该类映射nested平台属性
*/
@Data
public class SearchAttr {// 平台属性Id@Field(type = FieldType.Long)private Long attrId;// 平台属性值名称@Field(type = FieldType.Keyword)private String attrValue;// 平台属性名@Field(type = FieldType.Keyword)private String attrName;
}
在Goods类上,通过添加@Document注解,我们将Goods类映射的文档所属的索引:
- @Document注解的indexName属性,用来定义实体类所映射的文档所属的目标索引名称
- @Document的shards属性,表示目标索引的住分片数量
- @Document的replicas属性,表示每个主分片所拥有的副本分片的数量
在Goods类的成员变量Id上通过添加@Id注解指定,Id成员变量映射到Goods索引中文档的id字段,同时也映射到文档的唯一表示_id字段。
在Goods类的其他成员变量上,通过添加@Field注解,定义成员变量和文档字段的映射关系:
- 默认同名成员变量,映射到文档中的同名字段(也可以由@Field注解的name属性显示指定)
- 通过@Field注解的type属性指定文档中同名字段的数据类型
- 通过@Field注解的analyzer属性,指定成员变量所映射的文档字段所使用的分词器
2. Repository
类比于Mybatis-Plus中定义BaseMaper子接口即可对单表做增删改查的操作,Spring Data Elastisearch中我们可以通过定义ElasticsearchRepository子接口,迅速实现对索引中的文档数据的增删改查,以及通过自定义方法,实现自定义查询。
public interface GoodsRepository extends ElasticsearchRepository<Goods,Long> {}
ElasticsearchRepository接口需要接收两个泛型,第一个泛型即映射实体类,第二个泛型是在实体类中加了@Id注解的成员变量的数据类型,即映射到文档唯一标识_id字段的成员变量类型。
一旦我们定义好了ElasticsearchRepository的子接口,马上就可以实现对goods索引中文档的增删改查功能
// 注入repository对象@Autowiredprivate GoodsRepository goodsRepository;// 保存单个文档对象Goods good = ....goodsRepository.save(good);// 批量保存多个文档对象List<Goods> goods = ...goodsRepository.save(goods);// 根据id查询goodsRepository.findById(id);// 根据id删除goodsRepository.deleteById(id);同时,还需要注意一点,一旦定义好了ElasticsearchRepository接口,而且被SpringBoot启动类扫描到,那么在应用启动的时候,如果ElasticsearchRepository子接口所访问的索引在ES中不存在,Spring Data Elasticsearch会在ES中自动创建索引,并根据映射实体类定义索引的映射。
但是,大多数时候,我们可能需要对索引中的文档数据做自定义查询,此时仅仅使用ElasticsearchRepository接口中继承的方法无法满足我们的需求。此时就需要在自己的Repository接口中,通过自定义方法来实现各种自定义查询。
- 利用@Query注解自定义查询脚本
/* 1. 通过Query注解定义具体的查询字符串(也可以替换为其他查询)2. 字符串中的?0是固定格式,表示第0个参数的占位符,在实际查询时会被方法的第一个参数值title的值替换, 如果有多个参数,依次类推即可3. List<Goods>// 模糊查询@Query("{\"fuzzy\": {\"title\": \"?0\"}}") // 范围查询@Query("{\"range\": {\"price\": {\"gte\": ?0, \"lte\": ?1}}}") // 前缀查询@Query("{\"prefix\": {\"title\": \"?0\"}}")*/@Query("{ " +"\"match\": {\n" +" \"title\": \"?0\"\n" +"}" +"}")List<Goods> matchSearch(String title);
这里的@Query注解中,只需要包含我们查询脚本中"query"{}里面的内容即可,比如上面的@Query注解所表示的查询等价于
GET goods/_search
{"query": {"match": {"title": 具体待查询的参数值}}
}
@AutowiredProductRepository productRepository;@Testpublic void testMatchSearch() {// 在调用的时候传递查询的参数值List<Goods> list = goodsRepository.matchSearch("荣耀手机");System.out.println(list);}
- 利用@Query注解结合分页参数,实现分页查询
/*1. 针对一个查询结果,返回对应的一页数据2. Pageable参数是当想要获取分页数据的时候,必须携带的参数,表示分页信息比如,查询第多少页数据,每页多少条数据等,该参数不会用来替换我们的@Query字符串中的参数3. 返回的结果是一个包含一页文档数据的Page对象*/@Query(" {" +" \"match\": {\n" +" \"title\": \"?0\"\n" +" }" +"}")Page<Goods> testSearchPage(String title, Pageable pageable);
// 注入repository对象@Autowiredprivate GoodsRepository goodsRepository;/*测试分页查询*/@Testpublic void testSearchPage() {// 创建表示分页信息的Pageable对象// 表示查询第几页数据,这里一定要注意,页数是从0开始算的int page = 0;// 每页假设10个文档int pageCount = 10;// 调用Sort方法得到Sort对象,一个Sort对象表示Sort sort = Sort.by(Sort.Direction.ASC, "price");// PageRequest 是 Pageable接口子类对象PageRequest pageInfo = PageRequest.of(page, pageCount,sort);// 这里的Page对象可以被看做是ListPage<Goods> pageResult = goodsRepository.testSearchPage("小米手机", pageInfo);// 遍历集合,从每个SearchHit对象中取出文档对象,// 如果需要返回可以在遍历的时候将其,放入一个List中返回pageResult.forEach( goods -> {// 访问查询到的一条文档// ...});// 获取满足条件的总的文档数量long totalElements = pageResult.getTotalElements();}
- @Query注解 + @Highlight + 分页参数实现高亮,分页自定义查询
@Query(" { \"match\": {\n" +" \"title\": \"?0\"\n" +" }" +"}")@Highlight(fields = {@HighlightField(name = "title",parameters = @HighlightParameters(preTags = "<font color='red'>", postTags = "</font>"))})List<SearchHit<Goods>> testHighlight(String title, Pageable pageable);
@Testpublic void testHighlight() {// 分页参数PageRequest of = PageRequest.of(0, 10);// 调用Repository方法获取搜索结果List<SearchHit<Goods>> result = goodsRepository.testHighlight("小米手机", of);// 结果集List<Goods> itemDocuments = new ArrayList<>();result.forEach(hit -> {// 获取目标文档Goods content = hit.getContent();// 获取高亮字段title对应的高亮字符串List<String> title = hit.getHighlightField("title");// 在文档对象中,用高亮字符串替换掉原来的值content.setTitle(title.get(0));// 加入结果集itemDocuments.add(content);});System.out.println(itemDocuments.size());}
虽然,testHighlight方法既实现了分页查询,又实现了高亮查询,但是有一个缺陷就是,该方法无法获取到满足查询条件的总的文档数量,它只会返回满足条件的一页文档数据。不知道满足条件的文档总数,前端就无法完成分页。
所以,很明显Repository好用,但是具有一定的局限性,如果面对比较复杂的查询,此时就只能使用Spring Data Elasticsearch提供的另外一个工具ElasticsearchRestTemplate了。
3. ElasticsearchRestTemplate
3.1 查询相关特性
3.1.1 过滤
使用BoolQuery进行过滤:
BoolQueryBuilder qb = QueryBuilders.boolQuery();
qb.filter(QueryBuilders.termQuery("price", 199)); // 过滤条件
3.1.2 排序
使用SortBuilders构建排序条件:
SortBuilder sort = SortBuilders.fieldSort("price").order(SortOrder.ASC);
3.1.3 自定义分词器
在字段上使用analyzer属性指定分词器:
@Field(analyzer = "ik_max_word")
private String title;
3.2 高级查询
构造自定义分页,高亮,nested以及聚合查询,并发起请求
@AutowiredElasticsearchRestTemplate restTemplate;@AutowiredGoodsConverter goodsConverter;@Testpublic void testRestTemplate() {// 该Builder包含所有搜索请求的参数NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();// 获取bool查询BuilderBoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();// 构造bool查询中match查询MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("title", "小米手机");// 将该查询加入bool查询must中boolQueryBuilder.must(matchQuery);TermQueryBuilder subQueryForAttrNested = QueryBuilders.termQuery("attrs.attrValue", "8G");// 构造nested查询NestedQueryBuilder attrsNestedQuery = QueryBuilders.nestedQuery("attrs", subQueryForAttrNested, ScoreMode.None);// 将nested查询作为一个过滤条件boolQueryBuilder.filter(attrsNestedQuery);// 将整个bool查询添加到NativeSearchQueryBuilderqueryBuilder.withQuery(boolQueryBuilder);// 构造分页参数//PageRequest price = PageRequest.of(0, 10, Sort.by(Sort.Order.desc("price")));PageRequest price = PageRequest.of(0, 10);// 向NativeSearchQueryBuilder添加分页参数queryBuilder.withPageable(price);// 按照指定字段值排序FieldSortBuilder priceSortBuilder = SortBuilders.fieldSort("price").order(SortOrder.ASC);queryBuilder.withSort(priceSortBuilder);// 构造高亮参数HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.field("title").preTags("<font color='red'>").postTags("</font>");// 向NativeSearchQueryBuilder添加高亮参数queryBuilder.withHighlightBuilder(highlightBuilder);// 设置品牌聚合(平台属性等的聚合也是相同的方式)TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("tmIdAgg").field("tmId").subAggregation(AggregationBuilders.terms("tmNameAgg").field("tmName")).subAggregation(AggregationBuilders.terms("tmLogoUrlAgg").field("tmLogUrl"));// 向NativeSearchQueryBuilder添加聚合参数queryBuilder.addAggregation(termsAggregationBuilder);// 结果集过滤,只包含原始文档的id,defaultImg,title,pricequeryBuilder.withFields("id", "defaultImg", "title", "price");// 使用ElasticsearchRestTemplate发起搜索请求NativeSearchQuery build = queryBuilder.build();SearchHits<Goods> search = restTemplate.search(build, Goods.class);//封装所有的查询数据SearchResponseDTO searchResponseDTO = new SearchResponseDTO();// 获取满足条件的总文档数量long totalHits = search.getTotalHits();// 设置查询到的总文档条数searchResponseDTO.setTotal(totalHits);// 获取包含所有命中文档的SearchHit对象List<SearchHit<Goods>> searchHits = search.getSearchHits();// 处理搜索到的结果集即SearchHit<Goods>集合, 并使用高亮字符串替换List<GoodsDTO> goodsList = searchHits.stream().map(hit -> {// 获取命中的文档Goods content = hit.getContent();//获取高亮字段List<String> title = hit.getHighlightField("title");// 用高亮字段替换content.setTitle(title.get(0));// 将Goods对象转化为GoodsDTO对象GoodsDTO goodsDTO = goodsConverter.goodsPO2DTO(content);return goodsDTO;}).collect(Collectors.toList());// 设置查询到的结果列表searchResponseDTO.setGoodsList(goodsList);// 从品牌聚合中获取品牌集合// 根据id获取品牌id terms聚合结果Terms terms = search.getAggregations().get("tmIdAgg");List<SearchResponseTmDTO> trademarkList = terms.getBuckets().stream().map(tmIdBucket -> {// 封装品牌数据SearchResponseTmDTO searchResponseTmDTO = new SearchResponseTmDTO();String tmIdStr = tmIdBucket.getKeyAsString();// 获取品牌idLong tmId = Long.parseLong(tmIdStr);// 设置品牌idsearchResponseTmDTO.setTmId(tmId);// 获取品牌名称聚合(子聚合)Terms tmNameAgg = tmIdBucket.getAggregations().get("tmNameAgg");// 通过聚合桶的名称获取品牌名称String tmName = tmNameAgg.getBuckets().get(0).getKeyAsString();// 设置品牌名称searchResponseTmDTO.setTmName(tmName);// 获取品牌logo聚合(子聚合)Terms tmLogoUrlAgg = tmIdBucket.getAggregations().get("tmLogoUrlAgg");// 通过聚合桶的名称获取品牌名称String tmLogoUrl = tmLogoUrlAgg.getBuckets().get(0).getKeyAsString();// 设置品牌名称searchResponseTmDTO.setTmLogoUrl(tmLogoUrl);return searchResponseTmDTO;}).collect(Collectors.toList());// 设置聚合品牌数据searchResponseDTO.setTrademarkList(trademarkList);// .....}
4. 索引管理
4.1 创建索引
可以通过ElasticsearchRestTemplate的createIndex方法创建索引:
// 创建索引,使用实体类进行映射
restTemplate.createIndex(Goods.class);// 自定义索引设置
restTemplate.createIndex(Goods.class, c -> c.settings(s -> s .put("index.number_of_shards", 3) // 指定主分片数.put("index.number_of_replicas", 2) // 指定副本分片数).mapping(m -> m.put("dynamic", false) // 禁用动态映射)
);
4.2 检索索引
使用getIndex方法获取索引信息:
GetIndexResponse response = restTemplate.getIndex(Goods.class);
Map<String, Object> settings = response.getSettings();
Map<String, Object> mappings = response.getMappings();
4.3 修改映射
使用putMapping方法更新索引字段映射:
// 新增一个text字段
restTemplate.putMapping(Goods.class, m -> m.textField("newField"));
4.4 删除索引
使用deleteIndex删除索引:
restTemplate.deleteIndex(Goods.class);
5. 异常处理
使用@ExceptionHandler注解处理Elasticsearch异常:
@ExceptionHandler(ElasticsearchException.class)
public Response handleError(Exception e) {// 处理异常逻辑return Response.status(500).build();
}
6. 性能优化
- 加载批量文档,使用 bulk 或 batch 方式
- 使用 scroll api 避免深分页问题
- 控制请求缓存大小,不要缓存过多数据
- 定期优化索引,提高查询性能
7. 应用案例
以电商网站的商品搜索为例:
- 定义商品索引、文档映射实体
- 构建查询,实现精确匹配、分词匹配、过滤、聚合等复杂查询
- 使用高级功能如Suggest完成自动补全
- 可视化分析商品热门趋势、用户行为数据
8. Spring Data Elasticsearch优势
- 简化开发,不需要了解 ES 客户端细节
- 查询方式灵活,支持自定义复杂 DSL 语句
- 提供索引管理、错误处理等功能
- 易于测试和扩展
- 与 Spring Boot 无缝集成,开发效率高
相关文章:

Spring Data Elasticsearch - 在Spring应用中操作Elasticsearch数据库
Spring Data Elasticsearch 文章目录 Spring Data Elasticsearch1. 定义文档映射实体类2. Repository3. ElasticsearchRestTemplate3.1 查询相关特性3.1.1 过滤3.1.2 排序3.1.3 自定义分词器 3.2 高级查询 4. 索引管理4.1 创建索引4.2 检索索引4.3 修改映射4.4 删除索引 5. 异常…...
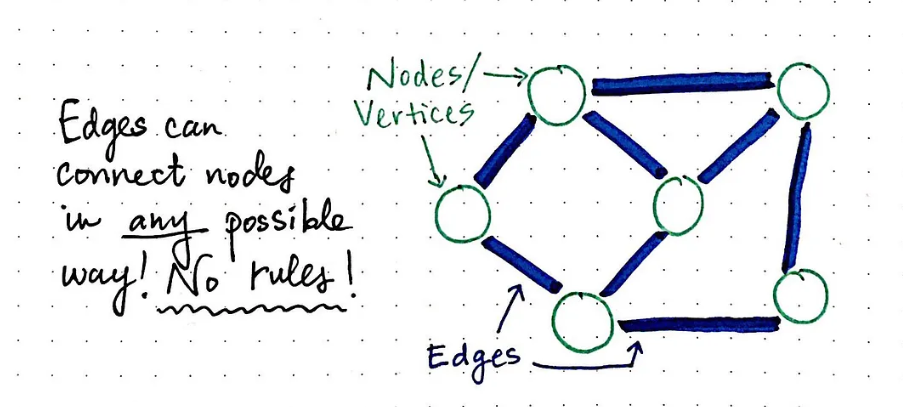
图论-简明导读
计算机图论是计算机科学中的一个重要分支,它主要研究图的性质和结构,以及如何在计算机上有效地存储、处理和操作这些图。本文将总结计算机图论的核心知识点。 一、基本概念 计算机图论中的基本概念包括图、节点、边等。图是由节点和边构成的数据结构&am…...
记一次 .NET 某物流API系统 CPU爆高分析
一:背景 1. 讲故事 前段时间有位朋友找到我,说他程序CPU直接被打满了,让我帮忙看下怎么回事,截图如下: 看了下是两个相同的程序,既然被打满了那就抓一个 dump 看看到底咋回事。 二:为什么会打…...
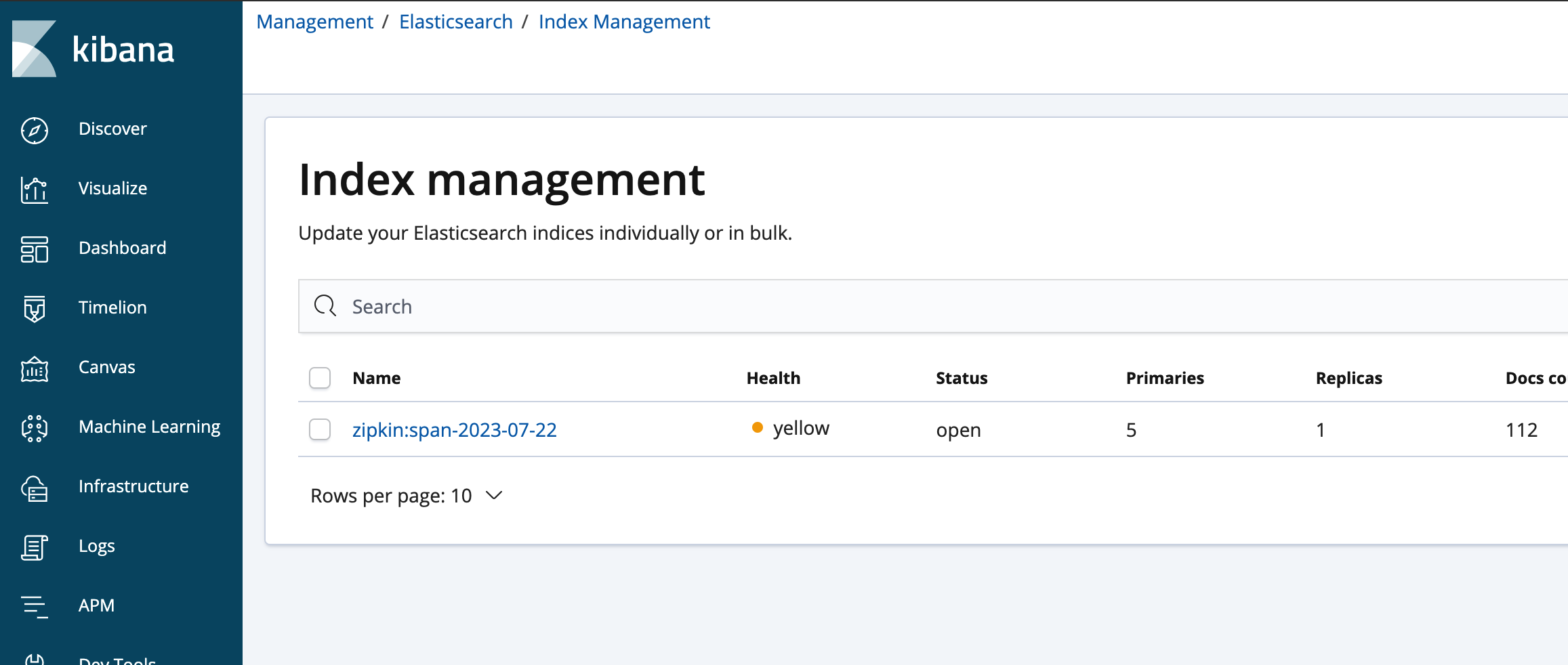
【Docker】Docker安装Kibana服务_Docker+Elasticsearch+Kibana
文章目录 1. 什么是Kibana2. Docker安装Kibana2.1. 前提2.2. 安装Kibana 点击跳转:Docker安装MySQL、Redis、RabbitMQ、Elasticsearch、Nacos等常见服务全套(质量有保证,内容详情) 1. 什么是Kibana Kibana 是一款适用于Elasticse…...

前端面试题-VUE
1. 对于MVVM的理解 MVVM 是 Model-View-ViewModel 的缩写Model 代表数据模型,也可以在 Model 中定义数据修改和操作的业务逻辑。View 代表 UI 组件,它负责将数据模型转化成 UI 展现出来。ViewModel 监听模型数据的改变和控制视图⾏为、处理⽤户交互&…...

Linux嵌入式平台安全启动理解介绍
一、意义 安全启动可以防止未授权的或是进行恶意篡改的软件在系统上运行,是系统安全的保护石,每一级的前一个镜像会对该镜像进行校验。 1.1 安全启动原理介绍 通过数字签名进行镜像完整性验证(使用到非对称加密算法和哈希算法) 签名过程: raw_image--->use ha…...
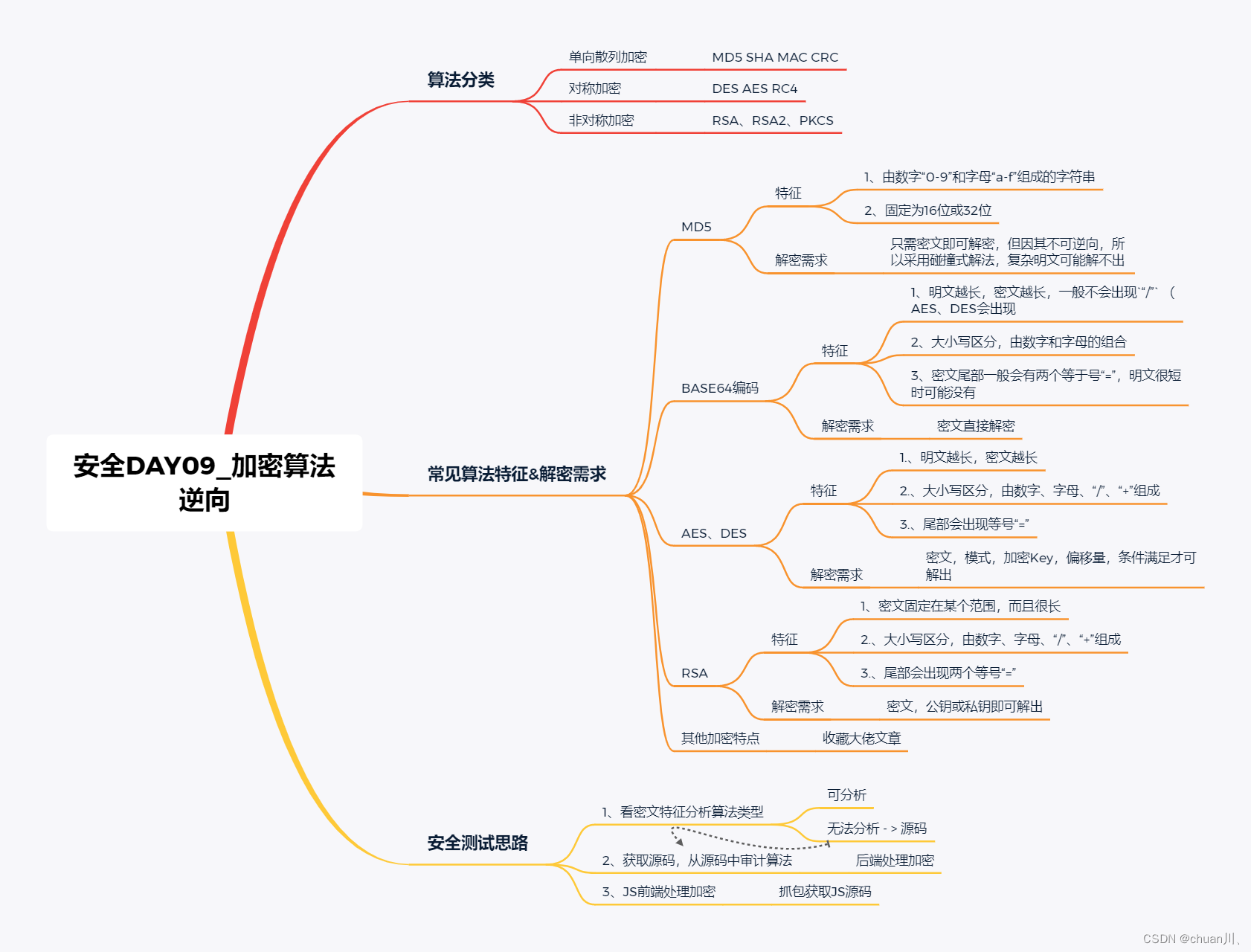
安全学习DAY09_加密逆向,特征识别
算法逆向&加密算法分类,特征识别 文章目录 算法逆向&加密算法分类,特征识别算法概念,分类单向散列加密 - MD5对称加密 - AES非对称加密 - RSA 常见加密算法识别特征,解密特点MD5密文特点BASE64编码特点AES、DES特点RSA密文…...
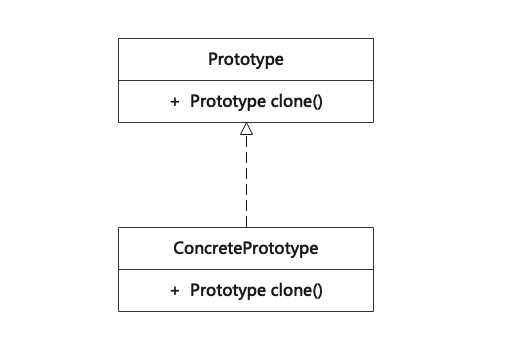
原型模式(Prototype)
原型模式是一种创建型设计模式,使调用方能够复制已有对象,而又无需使代码依赖它们所属的类。当有一个类的实例(原型),并且想通过复制原型来创建新对象时,通常会使用原型模式。 The Prototype pattern is g…...
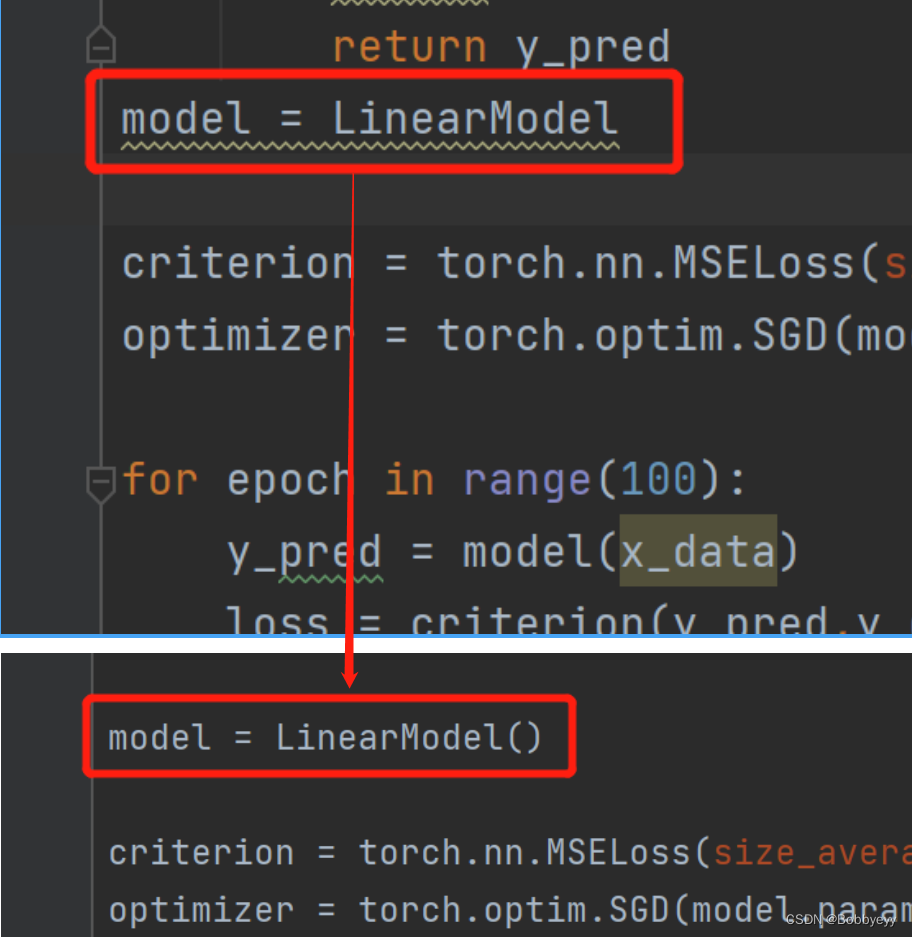
深度学习之用PyTorch实现线性回归
代码 # 调用库 import torch# 数据准备 x_data torch.Tensor([[1.0], [2.0], [3.0]]) # 训练集输入值 y_data torch.Tensor([[2.0], [4.0], [6.0]]) # 训练集输出值# 定义线性回归模型 class LinearModel(torch.nn.Module):def __init__(self):super(LinearModel, self)._…...

45.248.11.X服务器防火墙是什么,具有什么作用
防火墙是一种网络安全设备或软件,服务器防火墙的作用主要是在服务器和外部网络之间起到一个安全屏障的作用,保护计算机网络免受未经授权的访问、恶意攻击或不良网络流量的影响,保护服务器免受恶意攻击和非法访问。它具有以下功能:…...
如何以无服务器方式运行 Go 应用程序
Go编程语言一直以来都对构建REST API提供了丰富的支持。这包括一个出色的标准库(net/HTTP),以及许多流行的包,如Gorilla mux、Gin、Negroni、Echo、Fiber等。使用AWS Lambda Go运行时,我们可以使用Go构建AWS Lambda函数…...

小程序商城系统的开发方式及优缺点分析
小程序商城系统是一种新型的电子商务平台,它通过小程序的形式为商家提供了一种全新的销售渠道,同时也为消费者提供了一种便捷的购物体验。小程序商城系统具有低成本、快速上线、易于维护等特点,因此在市场上受到了广泛的关注和应用。这里就小…...

[数据集][目标检测]城市道路井盖破损丢失目标检测1377张
数据集制作单位:未来自主研究中心(FIRC) 数据集格式:Pascal VOC格式(不包含分割路径的txt文件和yolo格式的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):1377 标注数量(xml文件个数):1377 标注类别数&a…...
【Spring Cloud 三】Eureka服务注册与服务发现
系列文章目录 【Spring Cloud一】微服务基本知识 Eureka服务注册与服务发现 系列文章目录前言一、什么是Eureka?二、为什么要有服务注册发现中心?三、Eureka的特性四、搭建Eureka单机版4.1Eureka服务端项目代码pom文件配置文件启动类启动项目查看效果 E…...

WPF实战学习笔记21-自定义首页添加对话服务
自定义首页添加对话服务 定义接口与实现 添加自定义添加对话框接口 添加文件:Mytodo.Dialog.IDialogHostAware.cs using Prism.Commands; using Prism.Services.Dialogs; using System; using System.Collections.Generic; using System.Linq; using System.Tex…...
)
AngularJS学习(一)
目录 1. 引入 AngularJS2. 创建一个 AngularJS 应用3. 控制器(Controller)4. 模型(Model)5. 视图(View)6. 指令(Directive)7. 过滤器(Filter)8. 服务…...

918. 环形子数组的最大和
918. 环形子数组的最大和 给定一个长度为 n 的环形整数数组 nums ,返回 nums 的非空 子数组 的最大可能和 。 环形数组 意味着数组的末端将会与开头相连呈环状。形式上, nums[i] 的下一个元素是 nums[(i 1) % n] , nums[i] 的前一个元素是…...

AI算法图形化编程加持|OPT(奥普特)智能相机轻松适应各类检测任务
OPT(奥普特)基于SciVision视觉开发包,全新推出多功能一体化智能相机,采用图形化编程设计,操作简单、易用;不仅有上百种视觉检测算法加持,还支持深度学习功能,能轻松应对计数、定位、…...

C语言文件指针设置偏移量--fseek
一、fseek fseek是设置文件指针偏移量的函数,具体传参格式为: int fseek(FILE *stream, long int offset, int whence) 返回一个整数,其中: 1、stream是指向文件的指针 2、offset是偏移量,一般是指相对于whence的便…...
快速消除视频的原声的技巧分享
网络上下载的视频都会有视频原声或者背景音乐,如果不喜欢并且想更换新的BGM要怎么操作呢?今天小编就来教你如何快速给多个视频更换新的BGM,很简单,只需要将原视频的原声快速消音同时添加新的背景音频就行,一起来看看详…...

3.2 系统是能力的容器,不是能力的创造者
系列文章:《组织基因、利益格局与系统驱动——数字化变革的底层逻辑》 上一节我们讲了公司花了不少钱做研发,但系统最后用成了工具。这一节,我们来回答一个更根本的问题:系统到底是什么? 很多人对系统有一个误解&…...

卡梅德生物技术快报|多肽库筛选:基于全质粒 PCR 的噬菌体文库构建与小分子表位淘选实战
正文摘要本文面向生物研发、实验技术、噬菌体展示方向开发者,系统讲解多肽库筛选完整流程:从问题分析、瓶颈定位、实验方案设计到质控与结果输出,提供可复现的技术方案与关键参数。内容基于真实学位论文研究,聚焦高库容、高多样性…...

5月最新10款降AI神器实测:哪个能降知网维普AI率,从99.5%降至3.8%可信吗?
2025 年 12 月 25 日知网 AIGC 检测系统升级,2026 年 4 月 27 日维普 AI 率检测平台升级…2026 毕业季,各大主流 AIGC 检测软件陆续升级系统,识别 AI 痕迹更加精准。 临近毕业,同学们看者飘红的 AIGC 检测报告、纷繁复杂的降 AI 系…...

Borderless Gaming终极指南:三步搞定无缝游戏窗口切换的魔法
Borderless Gaming终极指南:三步搞定无缝游戏窗口切换的魔法 【免费下载链接】Borderless-Gaming Play your favorite games in a borderless window; no more time consuming alt-tabs. 项目地址: https://gitcode.com/gh_mirrors/bo/Borderless-Gaming 你…...

CANN/pypto填充操作API
pypto.pad 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品/Atla…...

边缘AI闭环数控系统:基于IIoT的轻量级CNC智能改造实践
1. 项目概述:这不是在改装一台机床,而是在给金属切削装上“神经系统”“AI-Driven Machining: Building a Closed-Loop CNC System with IIoT Feedback (Building the CNC)”——这个标题里没有一个词是虚的。它不是讲怎么用AI生成G代码,也不…...

k-Mode聚类算法原理与手写实现:专治分类数据的无监督学习利器
1. 项目概述:为什么k-Mode不是k-Means的“换皮版”,而是一把专治分类数据的手术刀你有没有遇到过这样的场景:手头有一批客户数据,字段全是“性别:男/女”、“城市:北京/上海/广州”、“会员等级:…...

群晖SSH远程访问全链路打通指南
1. 为什么群晖的SSH不是“开个开关”就完事的很多人第一次在群晖DSM界面里点开“控制面板 > 终端机和SNMP > 启用SSH服务”,看到端口22打钩、状态显示“已启用”,就以为大功告成,兴冲冲拿Mac或Windows的终端连一下——结果ssh admin192…...

Unity UGUI三大Layout Group核心原理与工程实践
1. 为什么这三个Layout Group是Unity UI开发的“地基级”组件,而不是可有可无的装饰品?在Unity里做UI,很多人第一反应是拖控件、调锚点、手动改RectTransform——这就像盖房子不打地基,先砌墙再想承重。我带过十几期新人训练营&am…...

如何快速掌握拯救者工具箱:联想笔记本性能调校终极指南
如何快速掌握拯救者工具箱:联想笔记本性能调校终极指南 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit 还在为联…...