医疗知识图谱问答——文本分类解析
前言
Neo4j的数据库构建完成后,现在就是要实现医疗知识的解答功能了。因为是初版,这里的问题解答不会涉及深度学习,目前只是一个条件查询的过程。而这个过程包括对问题的关键词拆解分类,然后提取词语和类型去图数据库查询,最后就是根据查询结果和问题类型组装语言完成回答,那么以下就是完成这个过程的全部代码流程了。
环境
这里所需的环境除了前面提到的外,还需要ahocorasick库,用于从问题中提取关键词。另一个是colorama,用于给输出面板文字美化的库。
编码
1. 问答面板
from colorama import init,Fore,Style,Back
from classifier import Classifier
from parse import Parse
from answer import Answerclass ChatRobot:def __init__(self):init(autoreset=True)print("====================================")print(Back.BLUE+"欢迎进入智慧医疗问答面板!")print("====================================")def main(self, question):print("")default_answer = "您好,小北知识有限,暂时回答不上来,正在努力迭代中!"final_classify = Classifier().classify(question)parse_sql = Parse().main(final_classify)final_answer = Answer().main(parse_sql)if not final_answer:return default_answerreturn "\n\n".join(final_answer)if __name__ == "__main__":robot = ChatRobot()while 1:print(" ")question = input("您问:")if "关闭" in question:print("")print("小北说:", "好的,已经关闭了哦,欢迎您下次提问~")break;answer = robot.main(question)print(Fore.LIGHTRED_EX+"小北答:", Fore.GREEN + answer)2. 问题归类
import ahocorasickclass Classifier:def __init__(self):# print("开始初始化:", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))self.checks_wds = [i.strip() for i in open("dict/checks.txt", encoding="utf-8", mode="r") if i.strip()]self.departments_wds = [i.strip() for i in open("dict/departments.txt", encoding="utf-8", mode="r") if i.strip()]self.diseases_wds = [i.strip() for i in open("dict/diseases.txt", encoding="utf-8", mode="r") if i.strip()]self.drugs_wds = [i.strip() for i in open("dict/drugs.txt", encoding="utf-8", mode="r") if i.strip()]self.foods_wds = [i.strip() for i in open("dict/foods.txt", encoding="utf-8", mode="r") if i.strip()]self.producers_wds = [i.strip() for i in open("dict/producers.txt", encoding="utf-8", mode="r") if i.strip()]self.symptoms_wds = [i.strip() for i in open("dict/symptoms.txt", encoding="utf-8", mode="r") if i.strip()]self.features_wds = set(self.checks_wds+self.departments_wds+self.diseases_wds+self.drugs_wds+self.foods_wds+self.producers_wds+self.symptoms_wds)self.deny_words = [name.strip() for name in open("dict/deny.txt", encoding="utf-8", mode="r") if name.strip()]# actree 从输入文本中提取出指定分词表中的词self.actree = self.build_actree(list(self.features_wds))# 给每个词创建类型词典(相当慢的操作)self.wds_dict = self.build_words_dict()# print("给每个词创建类型词典结束:", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))# 问句疑问词self.symptom_qwds = ['症状', '表征', '现象', '症候', '表现']self.cause_qwds = ['原因', '成因', '为什么', '怎么会', '怎样才', '咋样才', '怎样会', '如何会', '为啥', '为何', '如何才会', '怎么才会', '会导致','会造成']self.acompany_qwds = ['并发症', '并发', '一起发生', '一并发生', '一起出现', '一并出现', '一同发生', '一同出现', '伴随发生', '伴随', '共现']self.food_qwds = ['饮食', '饮用', '吃', '食', '伙食', '膳食', '喝', '菜', '忌口', '补品', '保健品', '食谱', '菜谱', '食用', '食物', '补品']self.drug_qwds = ['药', '药品', '用药', '胶囊', '口服液', '炎片']self.prevent_qwds = ['预防', '防范', '抵制', '抵御', '防止', '躲避', '逃避', '避开', '免得', '逃开', '避开', '避掉', '躲开', '躲掉', '绕开','怎样才能不', '怎么才能不', '咋样才能不', '咋才能不', '如何才能不','怎样才不', '怎么才不', '咋样才不', '咋才不', '如何才不','怎样才可以不', '怎么才可以不', '咋样才可以不', '咋才可以不', '如何可以不','怎样才可不', '怎么才可不', '咋样才可不', '咋才可不', '如何可不']self.lasttime_qwds = ['周期', '多久', '多长时间', '多少时间', '几天', '几年', '多少天', '多少小时', '几个小时', '多少年']self.cureway_qwds = ['怎么治疗', '如何医治', '怎么医治', '怎么治', '怎么医', '如何治', '医治方式', '疗法', '咋治', '怎么办', '咋办', '咋治']self.cureprob_qwds = ['多大概率能治好', '多大几率能治好', '治好希望大么', '几率', '几成', '比例', '可能性', '能治', '可治', '可以治', '可以医']self.easyget_qwds = ['易感人群', '容易感染', '易发人群', '什么人', '哪些人', '感染', '染上', '得上']self.check_qwds = ['检查', '检查项目', '查出', '检查', '测出', '试出']self.belong_qwds = ['属于什么科', '属于', '什么科', '科室']self.cure_qwds = ['治疗什么', '治啥', '治疗啥', '医治啥', '治愈啥', '主治啥', '主治什么', '有什么用', '有何用', '用处', '用途','有什么好处', '有什么益处', '有何益处', '用来', '用来做啥', '用来作甚', '需要', '要']'''构造actree,加速过滤'''def build_actree(self, wordlist):actree = ahocorasick.Automaton()for index, word in enumerate(wordlist):actree.add_word(word, (index, word))actree.make_automaton()return actree# 构建特征词属性def build_words_dict(self):words_dict = {}check_words = set(self.checks_wds)department_words = set(self.departments_wds)disease_words = set(self.diseases_wds)drug_words = set(self.drugs_wds)food_words = set(self.foods_wds)producer_words = set(self.producers_wds)symptom_words = set(self.symptoms_wds)for word in self.features_wds:words_dict[word] = []if word in check_words:words_dict[word].append("check")if word in department_words:words_dict[word].append("department")if word in disease_words:words_dict[word].append("disease")if word in drug_words:words_dict[word].append("drug")if word in food_words:words_dict[word].append("food")if word in producer_words:words_dict[word].append("producer")if word in symptom_words:words_dict[word].append("symptom")return words_dict# 根据输入返回问题类型def classify(self, sent):# 最终输入给解析器的字典data = {}region_words = []lists = self.actree.iter(sent)for ii in lists:cur_word = ii[1][1]region_words.append(cur_word)# {'职业黑变病': ['diseases'], '倒睫': ['diseases', 'symptom']}final_dict = {i_name: self.wds_dict.get(i_name) for i_name in region_words}data['args'] = final_dictquestion_type = "other"questions_type = []# ['diseases', 'diseases', 'symptom']type = []for i_type in final_dict.values():type += i_type# 判断type中是否有指定类型, 提出的问题是否包含指定的修饰词,给问题定类型# 1. 如提问词是否出现状态词语,那就是问某种疾病会出现什么症状if self.check_word_exist(self.symptom_qwds, sent) and ('disease' in type):question_type = "disease_symptom"questions_type.append(question_type)# 根据症状问疾病if self.check_word_exist(self.symptom_qwds, sent) and ('symptom' in type):question_type = "symptom_disease"questions_type.append(question_type)# 原因if self.check_word_exist(self.cause_qwds, sent) and ('disease' in type):question_type = 'disease_cause'questions_type.append(question_type)# 并发症if self.check_word_exist(self.acompany_qwds, sent) and ('disease' in type):question_type = 'disease_acompany'questions_type.append(question_type)# 推荐食品if self.check_word_exist(self.food_qwds, sent) and 'disease' in type:deny_status = self.check_word_exist(self.deny_words, sent)if deny_status:question_type = 'disease_not_food'else:question_type = 'disease_do_food'questions_type.append(question_type)# 已知食物找疾病if self.check_word_exist(self.food_qwds + self.cure_qwds, sent) and 'food' in type:deny_status = self.check_word_exist(self.deny_words, sent)if deny_status:question_type = 'food_not_disease'else:question_type = 'food_do_disease'questions_type.append(question_type)# 推荐药品if self.check_word_exist(self.drug_qwds, sent) and 'disease' in type:question_type = 'disease_drug'questions_type.append(question_type)# 药品治啥病if self.check_word_exist(self.cure_qwds, sent) and 'drug' in type:question_type = 'drug_disease'questions_type.append(question_type)# 疾病接受检查项目if self.check_word_exist(self.check_qwds, sent) and 'disease' in type:question_type = 'disease_check'questions_type.append(question_type)# 已知检查项目查相应疾病if self.check_word_exist(self.check_qwds + self.cure_qwds, sent) and 'check' in type:question_type = 'check_disease'questions_type.append(question_type)# 症状防御if self.check_word_exist(self.prevent_qwds, sent) and 'disease' in type:question_type = 'disease_prevent'questions_type.append(question_type)# 疾病医疗周期if self.check_word_exist(self.lasttime_qwds, sent) and 'disease' in type:question_type = 'disease_lasttime'questions_type.append(question_type)# 疾病治疗方式if self.check_word_exist(self.cureway_qwds, sent) and 'disease' in type:question_type = 'disease_cureway'questions_type.append(question_type)# 疾病治愈可能性if self.check_word_exist(self.cureprob_qwds, sent) and 'disease' in type:question_type = 'disease_cureprob'questions_type.append(question_type)# 疾病易感染人群if self.check_word_exist(self.easyget_qwds, sent) and 'disease' in type:question_type = 'disease_easyget'questions_type.append(question_type)# 若没有查到相关的外部查询信息,那么则将该疾病的描述信息返回if questions_type == [] and 'disease' in type:questions_type = ['disease_desc']# 若没有查到相关的外部查询信息,那么则将该疾病的描述信息返回if questions_type == [] and 'symptom' in type:questions_type = ['symptom_disease']# 将多个分类结果进行合并处理,组装成一个字典data['question_types'] = questions_typereturn datadef check_word_exist(self, word_list, words):for item in word_list:if item in words:return Truereturn False
3. 类型解析(查询组装)
class Parse:def main(self, classify):entity = classify['args']questions_type = classify['question_types']entity_dict = self.entity_transform(entity)sqls = []for question in questions_type:sql_dict = {}sql_dict["qustion_type"] = questionsql_dict["sql"] = []sql = []if question == 'disease_symptom':sql = self.sql_transfer(question, entity_dict.get('disease'))elif question == 'symptom_disease':sql = self.sql_transfer(question, entity_dict.get('symptom'))elif question == 'disease_cause':sql = self.sql_transfer(question, entity_dict.get('disease'))elif question == 'disease_acompany':sql = self.sql_transfer(question, entity_dict.get('disease'))elif question == 'disease_not_food':sql = self.sql_transfer(question, entity_dict.get('disease'))elif question == 'disease_do_food':sql = self.sql_transfer(question, entity_dict.get('disease'))elif question == 'food_not_disease':sql = self.sql_transfer(question, entity_dict.get('food'))elif question == 'food_do_disease':sql = self.sql_transfer(question, entity_dict.get('food'))elif question == 'disease_drug':sql = self.sql_transfer(question, entity_dict.get('disease'))elif question == 'drug_disease':sql = self.sql_transfer(question, entity_dict.get('drug'))elif question == 'disease_check':sql = self.sql_transfer(question, entity_dict.get('disease'))elif question == 'check_disease':sql = self.sql_transfer(question, entity_dict.get('check'))elif question == 'disease_prevent':sql = self.sql_transfer(question, entity_dict.get('disease'))elif question == 'disease_lasttime':sql = self.sql_transfer(question, entity_dict.get('disease'))elif question == 'disease_cureway':sql = self.sql_transfer(question, entity_dict.get('disease'))elif question == 'disease_cureprob':sql = self.sql_transfer(question, entity_dict.get('disease'))elif question == 'disease_easyget':sql = self.sql_transfer(question, entity_dict.get('disease'))elif question == 'disease_desc':sql = self.sql_transfer(question, entity_dict.get('disease'))if sql:sql_dict['sql'] = sqlsqls.append(sql_dict)return sqlsdef sql_transfer(self, question_type, entities):# 查询语句sql = []# 查询疾病的原因if question_type == 'disease_cause':sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.cause".format(i) for i in entities]# 查询疾病的防御措施elif question_type == 'disease_prevent':sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.prevent".format(i) for i in entities]# 查询疾病的持续时间elif question_type == 'disease_lasttime':sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.cure_lasttime".format(i) for i in entities]# 查询疾病的治愈概率elif question_type == 'disease_cureprob':sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.cured_prob".format(i) for i in entities]# 查询疾病的治疗方式elif question_type == 'disease_cureway':sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.cure_way".format(i) for i in entities]# 查询疾病的易发人群elif question_type == 'disease_easyget':sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.easy_get".format(i) for i in entities]# 查询疾病的相关介绍elif question_type == 'disease_desc':sql = ["MATCH (m:Diseases) where m.name = '{0}' return m.name, m.desc".format(i) for i in entities]# 查询疾病有哪些症状elif question_type == 'disease_symptom':sql = ["MATCH (m:Diseases)-[r:has_symptoms]->(n:Symptoms) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]# 查询症状会导致哪些疾病elif question_type == 'symptom_disease':sql = ["MATCH (m:Diseases)-[r:has_symptoms]->(n:Symptoms) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]# 查询疾病的并发症elif question_type == 'disease_acompany':sql1 = ["MATCH (m:Diseases)-[r:acompany_with]->(n:Symptoms) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]sql2 = ["MATCH (m:Diseases)-[r:acompany_with]->(n:Symptoms) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]sql = sql1 + sql2# 查询疾病的忌口elif question_type == 'disease_not_food':sql = ["MATCH (m:Diseases)-[r:not_eat]->(n:Foods) where m.name = '{0}' return m.name, r.name, n.name".format(i)for i in entities]# 查询疾病建议吃的东西elif question_type == 'disease_do_food':sql1 = ["MATCH (m:Diseases)-[r:do_eat]->(n:Foods) where m.name = '{0}' return m.name, r.name, n.name".format(i)for i in entities]sql2 = ["MATCH (m:Diseases)-[r:recomment_eat]->(n:Foods) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]sql = sql1 + sql2# 已知忌口查疾病elif question_type == 'food_not_disease':sql = ["MATCH (m:Diseases)-[r:not_eat]->(n:Foods) where n.name = '{0}' return m.name, r.name, n.name".format(i)for i in entities]# 已知推荐查疾病elif question_type == 'food_do_disease':sql1 = ["MATCH (m:Diseases)-[r:do_eat]->(n:Foods) where n.name = '{0}' return m.name, r.name, n.name".format(i)for i in entities]sql2 = ["MATCH (m:Diseases)-[r:recomment_eat]->(n:Foods) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]sql = sql1 + sql2# 查询疾病常用药品-药品别名记得扩充elif question_type == 'disease_drug':sql1 = ["MATCH (m:Diseases)-[r:common_drug]->(n:Drugs) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]sql2 = ["MATCH (m:Diseases)-[r:recommand_drug]->(n:Drugs) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]sql = sql1 + sql2# 已知药品查询能够治疗的疾病elif question_type == 'drug_disease':sql1 = ["MATCH (m:Diseases)-[r:common_drug]->(n:Drugs) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]sql2 = ["MATCH (m:Diseases)-[r:recommand_drug]->(n:Drugs) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]sql = sql1 + sql2# 查询疾病应该进行的检查elif question_type == 'disease_check':sql = ["MATCH (m:Diseases)-[r:need_check]->(n:Checks) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]# 已知检查查询疾病elif question_type == 'check_disease':sql = ["MATCH (m:Diseases)-[r:need_check]->(n:Checks) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]return sqldef entity_transform(self, entity):entity_dict = {}for args, types in entity.items():for type in types:if type in entity_dict:entity_dict[type] = [args]else:entity_dict[type] = []entity_dict[type].append(args)return entity_dict4. 数据查询(回答组装)
from py2neo import Graph, Nodeclass Answer:def __init__(self):self.neo4j = Graph('bolt://localhost:7687', auth=('neo4j', 'beiqiaosu123456'))self.num_limit = 20def main(self, question_parse):answers_final = []for item in question_parse:question_type = item['qustion_type']sqls = item['sql']answer = []for sql in sqls:data = self.neo4j.run(sql)answer+=data.data()final_answer = self.answer_prettify(question_type, answer)if final_answer:answers_final.append(final_answer)return answers_final'''根据对应的qustion_type,调用相应的回复模板'''def answer_prettify(self, question_type, answers):final_answer = []if not answers:return ''if question_type == 'disease_symptom':desc = [i['n.name'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}的症状包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'symptom_disease':desc = [i['m.name'] for i in answers]subject = answers[0]['n.name']final_answer = '症状{0}可能染上的疾病有:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_cause':desc = [i['m.cause'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}可能的成因有:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_prevent':desc = [i['m.prevent'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}的预防措施包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_lasttime':desc = [i['m.cure_lasttime'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}治疗可能持续的周期为:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_cureway':desc = [';'.join(i['m.cure_way']) for i in answers]subject = answers[0]['m.name']final_answer = '{0}可以尝试如下治疗:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_cureprob':desc = [i['m.cured_prob'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}治愈的概率为(仅供参考):{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_easyget':desc = [i['m.easy_get'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}的易感人群包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_desc':desc = [i['m.desc'] for i in answers]subject = answers[0]['m.name']final_answer = '{0},熟悉一下:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_acompany':desc1 = [i['n.name'] for i in answers]desc2 = [i['m.name'] for i in answers]subject = answers[0]['m.name']desc = [i for i in desc1 + desc2 if i != subject]final_answer = '{0}的症状包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_not_food':desc = [i['n.name'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}忌食的食物包括有:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_do_food':do_desc = [i['n.name'] for i in answers if i['r.name'] == '可以吃']recommand_desc = [i['n.name'] for i in answers if i['r.name'] == '推荐吃']subject = answers[0]['m.name']final_answer = '{0}宜食的食物包括有:{1}\n推荐食谱包括有:{2}'.format(subject, ';'.join(list(set(do_desc))[:self.num_limit]),';'.join(list(set(recommand_desc))[:self.num_limit]))elif question_type == 'food_not_disease':desc = [i['m.name'] for i in answers]subject = answers[0]['n.name']final_answer = '患有{0}的人最好不要吃{1}'.format(';'.join(list(set(desc))[:self.num_limit]), subject)elif question_type == 'food_do_disease':desc = [i['m.name'] for i in answers]subject = answers[0]['n.name']final_answer = '患有{0}的人建议多试试{1}'.format(';'.join(list(set(desc))[:self.num_limit]), subject)elif question_type == 'disease_drug':desc = [i['n.name'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}通常的使用的药品包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'drug_disease':desc = [i['m.name'] for i in answers]subject = answers[0]['n.name']final_answer = '{0}主治的疾病有{1},可以试试'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'disease_check':desc = [i['n.name'] for i in answers]subject = answers[0]['m.name']final_answer = '{0}通常可以通过以下方式检查出来:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))elif question_type == 'check_disease':desc = [i['m.name'] for i in answers]subject = answers[0]['n.name']final_answer = '通常可以通过{0}检查出来的疾病有{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))return final_answer
写在最后
以上就是这个医疗知识问答机器人的全部代码了,从上面的问答里也能看出,回答得还是很生硬。因为这就只是一个程序化得思维导图,所以修改完善空间还是很大,这个就要后期用深度学习得方式对分类解析部分进行改动。
相关文章:
医疗知识图谱问答——文本分类解析
前言 Neo4j的数据库构建完成后,现在就是要实现医疗知识的解答功能了。因为是初版,这里的问题解答不会涉及深度学习,目前只是一个条件查询的过程。而这个过程包括对问题的关键词拆解分类,然后提取词语和类型去图数据库查询…...

JS关于多张图片上传显示报错不影响后面图片上传方法
关于多张图片上传或者下载显示报错后会程序会终止执行,从而影响后面图片上传。 解决方法: /*能正常访问的图片*/ const url https://2vimg.hitv.com/100/2308/0109/5359/dqKIZ7d4cnHL/81Vu0c.jpg?x-oss-processimage/format,webp; /*不能正常下载的图…...

MySQL踩坑之sql_mode的用法
目录 定义 报错重现 编辑 原因分析 sql_mode值说明 查看当前sql_mode 设置sql_mode 定义 什么是sql_mode?玩了这么久的MySQL语句...
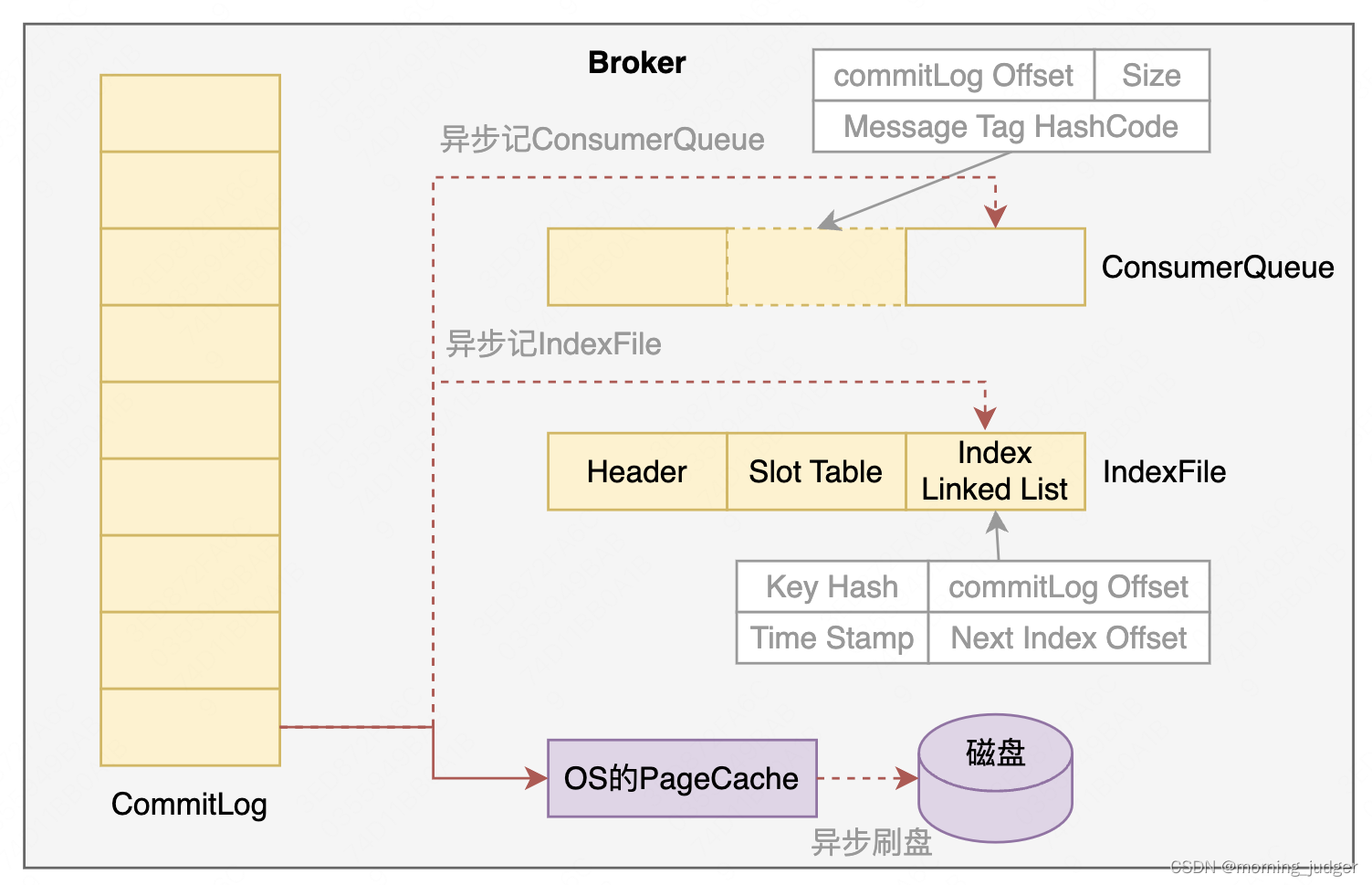
消息队列总结(4)- RabbitMQ Kafka RocketMQ高性能方案
1.RabbitMQ的高性能解决方案 1.1 发布确认机制 RabbitMQ提供了3种生产者发布确认的模式: 简单模式(Simple Mode):生产者发送消息后,等待服务器确认消息已经被接收。这种模式下,生产者发送消息后会阻塞&am…...
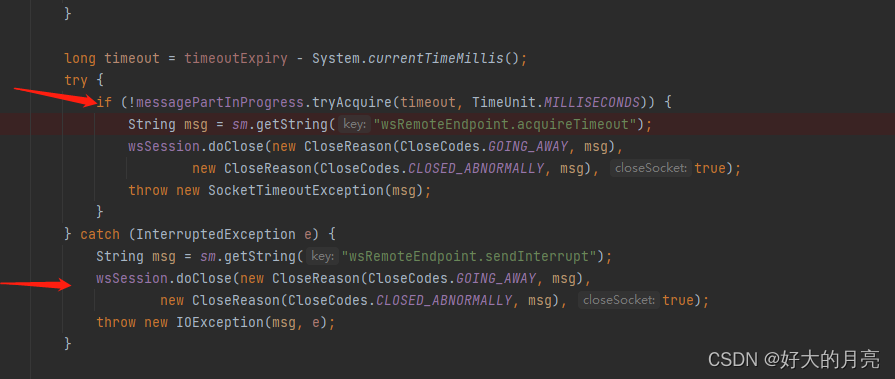
websocket服务端大报文发送连接自动断开分析
概述 当前springboot版本:2.7.4 使用依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dependency>现象概述: 客户端和服务端已经有心跳…...
想写几个上位机,是选择学c#还是 c++ qt呢?
C#基本也就上位机开发开发,另外做做日常用的小工具很方便。 结合PLC,以太网做上位机,这个基本上控制这块都比较有需求。 另外我们用C#也做一些工具的二次开发,感觉还行。 C用qt框架其实学习起来可能稍微复杂些,但是…...

JavaScript 简单实现观察者模式和发布-订阅模式
JavaScript 简单实现观察者模式和发布-订阅模式 1. 观察者模式1.1 什么是观察者模式1.2 代码实现 2. 发布-订阅模式2.1 什么是发布-订阅模式2.2 代码实现2.2.1 基础版2.2.2 取消订阅2.2.3 订阅一次 1. 观察者模式 1.1 什么是观察者模式 概念:观察者模式定义对象间…...
java集成短信服务 测试版 qq邮箱简单思路
java集成短信服务 注册一个帐号 使用的是容联云,百度搜一下官网 用手机注册一个帐号就行,免费体验不需要认证 注册后会有八块钱送,可以使用免费的给自己设置三个固定手机号发送短信,不需要认证。 此页面的 三个信息需要在代码中…...
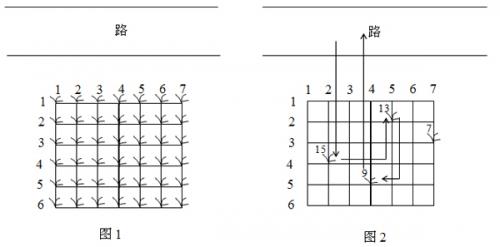
#P0994. [NOIP2004普及组] 花生采摘
题目描述 鲁宾逊先生有一只宠物猴,名叫多多。这天,他们两个正沿着乡间小路散步,突然发现路边的告示牌上贴着一张小小的纸条:“欢迎免费品尝我种的花生!――熊字”。 鲁宾逊先生和多多都很开心,因为花生正…...
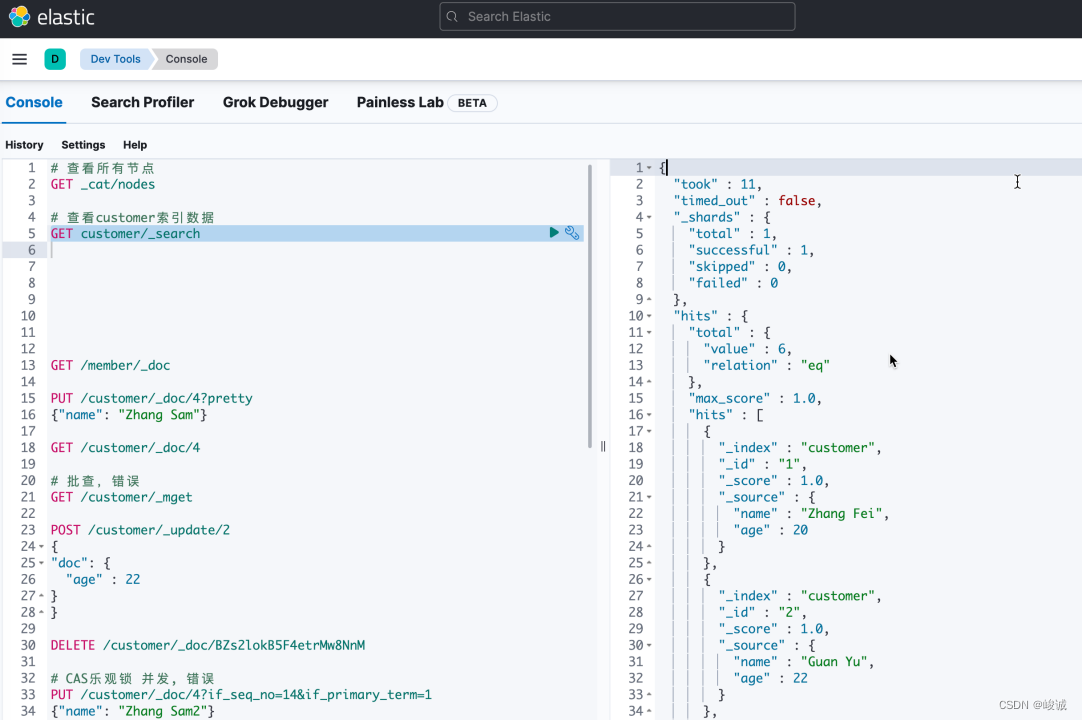
Elasticsearch和Kibana的安装及验证
金翅大鹏盖世英,展翅金鹏盖世雄。 穿云燕子锡今鸽,踏雪无痕花云平。 ---------------- 2023.7.31.101 ----------------- 本文密钥:365 Elasticsearch 是一个分布式的 RESTful 风格的搜索和数据分析引擎,常用来进行全文检索、…...
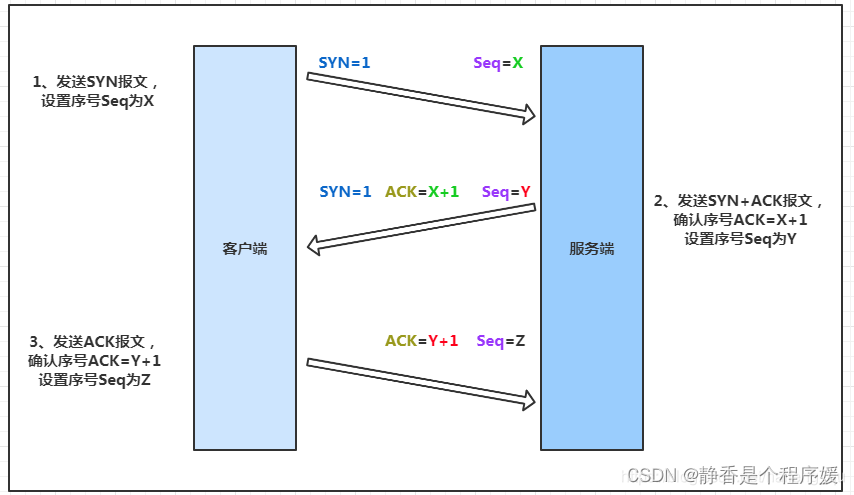
细讲TCP三次握手四次挥手(一)
计算机网络体系结构 在计算机网络的基本概念中,分层次的体系结构是最基本的。计算机网络体系结构的抽象概念较多,在学习时要多思考。这些概念对后面的学习很有帮助。 网络协议是什么? 在计算机网络要做到有条不紊地交换数据,就必…...

【linux-zabbix】zabbix-agent启动报错:Daemon never wrote its PID file. Failing.
背景: 发现有部分的agent失联,排查发现机器正常,agent没起来。 排查日志发现: # journalctl -xe -- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel -- -- Unit zabbix-agent.service has begun start…...

【微信小程序】初始化 wxCharts,调用updateData动态更新数据
要初始化 wxCharts,你需要按照以下步骤进行操作: 首先,确保已将 wx-charts.js 文件正确引入到小程序的相应页面或组件中。可以通过以下方式引入: const wxCharts require(../../../../components/wx-charts.js);请根据你的项目…...

【C语言初阶(19)】实用的 VS 调试技巧
文章目录 Ⅰ 调试的介绍Ⅱ 常用调试快捷键Ⅲ 调试的时候查看程序当前信息⒈查看临时变量的值⒉查看内存信息⒊查看调用堆栈⒋查看汇编信息⒌查看寄存器信息 Ⅳ 观察形参指针指向的数组Ⅴ 易于调试的代码该如何编写⒈const 修饰指针变量⒉良好代码示范 Ⅵ 编程中常见的错误 Ⅰ 调…...

虚拟机之间配置免密登录
目录 一、配置主机名映射 二、虚拟机配置SSH免密登录 三、验证 一、配置主机名映射 即修改/etc/hosts文件,将几台服务器和主机名进行映射。 注意每台服务器都要进行同样的配置。这样在各自服务器下,我们就可以通过主机名访问对应的ip地址了。 当然&…...
【contenteditable属性将元素改为可编辑状态】
元素添加contenteditable属性之后点击即可进入编辑状态 像这种只修改一条属性不必再打开弹框进行编辑,使用contenteditable会很方便 添加失焦、回车、获焦事件 如 <p :contenteditable"item.contenteditable || false"keydown.enter"key($event…...

Android 第三方库CalendarView
Android 第三方库CalendarView 根据需求和库的使用方式,自己弄了一个合适自己的日历,仅记录下,方便下次弄其他样式的日历。地址 需求: 只显示当月的数据 默认的月视图有矩形的线 选中的天数也要有选中的矩形框 今天的item需要…...
钉钉群消息推送
1. 添加钉钉群机器人 PC端登录(当前版本手机端无法进行推送关键词设置),群设置--> 机器人 --> webhook进行安全设置复制webhook对应的url 2. 群消息推送 钉钉群消息支持纯文本和markdown类型 2.1 调用示例源码 import com.alibaba.…...

css clip-path 属性介绍
circle() – 圆 语法:circle( [<shape-radius>]? [at <position>]? ) shape-radius 圆的半径 position 圆的中心点位置 使用方法: clip-path: circle(); // 以元素的中心点为圆的中心点,最小宽度一半为圆的半径。clip-path: c…...
Python之pyinstaller打包exe填坑总结
一、起因 编写了一个提取图片中文字的python脚本,想传给同事使用,但是同事电脑上没有任何python环境,更没有安装python库,因此想到通过pyinstaller打包成exe程序传给同事使用,于是开始了不断地挖坑填坑之旅 import p…...

Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南
Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南 【免费下载链接】Qwen3-Coder-30B-A3B-Instruct-FP8 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 在当今AI代码生成领域,Qwen3-Coder-30B-…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案
WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案 【免费下载链接】wtfautolayout The source code for Why The Failure, Auto Layout? 项目地址: https://gitcode.com/gh_mirrors/wt/wtfautolayout 在iOS开发中,Auto Layout是构建灵…...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...
用Azure Kinect DK和Body Tracking SDK,5分钟实现一个实时人体骨骼点检测Demo(C++版)
5分钟实战:用Azure Kinect DK实现实时人体骨骼点追踪(C版) 当你第一次拿到Azure Kinect DK时,最令人兴奋的莫过于它强大的人体追踪能力。这款深度相机不仅能捕捉高清彩色图像,更能通过AI算法实时重建人体骨骼关节点。本…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...

NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台
NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft世界文件…...

避坑指南:Unity中AABB碰撞检测失效的5种常见原因及解决方法
Unity中AABB碰撞检测失效的深度排查与解决方案在Unity开发中,AABB(轴对齐包围盒)碰撞检测是基础但容易出问题的环节。许多开发者都遇到过这样的情况:明明逻辑正确,测试时却出现物体穿透、碰撞时有时无等诡异现象。本文…...

解锁你的音乐收藏:浏览器端音频解密完整指南
解锁你的音乐收藏:浏览器端音频解密完整指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gitcod…...