Python web实战之 Django 的 ORM 框架详解
本文关键词:Python、Django、ORM。
概要
在 Python Web 开发中,ORM(Object-Relational Mapping,对象关系映射)是一个非常重要的概念。ORM 框架可以让我们不用编写 SQL 语句,就能够使用对象的方式来操作数据库,大大提高了代码的可读性和可维护性。Django 作为一款流行的 Web 框架,自带了强大的 ORM 框架。
本文将会详细介绍 Django 的 ORM 框架,包括基本使用方法、高级查询、性能优化等方面。
1. 基本使用方法
1.1 定义模型类
在 Django 里可以使用模型类来定义数据库表。模型类需要继承自 django.db.models.Model,并且定义表的各个字段。例如,下面是一个简单的模型类,用来表示一个博客文章:
from django.db import modelsclass Blog(models.Model):title = models.CharField(max_length=100)content = models.TextField()pub_date = models.DateTimeField(auto_now_add=True)
上面的代码定义了一个 Blog 类来表示博客文章。这个类继承自 django.db.models.Model,并且定义了三个字段:标题、内容和发布日期。其中,标题和内容都是字符串类型,使用 CharField 和 TextField 来定义。pub_date 是一个日期时间类型,使用 DateTimeField 来定义。auto_now_add=True 表示在创建新记录时自动设置为当前时间。
1.2 创建表
定义完模型类之后,我们需要创建对应的数据库表。在 Django 中,可以使用 manage.py 命令来进行数据库迁移操作。具体来说,我们需要执行以下两个命令:
# 生成迁移文件
python manage.py makemigrations# 执行迁移操作
python manage.py migrate
执行完上面的两个命令之后,Django 会根据模型类自动生成对应的数据库表。
注意:在进行迁移操作之前,请确保已经仔细确认了所有相关设置和代码,并且备份了数据。
1.3 插入数据
插入数据可以使用模型类来表示一条记录,并且调用 save() 方法来将记录保存到数据库中。例如,下面的代码演示了如何向 Blog 表中插入一条记录:
blog = Blog(title='Hello World', content='This is my first blog post.')
blog.save()
1.4 查询数据
查询数据可以使用模型类的 objects 属性,该属性是 Manager 类的实例,提供了各种查询方法。例如从 Blog 表中查询所有记录:
blogs = Blog.objects.all()for blog in blogs:print(blog.title, blog.content, blog.pub_date)
1.5 更新数据
更新数据可以先查询出需要更新的记录,然后修改对应的字段,最后调用 save() 方法进行保存。例如将 Blog 表中所有记录的标题修改为 'Hello Django':
blogs = Blog.objects.all()for blog in blogs:blog.title = 'Hello Django'blog.save()
1.6 删除数据
删除数据可以先查询出需要删除的记录,然后调用 delete() 方法进行删除。例如删除 Blog 表中所有记录:
blogs = Blog.objects.all()for blog in blogs:blog.delete()
2. 高级查询
2.1 条件查询
Django 的 ORM 框架提供了非常方便的条件查询功能。例如查询 Blog 表中标题为 'Hello World' 的记录:
blogs = Blog.objects.filter(title='Hello World')for blog in blogs:print(blog.title, blog.content,blog.pub_date)
可以看到,我们使用了 filter() 方法来指定查询条件,其中 title='Hello World' 表示标题等于 'Hello World'。filter() 方法返回一个 QuerySet 对象,可以使用 for 循环遍历查询结果。
2.2 聚合查询
聚合查询可以使用 aggregate() 方法来实现。例如统计 Blog 表中记录的数量:
from django.db.models import Countcount = Blog.objects.aggregate(Count('id'))
print(count['id__count'])
可以看到,我们使用了 aggregate() 方法来指定聚合操作,其中 Count('id') 表示统计 id 字段的数量。aggregate() 方法返回一个字典,其中键是聚合操作的名称(例如,id__count 表示统计数量),值是聚合操作的结果。
2.3 连接查询
连接查询可以使用 select_related() 方法和 prefetch_related() 方法来实现。例如,下面的代码演示了如何查询 Blog 表中的记录,并且同时连接查询关联的 Author 表中的作者信息:
class Author(models.Model):name = models.CharField(max_length=50)class Blog(models.Model):title = models.CharField(max_length=100)content = models.TextField()pub_date = models.DateTimeField(auto_now_add=True)author = models.ForeignKey(Author, on_delete=models.CASCADE)blogs = Blog.objects.select_related('author')for blog in blogs:print(blog.title, blog.content, blog.pub_date, blog.author.name)
可以看到,我们使用了 select_related('author') 方法来指定需要连接查询的外键字段(即 author 字段),这样就可以同时查询 Blog 表和 Author 表中的数据。注意,select_related() 方法只能用于一对一和多对一关系的查询,上面的例子是多对一关系。
2.4 原生 SQL 查询
Django 的 ORM 框架也支持原生 SQL 查询。例如使用原生 SQL 查询 Blog 表中的记录:
from django.db import connectionwith connection.cursor() as cursor:cursor.execute("SELECT * FROM myapp_blog")blogs = cursor.fetchall()for blog in blogs:print(blog[1], blog[2], blog[3])
可以看到,我们使用了 connection.cursor() 方法来获取数据库连接的游标,然后调用 execute() 方法执行 SQL 查询。最后,使用 fetchall() 方法获取查询结果。
3. 性能优化
3.1 使用索引
索引是提高数据库查询性能的重要手段。在 Django 中,可以使用 db_index=True 参数来为字段创建索引。例如为 title 字段创建索引:
class Blog(models.Model):title = models.CharField(max_length=100, db_index=True)content = models.TextField()pub_date = models.DateTimeField(auto_now_add=True)
3.2 批量操作
批量操作可以使用 bulk_create() 方法和 bulk_update() 方法来实现。例如,下面的代码演示了如何批量插入 Blog 表中的记录:
blogs = [Blog(title='Blog 1', content='Content 1'),Blog(title='Blog 2', content='Content 2'),Blog(title='Blog 3', content='Content 3'),
]Blog.objects.bulk_create(blogs)
可以看到,我们使用了 bulk_create() 方法来批量插入记录,其中 blogs 是一个包含多个 Blog 实例的列表。
3.3 延迟加载
延迟加载可以使用 defer() 方法和 only() 方法来实现。
使用 defer() 方法时,Django 将不会立即从数据库中获取指定字段的数据。它会在需要访问这些字段的数据时,再去查询数据库。这样可以避免一次性从数据库中取出大量的数据,减轻数据库的负担,提高查询效率。
使用 only() 方法可以指定只查询需要的字段,而不是查询整个表的所有字段。这样可以减少数据传输的大小,节省网络带宽和内存资源,提高查询效率。
例如延迟加载 Blog 表中的记录,并且只查询 title 和 pub_date 两个字段:
blogs = Blog.objects.defer('content').only('title', 'pub_date')for blog in blogs:print(blog.title, blog.pub_date)
可以看到,我们使用了 defer('content') 方法来延迟加载 content 字段,这样查询结果中就不会包含 content 字段的数据。同时,使用 only('title', 'pub_date') 方法来指定只查询 title 和 pub_date 两个字段的数据。
3.4 缓存查询结果
缓存查询结果可以使用 Django 的缓存框架来实现。Django的缓存框架可以配置为使用不同的缓存后端,下面是常见的几种缓存后端的配置方法:
3.4.1 内存缓存
使用内存缓存作为缓存后端是最简单的配置方式,它可以快速地缓存数据并且不需要额外的配置。在settings.py文件中进行如下配置:
CACHES = {'default': {'BACKEND': 'django.core.cache.backends.locmem.LocMemCache','LOCATION': 'unique-snowflake',}
}
BACKEND 指定了缓存后端为内存缓存,LOCATION 是一个可选的参数,用于指定缓存的名称,可以是任何字符串。
3.4.2 文件缓存
使用文件缓存作为缓存后端可以将缓存数据存储到文件系统中,需要指定缓存文件的路径。在settings.py文件中进行如下配置:
CACHES = {'default': {'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache','LOCATION': '/var/tmp/django_cache',}
}
BACKEND 指定了缓存后端为文件缓存,LOCATION 是一个必选的参数,用于指定缓存文件的路径。
3.4.3 Memcached
使用Memcached作为缓存后端可以将缓存数据存储到Memcached服务器中,需要指定Memcached服务器的地址和端口号。在settings.py文件中进行如下配置:
CACHES = {'default': {'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache','LOCATION': '127.0.0.1:11211',}
}
BACKEND 指定了缓存后端为Memcached,LOCATION 是一个必选的参数,用于指定Memcached服务器的地址和端口号。
3.4.4 Redis
使用Redis作为缓存后端可以将缓存数据存储到Redis服务器中,需要指定Redis服务器的地址、端口号和数据库编号。在settings.py文件中进行如下配置:
CACHES = {'default': {'BACKEND': 'django_redis.cache.RedisCache','LOCATION': 'redis://127.0.0.1:6379/0','OPTIONS': {'CLIENT_CLASS': 'django_redis.client.DefaultClient',},}
}
BACKEND 指定了缓存后端为Redis,LOCATION 是一个必选的参数,用于指定Redis服务器的地址、端口号和数据库编号。OPTIONS 是一个可选的参数,用于指定Redis客户端的选项,这里使用默认选项。
需要注意的是,在使用Redis作为缓存后端时,需要额外安装 django-redis 库。可以使用pip命令进行安装:
pip install django-redis
例如缓存 Blog 表中的记录:
from django.core.cache import cacheblogs = cache.get('blogs')if blogs is None:blogs = Blog.objects.all()cache.set('blogs', blogs, timeout=3600)for blog in blogs:print(blog.title, blog.content, blog.pub_date)
可以看到,我们使用了 cache.get('blogs') 方法来从缓存中获取查询结果。如果缓存中不存在查询结果,则使用 Blog.objects.all() 来查询数据库,并且使用 cache.set('blogs', blogs, timeout=3600) 方法将查询结果存入缓存中。其中,timeout=3600 表示缓存的过期时间为 3600 秒。
技术总结
本文详细介绍了 Django 的 ORM 框架,包括基本使用方法、高级查询和性能优化等方面。ORM 框架可以让我们不用编写 SQL 语句,就能够使用对象的方式来操作数据库,大大提高了代码的可读性和可维护性。同时,我们还介绍了一些性能优化技巧,例如使用索引、批量操作、延迟加载和缓存查询结果等。希望本文对你学习 Django 的 ORM 框架有所帮助!
欢迎点赞收藏转发,感谢🙏
相关文章:

Python web实战之 Django 的 ORM 框架详解
本文关键词:Python、Django、ORM。 概要 在 Python Web 开发中,ORM(Object-Relational Mapping,对象关系映射)是一个非常重要的概念。ORM 框架可以让我们不用编写 SQL 语句,就能够使用对象的方式来操作数据…...
pycharm制作柱状图
Bar - Bar_rotate_xaxis_label 解决标签名字过长的问题 from pyecharts import options as opts from pyecharts.charts import Barc (Bar().add_xaxis(["高等数学1,2","C语言程序设计","python程序设计","大数据导论",…...

静态资源导入探究
静态资源可以在哪里找呢?我们看看源码 从这个类进去 里面有个静态类 WebMvcAutoConfigurationAdapter 有个配置类,将这个类的对象创建并导入IOC容器里 这个静态类下有个方法 addResourceHandlers(ResourceHandlerRegistry registry)静态资源处理器 若自…...
安全狗V3.512048版本绕过
安全狗安装 安全狗详细安装、遇见无此服务器解决、在windows中命令提示符中进入查看指定文件夹手动启动Apache_安全狗只支持 glibc_2.14 但是服务器是2.17_黑色地带(崛起)的博客-CSDN博客 安全狗 safedogwzApacheV3.5.exe 右键电脑右下角安全狗图标-->选择插件-->安装…...
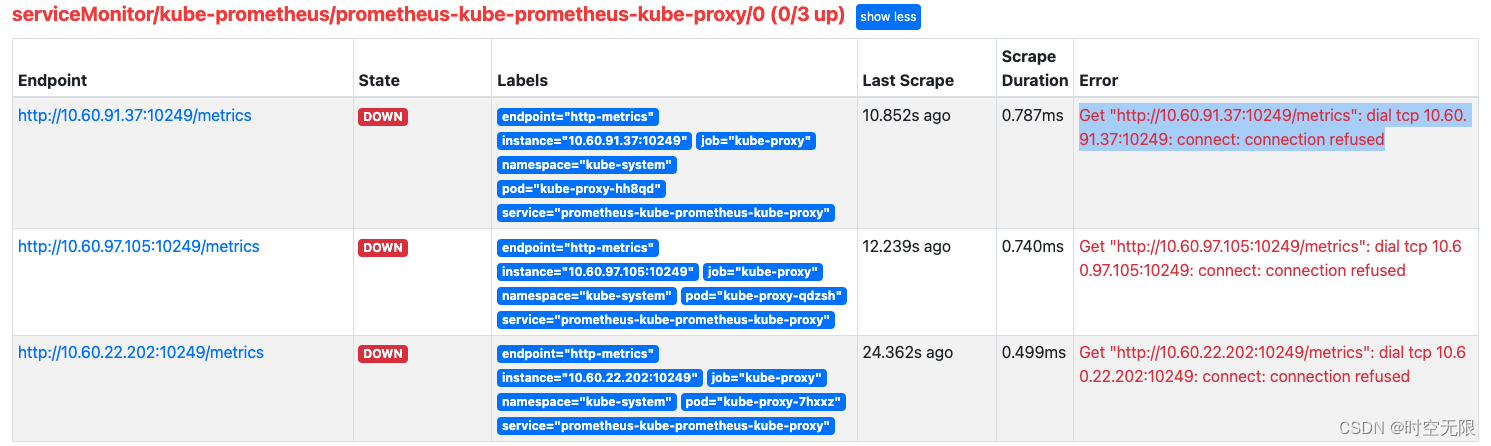
prometheus监控k8s kube-proxy target down
prometheus kube-proxy target down 解决 修改配置 kubectl edit cm/kube-proxy -n kube-systemmetricsBindAddress: "0.0.0.0:10249"删除 kube-proxy pod 使之重启应用配置 kubectl delete pod --force `kubectl get pod -n kube-system |grep kube-proxy|awk {pr…...
SPSS数据分析--假设检验的两种原假设取舍决定方式
假设检验的两种原假设取舍决定方式 在t检验,相关分析,回归分析,方差分析,卡方检验等等分析方法中,都需要用到假设检验。假设检验的步骤一般如下: 提出假设:H0 vs H1 ;假设原假设H0 成立的情况…...
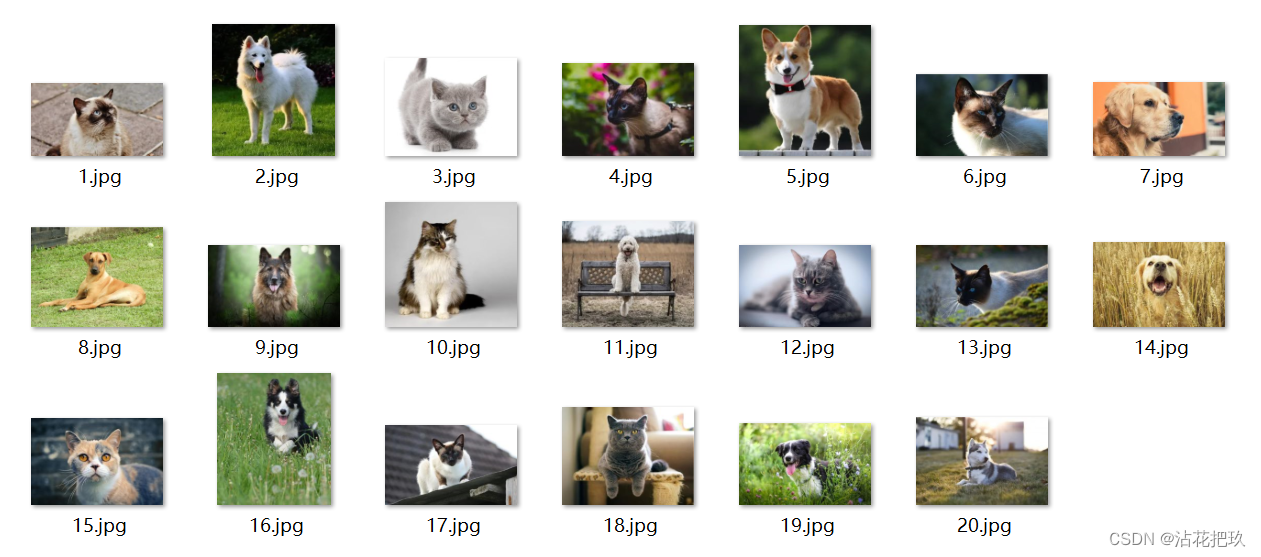
Python实现猫狗分类
不废话了,直接上代码: def load_imagepath_from_csv(csv_name):image_path []with open(csv_name,r) as file:csv_reader csv.reader(file)next(csv_reader)for row in csv_reader:image_path.append(row[0])return image_pathimport csv csv_name &…...
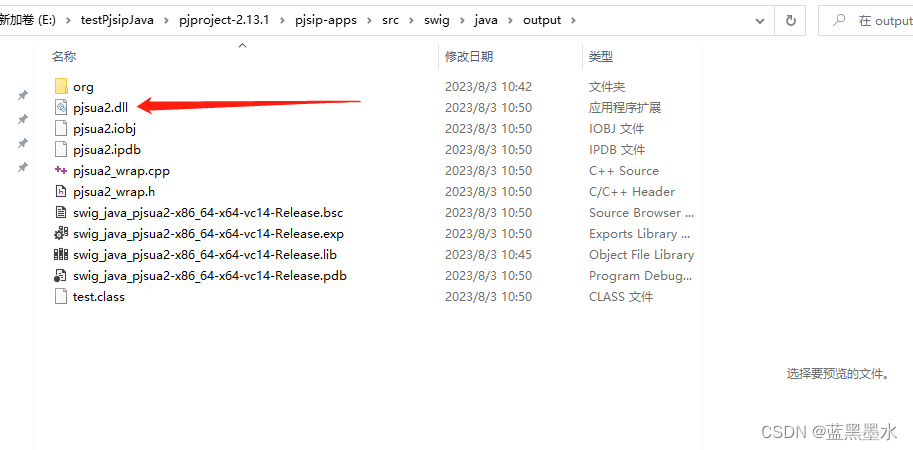
pjsip、pjsua2+bcg729 windows下编译java版本
文章目录 简要说明流程步骤 简要说明 基本参考的这里 https://docs.pjsip.org/en/latest/get-started/windows/build_instructions.html#building-the-projects 我这里主要是为了生成pjsua2.dll 用于在java下调用。 其中 libbcg729.dll 是通过vcpkg来进行安装。 pjsip使用vs2…...

尝试多数据表 sqlite
C 唯一值得骄傲的地方就是 通过指针来回寻址 😂 提高使用的灵活性 小脚本buff 加成...
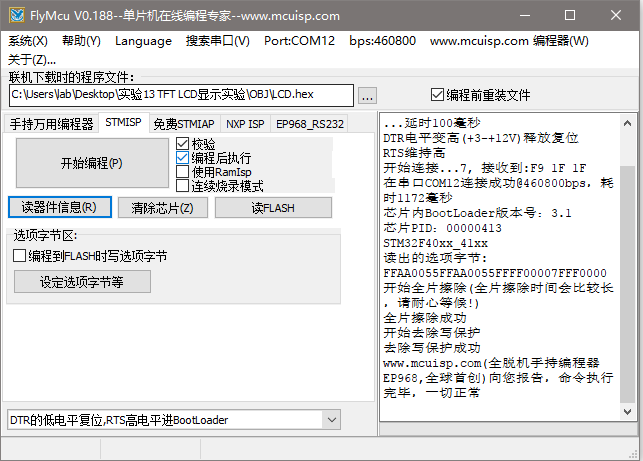
Keil出现Flash Timeout.Reset the Target and try it again.我有一种解决方法
2.解决方法 网上查找了找原因,是因为之前代码设置了读保护功能。 读保护即大家通常说的“加密”,是作用于整个Flash存储区域。一旦设置了Flash的读保护,内置的Flash存储区只能通过程序的正常执行才能读出,而不能通过下述任何一种…...

纯粹即刻,畅享音乐搜索的轻松体验
纯粹即刻,畅享音乐搜索的轻松体验 在当今快节奏的生活中,我们常常渴望一种简单而便捷的方式来探索和享受音乐。现在,你可以纯粹即刻地畅享音乐搜索的轻松体验。无论你是寻找热门歌曲还是探索不同风格的音乐,这款应用将为你带来随…...
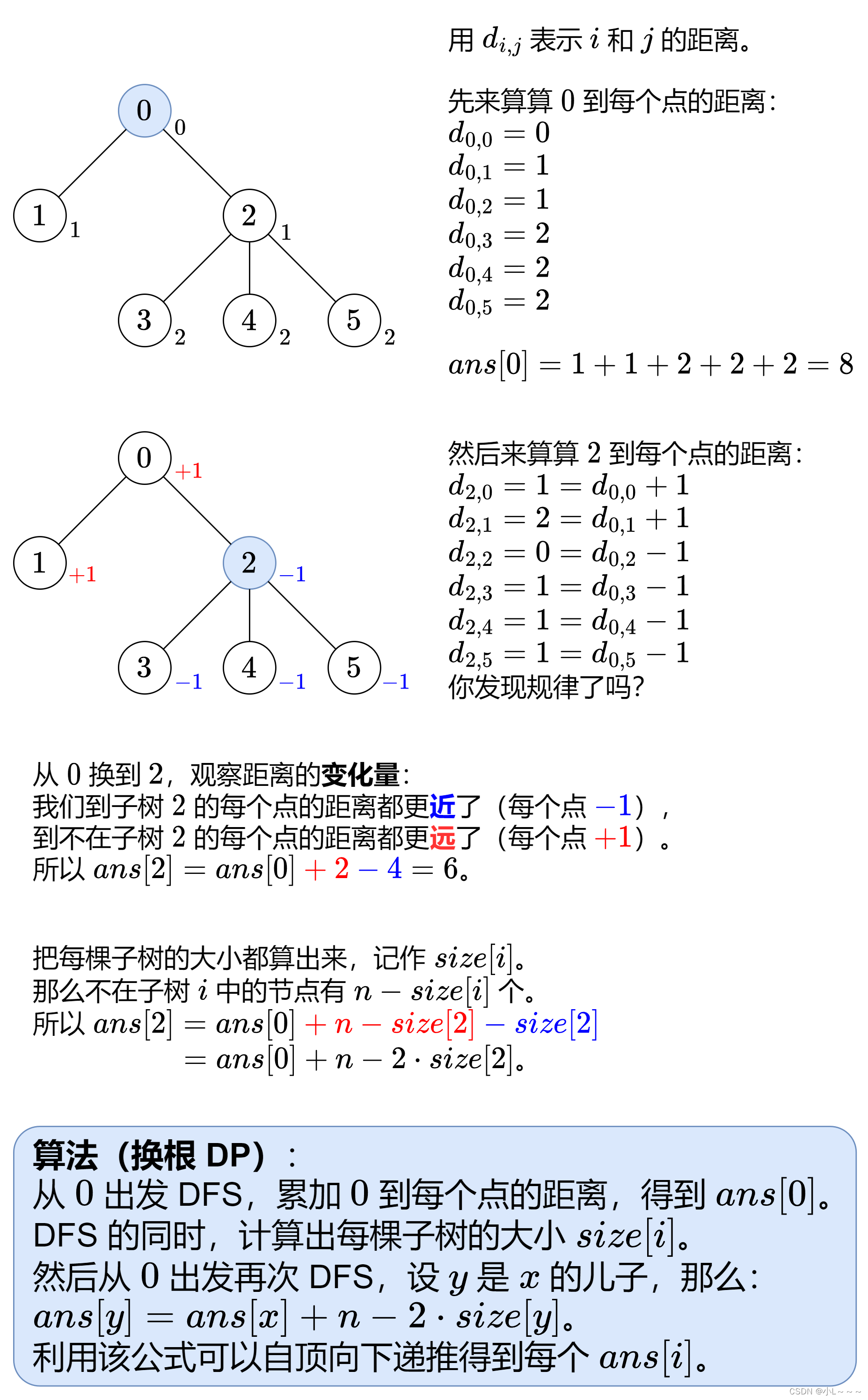
动态规划之树形DP
动态规划之树形DP 树形DP何为树形DP 树形DP例题HDU-1520 Anniversary partyHDU-2196 Computer834. 树中距离之和 树形DP 何为树形DP 树形DP是指在“树”这种数据结构上进行的动态规划:给出一颗树,要求以最少的代价(或取得最大收益ÿ…...

嵌入式_GD32使用宏开关进行Debug串口打印调试
嵌入式_GD32使用宏开关进行Debug串口打印调试 串口Debug是一种将数据通过串口发送的方法。通过使用printf函数,我们可以将需要发送的数据格式化为字符串,并通过串口发送出去。在C语言中,通常使用串口发送数据的函数为printf函数,…...

使用 GitHub Copilot 进行 Prompt Engineering 的初学者指南(译)
文章目录 什么是 GitHub Copilot ?GitHub Copilot 可以自己编码吗?GitHub Copilot 的底层是如何工作的?什么是 prompt engineering?这是 prompt engineering 的另一个例子 使用 GitHub Copilot 进行 prompt engineering 的最佳实践提供高级上下文&…...

c++开发模式,享元模式
享元模式,个人理解,就是应用共享技术来减少类的对象创建,节省计算机资源消耗,而且能够减少维护成本 #include <iostream> #include <string> #include <vector>using namespace std;class Flyweight { public:…...
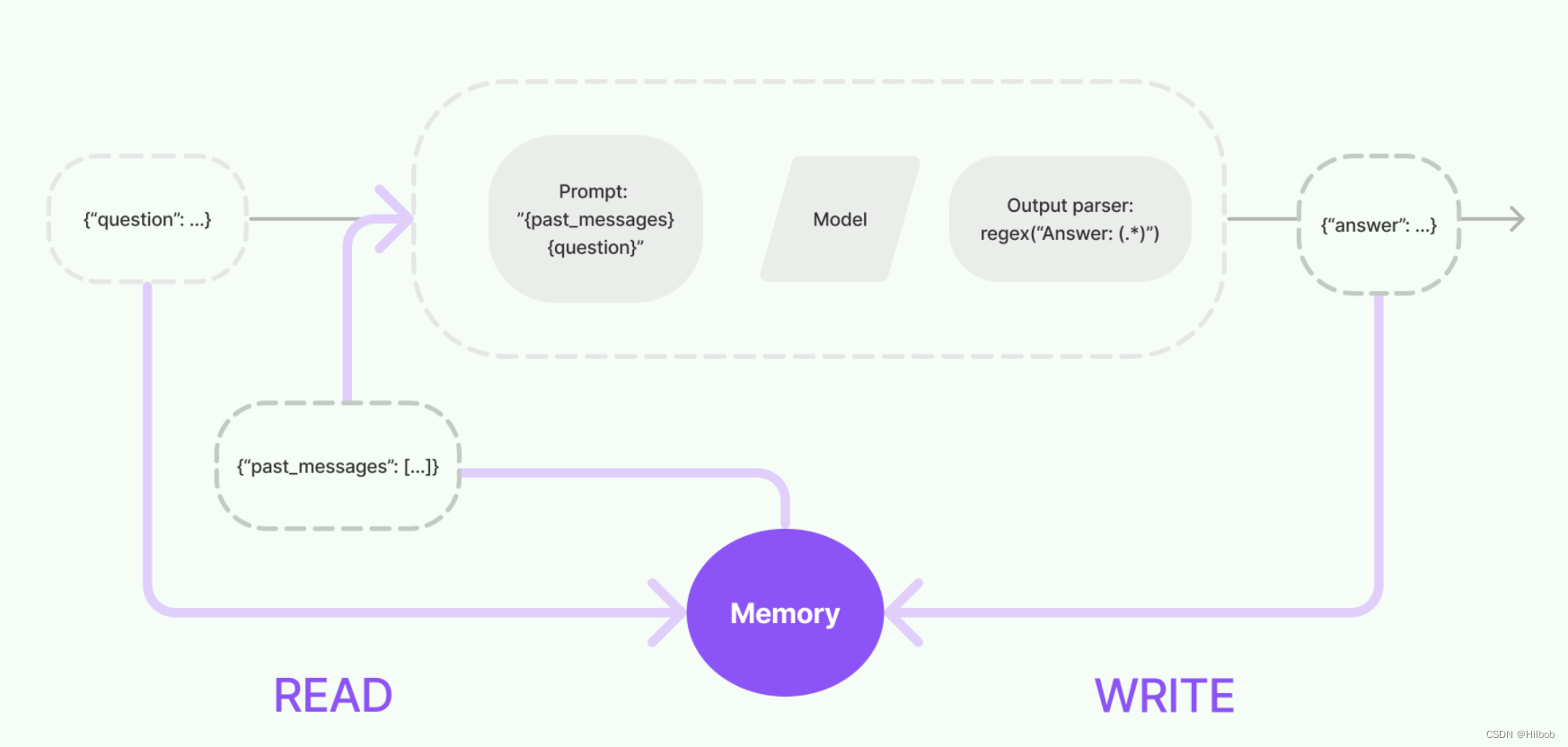
LLM大模型——langchain相关知识总结
目录 一、简介LangChain的主要价值支柱简单安装 二、 LangChain的主要模块1.Model I/Oprompt模版定义调用语言模型 2. 数据连接3. chains4. Agents5. MemoryCallbacks 三、其他记录多进程调用 主要参考以下开源文档 文档地址:https://python.langchain.com/en/lates…...

【Python】数据可视化利器PyCharts在测试工作中的应用
目录 PyCharts 简介 PyCharts 的安装 缺陷统计 测试用例执行情况 使用JavaScript情况 缺陷趋势分析 将两张图放在一个组合里(grid) 将两张图重叠成一张图(overlap) 将多张图组合在一个page 中(page࿰…...
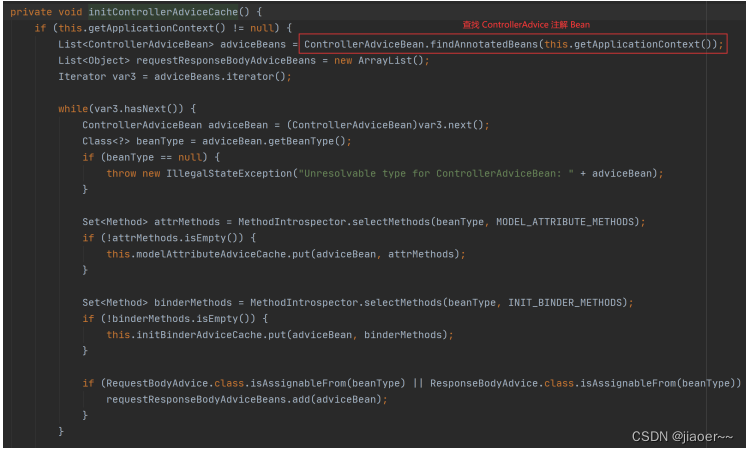
AOP的实战(统一功能处理模块)
一、用户登录权限效验 用户登录权限的发展从之前每个方法中自己验证用户登录权限,到现在统一的用户登录验证处理,它是一个逐渐完善和逐渐优化的过程。 1.1 最初用户登录验证 我们先来回顾一下最初用户登录验证的实现方法: RestController…...

时间复杂度为O(n2)的三种简单排序算法
1.冒泡排序 冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。一次冒泡会让至少少一个元素移动到它应该在的位置,重复n次,就完成了n个数据的排序工作。 /*** …...

LeetCode 热题 100 JavaScript --226. 翻转二叉树
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 示例 3: 输入:root [] 输出:[] 提示: 树中节点数目范围在 [0, 100] 内 -100 < Node.val < 100 var invertTree function(root…...

无机布防火卷帘门报价透明,包工包料,一次说清所有费用
很多客户在选购无机布防火卷帘门时,最关心实际成交价格,也担心报价不清晰,后期产生各类额外支出。行业内产品定价参差不齐,选材做工不同,最终价位自然存在差距,挑选时不能只看表面低价。 👉 点击…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...

PCL 基于强度的双边滤波【2026最新版】
目录 一、算法原理 1、计算步骤 2、算法源码 3、函数解析 4、参考文献 二、代码实现 三、结果展示 四、滤波后未发生变化的原因 五、解决办法 六、结果展示 七、相关链接 本文由CSDN点云侠原创,博客长期更新,本文最近一次更新时间为:2026年5月24日。 一、算法原理 1、计算…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...

Go开发者必备:circuitbreaker API全解析与最佳实践指南 [特殊字符]
Go开发者必备:circuitbreaker API全解析与最佳实践指南 🚀 【免费下载链接】circuitbreaker Circuit Breakers in Go 项目地址: https://gitcode.com/gh_mirrors/circ/circuitbreaker 作为一名Go开发者,你是否经常遇到远程服务调用失败…...

使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点 在团队协作或管理多个AI应用项目时,一个常见的痛点是每个…...

别只盯着主控芯片!拆解STM32最小系统板:电源、时钟、复位三大支柱电路深度解析
STM32最小系统板设计进阶:电源、时钟与复位电路的工程实践 在嵌入式系统开发中,我们常常将注意力集中在主控芯片的功能实现上,却忽略了支撑系统稳定运行的三大基础电路——电源、时钟和复位。这些看似简单的电路模块,实则是整个系…...