GoogLeNet卷积神经网络-笔记
GoogLeNet卷积神经网络-笔记
GoogLeNet是2014年ImageNet比赛的冠军,
它的主要特点是网络不仅有深度,
还在横向上具有“宽度”。
由于图像信息在空间尺寸上的巨大差异,
如何选择合适的卷积核来提取特征就显得比较困难了。
空间分布范围更广的图像信息适合用较大的卷积核来提取其特征;
而空间分布范围较小的图像信息则适合用较小的卷积核来提取其特征。
为了解决这个问题,
GoogLeNet提出了一种被称为Inception模块的方案。
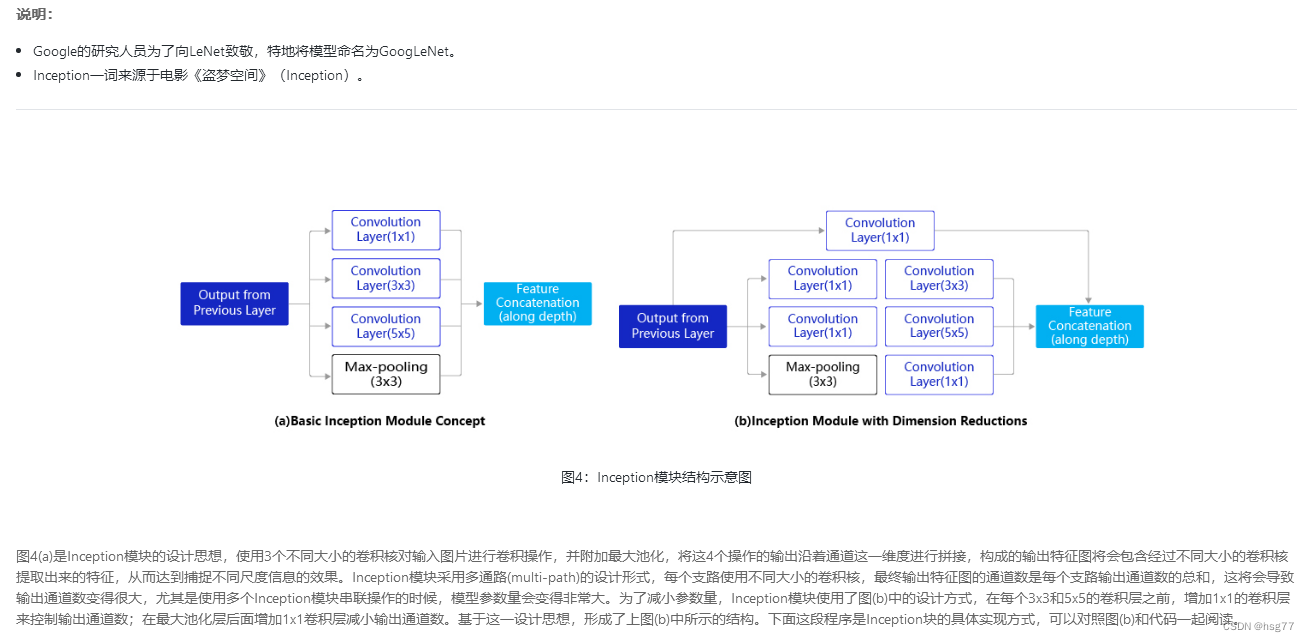
Inception模块结构图
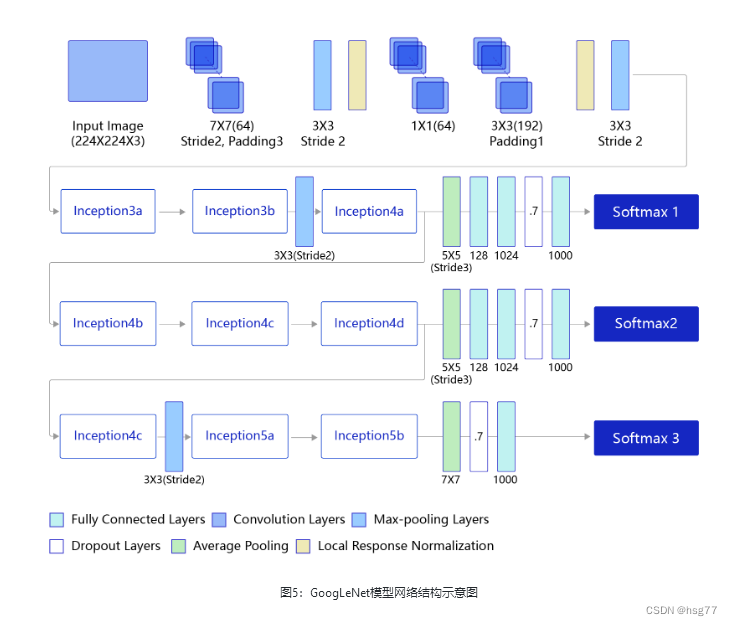
GoogleNet模型网络结构图
测试结果为:
通过运行结果可以发现,使用GoogLeNet在眼疾筛查数据集iChallenge-PM上,loss能有效的下降,经过5个epoch的训练,在验证集上的准确率可以达到95%左右。
实测准确率为0.95左右
[validation] accuracy/loss: 0.9575/0.1915
[validation] accuracy/loss: 0.9500/0.2322
#输出结果:
PS E:\project\python> & D:/ProgramData/Anaconda3/python.exe e:/project/python/PM/GoogLeNet_PM.py
W0803 18:25:55.522811 8308 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 12.2, Runtime API Version: 10.2
W0803 18:25:55.532805 8308 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
116
start training ...
epoch: 0, batch_id: 0, loss is: 0.6920
epoch: 0, batch_id: 20, loss is: 0.8546
[validation] accuracy/loss: 0.7100/0.5381
epoch: 1, batch_id: 0, loss is: 0.6177
epoch: 1, batch_id: 20, loss is: 0.4581
[validation] accuracy/loss: 0.9400/0.3120
epoch: 2, batch_id: 0, loss is: 0.2858
epoch: 2, batch_id: 20, loss is: 0.5234
[validation] accuracy/loss: 0.5975/0.5757
epoch: 3, batch_id: 0, loss is: 0.6338
epoch: 3, batch_id: 20, loss is: 0.3180
[validation] accuracy/loss: 0.9575/0.1915
epoch: 4, batch_id: 0, loss is: 0.1087
epoch: 4, batch_id: 20, loss is: 0.3728
[validation] accuracy/loss: 0.9500/0.2322
PS E:\project\python>
'''
GoogleNet网模型中子图层Shape[N,C,H,W],w参数,b参数[Cout]
PS E:\project\python> & D:/ProgramData/Anaconda3/python.exe e:/project/python/PM/GoogLeNet_PM.py
W0803 20:27:47.303915 15396 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 12.2, Runtime API Version: 10.2
W0803 20:27:47.311910 15396 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6.
116
(10, 3, 224, 224)
[10, 3, 224, 224]
conv2d_0 [10, 64, 224, 224] [64, 3, 7, 7] [64]
max_pool2d_0 [10, 64, 112, 112]
conv2d_1 [10, 64, 112, 112] [64, 64, 1, 1] [64]
conv2d_2 [10, 192, 112, 112] [192, 64, 3, 3] [192]
max_pool2d_1 [10, 192, 56, 56]
print block3-1:
conv2d_3 [10, 64, 56, 56] [64, 192, 1, 1] [64]
conv2d_4 [10, 96, 56, 56] [96, 192, 1, 1] [96]
conv2d_5 [10, 128, 56, 56] [128, 96, 3, 3] [128]
conv2d_6 [10, 16, 56, 56] [16, 192, 1, 1] [16]
conv2d_7 [10, 32, 56, 56] [32, 16, 5, 5] [32]
max_pool2d_2 [10, 192, 56, 56]
conv2d_8 [10, 32, 56, 56] [32, 192, 1, 1] [32]
print block3-2:
conv2d_9 [10, 128, 56, 56] [128, 256, 1, 1] [128]
conv2d_10 [10, 128, 56, 56] [128, 256, 1, 1] [128]
conv2d_11 [10, 192, 56, 56] [192, 128, 3, 3] [192]
conv2d_12 [10, 32, 56, 56] [32, 256, 1, 1] [32]
conv2d_13 [10, 96, 56, 56] [96, 32, 5, 5] [96]
max_pool2d_3 [10, 256, 56, 56]
conv2d_14 [10, 64, 56, 56] [64, 256, 1, 1] [64]
max_pool2d_4 [10, 480, 28, 28]
print block4_1:
conv2d_15 [10, 192, 28, 28] [192, 480, 1, 1] [192]
conv2d_16 [10, 96, 28, 28] [96, 480, 1, 1] [96]
conv2d_17 [10, 208, 28, 28] [208, 96, 3, 3] [208]
conv2d_18 [10, 16, 28, 28] [16, 480, 1, 1] [16]
conv2d_19 [10, 48, 28, 28] [48, 16, 5, 5] [48]
max_pool2d_5 [10, 480, 28, 28]
conv2d_20 [10, 64, 28, 28] [64, 480, 1, 1] [64]
print block4_2:
conv2d_21 [10, 160, 28, 28] [160, 512, 1, 1] [160]
conv2d_22 [10, 112, 28, 28] [112, 512, 1, 1] [112]
conv2d_23 [10, 224, 28, 28] [224, 112, 3, 3] [224]
conv2d_24 [10, 24, 28, 28] [24, 512, 1, 1] [24]
conv2d_25 [10, 64, 28, 28] [64, 24, 5, 5] [64]
max_pool2d_6 [10, 512, 28, 28]
conv2d_26 [10, 64, 28, 28] [64, 512, 1, 1] [64]
print block4_3:
conv2d_27 [10, 128, 28, 28] [128, 512, 1, 1] [128]
conv2d_28 [10, 128, 28, 28] [128, 512, 1, 1] [128]
conv2d_29 [10, 256, 28, 28] [256, 128, 3, 3] [256]
conv2d_30 [10, 24, 28, 28] [24, 512, 1, 1] [24]
conv2d_31 [10, 64, 28, 28] [64, 24, 5, 5] [64]
max_pool2d_7 [10, 512, 28, 28]
conv2d_32 [10, 64, 28, 28] [64, 512, 1, 1] [64]
print block4_4:
conv2d_33 [10, 112, 28, 28] [112, 512, 1, 1] [112]
conv2d_34 [10, 144, 28, 28] [144, 512, 1, 1] [144]
conv2d_35 [10, 288, 28, 28] [288, 144, 3, 3] [288]
conv2d_36 [10, 32, 28, 28] [32, 512, 1, 1] [32]
conv2d_37 [10, 64, 28, 28] [64, 32, 5, 5] [64]
max_pool2d_8 [10, 512, 28, 28]
conv2d_38 [10, 64, 28, 28] [64, 512, 1, 1] [64]
print block4_5:
conv2d_39 [10, 256, 28, 28] [256, 528, 1, 1] [256]
conv2d_40 [10, 160, 28, 28] [160, 528, 1, 1] [160]
conv2d_41 [10, 320, 28, 28] [320, 160, 3, 3] [320]
conv2d_42 [10, 32, 28, 28] [32, 528, 1, 1] [32]
conv2d_43 [10, 128, 28, 28] [128, 32, 5, 5] [128]
max_pool2d_9 [10, 528, 28, 28]
conv2d_44 [10, 128, 28, 28] [128, 528, 1, 1] [128]
max_pool2d_10 [10, 832, 14, 14]
print block5_1:
conv2d_45 [10, 256, 14, 14] [256, 832, 1, 1] [256]
conv2d_46 [10, 160, 14, 14] [160, 832, 1, 1] [160]
conv2d_47 [10, 320, 14, 14] [320, 160, 3, 3] [320]
conv2d_48 [10, 32, 14, 14] [32, 832, 1, 1] [32]
conv2d_49 [10, 128, 14, 14] [128, 32, 5, 5] [128]
max_pool2d_11 [10, 832, 14, 14]
conv2d_50 [10, 128, 14, 14] [128, 832, 1, 1] [128]
print block5_2:
conv2d_51 [10, 384, 14, 14] [384, 832, 1, 1] [384]
conv2d_52 [10, 192, 14, 14] [192, 832, 1, 1] [192]
conv2d_53 [10, 384, 14, 14] [384, 192, 3, 3] [384]
conv2d_54 [10, 48, 14, 14] [48, 832, 1, 1] [48]
conv2d_55 [10, 128, 14, 14] [128, 48, 5, 5] [128]
max_pool2d_12 [10, 832, 14, 14]
conv2d_56 [10, 128, 14, 14] [128, 832, 1, 1] [128]
adaptive_avg_pool2d_0 [10, 1024, 1, 1]
linear_0 [10, 1] [1024, 1] [1]
PS E:\project\python>
测试源代码如下所示:
# GoogLeNet模型代码
#GoogLeNet卷积神经网络-笔记
import numpy as np
import paddle
from paddle.nn import Conv2D, MaxPool2D, AdaptiveAvgPool2D, Linear
## 组网
import paddle.nn.functional as F# 定义Inception块
class Inception(paddle.nn.Layer):def __init__(self, c0, c1, c2, c3, c4, **kwargs):'''Inception模块的实现代码,c1,图(b)中第一条支路1x1卷积的输出通道数,数据类型是整数c2,图(b)中第二条支路卷积的输出通道数,数据类型是tuple或list, 其中c2[0]是1x1卷积的输出通道数,c2[1]是3x3c3,图(b)中第三条支路卷积的输出通道数,数据类型是tuple或list, 其中c3[0]是1x1卷积的输出通道数,c3[1]是3x3c4,图(b)中第一条支路1x1卷积的输出通道数,数据类型是整数'''super(Inception, self).__init__()# 依次创建Inception块每条支路上使用到的操作self.p1_1 = Conv2D(in_channels=c0,out_channels=c1, kernel_size=1, stride=1)self.p2_1 = Conv2D(in_channels=c0,out_channels=c2[0], kernel_size=1, stride=1)self.p2_2 = Conv2D(in_channels=c2[0],out_channels=c2[1], kernel_size=3, padding=1, stride=1)self.p3_1 = Conv2D(in_channels=c0,out_channels=c3[0], kernel_size=1, stride=1)self.p3_2 = Conv2D(in_channels=c3[0],out_channels=c3[1], kernel_size=5, padding=2, stride=1)self.p4_1 = MaxPool2D(kernel_size=3, stride=1, padding=1)self.p4_2 = Conv2D(in_channels=c0,out_channels=c4, kernel_size=1, stride=1)# # 新加一层batchnorm稳定收敛# self.batchnorm = paddle.nn.BatchNorm2D(c1+c2[1]+c3[1]+c4)def forward(self, x):# 支路1只包含一个1x1卷积p1 = F.relu(self.p1_1(x))# 支路2包含 1x1卷积 + 3x3卷积p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))# 支路3包含 1x1卷积 + 5x5卷积p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))# 支路4包含 最大池化和1x1卷积p4 = F.relu(self.p4_2(self.p4_1(x)))# 将每个支路的输出特征图拼接在一起作为最终的输出结果return paddle.concat([p1, p2, p3, p4], axis=1)# return self.batchnorm()class GoogLeNet(paddle.nn.Layer):def __init__(self):super(GoogLeNet, self).__init__()# GoogLeNet包含五个模块,每个模块后面紧跟一个池化层# 第一个模块包含1个卷积层self.conv1 = Conv2D(in_channels=3,out_channels=64, kernel_size=7, padding=3, stride=1)# 3x3最大池化self.pool1 = MaxPool2D(kernel_size=3, stride=2, padding=1)# 第二个模块包含2个卷积层self.conv2_1 = Conv2D(in_channels=64,out_channels=64, kernel_size=1, stride=1)self.conv2_2 = Conv2D(in_channels=64,out_channels=192, kernel_size=3, padding=1, stride=1)# 3x3最大池化self.pool2 = MaxPool2D(kernel_size=3, stride=2, padding=1)# 第三个模块包含2个Inception块self.block3_1 = Inception(192, 64, (96, 128), (16, 32), 32)self.block3_2 = Inception(256, 128, (128, 192), (32, 96), 64)# 3x3最大池化self.pool3 = MaxPool2D(kernel_size=3, stride=2, padding=1)# 第四个模块包含5个Inception块self.block4_1 = Inception(480, 192, (96, 208), (16, 48), 64)self.block4_2 = Inception(512, 160, (112, 224), (24, 64), 64)self.block4_3 = Inception(512, 128, (128, 256), (24, 64), 64)self.block4_4 = Inception(512, 112, (144, 288), (32, 64), 64)self.block4_5 = Inception(528, 256, (160, 320), (32, 128), 128)# 3x3最大池化self.pool4 = MaxPool2D(kernel_size=3, stride=2, padding=1)# 第五个模块包含2个Inception块self.block5_1 = Inception(832, 256, (160, 320), (32, 128), 128)self.block5_2 = Inception(832, 384, (192, 384), (48, 128), 128)# 全局池化,用的是global_pooling,不需要设置pool_strideself.pool5 = AdaptiveAvgPool2D(output_size=1)self.fc = Linear(in_features=1024, out_features=1)def forward(self, x):x = self.pool1(F.relu(self.conv1(x)))x = self.pool2(F.relu(self.conv2_2(F.relu(self.conv2_1(x)))))x = self.pool3(self.block3_2(self.block3_1(x)))x = self.block4_3(self.block4_2(self.block4_1(x)))x = self.pool4(self.block4_5(self.block4_4(x)))x = self.pool5(self.block5_2(self.block5_1(x)))x = paddle.reshape(x, [x.shape[0], -1])x = self.fc(x)return x#=================================
import PM
# 创建模型
model = GoogLeNet()
print(len(model.parameters()))
opt = paddle.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameters=model.parameters(), weight_decay=0.001)
# 启动训练过程
PM.train_pm(model, opt)—the—end—
相关文章:
GoogLeNet卷积神经网络-笔记
GoogLeNet卷积神经网络-笔记 GoogLeNet是2014年ImageNet比赛的冠军, 它的主要特点是网络不仅有深度, 还在横向上具有“宽度”。 由于图像信息在空间尺寸上的巨大差异, 如何选择合适的卷积核来提取特征就显得比较困难了。 空间分布范围更广的…...

腾讯云TencentOS Server镜像系统常见问题解答
腾讯云TencentOS Server镜像是腾讯云推出的Linux操作系统,完全兼容CentOS生态和操作方式,TencentOS Server操作系统为云上运行的应用程序提供稳定、安全和高性能的执行环境,TencentOS可以运行在腾讯云CVM全规格实例上,包括黑石物理…...

【项目 进程13】2.28共享内存(1) 2.29共享内存(2)
文章目录 2.28共享内存(1)共享内存(效率最高,比内存映射更高。因为内存映射还需一个文件做载体)共享内存使用步骤共享内存操作函数头文件 2.29共享内存(2)共享内存相关问题共享内存和内存映射的…...

Flask框架-流量控制:flask-limiter的使用
一、flask使用flask-limiter存在版本问题 Flask1.1.4 Flask-Bootstrap3.3.7.1 Flask-Caching1.9.0 Flask-Cors3.0.10 Flask-Limiter1.4 Flask-Migrate2.5.3 Flask-RESTful0.3.8 Flask-Script2.0.6 Flask-SocketIO5.0.1 Flask-Sockets0.2.1 Flask-SQLAlchemy2.4.4 Jinjia22.11.…...
【机器学习】西瓜书习题3.5Python编程实现线性判别分析,并给出西瓜数据集 3.0α上的结果
参考代码 结合自己的理解,添加注释。 代码 导入相关的库 import numpy as np import pandas as pd import matplotlib from matplotlib import pyplot as plt导入数据,进行数据处理和特征工程 得到数据集 D { ( x i , y i ) } i 1 m , y i ∈ { 0 ,…...

Elasticsearch:通过动态修剪实现更快的基数聚合
作者:Adrien Grand Elasticsearch 8.9 通过支持动态修剪(dynamic pruning)引入了基数聚合加速。 这种优化需要满足特定的条件才能生效,但一旦实现,通常会产生惊人的结果。 我们观察到,通过此更改࿰…...

Webpack5 生产模式压缩图片ImageMinimizerPlugin
文章目录 一、 ImageMinimizerPlugin是什么?二、已经有了asset,为什么需要ImageMinimizerPlugin?三、怎么使用ImageMinimizerPlugin?四、ImageMinimizerPlugin压缩的成果 一、 ImageMinimizerPlugin是什么? 它的实际依…...

时序预测 | Matlab实现基于BP神经网络的电力负荷预测模型
文章目录 效果一览文章概述源码设计参考资料效果一览 文章概述 时序预测 | Matlab实现基于BP神经网络的电力负荷预测模型 BP神经网络是一种多层的前馈神经网络,其主要的特点是:信号是前向传播的,而误差是反向传播的。B...
基于回溯算法实现八皇后问题
八皇后问题是一个经典的计算机科学问题,它的目标是将8个皇后放置在一个大小为88的棋盘上,使得每个皇后都不会攻击到其他的皇后。皇后可以攻击同一行、同一列和同一对角线上的棋子。 一、八皇后问题介绍 八皇后问题最早由国际西洋棋大师马克斯贝瑟尔在18…...
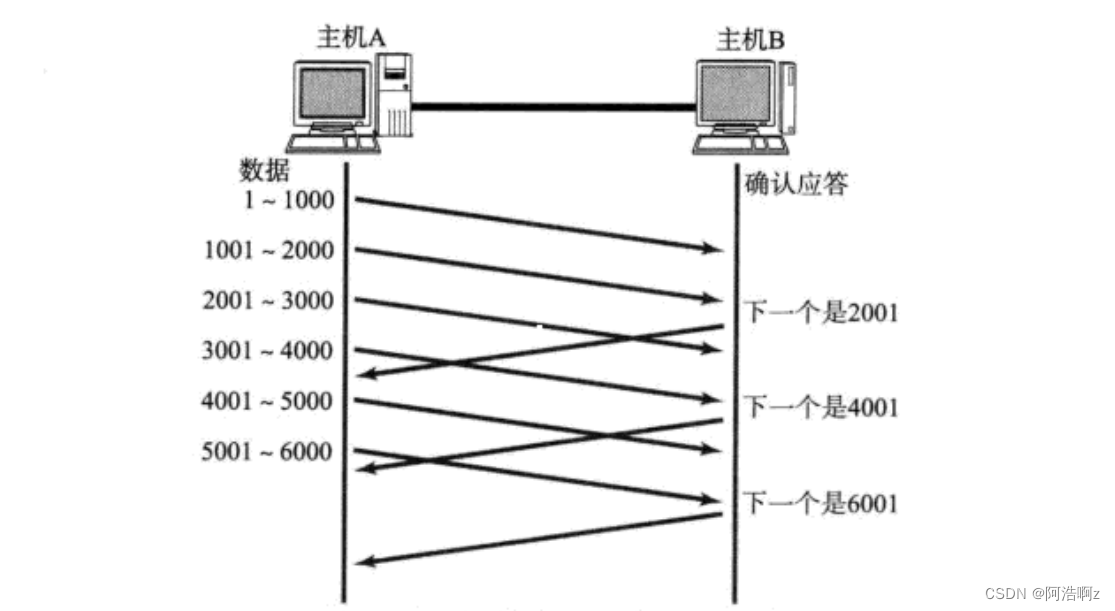
Linux【网络编程】之深入理解TCP协议
Linux【网络编程】之深入理解TCP协议 TCP协议TCP协议段格式4位首部长度---TCP报头长度信息 TCP可靠性(确认应答)&& 提高传输效率确认应答(ACK)机制32位序号与32为确认序号 16位窗口大小---自己接收缓冲区剩余空间的大小16位紧急指针---紧急数据处…...

如何克服看到别人优于自己而感到的焦虑和迷茫?
文章目录 每日一句正能量前言简述自己的感受怎么做如何调整自己的心态后记 每日一句正能量 行动是至于恐惧的良药,而犹豫、拖延,将不断滋养恐惧。 前言 虽然清楚知识需要靠时间沉淀,但在看到自己做不出来的题别人会做,自己写不出的…...
浅谈React中的ref和useRef
目录 什么是useRef? 使用 ref 访问 DOM 元素 Ref和useRef之间的区别 Ref和useRef的使用案例 善用工具 结论 在各种 JavaScript 库和框架中,React 因其开发人员友好性和支持性而得到认可。 大多数开发人员发现 React 非常舒适且可扩展,…...

Linux C 获取主机网卡名及 IP 的几种方法
在进行 Linux 网络编程时,经常会需要获取本机 IP 地址,除了常规的读取配置文件外,本文罗列几种个人所知的编程常用方法,仅供参考,如有错误请指出。 方法一:使用 ioctl() 获取本地 IP 地址 Linux 下可以使用…...

解密外接显卡:笔记本能否接外置显卡?如何连接外接显卡?
伴随着电脑游戏和图形处理的需求不断增加,很多笔记本电脑使用者开始考虑是否能够通过外接显卡来提升性能。然而,外接显卡对于笔记本电脑是否可行,以及如何连接外接显卡,对于很多人来说仍然是一个迷。本文将为您揭秘外接显卡的奥秘…...
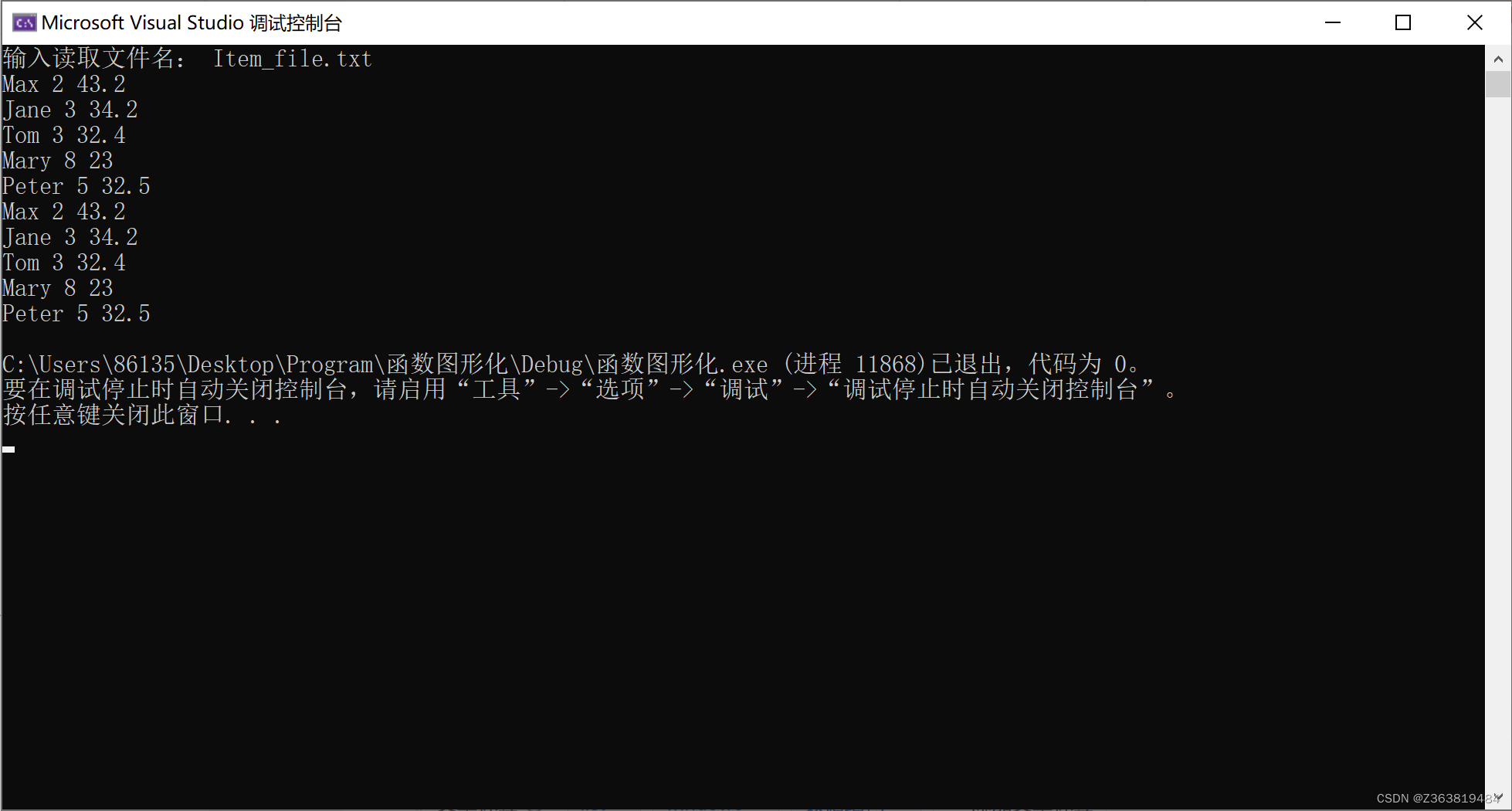
list与erase()
运行代码: //list与erase() #include"std_lib_facilities.h" //声明Item类 struct Item {string name;int iid;double value;Item():name(" "),iid(0),value(0.0){}Item(string ss,int ii,double vv):name(ss),iid(ii),value(vv){}friend istr…...
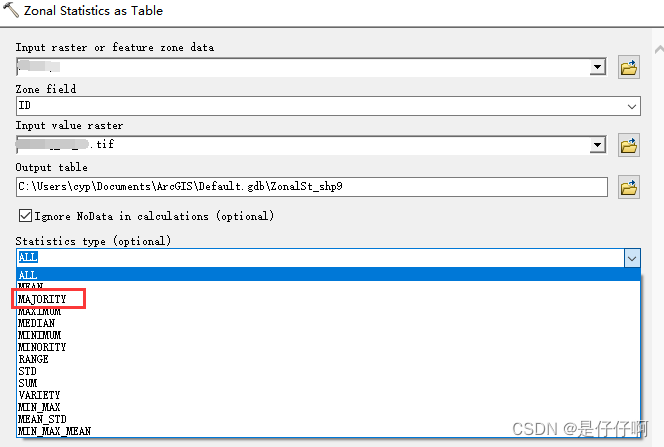
Arcgis 分区统计majority参数统计问题
利用Arcgis 进行分区统计时,需要统计不同矢量区域中栅格数据的众数(majority),出现无法统计majority参数问题解决 解决:利用copy raster工具,将原始栅格数据 64bit转为16bit...
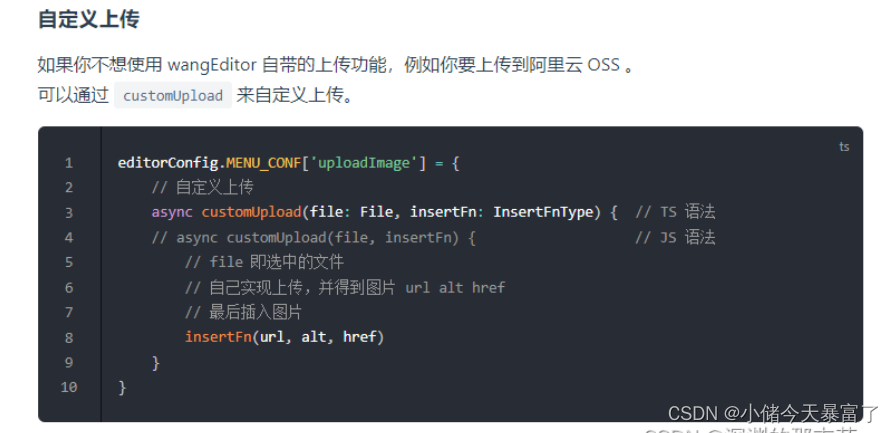
vue2+wangEditor5富文本编辑器(图片视频自定义上传七牛云/服务器)
1、安装使用 安装 yarn add wangeditor/editor # 或者 npm install wangeditor/editor --save yarn add wangeditor/editor-for-vue # 或者 npm install wangeditor/editor-for-vue --save在main.js中引入样式 import wangeditor/editor/dist/css/style.css在使用编辑器的页…...

shell脚本练习--安全封堵脚本,使用firewalld实现
一.什么是安全封堵 安全封堵(security hardening)是指采取一系列措施来增强系统的安全性,防止潜在的攻击和漏洞利用。以下是一些常见的安全封堵措施: 更新和修补系统:定期更新操作系统和软件包以获取最新的安全补丁和修…...

双端冒泡排序
双端冒泡排序是对传统冒泡排序的改进,其主要改进在于同时从两端开始排序,相对于传统冒泡排序每次只从一端开始排序,这样可以减少排序的遍历次数。 传统冒泡排序从一端开始,每次将最大(或最小)的元素冒泡到…...

如何在Visual Studio Code中用Mocha对TypeScript进行测试
目录 使用TypeScript编写测试用例 在Visual Studio Code中使用调试器在线调试代码 首先,本文不是一篇介绍有关TypeScript、JavaScript或其它编程语言数据结构和算法的文章。如果你正在准备一场面试,或者学习某一个课程,互联网上可以找到许多…...

武昌老酒回收电话
随着消费升级与收藏文化的兴起,名贵老酒已成为许多家庭和企业资产的一部分。在武汉武昌区,如何处理手中闲置或珍藏的老酒,实现其价值的安全、高效变现,是不少持有者关心的话题。本文将深入分析武昌老酒回收市场的现状,…...

背靠背VSC直流母线电压控制与同步发电机并网发散问题:原理、分析与解决方案
背靠背VSC直流母线电压控制与同步发电机并网发散问题:原理、分析与解决方案 摘要 背靠背电压源换流器(Back-to-Back VSC)是现代柔性直流输电和新能源并网系统的核心设备。在实际工程调试中,经常出现一个令人困扰的现象:当采用“三相电源-VSC-直流母线-VSC-三相电源”的背…...

如何高效使用Python-miio:5个实战场景完整指南
如何高效使用Python-miio:5个实战场景完整指南 【免费下载链接】python-miio Python library & console tool for controlling Xiaomi smart appliances 项目地址: https://gitcode.com/gh_mirrors/py/python-miio Python-miio是一个强大的开源工具&…...

python containerd
# 聊聊Python Containerd:容器运行时的新选择 容器技术这几年发展得特别快,Docker几乎成了容器的代名词。但如果你在容器生态里待得够久,会发现事情正在起变化。Docker确实好用,但它把太多东西打包在一起了——运行时、镜像管理、…...

C语言接口开发:Shadow Sound Hunter模型高效调用
C语言接口开发:Shadow & Sound Hunter模型高效调用 1. 引言 在实际的AI模型部署中,我们经常遇到这样的场景:需要将先进的AI模型集成到现有的C/C项目中,或者为嵌入式设备开发高效推理接口。Shadow & Sound Hunter作为功能…...
)
保姆级教程:用Python搞定Semantic Drone Dataset的掩码图生成与数据加载(附完整代码)
从零构建无人机语义分割数据管道:Semantic Drone Dataset实战指南 当第一次打开Semantic Drone Dataset的压缩包时,很多开发者会陷入茫然——6000x4000像素的原始图像、复杂的目录结构、没有现成的掩码文件。这份数据集就像未经雕琢的玉石,需…...

从《倘若鸟儿回还》看无障碍设计:如何用技术为轮椅用户打造真正的“独立出行”体验
从《倘若鸟儿回还》看无障碍设计:如何用技术为轮椅用户打造真正的“独立出行”体验 艾米的故事让我们看到,残障人士对独立性的渴望往往被善意所掩盖。查尔斯希望成为她"唯一的推椅人",却忽略了轮椅对她而言不是束缚,而是…...

水性浸涂漆工艺规范:从调配到干燥,讲透五金浸涂所有细节
在水性工业漆的实际应用中,浸涂工艺因其效率高、适合大批量小五金件(如螺栓、垫圈、弹簧、小型电机壳、刹车钳、千斤顶零部件等)而备受青睐。但很多工厂在浸漆时常常遇到气泡、流挂、膜厚不均等问题。本文以敦普水性工业漆的水性浸涂漆为例&a…...

单例管理化技术中的单例计划单例实施单例验证
单例管理化技术:计划、实施与验证的闭环实践 在软件开发中,单例模式因其全局唯一性和资源高效管理的特点被广泛应用。如何系统化地管理单例的生命周期,确保其正确性与稳定性?单例管理化技术通过“单例计划”“单例实施”“单例验…...
日常运维最常用的10条命令,附实战场景)
别再死记硬背了!华为交换机(CE/VRP)日常运维最常用的10条命令,附实战场景
华为交换机运维实战:10条高频命令的深度场景解析 刚接手华为交换机的运维工程师,面对VRP系统里上百条命令时,常陷入两个极端:要么机械记忆却不知何时使用,要么临时查手册耽误故障处理。真正高效的运维不在于记住所有命…...