Linux【网络编程】之深入理解TCP协议
Linux【网络编程】之深入理解TCP协议
- TCP协议
- TCP协议段格式
- 4位首部长度---TCP报头长度信息
- TCP可靠性(确认应答)&& 提高传输效率
- 确认应答(ACK)机制
- 32位序号与32为确认序号
- 16位窗口大小---自己接收缓冲区剩余空间的大小
- 16位紧急指针---紧急数据处理
- 6位标记位---区分TCP报文类型
- 超时重传机制
- 连接管理机制
- 三次握手
- 四次挥手与地址复用
- 流量控制
- 滑动窗口
- 拥塞控制与拥塞窗口
- 延迟应答
- 捎带应答
- 面向字节流
- 粘包问题
- TCP异常情况
- TCP小结
- 连接队列与listen 的第二个参数
TCP协议
TCP全称为 “传输控制协议(Transmission Control Protocol”). 人如其名, 要对数据的传输进行一个详细的控制
TCP协议段格式
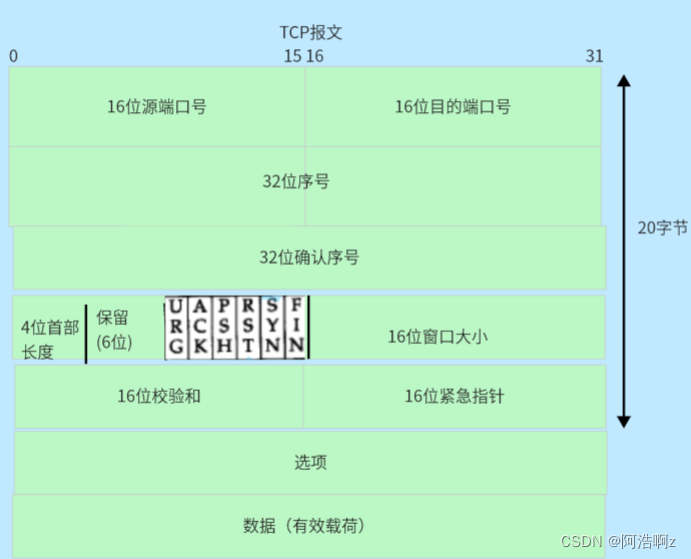
源端口,目的端口:OS给的,也就是我前面模拟基于tcp的应用层协议为什么要用16位端口号
16位校验和: 发送端填充, CRC校验. 接收端校验不通过, 则认为数据有问题. 此处的检验和不光包含TCP首部, 也包含TCP数据部分.
16位紧急指针: 这个指针指向了紧急数据最后一个字节的下一个字节
4位首部长度—TCP报头长度信息
-
tcp协议是有标准长度的20字节,但是报头中可能含有选项,选项占一定字节,也就是说报头的长度是变化的,最小是20字节
-
当服务端收到报文后,转化成一个结构化的数据,就可以得到标准报头中的四位首部长度;
TCP约定:TCP报头总长度=四位首部长度*4字节,因此TCP报头长度范围是[20,60]字节。
假设报头是20字节,那么首部长度就是5,即0101 -
基于上面两条,就可以得到选项的字节:四位首部长度*4-20
-
报头全部读取完毕,就可以得到有效载荷
TCP协议的解包参考以上,封装就是添加报头信息(同UDP),分用就是根据目的端口号,找到应用层对应的进程,交给它
收到的报文是如何找到曾经bind过的特定port进程的?
应用层维护一张port哈希表,当有端口号到来,就会查表找到对应进程PCB
TCP可靠性(确认应答)&& 提高传输效率
网络传输中,因为距离变长,存在着不可靠问题,常见的不可靠场景有丢包、乱序、校验错误、重复等
确认应答(ACK)机制
TCP收发消息最基本的工作模式:发一个新消息给一件应答
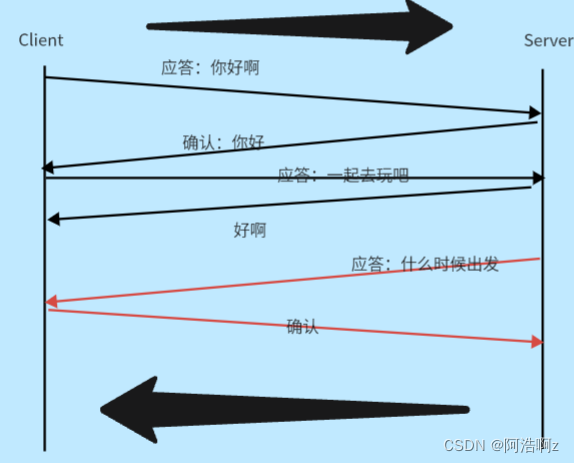
双方再进行通信的时候,除了正常的数据段,还有可能带有确认数据段,对于确认数据段,不需要再次应答
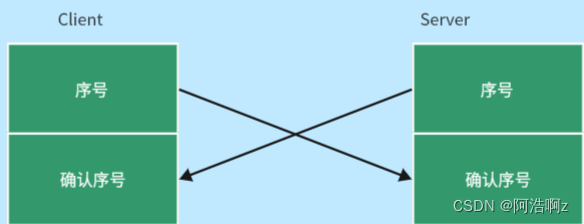
32位序号与32为确认序号
- TCP层双方通信是对等的:像HTTP层,客户端只能请求,服务端只能应答,地位是不对等的;而TCP层双方都是确认应答
- 无论是正常数据段还是确认数据段,都有方式标识数据段本身;只不过是包不包括数据的区别
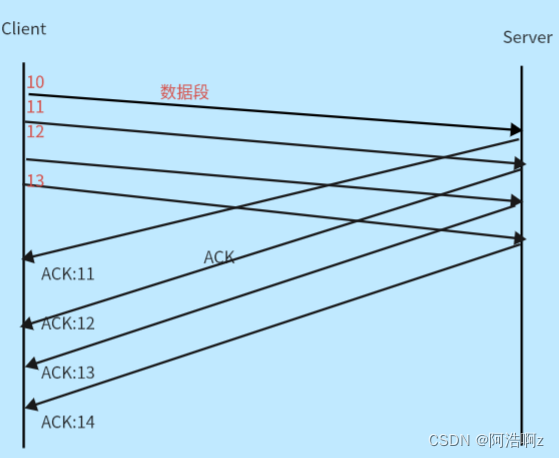
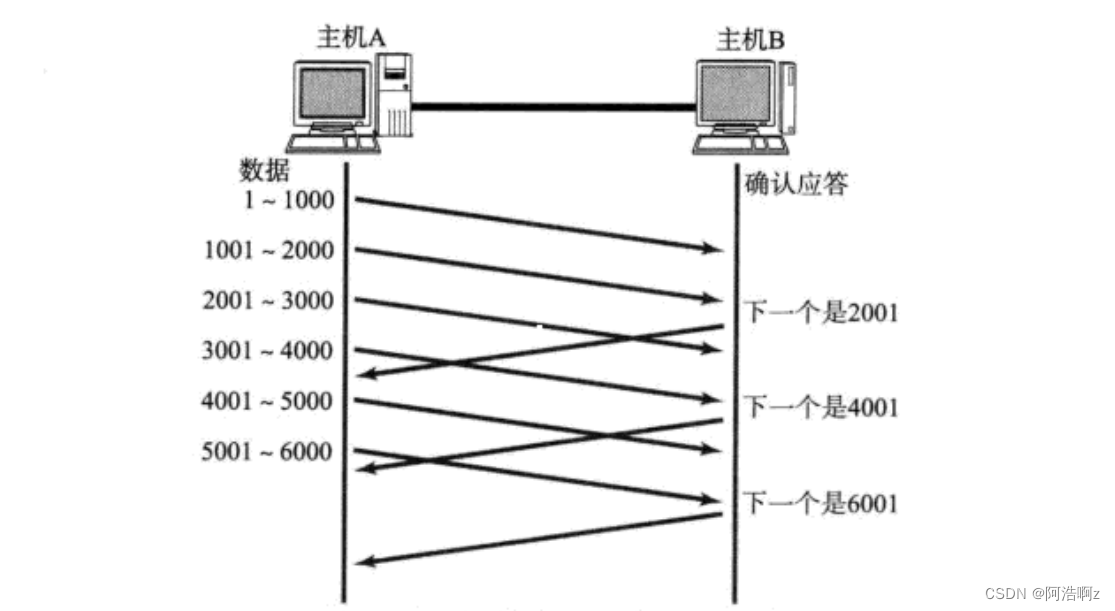
确认应答&&确认序号:接收方已经收到了ACK序号之前的所有(真的报文且连续)报文
例如:ACK:14表示已经收到了14号报文之前的所有报文,下次从14开始发
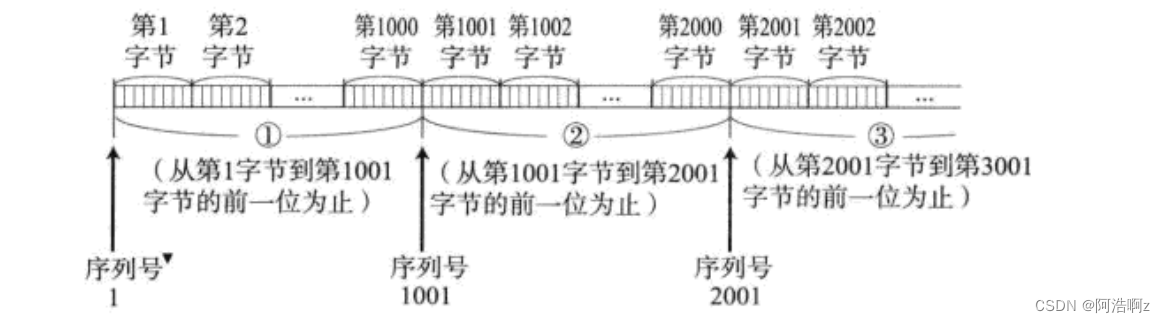
TCP将每个字节的数据都进行了编号. 即为序列号
每一个ACK都带有对应的确认序列号, 意思是告诉发送者, 我已经收到了哪些数据; 下一次你从哪里开始发
为什么要有两组序号?
这是因为TCP是全双工的,当Client向Server发送的时候,Client的序号与Server的确认序号为一组;Server也可以向Client发送,Server的序号与Client的确认序号又成为一组;如下图
16位窗口大小—自己接收缓冲区剩余空间的大小
前面我们说到,TCP协议有两个缓冲区:发送缓冲区和接收缓冲区,当双方进行通信的时候,需要把数据拷贝到缓冲区内,交给对方的接受缓冲区,对方再交付给上层。如果发送过快或者过慢,就会影响传输效率

在报头中有一个16位窗口大小的字段,供发送方使用,里面填写自己的接收缓冲区大小,正因为不知道对方的,才要填自己的,来获取对方的;构建的报文都是要发送给对方的,这样就就换了双方的接收缓冲区剩余大小,也就可以进行流量控制
由于窗口大小与缓冲区挂钩,所以一次只能发64KB的数据,如果想要扩容,需要研究“选项”字段,这里不做讨论
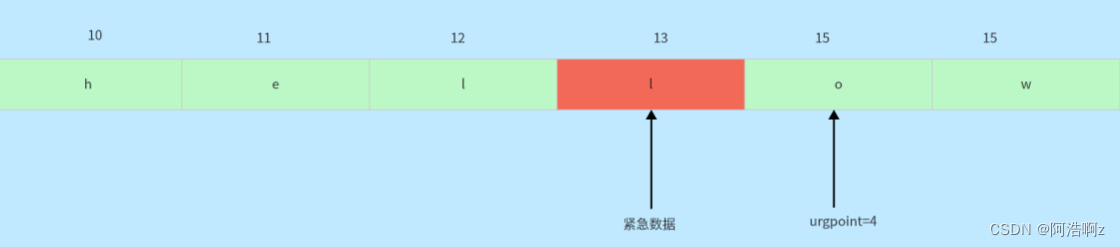
16位紧急指针—紧急数据处理
当报文中有紧急数据需要处理的时候(不是所有的有效载荷,是有效载荷的一部分),会将报头中urg标记位置为1,16位紧急指针作为偏移量指向有效载荷中的紧急数据的下一字节,TCP紧急指针指向的数据只能有一个字节,也就是说,根据偏移量找到数据后,只有一个字节的数据是紧急数据
6位标记位—区分TCP报文类型
TCP报文是有类型的,6位标记位就是来区分不同类型的报文
SYN: 同步标记位,默认为0,只有在建立连接的时候被置为1,三次挥手再详谈
FIN: 断开连接标记位,四次挥手详谈
ACK: 确认标记位,报文带有确认,就会将此标记为置1
PSH: 提示接收端应用程序立刻从TCP缓冲区把数据读走
URG: 紧急指针是否有效
RST: 复位标记位,对方要求重新建立连接; 我们把携带RST标识的称为复位报文段
当客户端和服务器建立连接、断开连接的时候,有可能会失败,即使成功,通信过程一方也可能会出问题;假设服务端出现问题断开重启,但是客户端并不知道,依旧发送报文,服务端就会发送相应报文,携带RST标记位,告诉客户端重新建立连接。同理,客户端如果断开,会给服务端发信息
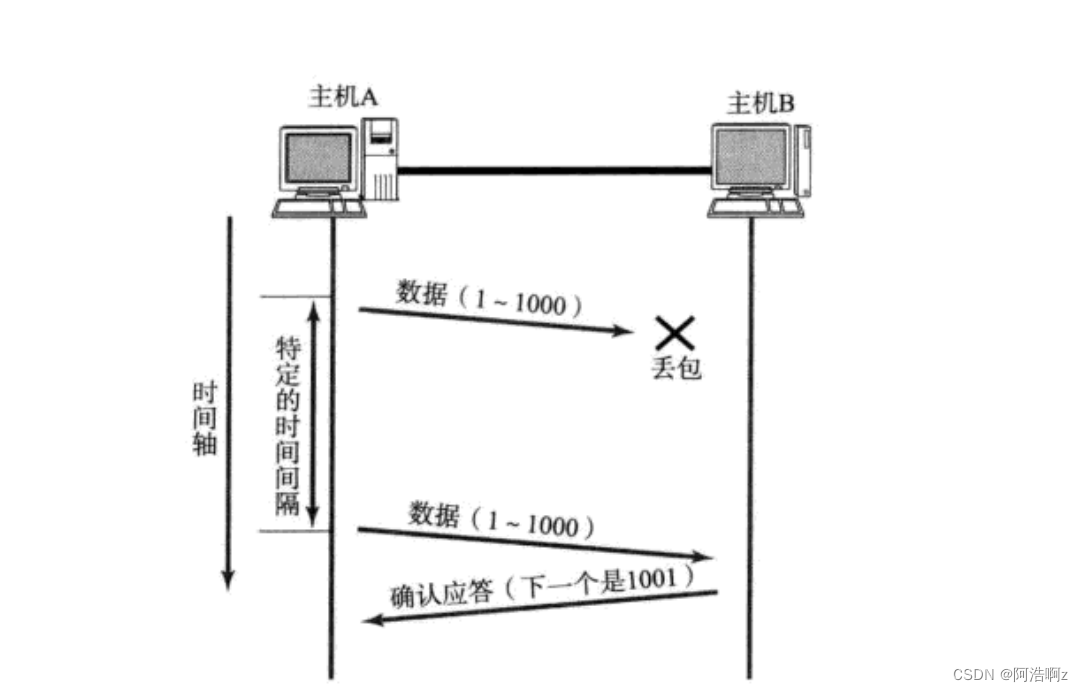
超时重传机制
第一种:主机A给主机B发送数据,但是没有到达主机B,经过特定的时间间隔没有收到来自B的确认应答,就会再次给B发送数据
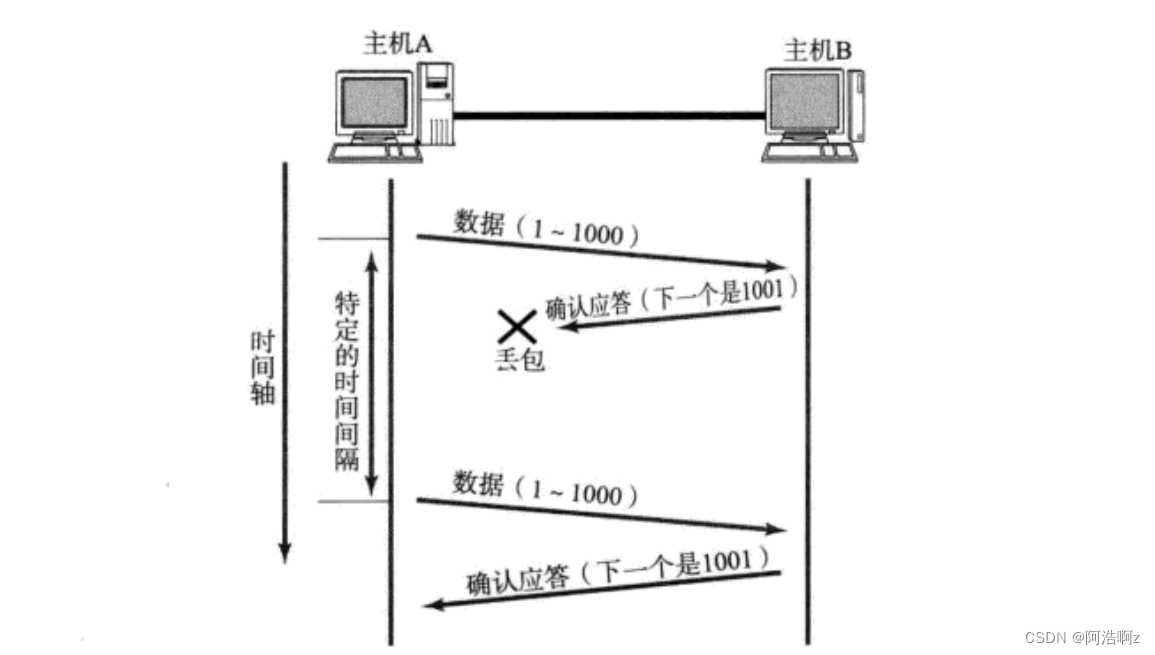
第二种:
主机A给主机B发送数据,主机B收到了给A确认应答,但是A没有收到,在A看来与第一种一样,过段时间再次给B发送数据
-
A是根据时间间隔来判断是否丢包的!!!
-
前面说到,重复也是不可靠的一种,那么超时重传机制中B主机会收到重复数据,就会曾经提到过的序列号来去重
-
被发出的数据不会被立即移除(为了超时重传),需要收到应答才能移除
连接管理机制
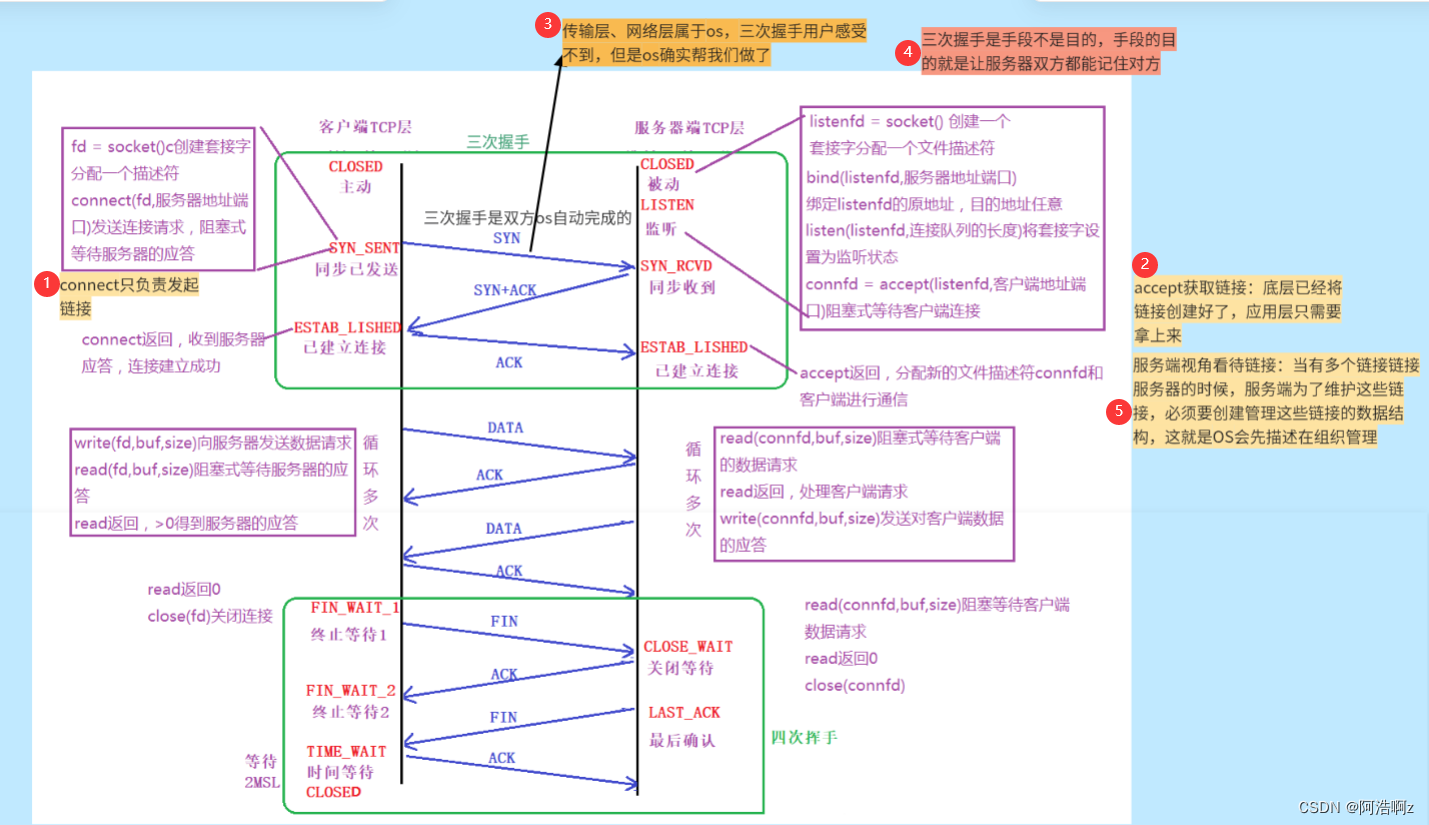
三次握手
在前面我提到过:三次握手只是手段不是目的,也就是说,三次握手不一定会成功
在上图中三条报文前两条不用担心丢失(超时重传机制),需要考虑的是第三条报文丢失的情况
为什么需要三次握手?一次?两次?四次不可以吗?
-
一次:不可以
如果只需要一次握手,就会导致服务器收到来自同一个客户端多个链接,服务器需要维护这些链接,成本太高----SYN洪水 -
两次:不可以
1.二次握手的话可能出现第二条报文丢失的情况,导致客户端再给服务器发送连接请求,出现同上的问题
2.还有一种情况是第一条报文因为延迟长时间未到服务端,客户端再发一条报文与服务端建立连接进行通信,当断开连接的时候,之前的第一条报文到了,服务端就会给客户端发送带有ACK字段的报文,但是此时客户端已经断开连接了,这就会让服务端一直等待,造成资源浪费 -
三次:可行
1.通信之前,需要验证信道是全双工的,而三次握手就是用最小成本验证该信道是通畅的
第一条可以验证:客户端是可以发送的,服务端是可以收到的
第二条可以验证:客户端是可以收到的,(这里服务端虽然发送了,但是无法确认被客户端收到了)
第三条可以验证:服务端是可以发送的
2.三次握手可以有效防止单主机对服务器进行攻击(最后一条报文保证了客户端先建立好连接,然后服务器建立好连接);保证收到同等伤害 -
四次:可以,但没必要
1.三次握手已经最小成本建立成功了,四次就显得多余了
2.如果是四次握手,那么就会导致最后一条是服务端发送的,如果一直丢失,就会导致服务端连接一一直挂着,与两次握手一样有隐患
四次挥手与地址复用
主动断开的一方,最终状态是TIME_WAIT状态
被动断开的一方,两次挥手完成后,会进入CLOSE_WAIT状态
由于TCP双方对等,主动、被动C/S都有可能
如果服务器出现了大量的close_wait原因有:
1.服务器存在bug,没有做close文件描述符
2.服务器有压力,可能一直推送消息给client,导致来不及close
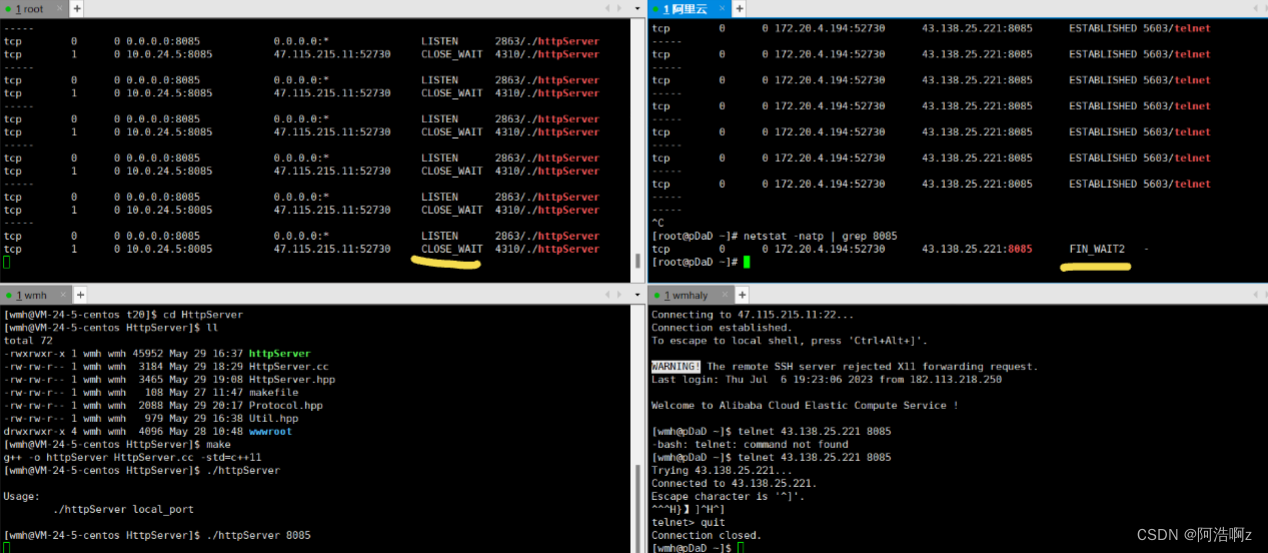
当关闭服务器的时候,系统层面会去执行第三次第四次挥手,完成断开连接
四次挥手已经完成,主动断开的一方会维持一段时间的TIME_WAIT状态,等待两个MSL(maximum segment lifetime)的时间后才能回到CLOSED状态;我们使用Ctrl+C终止了server, 所以server是主动关闭连接的一方, 在TIME_WAIT期间仍然不能再次监听同样的server端口,也就不能绑定同样的端口
解决办法:添加地址复用
使用setsockopt()设置socket描述符的 选项SO_REUSEADDR为1, 表示允许创建端口号相同但IP地址不同的多个socket描述符
//设置地址复用
int opt=1;
setsockopt(listen_sockfd_,SOL_SOCKET,SO_REUSEADDR,&opt,sizeof(opt));
为什么是TIME_WAIT的时间是2MSL?
- MSL是TCP报文的最大生存时间, 因此TIME_WAIT持续存在2MSL的话
- 就能保证在两个传输方向上的尚未被接收或迟到的报文段都已经消失(否则服务器立刻重启, 可能会收到
- 来自上一个进程的迟到的数据, 但是这种数据很可能是错误的;同时也是在理论上保证最后一个报文可靠到达(假设最后一个ACK丢失, 那么服务器会再重发一个FIN. 这时虽然客户端的进程不在了, 但是TCP连接还在, 仍然可以重发LAST_ACK);
流量控制
接收端处理数据的速度是有限的. 如果发送端发的太快, 导致接收端的缓冲区被充满, 这个时候如果发送端继续发送,就会造成丢包, 继而引起丢包重传等等一系列连锁反应.因此TCP支持根据接收端的处理能力, 来决定发送端的发送速度. 这个机制就叫做流量控制(Flow Control)
- 接收端将自己可以接收的缓冲区大小放入 TCP 首部中的 “窗口大小” 字段, 通过ACK端通知发送端
- 窗口大小字段越大, 说明网络的吞吐量越高;
- 接收端一旦发现自己的缓冲区快满了, 就会将窗口大小设置成一个更小的值通知给发送端;
- 发送端接受到这个窗口之后, 就会减慢自己的发送速度;
- 如果接收端缓冲区满了, 就会将窗口置为0; 这时发送方不再发送数据, 但是需要定期发送一个窗口探测数据段, 使接收端把窗口大小告诉发送端.
在TCP三次握手阶段,完成窗口大小的交换,未来通信的时候就可以控制发送数据大小
滑动窗口
前面我提到过:发送的数据未收到应答之前,会将数据暂时保存起来,而保存的位置就是发送缓冲区根据课本上讲的,可以将缓冲区分为以下几段
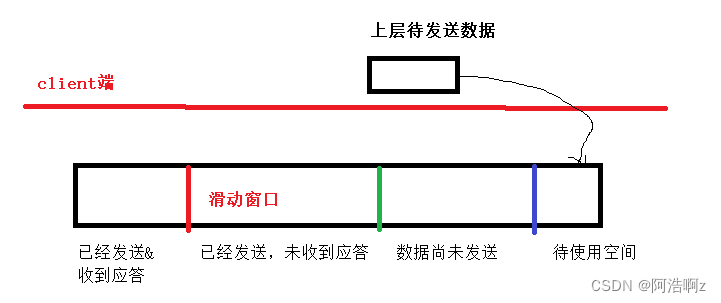
对上图进行抽象,可以处理成一个一维数组:而滑动窗口就是就是两个数组下标,滑动窗口的移动就是数据下标的更新

滑动窗口的大小如何设置?
滑动窗口大小和对方接受能力有关
滑动窗口会向左移动吗?一直向右移动吗?
不会向左,也不会一直向右移动,存在不动的情况
窗口会一直不变吗?会变大吗?会变小吗?依据是什么
不会一直不变,可能变大,可能变小;依据是对方接收缓冲区大小

如上图:当收到对方发来的确认序号的时候,滑动窗口start端会向右移动,如果接收方此时接受了但是没有取出,就会导致接收方缓冲区越来越小,也就导致了发送方窗口大小越来越小。
当越来越小缩小为0的时候,接收方把它接受缓冲区数据全拿走,这个时候发送方滑动窗口就会增大
收到应答确认的时候,如果不是最左端发送的报文的确认,而是中间的,结尾的该怎么办?要滑动吗?
以上存在两种丢包情况:
- 数据没丢,只是应答丢失了
根据确认应答机制,确认序号表示当前序号+1之前的数据已经收到了,不需要再管之前的,这个时候滑动窗口start端直接到确认序号的下一位置进行滑动 - 数据丢了
如果数据真的丢了,那么中间报文收到的确认序号一定是前面丢失报文的序号,连续收到三个一样的,这个时候就需要补发了,滑动窗口不需要滑动
滑动窗口一直滑动,剩余空间不够了怎么办
滑动窗口其实被内核组织成环形结构
拥塞控制与拥塞窗口
TCP连接的可靠性不仅考虑了主机之间的问题,也考虑了网络的问题
少量的丢包, 我们仅仅是触发超时重传; 大量的丢包, 我们就认为网络拥塞
如果网络比较拥堵,发送大量数据可能会引起大量丢包,TCP引入慢启动机制, 先发少量的数据, 探探路, 摸清当前的网络拥堵状态, 再决定按照多大的速度传输数据
发送数据不仅要考虑点到点,还需要考虑网络状况:引入拥塞窗口,发送开始的时候, 定义拥塞窗口大小为1,指数级别的. “慢启动” 只是指初使时慢, 但是增长速度非常快.当拥塞窗口超过阈值的时候, 不再按照指数方式增长, 而是按照线性方式增长
发送方---->网络---->接收方;
发送方拥有滑动窗口;网络拥有拥塞窗口;接受方有自己的窗口大小
滑动窗口大小取决于:MIN(拥塞窗口,接收方窗口大小)
拥塞控制, 归根结底是TCP协议想尽可能快的把数据传输给对方, 但是又要避免给网络造成太大压力的折中方案
延迟应答
如果接收数据的主机立刻返回ACK应答, 这时候返回的窗口可能比较小.
- 假设接收端缓冲区为1M. 一次收到了500K的数据; 如果立刻应答, 返回的窗口就是500K;
- 但实际上可能处理端处理的速度很快, 10ms之内就把500K数据从缓冲区消费掉了;
- 在这种情况下, 接收端处理还远没有达到自己的极限, 即使窗口再放大一些, 也能处理过来;
如果接收端稍微等一会再应答, 比如等待200ms再应答, 那么这个时候返回的窗口大小就是1M;
窗口越大, 网络吞吐量就越大, 传输效率就越高. 我们的目标是在保证网络不拥塞的情况下尽量提高传输效率;
那么所有的包都可以延迟应答么? 肯定也不是;
- 数量限制: 每隔N个包就应答一次;
- 时间限制: 超过最大延迟时间就应答一次;
具体的数量和超时时间, 依操作系统不同也有差异; 一般N取2, 超时时间取200ms,需要考虑超时重传机制
捎带应答
三次握手中服务端回复的时候SYN+ACK就是捎带应答,不是一问一答
面向字节流
创建一个TCP的socket, 同时在内核中创建一个发送缓冲区和一个接收缓冲区;
- 调用write时, 数据会先写入发送缓冲区中;
- 如果发送的字节数太长, 会被拆分成多个TCP的数据包发出;
- 如果发送的字节数太短, 就会先在缓冲区里等待, 等到缓冲区长度差不多了, 或者其他合适的时机发送出去;
- 接收数据的时候, 数据也是从网卡驱动程序到达内核的接收缓冲区;
- 然后应用程序可以调用read从接收缓冲区拿数据;
- 另一方面, TCP的一个连接, 既有发送缓冲区, 也有接收缓冲区, 那么对于这一个连接, 既可以读数据, 也可以写数据. 这个概念叫做 全双工
由于缓冲区的存在, TCP程序的读和写不需要一一匹配,:这就是面向字节流
- 写100个字节数据时, 可以调用一次write写100个字节, 也可以调用100次write, 每次写一个字节;
- 读100个字节数据时, 也完全不需要考虑写的时候是怎么写的, 既可以一次read 100个字节, 也可以一次read一个字节, 重复100次;
粘包问题
首先要明确, 粘包问题中的 “包” , 是指的应用层的数据包.
在TCP的协议头中, 没有如同UDP一样的 “报文长度” 这样的字段, 但是有一个序号这样的字段.
站在传输层的角度, TCP是一个一个报文过来的. 按照序号排好序放在缓冲区中.
站在应用层的角度, 看到的只是一串连续的字节数据.
那么应用程序看到了这么一连串的字节数据, 就不知道从哪个部分开始到哪个部分, 是一个完整的应用层数据包.
如何避免粘包问题呢? 归根结底就是一句话, 明确两个包之间的边界.
1.对于定长的包, 保证每次都按固定大小读取即可; 每次读取就从缓冲区从头开始按sizeof(包长)依次读取即可;
2.对于变长的包, 可以在包头的位置, 约定一个包总长度的字段, 从而就知道了包的结束位置;
3.对于变长的包, 还可以在包和包之间使用明确的分隔符(应用层协议, 是程序猿自己来定的, 只要保证分隔符不和正文冲突即可)
TCP异常情况
- 进程终止: 进程终止会释放文件描述符, 仍然可以发送FIN. 和正常关闭没有什么区别.
- 机器重启: 和进程终止的情况相同.
- 机器掉电/网线断开: 接收端认为连接还在, 一旦接收端有写入操作, 接收端发现连接已经不在了, 就会进行reset. 即使没有写入操作, TCP自己也内置了一个保活定时器, 会定期询问对方是否还在. 如果对方不在, 也会把连接释放.
另外, 应用层的某些协议, 也有一些这样的检测机制. 例如HTTP长连接中, 也会定期检测对方的状态. 例如QQ, 在QQ断线之后, 也会定期尝试重新连接.
TCP小结
为什么TCP这么复杂? 因为要保证可靠性, 同时又尽可能的提高性能.
可靠性:校验和、序列号(按序到达)、确认应答、超时重发、连接管理、流量控制、拥塞控制
提高性能:滑动窗口、快速重传、延迟应答、捎带应答(流量控制、拥塞控制)
其他:定时器(超时重传定时器, 保活定时器, TIME_WAIT定时器等)
连接队列与listen 的第二个参数
TCP协议要为上层维护一个链接队列,这个队列不能没有也不能太长,这个连接队列叫做全连接队列,相当于咱们日常吃饭排队等待
int listen(int sockfd, int backlog);
sockfd:表示要监听的套接字描述符。
backlog:指定在等待被接受的连接队列中允许的最大连接数。
TCP底层允许backlog+1个完整链接,后续来的都只能是半连接状态,即三次握手中的SYN_RCVD状态 ,并添加到半连接队列,如果后续还没完成连接,就会被Server关闭,转变为close_wait状态
Linux内核协议栈为一个tcp连接管理使用两个队列:
- 半链接队列:当客户端发起 SYN 到服务端,服务端收到以后会回 ACK 和自己的 SYN。这时服务端这边的 TCP 从 listen 状态变为 SYN_RCVD ,此时会将这个连接信息放入【半连接队列】
- 全连接队列(accpetd队列)用来保存处于established状态,包含了服务端所有完成了三次握手,但是还未被应用调用 accept 取走的连接队列,这也说明了,accept并不参与三次握手
全连接队列的长度是listen的第二个参数+1 - 全连接队列满了的时候, 就无法继续让当前连接的状态进入 established 状态了
区别全连接队列中的连接和已建立好的连接:就像是排队等待的人和已经进入饭店吃饭的人;这个队列相当于一个连接缓冲区,上层服务完毕的时候可以从缓冲区取出新连接
相关文章:
Linux【网络编程】之深入理解TCP协议
Linux【网络编程】之深入理解TCP协议 TCP协议TCP协议段格式4位首部长度---TCP报头长度信息 TCP可靠性(确认应答)&& 提高传输效率确认应答(ACK)机制32位序号与32为确认序号 16位窗口大小---自己接收缓冲区剩余空间的大小16位紧急指针---紧急数据处…...

如何克服看到别人优于自己而感到的焦虑和迷茫?
文章目录 每日一句正能量前言简述自己的感受怎么做如何调整自己的心态后记 每日一句正能量 行动是至于恐惧的良药,而犹豫、拖延,将不断滋养恐惧。 前言 虽然清楚知识需要靠时间沉淀,但在看到自己做不出来的题别人会做,自己写不出的…...
浅谈React中的ref和useRef
目录 什么是useRef? 使用 ref 访问 DOM 元素 Ref和useRef之间的区别 Ref和useRef的使用案例 善用工具 结论 在各种 JavaScript 库和框架中,React 因其开发人员友好性和支持性而得到认可。 大多数开发人员发现 React 非常舒适且可扩展,…...

Linux C 获取主机网卡名及 IP 的几种方法
在进行 Linux 网络编程时,经常会需要获取本机 IP 地址,除了常规的读取配置文件外,本文罗列几种个人所知的编程常用方法,仅供参考,如有错误请指出。 方法一:使用 ioctl() 获取本地 IP 地址 Linux 下可以使用…...

解密外接显卡:笔记本能否接外置显卡?如何连接外接显卡?
伴随着电脑游戏和图形处理的需求不断增加,很多笔记本电脑使用者开始考虑是否能够通过外接显卡来提升性能。然而,外接显卡对于笔记本电脑是否可行,以及如何连接外接显卡,对于很多人来说仍然是一个迷。本文将为您揭秘外接显卡的奥秘…...
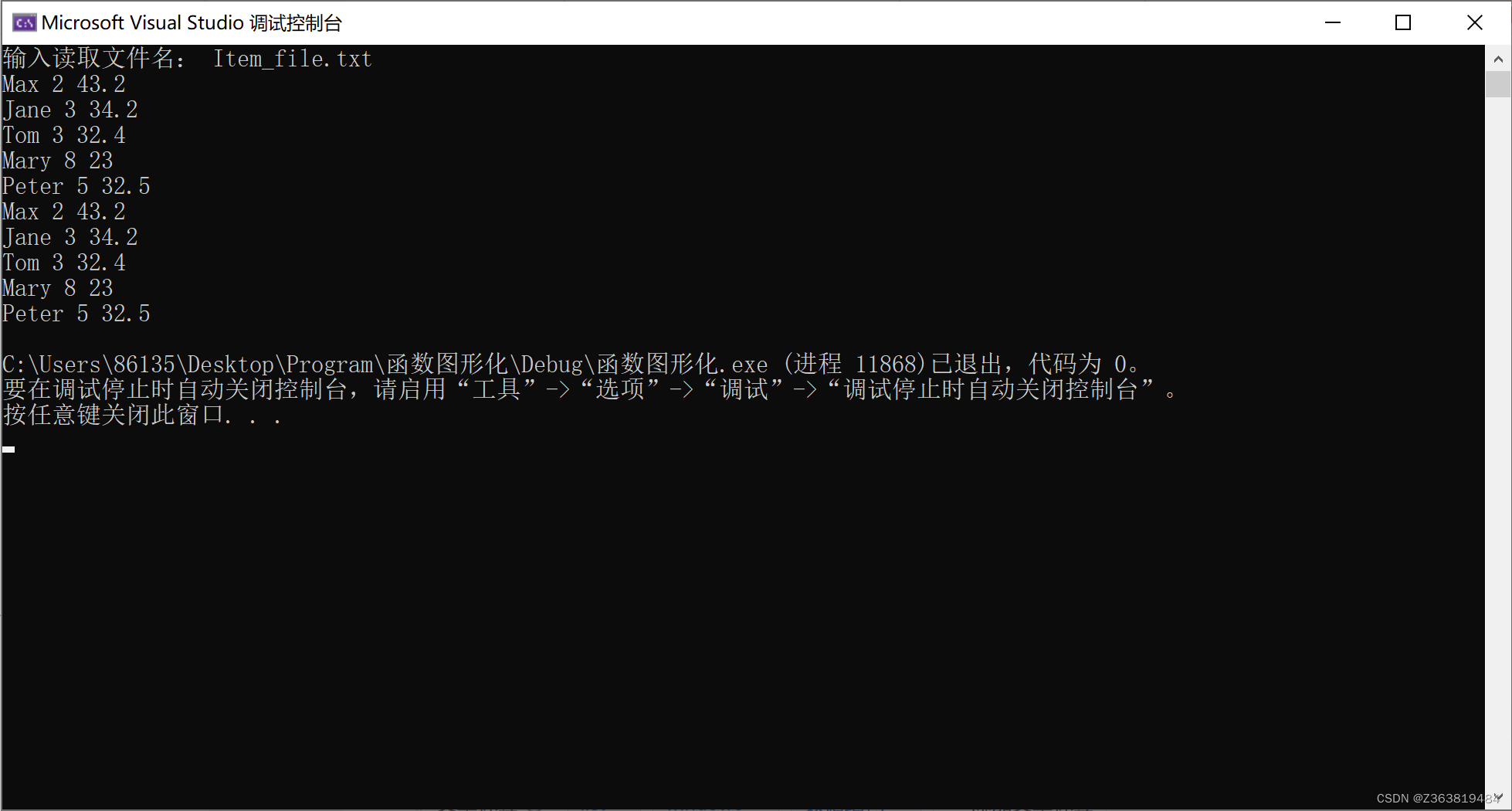
list与erase()
运行代码: //list与erase() #include"std_lib_facilities.h" //声明Item类 struct Item {string name;int iid;double value;Item():name(" "),iid(0),value(0.0){}Item(string ss,int ii,double vv):name(ss),iid(ii),value(vv){}friend istr…...
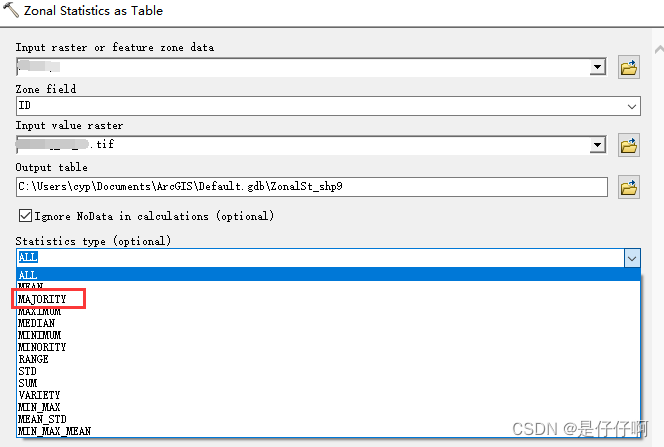
Arcgis 分区统计majority参数统计问题
利用Arcgis 进行分区统计时,需要统计不同矢量区域中栅格数据的众数(majority),出现无法统计majority参数问题解决 解决:利用copy raster工具,将原始栅格数据 64bit转为16bit...
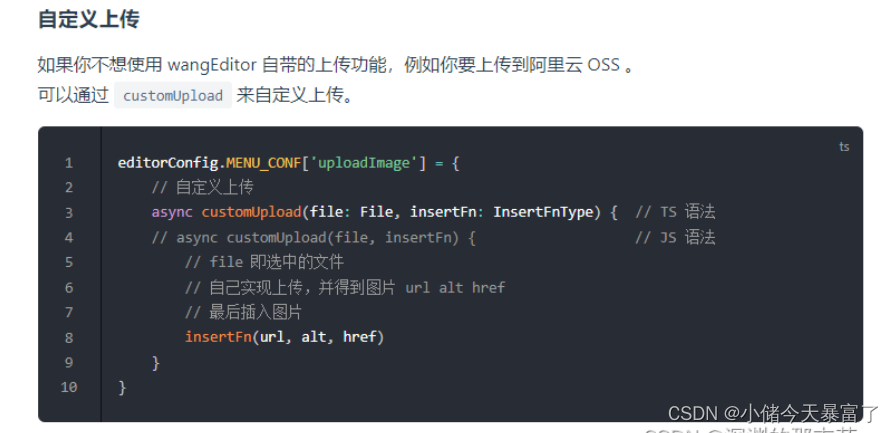
vue2+wangEditor5富文本编辑器(图片视频自定义上传七牛云/服务器)
1、安装使用 安装 yarn add wangeditor/editor # 或者 npm install wangeditor/editor --save yarn add wangeditor/editor-for-vue # 或者 npm install wangeditor/editor-for-vue --save在main.js中引入样式 import wangeditor/editor/dist/css/style.css在使用编辑器的页…...

shell脚本练习--安全封堵脚本,使用firewalld实现
一.什么是安全封堵 安全封堵(security hardening)是指采取一系列措施来增强系统的安全性,防止潜在的攻击和漏洞利用。以下是一些常见的安全封堵措施: 更新和修补系统:定期更新操作系统和软件包以获取最新的安全补丁和修…...

双端冒泡排序
双端冒泡排序是对传统冒泡排序的改进,其主要改进在于同时从两端开始排序,相对于传统冒泡排序每次只从一端开始排序,这样可以减少排序的遍历次数。 传统冒泡排序从一端开始,每次将最大(或最小)的元素冒泡到…...

如何在Visual Studio Code中用Mocha对TypeScript进行测试
目录 使用TypeScript编写测试用例 在Visual Studio Code中使用调试器在线调试代码 首先,本文不是一篇介绍有关TypeScript、JavaScript或其它编程语言数据结构和算法的文章。如果你正在准备一场面试,或者学习某一个课程,互联网上可以找到许多…...

GO中Json的解析
一个json字串,想要拿到其中的数据,就需要解析出来 一、适用于json数据的结构已知的情况下 使用json.Unmarshal将json数据解析到结构体中 根据json字串数据的格式定义struct,用来保存解码后的值。这里首先定义了一个与要解析的数据结构一样的…...

chatgpt 提示词-关于数据科学的 75个词语
这里有 75 个 chatgpt 提示,可以立即将其用于数据科学或数据分析等。 1. 伪装成一个SQL终端 提示:假设您是示例数据库前的 SQL 终端。该数据库包含名为“用户”、“项目”、“订单”、“评级”的表。我将输入查询,您将用终端显示的内容进行…...

(自控原理)控制系统的数学模型
目录 一、时域数学模型 1、线性元件微分方程的建立 2、微分方程的求解方法编辑 3、非线性微分方程的线性化 二、复域数学模型 1、传递函数的定义 2、传递函数的标准形式 3、系统的典型环节的传递函数 4、传递函数的性质 5、控制系统数学模型的建立 6、由传递函数求…...

Webpack5 cacheGroups
文章目录 一、 cacheGroups是什么?二、怎么使用cacheGroups?三、cacheGroups实际应用之一? 一、 cacheGroups是什么? 在Webpack 5中,cacheGroups是用于配置代码拆分的规则,它可以帮助你更细粒度地控制生成…...
每篇10题)
前端面试的游览器部分(5)每篇10题
41.什么是浏览器的同步和异步加载脚本的区别?你更倾向于使用哪种方式,并解释原因。 浏览器的同步和异步加载脚本是两种不同的脚本加载方式,它们的主要区别在于加载脚本时是否阻塞页面的解析和渲染。 同步加载脚本: 同步加载脚本…...

数据挖掘七种常用的方法汇总
数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。这个定义包括几层含义:数据源必须是真实的、大量的、含噪声的;发现的是用户…...
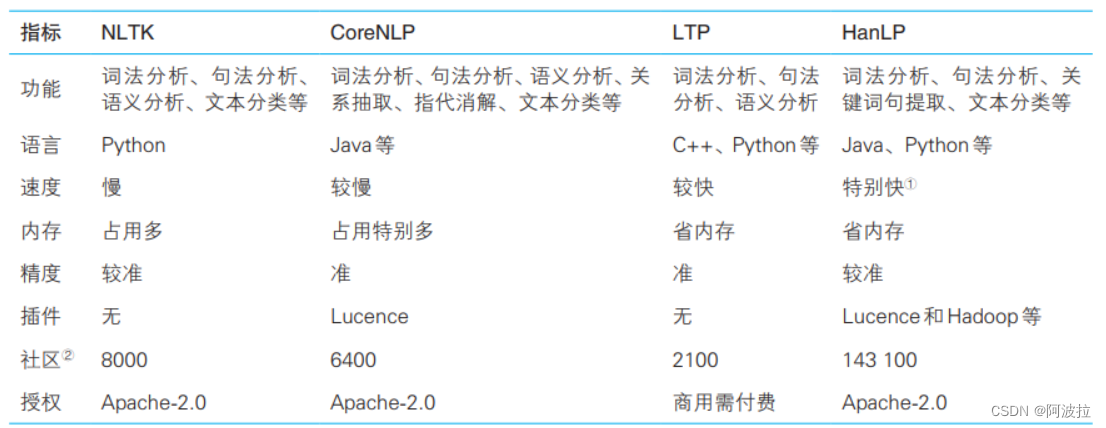
自然语言处理学习笔记(二)————语料库与开源工具
目录 1.语料库 2.语料库建设 (1)规范制定 (2)人员培训 (3)人工标注 3.中文处理中的常见语料库 (1)中文分词语料库 (2)词性标注语料库 (3…...

Rust dyn - 动态分发 trait 对象
dyn - 动态分发 trait 对象 dyn是关键字,用于指示一个类型是动态分发(dynamic dispatch),也就是说,它是通过trait object实现的。这意味着这个类型在编译期间不确定,只有在运行时才能确定。 practice tr…...

uniapp 中过滤获得数组中某个对象里id:1的数据
// 假设studentData是包含多个学生信息的数组 const studentData [{id: 1, name: 小明, age: 18},{id: 2, name: 小红, age: 20},{id: 3, name: 小刚, age: 19},{id: 4, name: 小李, age: 22}, ]; // 过滤获取id为1的学生信息 const result studentData.filter(item > ite…...

Qt 6.2 静态编译实战:从环境配置到IDE集成的完整指南
1. 环境准备:搭建静态编译的基础舞台 第一次尝试Qt静态编译时,我盯着满屏的英文文档和报错信息整整发呆了半小时。作为过来人,我理解那种面对复杂工具链的无力感。别担心,跟着我的步骤走,咱们用最稳妥的方式把地基打牢…...

SuperMap iDesktopX 实战:三步解锁高德POI数据,赋能地理信息应用
1. 为什么你需要掌握高德POI数据获取技能 作为一名GIS分析师或数据工程师,相信你经常遇到这样的场景:老板突然要求分析某区域的商业分布情况,或者规划部门急需某类公共设施的服务覆盖范围报告。这时候,POI(Point of In…...

从零搭建Adams-Matlab机器人联合仿真环境:一份详尽的配置指南
1. 为什么需要Adams-Matlab联合仿真 作为一名在机器人领域摸爬滚打多年的工程师,我深刻理解动力学仿真和控制系统设计之间的鸿沟。Adams擅长多体动力学分析,能精确模拟机械系统的运动学和动力学特性;Matlab则是控制算法开发和验证的利器。但…...

C# 在工控机中的多任务并发处理技术
在工业自动化领域,工控机(工业计算机)作为工业控制和数据采集的核心设备,承担着大量的数据处理任务。随着智能制造和工业4.0的推进,工控机需要处理的任务越来越复杂,涉及到对设备的实时监控、数据采集、分析与处理、报警等多项工作。在这种背景下,多任务并发处理技术成为…...

实战教程:用 Python 从 0 到 1 实现一个具备联网搜索能力的 Agent
实战教程:用 Python 从 0 到 1 实现一个具备联网搜索能力的 Agent 1. 核心概念 在当今人工智能技术飞速发展的时代,“Agent”(智能体)已经成为了一个炙手可热的概念。简单来说,Agent 是一个能够感知环境、做出决策并执行行动的自主实体。当我们赋予 Agent 联网搜索的能力…...

5分钟极速部署:为Windows 11 LTSC系统解锁微软商店完整生态
5分钟极速部署:为Windows 11 LTSC系统解锁微软商店完整生态 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 当企业管理员面对Windows 11 L…...

自主智能体是什么?为什么是下一代 AI 形态
文章目录前言一、先搞懂:自主智能体到底是什么?(人话版)1.1 官方定义(看完就忘版)1.2 通俗类比(秒懂版)1.3 核心特征:5大"超能力"二、灵魂拷问:自主…...

别再每次新建项目都配一遍了!用VS2022属性表一劳永逸搞定OpenCV环境
VS2022属性表实战:打造可复用的OpenCV开发环境模板 每次新建项目都要重新配置OpenCV环境?这简直是开发者的噩梦。想象一下,你正在为一个紧急项目赶工,却被重复的环境配置拖慢了进度——这种低效操作早该被淘汰了。本文将带你用VS…...

G-Helper:华硕笔记本用户如何告别臃肿控制软件,实现极致性能优化?
G-Helper:华硕笔记本用户如何告别臃肿控制软件,实现极致性能优化? 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting acro…...

终极指南:5个技巧快速掌握FitGirl游戏启动器
终极指南:5个技巧快速掌握FitGirl游戏启动器 【免费下载链接】Fitgirl-Repack-Launcher An Electron launcher designed specifically for FitGirl Repacks, utilizing pure vanilla JavaScript, HTML, and CSS for optimal performance and customization 项目地…...