ConcurrentHashMap1.7 源码浅析
分析过HashMap的1.7的版本的结构,但是HashMap是线程不安全的,多线程触发扩容还会发生死循环问题,那么ConcurrentHashMap 就是解决这个问题的,这是一个线程安全的Map,那么对应的内部实现是怎么样的,简单分析下,和HashMap相同的位置就不多做重复分析了
构造方法
这是个最基础的构造方法,需要的参数有容量,扩容因子,这是和HashMap相同的地方,但是多了一个并发水平选项,这里默认值是16,也就是并发粒度的控制,最多可以16个线程同时加锁对Map处理,我们看下具体怎么做的。
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)throw new IllegalArgumentException();if (concurrencyLevel > MAX_SEGMENTS)concurrencyLevel = MAX_SEGMENTS;// Find power-of-two sizes best matching argumentsint sshift = 0;int ssize = 1;// 小于并发等级就左移动一位,*2倍在得到一个大于等于这个数的2的n次幂while (ssize < concurrencyLevel) {++sshift;ssize <<= 1;}// sshift 记录的是对应的多少位// ssize记录的就是处理过的并发水平this.segmentShift = 32 - sshift;this.segmentMask = ssize - 1;if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;// 这里在计算分段之后,每段的长度int c = initialCapacity / ssize;// 这里向上取下,因为上面int处理的直接向下取整了if (c * ssize < initialCapacity)++c;// 最小的分段长度为2int cap = MIN_SEGMENT_TABLE_CAPACITY;// 如果小于需要的值,就左移动一位,扩大二倍,知道大于等于需要的while (cap < c)cap <<= 1;// create segments and segments[0]// 对应的段,段的数组长度就是cap,长度的HashEntrySegment<K,V> s0 =new Segment<K,V>(loadFactor, (int)(cap * loadFactor),(HashEntry<K,V>[])new HashEntry[cap]);// 然后创建段的数组,长度就是之前处理过的并发粒度,可以保证锁段的时候并发粒度大于等于需要的Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];// cas 赋值UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]// 赋值给Map的成员变量this.segments = ss;}
从构造方法来看,就是对HashMap进行分段了,控制实际的容量大于等于需要的容量,并发粒度也是大于等于需要的粒度,这样可以对每一个段进行加锁,保证并发安全,又能保证一定的并发粒度,后面看下是怎么进行插入和获取的,是怎么进行加锁的,怎么保证数据安全的?
Segment 的结构
看下主要的结构,继承了ReentrantLock,同样维护了Map的扩容因子,扩容阈值,元素数量,Entry数组这些
static final class Segment<K,V> extends ReentrantLock implements Serializable {// 在预扫描之前尝试锁定的最大次数static final int MAX_SCAN_RETRIES =Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;// 对应的Entry数组,volatile修饰,修改数据对其他线程可见,及时刷新回主存// transient修饰,序列化忽略这个transient volatile HashEntry<K,V>[] table;// 分段内的元素的数量transient int count;// 修改相关的计数transient int modCount;// 扩容阈值transient int threshold;// 扩容因子final float loadFactor;}
put 方法分析
老规矩先从主要方法put开始看,put里面一般能看到存储结构,查找顺序等关键信息
public V put(K key, V value) {Segment<K,V> s;if (value == null)throw new NullPointerException();int hash = hash(key);// 计算位于哪个segmentint j = (hash >>> segmentShift) & segmentMask;// segment未初始化化的时候,进行初始化if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegments = ensureSegment(j);// 元素插入return s.put(key, hash, value, false);
}final V put(K key, int hash, V value, boolean onlyIfAbsent) {// 尝试获取锁,获取到了,第一步获取不到就是后面还是在获取,// 存在尝试次数,尝试次数完了之后死等,如果直接得到锁,返回的node就是null// 如果开始没得到锁,并且开始数组没数据的时候,会得到一个nodeHashEntry<K,V> node = tryLock() ? null :scanAndLockForPut(key, hash, value);// 上一步走完就是获取到锁了V oldValue;try {HashEntry<K,V>[] tab = table;int index = (tab.length - 1) & hash;// 获取对应下标的值,valitale保证及时可见HashEntry<K,V> first = entryAt(tab, index);for (HashEntry<K,V> e = first;;) {// 数组上有值if (e != null) {K k;// 遇见相同keyif ((k = e.key) == key ||(e.hash == hash && key.equals(k))) {//记录旧的值oldValue = e.value;if (!onlyIfAbsent) {e.value = value;++modCount;}break;}// 遍历下一个e = e.next;}else {// 数组上对应位置为空if (node != null)// 头插法,上面获取到了nodenode.setNext(first);elsenode = new HashEntry<K,V>(hash, key, value, first);int c = count + 1;if (c > threshold && tab.length < MAXIMUM_CAPACITY)// 大于扩容因子进行扩容,单独分析rehash(node);else// 否则直接添加setEntryAt(tab, index, node);++modCount;count = c;oldValue = null;break;}}} finally {// 解锁unlock();}return oldValue;
}
put方法就是先检查对应的segment是不是初始化了,未初始化的先进性初始化,初始化的时候按照第一个进行复制,然后cas赋值到对应位置,然后执行实际的插入逻辑,插入的时候先进行获取lock,因为Segnment继承的ReentrantLock,直接使用tryLock(),和lock()进行获取的非公平锁,获取之后对对应的值进行添加
ensureSegment 初始化segment分析
private Segment<K,V> ensureSegment(int k) {final Segment<K,V>[] ss = this.segments;long u = (k << SSHIFT) + SBASE; // raw offsetSegment<K,V> seg;if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {// 用构造方法时创建的第一个segment作为原型,复制一个segment出来Segment<K,V> proto = ss[0]; // use segment 0 as prototypeint cap = proto.table.length;float lf = proto.loadFactor;int threshold = (int)(cap * lf);// 对应的数组HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) { // recheckSegment<K,V> s = new Segment<K,V>(lf, threshold, tab);// cas赋值segmentwhile ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) {if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))break;}}}return seg;
}
scanAndLockForPut� 这里也是在获取锁,能抽空的话就会返回一个HashEntry
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {// 寻找hash对应的entryHashEntry<K,V> first = entryForHash(this, hash);HashEntry<K,V> e = first;HashEntry<K,V> node = null;int retries = -1; // negative while locating node// 获取不到锁,就一直获取while (!tryLock()) {HashEntry<K,V> f; // to recheck first below// 尝试次数if (retries < 0) {// 这里的e是遍历的当前节点if (e == null) {if (node == null) // speculatively create node// 这里的创建Entry应该就是简单的没别的事情做?充分利用下node = new HashEntry<K,V>(hash, key, value, null);retries = 0;}// 直接遇到相同的了else if (key.equals(e.key))retries = 0;// 遍历下一个elsee = e.next;}// 超过获取锁的最大尝试次数了else if (++retries > MAX_SCAN_RETRIES) {lock();break;}// 这里在判断尝试次数是不是为0,为0的上面两种,一种是对应数组位置无值,一种是有相同// key,可以直接替换的,//然后 后面的&& 判断了下是不是自己,如果不是自己插入的,更换下头节点,可能是别的线程// 插入的else if ((retries & 1) == 0 &&(f = entryForHash(this, hash)) != first) {e = first = f; // re-traverse if entry changedretries = -1;}}return node;
}
static final <K,V> HashEntry<K,V> entryForHash(Segment<K,V> seg, int h) {HashEntry<K,V>[] tab;// 判断段是不是空,里面数组是不是空,不空的时候获取对应的下标return (seg == null || (tab = seg.table) == null) ? null :(HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
}
�
rehash(node) 扩容方法分析
private void rehash(HashEntry<K,V> node) {HashEntry<K,V>[] oldTable = table;// 原来的容量int oldCapacity = oldTable.length;// 新的容量,扩大为2倍int newCapacity = oldCapacity << 1;threshold = (int)(newCapacity * loadFactor);//新的数组HashEntry<K,V>[] newTable =(HashEntry<K,V>[]) new HashEntry[newCapacity];int sizeMask = newCapacity - 1;// 遍历旧的for (int i = 0; i < oldCapacity ; i++) {HashEntry<K,V> e = oldTable[i];if (e != null) {HashEntry<K,V> next = e.next;int idx = e.hash & sizeMask;if (next == null) // Single node on list// 只有一个newTable[idx] = e;else { // Reuse consecutive sequence at same slot// 记录的当前遍历的头节点eHashEntry<K,V> lastRun = e;int lastIdx = idx;// 这里在遍历链表,last就是当前遍历到的for (HashEntry<K,V> last = next;last != null;last = last.next) {// 计算下标int k = last.hash & sizeMask;// 这里计算的是新下标的数据if (k != lastIdx) {// 不在现在这个位置的话,lastIdx = k;// 这个在记录链表最后一个不在本位置的节点// 获取这个引用的意义就在于,后面的不需要转移,直接就一串带走lastRun = last;}}// 然后赋值给新的位置newTable[lastIdx] = lastRun;// Clone remaining nodes// 然后重新遍历了一遍,遇到之前lastRun节点停止for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {V v = p.value;int h = p.hash;int k = h & sizeMask;// 采用头插法进行遍历插入到对应的链表中HashEntry<K,V> n = newTable[k];newTable[k] = new HashEntry<K,V>(h, p.key, v, n);}}}}// 扩容之后把node插入进去int nodeIndex = node.hash & sizeMask; // add the new nodenode.setNext(newTable[nodeIndex]);newTable[nodeIndex] = node;table = newTable;
}
可以看到resize基本等同HashMap,不过在resize里面把node进行插入的
get 方法
可以看到get方法比较简单,不需要加锁,通过volitale修饰的key,然后UNSAFE.getObjectVolatile 拿到对应的值
public V get(Object key) {Segment<K,V> s; // manually integrate access methods to reduce overheadHashEntry<K,V>[] tab;int h = hash(key);long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&(tab = s.table) != null) {for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);e != null; e = e.next) {K k;if ((k = e.key) == key || (e.hash == h && key.equals(k)))return e.value;}}return null;}
总结
整体总结下,ConcurrentHashMap 通过引入Segment概念来对HashMap进行分段,等于有了很多个小的HashMap,然后又继承了ReentrantLock,通过lock来保证put的数据安全性,并发粒度通过设置segment的数组长度来控制,默认16,可以自定义,不过也是2的n次幂,类似于原来hashmap的数组大小取值算法,对于segment里面,数组的最小长度为2,这个数组长度和segment的长度决定了容量大小,这里会大于等于设置的值,segment数组是不可变的,也就是map构造完成的时候,并发粒度就确定了,segment的长度大小不可变,扩容是在扩容的内部的HashMap,也就是HashEntry数组,整体就是hash计算了两次,第一次确认在那个segment,然后再计算落到那个段里面的哪个位置。
相关文章:

ConcurrentHashMap1.7 源码浅析
分析过HashMap的1.7的版本的结构,但是HashMap是线程不安全的,多线程触发扩容还会发生死循环问题,那么ConcurrentHashMap 就是解决这个问题的,这是一个线程安全的Map,那么对应的内部实现是怎么样的,简单分析…...

跨境电商时代的安全护航
随着跨境电商业务的蓬勃发展,网络安全问题日益突出。为了保障个人信息的安全和商业竞争的公平性,防关联浏览器和多开浏览器的需求日益增长。本文将为您介绍隐擎fox指纹浏览器,探讨其在跨境电商时代的重要作用,以及如何通过该浏览器…...

JavaScript Es6 _1 笔记
JavaScript Es6 _1 笔记 学习作用域、变量提升、闭包等语言特征,加深对 JavaScript 的理解,掌握变量赋值、函数声明的简洁语法,降低代码的冗余度。 理解作用域对程序执行的影响能够分析程序执行的作用域范围理解闭包本质,利用闭包…...

结构体和 Json 相互转换(序列化反序列化)
关于 JSON 数据 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。易于人阅读和编写。同时也 易于机器解析和生成。RESTfull Api 接口中返回的数据都是 json 数据。 Json 的基本格式如下: { "a": "Hello", "b": "…...

【力扣刷题 | 第二十四天】
目录 前言: 416. 分割等和子集 - 力扣(LeetCode) 总结 前言: 今晚我们爆刷动态规划类型的题目。 416. 分割等和子集 - 力扣(LeetCode) 给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这…...
(常用库))
PyTorch使用(一)(常用库)
1.各大模型库 hub:简单来说就是专门为PyTorch集成的算法模型库 网站:GitHub - pytorch/hub: Submission to https://pytorch.org/hub/ Model Zoo:这个平台上提供预训练模型,在每个模型上,会标注出这个模型在GitHub的标…...

React ~ React Router 6
React Router 6 VS React Router 5.x 内置组件的变化; 移除<Switch /> , 新增<Routes />语法的变化; component { About } 变为 element { <About /> }新增多个hook官方明确推荐函数式组件了! 一级路由(变化) 安装路由 npm i react-router-dom (默认是最…...
【LeetCode每日一题】——304.二维区域和检索-矩阵不可变
文章目录 一【题目类别】二【题目难度】三【题目编号】四【题目描述】五【题目示例】六【题目提示】七【解题思路】八【时间频度】九【代码实现】十【提交结果】 一【题目类别】 矩阵 二【题目难度】 中等 三【题目编号】 304.二维区域和检索-矩阵不可变 四【题目描述】 …...
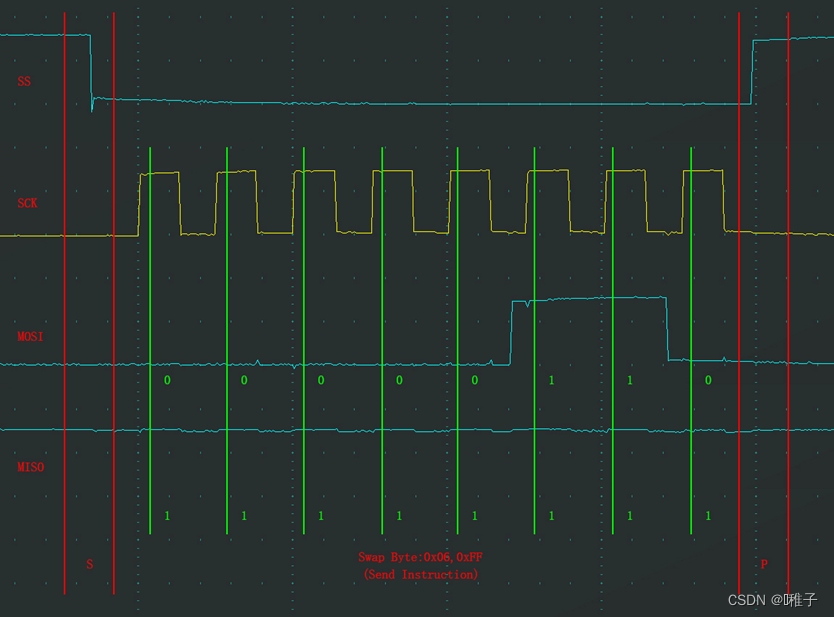
硬件串口通信协议学习(UART、IIC、SPI、CAN)
0.前言 学习资料:江协科技的个人空间-江协科技个人主页-哔哩哔哩视频 通信的目的:将一个设备的数据传送到另一个设备,扩展硬件系统通信协议:制定通信的规则,通信双方按照协议规则进行数据收发 全双工:通信…...

第一章-JavaScript基础进阶part2:事件
文章目录 概念一、注册事件(绑定事件)1.1 addEventListener事件监听 二、删除事件(解绑)三、DOM事件流四、事件对象event4.1 e.target与this与e.currentTarget的区别4.2 事件对象的常见属性 五、阻止事件默认行为及冒泡六、事件委…...

如何优雅的使用后端接口
优雅的后端接口 一个后端接口大致分为四个部分:接口地址(url)、接口请求方式(get、post等)、请求数据(request)、响 应数据(response)。 一、URL & Method Rest 设计风格 》 Restful API 简单理解: URI 是用来唯一标志一个互联网资源;Me…...
)
QEMU源码全解析25 —— QOM介绍(14)
接前一篇文章:QEMU源码全解析24 —— QOM介绍(13) 本文内容参考: 《趣谈Linux操作系统》 —— 刘超,极客时间 《QEMU/KVM》源码解析与应用 —— 李强,机械工业出版社 特此致谢! 本文开始对于…...

TopK问题
topK问题: N个数找最大或者最小的前k个。 例子: 优质筛选(店面的排名) 10000个数,找出最大的前10个数 解决思路:建立大堆,然后pop9次 但是有些场景,上面的思路…...
接口自动化测试-Postman+Newman+Git+Jenkins实战集成(详细)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、Postman 创建…...
)
CMake 学习笔记 (Generator Expressions)
CMake 学习笔记 (Generator Expressions) Generator Expressions 可以认为是一种特殊的变量,它会在编译阶段求值。通常用在 target_link_libraries(), target_include_directories(), target_compile_definitions() 上。 用 Generator Expr…...
提高测试用例质量的6大注意事项
在软件测试中,经常会遇到测试用例设计不完整,用例没有完全覆盖需求等问题,这样往往容易造成测试工作效率低下,不能及时发现项目问题,无形中增加了项目风险。 因此提高测试用例质量,就显得尤为重要。一般来说…...

2023牛客暑期多校训练营6 A-Tree (kruskal重构树))
文章目录 题目大意题解参考代码 题目大意 ( 0 ≤ a i ≤ 1 ) , ( 1 ≤ c o s t i ≤ 1 0 9 ) (0\leq a_i\leq 1),(1 \leq cost_i\leq 10^9) (0≤ai≤1),(1≤costi≤109) 题解 提供一种新的算法,kruskal重构树。 该算法重新构树,按边权排序每一条边…...
软件测试—支付功能测试
有人问过我这样一个问题:作为一个支付平台,接入了快钱、易宝或直连银行等多家的渠道,内在的产品流程是自己的。业内有什么比较好的测试办法,来测试各渠道及其支持的银行通道呢? 回答:对支付平台而言&#…...

自动化测试的统筹规划
背景 回顾以前自动化测试编写的经历,主要是以开发者自驱动的方式进行,测试的编写随心而动,没有规划,也没有章法,这样就面临如下的一些问题: 测试用例设计不到位,覆盖不全,或者不够…...
、django中如何开启事务)
外键字段的增删改查、多表查询(子查询和连表查询、正反向、聚合查询、 分组查询、 F与Q查询)、django中如何开启事务
一、 外键字段的增删改查 1.多对多的外键增删改查图书和作者是多对多,借助于第三张表实现的,如果想绑定图书和作者的关系,本质上就是在操作第三方表2.如何操作第三张表问题:让你给图书添加一个作者,他俩的关系可是多对…...

K8s Pod CrashLoopBackOff 根因分析
Kubernetes作为容器编排领域的标杆,其Pod的CrashLoopBackOff状态是运维人员最头疼的问题之一。当Pod反复崩溃重启时,不仅影响业务连续性,还可能隐藏着更深层次的系统隐患。本文将深入剖析这一现象的典型诱因,帮助开发者快速定位问…...

Serilog:从结构化日志认知到 .NET 工程落地痛
1. 前言 本文详细介绍如何使用 kylin v10 iso 文件构建出 docker image,docker 版本为 20.10.7。 2. 构建 yum 离线源 2.1. 挂载 ISO 文件 mount Kylin-Server-V10-GFB-Release-030-ARM64.iso /media 2.2. 添加离线 repo 文件 在/etc/yum.repos.d/下创建kylin-local…...

零基础如何选择全栈低代码平台?iVX/CodeWave/OneCode保姆级入门指南
零基础如何选择全栈低代码平台?iVX/CodeWave/OneCode保姆级入门指南 当你想快速开发一个应用却不懂编程时,全栈低代码平台就像给你的想象力插上了翅膀。我至今记得第一次用可视化工具完成订单管理系统时的成就感——原本需要专业团队开发两周的功能&…...
)
从社交网络到推荐系统:图解GNN消息传播的5个真实应用场景(含PyG核心API速查)
从社交网络到推荐系统:图解GNN消息传播的5个真实应用场景(含PyG核心API速查) 当你在社交平台看到"可能认识的人"推荐,或在电商网站收到精准的商品推荐时,背后很可能隐藏着一个强大的图神经网络(G…...

Agent Client Protocol 全景解析哪
1. 核心概念 在 Antigravity 中,技能系统分为两层: Skills (全局库):实际的代码、脚本和指南,存储在系统级目录(如 ~/.gemini/antigravity/skills)。它们是“能力”的本体。 Workflows (项目级):…...

袁永福 电子病历,医疗信息化吓
在AI辅助开发的语境下,Skill就是一个包含了领域知识、最佳实践、代码模板的知识包。 以"DAO层CRUD生成"为例,一个Skill包含: /mnt/skills/dao-crud/ ├── SKILL.md # 使用说明 │ ├── 何时使用这个Skill │ …...

你的电脑会呼吸吗?用FanControl打造智能散热系统的终极指南
你的电脑会呼吸吗?用FanControl打造智能散热系统的终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendi…...

SensitivityMatcher:终极免费鼠标灵敏度跨游戏转换工具
SensitivityMatcher:终极免费鼠标灵敏度跨游戏转换工具 【免费下载链接】SensitivityMatcher Script that can be used to convert your mouse sensitivity between different 3D games. 项目地址: https://gitcode.com/gh_mirrors/se/SensitivityMatcher 还…...
)
实时语义理解+物理世界反馈=下一代产线?SITS2026现场演示的AI原生控制环(毫秒级动态拓扑重构)
第一章:SITS2026分享:AI原生智能制造应用 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026大会上,多家头部制造企业与AI基础设施厂商联合展示了“AI原生”范式在产线调度、质量检测、设备预测性维护等核心场景的深度落地实践。该范…...

Win11Debloat终极指南:三步释放Windows 11隐藏性能的完整解决方案
Win11Debloat终极指南:三步释放Windows 11隐藏性能的完整解决方案 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declu…...