pyspark使用XGboost训练模型实例
遇到一个还不错的使用Xgboost训练模型的githubhttps://github.com/MachineLP/Spark-/tree/master/pyspark-xgboost
1、这是一个跑通的代码实例,使用的是泰坦尼克生还数据,分类模型。
这里使用了Pipeline来封装特征处理和模型训练步骤,保存为pipelineModel。
注意这里加载xgboost依赖的jar包和zip包的方法。
#这是用 pipeline 包装了XGBOOST的例子。 此路通!import os
import sys
import time
import pandas as pd
import numpy as np
import pyspark.sql.types as typ
import pyspark.ml.feature as ft
from pyspark.sql.functions import isnan, isnullfrom pyspark.sql.types import StructType, StructFieldfrom pyspark.sql.types import *
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml import Pipeline
from pyspark.sql.functions import col
from pyspark.sql import SparkSessionos.environ['PYSPARK_PYTHON'] = 'Python3.7/bin/python'
os.environ['PYSPARK_SUBMIT_ARGS'] = '--jars xgboost4j-spark-0.90.jar,xgboost4j-0.90.jar pyspark-shell'spark = SparkSession \.builder \.appName("PySpark XGBOOST Titanic") \.config('spark.driver.allowMultipleContexts', 'true') \.config('spark.pyspark.python', 'Python3.7/bin/python') \.config('spark.yarn.dist.archives', 'hdfs://ns62007/user/dmc_adm/_PYSPARK_ENV/Python3.7.zip#Python3.7') \.config('spark.executorEnv.PYSPARK_PYTHON', 'Python3.7/bin/python') \.config('spark.sql.autoBroadcastJoinThreshold', '-1') \.enableHiveSupport() \.getOrCreate()spark.sparkContext.addPyFile("sparkxgb.zip")schema = StructType([StructField("PassengerId", DoubleType()),StructField("Survived", DoubleType()),StructField("Pclass", DoubleType()),StructField("Name", StringType()),StructField("Sex", StringType()),StructField("Age", DoubleType()),StructField("SibSp", DoubleType()),StructField("Parch", DoubleType()),StructField("Ticket", StringType()),StructField("Fare", DoubleType()),StructField("Cabin", StringType()),StructField("Embarked", StringType())])upload_file = "titanic/train.csv"
hdfs_path = "hdfs://tmp/gao/dev_data/dmb_upload_data/"
file_path = os.path.join(hdfs_path, upload_file.split("/")[-1])df_raw = spark\.read\.option("header", "true")\.schema(schema)\.csv(file_path)df_raw.show(20)
df = df_raw.na.fill(0)sexIndexer = StringIndexer()\.setInputCol("Sex")\.setOutputCol("SexIndex")\.setHandleInvalid("keep")cabinIndexer = StringIndexer()\.setInputCol("Cabin")\.setOutputCol("CabinIndex")\.setHandleInvalid("keep")embarkedIndexer = StringIndexer()\.setInputCol("Embarked")\.setHandleInvalid("keep")# .setOutputCol("EmbarkedIndex")\vectorAssembler = VectorAssembler()\.setInputCols(["Pclass", "Age", "SibSp", "Parch", "Fare"])\.setOutputCol("features")from sparkxgb import XGBoostClassifier
xgboost = XGBoostClassifier(maxDepth=3,missing=float(0.0),featuresCol="features",labelCol="Survived"
)pipeline = Pipeline(stages=[vectorAssembler, xgboost])trainDF, testDF = df.randomSplit([0.8, 0.2], seed=24)
trainDF.show(2)
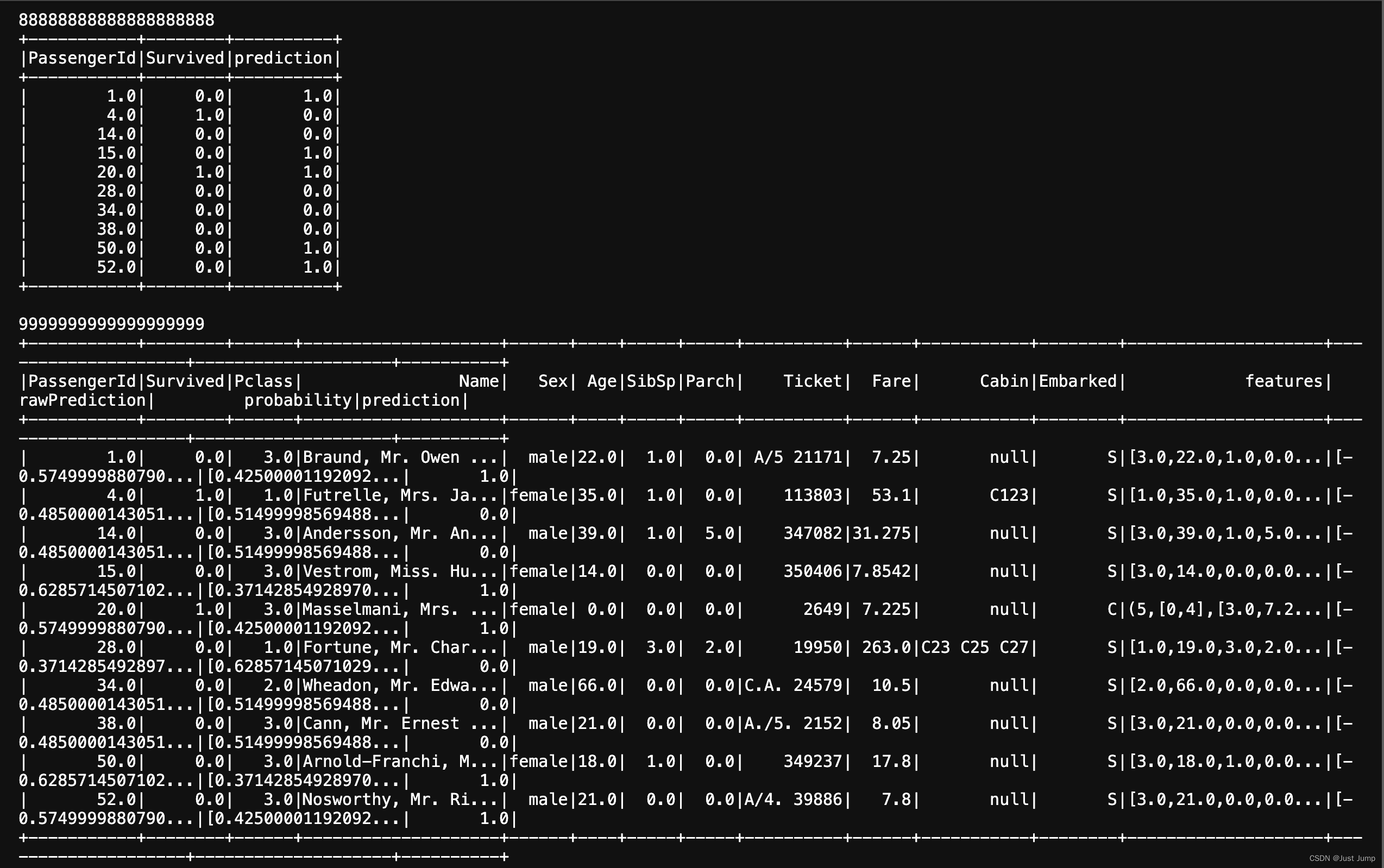
model = pipeline.fit(trainDF)print (88888888888888888888)
model.transform(testDF).select(col("PassengerId"), col("Survived"), col("prediction")).show()
print (9999999999999999999)# Write model/classifier
model.write().overwrite().save(os.path.join(hdfs_path,"xgboost_class_test"))from pyspark.ml import PipelineModel
model1 = PipelineModel.load(os.path.join(hdfs_path,"xgboost_class_test"))
model1.transform(testDF).show()
这是执行结果:

2、当然也可以不用pipeline封装,直接训练xgboost模型,并保存。
但这里遇到无法加载训练好的xgb模型的问题。
# Train a xgboost model
from pyspark.ml.feature import VectorAssembler, StringIndexer, OneHotEncoder, StandardScaler
from pyspark.ml import Pipeline
from sparkxgb import XGBoostClassifierassembler = VectorAssembler(inputCols=[ 'Pclass', 'Age', 'SibSp', 'Parch','Fare'],outputCol="features", handleInvalid="skip")xgboost = XGBoostClassifier(maxDepth=3,missing=float(0.0),featuresCol="features", labelCol="Survived")# pipeline = Pipeline(stages=[assembler, xgboost])
# trained_model = pipeline.fit(data)td = assembler.transform(data)
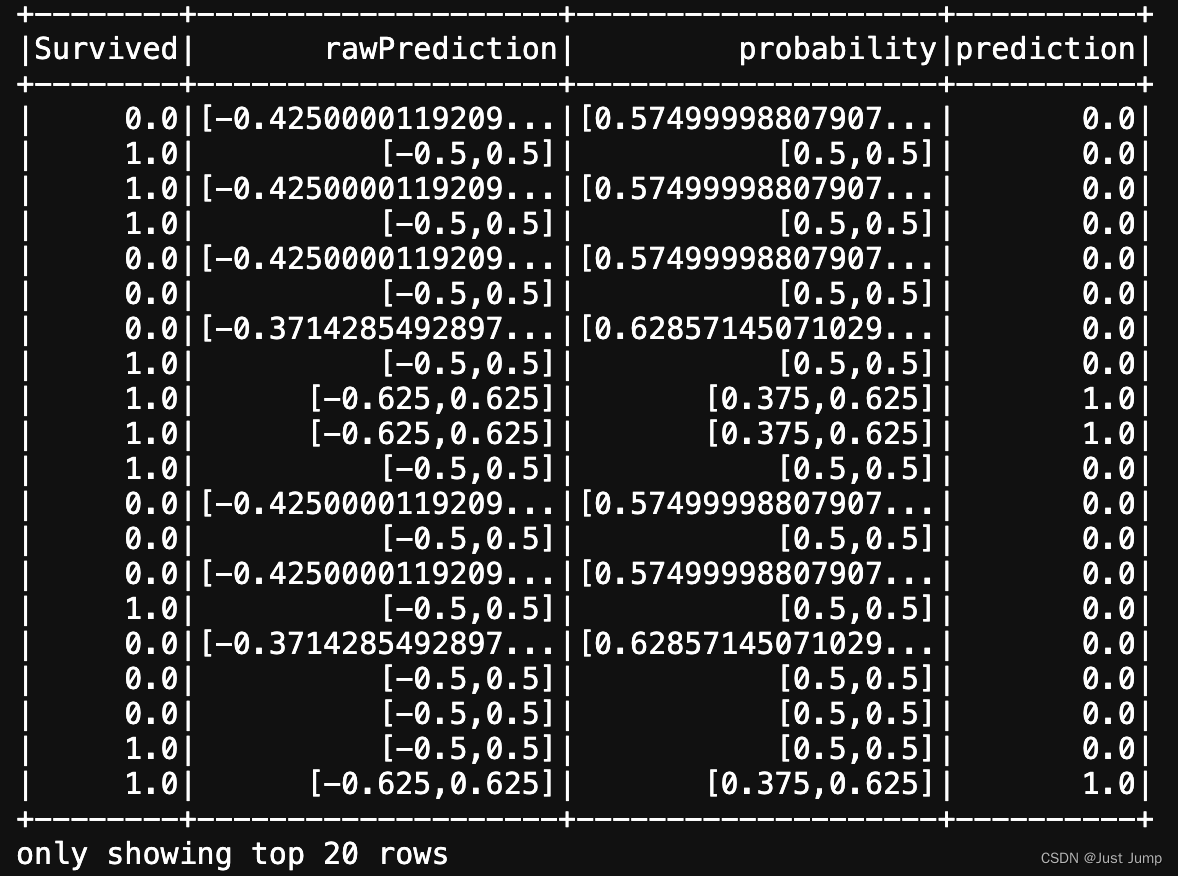
trained_raw_model = xgboost.fit(td)result = trained_raw_model.transform(td)
result.select(["Survived", "rawPrediction", "probability", "prediction"]).show()# save trained model to local disk
trained_raw_model.nativeBooster.saveModel("outputmodel.xgboost")# 无法加载已经训练好的XGB模型
from sparkxgb import XGBoostClassifier,XGBoostClassificationModel
model1= XGBoostClassificationModel.load("outputmodel.xgboost")
model1.transform(td).show()这是运行结果:
这里报错,无法使用 XGBoostClassificationModel加载已经训练好的XGB模型。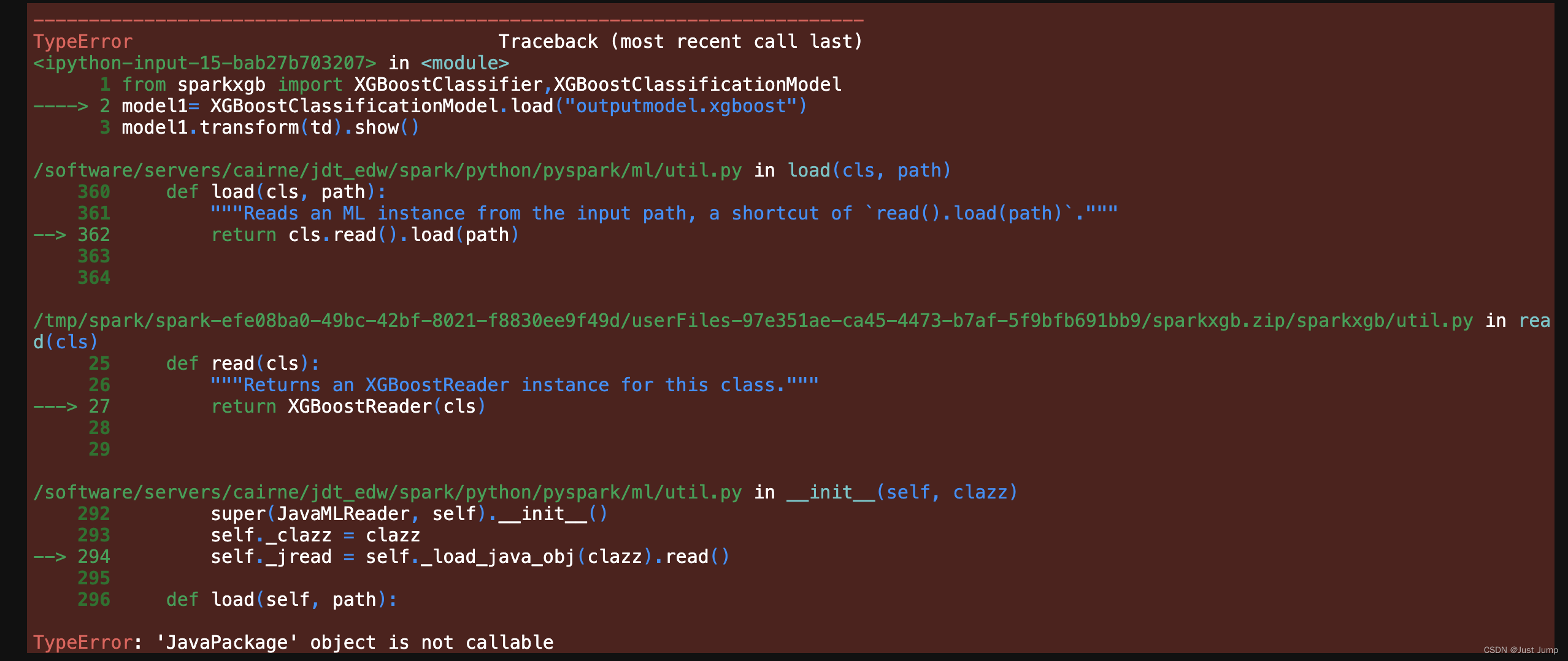
相关文章:
pyspark使用XGboost训练模型实例
遇到一个还不错的使用Xgboost训练模型的githubhttps://github.com/MachineLP/Spark-/tree/master/pyspark-xgboost 1、这是一个跑通的代码实例,使用的是泰坦尼克生还数据,分类模型。 这里使用了Pipeline来封装特征处理和模型训练步骤,保存为…...
完整模型的训练套路
从心所欲 不逾矩 天大地大 皆可去 一、官方模型的初使用 使用VGG16模型 VGG模型使用代码示例: import torchvision.models from torch import nndataset torchvision.datasets.CIFAR10(/cifar10, False, transformtorchvision.transforms.ToTensor())vgg16_true …...

PtahDAO:全球首个DAO治理资产信托计划的金融平台
金融科技是当今世界最具创新力和影响力的领域之一,区块链技术作为金融科技的核心驱动力,正在颠覆传统的金融模式,为全球用户提供更加普惠、便捷、安全的金融服务。在这个变革的浪潮中,PtahDAO(普塔道)作为全…...
从零搭建一个react + electron项目
最近打算搭建一个react electron的项目,发现并不是那么傻瓜式 于是记录一下自己的实践步骤 通过create-react-app 创建react项目 npx create-react-app my-app 安装electron依赖 npm i electron -D暴露react项目的配置文件(这一步看自己需求,…...

MATLAB /Simulink 快速开发STM32(使用st官方工具 STM32-MAT/TARGET),以及开发过程
配置好环境以后就是开发: stm32cube配置芯片,打开matlab添加ioc文件,写处理逻辑,生成代码,下载到板子中去。 配置需要注意事项: STM32CUBEMAX6.5.0 MABLAB2022BkeilV5.2 Matlab生成的代码CTRLB 其中关键的…...
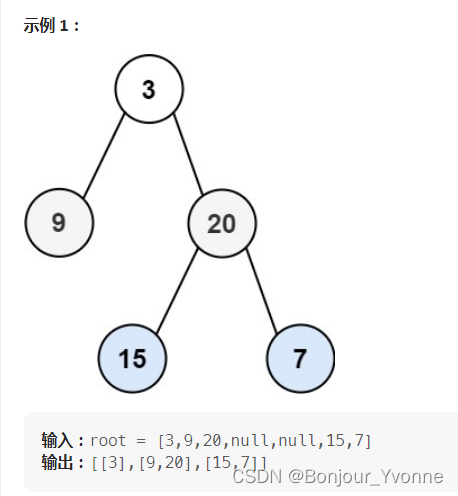
LeetCode 热题 100 JavaScript--102. 二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]] 示例 2: 输入:root [1…...

常见Git命令
Git常见命令 1. 添加单个文件 git add a.txt2. 添加多个文件 git add a.txt b.txt c.txt3. 添加(commit)修改,此时修改还未push到服务器上 git commit -m "修改了a.txt内容"4. 提交(push)修改,此时修改会同步到服务器上 git push5. 查看当…...

在C语言中调用汇编语言的函数
在C语言中调用汇编文件中的函数,要做的主要工作有两个: 一是在C语言中声明函数原型,并加extern关键字; 二是在汇编中用EXPORT导出函数名,并用该函数名作为汇编代码段的标识,最后用mov pc, lr返回。然后&a…...
Delphi Professional Crack,IDE插件开发和扩展IDE
Delphi Professional Crack,IDE插件开发和扩展IDE 构建具有强大视觉设计功能的单源多平台本机应用程序。 Delphi帮助您使用Object Pascal为Windows、Mac、Mobile、IoT和Linux构建和更新数据丰富、超连接、可视化的应用程序。Delphi Professional适合个人开发人员和小型团队构建…...

程序框架-公共MONO模块
作用:让没有继承MONO的类可以开启协程,可以update更新,可以统一管理update MonoController脚本继承MonoBehaviour使得脚本过场不移除,并通过UnityAction可以添加多个函数(多播委托),实现Update…...

采用鲁棒随机森林实现的流异常检测:Python应用的一种新型机器学习方法
在数字化和互联网化日益普遍的现代社会,处理海量的网络流量数据是网络安全分析中不可或缺的一部分。流异常检测是一种重要的技术,用于发现可能的安全威胁,例如:网络攻击、恶意行为和系统故障等。随机森林是一种普遍用于解决这类问题的机器学习算法。在本文中,我们将介绍一…...

缓存友好在实际编程中的重要性
引入 当CPU执行程序时,需要频繁地访问主存储器(RAM)中的数据和指令。然而,主存储器的访问速度相对较慢,与CPU的运算速度相比存在显著差异,每次都从主存中读取数据都会导致相对较长的等待时间,从…...
uni-ajax网络请求库使用
uni-ajax网络请求库使用 uni-ajax是什么 uni-ajax是基于 Promise 的轻量级 uni-app 网络请求库,具有开箱即用、轻量高效、灵活开发 特点。 下面是安装和使用教程 安装该请求库到项目中 npm install uni-ajax编辑工具类request.js // ajax.js// 引入 uni-ajax 模块 import ajax…...
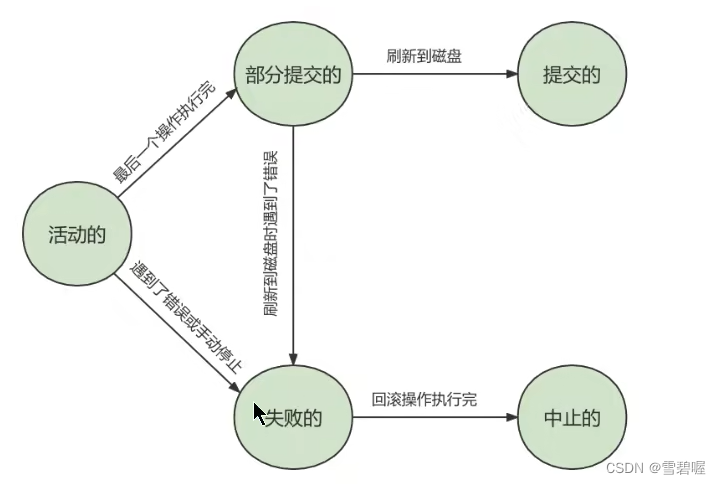
MYSQL进阶-事务
1.什么是数据库事务? 事务是一个不可分割的数据库操作序列,也是数据库并发控制的基本单位,其执 行的结果必须使数据库从一种一致性状态变到另一种一致性状态。事务是逻辑上 的一组操作,要么都执行,要么都不执行。 事务…...

python 常见数据类型和方法
不可变数据类型 不支持直接增删改 只能查 str 字符串 int 整型 bool 布尔值 None None型特殊常量 tuple 元组(,,,)回到顶部 可变数据类型,支持增删改查 list 列表[,,,] dic 字典{"":"","": ,} set 集合("",""…...

a-date-picker报错TypeError: date4.locale is not a function
问题描述 使用日期选择器,数据从后端获得,再赋值给a-date-picker做数据回显,遇到这个报错,排错后定位到a-date-picker组件本身接收数据的问题。 如果使用了dayjs或moment库来处理时间字符串,并且使用.format对时间数据…...
LNMP安装
目录 1、LNMP简述: 1.1、概述 1.2、LNMP是一个缩写词,及每个字母的含义 1.3、编译安装与yum安装差异 1.4、编译安装的优点 2、通过LNMP创建论坛 2.1、 安装nginx服务 2.1.1、关闭防火墙 2.1.2、创建运行用户 2.1.3、 编译安装 2.1.4、 优化路…...
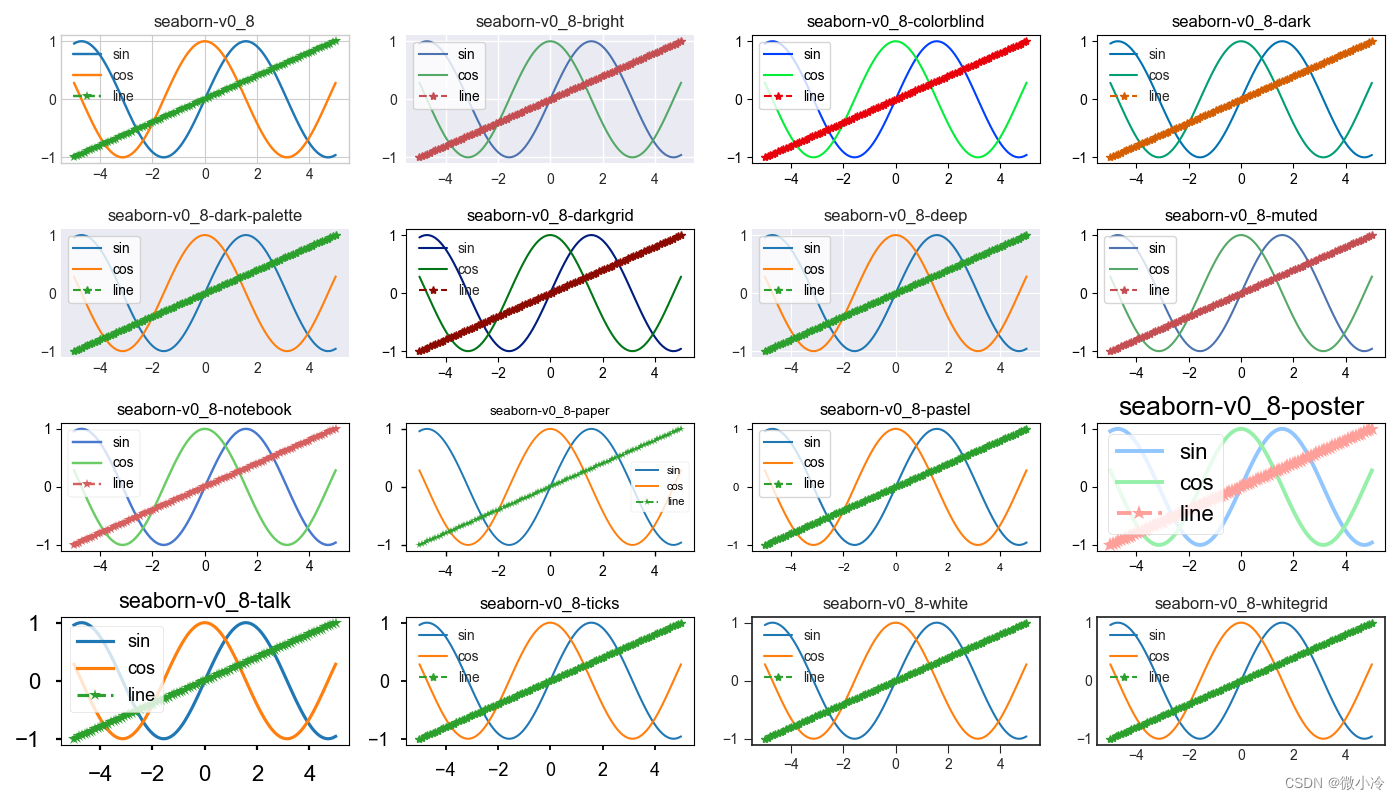
matplotlib绘图风格
文章目录 绘图风格测试代码默认和mpl风格复制风格seaborn风格 绘图风格 matplotlib功能强大,可以定制各种绘图要素,以满足个性化的绘图需求,而更换绘图风格也十分便捷,一个matplotlib.style.use函数轻松搞定,而可用的…...

【初级教程】Appium 启动应用 log 日志分析
刚开始学习 appium 时,老师给我布置了 appium 启动应用 log 分析的作业。由于工作比较忙,再者自己想先动手用 appium 写个公司的 app 的 UI 测试(目前简单的框架基本完成,在不断完善用例管理中)。写这篇文章是为了完成…...

FANUC机器人SRVO-300机械手断裂故障报警原因分析及处理办法
FANUC机器人SRVO-300机械手断裂故障报警原因分析及处理办法 首先,我们查看报警说明书上的介绍: 总结:即在机械手断裂设置为无效时,机器人检测出了机械手断裂信号(不该有的信号,现在检测到了,所以报警) 使机械手断裂设定为无效/有效的具体方法: 按下示教器的MENU菜单…...

SeqGPT-560M效果展示:无需训练的中文文本理解,财经/科技/娱乐分类实测案例
SeqGPT-560M效果展示:无需训练的中文文本理解,财经/科技/娱乐分类实测案例 今天我们来聊聊一个特别省心的AI工具——SeqGPT-560M。你可能听说过很多大模型,但训练它们往往需要准备数据、调参数,费时费力。SeqGPT-560M不一样&…...

OpenClaw+Qwen3-14B组合优化:长文本处理的内存占用实测
OpenClawQwen3-14B组合优化:长文本处理的内存占用实测 1. 为什么需要关注长文本处理的显存占用? 上周我在整理一批技术文档时遇到了一个典型问题:用OpenClaw调用Qwen3-14B处理200页的PDF文件时,系统突然崩溃。查看日志才发现是显…...

什么是OPC
### 先说一个残酷的事实 你在公司干了十年,名片上印着"总监""教授""专家"。 但那些头衔,离职那天就跟你没关系了。 你带过的团队、做过的项目、写过的PPT,公司服务器一关,痕迹全无。 你真正能带走的…...
边缘端适配记录)
万象熔炉 | Anything XL部署教程:ARM架构(Jetson Orin)边缘端适配记录
万象熔炉 | Anything XL部署教程:ARM架构(Jetson Orin)边缘端适配记录 1. 项目简介与核心价值 最近在折腾边缘计算设备,手头的Jetson Orin Nano开发者套件性能不错,但一直想找个能稳定跑起来的图像生成模型。SDXL效果…...

Linux操作系统-系统安装与三种网络模式
本文将指导您在VMware Workstation 16 Pro环境下安装CentOS 7系统,详细介绍从创建虚拟机到完成操作系统安装的完整步骤。一、创建虚拟机1.点击“文件”菜单,选择“创建虚拟机”,然后点击“自定义”开始创建虚拟机。2.点击"浏览"按钮…...

【无标题】1
把AI领域最前沿的技术,最硬核的实现,最有趣的见闻,变成能看懂,能上手,能直接用的内容。把不可能变成产品落地。...

【算法日记 08】一行代码秒杀!当“程序模拟”变成“数学脑筋急转弯”
🤯【算法日记 08】一行代码秒杀!当“程序模拟”变成“数学脑筋急转弯” 📍 场景引入 今天在刷题时,遇到了一个极其“唬人”的题目:题目大意:给定一组正整数,问其中有几个数,可以被分…...

从原理到实战:一文读懂主流交叉验证技术及其Python/R实现
1. 交叉验证的本质与价值 第一次听说"交叉验证"这个词时,我正被一个电商用户流失预测项目折磨得焦头烂额。当时在测试集上的准确率像过山车一样忽高忽低,直到 mentor 扔给我一句:"你该试试 K 折交叉验证"。这个简单的改变…...

避坑指南:在Ubuntu 20.04上安装MinkowskiEngine时,如何解决OpenBLAS依赖导致PyTorch变CPU版的诡异问题
深度解析Ubuntu 20.04安装MinkowskiEngine时的OpenBLAS依赖陷阱与解决方案 在Ubuntu 20.04上配置深度学习环境时,MinkowskiEngine作为处理稀疏3D数据的利器,其安装过程往往暗藏玄机。许多开发者在安装过程中都会遇到一个令人困惑的现象:明明已…...

存算分离,性能跃升:实现查询效率再提升60%
概述 盖雅在腾讯云 TCHouse-D 2.0 基础上无缝升级至 3.0 版本,依托其全新存算分离架构、软硬结合的资源隔离能力与优化的查询引擎,实现了数仓性能与运维效率的双重飞跃。通过原生支持的弹性资源调度,精准匹配月结等高并发峰值需求࿰…...