AOF日志:宕机了,Redis如何避免数据丢失
当服务器宕机后,数据全部丢失:我们很容易想到的一个解决方案是从后端数据库恢复这些数据,但这种方式存在两个问题:一是,需要频繁访问数据库,会给数据库带来巨大的压力;二是,这些数据是从慢速数据库中读取出来的,性能肯定比不上从 Redis 中读取,导致使用这些数据的应用程序响应变慢。所以,对 Redis 来说,实现数据的持久化,避免从后端数据库中进行恢复,是至
关重要的。
目前,Redis 的持久化主要有两大机制,即 AOF 日志和 RDB 快照。
AOF 日志是如何实现的?
说到日志,我们比较熟悉的是数据库的写前日志(Write Ahead Log, WAL),也就是
说,在实际写数据前,先把修改的数据记到日志文件中,以便故障时进行恢复。不过,
AOF 日志正好相反,它是写后日志,“写后”的意思是 Redis 是先执行命令,把数据写入
内存,然后才记录日志,如下图所示:

那 AOF 为什么要先执行命令再记日志呢?要回答这个问题,我们要先知道 AOF 里记录了
什么内容?
传统数据库的日志,例如 redo log(重做日志),记录的是修改后的数据,而 AOF 里记
录的是 Redis 收到的每一条命令,这些命令是以文本形式保存的。
我们以 Redis 收到“set testkey testvalue”命令后记录的日志为例,看看 AOF 日志的内
容。其中,“*3”表示当前命令有三个部分,每部分都是由“$+数字”开头,后面紧跟着
具体的命令、键或值。这里,“数字”表示这部分中的命令、键或值一共有多少字节。例
如,“$3 set”表示这部分有 3 个字节,也就是“set”命令。

但是,为了避免额外的检查开销,Redis 在向 AOF 里面记录日志的时候,并不会先去对这
些命令进行语法检查。所以,如果先记日志再执行命令的话,日志中就有可能记录了错误
的命令,Redis 在使用日志恢复数据时,就可能会出错。
而写后日志这种方式,就是先让系统执行命令,只有命令能执行成功,才会被记录到日志
中,否则,系统就会直接向客户端报错。所以,Redis 使用写后日志这一方式的一大好处
是,可以避免出现记录错误命令的情况。
除此之外,AOF 还有一个好处:它是在命令执行后才记录日志,所以不会阻塞当前的写操
作。
不过,AOF 也有两个潜在的风险 :
首先,如果刚执行完一个命令,还没有来得及记日志就宕机了,那么这个命令和相应的数
据就有丢失的风险。如果此时 Redis 是用作缓存,还可以从后端数据库重新读入数据进行恢复,但是,如果 Redis 是直接用作数据库的话,此时,因为命令没有记入日志,所以就无法用日志进行恢复了。
其次,AOF 虽然避免了对当前命令的阻塞,但可能会给下一个操作带来阻塞风险。这是因
为,AOF 日志也是在主线程中执行的,如果在把日志文件写入磁盘时,磁盘写压力大,就
会导致写盘很慢,进而导致后续的操作也无法执行了
其次,AOF 虽然避免了对当前命令的阻塞,但可能会给下一个操作带来阻塞风险。这是因
为,AOF 日志也是在主线程中执行的,如果在把日志文件写入磁盘时,磁盘写压力大,就
会导致写盘很慢,进而导致后续的操作也无法执行了
三种写回策略
其实,对于这个问题,AOF 机制给我们提供了三个选择,也就是 AOF 配置项
appendfsync 的三个可选值。
Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
Everysec,每秒写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲
区,每隔一秒把缓冲区中的内容写入磁盘;
No,操作系统控制的写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓
冲区,由操作系统决定何时将缓冲区内容写回磁盘
针对避免主线程阻塞和减少数据丢失问题,这三种写回策略都无法做到两全其美。我们来
分析下其中的原因:
“同步写回”可以做到基本不丢数据,但是它在每一个写命令后都有一个慢速的落盘操
作,不可避免地会影响主线程性能;
虽然“操作系统控制的写回”在写完缓冲区后,就可以继续执行后续的命令,但是落盘
的时机已经不在 Redis 手中了,只要 AOF 记录没有写回磁盘,一旦宕机对应的数据就
丢失了;
每秒写回”采用一秒写回一次的频率,避免了“同步写回”的性能开销,虽然减少了
对系统性能的影响,但是如果发生宕机,上一秒内未落盘的命令操作仍然会丢失。所
以,这只能算是,在避免影响主线程性能和避免数据丢失两者间取了个折中。
三种写回策略的优缺点:
我们就可以根据系统对高性能和高可靠性的要求,来选择使用哪种写回策略

但是,按照系统的性能需求选定了写回策略,并不是“高枕无忧”了。毕竟,AOF 是以文
件的形式在记录接收到的所有写命令。随着接收的写命令越来越多,AOF 文件会越来越
大。这也就意味着,我们一定要小心 AOF 文件过大带来的性能问题。
这里的“性能问题”,主要在于以下三个方面:一是,文件系统本身对文件大小有限制,
无法保存过大的文件;二是,如果文件太大,之后再往里面追加命令记录的话,效率也会
变低;三是,如果发生宕机,AOF 中记录的命令要一个个被重新执行,用于故障恢复,如
果日志文件太大,整个恢复过程就会非常缓慢,这就会影响到 Redis 的正常使用。
所以,我们就要采取一定的控制手段,这个时候,AOF 重写机制就登场了。
日志文件太大了怎么办?
简单来说,AOF 重写机制就是在重写时,Redis 根据数据库的现状创建一个新的 AOF 文
件,也就是说,读取数据库中的所有键值对,然后对每一个键值对用一条命令记录它的写
入。比如说,当读取了键值对“testkey”: “testvalue”之后,重写机制会记录 set
testkey testvalue 这条命令。这样,当需要恢复时,可以重新执行该命令,实
现“testkey”: “testvalue”的写入。
为什么重写机制可以把日志文件变小呢? 实际上,重写机制具有“多变一”功能。所谓
的“多变一”,也就是说,旧日志文件中的多条命令,在重写后的新日志中变成了一条命
令。
我们知道,AOF 文件是以追加的方式,逐一记录接收到的写命令的。当一个键值对被多条
写命令反复修改时,AOF 文件会记录相应的多条命令。但是,在重写的时候,是根据这个
键值对当前的最新状态,为它生成对应的写入命令。这样一来,一个键值对在重写日志中
只用一条命令就行了,而且,在日志恢复时,只用执行这条命令,就可以直接完成这个键
值对的写入了。
下面这张图就是一个例子:
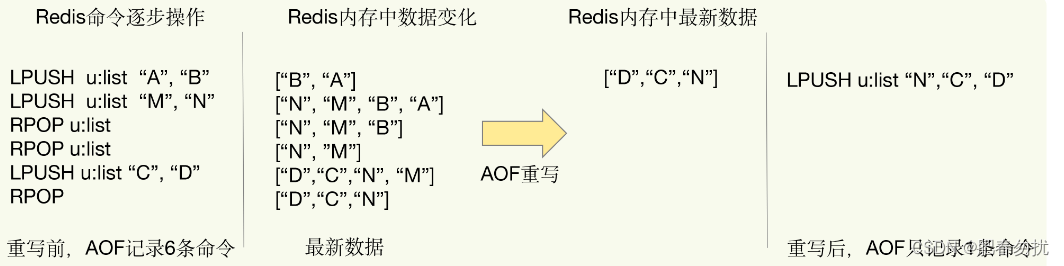
当我们对一个列表先后做了 6 次修改操作后,列表的最后状态是[“D”, “C”, “N”],
此时,只用 LPUSH u:list “N”, “C”, "D"这一条命令就能实现该数据的恢复,这就节省
了五条命令的空间。对于被修改过成百上千次的键值对来说,重写能节省的空间当然就更
大了。
不过,虽然 AOF 重写后,日志文件会缩小,但是,要把整个数据库的最新数据的操作日志
都写回磁盘,仍然是一个非常耗时的过程。这时,我们就要继续关注另一个问题了:重写
会不会阻塞主线程?
AOF 重写会阻塞吗?
和 AOF 日志由主线程写回不同,重写过程是由后台线程 bgrewriteaof 来完成的,这也是
为了避免阻塞主线程,导致数据库性能下降。
我把重写的过程总结为“一个拷贝,两处日志”
一个拷贝”就是指,每次执行重写时,主线程 fork 出后台的 bgrewriteaof 子进程。此
时,fork 会把主线程的内存拷贝一份给 bgrewriteaof 子进程,这里面就包含了数据库的
最新数据。然后,bgrewriteaof 子进程就可以在不影响主线程的情况下,逐一把拷贝的数
据写成操作,记入重写日志。
“两处日志”又是什么呢?
因为主线程未阻塞,仍然可以处理新来的操作。此时,如果有写操作,第一处日志就是指
正在使用的 AOF 日志,Redis 会把这个操作写到它的缓冲区。这样一来,即使宕机了,这
个 AOF 日志的操作仍然是齐全的,可以用于恢复。
而第二处日志,就是指新的 AOF 重写日志。这个操作也会被写到重写日志的缓冲区。这
样,重写日志也不会丢失最新的操作。等到拷贝数据的所有操作记录重写完成后,重写日
志记录的这些最新操作也会写入新的 AOF 文件,以保证数据库最新状态的记录。此时,我
们就可以用新的 AOF 文件替代旧文件了。
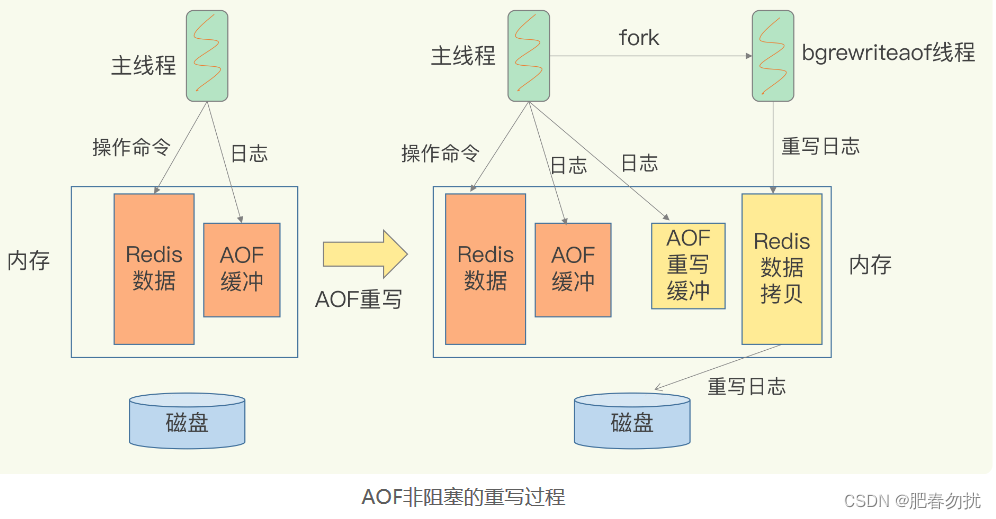
总结来说,每次 AOF 重写时,Redis 会先执行一个内存拷贝,用于重写;然后,使用两个
日志保证在重写过程中,新写入的数据不会丢失。而且,因为 Redis 采用额外的线程进行
数据重写,所以,这个过程并不会阻塞主线程。
问题的提出
不过,你可能也注意到了,落盘时机和重写机制都是在“记日志”这一过程中发挥作用
的。例如,落盘时机的选择可以避免记日志时阻塞主线程,重写可以避免日志文件过大。
但是,在“用日志”的过程中,也就是使用 AOF 进行故障恢复时,我们仍然需要把所有的
操作记录都运行一遍。再加上 Redis 的单线程设计,这些命令操作只能一条一条按顺序执
行,这个“重放”的过程就会很慢了。
那么,有没有既能避免数据丢失,又能更快地恢复的方法呢?当然有,那就是 RDB 快照
了。
AOF 日志重写的时候,是由 bgrewriteaof 子进程来完成的,不用主线程参与,我们今
天说的非阻塞也是指子进程的执行不阻塞主线程。但是,你觉得,这个重写过程有没有
其他潜在的阻塞风险呢?如果有的话,会在哪里阻塞?
AOF 重写也有一个重写日志,为什么它不共享使用 AOF 本身的日志呢?
学习就是这样你会发现,你学着学着就会发现很多问题
相关文章:
AOF日志:宕机了,Redis如何避免数据丢失
当服务器宕机后,数据全部丢失:我们很容易想到的一个解决方案是从后端数据库恢复这些数据,但这种方式存在两个问题:一是,需要频繁访问数据库,会给数据库带来巨大的压力;二是,这些数据…...
【编程】典型题目:寻找数组第K大数(四种方法对比)
【编程】典型题目:寻找数组第K大数(四种方法对比) 文章目录 【编程】典型题目:寻找数组第K大数(四种方法对比)1. 题目2. 题解2.1 方法一:全局排序(粗暴)2.2 方法二&#…...

Vue3 对比 Vue2 的变化
Vue3 对比 Vue2 的变化 1.源码组织方式变化:使用 TS 重写 2.支持 compositionAPI,基于函数的 api,更灵活组织组件逻辑(Vue2 使用 options api) 3.响应式系统提升:Vue3 的响应式数据原理改成了 Proxy,可以监听动态新增删…...

harbor搭建
回到目录 Harbor 是 VMware 公司开源的企业级 Docker Registry 项目,其目标是帮助用户迅速搭建一个企业级的 Docker Registry 服务 通俗的讲,harbor是一个私人镜像存储服务器 1 下载安装 进入官网,下载一个离线安装包,harbor官网下载 这…...
)
机器学习05-数据准备(利用 scikit-learn基于Pima Indian数据集作数据预处理)
机器学习的数据准备是指在将数据用于机器学习算法之前,对原始数据进行预处理、清洗和转换的过程。数据准备是机器学习中非常重要的一步,它直接影响了模型的性能和预测结果的准确性 以下是机器学习数据准备的一些常见步骤: 数据收集ÿ…...
【枚举+trie+dfs】CF514 C
Problem - 514C - Codeforces 题意: 思路: 其实是trie上dfs的板题 先把字符串插入到字典树中 对于每次询问,都去字典树上dfs 注意到字符集只有3,因此如果发现有不同的字符,去枚举新的字符 Code: #in…...
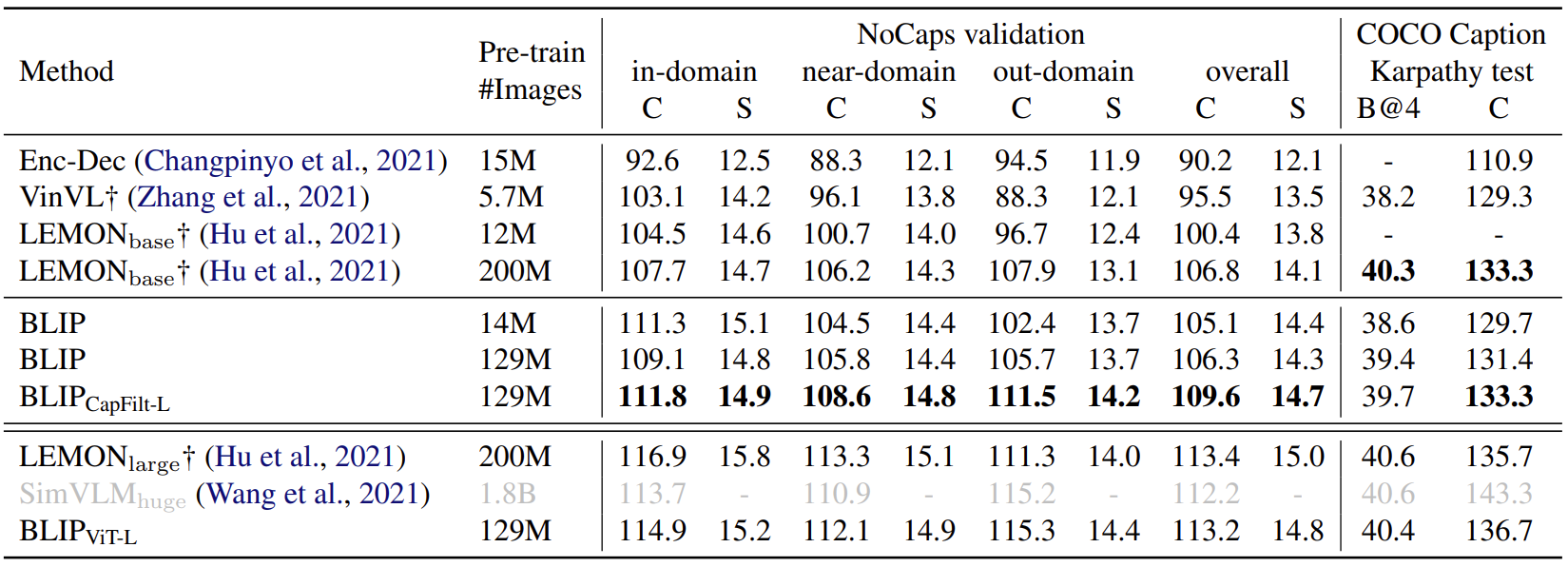
【计算机视觉】BLIP:统一理解和生成的自举多模态模型
文章目录 一、导读二、背景和动机三、方法3.1 模型架构3.2 预训练目标3.3 BLIP 高效率利用噪声网络数据的方法:CapFilt 四、实验4.1 实验结果4.2 各个下游任务 BLIP 与其他 VLP 模型的对比 一、导读 BLIP 是一种多模态 Transformer 模型,主要针对以往的…...
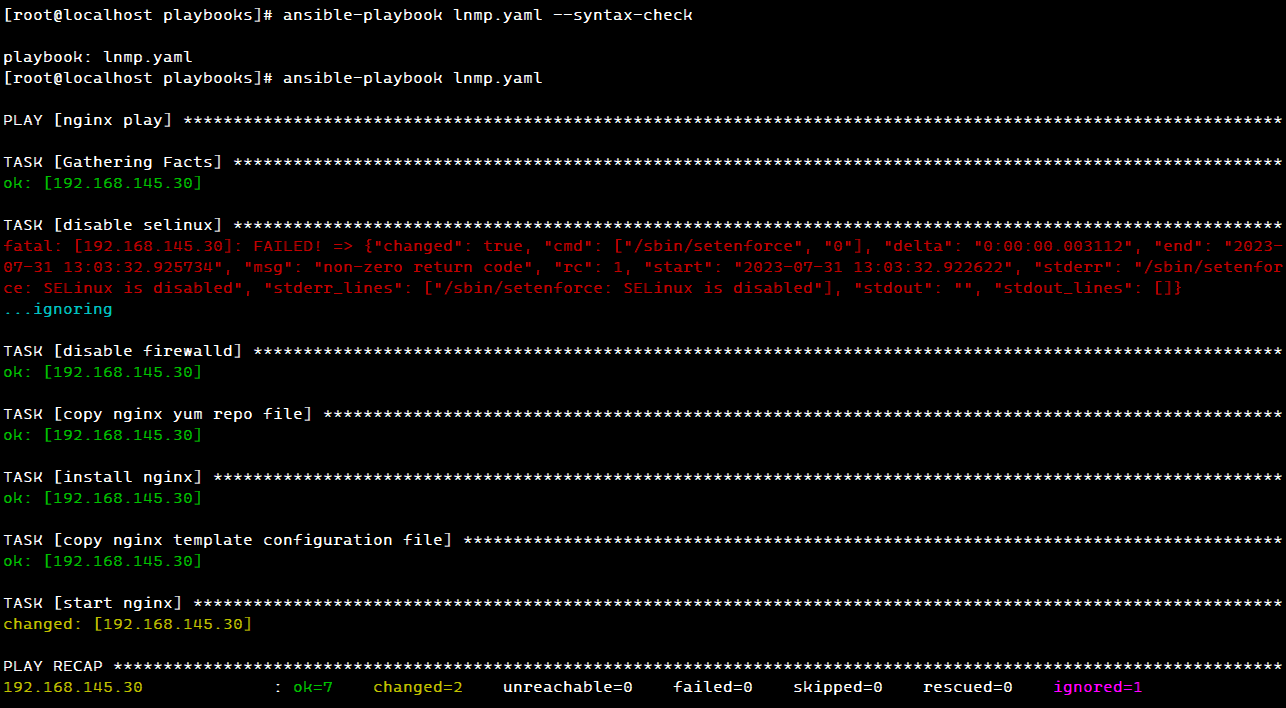
【Ansible】Ansible自动化运维工具之playbook剧本搭建LNMP架构
LNMP 一、playbooks 分布式部署 LNMP1. 环境配置2. 安装 ansble3. 安装 nginx3.1 准备 nginx 相关文件3.2 编写 lnmp.yaml 的 nginx 部分3.3 测试 nginx4. 安装 mysql4.1 准备 mysql 相关文件4.2 编写 lnmp.yaml 的 mysql 部分4.3 测试 mysql5. 安装 php5.1 编写 lnmp.yaml 的 …...

Spring中的事务
一、为什么需要事务? 事务定义 将一组操作封装成一个执行单元(封装到一起),要么全部成功,要么全部失败。 为什么要用事务? 比如转账分为两个操作: 第一步操作: A 账户 -100 元…...
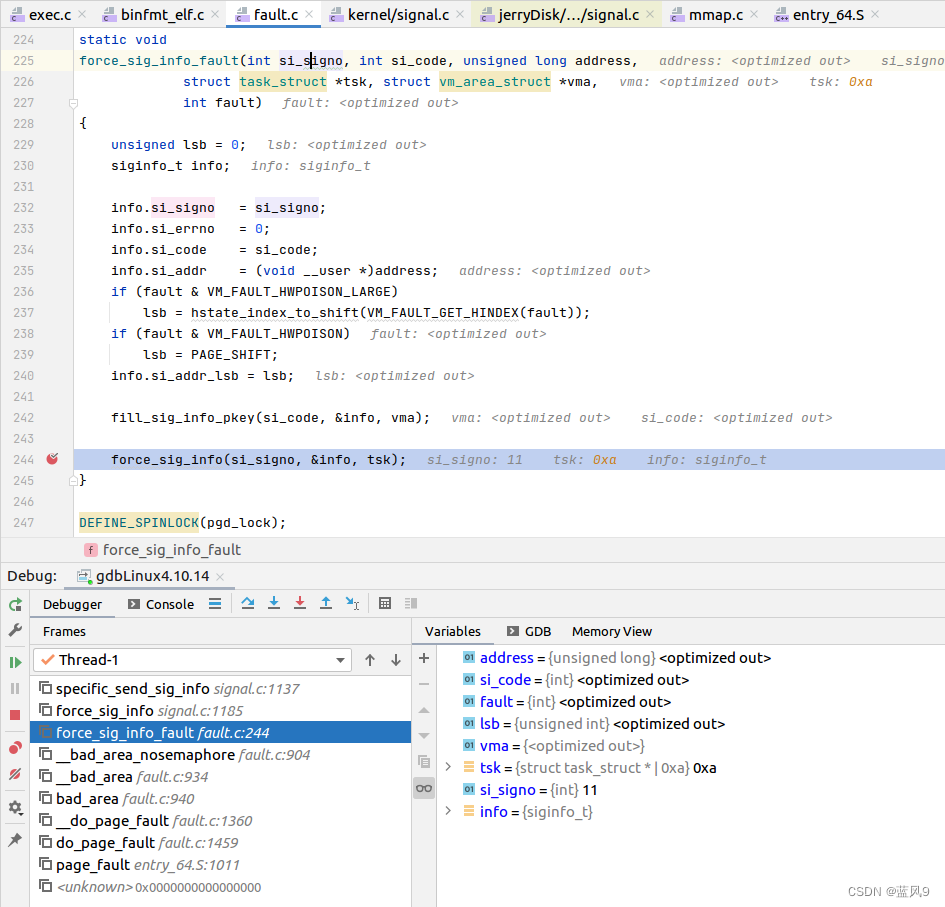
38 非法地址访问的 segment fault 的调试
前言 在前面一篇文章 coredump 的生成和使用 中, 我们看到 "测试用例2 - 非法地址访问" 产生了一个 segment fault 我们这里 就来调试一下 这个 segment fault 是怎么回事 测试用例 #include "stdio.h"int main(int argc, char** argv) {int x 2; i…...
的用法详解)
c++中c_str()的用法详解
c_str()就是将C的string转化为C的字符串数组!!! C中没有string,所以函数c_str()就是将C的string转化为C的字符串数组,c_str()生成一个const char *指针,指向字符串的首地址。 下文通过3段简单的代码比较分析…...

谈谈关于新能源汽车的话题
新能源汽车是指使用新型能源替代传统燃油的汽车,主要包括纯电动汽车、插电式混合动力汽车和燃料电池汽车等。随着环境污染和能源安全问题的日益突出,新能源汽车已经成为全球汽车行业的发展趋势。下面我们来谈谈关于新能源汽车的话题。 首先,新…...
)
EventBus 开源库学习(二)
整体流程阅读 EventBus在使用的时候基本分为以下几步: 1、注册订阅者 EventBus.getDefault().register(this);2、订阅者解注册,否者会导致内存泄漏 EventBus.getDefault().unregister(this);3、在订阅者中编写注解为Subscribe的事件处理函数 Subscri…...

4_Apollo4BlueLite电源管理
1.Cortex-M4 Power Modes Apollo4BlueLite支持以下4种功耗模式: ▪ High Performance Active (not a differentiated power mode for the Cortex-M4) ▪ Active ▪ Sleep ▪ Deep Sleep (1)High Performance Mode 高性能模式不是arm定…...

Pytorch入门学习——快速搭建神经网络、优化器、梯度计算
我的代码可以在我的Github找到 GIthub地址 https://github.com/QinghongShao-sqh/Pytorch_Study 因为最近有同学问我如何Nerf入门,这里就简单给出一些我的建议: (1)基本的pytorch,机器学习,深度学习知识&a…...

举例说明typescript的Exclude、Omit、Pick
一、提前知识说明:联合类型 typescript的联合类型是一种用于表示一个值可以是多种类型中的一种的类型。我们使用竖线(|)来分隔每个类型,所以number | string | boolean是一个可以是number,string或boolean的值的类型。…...

记录一次Linux环境下遇到“段错误核心已转储”然后利用core文件解决问题的过程
参考Linux 下Coredump分析与配置 在做项目的时候,很容易遇到“段错误(核心已转储)”的问题。如果是语法错误还可以很快排查出来问题,但是碰到coredump就没办法直接找到问题,可以通过设置core文件来查找问题࿰…...

WPF中自定义Loading图
纯前端方式,通过动画实现Loading样式,如图所示 <Grid Width"35" Height"35" HorizontalAlignment"Center" VerticalAlignment"Center" Name"Loading"><Grid.Resources><DrawingBrus…...
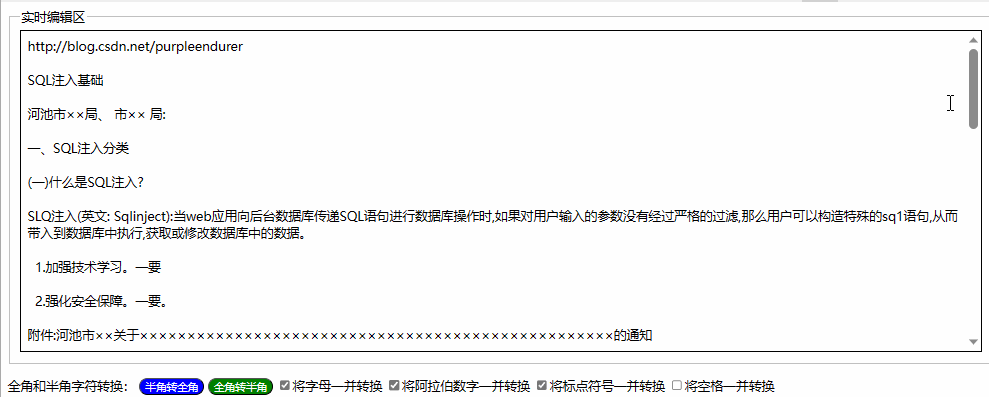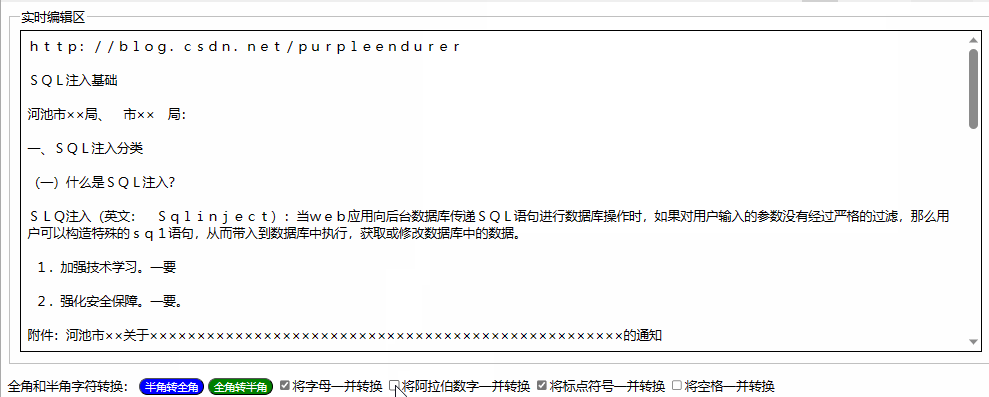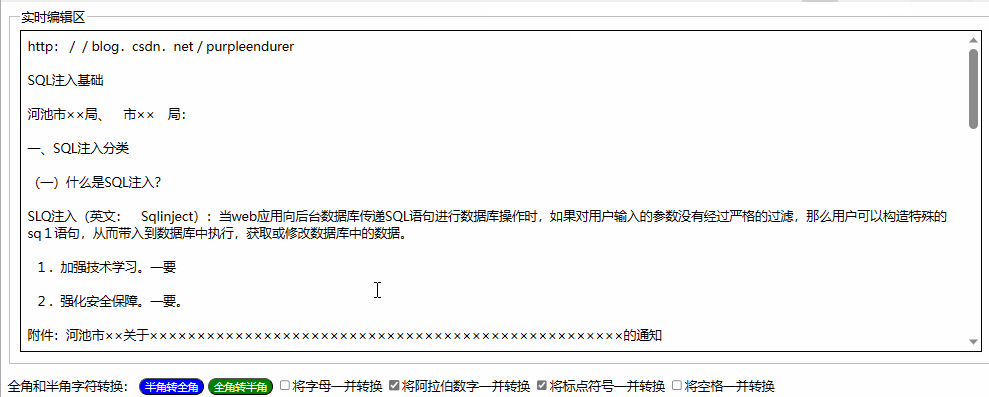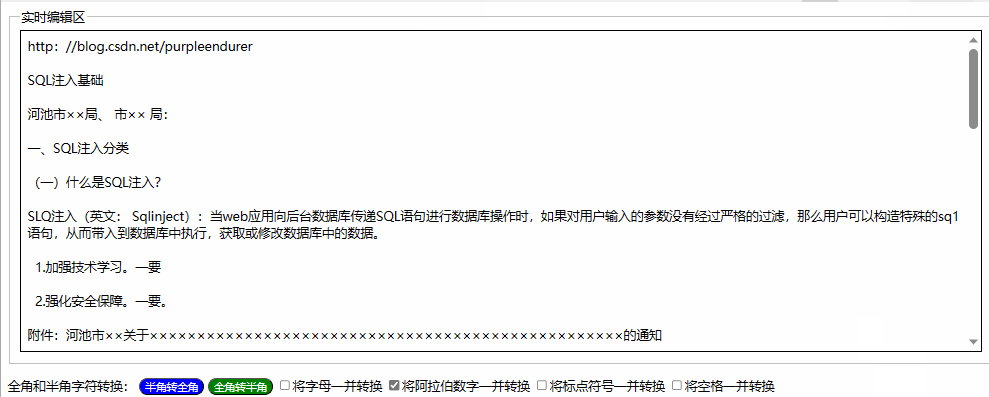
用html+javascript打造公文一键排版系统14:为半角和全角字符相互转换功能增加英文字母、阿拉伯数字、标点符号、空格选项
一、实际工作中需要对转换选项细化内容 在昨天我们实现了最简单的半角字符和全角字符相互转换功能,就是将英文字母、阿拉伯数字、标点符号、空格全部进行转换。 在实际工作中,我们有时只想英文字母、阿拉伯数字、标点符号、空格之中的一两类进行转换&a…...

叮咚买菜财报分析:叮咚买菜第二季度财报将低于市场预期
来源:猛兽财经 作者:猛兽财经 卖方分析师对叮咚买菜第二季度财报的预测 尽管叮咚买菜(DDL)尚未明确披露第二季度财报的具体日期,但根据其以往的业绩公告,猛兽财经认为叮咚买菜很有可能会在8月的第二周发布…...

零基础玩转EVA-01:手把手教你用机甲AI分析图片,效果惊艳
零基础玩转EVA-01:手把手教你用机甲AI分析图片,效果惊艳 1. 初识EVA-01:你的机甲视觉助手 想象一下,你面前有一张复杂的机械设计图,或者一张充满细节的风景照片。传统的AI图片分析工具可能只会给你一段干巴巴的文字描…...

Qwen3-ASR-1.7B代码实例:Python调用API接口实现批量音频转写自动化
Qwen3-ASR-1.7B代码实例:Python调用API接口实现批量音频转写自动化 1. 引言:音频转写的自动化需求 在日常工作中,我们经常需要处理大量的音频文件转写任务。无论是会议录音、采访记录还是语音备忘录,手动逐一听写不仅耗时耗力&a…...

Science Bulletin-2026 | 首套中国40年城市土地利用数据集
数据介绍 Fig. 1. Study areas for time-series urban land use mapping in China. Spatial distribution of urban area density (defined as the ratio of built-up area to the total administrative area) across China and six representative subregions: (a) Xinjiang, …...

【nginx】深入解析net::ERR_CONTENT_LENGTH_MISMATCH 200:权限配置与日志排查实战
1. 错误现象与初步诊断 当你用浏览器访问Nginx托管的网站时,突然看到控制台报错net::ERR_CONTENT_LENGTH_MISMATCH 200,但页面居然还能正常显示部分内容,这种情况是不是很诡异?我第一次遇到时也是一头雾水。这个错误表面看是内容长…...

Omni-Vision Sanctuary赋能Claude等对话Agent:实现文本对话到视觉创作的延伸
Omni-Vision Sanctuary赋能Claude等对话Agent:实现文本对话到视觉创作的延伸 1. 引言:当语言模型遇上视觉创作 想象一下这样的场景:你正在和Claude讨论一个创意方案,描述着脑海中的画面——"我想要一个未来感十足的城市夜景…...
全覆盖输出)
SecGPT-14B作品分享:5类典型安全任务(漏洞/日志/异常/攻防/命令)全覆盖输出
SecGPT-14B作品分享:5类典型安全任务全覆盖输出 1. SecGPT-14B简介 SecGPT是由云起无垠团队于2023年推出的开源大语言模型,专门针对网络安全领域设计开发。该模型基于先进的自然语言处理技术,融合了安全专业知识库,能够高效处理…...

膜结构工程:从方案设计到施工落地的完整解析
一、什么是膜结构工程,为什么这几年越来越常见膜结构工程,通常是指以膜材作为覆盖层,配合钢结构、索结构或支撑体系形成完整空间结构的工程形态。常见形式包括张拉膜结构、骨架式膜结构、充气膜结构等。和传统钢筋混凝土或普通彩钢建筑相比&a…...

Tinycon终极指南:如何在网站favicon上优雅显示通知气泡的完整教程
Tinycon终极指南:如何在网站favicon上优雅显示通知气泡的完整教程 【免费下载链接】tinycon A small library for manipulating the favicon, in particular adding alert bubbles and changing images. 项目地址: https://gitcode.com/gh_mirrors/ti/tinycon …...

Android 8.0长时定时关机总延迟?我换了种思路,用系统广播ACTION_TIME_TICK轻松搞定
Android定时任务稳定性优化:从AlarmManager到系统广播的实践之路 在智能硬件和特定应用场景中,定时功能的可靠性往往直接影响用户体验。想象一下,你为孩子设置的学习软件定时关闭功能延迟了几分钟,或者智能家居设备的自动关机未能…...

Laravel 11重磅更新:10大核心特性解析
Laravel 11.x(2024年3月发布)引入了多项重要更新,主要特性如下: 1. 精简项目结构 默认移除了 app/Http/Kernel.php 和 app/Console/Kernel.php,中间件配置迁移至 bootstrap/app.php: ->withMiddleware(…...