【数据分析入门】人工智能、数据分析和深度学习是什么关系?如何快速入门 Python Pandas?
目录
- 一、前言
- 二、数据分析和深度学习的区别
- 三、人工智能
- 四、深度学习
- 五、Pandas
- 六、Pandas数据结构
- 6.1 Series - 序列
- 6.2 DataFrame - 数据框
- 七、输入、输出
- 7.1 读取/写入CSV
- 7.2 读取/写入Excel
- 7.3 读取和写入 SQL 查询及数据库表
- 八、调用帮助
- 九、选择(这里可以参考上一篇文章的 Numpy Arrays 相关部分)
- 9.1 取值
- 9.2 选取、布尔索引及设置值
- 9.2.1 按位置
- 9.2.2 按标签
- 9.2.3 按标签/位置
- 9.2.4 布尔索引
- 9.2.5 设置值
- 十、删除数据
- 十一、排序
- 十二、查询序列与数据框的信息
- 12.1 基本信息
- 12.2 汇总
- 十三、应用函数
- 十四、数据对齐
- 14.1 内部数据对齐
- 14.2 使用 Fill 方法运算
- 十五、后记
本文详细介绍了人工智能、数据分析和深度学习之间的关系,并就数据分析所需的Pandas库做了胎教般的入门引导。祝读得开心!
一、前言
本文是原 《数据分析大全》、现改名为 《数据分析》 专栏的第二篇,我在写这篇文章的时候突然意识到——单靠我是不可能把数据分析的方方面面都讲得明明白白,只是是我自己知道什么,然后再输出我所明白的知识罢了。所以《数据分析大全》的“大全”两个字还真是担不起,就改成 《数据分析》 了。
本篇主要介绍数据分析中 Python Pandas 相关知识点,打算通过这一篇帮助大家顺利入门Python Pandas,掌握基本的用法和思想。
上一期《数据分析大全》——Numpy基础可能讲的太过侧重代码而忽略了讲解,如果是还未入门的小白可能看完都不知道讲了啥、为什么要讲这些。
实用性强和门槛低才是好文章的必要因素,像之前的那一篇就太过强调实用了。结果文章是简短了,可除了已经入门或从事相关工作的同行外,没几个能明白讲了啥的。因此,本篇吸取之前的教训,在交稿前又认真地完善了文章的措辞,加上段落间的衔接和引例等语句,方便小白也能看懂。
让我先来填一下上期的坑,聊聊数据分析和深度学习都有什么区别和联系。
二、数据分析和深度学习的区别
数据分析也好,深度学习也罢,都是一种新的技术,而新技术的产生则是为了解决现实中遇到的问题。我们可以姑且把现实问题分为简单问题和复杂问题。简单问题,只需要简单分析,我们使用数据分析就够了。而复杂问题,则需要复杂分析,我们这才使用机器学习。
——那什么是简单问题,什么是复杂问题呢?
简单问题就比如是今年学院奖学金的评选情况、今天公司的业绩这类问题,数据量不是很大,我们就用数据分析。
而我们天天使用的某宝、某东这类购物APP,它会根据你的历史购物习惯(这里面有着海量的数据),来给推荐你可能感兴趣的商品。那是如何做到的呢?对于这种复杂问题,这类APP背后使用的就是机器学习以及相应的推荐算法。
三、人工智能
人工智能的范围很广,广义上的人工智能泛指通过计算机(机器)实现人的头脑思维,使机器像人一样去决策。
机器学习是实现人工智能的一种技术。在机器学习分很多方法(算法),不同的方法解决不同的问题。深度学习是机器学习中的一个分支方法。
总结一下:人工智能、机器学习和深度学习的关系是:人工智能包含机器学习,机器学习包含深度学习(方法),即数据分析>机器学习>深度学习>机器学习。
四、深度学习
深度学习在图像,语音等富媒体的分类和识别上取得了非常好的效果,所以各大研究机构和公司都投入了大量的人力做相关的研究和开发。
举个众人皆知的例子,那就是2016年谷歌旗下DeepMind公司开发的阿尔法围棋(AlphaGo)战胜人类顶尖围棋选手。阿尔法围棋的主要工作原理就是“深度学习”。

五、Pandas
咳咳,扯远了,本篇文章要讲的Pandas还没说呢。
在学习任何东西之前,我们都应该明白两个问题——它能干什么?我能用它做什么?
我相信肯定有人和我在入门数据结构时一样,对这个叫“Pandas”的库有很多问题——Pandas是什么?Pandas一词是怎么来的?Pandas是做什么的?…让我们来一起解决这些困惑。
首先,Pandas是什么?是Panda→熊猫吗?

这听起来很Cool…但很显然我们不可能用熊猫来帮助我们进行数据分析的工作。其实,Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
那么,Pandas 一词是怎么来的呢?
Pandas 名字的由来衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析。总的来说,Pandas 是一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
听起来明白点了,让我们再来看看 Pandas 究竟是干什么用的。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
让我们来总结一下:Pandas 是基于 Numpy 创建的 Python 库,为 Python 提供了易于使用的数据结构和数据分析工具。只需要记住这句话,就可以继续进行我们接下来的学习了!

在Python中,我们可以使用以下语句导入 Pandas 库:
>>> import pandas as pd
六、Pandas数据结构
6.1 Series - 序列
首先我们来看看序列,Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
让我们对上的参数进行简单的说明:
data:一组数据(ndarray 类型)。
index:数据索引标签,如果不指定,默认从 0 开始。
dtype:数据类型,默认会自己判断。
name:设置名称。
copy:拷贝数据,默认为 False。
想想看,要是实现存储任意类型数据的一维数组(如下图),应该怎么实现呢?
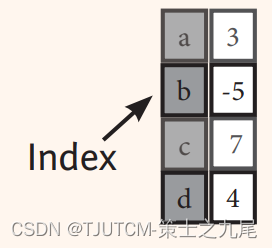
这边附上了实现代码:
>>> s = pd.Series([3, -5, 7, 4], index=['a', 'b', 'c', 'd'])
6.2 DataFrame - 数据框
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(比如数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
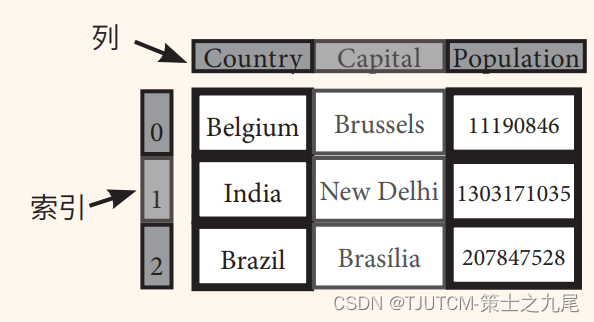
我们要是想实现上方的存储不同类型数据的二维数组,可以这么实现:
>>> data = {'Country': ['Belgium', 'India', 'Brazil'], 'Capital': ['Brussels', 'New Delhi', 'Brasília'],'Population': [11190846, 1303171035, 207847528]}>>> df = pd.DataFrame(data, columns=['Country', 'Capital', 'Population'])
七、输入、输出
7.1 读取/写入CSV
在解决这个问题前先来了解一下,什么是CSV:
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
Pandas 可以很轻松地处理CSV文件:
>>> pd.read_csv('file.csv', header=None, nrows=5)
>>> df.to_csv('myDataFrame.csv')
7.2 读取/写入Excel
在解决问题时,往往涉及到从Excel读取或写入数据,以下给出了相关的代码实现。也有读取内含多个表的Excel中数据的代码实现:
>>> pd.read_excel('file.xlsx')
>>> pd.to_excel('dir/myDataFrame.xlsx', sheet_name='Sheet1')
# 读取内含多个表的Excel
>>> xlsx = pd.ExcelFile('file.xls')
>>> df = pd.read_excel(xlsx, 'Sheet1')
7.3 读取和写入 SQL 查询及数据库表
关于读取和写入 SQL 查询及数据库表的代码如下:
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///:memory:')
>>> pd.read_sql("SELECT * FROM my_table;", engine)
>>> pd.read_sql_table('my_table', engine)
>>> pd.read_sql_query("SELECT * FROM my_table;", engine)
read_sql()是 read_sql_table() 与 read_sql_query() 的便捷打包器
>>> pd.to_sql('myDf', engine)
八、调用帮助
当然,在开发过程中遇到的问题肯定是千奇百怪的。除了在技术论坛上发帖求问、求助师兄师姐,我们也要学会自己查看帮助文档:

调用帮助的代码如下:
>>>help(pd.Series.loc)
九、选择(这里可以参考上一篇文章的 Numpy Arrays 相关部分)
9.1 取值
在取值时,我们可以取序列的值,也可以取数据框的值。以下是取序列值和取数据框子集的代码实现,可以参考一下:
# 取序列的值
>>> s['a']
-5# 取数据框的子集
>>> df[1:]Country Capital Population1 India New Delhi 13031710352 Brazil Brasília 207847528
9.2 选取、布尔索引及设置值
9.2.1 按位置
在我们根据需求选择某些数据时,往往涉及到按行与列的位置选择某值,以下给出了具体的代码:
# 按行与列的位置选择某值
>>> df.iloc[[0],[0]]
'Belgium'
>>> df.iat([0],[0])'Belgium'
9.2.2 按标签
按行与列的名称选择某值的代码实现如下:
# 按行与列的名称选择某值
>>> df.loc[[0], ['Country']]'Belgium'>>> df.at([0], ['Country']) 'Belgium'
9.2.3 按标签/位置
我们也可以选择某行或者选择某列:
# 选择某行
>>> df.ix[2] Country Brazil Capital Brasília Population 207847528# 选择某列
>>> df.ix[:,'Capital']0 Brussels1 New Delhi2 Brasília >>> df.ix[1,'Capital']'New Delhi'
9.2.4 布尔索引
Pandas支持物理顺序进行选取,也支持通过逻辑进行取值。下面给出了几个例子:
>>> s[~(s > 1)] # 序列 S 中没有大于1的值
>>> s[(s < -1) | (s > 2)] # 序列 S 中小于-1或大于2的值
>>> df[df['Population']>1200000000] # 序列 S 中小于-1或大于2的值
9.2.5 设置值
还可以设置索引项的值:
>>> s['a'] = 6 # 将序列 S 中索引为 a 的值设为6
十、删除数据
按索引删除序列的值:
>>> s.drop(['a', 'c']) # 按索引删除序列的值 (axis=0)
>>> df.drop('Country', axis=1) # 按索引删除序列的值 (axis=0)
十一、排序
基本的增删查改都介绍完了,这里再介绍以下排序。下面给出了按索引排序、按某列的值排序、按某列的值排序的另解的代码:
>>> df.sort_index() # 按索引排序
>>> df.sort_values(by='Country') # 按某列的值排序
>>> df.rank() # 按某列的值排序
十二、查询序列与数据框的信息
12.1 基本信息
排序也介绍完了,再来说说查询吧。这里给出了获取行、列索引和获取数据框基本信息的两种方法:
>>> df.shape # (行,列))
>>> df.index # 获取索引
>>> df.columns # 获取索引
>>> df.info() # 获取数据框基本信息
>>> df.count() # 获取数据框基本信息
12.2 汇总
常见的功能实现函数汇总如下:
>>> df.sum() # 合计
>>> df.cumsum() # 合计
>>> df.min()/df.max() # 最小值除以最大值
>>> df.idxmin()/df.idxmax() # 最小值除以最大值
>>> df.describe() # 基础统计数据
>>> df.mean() # 平均值
>>> df.median() # 中位数
十三、应用函数
这里给出了几个常用的函数的调用方法:
>>> f = lambda x: x*2 # 应用匿名函数lambda
>>> df.apply(f) # 应用函数
>>> df.applymap(f) # 应用函数
十四、数据对齐
14.1 内部数据对齐
如有不一致的索引,则使用NA值:
>>> s3 = pd.Series([7, -2, 3], index=['a', 'c', 'd'])
>>> s + s3a 10.0b NaNc 5.0d 7.0
14.2 使用 Fill 方法运算
还可以使用 Fill 方法进行内部对齐运算:
>>> s.add(s3, fill_value=0)a 10.0b -5.0c 5.0d 7.0
>>> s.sub(s3, fill_value=2)
>>> s.div(s3, fill_value=4)
>>> s.mul(s3, fill_value=3)
十五、后记
本期关于人工智能、数据分析和深度学习的关系,人工智能、深度学习的相关内容也介绍完了,本文的重点放在了 Pandas 的快速入门方面,如果能在科研项目、工程开发和日常学习方面帮到大家,就最好不过了!下期会接着介绍Pandas进阶方向的知识(因为这篇写得太多了,就拆成两篇发了)。
非常感谢大家的阅读,也欢迎大家提出宝贵的建议!我们下周见!
相关文章:
【数据分析入门】人工智能、数据分析和深度学习是什么关系?如何快速入门 Python Pandas?
目录 一、前言二、数据分析和深度学习的区别三、人工智能四、深度学习五、Pandas六、Pandas数据结构6.1 Series - 序列6.2 DataFrame - 数据框 七、输入、输出7.1 读取/写入CSV7.2 读取/写入Excel7.3 读取和写入 SQL 查询及数据库表 八、调用帮助九、选择(这里可以参考上一篇文…...

JavaScript 里三个点 ... 的用法
// table表头数据let tableHeadData deepClone(data);let tableCacheData [];//表格缓存对比if (!parent && isCacheHeadData) {// 缓存数据keylet tableCacheKey ${window.location.pathname}-${$self.attr(id)}if (localStorage.getItem(tableCacheKey)) {//根据缓…...
Linux修改系统语言
sudo dpkg-reconfigure locales 按pagedown键,移动红色光标到 zh_CN.UTF-8 UTF-8,空格标记*号(没标记下一页没有这一项),回车。 下一页选择 zh_CN.UTF-8。 如果找不到 dpkg-reconfigure whereis dpkg-reconfigure …...
Spring注解开发
目录 1、简介 2、原始注解 2.1、注解种类 2.2、组件扫描 2.3、具体使用 2.3.1、xml配置 2.3.2、注解配置 3、⭐新注解 3.1、新注解种类 3.2、实践 3.3、运行结果 3.4、警告信息 1、简介 Spring框架提供了许多注解,用于在Java类中进行配置和标记…...
图像处理库(Opencv, Matplotlib, PIL)以及三者之间的转换
文章目录 1. Opencv2. Matplotlib3. PIL4. 三者的区别和相互转换5. Torchvision 中的相关转换库5.1 ToPILImage([mode])5.2 ToTensor5.3 PILToTensor 1. Opencv opencv的基本图像类型可以和numpy数组相互转化,因此可以直接调用torch.from_numpy(img) 将图像转换成t…...

html+Vue+封装axios实现发送请求
在html中使用Vue和Axios时,可以在HTML中引入Vue库和Axios库,然后使用Vue的语法和指令来创建Vue组件和模板。在Vue组件中,你可以使用Axios发送HTTP请求来获取数据,并将数据绑定到Vue模板中进行展示。 <template><div>&…...

GoogLeNet卷积神经网络输出数据形参分析-笔记
GoogLeNet卷积神经网络输出数据形参分析-笔记 分析结果为: 输入数据形状:[10, 3, 224, 224] 最后输出结果:linear_0 [10, 1] [1024, 1] [1] 子空间执行逻辑 def forward_old(self, x):# 支路1只包含一个1x1卷积p1 F.relu(self.p1_1(x))# 支路2包含 1…...

【docker】dockerfile发布springboot项目
目录 一、实现步骤二、示例 一、实现步骤 1.定义父镜像:FROM java:8 2.定义作者信息:MAINTAINER:learn_docker<https://www.docker.com> 3.将jar包添加到容器:ADD jar包名称.jar app.jar 4.定义容器启动执行命令:…...

利用docker run -v 命令实现使用宿主机中没有的命令
利用docker run -v 命令实现使用宿主机中没有的命令 使用容器中的jar命令解压jar包,并将解压内容输出到挂载在宿主机中的目录里 使用容器中的jar命令解压jar包,并将解压内容输出到挂载在宿主机中的目录里 docker run -it --name java -v /www/temp/java…...

【小沐学NLP】在线AI绘画网站(百度:文心一格)
文章目录 1、简介2、文心一格2.1 功能简介2.2 操作步骤2.3 使用费用2.4 若干示例2.4.1 女孩2.4.2 昙花2.4.3 山水画2.4.4 夜晚2.4.5 古诗2.4.6 二次元2.4.7 帅哥 结语 1、简介 当下,越来越多AI领域前沿技术争相落地,逐步释放出极大的产业价值࿰…...

react经验5:访问子组件内容
应用场景 父级需要调用子组件的某函数 实现步骤 案例:创建自定义按钮 button.tsx import { Ref, forwardRef, useImperativeHandle,ReactNode} from "react" declare type ButtonProps {/**按钮文字 */children?: ReactNode,onClick?: () > voi…...
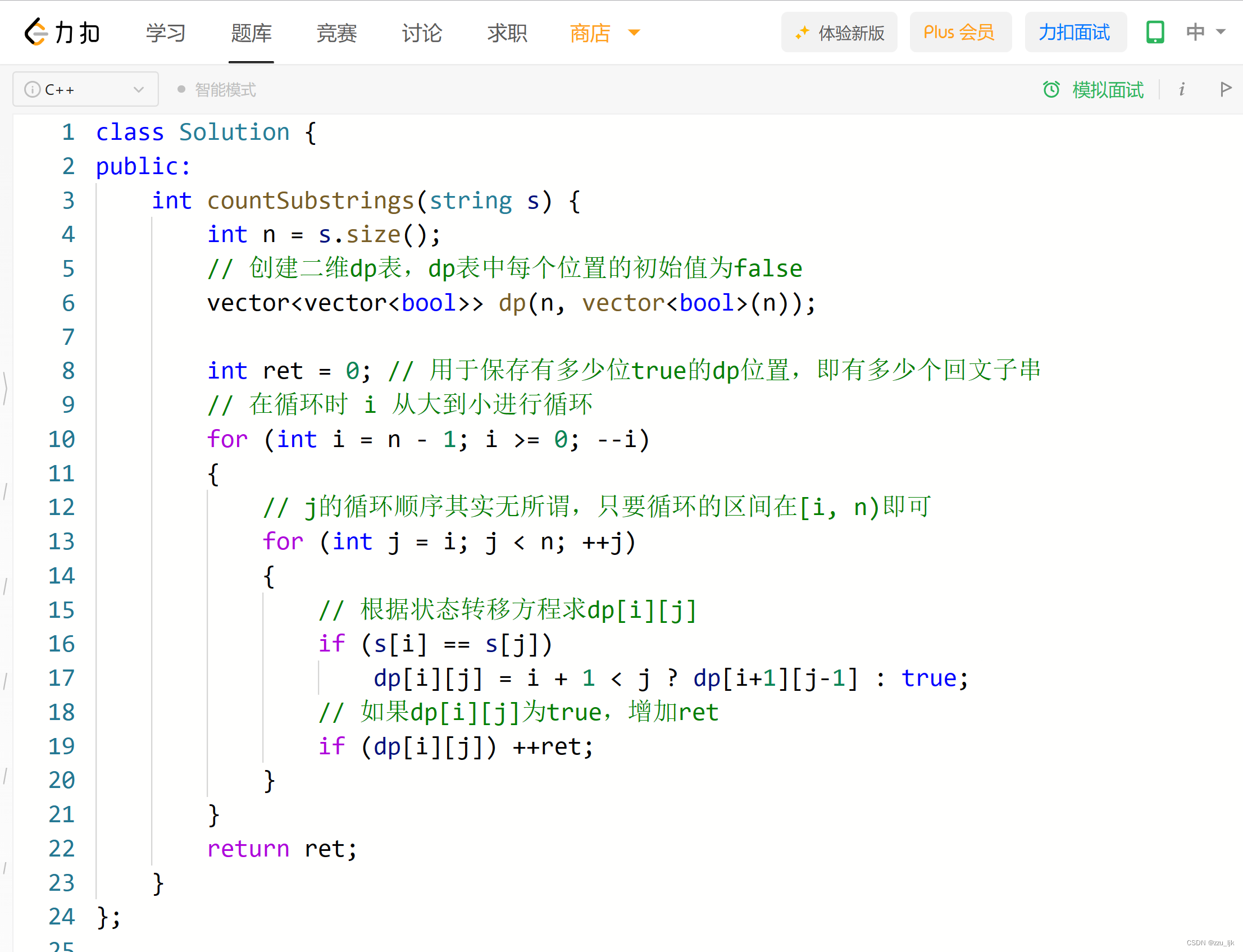
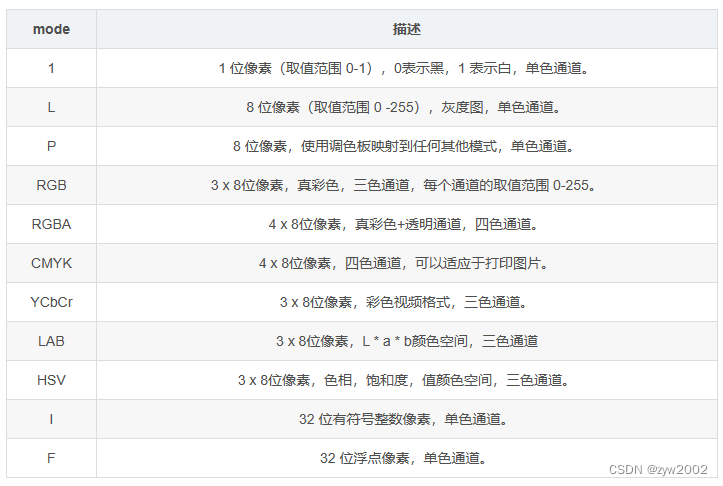
【LeetCode】647. 回文子串
题目链接 文章目录 1. 思路讲解1.1 方法选择1.2 dp表的创建1.3 状态转移方程1.4 填表顺序 2. 代码实现 1. 思路讲解 1.1 方法选择 这道题我们采用动态规划的解法,倒不是动态规划的解法对于这道题有多好,它并不是最优解。但是,这道题的动态…...
 角度制与弧度制的相互转换)
Open3D(C++) 角度制与弧度制的相互转换
目录 一、弧度转角度1、计算公式2、主要函数3、示例代码4、结果展示二、角度转弧度1、计算公式2、主要函数3、示例代码4、结果展示三、归一化到(-PI,PI)1、主要函数<...

【小沐学NLP】在线AI绘画网站(网易云课堂:AI绘画工坊)
文章目录 1、简介1.1 参与方式1.2 模型简介 2、使用费用3、操作步骤3.1 选择模型3.2 输入提示词3.3 调整参数3.4 图片生成 4、测试例子4.1 小狗4.2 蜘蛛侠4.3 人物4.4 龙猫 结语 1、简介 Stable Diffusion是一种强大的图像生成AI,它可以根据输入的文字描述词&#…...

GNN code Tips
1. 重置label取值范围 problem: otherwise occurs IndexError: target out of bounds # reset labels value range, otherwise occurs IndexError: target out of bounds uni_set torch.unique(labels) to_set torch.tensor(list(range(len(uni_set)))) labels_reset label…...
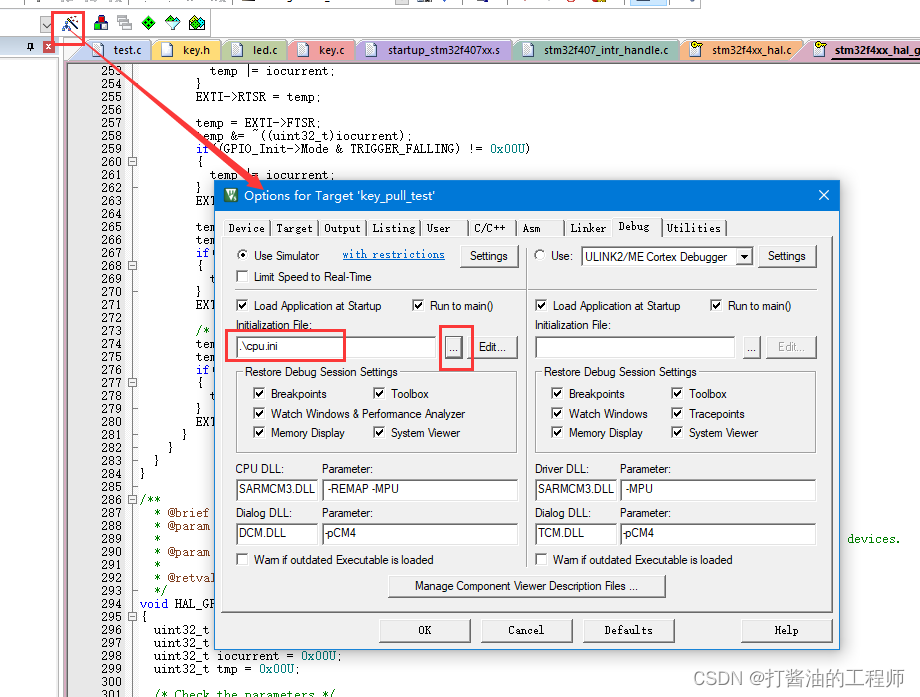
物联网|按键实验---学习I/O的输入及中断的编程|函数说明的格式|如何使用CMSIS的延时|读取通过外部中断实现按键捕获代码的实现及分析-学习笔记(14)
文章目录 通过外部中断实现按键捕获代码的实现及分析Tip1:函数说明的格式Tip2:如何使用CMSIS的延时GetTick函数原型stm32f407_intr_handle.c解析中断处理函数:void EXTI4_IRQHandler 调试流程软件模拟调试 两种代码的比较课后作业: 通过外部中断实现按键捕获代码的实…...

Java对象的前世今生
文章目录 一、创建对象的步骤二、类加载机制三、内存分配指针碰撞 (内存连续)空闲列表 (内存不连续) 四、创建对象的5种方法五、浅拷贝与深拷贝 以下一行代码内部发生了什么? Person person new Person();一、创建对象的步骤 根据JLS中的规定,Java对象…...

Qt中JSON的使用
一.前言: JSON是一种轻量级数据交换格式,常用于客户端和服务端的数据交互,不依赖于编程语言,在很多编程语言中都可以使用JSON,比如C,C,Java,Android,Qt。除了JSON&#x…...

linux安装Tomcat部署jpress教程
yum在线安装: 查看tomcat相关的安装包: [rootRHCE ~]# yum list | grep -i tomcat tomcat.noarch 7.0.76-16.el7_9 updates tomcat-el-2.2-api.noarch 7.0.76-16.el7_9 updat…...

高并发负载均衡---LVS
目录 前言 一:负载均衡概述 二:为啥负载均衡服务器这么快呢? 编辑 2.1 七层应用程序慢的原因 2.2 四层负载均衡器LVS快的原因 三:LVS负载均衡器的三种模式 3.1 NAT模式 3.1.1 什么是NAT模式 3.1.2 NAT模式实现LVS的缺点…...

我的第一个CANOpen主站:手把手教你用CanFestival-3源码配置心跳、SYNC和PDO映射
我的第一个CANOpen主站:手把手教你用CanFestival-3源码配置心跳、SYNC和PDO映射 当你第一次面对工业现场总线协议时,那种既兴奋又忐忑的心情我至今记忆犹新。CANOpen作为工业自动化领域的"普通话",其主站开发往往是工程师进阶路上的…...

别再死记硬背了!用Pointer Network让AI学会‘抄作业’,搞定文本摘要和对话生成
别再死记硬背了!用Pointer Network让AI学会‘抄作业’,搞定文本摘要和对话生成 想象一下,当你面对一篇冗长的技术文档时,最有效的学习方法是什么?不是逐字背诵,而是用荧光笔划出关键概念——这正是Pointer …...

如何快速掌握League-Toolkit:英雄联盟玩家的终极辅助工具指南
如何快速掌握League-Toolkit:英雄联盟玩家的终极辅助工具指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League-Toolkit是一款…...

Windows防撤回补丁终极指南:微信QQ消息永久保存的完整解决方案
Windows防撤回补丁终极指南:微信QQ消息永久保存的完整解决方案 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gi…...

避坑指南:在Ubuntu 22.04上用Anaconda配置Vision-Mamba环境,解决‘bimamba_type‘报错
深度避坑:Ubuntu 22.04下Vision-Mamba环境配置全攻略 在深度学习项目部署过程中,环境配置往往是第一个拦路虎。最近在配置Vision-Mamba环境时,我遇到了几个令人头疼的问题,特别是那个让人摸不着头脑的bimamba_type报错。经过一番折…...

FFXIV TexTools终极指南:5步轻松掌握《最终幻想14》模组制作与安装
FFXIV TexTools终极指南:5步轻松掌握《最终幻想14》模组制作与安装 【免费下载链接】FFXIV_TexTools_UI 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_TexTools_UI 你是否曾经梦想过在《最终幻想14》中拥有独一无二的角色外观?想要定制专…...

TP-LINK AX300 网卡驱动
TP-LINK AX300无线网卡的驱动一直不更新,只好自己动手 适配:TL-XDN6000H 免驱版 操作系统:Ubuntu 24.04.4 LTS 内核版本:6.17.0-29-generic #29~24.04.1-Ubuntu https://download.csdn.net/download/zzzhy/92882718...

Visual C++运行库合集:解决Windows程序依赖的终极方案
Visual C运行库合集:解决Windows程序依赖的终极方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否遇到过这样的烦恼?刚下载了一个…...

别再只会抄电路图了!深入拆解LM317数据手册,搞懂可调稳压电源每个电阻电容的作用
从数据手册到实战设计:LM317可调稳压电源的深度解析 在电子设计领域,能够读懂并应用集成电路数据手册是区分初级玩家和专业工程师的重要标志。LM317作为经典的线性稳压器,其数据手册中蕴含的设计智慧远比大多数教科书上的标准电路图丰富得多。…...

如何快速掌握大众点评爬虫:解决动态字体加密的终极实战指南
如何快速掌握大众点评爬虫:解决动态字体加密的终极实战指南 【免费下载链接】dianping_spider 大众点评爬虫(全站可爬,解决动态字体加密,非OCR)。持续更新 项目地址: https://gitcode.com/gh_mirrors/di/dianping_sp…...