ChatGPT模型采样算法详解
ChatGPT模型采样算法详解
ChatGPT所使用的模型——GPT(Generative Pre-trained Transformer)模型有几个参数,理解它们对文本生成任务至关重要。其中最重要的一组参数是temperature和top_p。二者控制两种不同的采样技术,用于因果语言模型(Causal language models)中预测给定上下文情景中下一个单词出现的概率。本文将重点讲解temperature和top_p的采样原理,以及它们对模型输出的影响。
文章目录
- 理解因果语言模型中的采样
- Top-k采样
- Top-p采样
- 温度采样
- 典型用例
- 总结
理解因果语言模型中的采样
假设我们训练了一个描述个人生活喜好的模型,我们想让它来补全“我喜欢漂亮的___”这个句子。一般语言模型会按照下图的流程来工作:

模型会查看所有可能的单词,并根据其概率分布从中采样,以预测下一个词。为了方便起见,假设模型的词汇量不大,只有:“大象”、“西瓜”、“鞋子”和“女孩”。通过下图的词汇概率我们可以发现,“女孩”的选中概率最高(p=0.664p=0.664p=0.664),“西瓜”的选中概率最低(p=0.032p=0.032p=0.032)。

上面的例子中,很明显“女孩”最可能被选中。因为人类对于单一问题在心智上习惯采用 “贪心策略”,即选择概率最高的事件。

贪心策略符合人类的心智,但是存在严重缺陷。
但是上面这种策略用在频繁交互的场景下会有一个显著缺陷——如果我们总是选择最可能的单词,那么这个词会反复不断被强化,因为现代语言模型中大多数模型的注意力只集中在最近的几个词(Token)上。这样生成的内容将非常的生硬和可预测,人们一眼就能看出是机器生成的且一点也不智能。
如何让我们的模型不那么具有确定性,让它生成的内容用词更加活跃呢?为此,我们引入了基于分布采样的生成采样算法。但是传统的采样方法会遇到了一个问题:如果我们有5万个候选词(Token),即使最后2.5万个极不可能出现的长尾词汇,它们的概率质量也可能会高达30%。这意味着,对于每个样本,我们有1/3的机会完全偏离原来的“主题”。又由于上面提到的注意力模型倾向于集中在最近出现的词上,这将导致不可恢复的错误级联,因为下一个词严重依赖于最近的错误词。
为了防止从尾部采样,最流行的方法是Top-k采样和温度采样。
Top-k采样
Top-k采样是对前面“贪心策略”的优化,它从排名前k的token种进行抽样,允许其他分数或概率较高的token也有机会被选中。在很多情况下,这种抽样带来的随机性有助于提高生成质量。

上图示例中,我们首先筛选似然值前三的token,然后根据似然值重新计算采样概率。
通过调整k的大小,即可控制采样列表的大小。“贪心策略”其实就是k=1的top-k采样。

Top-p采样
ChatGPT实际使用的不是Top-k采样,而是其改进版——Top-p采样。
Top-k有一个缺陷,那就是“k值取多少是最优的?”非常难确定。于是出现了动态设置token候选列表大小策略——即核采样(Nucleus Sampling)。下图展示了top-p值为0.9的Top-p采样效果:

top-p值通常设置为比较高的值(如0.75),目的是限制低概率token的长尾。我们可以同时使用top-k和top-p。如果k和p同时启用,则p在k之后起作用。
温度采样
温度采样受统计热力学的启发,高温意味着更可能遇到低能态。在概率模型中,logits扮演着能量的角色,我们可以通过将logits除以温度来实现温度采样,然后将其输入Softmax并获得采样概率。
越低的温度使模型对其首选越有信心,而高于1的温度会降低信心。0温度相当于argmax似然,而无限温度相当于于均匀采样。
温度采样中的温度与玻尔兹曼分布有关,其公式如下所示:
ρi=1Qe−ϵi/kT=e−ϵi/kT∑j=1Me−ϵj/kT\rho_i = \frac{1}{Q}e^{-\epsilon_i/kT}=\frac{e^{-\epsilon_i/kT}}{\sum_{j=1}^M e^{-\epsilon_j/kT}} ρi=Q1e−ϵi/kT=∑j=1Me−ϵj/kTe−ϵi/kT
其中 ρi\rho_iρi 是状态 iii 的概率,ϵi\epsilon_iϵi 是状态 iii 的能量, kkk 是波兹曼常数,TTT 是系统的温度,MMM 是系统所能到达的所有量子态的数目。
有机器学习背景的朋友第一眼看到上面的公式会觉得似曾相识。没错,上面的公式跟Softmax函数Softmax(zi)=ezi∑c=1CezcSoftmax(z_i) = \frac{e^{z_i}}{\sum_{c=1}^Ce^{z_c}}Softmax(zi)=∑c=1Cezcezi 很相似,本质上就是在Softmax函数上添加了温度(T)这个参数。Logits根据我们的温度值进行缩放,然后传递到Softmax函数以计算新的概率分布。
上面“我喜欢漂亮的___”这个例子中,初始温度T=1T=1T=1,我们直观看一下 TTT 取不同值的情况下,概率会发生什么变化:

通过上图我们可以清晰地看到,随着温度的降低,模型愈来愈越倾向选择”女孩“;另一方面,随着温度的升高,分布变得越来越均匀。当T=50T=50T=50时,选择”西瓜“的概率已经与选择”女孩“的概率相差无几了。

通常来说,温度与模型的“创造力”有关。但事实并非如此。温度只是调整单词的概率分布。其最终的宏观效果是,在较低的温度下,我们的模型更具确定性,而在较高的温度下,则不那么确定。
典型用例
temperature = 0.0
temperature=0会消除输出的随机性,这会使得GPT的回答稳定不变。
较低的温度适用于需要稳定性、最可能输出(实际输出、分类等)的情况。
temperature = 1.0
temperature=1每次将产生完全不同的输出,且有时输出的结果会非常搞笑。因此,即便是开放式任务,也应该谨慎使用temperature=1。对于故事创作或创意文案生成等任务,温度值设为0.7到0.9之间更为合适。
temperature = 0.75
通常,温度设在0.70–0.90之间是创造性任务最常见的温度。
虽然存在一些关于温度设置的一般性建议,但没有什么是一成不变的。作为GPT-3最重要的设置之一,实际使用中建议多一试下,看看不同设置对输出效果的影响。
总结
本文详细为大家阐述了temperature和top_p的采样原理,以及它们对模型输出的影响。实际使用中建议只修改其中一个的值,不要两个同时修改。
temperature可以简单得将其理解为“熵”,控制输出的混乱程度(随机性),而top-p可以简单将其理解为候选词列表大小,控制模型所能看到的候选词的多少。实际使用中大家要多尝试不同的值,从而获得最佳输出效果。
另外还有两个参数——frequency_penalty 和 presence_penalty 对生成输出也有较大影响,请参考《ChatGPT模型中的惩罚机制》。
相关文章:
ChatGPT模型采样算法详解
ChatGPT模型采样算法详解 ChatGPT所使用的模型——GPT(Generative Pre-trained Transformer)模型有几个参数,理解它们对文本生成任务至关重要。其中最重要的一组参数是temperature和top_p。二者控制两种不同的采样技术,用于因果…...
【Unity3d】Unity与iOS通信
在unity开发或者sdk开发经常需要用到unity与oc之间进行交互,这里把它们之间通信代码整理出来。 Unity调用Objective-C 主要分三个步骤: (一)、在xcode中定义要被unity调用的函数 新建一个类,名字可以任意,比如UnityBridge&…...

RDD的持久化【博学谷学习记录】
RDD的缓存缓存: 一般当一个RDD的计算非常的耗时|昂贵(计算规则比较复杂),或者说这个RDD需要被重复(多方)使用,此时可以将这个RDD计算完的结果缓存起来, 便于后续的使用, 从而提升效率通过缓存也可以提升RDD的容错能力, 当后续计算失败后, 尽量不让RDD进行回溯所有的依赖链条, 从…...

Python3 正则表达式
Python3 正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。 re 模块使 Python 语言拥有全部的正则表达式功能。 compile 函数根…...

Qt-基础
Qt1. 概念其他概念对话框模态对话框与非模态对话框事件事件拦截/过滤事件例子鼠标/屏幕使用界面功能qt-designer工具debug目录结构mainwindow控件窗口QMainWindow事件2. 项目概览QOBJECT tree 对象树3. 信号和槽信号函数关联自定义信号和槽函数自定义信号和槽函数1自定义信号和…...

ABB机器人将实时坐标发送给西门子PLC的具体方法示例
ABB机器人将实时坐标发送给西门子PLC的具体方法示例 本次以PROFINET通信为例进行说明,演示ABB机器人将实时坐标发送给西门子PLC的具体方法。 首先,要保证ABB机器人和PLC的信号地址分配已经完成,具体的内容可参考以下链接: S7-1200PLC与ABB机器人进行PROFINET通信的具体方法…...

反向传播与梯度下降详解
一,前向传播与反向传播 1.1,神经网络训练过程 神经网络训练过程是: 先通过随机参数“猜“一个结果(模型前向传播过程),这里称为预测结果 a a a;然后计算 a a a 与样本标签值...
Skywalking ui页面功能介绍
菜单栏 仪表盘:查看被监控服务的运行状态; 拓扑图:以拓扑图的方式展现服务之间的关系,并以此为入口查看相关信息; 追踪:以接口列表的方式展现,追踪接口内部调用过程; 性能剖析&am…...
哪里可以找到免费的 PDF 阅读编辑器?7 个免费 PDF 阅读编辑器分享
如果您曾经需要编辑 PDF,您可能会发现很难找到免费的 PDF 编辑器。幸运的是,您可以使用在线资源来编辑该文档,而无需为软件付费。 在本文中,我将介绍七种不同的 PDF 编辑器,它们至少可以让您免费编辑几个文件。我通过…...
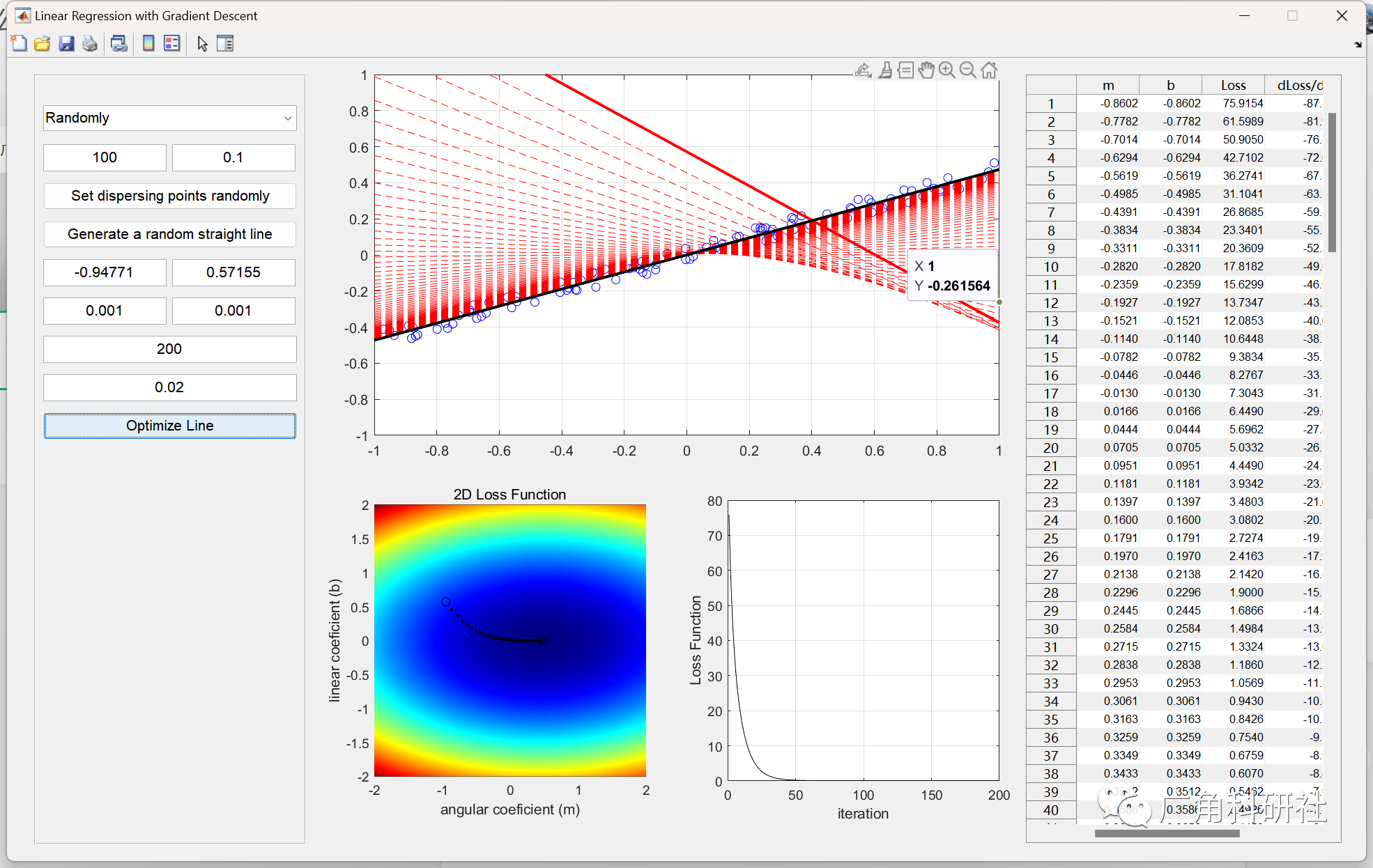
使用梯度下降的线性回归(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 梯度下降法,是一种基于搜索的最优化方法,最用是最小化一个损失函数。梯度下降是迭代法的一种,可以用于求…...
在Ubuntu上设置MySQL可以远程登录
在Ubuntu上设置MySQL可以远程登录一.设置数据库二.设置防火墙由于Ubuntu查看修改MySQL不是很方便,想着在虚拟机安装的Windows系统或者局域网中的其他电脑上去查看Ubuntu系统上的数据库,这样省事一些,我电脑安装的数据库是MySQL8。一.设置数据…...
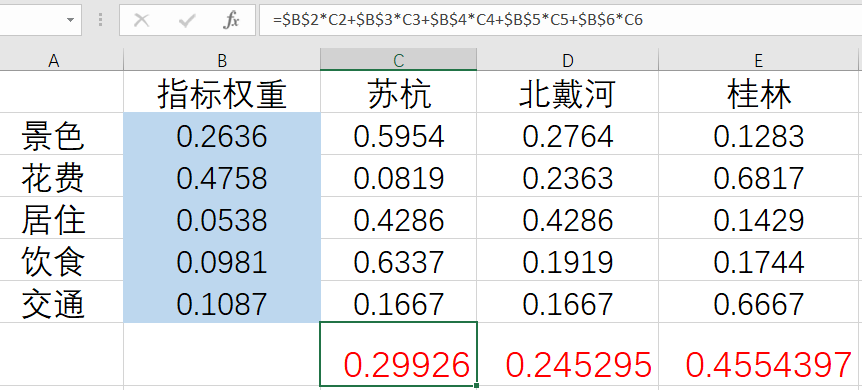
清风1.层次分析法
一.流程1.建立评价体系2.建立判断矩阵2.1 A-C-C矩阵从准则层对目标层的特征向量上看,花费的权重最大算术平均法求权重的结果为:0.26230.47440.05450.09850.1103几何平均法求权重的结果为:0.26360.47730.05310.09880.1072特征值法求权重的结果…...

「首席架构师推荐」免费数据可视化软件你喜欢哪一个?
数据可视化,是关于数据视觉表现形式的科学技术研究。其中,这种数据的视觉表现形式被定义为,一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。它是一个处于不断演变之中的概念,其边界在不断地扩大…...

深度学习术语解释:backbone、head、neck,etc
backbone:翻译为主干网络的意思,既然说是主干网络,就代表其是网络的一部分,那么是哪部分呢?这个主干网络大多时候指的是提取特征的网络,其作用就是提取图片中的信息,共后面的网络使用。这些网络…...
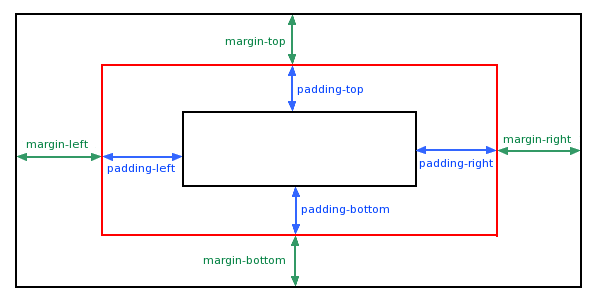
基础篇—CSS margin(外边距)解析
什么是CSS margin(外边距)? CSS margin(外边距)属性定义元素周围的空间。 属性描述margin简写属性。在一个声明中设置所有外边距属性。margin-bottom设置元素的下外边距。margin-left设置元素的左外边距。margin-right设置元素的右外边距。margin-top设置元素的上外边距。mar…...

ChatGPT或将引发新一轮失业潮?是真的吗?
最近,要说有什么热度不减的话题,那ChatGPT必然榜上有名。据悉是这是由美国人工智能研究实验室OpenAI开发的一种全新聊天机器人模型,它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,并协助人类…...
【Selenium学习】Selenium 中特殊元素操作
1.鼠标定位操作鼠标悬停,即当光标与其名称表示的元素重叠时触发的事件,在 Selenium 中将键盘鼠标操作封装在 Action Chains 类中。Action Chains 类的主要应用场景为单击鼠标、双击鼠标、鼠标拖曳等。部分常用的方法使用分类如下:• click(on…...

Spark相关的依赖冲突,后期持续更新总结
Spark相关的依赖冲突持续更新总结 Spark-Hive_2.11依赖报错 这个依赖是Spark开启支持hive SQL解析,其中2.11是Spark对应的Scala版本,如Spark2.4.7,对应的Scala版本是2.11.12;这个依赖会由于Spark内部调用的依赖guava的版本问题出…...

【每日一题Day122】LC1237找出给定方程的正整数解 | 双指针 二分查找
找出给定方程的正整数解【LC1237】 给你一个函数 f(x, y) 和一个目标结果 z,函数公式未知,请你计算方程 f(x,y) z 所有可能的正整数 数对 x 和 y。满足条件的结果数对可以按任意顺序返回。 尽管函数的具体式子未知,但它是单调递增函数&#…...
笔记本加装固态和内存条教程(超详细)
由于笔记本是几年前买的了,当时是4000,现在用起来感到卡顿,启动、运行速度特别慢,就决定换个固态硬盘,加个内存条,再给笔记本续命几年。先说一下加固态硬盘SSD的好处:1.启动快 2.读取延迟小 3.写…...

豆包输入法Mac版正式上线,所有人都该试试AI语音输入了。
豆包输入法的Mac版,终于正式上线了。我自己已经内测使用了快1个月了,但是我等这一天,也真的等了好久好久。因为这篇文章我想写很久了,但是一直没写就是因为,对于大众用户来说,之前还一直没有一个比较好的产…...
)
手把手教你用PyTorch 0.4.1复现D-LinkNet道路分割(附完整代码与数据集)
从零复现D-LinkNet道路分割:PyTorch 0.4.1实战指南 当你在GitHub上发现一个两年前的热门道路分割项目D-LinkNet,却发现它依赖PyTorch 0.4.1和CUDA 8.0这种"古董级"环境时,是否感到无从下手?本文将带你穿越时空…...

解决ROS的‘Done checking log file disk usage’卡顿:你的~/.bashrc里ROS_IP设对了吗?
解决ROS日志检查卡顿:环境变量配置的深层解析与实战指南 当你在终端启动roscore时,是否遇到过长时间卡在"Done checking log file disk usage"提示的尴尬?这个问题看似简单,背后却隐藏着ROS环境配置的关键细节。本文将带…...

PyTorch深度学习资源大全:如何快速找到最佳教程和项目库的终极指南
PyTorch深度学习资源大全:如何快速找到最佳教程和项目库的终极指南 【免费下载链接】the-incredible-pytorch The Incredible PyTorch: a curated list of tutorials, papers, projects, communities and more relating to PyTorch. 项目地址: https://gitcode.c…...

FPGA电源系统设计与线性/开关稳压器应用指南
1. FPGA电源系统设计基础在数字系统设计中,FPGA因其可编程性和高性能已成为现代电子系统的核心器件。随着工艺技术进步,当代FPGA集成了数百万逻辑门、高速收发器、锁相环和专用处理单元,这些复杂模块对供电系统提出了严苛要求。一个典型的Xil…...

从零构建Copaw自定义Channel:WebSocket实时通信与Agent能力接入实战
1. 项目概述:一个最小可用的Copaw自定义Channel实现如果你正在研究如何将Copaw Agent的能力“暴露”给外部世界,比如一个网页、一个桌面应用,或者你自己的业务系统,那么你很可能已经意识到,官方文档里关于Channel的示例…...

如何快速掌握TreeViewer:系统发育树可视化工具的完整指南
如何快速掌握TreeViewer:系统发育树可视化工具的完整指南 【免费下载链接】TreeViewer Cross-platform software to draw phylogenetic trees 项目地址: https://gitcode.com/gh_mirrors/tr/TreeViewer TreeViewer是一款功能强大的跨平台系统发育树可视化软件…...

Neper终极指南:免费开源的多晶体建模与网格划分神器
Neper终极指南:免费开源的多晶体建模与网格划分神器 【免费下载链接】neper Polycrystal generation and meshing 项目地址: https://gitcode.com/gh_mirrors/nep/neper 你是否正在为材料微观结构建模而烦恼?面对复杂的多晶体生成、网格划分和可视…...

Latte文本到视频生成实战:打造个性化AI视频的终极指南
Latte文本到视频生成实战:打造个性化AI视频的终极指南 【免费下载链接】Latte [TMLR 2025] Latte: Latent Diffusion Transformer for Video Generation. 项目地址: https://gitcode.com/gh_mirrors/la/Latte Latte是一款基于TMLR 2025研究成果的文本到视频…...

为什么92%的用户调不出正宗120胶片感?揭秘Midjourney底层色彩映射矩阵与胶片光谱响应偏差
更多请点击: https://intelliparadigm.com 第一章:胶片感的视觉本质与数字复现困境 胶片感并非单一参数可定义的视觉效果,而是由卤化银晶体随机分布、显影化学反应非线性响应、颗粒噪点的空间相关性以及动态范围压缩特性共同构成的模拟物理现…...