RDD的持久化【博学谷学习记录】
RDD的缓存
缓存:
一般当一个RDD的计算非常的耗时|昂贵(计算规则比较复杂),或者说这个RDD需要被重复(多方)使用,此时可以将这个RDD计算完的结果缓存起来, 便于后续的使用, 从而提升效率
通过缓存也可以提升RDD的容错能力, 当后续计算失败后, 尽量不让RDD进行回溯所有的依赖链条, 从而减少重新计算时间
注意:
缓存仅仅是一种临时的存储, 缓存数据可以保存到内存(executor内存空间),也可以保存到磁盘中, 甚至支持将缓存数据保存到堆外内存中(executor以外的系统内容)
由于临时存储, 可能会存在数据丢失, 所以缓存操作, 并不会将RDD之间的依赖关系给截断掉(丢失掉),因为当缓存失效后, 可以基于原有依赖关系重新计算
缓存的API都是LAZY的, 如果需要触发缓存操作, 必须后续跟上一个action算子, 一般建议使用count
如果不添加action算子, 只有当后续遇到第一个action算子后, 才会触发缓存
如何使用缓存
设置缓存的API:
rdd.cache(): 执行缓存操作 仅能将数据缓存到内存中
rdd.persist(缓存的级别(位置)): 执行缓存操作, 默认将数据缓存到内存中, 当然也可以自定义缓存位置
手动清理缓存的API:
rdd.unpersist()
默认情况下, 当整个Spark应用程序执行完成后, 缓存也会自动失效的, 自动删除
常用的缓存级别:
MEMORY_ONLY : 仅缓存到内存中
DISK_ONLY: 仅缓存到磁盘
MEMORY_AND_DISK: 内存 + 磁盘 优先缓存到内存中, 当内存不足的时候, 剩余数据缓存到磁盘中
OFF_HEAP: 缓存到堆外内存
最为常用的: MEMORY_AND_DISK
import timeimport jieba
from pyspark import SparkContext, SparkConf, StorageLevel
import os# 锁定远端环境, 确保环境统一
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
"""清洗需求: 需要先对数据进行清洗转换处理操作, 清洗掉为空的数据, 以及数据字段个数不足6个的数据, 并且将每一行的数据放置到一个元组中, 元组中每一个元素就是一个字段的数据
"""def xuqiu1():# 需求一: 统计每个关键词出现了多少次, 获取前10个res = rdd_map \.flatMap(lambda field_tuple: jieba.cut(field_tuple[2])) \.map(lambda keyWord: (keyWord, 1)) \.reduceByKey(lambda agg, curr: agg + curr) \.sortBy(lambda res_tup: res_tup[1], ascending=False).take(10)print(res)def xuqiu2():res = rdd_map \.map(lambda field_tuple: ((field_tuple[1], field_tuple[2]), 1)) \.reduceByKey(lambda agg, curr: agg + curr) \.top(10, lambda res_tup: res_tup[1])print(res)if __name__ == '__main__':print("Spark的Python模板")# 1. 创建SparkContext核心对象conf = SparkConf().setAppName('sougou').setMaster('local[*]')sc = SparkContext(conf=conf)# 2. 读取外部文件数据rdd = sc.textFile(name='file:///export/data/workspace/ky06_pyspark/_02_SparkCore/data/SogouQ.sample')# 3. 执行相关的操作:# 3.1 执行清洗操作rdd_filter = rdd.filter(lambda line: line.strip() != '' and len(line.split()) == 6)rdd_map = rdd_filter.map(lambda line: (line.split()[0],line.split()[1],line.split()[2][1:-1],line.split()[3],line.split()[4],line.split()[5]))# 由于 rdd_map 被多方使用了, 此时可以将其设置为缓存rdd_map.persist(storageLevel=StorageLevel.MEMORY_AND_DISK).count()# 3.2 : 实现需求# 需求一: 统计每个关键词出现了多少次, 获取前10个# 快速抽取函数: ctrl + alt + Mxuqiu1()# 当需求1执行完成, 让缓存失效rdd_map.unpersist().count()# 需求二:统计每个用户每个搜索词点击的次数xuqiu2()time.sleep(100)RDD的checkpoint检查点
checkpoint比较类似于缓存操作, 只不过缓存是将数据保存到内存 或者 磁盘上, 而checkpoint是将数据保存到磁盘或者HDFS(主要)上
checkpoint提供了更加安全可靠的持久化的方案, 确保RDD的数据不会发生丢失, 一旦构建checkpoint操作后, 会将RDD之间的依赖关系(血缘关系)进行截断,后续计算出来了问题, 可以直接从检查点的位置恢复数据
主要作用: 容错 也可以在一定程度上提升效率(性能) (不如缓存)
在后续计算失败后, 从检查点直接恢复数据, 不需要重新计算
相关的API:
第一步: 设置检查点保存数据位置
sc.setCheckpointDir('路径地址')
第二步: 在对应RDD开启检查点
rdd.checkpoint()
rdd.count()
注意:
如果运行在集群模式中, checkpoint的保存的路径地址必须是HDFS, 如果是local模式 可以支持在本地路径
checkpoint数据不会自动删除, 必须同时手动方式将其删除掉
相关文章:

RDD的持久化【博学谷学习记录】
RDD的缓存缓存: 一般当一个RDD的计算非常的耗时|昂贵(计算规则比较复杂),或者说这个RDD需要被重复(多方)使用,此时可以将这个RDD计算完的结果缓存起来, 便于后续的使用, 从而提升效率通过缓存也可以提升RDD的容错能力, 当后续计算失败后, 尽量不让RDD进行回溯所有的依赖链条, 从…...

Python3 正则表达式
Python3 正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。 re 模块使 Python 语言拥有全部的正则表达式功能。 compile 函数根…...

Qt-基础
Qt1. 概念其他概念对话框模态对话框与非模态对话框事件事件拦截/过滤事件例子鼠标/屏幕使用界面功能qt-designer工具debug目录结构mainwindow控件窗口QMainWindow事件2. 项目概览QOBJECT tree 对象树3. 信号和槽信号函数关联自定义信号和槽函数自定义信号和槽函数1自定义信号和…...

ABB机器人将实时坐标发送给西门子PLC的具体方法示例
ABB机器人将实时坐标发送给西门子PLC的具体方法示例 本次以PROFINET通信为例进行说明,演示ABB机器人将实时坐标发送给西门子PLC的具体方法。 首先,要保证ABB机器人和PLC的信号地址分配已经完成,具体的内容可参考以下链接: S7-1200PLC与ABB机器人进行PROFINET通信的具体方法…...

反向传播与梯度下降详解
一,前向传播与反向传播 1.1,神经网络训练过程 神经网络训练过程是: 先通过随机参数“猜“一个结果(模型前向传播过程),这里称为预测结果 a a a;然后计算 a a a 与样本标签值...
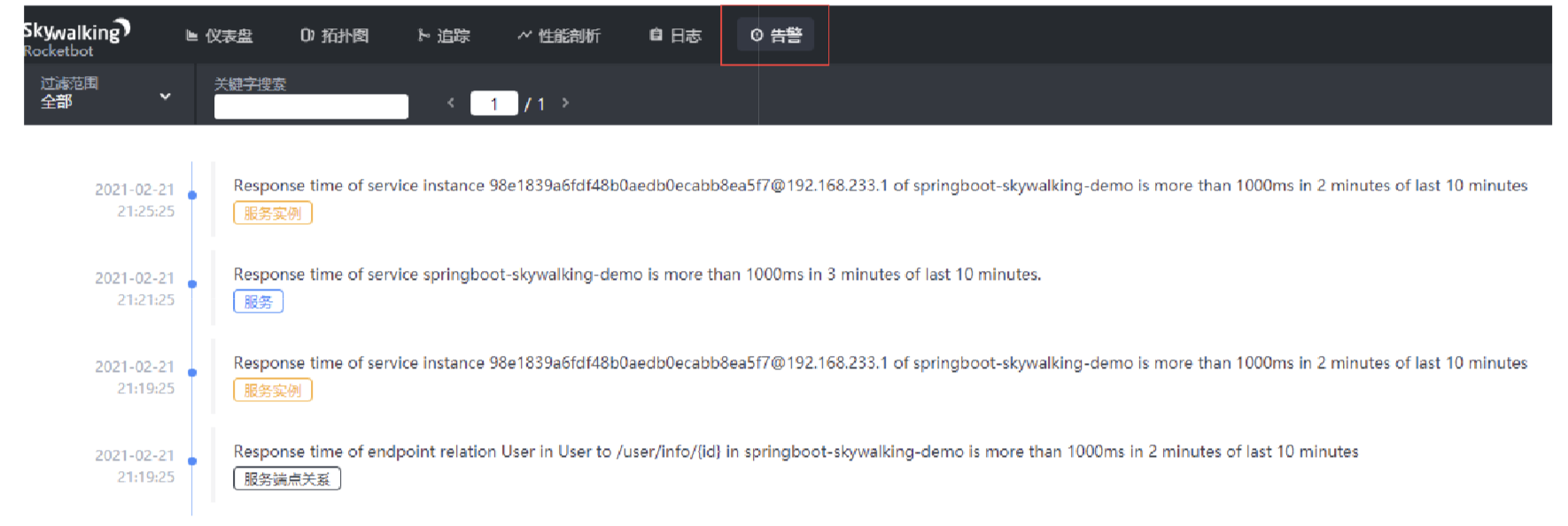
Skywalking ui页面功能介绍
菜单栏 仪表盘:查看被监控服务的运行状态; 拓扑图:以拓扑图的方式展现服务之间的关系,并以此为入口查看相关信息; 追踪:以接口列表的方式展现,追踪接口内部调用过程; 性能剖析&am…...
哪里可以找到免费的 PDF 阅读编辑器?7 个免费 PDF 阅读编辑器分享
如果您曾经需要编辑 PDF,您可能会发现很难找到免费的 PDF 编辑器。幸运的是,您可以使用在线资源来编辑该文档,而无需为软件付费。 在本文中,我将介绍七种不同的 PDF 编辑器,它们至少可以让您免费编辑几个文件。我通过…...
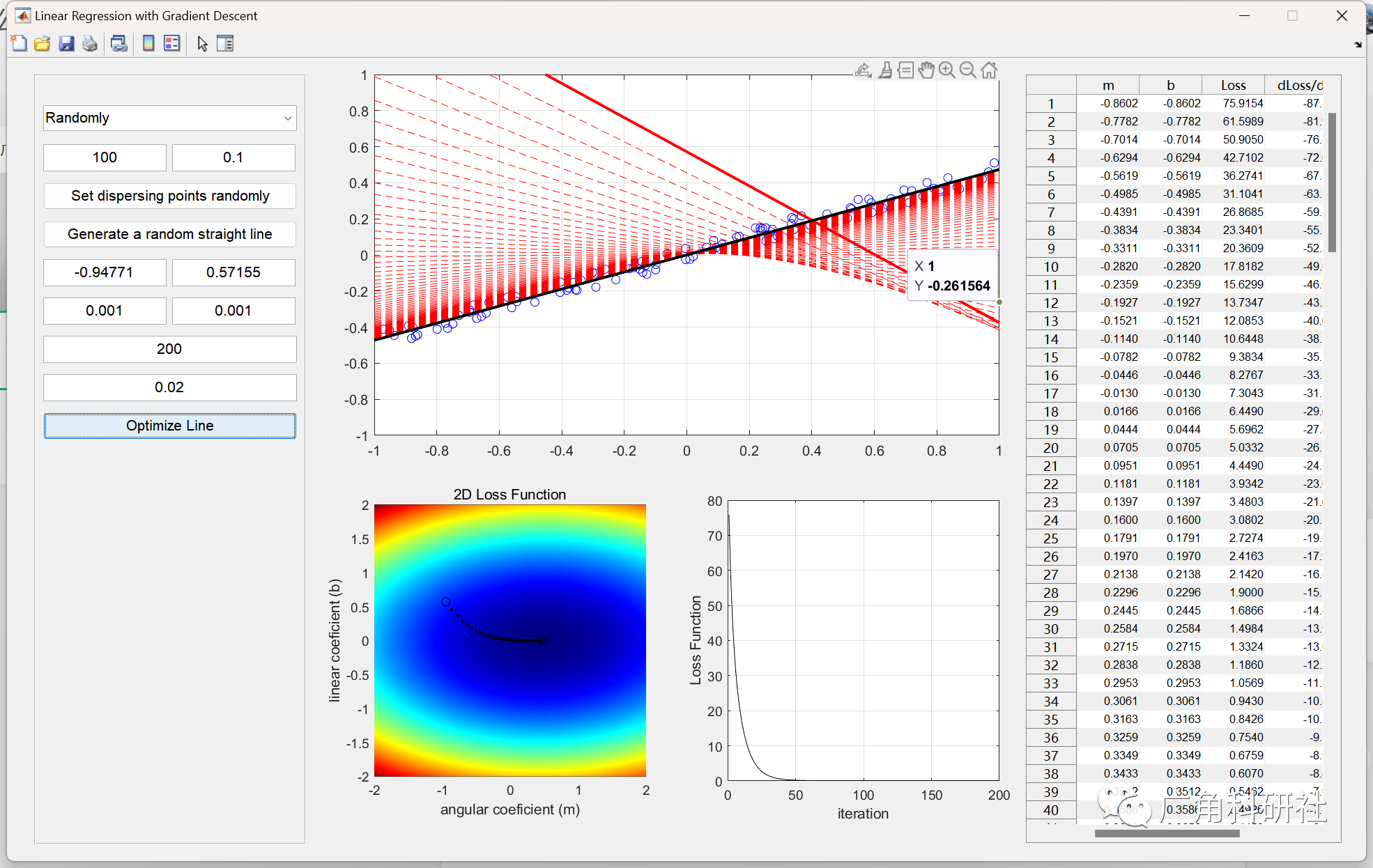
使用梯度下降的线性回归(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 梯度下降法,是一种基于搜索的最优化方法,最用是最小化一个损失函数。梯度下降是迭代法的一种,可以用于求…...
在Ubuntu上设置MySQL可以远程登录
在Ubuntu上设置MySQL可以远程登录一.设置数据库二.设置防火墙由于Ubuntu查看修改MySQL不是很方便,想着在虚拟机安装的Windows系统或者局域网中的其他电脑上去查看Ubuntu系统上的数据库,这样省事一些,我电脑安装的数据库是MySQL8。一.设置数据…...
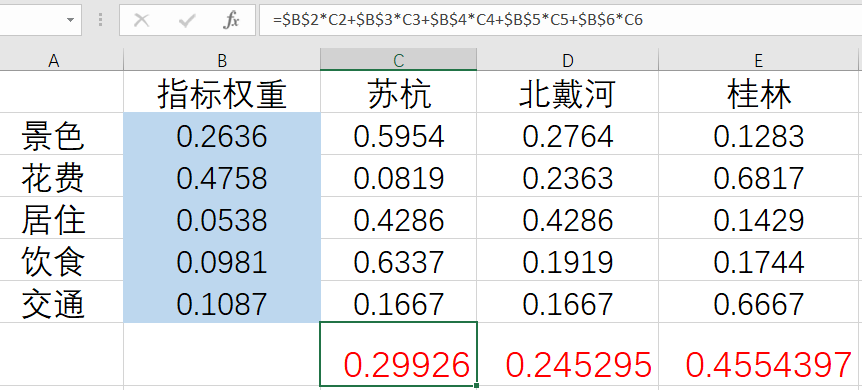
清风1.层次分析法
一.流程1.建立评价体系2.建立判断矩阵2.1 A-C-C矩阵从准则层对目标层的特征向量上看,花费的权重最大算术平均法求权重的结果为:0.26230.47440.05450.09850.1103几何平均法求权重的结果为:0.26360.47730.05310.09880.1072特征值法求权重的结果…...

「首席架构师推荐」免费数据可视化软件你喜欢哪一个?
数据可视化,是关于数据视觉表现形式的科学技术研究。其中,这种数据的视觉表现形式被定义为,一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。它是一个处于不断演变之中的概念,其边界在不断地扩大…...

深度学习术语解释:backbone、head、neck,etc
backbone:翻译为主干网络的意思,既然说是主干网络,就代表其是网络的一部分,那么是哪部分呢?这个主干网络大多时候指的是提取特征的网络,其作用就是提取图片中的信息,共后面的网络使用。这些网络…...
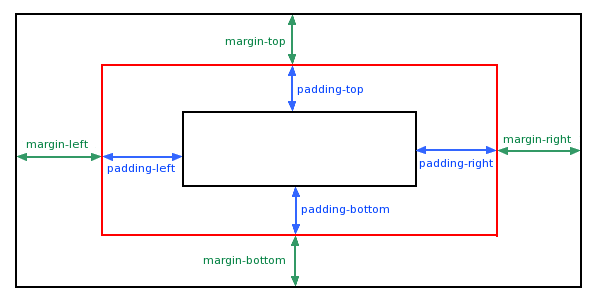
基础篇—CSS margin(外边距)解析
什么是CSS margin(外边距)? CSS margin(外边距)属性定义元素周围的空间。 属性描述margin简写属性。在一个声明中设置所有外边距属性。margin-bottom设置元素的下外边距。margin-left设置元素的左外边距。margin-right设置元素的右外边距。margin-top设置元素的上外边距。mar…...

ChatGPT或将引发新一轮失业潮?是真的吗?
最近,要说有什么热度不减的话题,那ChatGPT必然榜上有名。据悉是这是由美国人工智能研究实验室OpenAI开发的一种全新聊天机器人模型,它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,并协助人类…...
【Selenium学习】Selenium 中特殊元素操作
1.鼠标定位操作鼠标悬停,即当光标与其名称表示的元素重叠时触发的事件,在 Selenium 中将键盘鼠标操作封装在 Action Chains 类中。Action Chains 类的主要应用场景为单击鼠标、双击鼠标、鼠标拖曳等。部分常用的方法使用分类如下:• click(on…...

Spark相关的依赖冲突,后期持续更新总结
Spark相关的依赖冲突持续更新总结 Spark-Hive_2.11依赖报错 这个依赖是Spark开启支持hive SQL解析,其中2.11是Spark对应的Scala版本,如Spark2.4.7,对应的Scala版本是2.11.12;这个依赖会由于Spark内部调用的依赖guava的版本问题出…...

【每日一题Day122】LC1237找出给定方程的正整数解 | 双指针 二分查找
找出给定方程的正整数解【LC1237】 给你一个函数 f(x, y) 和一个目标结果 z,函数公式未知,请你计算方程 f(x,y) z 所有可能的正整数 数对 x 和 y。满足条件的结果数对可以按任意顺序返回。 尽管函数的具体式子未知,但它是单调递增函数&#…...
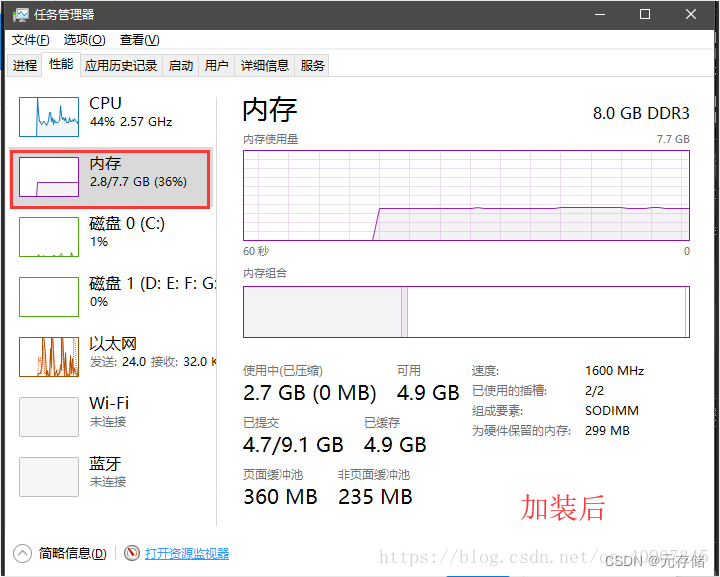
笔记本加装固态和内存条教程(超详细)
由于笔记本是几年前买的了,当时是4000,现在用起来感到卡顿,启动、运行速度特别慢,就决定换个固态硬盘,加个内存条,再给笔记本续命几年。先说一下加固态硬盘SSD的好处:1.启动快 2.读取延迟小 3.写…...

【Python】字典 - Dictionary
字典 - Dictionarykeys()values()items()get()获取文件中指定字符的个数进阶版:获取所有单词的频数进阶版:获取所有字符的频数函数内容keys()输出字典中的所有键values()输出字典中的所有值items()以元组的形式输出键值对get()获取字典中指定键的值 keys…...
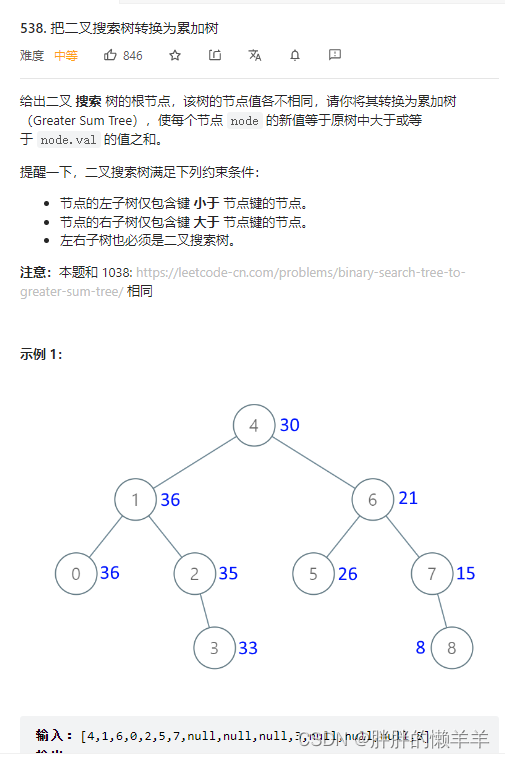
LeetCode分类刷题----二叉树
二叉树1.二叉树的递归遍历144.二叉树的前序遍历145.二叉树的后序遍历94.二叉树的中序遍历2.二叉树的迭代遍历144.二叉树的前序遍历145.二叉树的后序遍历94.二叉树的中序遍历3.二叉树的层序遍历102.二叉树的层序遍历107.二叉树的层序遍历||199.二叉树的右视图637.二叉树的层平均…...
)
手把手教你用PyTorch 0.4.1复现D-LinkNet道路分割(附完整代码与数据集)
从零复现D-LinkNet道路分割:PyTorch 0.4.1实战指南 当你在GitHub上发现一个两年前的热门道路分割项目D-LinkNet,却发现它依赖PyTorch 0.4.1和CUDA 8.0这种"古董级"环境时,是否感到无从下手?本文将带你穿越时空…...

五分钟 熟悉所有Claude Code指令
废话不多说,直接上干货,点赞收藏一、 启动与退出cd xx #进入你的项目 claude start # 启动 Claude Code claude exit # 退出二、查看帮助claude /help # 显示所有命令及使用说明 claude /status # 查看当前会话状态三、文件操作claude /add <file&g…...

[特殊字符] 论文查重还在花钱?这个AI平台凭什么敢免费?一条给你讲透
各位正在跟论文死磕的朋友们,今天咱们不聊选题,不聊文献,聊一个每个毕业生都绑不开的刚需——查重。 你有没有算过一笔账?本科论文查一次少说三四十,硕士论文动辄上百,有些平台甚至标价两三百。一篇论文改…...
)
微分方程详解(理工科)
一句总纲:微分方程不是在求一个数,而是在求一个函数。它研究的是:如果我知道一个系统“怎么变化”,能不能反推出它“长什么样”。普通方程:未知量是一个数 (x)。微分方程:未知量是一个函数 y(x)。它的意思是…...

9D传感器融合技术:原理、优化与应用
1. 9D传感器融合技术概述在当今的智能设备领域,精确的姿态感知已成为标配功能。从智能手机的自动旋转屏幕到VR头显的动作追踪,背后都离不开多传感器数据的融合处理。9D传感器融合技术通过整合加速度计、陀螺仪和磁力计的数据(各提供3轴测量&a…...

AI小白必看:收藏这份从零入门大模型的核心概念指南
本文通过一个生动的故事,用通俗易懂的方式讲解了AI领域最核心的7个概念:LLM(大语言模型)、Agent(智能体)、Skill(技能包)、MCP(模型上下文协议)、IDE…...

im2col算法实现:从原理到代码的逐行剖析
1. im2col算法原理揭秘 想象你正在整理一副扑克牌,需要把相邻的几张牌快速组合起来。im2col算法的核心思想与此类似——它将图像中相邻的像素区域重新排列成矩阵的列,从而将卷积运算转化为高效的矩阵乘法。这个"image to column"的转换过程&am…...

从佳能FS20文件管理混乱看工程师思维陷阱与视频素材管理实战
1. 项目概述:一个让技术博主抓狂的摄像机文件管理系统作为一名经常需要拍摄产品评测、开箱视频的技术博主,我每天打交道最多的除了代码,就是各种拍摄设备。最近在整理几年前的老项目素材时,翻出了一台经典的佳能FS20摄像机&#x…...

面向软件测试从业者的多模态AI系统评估体系构建指南
随着人工智能技术的飞速演进,多模态AI系统正逐渐从实验室走向广泛的产业应用。这类系统能够同时处理和理解文本、图像、音频、视频等多种模态的信息,并实现跨模态的语义融合与推理。对于软件测试从业者而言,评估此类系统的复杂性远超传统单模…...

2026届必备的六大AI辅助写作网站横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 现今,各类数字化内容的AI生成痕迹核验标准不断持续迭代,多数内容创作…...