clickhouse查询缓存
为了实现最佳性能,数据库需要优化其内部数据存储和处理管道的每一步。但是数据库执行的最好的工作是根本没有完成的工作!缓存是一种特别流行的技术,它通过存储早期计算的结果或远程数据来避免不必要的工作,而访问这些数据的成本往往很高。在今天的博文中,介绍一下 ClickHouse 缓存系列的最新成员——查询缓存,在 v23.1 版本中作为实验性特性。
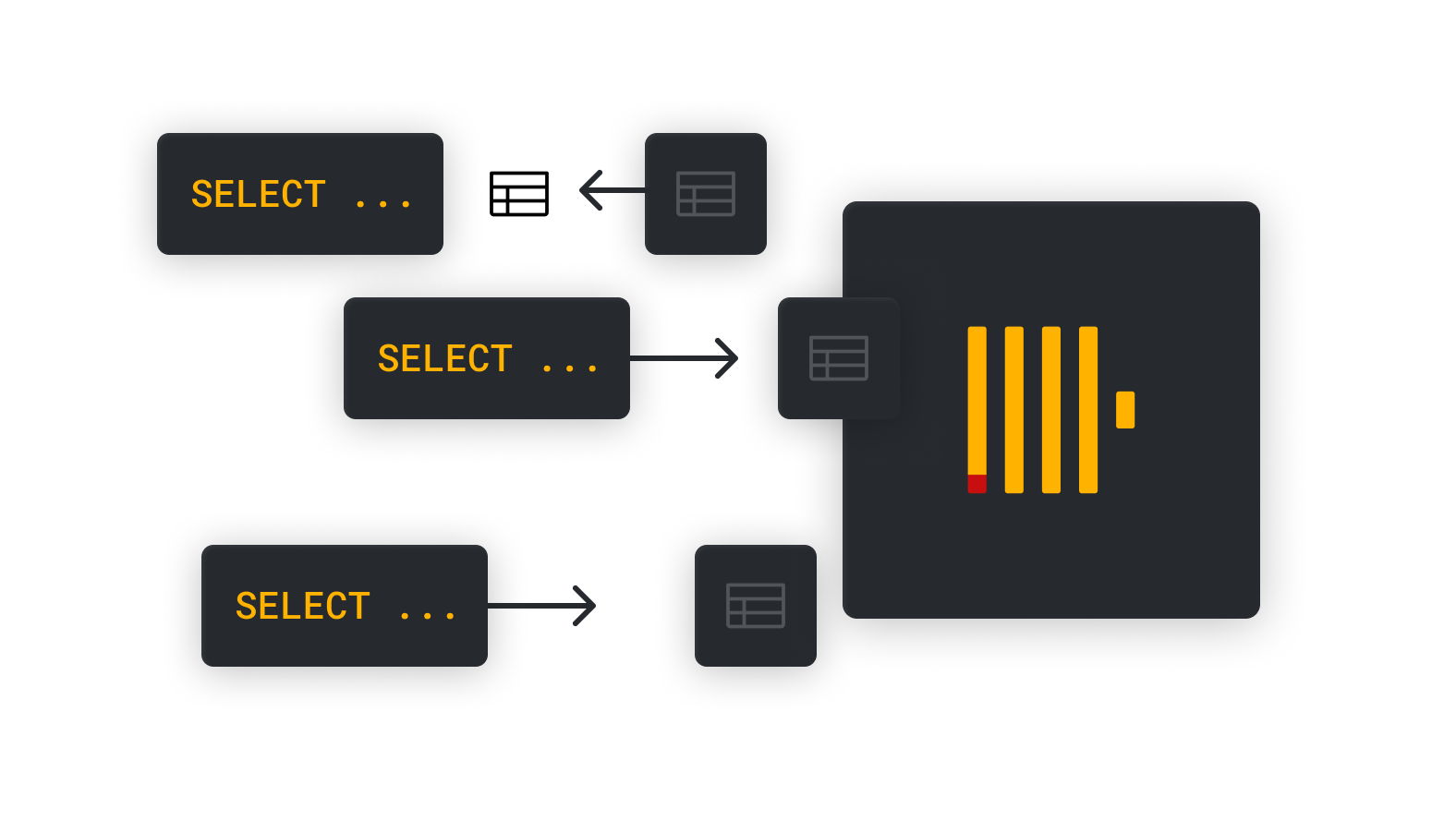
一、缓存一致性问题
在实操 clickhouse 的查询缓存前需要先了解一下缓存事务问题,查询缓存通常可以分为事务一致和事务不一致。
在事务一致缓存中,如果 SELECT 查询的结果发生更改或可能发生更改,则数据库会使缓存的查询结果无效(丢弃)。在 ClickHouse 中,更改数据的操作包括在表中插入/更新/删除或折叠合并。事务一致性缓存特别适合 OLTP 数据库,例如MySQL(在v8.0之后删除了查询缓存)和 Oracle。
在事务不一致缓存中,所有缓存条目都被分配了一个有效期,之后它们就会过期,并且基础数据在此期间仅发生很小的变化,那么查询结果中的轻微不准确是可以接受的,这种方法总体上更适合 OLAP 数据库。在一些应用场景中数据的变化假如很慢,数据库就只需要计算一次报告(由第一个 SELECT 查询表示)。可以直接从查询缓存提供进一步的查询。
事务上不一致的缓存通常是由与数据库交互的客户端工具或代理包提供的
二、查询缓存实操
2.1 前期准备
这里使用 clickhouse 官方提供的 Anonymized Web Analytics Data,数据集下载
准备数据表
CREATE TABLE hits_100m_obfuscated
(WatchID UInt64,JavaEnable UInt8,Title String,GoodEvent Int16,EventTime DateTime,EventDate Date,CounterID UInt32,ClientIP UInt32,RegionID UInt32,UserID UInt64,CounterClass Int8,OS UInt8,UserAgent UInt8,URL String,Referer String,Refresh UInt8,RefererCategoryID UInt16,RefererRegionID UInt32,URLCategoryID UInt16,URLRegionID UInt32,ResolutionWidth UInt16,ResolutionHeight UInt16,ResolutionDepth UInt8,FlashMajor UInt8,FlashMinor UInt8,FlashMinor2 String,NetMajor UInt8,NetMinor UInt8,UserAgentMajor UInt16,UserAgentMinor FixedString(2),CookieEnable UInt8,JavascriptEnable UInt8,IsMobile UInt8,MobilePhone UInt8,MobilePhoneModel String,Params String,IPNetworkID UInt32,TraficSourceID Int8,SearchEngineID UInt16,SearchPhrase String,AdvEngineID UInt8,IsArtifical UInt8,WindowClientWidth UInt16,WindowClientHeight UInt16,ClientTimeZone Int16,ClientEventTime DateTime,SilverlightVersion1 UInt8,SilverlightVersion2 UInt8,SilverlightVersion3 UInt32,SilverlightVersion4 UInt16,PageCharset String,CodeVersion UInt32,IsLink UInt8,IsDownload UInt8,IsNotBounce UInt8,FUniqID UInt64,OriginalURL String,HID UInt32,IsOldCounter UInt8,IsEvent UInt8,IsParameter UInt8,DontCountHits UInt8,WithHash UInt8,HitColor FixedString(1),LocalEventTime DateTime,Age UInt8,Sex UInt8,Income UInt8,Interests UInt16,Robotness UInt8,RemoteIP UInt32,WindowName Int32,OpenerName Int32,HistoryLength Int16,BrowserLanguage FixedString(2),BrowserCountry FixedString(2),SocialNetwork String,SocialAction String,HTTPError UInt16,SendTiming UInt32,DNSTiming UInt32,ConnectTiming UInt32,ResponseStartTiming UInt32,ResponseEndTiming UInt32,FetchTiming UInt32,SocialSourceNetworkID UInt8,SocialSourcePage String,ParamPrice Int64,ParamOrderID String,ParamCurrency FixedString(3),ParamCurrencyID UInt16,OpenstatServiceName String,OpenstatCampaignID String,OpenstatAdID String,OpenstatSourceID String,UTMSource String,UTMMedium String,UTMCampaign String,UTMContent String,UTMTerm String,FromTag String,HasGCLID UInt8,RefererHash UInt64,URLHash UInt64,CLID UInt32
)ENGINE = MergeTree()PARTITION BY toYYYYMM(EventDate)ORDER BY (CounterID, EventDate, intHash32(UserID))SAMPLE BY intHash32(UserID) SETTINGS index_granularity = 8192;
导入数据建议使用 clickhouse-client 来操作,下面基于 centos 或 rpm 安装客户端
yum install -y yum-utils
yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.repo
yum install -y clickhouse-client
导入数据
# 解压数据文件
xz -dk hits_100m_obfuscated_v1.tsv.xz
# 导入数据
cat hits_100m_obfuscated_v1.tsv | clickhouse-client -h 192.168.0.190 -u admin --password admin --query "insert into hits_100m_obfuscated FORMAT TSV" --max_insert_block_size=100000
查看数据量
select count() from hits_100m_obfuscated;Query id: 9152e4a1-fea1-4869-9857-656fc0d4d68a┌───count()─┐
│ 100000000 │
└───────────┘1 row in set. Elapsed: 0.007 sec.
2.2 查询缓存
假象一个需求:根据操作系统、浏览器和引用页面(Referer),计算总访问量和访问者数量,sql 极其执行结果如下
SELECT OS AS OperatingSystem,UserAgent AS Browser,Referer AS ReferringPage,COUNT(*) AS TotalVisits,COUNT(DISTINCT UserID) AS UniqueVisitors
FROM hits_100m_obfuscated
GROUP BY OperatingSystem, Browser, ReferringPage
ORDER BY UniqueVisitors DESC
LIMIT 10;Query id: 458deafe-25fb-4695-bbbf-87bd14e0b7ff┌─OperatingSystem─┬─Browser─┬─ReferringPage───────┬─TotalVisits─┬─UniqueVisitors─┐
│ 44 │ 5 │ │ 2724345 │ 1261517 │
│ 44 │ 7 │ │ 2236143 │ 798198 │
│ 44 │ 2 │ │ 1713149 │ 633544 │
│ 44 │ 3 │ │ 1815864 │ 625035 │
│ 2 │ 5 │ │ 1075898 │ 515312 │
│ 2 │ 3 │ │ 1378892 │ 504849 │
│ 159 │ 32 │ │ 924871 │ 432929 │
│ 2 │ 2 │ │ 1064491 │ 407627 │
│ 2 │ 7 │ │ 914442 │ 338232 │
│ 44 │ 5 │ http://новострашная │ 464194 │ 316512 │
└─────────────────┴─────────┴─────────────────────┴─────────────┴────────────────┘10 rows in set. Elapsed: 6.145 sec. Processed 100.00 million rows, 8.56 GB (16.27 million rows/s., 1.39 GB/s.)
平均执行时长 6 秒。
作为实验性功能查询缓存默认关闭,通过下面方式开启
set allow_experimental_query_cache = true;
同时在查询语句中显式指定启用缓存
SELECT OS AS OperatingSystem,UserAgent AS Browser,Referer AS ReferringPage,COUNT(*) AS TotalVisits,COUNT(DISTINCT UserID) AS UniqueVisitors
FROM hits_100m_obfuscated
GROUP BY OperatingSystem, Browser, ReferringPage
ORDER BY UniqueVisitors DESC
LIMIT 10
SETTINGS use_query_cache = true;Query id: 93098a52-adcb-421f-bc68-acbfd5b1af8b┌─OperatingSystem─┬─Browser─┬─ReferringPage───────┬─TotalVisits─┬─UniqueVisitors─┐
│ 44 │ 5 │ │ 2724345 │ 1261517 │
│ 44 │ 7 │ │ 2236143 │ 798198 │
│ 44 │ 2 │ │ 1713149 │ 633544 │
│ 44 │ 3 │ │ 1815864 │ 625035 │
│ 2 │ 5 │ │ 1075898 │ 515312 │
│ 2 │ 3 │ │ 1378892 │ 504849 │
│ 159 │ 32 │ │ 924871 │ 432929 │
│ 2 │ 2 │ │ 1064491 │ 407627 │
│ 2 │ 7 │ │ 914442 │ 338232 │
│ 44 │ 5 │ http://новострашная │ 464194 │ 316512 │
└─────────────────┴─────────┴─────────────────────┴─────────────┴────────────────┘10 rows in set. Elapsed: 0.003 sec.
上述结果是第二次查询,发现几乎不消耗时间,同时打印查询日志
select query_duration_ms, read_rows, read_bytes, memory_usage
from system.query_log
where query_id in ('93098a52-adcb-421f-bc68-acbfd5b1af8b', '458deafe-25fb-4695-bbbf-87bd14e0b7ff')and type = 'QueryFinish';Query id: b224a866-6eed-42a5-b81f-d186568e2570┌─query_duration_ms─┬─read_rows─┬─read_bytes─┬─memory_usage─┐
│ 6125 │ 100000000 │ 8562787759 │ 14943181799 │
│ 2 │ 10 │ 301 │ 9912 │
└───────────────────┴───────────┴────────────┴──────────────┘2 rows in set. Elapsed: 0.049 sec. Processed 1.97 thousand rows, 153.00 KB (40.50 thousand rows/s., 3.15 MB/s.)
可以看出查询缓存对用户体验的提升是极高的
虽然可以在配置文件中全局开启查询缓存,但是这样所有的 SELECT 查询(包括对系统表的监视或调试查询)都可能会返回缓存,所以还是针对特定查询语句提供缓存功能
三、进阶
3.1 缓存配置
如何确定查询是否命中缓存?语法如下
select query_id,ProfileEvents['QueryCacheHits'] AS query_cache,query_duration_ms / 1000 AS query_duration,formatReadableSize(memory_usage) AS memory_usage,formatReadableQuantity(read_rows) AS read_rows,formatReadableSize(read_bytes) AS read_data
from system.query_log
where type = 'QueryFinish'and query_id in ('93098a52-adcb-421f-bc68-acbfd5b1af8b', '458deafe-25fb-4695-bbbf-87bd14e0b7ff');Query id: 04744ba4-d3cb-4f28-84fc-81a2e7598789┌─query_id─────────────────────────────┬─query_cache─┬─query_duration─┬─memory_usage─┬─read_rows──────┬─read_data─┐
│ 458deafe-25fb-4695-bbbf-87bd14e0b7ff │ 0 │ 6.125 │ 13.92 GiB │ 100.00 million │ 7.97 GiB │
│ 93098a52-adcb-421f-bc68-acbfd5b1af8b │ 1 │ 0.002 │ 9.68 KiB │ 10.00 │ 301.00 B │
└──────────────────────────────────────┴─────────────┴────────────────┴──────────────┴────────────────┴───────────┘2 rows in set. Elapsed: 0.024 sec. Processed 2.00 thousand rows, 364.80 KB (83.00 thousand rows/s., 15.17 MB/s.)
如果想要更详细的了解系统中存在哪些缓存,可以查询 system.query_cache 表(结果展示太长,直接使用工具查询后截图)

其中
- query:缓存的查询语句
- result_size:缓存数据的大小,单位 byte
- stale:缓存是否可用,0 表示可用,否则为不可用,需要重新执行缓存 query 将新的结果存储到缓存中
- shard:缓存所存储的分片节点
- compressed:是否被压缩,1 表示压缩,否则缓存没有被压缩
- expires_at:缓存过期时间
- key_hash:缓存的唯一标识
key_hash 主要被用来标识哪个缓存,在 clickhouse 中查询缓存会以 hash 表的形式存储在内存中
下面来介绍一下缓存的高级用法及其配置
3.1.1 更精细的缓存控制
use_query_cache 用户开启查询缓存,但如果我们需要更精细的控制查询缓存则需要额外的配置,例如:我只需要从缓存中读取数据而不想将新的查询结果写入缓存中。
SELECT OS AS OperatingSystem,UserAgent AS Browser,Referer AS ReferringPage,COUNT(*) AS TotalVisits,COUNT(DISTINCT UserID) AS UniqueVisitors
FROM hits_100m_obfuscated
GROUP BY OperatingSystem, Browser, ReferringPage
ORDER BY UniqueVisitors DESC
LIMIT 10
SETTINGS
use_query_cache = true,
enable_writes_to_query_cache = false,
enable_reads_from_query_cache = true;
enable_writes_to_query_cache: 是否将查询缓存写入缓存中,禁止时所有的缓存都不会被写入。即:缓存如果存在直接获取,缓存失效后改查询不在缓存
enable_reads_from_query_cache: 是否从缓存中读取数据,禁止时及时缓存命中也不会获取缓存数据而是直接查询原始数据
该参数可以精细控制缓存,让用户可以精准把控业务查询是否要走缓存,因为缓存在带来查询效率提升的同时,也带来了查询不一致的情况需要在生产中结合实际场景进行合理配置
上述的两个配置需要在
use_query_cache开启的情况下才会起作用
3.1.2 缓存时间控制
从 system.query_cache 表的 expires_at 字段可以获知缓存的过期时间,默认为 1min,该配置允许用户根据实际业务需求自己配置
SELECT OS AS OperatingSystem,UserAgent AS Browser,Referer AS ReferringPage,COUNT(*) AS TotalVisits,COUNT(DISTINCT UserID) AS UniqueVisitors
FROM hits_100m_obfuscated
GROUP BY OperatingSystem, Browser, ReferringPage
ORDER BY UniqueVisitors DESC
LIMIT 10
SETTINGS
use_query_cache = true,
query_cache_ttl = 30;
query_cache_ttl: 缓存的过期时间,单位:秒
该配置交给各位看官自己去验证
3.1.3 缓存大小控制
缓存虽好,但不能过度使用。如果不加以限制服务器 OOM 随时可能发生,例如某个用户在查询明细表时开启了缓存那么将是灾难级的。好在 clickhouse 提供了缓存大小的控制。
从粗粒度层面可以控制当前节点的缓存大小和个数,在config.xml中
<query_cache><!-- 查询缓存总大小,单位:byte --><size>1073741824</size><!-- 可以缓存的查询条数 --><max_entries>1024</max_entries><!-- 允许缓存的单个查询最大容量 单位:byte --><max_entry_size>1048576</max_entry_size><!-- 许缓存的单个查询最大行数 --><max_entry_records>30000000</max_entry_records>
</query_cache>
- size:限制节点可以缓存的总大小,上面配置了 1G,如果超过阈值会删除所有过期的缓存,此时如果没有足够空间则不会插入新的条目
- max_entries:限制节点可以缓存的总条数,上面配置了 1024 条,如果超过阈值会删除所有过期的缓存,此时如果没有足够空间则不会插入新的条目
- max_entry_size:限制单个查询可以缓存的容留上限,上面配置了 1M,如果超过这个阈值该查询不会被缓存
- max_entry_records:限制单个查询可以缓存的行数上线,上面配置了 3000w,如果超过这个阈值该查询不会被缓存
从用户细粒度控制可以缓存的大小和个数,在用户独立的配置文件或用户配置域内
<profiles><default><!-- default 用户可以缓存的最大空间,单位字节 --><query_cache_max_size_in_bytes>10000</query_cache_max_size_in_bytes><!-- default 用户可以缓存的查询条数 --><query_cache_max_entries>100</query_cache_max_entries><!-- 设置配置只读,不允许修改 --><constraints><query_cache_max_size_in_bytes><readonly/></query_cache_max_size_in_bytes><query_cache_max_entries><readonly/><query_cache_max_entries></constraints></default>
</profiles>
如果用户需要尽可能多的缓存大数据集的话可以开启缓存压缩,当然默认就是开启的。
SELECT ...
SETTINGS use_query_cache = true,query_cache_compress_entries = true;
缓存压缩可以大幅降低内存消耗,但查询缓存的写入和读取效率将会被降低
3.1.4 缓存行为控制
为了让缓存可以被应用在频繁且耗时的查询中,可以控制查询次数和查询耗时来避免一些本身相对较快的查询来消耗缓存空间
SELECT OS AS OperatingSystem,UserAgent AS Browser,Referer AS ReferringPage,COUNT(*) AS TotalVisits,COUNT(DISTINCT UserID) AS UniqueVisitors
FROM hits_100m_obfuscated
GROUP BY OperatingSystem, Browser, ReferringPage
ORDER BY UniqueVisitors DESC
LIMIT 10
SETTINGS
use_query_cache = true,
query_cache_min_query_duration = 5000,
query_cache_min_query_runs = 2;
use_query_cache_min_query_duration: 查询至少耗时 5000 毫秒才会被缓存
use_query_cache_min_query_runs: 查询至少运行 2 次以上才会被缓存
如果都配置则需要同时满足才会被缓存
上述配置主要是为了约束将缓存空间用在真正需要被缓存的 sql 上
3.1.5 事务不一致的缓存
在使用一些带有随机语义函数的查询时 clickhouse 默认是不缓存的,例如:now() 和 rand() 函数,例如:
SELECT OS AS OperatingSystem,UserAgent AS Browser,Referer AS ReferringPage,COUNT(*) AS TotalVisits,COUNT(DISTINCT UserID) AS UniqueVisitors
FROM hits_100m_obfuscated
where EventDate >= toDateTime('2013-07-10 00:00:00')and EventDate <= now()
GROUP BY OperatingSystem, Browser, ReferringPage
ORDER BY UniqueVisitors DESC
LIMIT 10
SETTINGS
use_query_cache = true;
即使开启了use_query_cache也不会被缓存,因为查询中存在不确定函数 now(),clickhouse 并不知道原表的数据何时发生变化,这就会导致此类函数的查询存在数据不一致情况。当然如果业务场景允许,需要追求极致的查询体验,可以开启query_cache_store_results_of_queries_with_nondeterministic_functions
SELECT OS AS OperatingSystem,UserAgent AS Browser,Referer AS ReferringPage,COUNT(*) AS TotalVisits,COUNT(DISTINCT UserID) AS UniqueVisitors
FROM hits_100m_obfuscated
where EventDate >= toDateTime('2013-07-10 00:00:00')and EventDate <= now()
GROUP BY OperatingSystem, Browser, ReferringPage
ORDER BY UniqueVisitors DESC
LIMIT 10
SETTINGS
use_query_cache = true,
query_cache_store_results_of_queries_with_nondeterministic_functions = true;
此时查询 system.query_cache 就可以看到
3.1.6 缓存共享
clickhouse 默认不允许多个用户之间共享缓存,因为这个操作太过于危险。如果有必要通过query_cache_share_between_users开启
SELECT ...
SETTINGS use_query_cache = true, query_cache_share_between_users = true;
3.1.7 删除缓存
system drop query cache [on cluster cluster_name];
此操作会删除该节点所有缓存(过期不过期都会被删除)
3.2 不足
- 从目前来看,我并没有找到删除指定缓存的方式只能删除全部缓存,显然这个操作是被禁止的
- 暂不支持缓存淘汰策略(如:LRU),当前的做法是当缓存达到上限自动删除所有过期缓存
- 当前缓存被存储在内存的哈希表中并没有持久化,当服务器重启后缓存将会失效
当然上述的不足在 clickhouse 的 roadmap 均有体现,相信在不久将来的新版本中查询缓存将越来越优秀
相关文章:
clickhouse查询缓存
为了实现最佳性能,数据库需要优化其内部数据存储和处理管道的每一步。但是数据库执行的最好的工作是根本没有完成的工作!缓存是一种特别流行的技术,它通过存储早期计算的结果或远程数据来避免不必要的工作,而访问这些数据的成本往…...

vue中使用Base64加密、解密以及des加密、解密
Base64加密、解密 第一步: npm install js-base64 --save 下载依赖 第二步: 直接引入即可 import { Base64 } from js-base64; 第三步: Base64.encode(xxxx) 其中 .encode() 加密 .decode() 解密 中间不需要使用加密的key等…...
关于丢失安卓秘钥的撞sha-1值的办法
实验得知,安卓sha-1和keytool生成秘钥签名文件的时间有关。 前提条件是,开发者必须知道生成秘钥的所有细节参数 以下是撞文件代码(重复生成) import time import osidx 0while True:cmdkeytool -keyalg RSA -genkeypair -alia…...
maven如何打包你会吗?
1.新建一个maven项目,在main/java中建立Main类 public class Main {public static void main(String[] args) {System.out.println("hello java ...");} } 2.添加依赖,使其成为可执行包 <build><plugins><!--打包成为可执行包-…...

idea 控制台 打印 Tomcat日志Tomcat Catalina Log控制台乱码问题
修改tomcat的日志配置文件 conf一>logging.properties 修改【1catalina.org.apache.juli.AsyncFileHandler.encoding】的值为gbk 1catalina.org.apache.juli.AsyncFileHandler.level FINE 1catalina.org.apache.juli.AsyncFileHandler.directory ${catalina.base}/logs 1…...

python我的世界
我的世界不知道大家有没有玩过,今天博主用python的Ursina库复刻了我的世界给大家分享 安装Ursina pip install ursina 导入Ursina from ursina import * from ursina.prefabs.first_person_controller import FirstPersonController 创建app app Ursina() 创建Voxe…...

SpringBoot+vue 大文件分片下载
学习链接 SpringBootvue文件上传&下载&预览&大文件分片上传&文件上传进度 Blob & File & FileReader & ArrayBuffer VueSpringBoot实现文件的分片下载 video标签学习 & xgplayer视频播放器分段播放mp4(Range请求交互过程可以参…...
scanf函数读取数据 清空缓冲区
scanf函数读取数据&清空缓冲区 scanf 从输入缓冲区读取数据数据的接收数据存入缓冲区scanf 中%d读取数据scanf中%c读取数据 清空输入缓冲区例子用getchar()吸收回车练习 scanf 从输入缓冲区读取数据 首先,要清楚的是,scanf在读取数据的时候ÿ…...

js 文件常用转换
获取上传文件的arrayBuffer:var u8arr await file.arrayBuffer() 通过arrayBuffer转换成Buffer:Buffer.from(u8arr) 1. Blob、File → Base64 function fileToDataURL(file) {let reader new FileReader();reader.readAsDataURL(file);reader.onload…...
基于Open3D的点云处理15-特征点
Intrinsic shape signatures (ISS) 参考 ISS关键点: 基本原理是避免在沿主要方向表现出类似分布的点上检测关键点,在这些点上无法建立可重复的规范参考框架,因此后续描述阶段很难变得有效。在剩余点中,显着性由最小特征值的大小决定,以便仅包…...

算法刷题Day 58 每日温度+下一个更大元素I
Day 58 单调栈 739. 每日温度 class Solution { public:vector<int> dailyTemperatures(vector<int>& temperatures) {vector<int> rst(temperatures.size());vector<int> decsStk; // 单调递减栈for (int i 0; i < temperatures.size(); i)…...

认识 spring AOP (面向切面编程) - springboot
前言 本篇介绍什么是spring AOP, AOP的优点,使用场景,spring AOP的组成,简单实现AOP 并 了解它的通知;如有错误,请在评论区指正,让我们一起交流,共同进步! 文章目录 前言1. 什么是s…...

将css文件中的px转化为rem
pxToRem.js /*** 使用方式:* 与引入的文件放在同一目录下进行引用配置,执行:node (定义的文件)*/ const fs require(fs) const path require(path) /*** entry:入口文件路径 type:Strng* pxtopx:以倍数转…...

JNI之Java实现远程打印
打印机是最常见的办公设备了。一般情况下如果需要实现打印,可通过前端print.js包来完成。但是,如果要实现智能办公打印,就可以使用JNI技术、封装接口、远程调用实现完成。 导包 jacob:Java COM Bridge <dependency><g…...

YOLOv5基础知识入门(2)— YOLOv5核心基础知识讲解
前言:Hello大家好,我是小哥谈。YOLOV4出现之后不久,YOLOv5横空出世。YOLOv5在YOLOv4算法的基础上做了进一步的改进,使检测性能得到更进一步的提升。YOLOv5算法作为目前工业界使用的最普遍的检测算法,存在着很多可以学习…...

免费的scrum敏捷开发管理工具
Scrum中非常强调公开、透明、直接有效的沟通,这也是“可视化的管理工具”在敏捷开发中如此重要的原因之一。通过“可视化的管理工具”让所有人直观的看到需求,故事,任务之间的流转状态,可以使团队成员更加快速适应敏捷开发流程。 …...
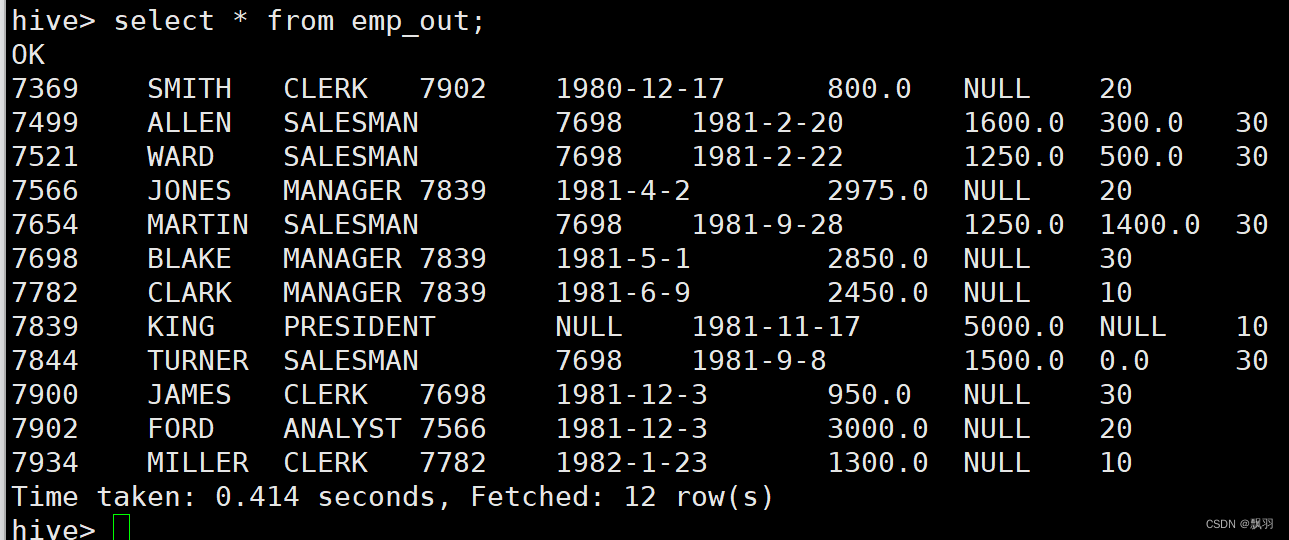
Hive创建外部表详细步骤
① 在hive中执行HDFS命令:创建/data目录 hive命令终端输入: hive> dfs -mkdir -p /data; 或者在linux命令终端输入: hdfs dfs -mkdir -p /data; ② 在hive中执行HDFS命令:上传/emp.txt至HDFS的data目录下,并命名为…...
leetcode 452. 用最少数量的箭引爆气球
2023.8.2 本题思路先将二维数组points按照第一个维度排序, 然后初始化射箭数为1,因为题中提示说了最少有一个气球。 在遍历这些气球,看是否有重叠,如果没有重叠区域,射箭数;如果有重叠区域,更新…...
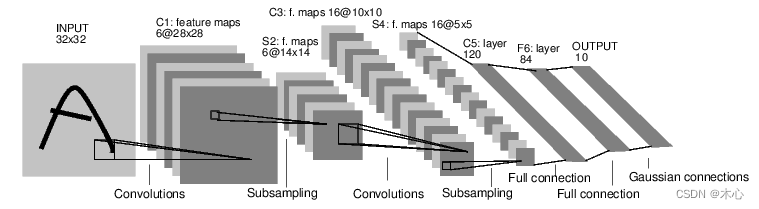
Pytorch Tutorial【Chapter 3. Simple Neural Network】
Pytorch Tutorial【Chapter 3. Simple Neural Network】 文章目录 Pytorch Tutorial【Chapter 3. Simple Neural Network】Chapter 3. Simple Neural Network3.1 Train Neural Network Procedure训练神经网络流程3.2 Build Neural Network Procedure 搭建神经网络3.3 Use Loss …...

2.虚拟机开启kali_linux
首先你应该搞一个虚拟机,搞虚拟机可以看一下这个 附录三 虚拟机的使用_Suyuoa的博客-CSDN博客 然后你需要搞一个 kali linux的镜像 Get Kali | Kali Linux 镜像下载好之后解压,你会得到一个文件夹包含下面这些文件 之后打开VMware,点击打开虚…...

SAP Smartforms避坑指南:从‘没有输出请求打开’到字体设置,手把手解决5个高频问题
SAP Smartforms实战避坑手册:5个高频问题深度解析与解决方案 在SAP项目实施过程中,Smartforms作为企业级报表输出的核心工具,几乎每个ABAP开发者都会与之打交道。表面上看,它提供了直观的图形化界面,似乎比传统的SAPsc…...
并优化代码)
别再为OpenMV串口传图卡顿发愁了!手把手教你选对硬件(STM32 SWD vs TTL)并优化代码
OpenMV串口传图性能优化实战:从硬件选型到代码调优 当你在实验室调试OpenMV串口传图项目时,是否经历过这样的场景:图像传输像老式拨号上网一样缓慢,帧率低得让人怀疑人生,调试界面卡成PPT?这背后往往隐藏着…...

YOLOv8实战:构建实时跌倒预警监控系统
1. 为什么需要实时跌倒预警系统 记得去年帮朋友给独居老人安装监控摄像头时,发现一个痛点:传统监控只能事后回放,当老人跌倒时往往错过黄金救援时间。这个问题在养老院和社区医疗场景尤为突出,护工不可能24小时盯着每个监控画面。…...
)
高校学生综合测评管理系统(10054)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

5G 网络优化工程师是骗局吗?从业15年资深老工程师实话实说
01 5G 网优岗位,本身真实靠谱很多人一刷到 5G 网络优化工程师这个岗位,第一反应都是犹豫、怀疑:这到底是不是收割小白的骗局?我在通信行业深耕整整 15 年,也拿到过华为高级工程师认证,今天以业内老兵的身份…...

AI工程师实战技能树:从特征工程到MLOps的完整指南
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的仓库,叫tqviet1978/ai-skills。光看名字,你可能会觉得这又是一个关于AI技能学习的普通教程合集。但当我点进去仔细研究后,发现它的定位和内容组织方式,与市面上大多数“AI学…...

OpenClaw Provider Manager:统一管理第三方服务的微服务治理框架
1. 项目概述与核心价值最近在折腾一些自动化流程和微服务治理,发现一个挺普遍但处理起来又有点琐碎的问题:如何高效、统一地管理那些分散在各个角落的第三方服务提供商(Provider)?比如短信发送、邮件推送、对象存储、支…...

【HarmonyOS6.1全场景实战】基线版本:我用了15篇文章,造出了一个能登录、能推荐、带后台的鸿蒙全栈App
我用了15篇文章,造出了一个能登录、能推荐、带后台的鸿蒙全栈App 摘要:从开篇词到第15篇,《灵犀厨房》的第一个里程碑版本 v2.0 正式发布。它不再是一个前端Demo,而是一个拥有用户认证系统、Python Flask后台、MySQL数据库、AI智能…...

基于LLM的代码仓库智能分析:RepoMap-AI实现架构可视化与认知图谱
1. 项目概述:当AI成为你的代码库“活地图”最近在折腾一个老旧的Java项目,里面模块套模块,依赖关系复杂得像一团乱麻。想找个特定的工具类,得在十几个包里翻来覆去地搜;想理清某个核心服务的调用链路,光靠I…...

通过 curl 命令快速测试 Taotoken 各大模型 API 的连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 curl 命令快速测试 Taotoken 各大模型 API 的连通性 在将大模型能力集成到应用或服务之前,验证 API 的连通性、密…...