【NLP】训练chatglm2的评价指标BLEU,ROUGE
当进行一定程度的微调后,要评价模型输出的语句的准确性。由于衡量的对象是一个个的自然语言文本,所以通常会选择自然语言处理领域的相关评价指标。这些指标原先都是用来度量机器翻译结果质量的,并且被证明可以很好的反映待评测语句的准确性,主要包含4种:BLEU,METEOR,ROUGE,CIDEr。
本文只介绍BLEU,ROUGE两个指标,其他待补充。
1、BLEU
- BLEU(Bilingual Evaluation understudy,双语互译质量评估)是一种流行的机器翻译评价指标,一种基于精确度的相似度量方法,用于分析候选译文中有多少 n 元词组出现在参考译文中(就是在判断两个句子的相似程度)
- BLEU有许多变种,根据n-gram可以划分成多种评价指标,常见的评价指标有BLEU-1、BLEU-2、BLEU-3、BLEU-4四种,其中n-gram指的是连续的单词个数为 n,BLEU-1衡量的是单词级别的准确性,更高阶的BLEU可以衡量句子的流畅性。
假设, c i c_i ci表示候选译文【也就是机器译文(candidate)】,该候选译文对应的一组参考译文【也就是人工译文(reference)】可以表示为 S i = { s i 1 , s i 2 , … , s i m } \mathrm{S_{i}=\{s_{i1},s_{i2},\ldots,s_{im}\}} Si={si1,si2,…,sim};将候选译文 c i c_i ci中所有相邻的 n 个单词提取出来组成一个集合 n − g r a m n-gram n−gram,一般取 n = 1 , 2 , 3 , 4 n=1,2,3,4 n=1,2,3,4;用 ω k \omega_k ωk表示 n − g r a m n-gram n−gram中的第 k k k 个词组, h k ( c i ) h_k(c_i) hk(ci)表示第k个词组 ω k \omega_k ωk在候选译文 c i c_i ci中出现的次数, h k ( s i j ) h_k(s_{ij}) hk(sij)表示第 k k k 个词组 ω k \omega_k ωk,在参考译文 s i j s_{ij} sij中出现的次数。此时,在n-gram下,参考译文和候选译文 c i c_i ci的匹配度计算公式可以表示为:
p n ( c i , S ) = ∑ k min ( h k ( c i ) , max j ∈ m h k ( s i j ) ) ∑ k h k ( c i ) \mathrm{p_n}\left(\mathrm{c_i},\mathrm{S}\right)=\frac{\sum_{\mathrm{k}}\min\left(\mathrm{h_k}\left(\mathrm{c_i}\right),\max_{\mathrm{j}\in\mathrm{m}}\mathrm{h_k}\left(\mathrm{s_{ij}}\right)\right)}{\sum_{\mathrm{k}}\mathrm{h_k}\left(\mathrm{c_i}\right)} pn(ci,S)=∑khk(ci)∑kmin(hk(ci),maxj∈mhk(sij))
举例说明:
candidate:The cat sat on the mat.
reference:The cat is on the mat
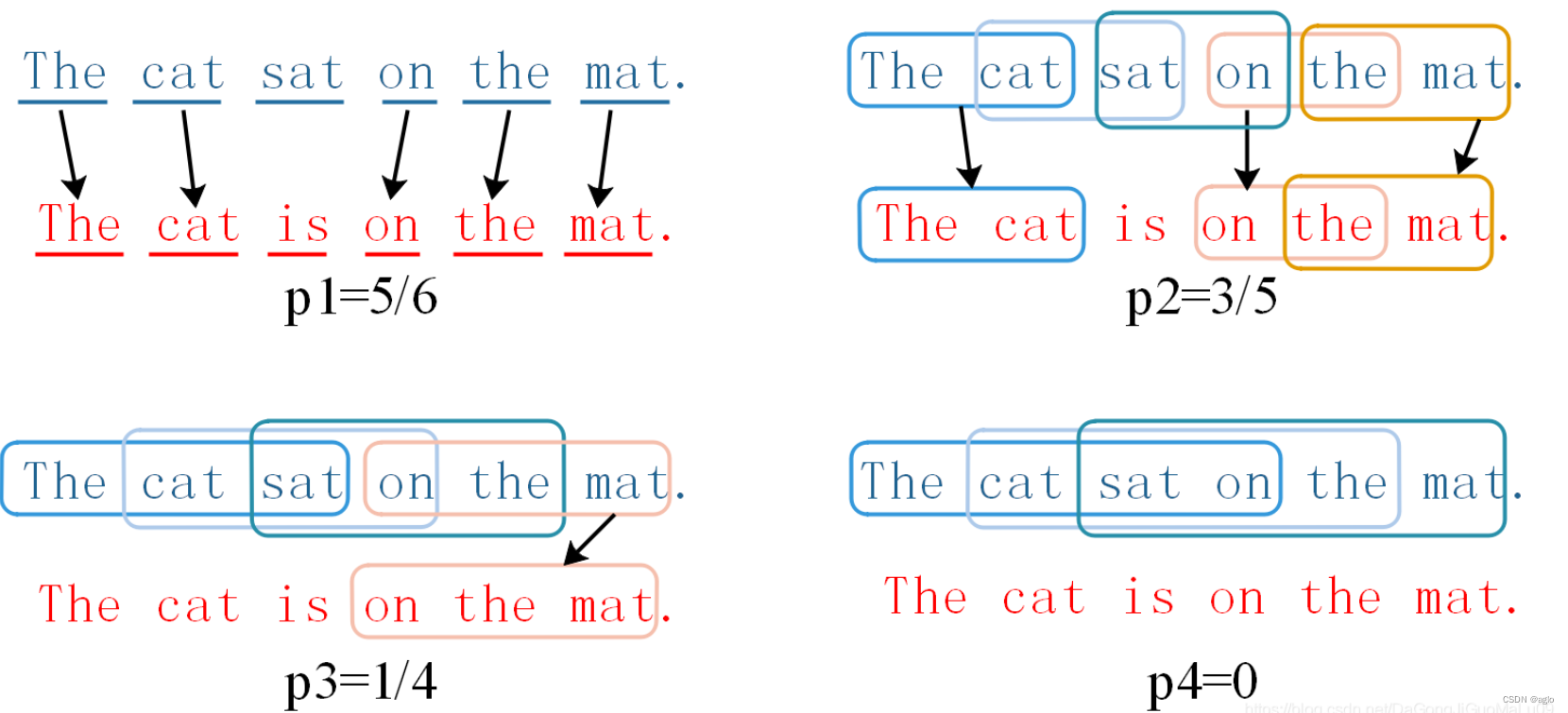
( c a n d i d a t e 和 r e f e r e n c e 中匹配的 n − g r a m 的个数 ) / c a n d i d a t e 中 n − g r a m 的个数 (candidate\text{和}reference\text{中匹配的}n-gram\text{的个数})/candidate\text{中}n-gram\text{的个数} (candidate和reference中匹配的n−gram的个数)/candidate中n−gram的个数
一般来说, n 取值越大,参考译文就越难匹配上,匹配度就会越低. 1 − g r a m 1-gram 1−gram能够反映候选译文中有多少单词被单独翻译出来,也就代表了参考译文的充分性; 2 − g r a m 2-gram 2−gram、 3 − g r a m 3-gram 3−gram、 4 − g r a m 4-gram 4−gram 值越高说明参考译文的可读性越好,也就代表了参考译文的流畅性。
当参考译文比候选译文长(单词更多)时,这种匹配机制可能并不准确,例如上面的参考译文如果是The cat,匹配度就会变成1,这显然是不准确的;为此我们引入一个惩罚因子。
B P ( c i , s i j ) = { 1 , l c i > l s i j e l − l s i j l c i , l c i ≤ l s i j BP(c_i,s_{ij}) = \left\{\begin{matrix} 1\quad ,\quad l_{ci}>l_{s_{ij}} \\ {e^{l-\frac{l_{s_{ij}}}{l_{c_i}}},\quad l_{ci}~\leq l_{sij}} \end{matrix}\right. BP(ci,sij)={1,lci>lsijel−lcilsij,lci ≤lsij
l l l 表示各自的长度。最终,BLEU的计算公式就是
B L E U = B P ⋅ exp ( ∑ n = 1 N w n log p n ) BLEU=BP \cdot \exp \left(\sum_{n=1}^Nw_n \log p_n \right) BLEU=BP⋅exp(n=1∑Nwnlogpn)
w n w_n wn代表每一个 n-gram 的权重,一般 n n n 最大取4,所以 w n = 0.25 w_n = 0.25 wn=0.25 。
BLEU 更偏向于较短的翻译结果,它看重准确率而不注重召回率(n-gram 词组是从候选译文中产生的,参考译文中出现、候选译文中没有的词组并不关心);原论文提议数据集多设置几条候选译文,4条比较好,但是一般的数据集只有一条。
2、ROUGE
BLEU 是统计机器翻译时代的产物,因为机器翻译出来的结果往往不通顺,所以BLEU更关注翻译结果的准确性和流畅度;到了神经网络翻译时代,神经网络很擅长脑补,自己就把语句梳理得很流畅了,这个时候人们更关心的是召回率,也就是参考译文中有多少词组在候选译文中出现了。
关于ROUGE(recall-oriented understanding for gisting evaluation),就是一种基于召回率的相似性度量方法,主要考察参考译文的充分性和忠实性,无法评价参考译文的流畅度,它跟BLEU的计算方式几乎一模一样,但是 n-gram 词组是从参考译文中产生的。分为4种类型:
| ROUGE | 解释 |
|---|---|
| ROUGE-N | 基于 N-gram 的共现(共同出现)统计 |
| ROUGE-L | 基于最长共有子句共现性精度和召回率 Fmeasure 统计 |
| ROUGE-W | 带权重的最长共有子句共现性精度和召回率 Fmeasure 统计 |
| ROUGE-S | 不连续二元组共现性精度和召回率 Fmeasure 统计 |
Rouge-1、Rouge-2、Rouge-N
论文[3]中对Rouge-N的定义是这样的:
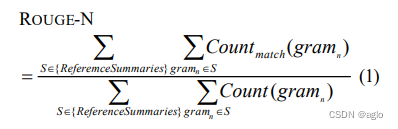
分母是n-gram的个数,分子是参考摘要和自动摘要共有的n-gram的个数。直接借用文章[2]中的例子说明一下:
自动摘要 Y Y Y(一般是自动生成的):
the cat was found under the bed
参考摘要, X 1 X1 X1(gold standard ,人工生成的):
the cat was under the bed
summary的1-gram、2-gram如下,N-gram以此类推:
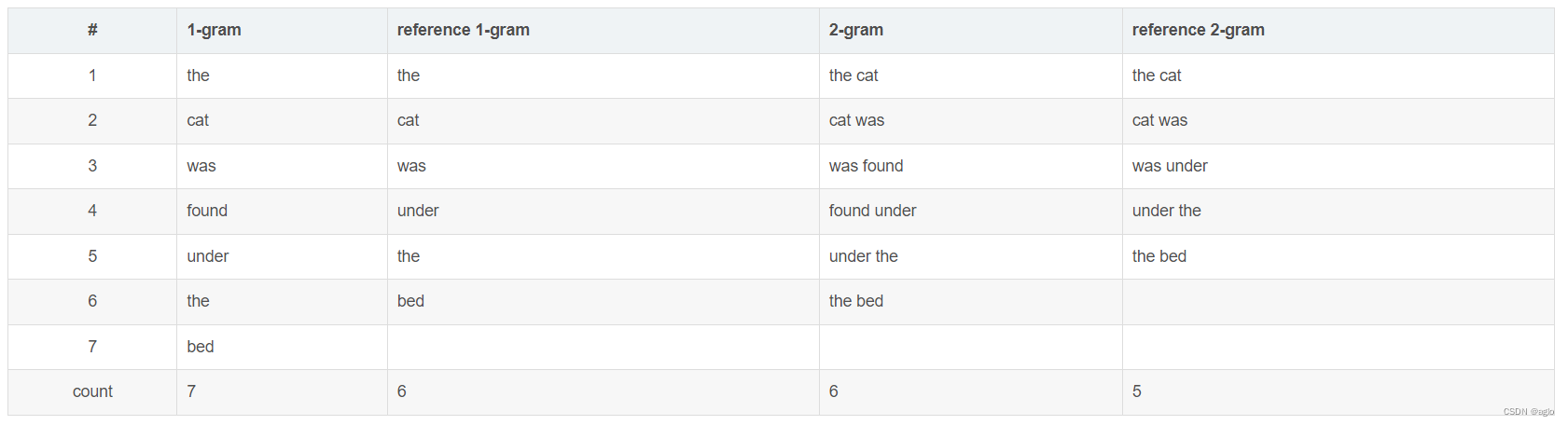
R o u g e _ 1 ( X 1 , Y ) = 6 6 = 1.0 Rouge\_1(X1,Y)=\dfrac66=1.0 Rouge_1(X1,Y)=66=1.0,分子是待评测摘要和参考摘要都出现的1-gram的个数,分子是参考摘要的1-gram个数。(其实分母也可以是待评测摘要的,但是在精确率和召回率之间,我们更关心的是召回率Recall,同时这也和上面ROUGN-N的公式相同)
同样, R o u g e _ 2 ( X 1 , Y ) = 4 5 = 0.8 Rouge\_2(X1,Y)=\dfrac{4}{5}=0.8 Rouge_2(X1,Y)=54=0.8
Rouge-L
L即是LCS(longest common subsequence,最长公共子序列)的首字母,因为Rouge-L使用了最长公共子序列。Rouge-L计算方式如下:
R l c s = L C S ( X , Y ) m ( 2 ) R_{lcs}=\frac{LCS(X,Y)}m\quad(2) Rlcs=mLCS(X,Y)(2)
P l c s = L C S ( X , Y ) n ( 3 ) P_{lcs}=\frac{LCS(X,Y)}{n}\quad(3) Plcs=nLCS(X,Y)(3)
F l c s = ( 1 + β 2 ) R l c s P l c s R l c s + β 2 P l c s ( 4 ) F_{lcs}=\frac{(1+\beta^2)R_{lcs}P_{lcs}}{R_{lcs}+\beta^2P_{lcs}}\quad(4) Flcs=Rlcs+β2Plcs(1+β2)RlcsPlcs(4)
其中 L C S ( X , Y ) LCS(X,Y) LCS(X,Y)是X和Y的最长公共子序列的长度,m,n分别表示参考摘要和自动摘要的长度(一般就是所含词的个数), R l c s R_{lcs} Rlcs, P l c s P_{lcs} Plcs分别表示召回率和准确率。最后的 F l c s F_{lcs} Flcs即是我们所说的Rouge-L。在DUC中, β \beta β被设置为一个很大的数,所以 R o u g e _ L Rouge\_L Rouge_L几乎只考虑了 R l c s R_{lcs} Rlcs,与上文所说的一般只考虑召回率对应。
参考文章:
[1].自动文摘评测方法:Rouge-1、Rouge-2、Rouge-L、Rouge-S
[2].What is ROUGE and how it works for evaluation of summaries?
[3].ROUGE:A Package for Automatic Evaluation of Summaries
[4].BLEU评估指标
[5].评价度量指标之BLEU,METEOR,ROUGE,CIDEr
相关文章:
【NLP】训练chatglm2的评价指标BLEU,ROUGE
当进行一定程度的微调后,要评价模型输出的语句的准确性。由于衡量的对象是一个个的自然语言文本,所以通常会选择自然语言处理领域的相关评价指标。这些指标原先都是用来度量机器翻译结果质量的,并且被证明可以很好的反映待评测语句的准确性&a…...

java+springboot+mysql员工工资管理系统
项目介绍: 使用javaspringbootmysql开发的员工工资管理系统,系统包含超级管理员,系统管理员、员工角色,功能如下: 超级管理员:管理员管理;部门管理;员工管理;奖惩管理&…...
FL Studio Producer Edition 21 v21.0.3 Build 3517 Windows/mac官方中文版
FL Studio Producer Edition 21 v21.0.3 Build 3517 Windows FL Studio Producer Edition 21 v21.0.3 Build 3517 Windows/mac官方中文版是一个完整的软件音乐制作环境或数字音频工作站(DAW)。它代表了 25 多年的创新发展,将您创作、编曲、录…...

探索Python数据容器之乐趣:列表与元组的奇妙旅程!
文章目录 零 数据容器入门一 数据容器:list(列表)1.1 列表的定义1.2 列表的下表索引1.3 列表的常用操作1.3.1 列表的查询功能1.3.2 列表的修改功能1.3.3 列表常用方法总结 1.4 补充:append与extend对比1.5 list(列表)的遍历1.6 补…...
Python自动化实战之使用Pytest进行API测试详解
概要 每次手动测试API都需要重复输入相同的数据,而且还需要跑多个测试用例,十分繁琐和无聊。那么,有没有一种方法可以让你更高效地测试API呢?Pytest自动化测试!今天,小编将向你介绍如何使用Pytest进行API自…...
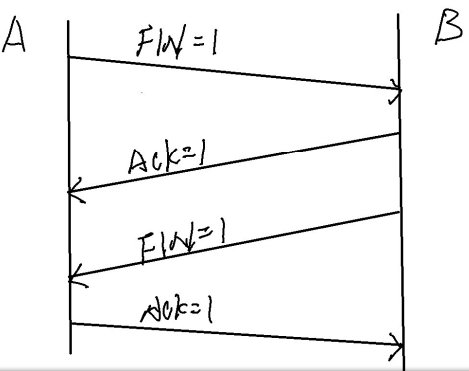
TCP的三次握手以及四次断开
TCP的三次握手和四次断开,就是TCP通信建立连接以及断开的过程 目录 【1】TCP的三次握手过程 ---- TCP建立连接的过程 【2】TCP的四次挥手 ---- TCP会话的断开 注意: 【1】TCP的三次握手过程 ---- TCP建立连接的过程 三次握手的过程:…...

目标检测YOLO实战应用案例100讲-基于视觉与激光雷达信息融合的智能车辆目标检测研究
目录 前言 传感器选型及同步 2.1 各传感器工作原理及性能对比 2.1.1 视觉传感器...

Day 22 C++ STL常用容器——string容器
string容器 概念本质string和char 区别:特点string构造函数构造函数原型 string赋值操作赋值的函数原型示例 string字符串拼接函数原型:示例 string查找和替换函数原型示例 string字符串比较比较方式 字符串比较是按字符的ASCII码进行对比函数原型示例 s…...

使用Socket实现UDP版的回显服务器
文章目录 1. Socket简介2. DatagramSocket3. DatagramPacket4. InetSocketAddress5. 实现UDP版的回显服务器 1. Socket简介 Socket(Java套接字)是Java编程语言提供的一组类和接口,用于实现网络通信。它基于Socket编程接口,提供了…...

【MCU学习】GD32F427VG开发
(一)学习文档和例程 兆易创新GD32 MCU参考资料下载 1.GD232F4xx的Keil芯片支持包 2.标准固件库和示例程序 3.GD32F4xx_固件库使用指南_Rev1.2 4.用户手册:GD32F4xx_User_Manual_Rev2.8_CN 5.数据手册:GD32F427xx_Datasheet_Rev…...

Acwing.877 扩展欧几里得算法
题目 给定n对正整数ai , bi,对于每对数,求出一组ai ,g,使其满足ai* xi bi * yi gcd(ai ,bi)。 输入格式 第一行包含整数n。 接下来n行,每行包含两个整数ai , bi。 输出格式 输出共n行,对于每组ai, bi,…...
基于自组织竞争网络的患者癌症发病预测(matlab代码)
1.案例背景 1.1自组织竞争网络概述 前面案例中讲述的都是在训练过程中采用有导师监督学习方式的神经网络模型。这种学习方式在训练过程中,需要预先给网络提供期望输出,根据期望输出来调整网络的权重,使得实际输出和期望输出尽可能地接近。但是在很多情况下,在人们认知的过程中…...

golang mongodb
看代码吧 package main// 链接案例 https://www.mongodb.com/docs/drivers/go/current/fundamentals/connection/#connection-example // 快速入门 https://www.mongodb.com/docs/drivers/go/current/quick-start/ import ("context""fmt""log"…...
docker中的jenkins去配置sonarQube
docker中的jenkins去配置sonarQube 1、拉取sonarQube macdeMacBook-Pro:~ mac$ docker pull sonarqube:8.9.6-community 8.9.6-community: Pulling from library/sonarqube 8572bc8fb8a3: Pull complete 702f1610d53e: Pull complete 8c951e69c28d: Pull complete f95e4f8…...

企业如何实现自己的AI垂直大模型
文章目录 为什么要训练垂直大模型训练垂直大模型有许多潜在的好处训练垂直大模型也存在一些挑战 企业如何实现自己的AI垂直大模型1.确定需求2.收集数据3.准备数据4.训练模型5.评估模型6.部署模型 如何高效实现垂直大模型 ✍创作者:全栈弄潮儿 🏡 个人主页…...

Maven可选依赖和排除依赖简单使用
可选依赖 可选依赖指对外隐藏当前所依赖的资源 在maven_04_dao的pom.xml,在引入maven_03_pojo的时候,添加optional <dependency><groupId>com.rqz</groupId><artifactId>maven_03_pojo</artifactId><version>1.0-SNAPSHOT&…...

“深入探索JVM:Java虚拟机的工作原理解析“
标题:深入探索JVM:Java虚拟机的工作原理解析 摘要:本文将深入探索Java虚拟机(JVM)的工作原理,从类加载、内存管理、垃圾回收、即时编译器等方面进行详细解析,帮助读者更好地理解JVM的内部机制。…...

Prometheus-各种exporter
文章目录 一、 nginx-prometheus-exporter1 nginx 配置1.1 Nginx 模块支持1.2 Nginx 配置文件配置2 部署 nginx-prometheus-exporter2.1 二进制方式部署2.1.1 解压部署2.1.2 配置 systemd2.1.3 添加 prometheus 的配置2.1.4 Dashborad2.2 docker-compose 方式部署3 可配置的指标…...
小程序的 weiui的使用以及引入
https://wechat-miniprogram.github.io/weui/docs/quickstart.html 网址 1.点进去,在app.json里面配置 在你需要的 页面的 json里面配置,按需引入 然后看文档,再在你的 wxml里面使用就好了...
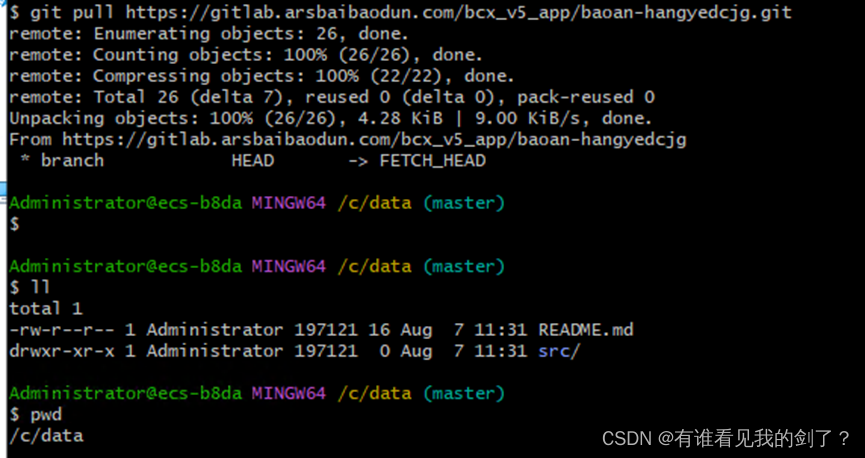
git目录初始化,并拉取最新代码
现有C:\data目录,将目录初始化,并拉取代码在这里插入代码片 https://gitlab.arsbaibaodun.com/bcx_v5_app/baoan-hangyedcjg.git 1、 git init生成 .git 目录即目录初始化完成,可以进行拉取代码 代码成功拉取到了data目录,默认…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...

腾讯 Marvis 初级使用教程——从安装到上手
腾讯最新系统级AI助手Marvis(2026年5月20日发布),官网 https://marvis.qq.com,主打“一句话操作电脑”、跨端协同、GUI Agent执行。虽然是个【小龙虾】,但上手其实不难。这篇就简单写写 Marvis 的安装和基础使用&#…...

AWS DevOps Agent 完全指南
AWS DevOps Agent 是 AWS 推出的前沿 AI 运维代理,自主调查和解决事件、持续预防故障、提升系统可靠性。本文档覆盖从原理到实战的全生命周期管理。 一、定位与价值 一句话定义 AWS DevOps Agent = AI 驱动的 SRE 队友,724 自主调查告警、定位根因、生成修复方案、预防未来…...

3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验
3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hive…...

Python到Android的魔法之旅:5步将你的代码变成移动应用
Python到Android的魔法之旅:5步将你的代码变成移动应用 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 想象一下,你花了几个月时间精心…...

通过Taotoken用量看板清晰追踪各模型的Token消耗情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken用量看板清晰追踪各模型的Token消耗情况 对于依赖大模型API进行开发的个人或团队而言,成本控制与预算规划…...

收藏2026版|大模型应用开发入门全攻略,小白程序员转行AI避坑学习指南
打算踏入大模型领域、转行AI赛道的新手与程序员,正式规划学习路径前,务必先吃透AI应用开发工程师的岗位定位与工作内容。清晰认知岗位核心价值,才能规避无效学习,精准找准发力方向。2026年大模型技术全面迈入商业化落地阶段&#…...