大模型使用——超算上部署LLAMA-2-70B-Chat
大模型使用——超算上部署LLAMA-2-70B-Chat
前言
1、本机为Inspiron 5005,为64位,所用操作系统为Windos 10。超算的操作系统为基于Centos的linux,GPU配置为A100,所使用开发环境为Anaconda。
2、本教程主要实现了在超算上部署LLAMA2-70B-Chat。
实现步骤
1、连接上超算以后,执行如下命令在超算上创建一个虚拟环境。
conda create --name alpaca python=3.9 -y
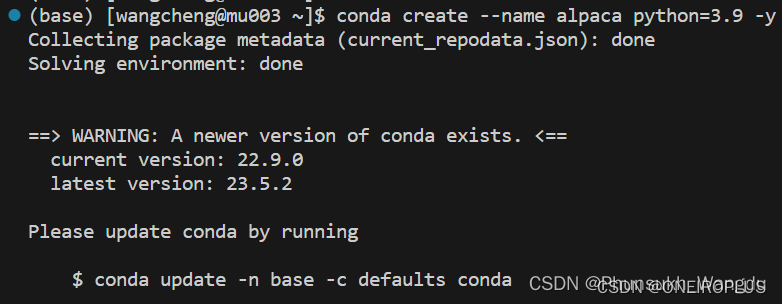
2、运行如下命令激活虚拟环境。
conda activate alpaca

3、在到LLAMA2的Github地址下载好llama2项目。
4、将下载好llama2项目的文件通过自己windows上的cmd中输入scp指令传输到超算上。
scp -r E:\llama-main wangcheng@10.26.14.56:/public/home/wangcheng/


5、在超算上进入llama-main文件夹,然后输入如下命令安装稳定版的llama2运行的依赖。
cd llama-main
pip install -e .

6、在Meta申请LLAMA2使用的链接地址上填写资料,然后申请LLAMA2模型的下载链接,申请完毕可以得到一份邮件,邮件中包含了下载链接。
7、在超算的llama-main目录下使用如下指令开始下载模型,在下载模型开始时,会要求你输入下载链接,第二步会让你选择要下载的模型,你选好要下载的模型以后,程序便会自己进行下载,整个过程时间比较长,在模型下载完毕后会自己先进行一步模型文件下载是否完整的校验,若你要自己进行一下文件的校验,可以使用如下所示的第二条指令,第二条指令双引号中的内容在下载的模型文件夹中包含的checklist.chk文件中找到,然后进行替换校验即可。
bash download.sh
echo "6efc8dab194ab59e49cd24be5574d85e consolidated.00.pth" | md5sum --check -

8、模型下载完毕后,通过如下指令将自己创建的llama_test.sh文件进行超算的使用调度。(注:llama_test.sh文件中的代码如下:)
sbatch llama_test.sh
#!/bin/bash
#SBATCH --job-name=llama_job_test
#SBATCH --output=testLLAMAJob.%j.out
#SBATCH --error=testLLAMAJob.%j.err
#SBATCH --partition=GPU_s
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=8
#SBATCH --gres=gpu:8starttime=`date +'%Y-%m-%d %H:%M:%S'` # 执行data命令,获取当前的日期和时间的格式化表示,并赋值给starttime
nvidia-smi # 查看NVIDIA GPU的状态和性能信息,输出当前节点上GPU的状态信息
echo "CUDA_VISIBLE_DEVICES = $CUDA_VISIBLE_DEVICES" # 输出当前进程中 CUDA_VISIBLE_DEVICES 的值,echo 命令用于输出字符串source ~/.bashrc # 于重新加载用户的 Bash 配置文件 ~/.bashrc,确保在后续的命令中可以使用最新的环境变量和别名设置
hostname >./hostfile # 获取当前主机的名称,并将其输出到一个名为 hostfile 的文件中echo $SLURM_NTASKS # 输出当前作业中分配的任务数
echo "Date = $(date)" # 输出当前的日期和时间
echo "Hostname = $(hostname -s)" # 输出当前主机的名称
echo "Working Directory = $(pwd)" # 输出当前工作目录的路径
echo "" # 输出一个空行,使易于阅读
echo "Number of Nodes Allocated = $SLURM_JOB_NUM_NODES" # 输出作业节点
echo "Number of Tasks Allocated = $SLURM_NTASKS" # 输出当前作业分配的任务数
echo "Number of Cores/Task Allocated = $SLURM_CPUS_PER_TASK" # 输出每个任务被分配的CPU核心数
echo $SLURM_NPROCS # 输出当前作业中分配的处理器数ulimit -s unlimited # 设置当前shell会话的栈大小限制为无限制
ulimit -v unlimited # 设置当前shell会话的虚拟内存限制为无限制,即不限制进程使用的虚拟内存大小
ulimit -m unlimited # 设置当前shell会话的物理内存限制为无限制module load cuda/11.7 # 加载11.7版本的CUDA软件模块
module load gcc/12.1 # 加载12.1的GCC编译器的软件模块
module load torch/2.0.1 # 加载2.0.1版本的torch# module load cuda/11.6 # 加载11.6版本的CUDA软件模块
# module load gcc/12.1 # 加载12.1的GCC编译器的软件模块
# module load torch/2.0 # 加载2.0版本的torchsource activate alpaca # 激活名为 alpaca 的Python虚拟环境python -V # 显示当前系统上安装的Python版本号
echo "CUDA_VISIBLE_DEVICES = $CUDA_VISIBLE_DEVICES" # 输出当前作业可以使用的CUDA设备的ID列表
echo "CONDA_DEFAULT_ENV = $CONDA_DEFAULT_ENV" # 输出当前工作的conda虚拟环境
# conda list # 列出当前conda环境下安装的python包# export MASTER_ADDR=localhost
# export MASTER_PORT=8888
# export WORLD_SIZE=8
# export NODE_RANK=0
# export OMP_NUM_THREADS=9# 使用torchrun进行分布式部署
# torchrun --nproc_per_node 8 example_chat_completion.py --ckpt_dir llama-2-70b-chat/ --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 4
torchrun --nproc_per_node 8 chat.py --ckpt_dir llama-2-70b-chat/ --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 4
# torchrun --nproc_per_node 1 example_chat_completion.py --ckpt_dir llama-2-7b-chat/ --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 4
# python chat.py --ckpt_dir llama-2-7b-chat/ --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 4
# python -m torch.distributed.launch --nproc_per_node=8 chat.py --ckpt_dir llama-2-70b-chat/ --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 4
nvidia-smi echo Job ends at `date` # 输出当前的日期
endtime=`date +'%Y-%m-%d %H:%M:%S'` # 执行data命令,获取当前的日期和时间的格式化表示,并赋值给endtime
start_seconds=$(date --date="$starttime" +%s); # 将开始时间转换为秒数
end_seconds=$(date --date="$endtime" +%s); # 将结束时间转换为秒数
echo "本次运行时间: "$((end_seconds-start_seconds))"s" # 输出字符串,得到当前任务
10、在得到的输出文件testLLAMAJob.389396.out中可以看到llama2成功部署到超算上了。
Remark:实行部署笔记纸质档

相关文章:
大模型使用——超算上部署LLAMA-2-70B-Chat
大模型使用——超算上部署LLAMA-2-70B-Chat 前言 1、本机为Inspiron 5005,为64位,所用操作系统为Windos 10。超算的操作系统为基于Centos的linux,GPU配置为A100,所使用开发环境为Anaconda。 2、本教程主要实现了在超算上部署LLAM…...
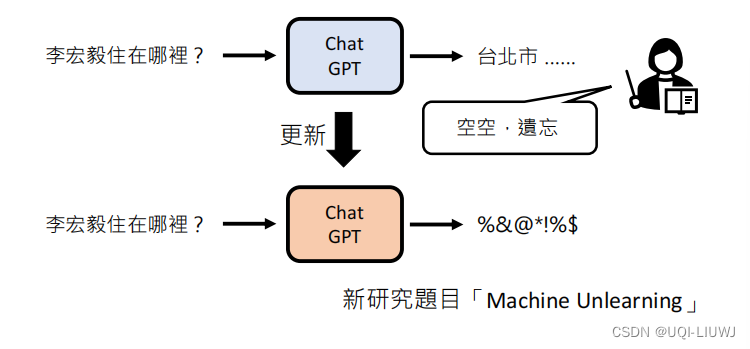
机器学习笔记:李宏毅ChatGPT课程1:刨析ChatGPT
ChatGPT——Chat Generative Pre-trained Transformer 1 文字接龙 每次输出一个概率分布,根据概率sample一个答案 ——>因为是根据概率采样,所以ChatGPT每次的答案是不一样的(把生成式学习拆分成多个分类问题)将生成的答案加到…...
)
Llama 2 with langchain项目详解(三)
Llama 2 with langchain项目详解(三) 17.3 Llama 2 with langchain基础 本节讲解在LangChain中使用Llama 2模型的基础知识,展示如何运行LangChain的代码,及在云端运行Llama 2的700亿模型。 首先,使用Python的pip管理器安装一系列库,包括huggingface/transformers、datase…...
)
牛客 AB30 排序(快排模板)
描述 给定一个长度为 n 的数组,请你编写一个函数,返回该数组按升序排序后的结果。 数据范围: 0≤�≤11030≤n≤1103,数组中每个元素都满足 0≤���≤1090≤val≤109 要求࿱…...

【Linux旅行记】第一个小程序“进度条“!
文章目录 一、预备知识1.1回车换行1.2缓冲区 二、倒计时三、进度条3.1普通版本源代码3.2高级版本源代码 🍀小结🍀 🎉博客主页:小智_x0___0x_ 🎉欢迎关注:👍点赞🙌收藏✍️留言 &…...

DeepMind将AI用于可控核聚变:将等离子体形状模拟精度提高65%
近日,英国AI公司DeepMind宣布取得了一项新的突破,成功实现了AI可控核聚变。这一技术能够在高温等离子体环境下实现精准放电,为核聚变技术的发展提供了新的思路和创新。 长期以来,相关领域的科学家们,一直在寻找清洁、取…...

Scrum是什么意思,Scrum敏捷项目管理工具有哪些?
一、什么是Scrum? Scrum是一种敏捷项目管理方法,旨在帮助团队高效地开展软件开发和项目管理工作。 Scrum强调迭代和增量开发,通过将项目分解为多个短期的开发周期(称为Sprint),团队可以更好地应对需求变…...

【从零单排Golang】第十三话:使用WaitGroup等待多路并行的异步任务
在后端开发当中,经常会遇到这样的场景:请求给了批量的输入,对于每一个输入,我们都要给外部发请求等待返回,然后才能继续其它自己的业务逻辑。在这样的case下,如果每一个输入串行处理的话,那么很…...
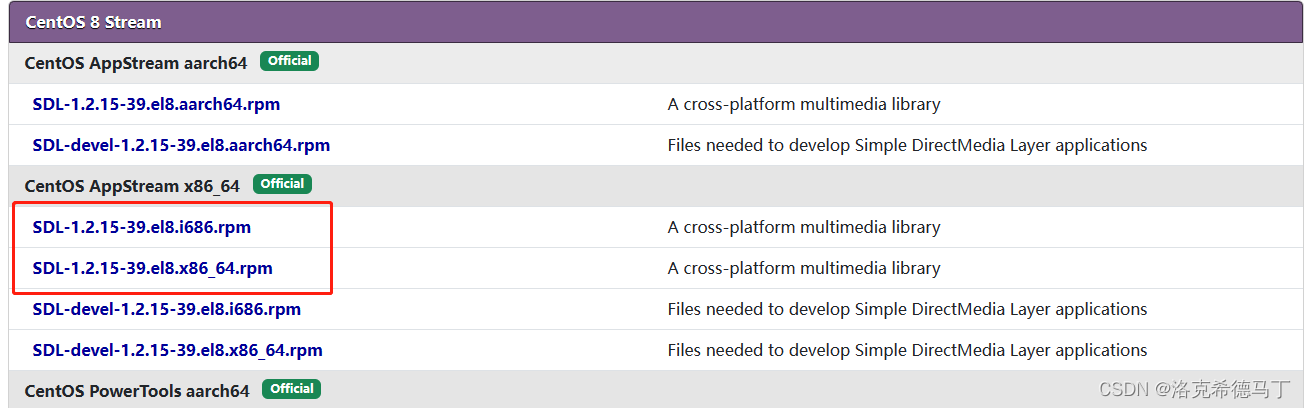
WSL2安装CentOS7和CentOS8
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、下载ZIP包?二、安装1.打开Windows子系统支持2.安装到指定位置3.管理虚拟机4.配置虚拟机1.配置国内源2.安装软件3.安装第三方源 5.配置用户1.创建…...

不平衡电网条件下基于变频器DG操作的多目标优化研究(Matlab代码Simulink实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 🌈4 Matlab代码&Simulink实现&文章讲解 💥1 概述 文献来源: 最近,利用并网转换器(GCC)克服电网故障并支撑电网电压已…...
简单题||单词数)
【Leetcode】(自食用)简单题||单词数
step by step. 题目: 统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。 请注意,你可以假定字符串里不包括任何不可打印的字符。 示例: 输入: "Hello, my name is John" 输出: 5 解释: 这里的单词是指连续的不是空格…...

C语言代码的x86-64汇编指令分析过程记录
先通过Xcode创建一个terminal APP,语言选择C。代码如下: #include <stdio.h>int main(int argc, const char * argv[]) {int a[7]{1,2,3,4,5,6,7};int *ptr (int*)(&a1);printf("%d\n",*(ptr));return 0; } 在return 0处打上断点&…...
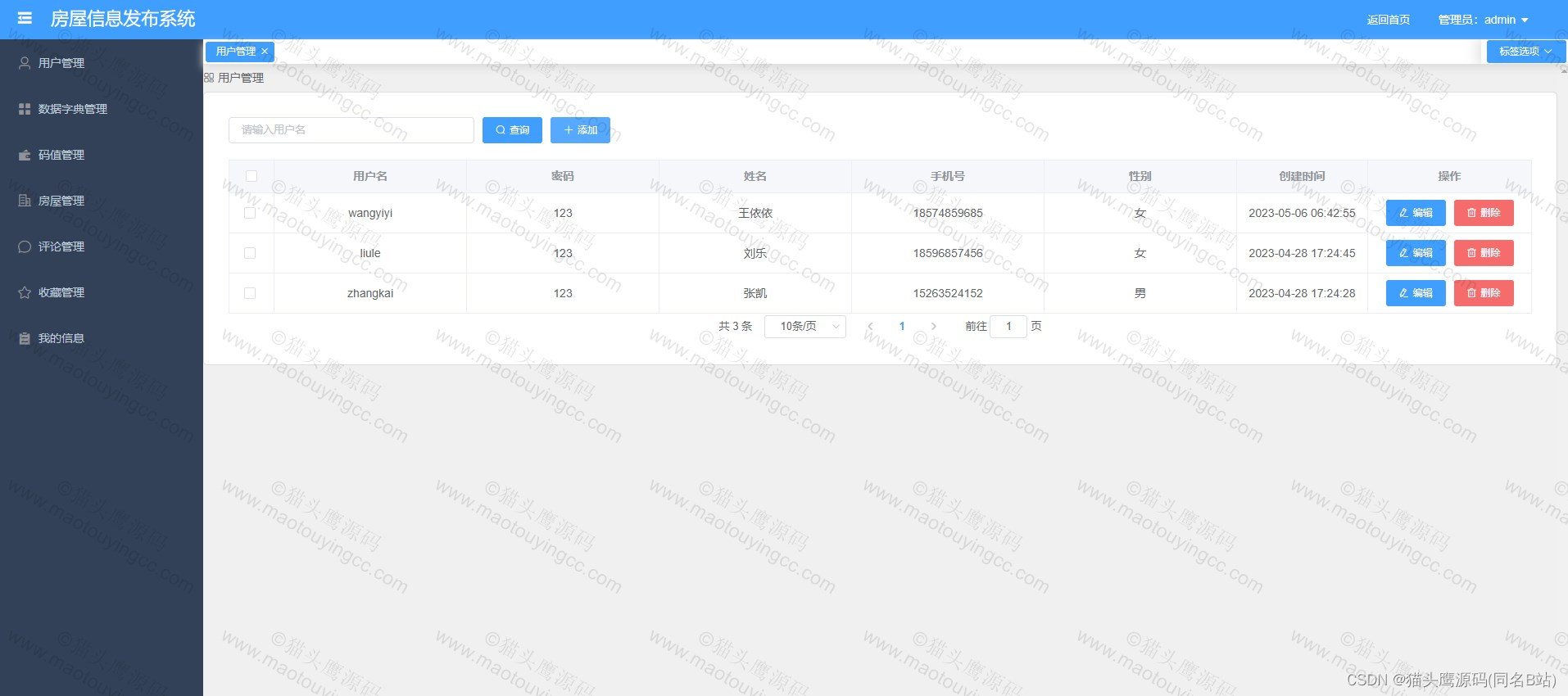
基于springboot+vue的房屋租赁系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...

Python文件读写操作详解:从基础到高级
摘要:文件读写是Python编程中常见的操作之一。本文将介绍Python中文件读写的基础知识,包括打开文件、读取文件内容、写入文件、关闭文件等基本操作。此外,还将探讨一些高级文件读写技术,如使用上下文管理器、处理异常、使用with语…...
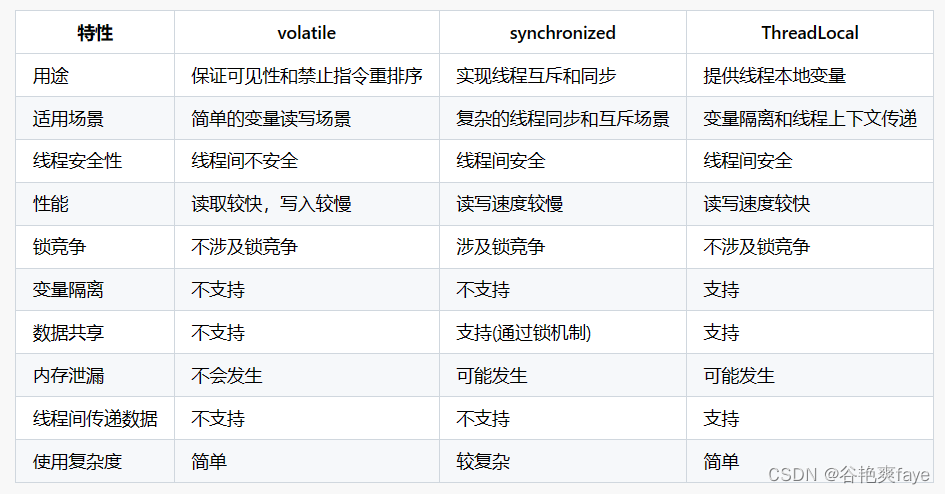
ThreadLocal基本介绍
文章目录 什么是ThreadLocalThreadLocal解决了什么问题ThreadLocal的作用 ThreadLocal的使用场景ThreadLocal的代码示例ThreadLocal的优点ThreadLocal的缺点与volatile、synchronized、ThreadLocal比较 总结 什么是ThreadLocal ThreadLocal是Java中的一个线程本地变量…...
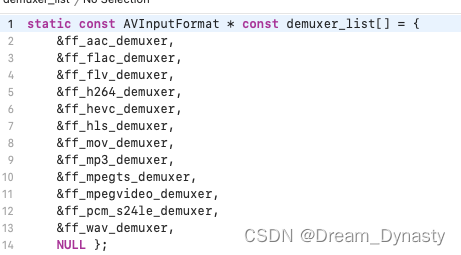
ffmpeg源码编译成功,但是引用生成的静态库(.a)报错,报错位置在xxx_list.c,报错信息为某变量未定义
背景:本文是对上一个文章的补充,在源码编译之前,项目是有完整的ffmpeg编译脚本的,只不过新增了断点调试ffmpeg,所以产生的上面的文章,也就是说,我在用make编译成功后,再去做的源码编…...

2023爱分析·信创云市场厂商评估报告:中国电子云
01 研究范围定义 信创2.0时代开启,信创进程正在从局部到全面、从细分到所有领域延展。在这个过程中,传统的系统集成,也在逐步向信创化、数字化及智能化转变。随着信创产业的发展,企业需要更多的技术支持和服务,而传统的系统集成已…...

网络安全学习笔记——XFF攻击流程
手工注入 手动报错注入,填写格式如:X-Forwarded-For: and updatexml(1,concat(0x7e,(select database()),0x7e),1) or 11 库名 1 and updatexml(1,concat(0x7e,database(),0x7e),1), 表名 1 and updatexml(1,concat(0x7e,(select table_name from…...

微信小程序阻止用户返回上一页,并弹窗给用户确定是否要返回上一页
在onload中调用微信的enableAlertBeforeUnload方法,在首次进入会自动监听当前的页面,在返回的时候会自动弹出弹窗阻止用户返回上一页,点击确定则返回上一页,取消则停留在当前页 onLoad: function(){wx.enableAlertBeforeUnload({…...
LangChain+ChatGLM整合LLaMa模型(二)
开源大模型语言LLaMa LLaMa模型GitHub地址添加LLaMa模型配置启用LLaMa模型 LangChainChatGLM大模型应用落地实践(一) LLaMa模型GitHub地址 git lfs clone https://huggingface.co/huggyllama/llama-7b添加LLaMa模型配置 在Langchain-ChatGLM/configs/m…...

ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程
ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程 【免费下载链接】ZjDroid Android app dynamic reverse tool based on Xposed framework. 项目地址: https://gitcode.com/gh_mirrors/zj/ZjDroid ZjDroid是一款基于Xposed框架的Android应用动态逆向分…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...

警惕!AI正在悄悄重构全球攻防格局
警惕!AI 正在悄悄重构全球攻防格局 热点聚焦 AI重构网络安全:全球巨头加速布局 2026年5月,全球网络安全领域迎来重大变革,AI技术正在重塑攻防格局。OpenAI发布专为网络安全防御打造的集成化AI平台Daybreak,将安全防…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

基于ATtiny84的智能冰箱监控器:低功耗温度与门状态监测方案
1. 项目概述:一个装在树莓派盒子里的智能冰箱管家如果你家里有台老冰箱,或者对食物储存温度特别在意,总担心冰箱门没关严或者突然断电导致内部升温,那么这个自己动手做的“冰箱看门狗”项目就太适合你了。它本质上是一个高度定制化…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法
1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法500块钱一个询盘,你敢信?做1688运营培训这么多年,这个数字我都觉得离谱。前阵子遇到一个老板,一上来就开始吐槽1688,说1688就是个垃圾平…...

NanaZip:现代Windows文件压缩问题的终极解决方案
NanaZip:现代Windows文件压缩问题的终极解决方案 【免费下载链接】NanaZip The 7-Zip derivative intended for the modern Windows experience 项目地址: https://gitcode.com/gh_mirrors/na/NanaZip 还在为Windows文件压缩工具界面老旧、功能单一而烦恼吗&…...