kafka:java client使用总结塈seek() VS commitSync()的区别(三)
最近一段日子接触了kafka这个消息系统,主要为了我的开源中间件项目simplemq增加kafka支持(基于kafka-client【java】),如今总算完成,本文是对这个过程中对kafka消息系统的使用总结
线程安全
关于线程安全,kafka-client的代码注释有明确说明,
KafkaProducer是线程安全的
The producer is thread safe and sharing a single producer instance across threads will generally be faster than having multiple instances.
– from Java Comment of org.apache.kafka.clients.producer.KafkaProducer
也就是说在工程实践中,KafkaProducer实例可以使用单例模式。不需要为了发送一条消息而频繁创建KafkaProducer实例。
KafkaConsumer不是线程安全的
Multi-threaded Processing
The Kafka consumer is NOT thread-safe. All network I/O happens in the thread of the application
making the call. It is the responsibility of the user to ensure that multi-threaded access
is properly synchronized. Un-synchronized access will result in {@link ConcurrentModificationException}.
– from Java Comment of org.apache.kafka.clients.consumerKafkaConsumer
在工程实践中,如果希望对订阅的主题单独管理,那么对于订阅的每一个主题(topic)必须创建一个单独的KafkaConsumer实例负责接收消息。并且要注意对KafkaConsumer实例的多数方法也只能在消息接收线程中。
分区
KafkaConsumer.poll()方法返回拉取的消息对象迭代对象(Iterable),迭代元素类型为ConsumerRecord,从ConsumerRecord返回的字段可知包括了key,value,offset,partition,partition即为分区。
也就是说,如果topic有多个分区,那么每次摘取的一批消息可能是来自不同分区的。所以不能想当然认为每一批消息都是一个分区的。
每批次拉取的消息同一个分区的消息的消息偏移值都是连续的。即[33,34,35]这样的连续数字,
不同的分区的偏移值没有相关性
手动提交
创建KafkaConsumer实例时如果不指定enable.auto.commit参数为true,默认KafkaConsumer是自动提交的。
自动提交模式没啥好说的,不会存在重复消费和遗漏消息的问题。
如果要使用手动提交模式,调用方就要自己维护分区的偏移,以确保不会出现重复消费和遗漏消息问题。
本节讲述手动提交模式下,设计需要注意的问题
团进团出
团进团出是旅游行业的一个术语,即要求一个旅行团,整团出发入境时是多少人,返程出境时要一个不少的回来
在这里的意思就是手动提交模式下每次KafkaConsumer.poll()方法每次拉取一批消息(数量不等),处理完消息后,就要对这批消息进行手动提交处理。提交完成后,才能继续拉取下一批消息。不能在上一批消息还没有完成提交的时候,就调用KafkaConsumer.poll()方法拉取下一批消息。
所以如果你的项目中消息处理是异步的,那么一定要同步等待当前这批消息被处理完,才能再次执行KafkaConsumer.poll()方法拉取消息。
前面说过如果主题有多个分区,每批拉取的消息可能是来自不同分区的。
为方便举例,我们以如下格式表示收到的一条消息
0-100-true
消息由-号三段数字字母代表,
- 第一段数字代表分区,
- 第二段数字为偏移,
- 最后的
true/false代表该消息是否正确处理并提交确认,
为true的需要提交,
false则是因为各种原因处理失败不需要提交,希望下一轮拉取消息继续处理。
完整提交
如下面的分区0,如果一批消息中同一个分区的所有消息都被正确处理需要提交,那么它就是完整提交
[0-100-true,0-101-true,0-103-true]
如下调用 KafkaConsumer.commitSync方法就可以了。
/** 分区完整提交,提交偏移为最后一个偏移+1 */
// 分区0
TopicPartition topicPartition = new TopicPartition(topic_name, 0);
long lastTrueOffset = 103;
/** 提交的偏移指向最后偏移量的下一条记录 */
OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(lastTrueOffset+1);
consumer.commitSync(Collections.singletonMap(topicPartition, offsetAndMetadata));
不完整提交
如下面的分区1,如果一批消息中同一个分区的消息有部分消息标记为false不能提交,那么它就是不完整提交。
[1-41-true,1-42-false,1-43-false,1-44-true]
对于不完整提交,我们只能从将第一个false之前的记录下次循环不用再处理,第一个false及之后的消息只能留给下次循环拉取消息再处理。如下使用seek()方法修改分区偏移
/** * 分区不完整提交:* 记录本轮第一个标记为false的记录之后所有提交标记为true的偏移 * 下一轮拉取消息从第一个标记为false的偏移开始*/
// 分区1
TopicPartition topicPartition = new TopicPartition(topic_name, 1);
long firstFalseOffset =42;
consumer.seek(topicPartition,firstFalseOffset);
在不完整提交的状态下,下次执行poll()方法拉取的消息中包含上一批消息为标记为true的消息,所以还需要有机制记录上一轮拉取的消息中不完整提交中标记为true的消息,这些消息不需要再被处理,否则就会出现重复消费问题。
重复消费问题
即使如上面所说在程序中有机制记录上次不完整提交中标记为true的消息,在下次循环拉取消息后,对上次已经标记为true的消息不再被重复处理,还是无法完全避免重复消费问题。因为这只是解决当前消费者实例在当前消费循环中的重复消费问题。
在消息循环结束前最后一次拉取消息如果是不完整提交,如果这些不完整提交的数据没有持久化保存,那么在下次创建的消费者实例还是会有已经被确认消费的消息被重复消费的情况。
所以如果要完全解决重复消费问题,需要应用层对不完全提交的消息进行额外处理:
- 将确认为false的消息存储到缓冲区或持久化存储中:在处理确认为false的消息时,你可以将这些消息存储到缓冲区或持久化存储中,例如内存队列、数据库或文件系统。这样,下次启动消费者时,可以从缓冲区或存储中加载这些消息,并进行再次处理。
- 使用定时任务重新处理消息:你可以设置一个定时任务,定期检查确认为false的消息,并重新进行处理。定时任务可以根据需要从缓冲区或持久化存储中获取这些消息,并重新发送给消费者进行处理。
seek() VS commitSync()
seek()方法和commitSync()方法的作用都是通过更新分区的偏移值,控制拉取消息的位置,但这两个方法肯定是有区别的否则不可能设计两个方法干同样的事儿。
commitAsync()与commitSync()方法作用是一样的,区别在于commitAsync()是异步提交
事实上我通过输出日志的方式发现commitAsync()执行结束调用OffsetCommitCallback对象时所在线程与commitAsync()执行在同一线程,也就是说commitAsync()可能也是同步提交
我通过反复的实验,对它们的差别有了初步的判断。但并不太确定。
于是,关于seek()方法和commitSync()方法的区别我问了bito机器人,这是它的回答,证实了我的想法,与我的实验结论是一致的。
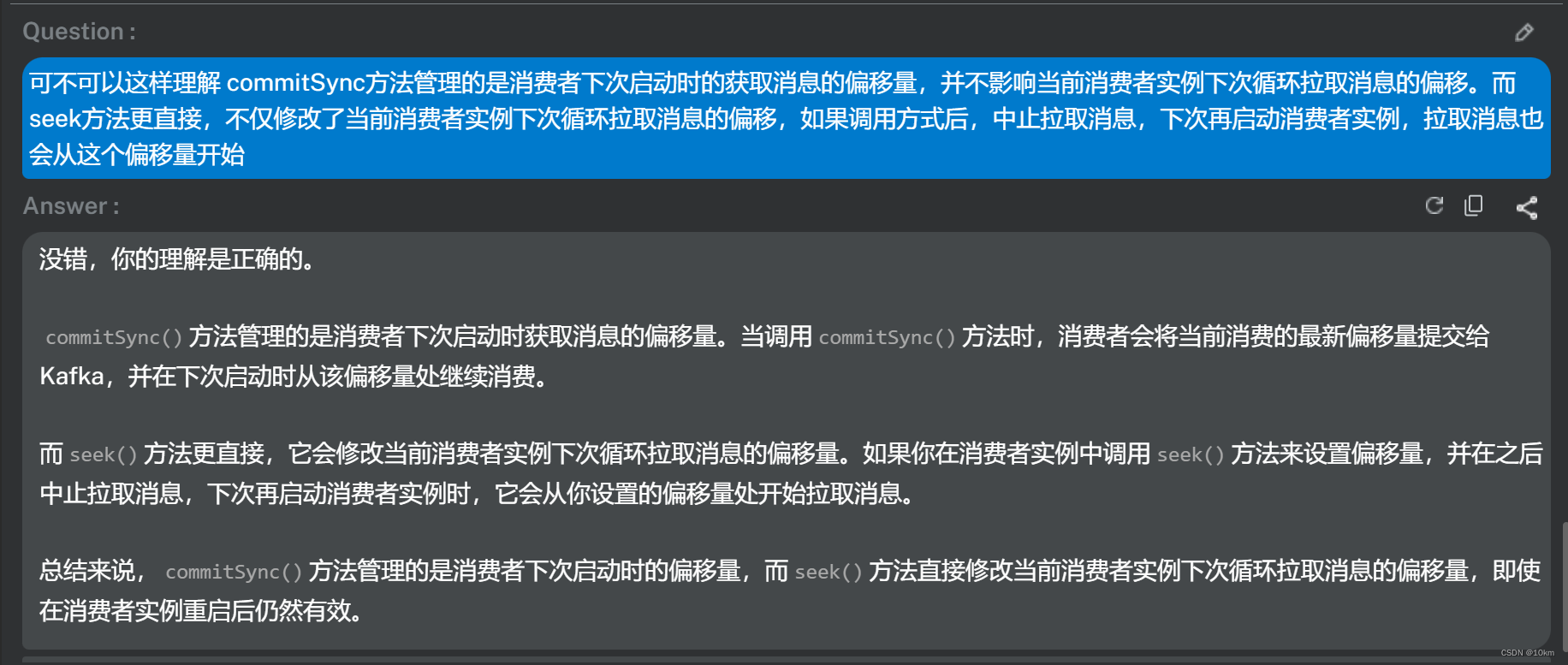
我在机器人回答的基础上再做一些示例补充就是如下完整的说明:
commitSync() 方法管理的是消费者下次启动时获取消息的偏移量。当调用 commitSync() 方法时,消费者会将当前消费的最新偏移量提交给Kafka,并在下次启动时从该偏移量处继续消费。
比如:本次poll拉取了 100,101,102三条消息,commitSync提交偏移101,那么下次一轮执行poll拉取消息会从偏移103开始,此刻如果中止拉取消息,下次再重新启动消费者时拉取偏移为101。
而 seek() 方法更直接,它会修改当前消费者实例下次循环拉取消息的偏移量。如果你在消费者实例中调用 seek() 方法来设置偏移量,并在之后中止拉取消息,下次再启动消费者实例时,它会从你设置的偏移量处开始拉取消息。
还以上例,本次poll拉取了 100,101,102三条消息,seek修改偏移101,那么下次一轮执行poll拉取消息会从偏移101开始,即使此刻中止拉取消息,下次再重新启动消费者时拉取偏移也为101。
总结来说, commitSync() 方法管理的是消费者下次启动时的偏移量,而 seek() 方法直接修改当前消费者实例下次循环拉取消息的偏移量,即使在消费者实例重启后仍然有效。
相关文章:
kafka:java client使用总结塈seek() VS commitSync()的区别(三)
最近一段日子接触了kafka这个消息系统,主要为了我的开源中间件项目simplemq增加kafka支持(基于kafka-client【java】),如今总算完成,本文是对这个过程中对kafka消息系统的使用总结 线程安全 关于线程安全,…...

如何用正确的姿势监听Android屏幕旋转
作者:37手游移动客户端团队 背景 关于个人,前段时间由于业务太忙,所以一直没有来得及思考并且沉淀点东西;同时组内一个个都在业务上能有自己的思考和总结,在这样的氛围下,不由自主的驱使周末开始写点东西&…...
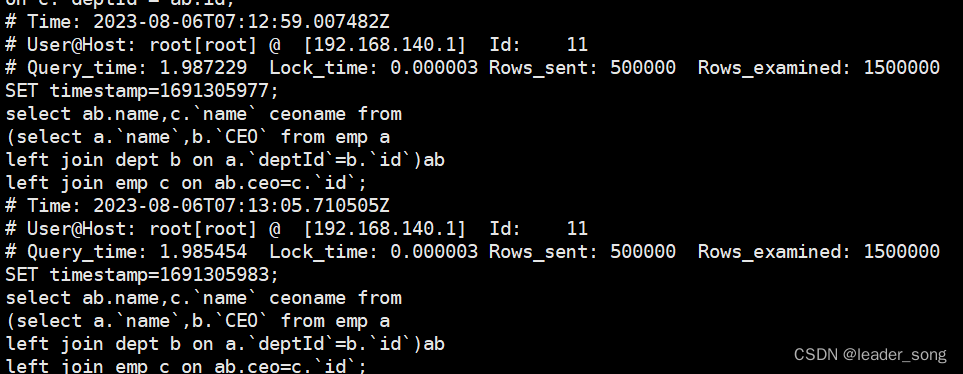
mysql高级三:sql性能优化+索引优化+慢查询日志
内容介绍 单表索引失效案例 0、思考题:如果把100万数据插入MYSQL ,如何提高插入效率 (1)关闭自动提交,只手动提交一次 (2)删除除主键索引外其他索引 (3)拼写mysql可以执…...
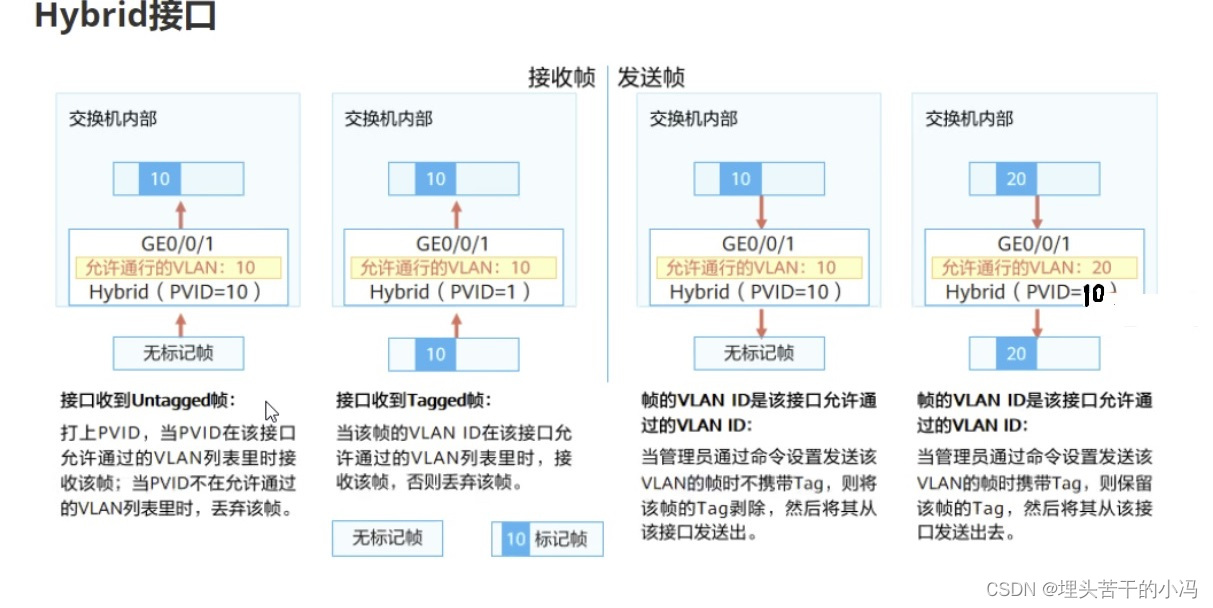
HCIP VLAN--Hybrid接口
一、VLAN的特点 1、一个VLAN就是一个广播域,所以在同一个VLAN内部,计算机可以直接进行二层通信;而不同VLAN内的计算机,无法直接进行二层通信,只能进行三层通信来传递信息,即广播报文被限制在一个VLAN内。 …...

大数据开发面试必问:Hive调优技巧系列二
接上次分享的Hive调优技巧系列一: 数据倾斜、HiveJob优化 第1章 数据倾斜(重点) 绝大部分任务都很快完成,只有一个或者少数几个任务执行的很慢甚至最终执行失败,这样的现象为数据倾斜现象。 一定要和数据过量导致的…...

【C++】STL——list的模拟实现、构造函数、迭代器类的实现、运算符重载、增删查改
文章目录 1.模拟实现list1.1构造函数1.2迭代器类的实现1.3运算符重载1.4增删查改 1.模拟实现list list使用文章 1.1构造函数 析构函数 在定义了一个类模板list时。我们让该类模板包含了一个内部结构体_list_node,用于表示链表的节点。该结构体包含了指向前一个节点…...

vscode 插件::EIDE
最新最全 VSCODE 插件推荐(2023版)_vscode_白墨石-华为云开发者联盟 (csdn.net) 超好用的开发工具-VScode插件EIDE_vscode eide_桃成蹊2.0的博客-CSDN博客 Setup | Embedded IDE For VSCode (em-ide.com)...

Python 网络编程
Python 网络编程 Python 提供了两个级别访问的网络服务: 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统 Socket 接口的全部方法。高级别的网络服务模块 SocketServer, 它提供了服务器…...
SQL 数据科学:了解和利用联接
推荐:使用 NSDT场景编辑器助你快速搭建可编辑的3D应用场景 什么是 SQL 中的连接? SQL 联接允许您基于公共列合并来自多个数据库表的数据。这样,您就可以将信息合并在一起,并在相关数据集之间创建有意义的连接。 SQL 中的连接类型…...
第五章决策树——四五节:决策树的剪枝,CART算法)
(统计学习方法|李航)第五章决策树——四五节:决策树的剪枝,CART算法
目录 一,决策数的剪枝 二,CART算法 1.CART生成 (1)回归树的生成 (2)分类树的生成 2.CART剪枝 (1)剪枝,形成一个子树序列 (2)在剪枝得到的子…...

C语言--结构体定义
整型数,浮点数,字符串是分散的数据表示,有时候我们需要很多类型表示一个整体,比如学生信息。 数组是元素类型一样的数据集合,如果是元素类型不同的数据集合,就要用到结构体 结构体一般是个模板,…...

解决Element Plus中Select在El Dialog里层级过低的问题(修改select选项框样式)
Element Plus是Vue.js的一套基于Element UI的组件库,提供了丰富的组件用于构建现代化的Web应用程序。其中,<el-select>是一个常用的下拉选择器组件,但在某些情况下,当<el-select>组件嵌套在<el-dialog>…...
【数据结构】二叉树 链式结构的相关问题
本篇文章来详细介绍一下二叉树链式结构经常使用的相关函数,以及相关的的OJ题。 目录 1.前置说明 2.二叉树的遍历 2.1 前序、中序以及后序遍历 2.2 层次遍历 3.节点个数相关函数实现 3.1 二叉树节点个数 3.2 二叉树叶子节点个数 3.3 二叉树第k层节点个数 3…...
【无标题】云原生在工业互联网的落地及好处!
什么是工业互联网? 工业互联网(Industrial Internet)是新一代信息通信技术与工业经济深度融合的新型基础设施、应用模式和工业生态,通过对人、机、物、系统等的全面连接,构建起覆盖全产业链、全价值链的全新制造和服务…...

人工智能在心电信号分类中的应用
目录 1 引言 2 传统机器学习中的特征提取与选择 3 深度学习中的特征提取与选择...
【Linux 网络】网络层协议之IP协议
IP协议 IP协议所处的位置网络层要解决的问题IP协议格式分片与组装网段划分特殊的IP地址IP地址的数量限制私网IP地址和公网IP地址路由 IP协议所处的位置 IP指网际互连协议,Internet Protocol的缩写,是TCP/IP体系中的网络层协议。 网络层要解决的问题 网络…...

.meta 文件
.meta 文件的作用简单来说是建立 Unity 与资源之间的“桥梁”。 在游戏中引用一个游戏资源,Unity 并不是直接按照文件的路径或者名称,而是使用一个独一无二的 GUID 来指向工程里该资源文件。 这个 GUID 就是存储在 Unity 工程为每一个资源和文件…...
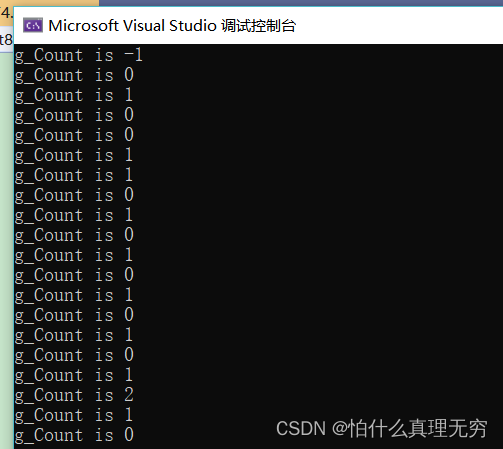
CRITICAL_SECTION 用法
#include <stdio.h> #include <windows.h> typedef RTL_CRITICAL_SECTION CRITICAL_SECTION; CRITICAL_SECTION g_cs; //声明关键段 // 共享资源 char g_cArray[10]; unsigned int g_Count 0; DWORD WINAPI ThreadProc10(LPVOID pParam) { // 进入临界区 …...
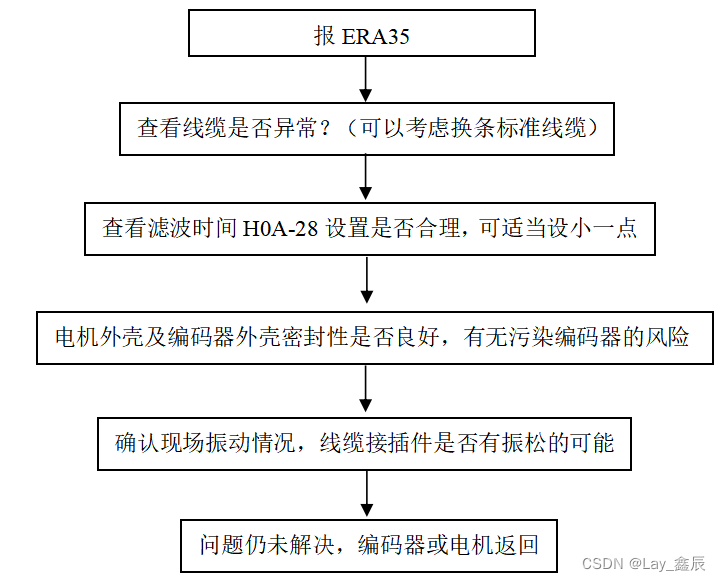
汇川运动控制产品故障排查
针对汇川伺服产品(IS600/IS620)的基本检测和一些出现频率较高的故障进行检测判断方法,适用于服务人员在现场排查/判断机器故障时,准确定位问题。 一、简单故障排查 注1:接线错误:1、UVW相序是否正确&#…...
【Groups】50 Matplotlib Visualizations, Python实现,源码可复现
详情请参考博客: Top 50 matplotlib Visualizations 因编译更新问题,本文将稍作更改,以便能够顺利运行。 1 Dendrogram 树状图根据给定的距离度量将相似的点组合在一起,并根据点的相似性将它们组织成树状的链接。 新建文件Dendrogram.py: …...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

AArch64内存管理:MAIR_EL3寄存器详解与应用
1. AArch64内存管理基础与MAIR_EL3寄存器定位 在Armv8-A/v9-A架构中,内存管理单元(MMU)通过多级页表实现虚拟地址到物理地址的转换。当处理器执行内存访问时,MMU会遍历页表条目(Translation Table Entry),其中包含两个关键信息:目…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...

WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案
WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案 【免费下载链接】wtfautolayout The source code for Why The Failure, Auto Layout? 项目地址: https://gitcode.com/gh_mirrors/wt/wtfautolayout 在iOS开发中,Auto Layout是构建灵…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...

对比不同模型在创意生成任务中的效果与token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比不同模型在创意生成任务中的效果与token消耗差异 在为一场创意大赛准备素材时,我们面临一个常见的选择:…...

ComfyUI-Manager完全指南:掌握AI工作流管理的核心技术
ComfyUI-Manager完全指南:掌握AI工作流管理的核心技术 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various custo…...

【C++】零基础入门 · 第 6 节:数组
上一节我们学习了函数,知道了如何把代码封装起来方便复用。但在实际编程中,你很快就会遇到一个问题:如果要存储 100 个学生的成绩,难道要定义 100 个变量吗?这显然不现实。数组就是 C++ 给出的答案——它让我们能用一个变量名管理一组相同类型的数据。 1. 为什么需要数组…...

LeagueAkari:基于LCU接口的英雄联盟客户端自动化工具深度解析
LeagueAkari:基于LCU接口的英雄联盟客户端自动化工具深度解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 功能模块架构与核心技…...