Python:Spider爬虫工程化入门到进阶(2)使用Spider Admin Pro管理scrapy爬虫项目
Python:Spider爬虫工程化入门到进阶系列:
- Python:Spider爬虫工程化入门到进阶(1)创建Scrapy爬虫项目
- Python:Spider爬虫工程化入门到进阶(2)使用Spider Admin Pro管理scrapy爬虫项目
目录
- 1、使用scrapyd运行爬虫
- 2、部署Scrapy爬虫项目
- 2.1、修改配置文件
- 2.2、部署项目
- 3、使用Spider Admin Pro定时执行爬虫
- 3.1、安装Spider Admin Pro
- 3.2、添加定时任务
- 3.3、查看调度日志
- 4、收集爬虫数据
- 4.1、返回Item对象
- 4.2、收集Item数据
- 5、总结
本文需要用到上文提到的scrapy-project 目录文件,需要提前创建
Python:Spider爬虫工程化入门到进阶(1)创建Scrapy爬虫项目
本文涉及3个文件目录,可以提前创建好
$ tree -L 1
.
├── scrapy-project
├── scrapyd-project
└── spider-admin-project
1、使用scrapyd运行爬虫
scrapyd可以管理scrapy爬虫项目
安装环境准备
# 创建目录,并进入
$ mkdir scrapyd-project && cd scrapyd-project# 创建虚拟环境,并激活
$ python3 -m venv venv && source venv/bin/activate
安装scrapyd
# 安装 scrapyd
$ pip install scrapyd$ scrapyd --version
Scrapyd 1.4.2
启动scrapyd服务
$ scrapyd
浏览器访问:http://127.0.0.1:6800/
2、部署Scrapy爬虫项目
2.1、修改配置文件
回到爬虫项目目录scrapy-project,修改配置文件 scrapy.cfg
将 deploy.url的注释去掉,6800 端口就是上面我们启动的scrapyd 端口
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html[settings]
default = web_spiders.settings[deploy]
# url = http://localhost:6800/
url = http://localhost:6800/
project = web_spiders2.2、部署项目
安装 scrapyd-client
pip install scrapyd-client
部署项目
$ scrapyd-deployPacking version 1691131715
Deploying to project "web_spiders" in http://localhost:6800/addversion.json
Server response (200):
{"node_name": "bogon", "status": "ok", "project": "web_spiders", "version": "1691131715", "spiders": 1}看到返回"status": "ok" 就是部署成功
3、使用Spider Admin Pro定时执行爬虫
Spider Admin Pro项目利用了scrapyd提供的api接口实现了一个可视化的爬虫管理平台,便于我们管理和调度爬虫
3.1、安装Spider Admin Pro
此时,我们需要再新建一个目录:spider-admin-project
# 创建目录,并进入
$ mkdir spider-admin-project && cd spider-admin-project# 创建虚拟环境,并激活
$ python3 -m venv venv && source venv/bin/activate
安装 spider-admin-pro
pip3 install spider-admin-pro
启动 spider-admin-pro
gunicorn 'spider_admin_pro.main:app'
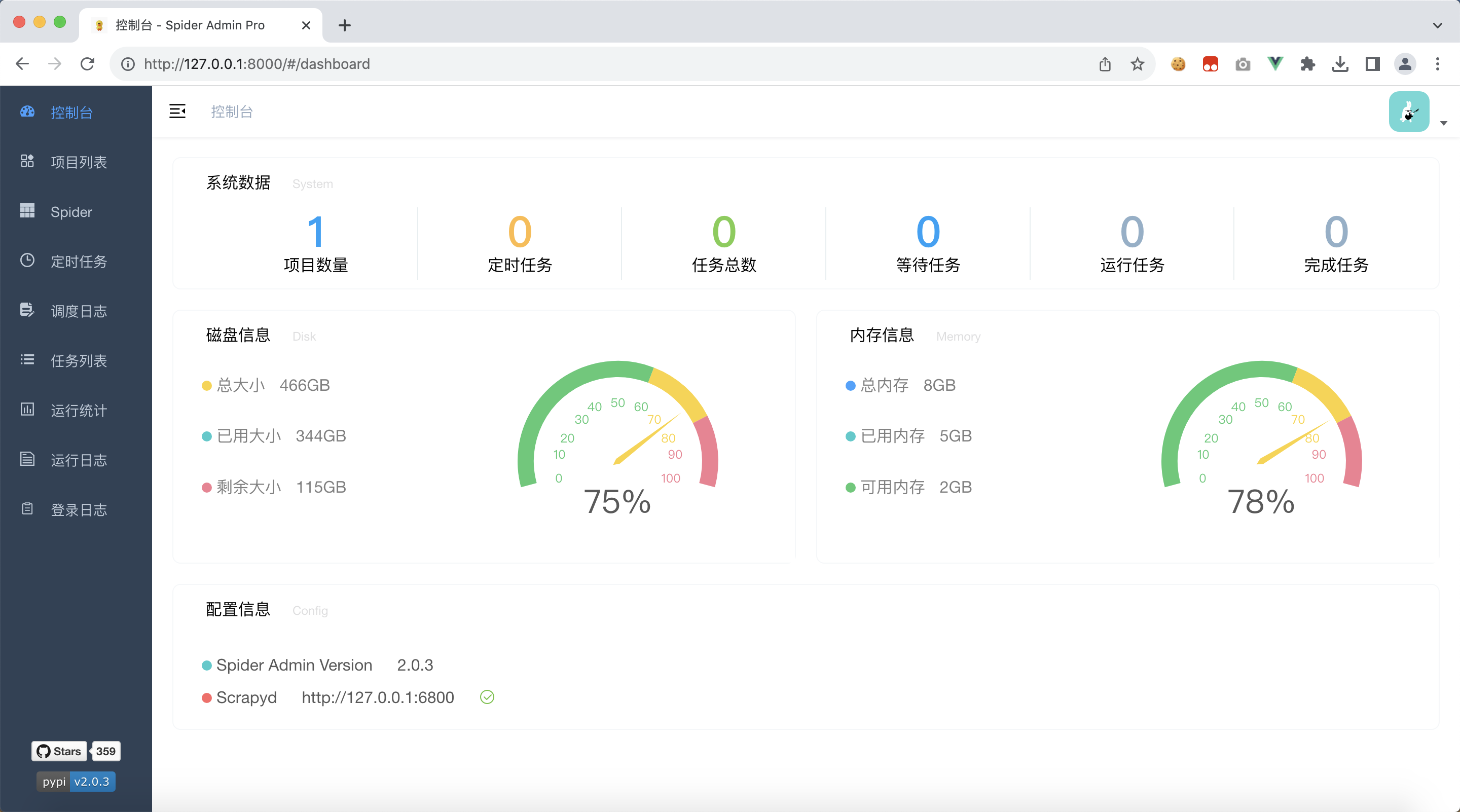
浏览器访问:http://127.0.0.1:8000/
默认的
- 账号 admin
- 密码 123456
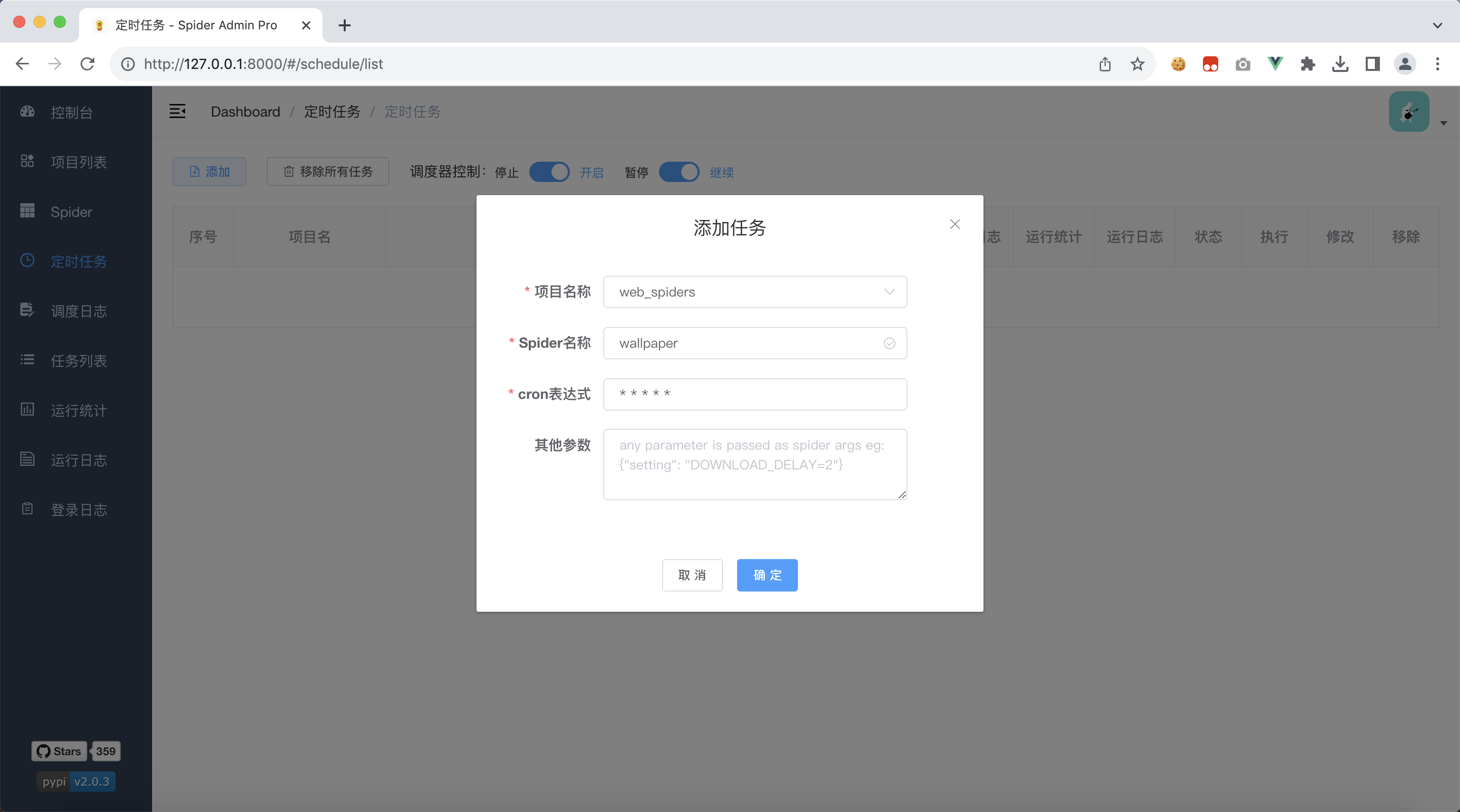
3.2、添加定时任务
我们点击左边tab栏:定时任务, 添加一个任务
我们的项目只有一个爬虫,默认会选中我们的爬虫名字
cron表达式表示的是每分钟执行一次
全部都是默认的,我们只需要点击确定 即可,因为现在还没有运行,所以日志都是空的,我们需要等待一会
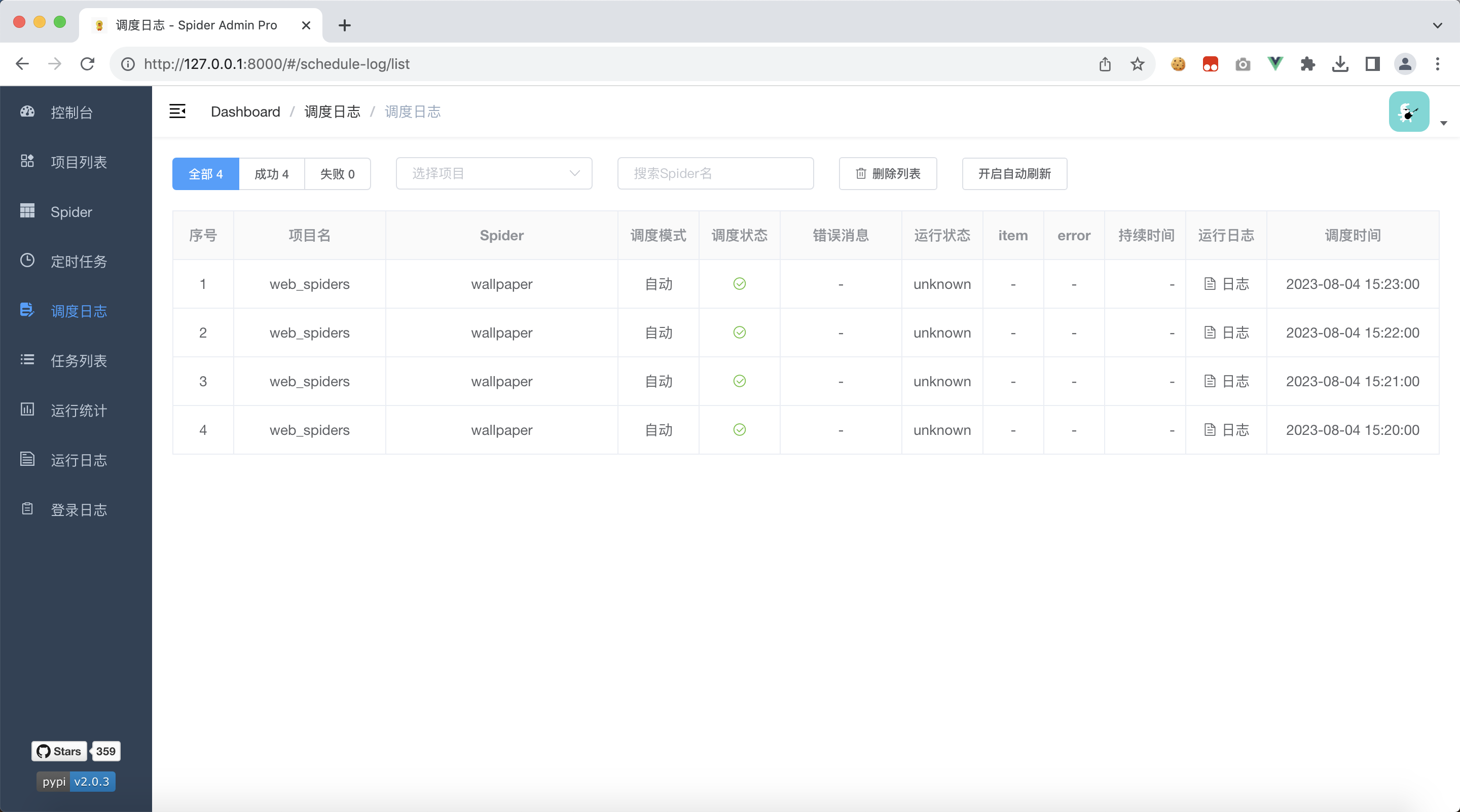
3.3、查看调度日志
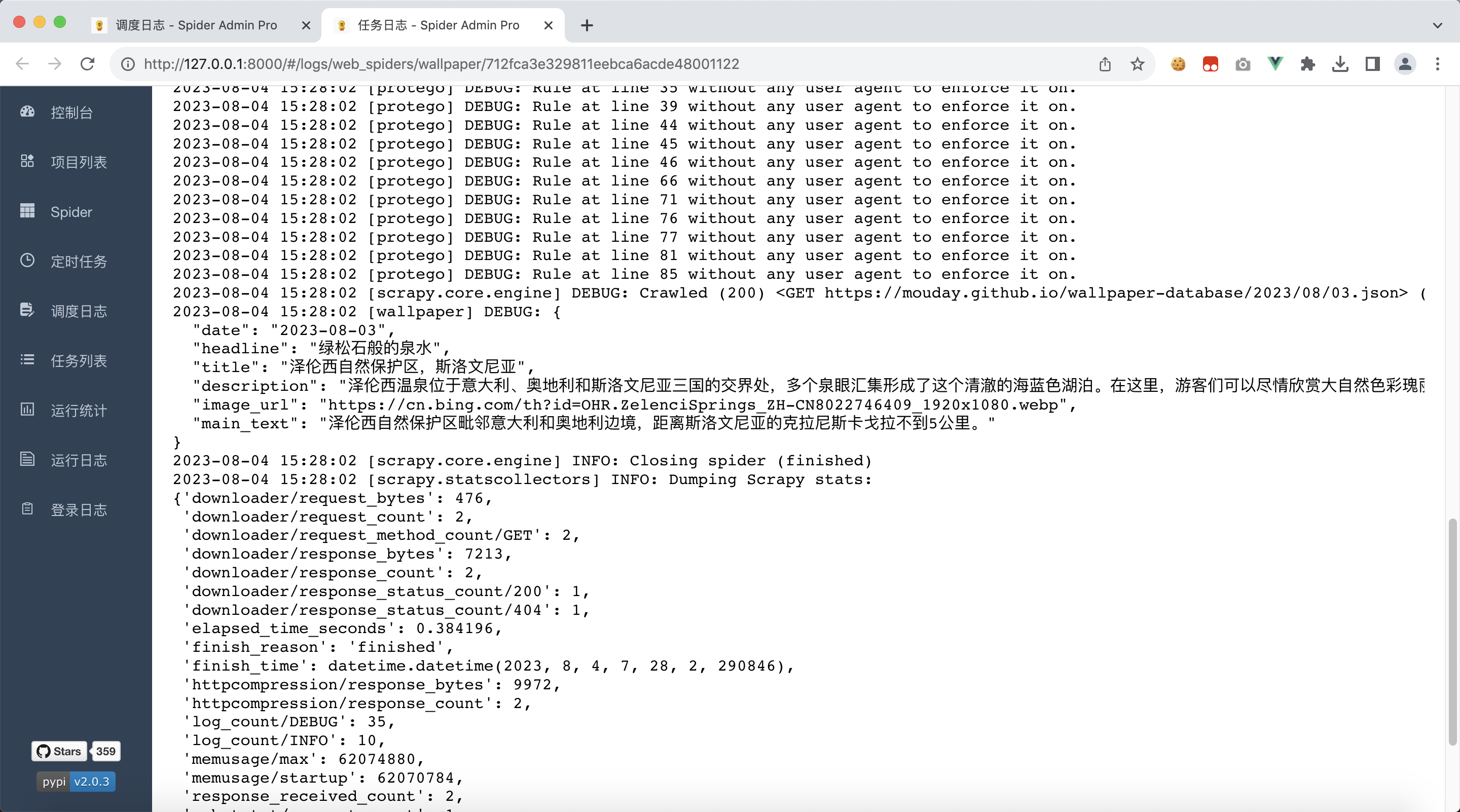
点击左侧tab栏:调度日志,过一会就能看到爬虫项目被执行了,可以在这里查看调度日志
需要注意的是,我们代码中使用 print 打印的内容,并不会出现在日志文件中
我们修改代码文件,将print修改为self.logger.debug
web_spiders/spiders/wallpaper.py
import scrapy
from scrapy.http import Responseclass WallpaperSpider(scrapy.Spider):name = "wallpaper"allowed_domains = ["mouday.github.io"]# 替换爬虫开始爬取的地址为我们需要的地址# start_urls = ["https://mouday.github.io"]start_urls = ["https://mouday.github.io/wallpaper-database/2023/08/03.json"]# 将类型标注加上,便于我们在IDE中快速编写代码# def parse(self, response):def parse(self, response: Response, **kwargs):# 我们什么也不做,仅打印爬取的文本# 使用 `print` 打印的内容,并不会出现在日志文件中# print(response.text)self.logger.debug(response.text)重新部署
$ scrapyd-deploy
等待刚刚部署的爬虫运行结束,就可以看到日志了
4、收集爬虫数据
4.1、返回Item对象
我们的目标网站返回的数据结构如下
{"date":"2023-08-03","headline":"绿松石般的泉水","title":"泽伦西自然保护区,斯洛文尼亚","description":"泽伦西温泉位于意大利、奥地利和斯洛文尼亚三国的交界处,多个泉眼汇集形成了这个清澈的海蓝色湖泊。在这里,游客们可以尽情欣赏大自然色彩瑰丽的调色盘。","image_url":"https://cn.bing.com/th?id=OHR.ZelenciSprings_ZH-CN8022746409_1920x1080.webp","main_text":"泽伦西自然保护区毗邻意大利和奥地利边境,距离斯洛文尼亚的克拉尼斯卡戈拉不到5公里。"
}所以,根据对应字段建立如下的Item对象
web_spiders/items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass WebSpidersItem(scrapy.Item):# define the fields for your item here like:date = scrapy.Field()headline = scrapy.Field()title = scrapy.Field()description = scrapy.Field()image_url = scrapy.Field()main_text = scrapy.Field()同时,修改爬虫文件,将数据包装到Item的子类 WebSpidersItem 对象上,并返回
web_spiders/spiders/wallpaper.py
import jsonimport scrapy
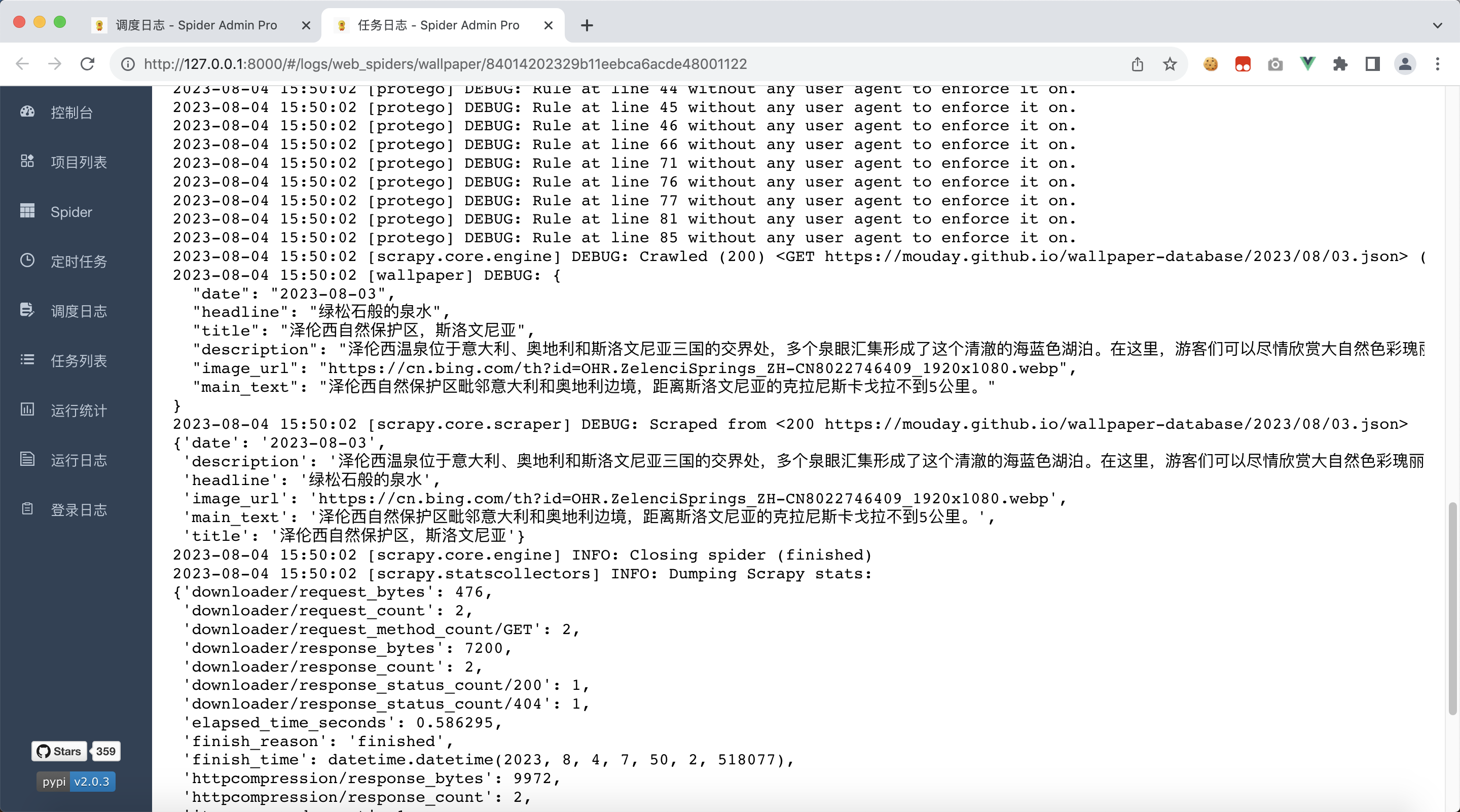
from scrapy.http import Responsefrom web_spiders.items import WebSpidersItemclass WallpaperSpider(scrapy.Spider):name = "wallpaper"allowed_domains = ["mouday.github.io"]# 替换爬虫开始爬取的地址为我们需要的地址# start_urls = ["https://mouday.github.io"]start_urls = ["https://mouday.github.io/wallpaper-database/2023/08/03.json"]# 将类型标注加上,便于我们在IDE中快速编写代码# def parse(self, response):def parse(self, response: Response, **kwargs):# 我们什么也不做,仅打印爬取的文本# 使用 `print` 打印的内容,并不会出现在日志文件中# print(response.text)self.logger.debug(response.text)# 使用json反序列化字符串为dict对象data = json.loads(response.text)# 收集我们需要的数据item = WebSpidersItem()item['date'] = data['date']item['headline'] = data['headline']item['title'] = data['title']item['description'] = data['description']item['image_url'] = data['image_url']item['main_text'] = data['main_text']return item重新部署
$ scrapyd-deploy
可以看到,除了打印的日志外,还多打印了一份数据,这就是我们刚返回的Item对象
4.2、收集Item数据
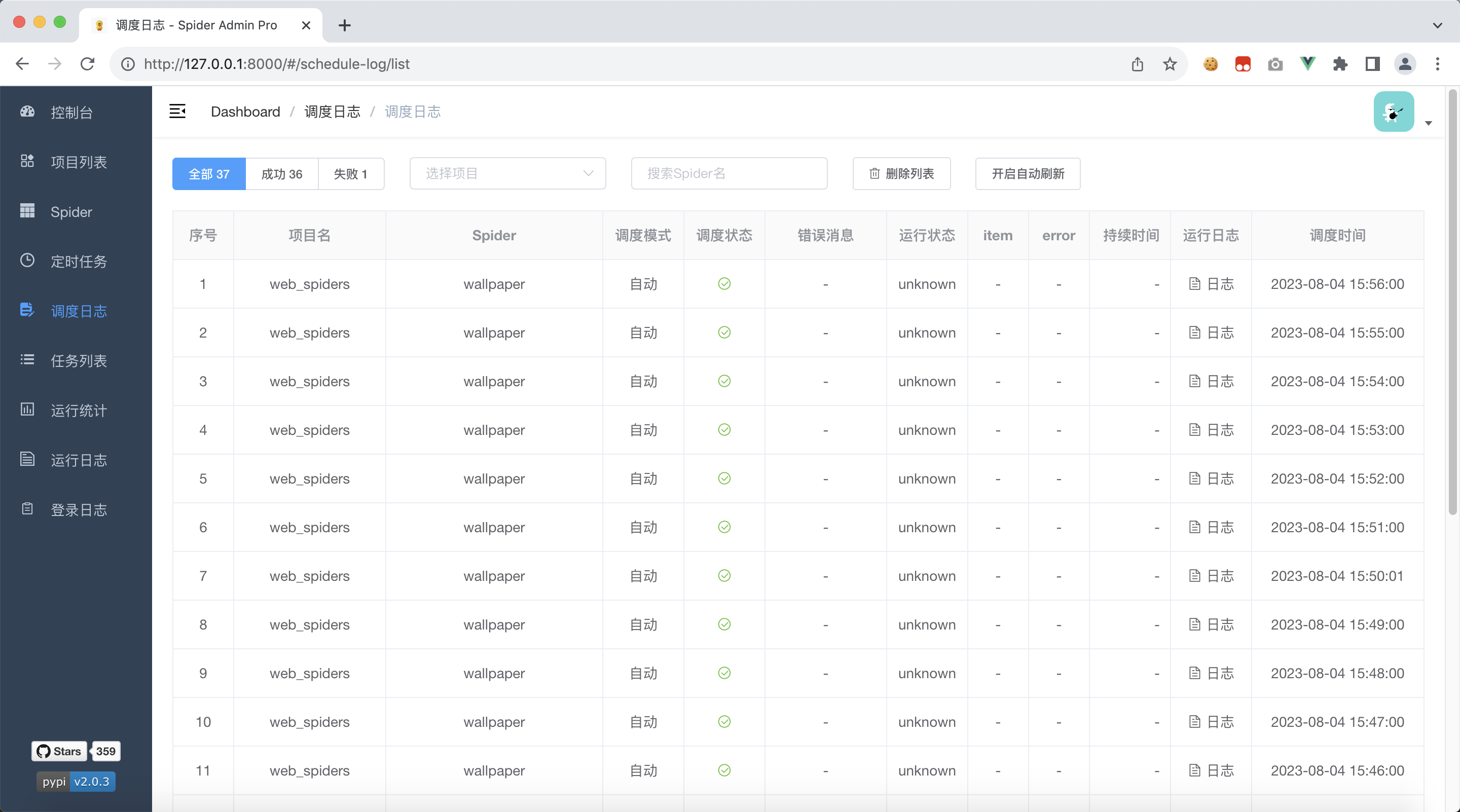
我们可以看到,运行状态一列,都是unknown,我们需要知道爬虫的运行状态,是成功还是失败
scrapy-util 可以帮助我们收集到程序运行的统计数据
返回项目scrapy-project
安装scrapy-util
pip install scrapy-util
修改配置文件 web_spiders/settings.py
将以下配置添加到配置文件中,端口号改为 spider-admin-pro 的实际端口号,这里是8000
# 设置收集运行日志的路径,会以post方式向 spider-admin-pro 提交json数据
# 注意:此处配置仅为示例,请设置为 spider-admin-pro 的真实路径
# 假设,我们的 spider-admin-pro 运行在http://127.0.0.1:8000
STATS_COLLECTION_URL = "http://127.0.0.1:8000/api/statsCollection/addItem"# 启用数据收集扩展
EXTENSIONS = {# ===========================================# 可选:如果收集到的时间是utc时间,可以使用本地时间扩展收集'scrapy.extensions.corestats.CoreStats': None,'scrapy_util.extensions.LocaltimeCoreStats': 0,# ===========================================# 可选,打印程序运行时长'scrapy_util.extensions.ShowDurationExtension': 100,# 启用数据收集扩展'scrapy_util.extensions.StatsCollectorExtension': 100
}
重新部署
$ scrapyd-deploy
我们看到scrapyd的控制台输出了如下信息
ModuleNotFoundError: No module named 'scrapy_util'
说明有问题,因为我们没有给scrapyd的运行环境安装依赖scrapy-util
停掉scrapyd,安装scrapy-util
pip install scrapy-util
安装完毕后,重新启动 scrapyd
让爬虫执行一会,我们就可以看到,调度日志列表多了一些信息,可以看到
- 运行状态:finished,而不是unknown
- item数量是1,我们返回了1个item对象
- error错误时空的,说明程序没有报错
- 持续时间是1秒,运行时间很短,很快就结束了

5、总结
本文用到了很多的第三方模块,将这些模块整合进我们的项目能极大提高工作效率
| 第三方库 | 说明 | 文档资料 |
|---|---|---|
| scrapy | 创建工程化的爬虫项目 | github |
| scrapyd | 运行scrapy爬虫 | github、docs |
| scrapyd-client | 部署scrapy爬虫 | github |
| spider-admin-pro | 调度scrapy爬虫 | github |
| scrapy-util | 收集爬虫运行结果 | github |
| gunicorn | 执行spider-admin-pro应用 | docs |
相关文章:
Python:Spider爬虫工程化入门到进阶(2)使用Spider Admin Pro管理scrapy爬虫项目
Python:Spider爬虫工程化入门到进阶系列: Python:Spider爬虫工程化入门到进阶(1)创建Scrapy爬虫项目Python:Spider爬虫工程化入门到进阶(2)使用Spider Admin Pro管理scrapy爬虫项目 目录 1、使…...

CubeMap convert into Octahedral思路
看了一些介绍,大多都是如何采样Octahedral的,那么如何把cubemap转成为这个呢 首先,我们想想 Vec4 Sample(Vec3 direction) { // Some logicwait wait wait think about what weve got here UV UV UV! return SampleTexture(Image, UV); }这个…...
vue项目实战-脑图编辑管理系统kitymind百度脑图
前言 项目为前端vue项目,把kitymind百度脑图整合到前端vue项目中,显示了脑图的绘制,编辑,到处为json,png,text等格式的功能 文章末尾有相关的代码链接,代码只包含前端项目,在原始的…...

c++调用ffmpeg api录屏 并进行rtmp推流
代码及工程见https://download.csdn.net/download/daqinzl/88156528 开发工具:visual studio 2019 记得启动rtmp流媒体服务 nginx的rtmp服务见https://download.csdn.net/download/daqinzl/20478812 播放,采用ffmpeg工具集里的ffplay.exe, 执行命令 f…...

SQL分类及通用语法数据类型(超详细版)
一、SQL分类 SQL是结构化查询语言(Structured Query Language)的缩写。它是一种用于管理和操作关系型数据库系统的标准化语言。SQL分类如下: DDL: 数据定义语言,用来定义数据库对象(数据库、表、字段)DML:…...

配置Hive远程服务详细步骤
HiveServer2支持多客户端的并发和认证,为开放API客户端如JDBC、ODBC提供了更好的支持。 (1)修改hive-site.xml,在文件中添加以下内容: <property><name>hive.metastore.event.db.notification.api.auth&l…...
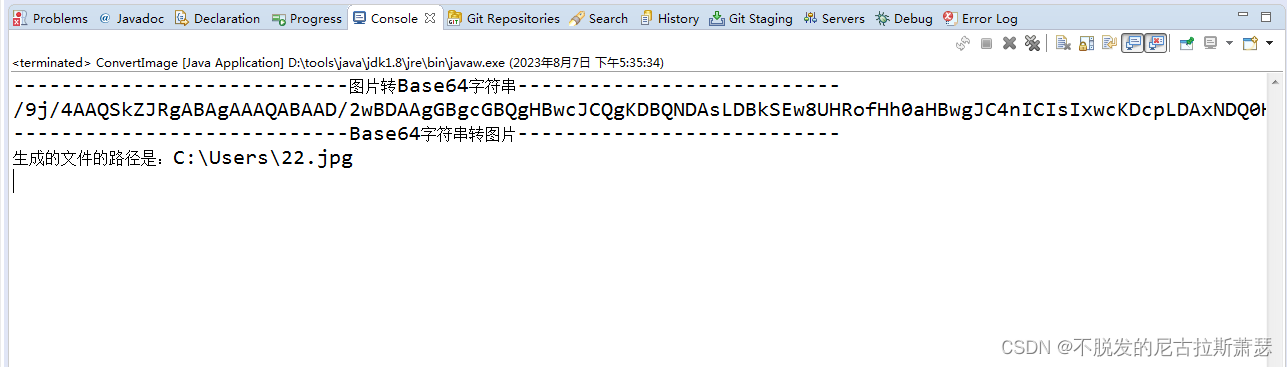
Java中实现图片和Base64的互相转化
文章目录 前言一、代码二、测试三、结果 前言 公司项目中用到了实名认证此,采用的第三方平台。后端中用到的单项功能为身份证信息人像对比功能,在写demo的过程中发现,它们所要求的图片信息为base64编码格式。 一、代码 package com.bajiao…...

视频添加字幕
1、依靠ffmpeg 命令 package zimu;import java.io.IOException;public class TestSrt {public static void main(String[] args) {String videoFile "/test/test1.mp4";String subtitleFile "/test/test1.SRT";String outputFile "/test/testout13…...

Vue VS React:两大前端框架的对比与分析
Vue和React是当前最流行的前端框架之一,它们都有着广泛的应用和开发者社区。下面是Vue和React之间的深度对比与分析: 学习曲线: Vue:Vue拥有简单直观的API和文档,对初学者友好。Vue的设计初衷是逐步增强的,…...
)
【机密计算标准解读】 基于TEE的安全计算(IEEE 2952)
目录 1.概述2.定义、术语、缩略语3.技术框架3.1 架构框架3.2 分层功能4.基础组件4.1 基础层4.2 平台层4.3 应用层4.4 服务层4.5 交叉层5.安全计算参考过程6.技术和安全要求6.1 隔离要求6.2 互操作要求6.3 性能要求6.4 可用性要求6.5 数据安全要求6.6 密码学要求 1. 概述 随着…...
程序员编写文档的 10 个技巧
编写好的文档在软件开发领域具有重大意义。文档是概述特定问题陈述、方法、功能、工作流程、架构、挑战和开发过程的书面数据或指令。文档可以让你全面了解解决方案的功能、安装和配置。 文档不仅是为其他人编写的,也是为自己编写的。它让我们自己知道我们以前做过什…...

【ES问题总结】
文章目录 1、什么是ElasticSearch;2、ElasticSearch的基本概念;3、什么是倒排索引;4、DocValue的作用;5、text和keyword类型的区别;7、query和filter的区别;8、es写数据的过程;9、es的更新和删除流程&#…...

数据结构----结构--线性结构--顺序存储--数组
数据结构----结构–线性结构–顺序存储–数组 数组:类型相同,空间连续,长度固定 搜索: (1)基于索引搜索,时间复杂度O(1) (2)基于数值搜索: 1.有序的&…...

docker 启动kitex 的opentelemetry
https://github.com/cloudwego/kitex-examples/blob/main/opentelemetry/docker-compose.yaml 下载两个yaml文件:docker-compose.yaml otel-collector-config.yaml 在该目录下执行 docker-compose up -d...
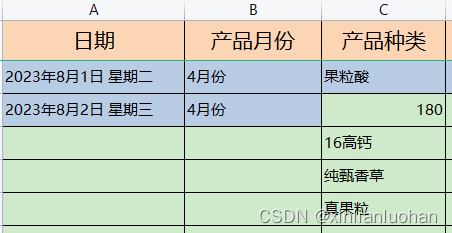
Excel中——日期列后添加星期
需求:在日期列中添加星期几? 第一步:打开需要添加星期的Excel文件,在日期后面添加日期 第二步:选择日期列,点击鼠标右键,在下拉列表中,选择“设置单元格格式” 第三步: 在…...
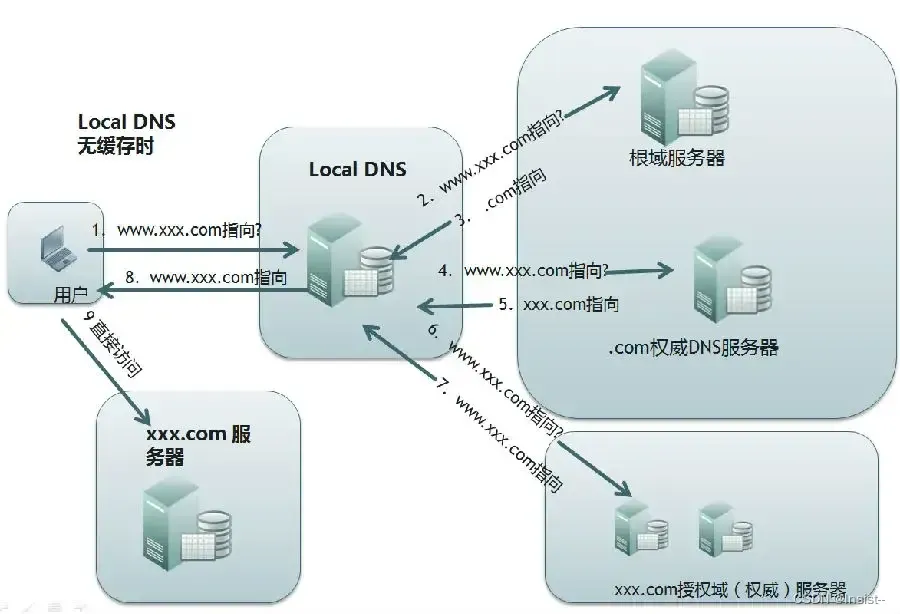
谈谈DNS是什么?它的作用以及工作流程
作者:Insist-- 个人主页:insist--个人主页 作者会持续更新网络知识和python基础知识,期待你的关注 目录 一、DNS是什么? 二、DNS的作用 三、DNS查询流程 1、查看浏览器缓存 2、查看系统缓存 3、查看路由器缓存 4、查看ISP …...

Qt小项目贪吃蛇实线,主要掌握定时器、信号与槽、按键事件、绘制事件、坐标运算、随机数生成等
Qt小项目贪吃蛇实线,主要掌握定时器、信号与槽、按键事件、绘制事件、坐标运算、随机数生成等 Qt 贪吃蛇演示QWidget 绘制界面项目源文件 注释清晰widget.hwidget.cpp 拓展QTimerQKeyEventQRectFQPointFQPainterQIcon Qt 贪吃蛇演示 QWidget 绘制界面 项目源文件 注…...

使用HTTP隧道时如何应对目标网站的反爬虫监测?
在进行网络抓取时,我们常常会遇到目标网站对反爬虫的监测和封禁。为了规避这些风险,使用代理IP成为一种常见的方法。然而,如何应对目标网站的反爬虫监测,既能保证数据的稳定性,又能确保抓取过程的安全性呢?…...
怎么样通过Bootstrap已经编译好(压缩好)的源码去查看符合阅读习惯的源码【通过Source Map(源映射)文件实现】
阅读本篇博文前,建议大家先看看下面这篇博文: https://blog.csdn.net/wenhao_ir/article/details/132089650 Bootstrap经编译(压缩)后的源码百度网盘下载地址: https://pan.baidu.com/s/14BM9gpC3K-LKxhyLGh4J9Q?pwdm02m Bootstrap未经编译…...
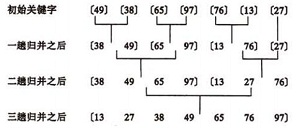
【排序算法】python之冒泡,选择,插入,快速,归并
参考资料: 《Python实现5大排序算法》《六大排序算法:插入排序、希尔排序、选择排序、冒泡排序、堆排序、快速排序》 --代码似乎是C语言 ———————— 本文介绍5种常见的排序算法和基于Python实现: 冒泡排序(Bubble Sort&am…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

GEMM内核与MHA中的寄存器分配优化策略
1. GEMM内核与寄存器分配基础解析通用矩阵乘法(GEMM)作为深度学习计算的核心算子,其性能表现直接决定了神经网络训练和推理的效率。在硬件层面,寄存器分配的优劣往往能带来数倍的性能差异。我们以典型的GEMM运算C αAB βC为例&…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

2026年,本地精准营销高性价比服务商来袭,你还不了解一下?
在本地商业竞争日益激烈的2026年,实体店面临着诸多挑战,引流难、成本高、复购率低等问题困扰着众多商家。而中粤(广州)信息科技有限公司作为本地精准营销的高性价比服务商,正以其独特的优势和卓越的服务,为…...

Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器
Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而头疼吗?想要备份游戏资源却不…...

AI率总超标?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案
OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 在惠…...