SQL分类及通用语法数据类型(超详细版)
一、SQL分类
SQL是结构化查询语言(Structured Query Language)的缩写。它是一种用于管理和操作关系型数据库系统的标准化语言。SQL分类如下:

- DDL: 数据定义语言,用来定义数据库对象(数据库、表、字段)
- DML: 数据操作语言,用来对数据库表中的数据进行增删改
- DQL: 数据查询语言,用来查询数据库中表的记录
- DCL: 数据控制语言,用来创建数据库用户、控制数据库的控制权限
二、DDL-数据定于语言
2.1 DDL-数据库操作

查询所有数据库: SHOW DATABASES;
查询当前数据库: SELECT DATABASE();
创建数据库: CREATE DATABASE [ IF NOT EXISTS ] 数据库名 [ DEFAULT CHARSET 字符集] [COLLATE 排序规则 ];
删除数据库: DROP DATABASE [ IF EXISTS ] 数据库名;
使用数据库: USE 数据库名;
注意事项
- UTF8字符集长度为3字节,有些符号占4字节,所以推荐用utf8mb4字符集
2.2 DDL-表操作

查询当前数据库所有表: SHOW TABLES;
查询表结构: DESC 表名;
查询指定表的建表语句: SHOW CREATE TABLE 表名;

创建表:
CREATE TABLE 表名 (
字段1 数据类型 约束,
字段2 数据类型 约束,
字段3 数据类型 约束,
...
);
添加字段: ALTER TABLE 表名 ADD 字段名 类型(长度) [COMMENT 注释] [约束];
例:ALTER TABLE emp ADD nickname varchar(20) COMMENT '昵称';
修改数据类型: ALTER TABLE 表名 MODIFY 字段名 新数据类型(长度);
修改字段名和字段类型: ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度) [COMMENT 注释] [约束];
例:将emp表的nickname字段修改为username,类型为varchar(30) ALTER TABLE emp CHANGE nickname username varchar(30) COMMENT '昵称';
删除字段: ALTER TABLE 表名 DROP 字段名;
修改表名: ALTER TABLE 表名 RENAME TO 新表名
删除表: DROP TABLE [IF EXISTS] 表名;
删除表,并重新创建该表: TRUNCATE TABLE 表名;
三、补充:数据类型
3.1 整型
| 类型名称 | 取值范围 | 大小 |
|---|---|---|
| TINYINT | -128〜127 | 1个字节 |
| SMALLINT | -32768〜32767 | 2个宇节 |
| MEDIUMINT | -8388608〜8388607 | 3个字节 |
| INT (INTEGHR) | -2147483648〜2147483647 | 4个字节 |
| BIGINT | -9223372036854775808〜9223372036854775807 | 8个字节 |
无符号在数据类型后加 unsigned 关键字。
3.2 浮点型
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| FLOAT | 单精度浮点数 | 4 个字节 |
| DOUBLE | 双精度浮点数 | 8 个字节 |
| DECIMAL (M, D),DEC | 压缩的“严格”定点数 | M+2 个字节 |
3.3 日期和时间
| 类型名称 | 日期格式 | 日期范围 | 存储需求 |
|---|---|---|---|
| YEAR | YYYY | 1901 ~ 2155 | 1 个字节 |
| TIME | HH:MM:SS | -838:59:59 ~ 838:59:59 | 3 个字节 |
| DATE | YYYY-MM-DD | 1000-01-01 ~ 9999-12-3 | 3 个字节 |
| DATETIME | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 | 8 个字节 |
| TIMESTAMP | YYYY-MM-DD HH:MM:SS | 1980-01-01 00:00:01 UTC ~ 2040-01-19 03:14:07 UTC | 4 个字节 |
3.4 字符串
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| CHAR(M) | 固定长度非二进制字符串(性能好) | M 字节,1<=M<=255 |
| VARCHAR(M) | 变长非二进制字符串 (性能较差) | L+1字节,在此,L< = M和 1<=M<=255 |
| TINYTEXT | 非常小的非二进制字符串 | L+1字节,在此,L<2^8 |
| TEXT | 小的非二进制字符串 | L+2字节,在此,L<2^16 |
| MEDIUMTEXT | 中等大小的非二进制字符串 | L+3字节,在此,L<2^24 |
| LONGTEXT | 大的非二进制字符串 | L+4字节,在此,L<2^32 |
| ENUM | 枚举类型,只能有一个枚举字符串值 | 1或2个字节,取决于枚举值的数目 (最大值为65535) |
| SET | 一个设置,字符串对象可以有零个或 多个SET成员 | 1、2、3、4或8个字节,取决于集合 成员的数量(最多64个成员) |
3.5 二进制类型
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| BIT(M) | 位字段类型 | 大约 (M+7)/8 字节 |
| BINARY(M) | 固定长度二进制字符串 | M 字节 |
| VARBINARY (M) | 可变长度二进制字符串 | M+1 字节 |
| TINYBLOB (M) | 非常小的BLOB | L+1 字节,在此,L<2^8 |
| BLOB (M) | 小 BLOB | L+2 字节,在此,L<2^16 |
| MEDIUMBLOB (M) | 中等大小的BLOB | L+3 字节,在此,L<2^24 |
| LONGBLOB (M) | 非常大的BLOB | L+4 字节,在此,L<2^32 |
四、DML- 数据操作语言
4.1 添加数据
指定字段: INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...);
全部字段: INSERT INTO 表名 VALUES (值1, 值2, ...);
批量添加数据: INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...), (值1, 值2, ...), (值1, 值2, ...); INSERT INTO 表名 VALUES (值1, 值2, ...), (值1, 值2, ...), (值1, 值2, ...);
注意事项
- 字符串和日期类型数据应该包含在引号中
- 插入的数据大小应该在字段的规定范围内
4.2 更新和删除数据

修改数据: UPDATE 表名 SET 字段名1 = 值1, 字段名2 = 值2, ... [ WHERE 条件 ];
例: UPDATE emp SET name = 'Jack' WHERE id = 1;
删除数据: DELETE FROM 表名 [ WHERE 条件 ];
五、DQL- 数据查询语言

5.1 基础查询

查询多个字段: SELECT 字段1, 字段2, 字段3, ... FROM 表名; SELECT * FROM 表名;
设置别名: SELECT 字段1 [ AS 别名1 ], 字段2 [ AS 别名2 ], 字段3 [ AS 别名3 ], ... FROM 表名; SELECT 字段1 [ 别名1 ], 字段2 [ 别名2 ], 字段3 [ 别名3 ], ... FROM 表名;
去除重复记录: SELECT DISTINCT 字段列表 FROM 表名;
5.2 条件查询

条件查询: SELECT 字段列表 FROM 表名 WHERE 条件列表;
例子:
-- 年龄等于30select * from employee where age = 30;-- 年龄小于30select * from employee where age < 30;-- 小于等于select * from employee where age <= 30;-- 没有身份证select * from employee where idcard is null or idcard = '';-- 有身份证select * from employee where idcard is not null;-- 不等于select * from employee where age != 30;-- 年龄在20到30之间select * from employee where age between 20 and 30;select * from employee where age >= 20 and age <= 30;-- 下面语句不报错,但查不到任何信息select * from employee where age between 30 and 20;-- 性别为女且年龄小于30select * from employee where age < 30 and gender = '女';-- 年龄等于25或30或35select * from employee where age = 25 or age = 30 or age = 35;select * from employee where age in (25, 30, 35);-- 姓名为两个字select * from employee where name like '__'; (此处为两个 _ )-- 身份证最后为Xselect * from employee where idcard like '%X';
5.3 聚合函数
 语法:
语法: SELECT 聚合函数(字段列表) FROM 表名;
例: SELECT count(id) from employee where workaddress = "广东省";
5.4 分组查询
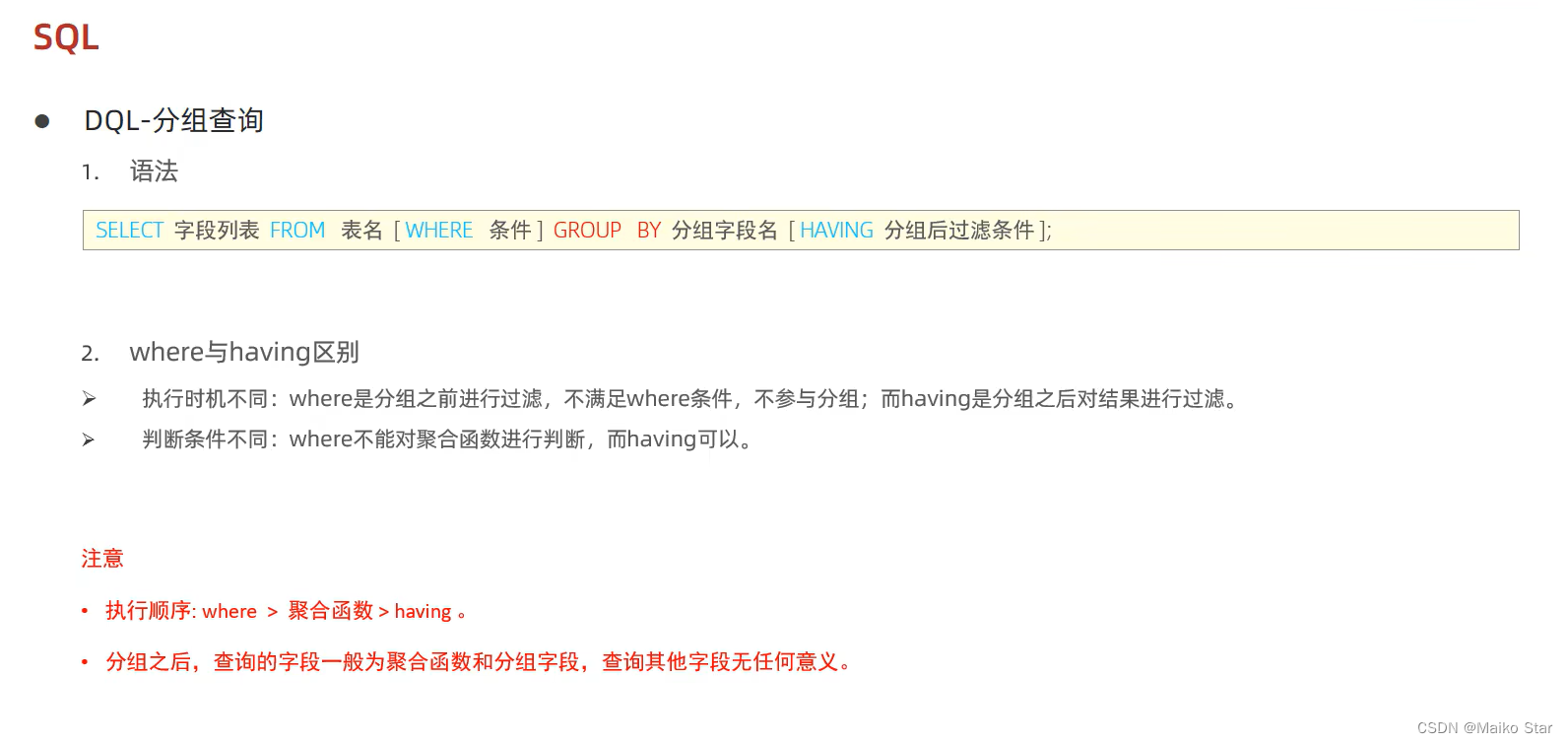
语法: SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组后的过滤条件 ];
where 和 having 的区别:
- 执行时机不同:where是分组之前进行过滤,不满足where条件不参与分组;having是分组后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
例子:
-- 根据性别分组,统计男性和女性数量(只显示分组数量,不显示哪个是男哪个是女)select count(*) from employee group by gender;-- 根据性别分组,统计男性和女性数量select gender, count(*) from employee group by gender;-- 根据性别分组,统计男性和女性的平均年龄select gender, avg(age) from employee group by gender;-- 年龄小于45,并根据工作地址分组select workaddress, count(*) from employee where age < 45 group by workaddress;-- 年龄小于45,并根据工作地址分组,获取员工数量大于等于3的工作地址select workaddress, count(*) address_count from employee where age < 45 group by workaddress having address_count >= 3;
注意事项
- 执行顺序:where > 聚合函数 > having
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
5.5 排序查询

语法: SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1, 字段2 排序方式2;
排序方式:
- ASC: 升序(默认)
- DESC: 降序
例子:
-- 根据年龄升序排序SELECT * FROM employee ORDER BY age ASC;SELECT * FROM employee ORDER BY age;-- 两字段排序,根据年龄升序排序,入职时间降序排序SELECT * FROM employee ORDER BY age ASC, entrydate DESC;
注意事项:
如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
5.6 分页查询

语法: SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数;
例子:
-- 查询第一页数据,展示10条SELECT * FROM employee LIMIT 0, 10;-- 查询第二页SELECT * FROM employee LIMIT 10, 10;
注意事项
- 起始索引从0开始,起始索引 = (查询页码 - 1) * 每页显示记录数
- 分页查询是数据库的方言,不同数据库有不同实现,MySQL是LIMIT
- 如果查询的是第一页数据,起始索引可以省略,直接简写 LIMIT 10
六、DQL-执行顺序
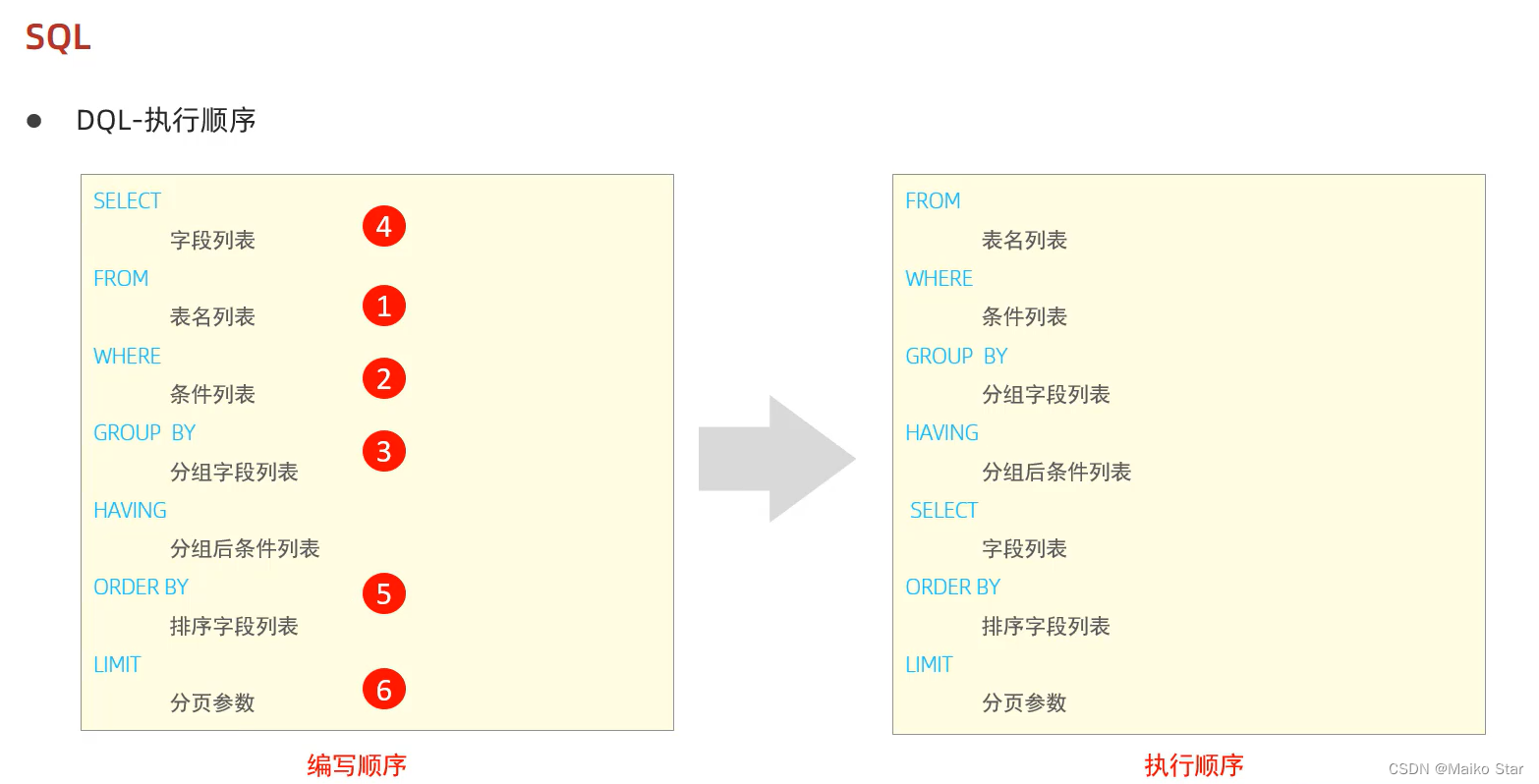
DQL执行顺序
FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY -> LIMIT
七、DCL-数据控制语言 (开发人员操作较少)
7.1 管理用户

查询用户:
USE mysql;SELECT * FROM user;
创建用户: CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
修改用户密码: ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码';
删除用户: DROP USER '用户名'@'主机名';
例子:
-- 创建用户test,只能在当前主机localhost访问create user 'test'@'localhost' identified by '123456';-- 创建用户test,能在任意主机访问create user 'test'@'%' identified by '123456';create user 'test' identified by '123456';-- 修改密码alter user 'test'@'localhost' identified with mysql_native_password by '1234';-- 删除用户drop user 'test'@'localhost';
注意事项
- 主机名可以使用 % 通配
7.2 权限控制
常用权限:
| 权限 | 说明 |
|---|---|
| ALL, ALL PRIVILEGES | 所有权限 |
| SELECT | 查询数据 |
| INSERT | 插入数据 |
| UPDATE | 修改数据 |
| DELETE | 删除数据 |
| ALTER | 修改表 |
| DROP | 删除数据库/表/视图 |
| CREATE | 创建数据库/表 |

查询权限: SHOW GRANTS FOR '用户名'@'主机名';
授予权限: GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名';
撤销权限: REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';
注意事项
- 多个权限用逗号分隔
- 授权时,数据库名和表名可以用 * 进行通配,代表所有
相关文章:
SQL分类及通用语法数据类型(超详细版)
一、SQL分类 SQL是结构化查询语言(Structured Query Language)的缩写。它是一种用于管理和操作关系型数据库系统的标准化语言。SQL分类如下: DDL: 数据定义语言,用来定义数据库对象(数据库、表、字段)DML:…...

配置Hive远程服务详细步骤
HiveServer2支持多客户端的并发和认证,为开放API客户端如JDBC、ODBC提供了更好的支持。 (1)修改hive-site.xml,在文件中添加以下内容: <property><name>hive.metastore.event.db.notification.api.auth&l…...
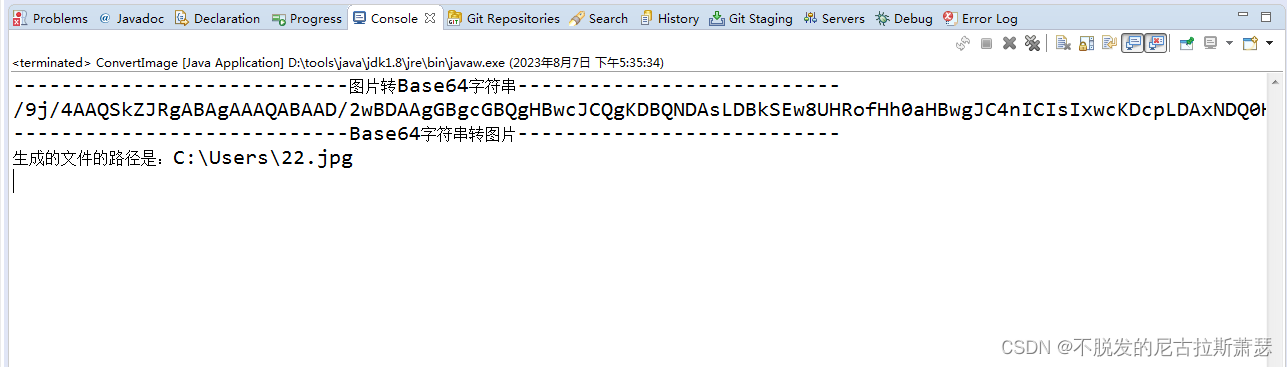
Java中实现图片和Base64的互相转化
文章目录 前言一、代码二、测试三、结果 前言 公司项目中用到了实名认证此,采用的第三方平台。后端中用到的单项功能为身份证信息人像对比功能,在写demo的过程中发现,它们所要求的图片信息为base64编码格式。 一、代码 package com.bajiao…...

视频添加字幕
1、依靠ffmpeg 命令 package zimu;import java.io.IOException;public class TestSrt {public static void main(String[] args) {String videoFile "/test/test1.mp4";String subtitleFile "/test/test1.SRT";String outputFile "/test/testout13…...

Vue VS React:两大前端框架的对比与分析
Vue和React是当前最流行的前端框架之一,它们都有着广泛的应用和开发者社区。下面是Vue和React之间的深度对比与分析: 学习曲线: Vue:Vue拥有简单直观的API和文档,对初学者友好。Vue的设计初衷是逐步增强的,…...
)
【机密计算标准解读】 基于TEE的安全计算(IEEE 2952)
目录 1.概述2.定义、术语、缩略语3.技术框架3.1 架构框架3.2 分层功能4.基础组件4.1 基础层4.2 平台层4.3 应用层4.4 服务层4.5 交叉层5.安全计算参考过程6.技术和安全要求6.1 隔离要求6.2 互操作要求6.3 性能要求6.4 可用性要求6.5 数据安全要求6.6 密码学要求 1. 概述 随着…...
程序员编写文档的 10 个技巧
编写好的文档在软件开发领域具有重大意义。文档是概述特定问题陈述、方法、功能、工作流程、架构、挑战和开发过程的书面数据或指令。文档可以让你全面了解解决方案的功能、安装和配置。 文档不仅是为其他人编写的,也是为自己编写的。它让我们自己知道我们以前做过什…...

【ES问题总结】
文章目录 1、什么是ElasticSearch;2、ElasticSearch的基本概念;3、什么是倒排索引;4、DocValue的作用;5、text和keyword类型的区别;7、query和filter的区别;8、es写数据的过程;9、es的更新和删除流程&#…...

数据结构----结构--线性结构--顺序存储--数组
数据结构----结构–线性结构–顺序存储–数组 数组:类型相同,空间连续,长度固定 搜索: (1)基于索引搜索,时间复杂度O(1) (2)基于数值搜索: 1.有序的&…...

docker 启动kitex 的opentelemetry
https://github.com/cloudwego/kitex-examples/blob/main/opentelemetry/docker-compose.yaml 下载两个yaml文件:docker-compose.yaml otel-collector-config.yaml 在该目录下执行 docker-compose up -d...
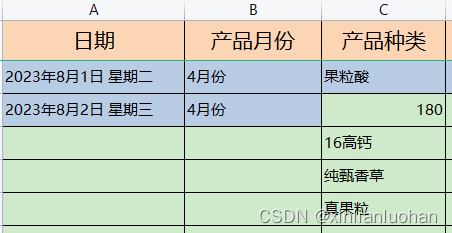
Excel中——日期列后添加星期
需求:在日期列中添加星期几? 第一步:打开需要添加星期的Excel文件,在日期后面添加日期 第二步:选择日期列,点击鼠标右键,在下拉列表中,选择“设置单元格格式” 第三步: 在…...
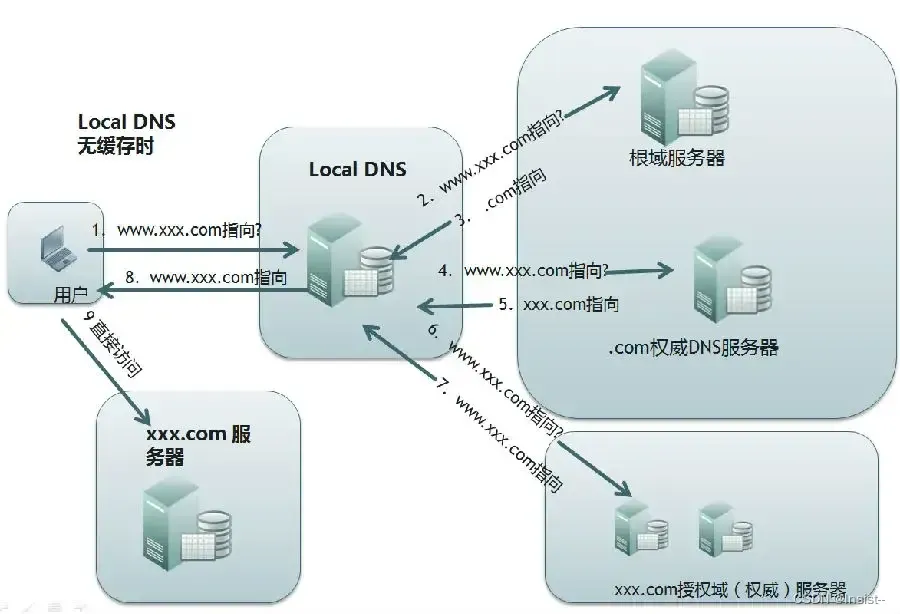
谈谈DNS是什么?它的作用以及工作流程
作者:Insist-- 个人主页:insist--个人主页 作者会持续更新网络知识和python基础知识,期待你的关注 目录 一、DNS是什么? 二、DNS的作用 三、DNS查询流程 1、查看浏览器缓存 2、查看系统缓存 3、查看路由器缓存 4、查看ISP …...

Qt小项目贪吃蛇实线,主要掌握定时器、信号与槽、按键事件、绘制事件、坐标运算、随机数生成等
Qt小项目贪吃蛇实线,主要掌握定时器、信号与槽、按键事件、绘制事件、坐标运算、随机数生成等 Qt 贪吃蛇演示QWidget 绘制界面项目源文件 注释清晰widget.hwidget.cpp 拓展QTimerQKeyEventQRectFQPointFQPainterQIcon Qt 贪吃蛇演示 QWidget 绘制界面 项目源文件 注…...

使用HTTP隧道时如何应对目标网站的反爬虫监测?
在进行网络抓取时,我们常常会遇到目标网站对反爬虫的监测和封禁。为了规避这些风险,使用代理IP成为一种常见的方法。然而,如何应对目标网站的反爬虫监测,既能保证数据的稳定性,又能确保抓取过程的安全性呢?…...
怎么样通过Bootstrap已经编译好(压缩好)的源码去查看符合阅读习惯的源码【通过Source Map(源映射)文件实现】
阅读本篇博文前,建议大家先看看下面这篇博文: https://blog.csdn.net/wenhao_ir/article/details/132089650 Bootstrap经编译(压缩)后的源码百度网盘下载地址: https://pan.baidu.com/s/14BM9gpC3K-LKxhyLGh4J9Q?pwdm02m Bootstrap未经编译…...
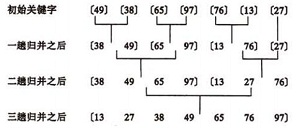
【排序算法】python之冒泡,选择,插入,快速,归并
参考资料: 《Python实现5大排序算法》《六大排序算法:插入排序、希尔排序、选择排序、冒泡排序、堆排序、快速排序》 --代码似乎是C语言 ———————— 本文介绍5种常见的排序算法和基于Python实现: 冒泡排序(Bubble Sort&am…...

UML—用例图的那些事
目录 背景: 1.用例图的发展史 过程: 1.用例图中的元素和关系 2.应用中的例子 总结: 背景: 1.用例图的发展史 用例图是一种常用的软件工程工具,用于描述系统的功能需求和用户与系统的交互。它在软件开发过程中起到了重要的作用,并且经历了…...
)
迷宫出口问题求解(DFS)
题面 一天Extense在森林里探险的时候不小心走入了一个迷宫,迷宫可以看成是由 nn 的格点组成,每个格点只有 22 种状态, 00 和 11,前者表示可以通行后者表示不能通行。 同时当Extense处在某个格点时,他只能移动到东南西北…...

基础算法模板
数据结构 单链表的插入删除 const int N=1e6+10; int head,e[N],ne[N],idx; //head 存储头节点的下标 //idx 存储当前已经用到的那个点 void init() {head=-1;idx=0; } void add_to_head(int x)//插入头节点操作 {e[idx]=x;ne[idx]=head;head=idx;idx++; } void add(int k)/…...

react Ref 的基本使用
类组件中使用ref 在类组件中,你可以使用createRef来创建一个ref,并将它附加到DOM元素或类组件实例上。使用ref允许你在类组件中访问和操作特定的DOM元素或类组件实例。 下面是在类组件中使用ref的步骤: 引入React和createRef: …...

四旋翼变形控制:RL与MPC在混合动力学中的对比
1. 四旋翼变形控制的技术挑战与解决方案四旋翼变形控制(Quadrotor Morpho-Transition)是当前机器人领域最具挑战性的前沿技术之一。这项技术使机器人能够在空中完成形态变换,实现从飞行模式到地面模式的平滑切换。想象一下,一架四…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

Burp Suite拦截与替换机制深度解析:从协议层到规则链
1. 这不是“点开就能用”的功能,而是你和目标系统之间的一道可编程闸门很多人第一次在Burp Suite里点开Proxy → Intercept,看到HTTP请求被拦下来,兴奋地改个User-Agent、删个Cookie就点Forward,以为自己已经掌握了“拦截与替换”…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...

HoRain云--CLAUDE.md 使用指南
🎬 HoRain云小助手:个人主页 🔥 个人专栏: 《Linux 系列教程》《c语言教程》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...

UE5 Cesium项目里,如何把默认的飞行Pawn换成建筑漫游Pawn?保姆级迁移教程
UE5 Cesium项目建筑漫游Pawn迁移实战:从飞行模式到精细化浏览的完整指南当你在UE5中结合Cesium插件构建数字孪生场景时,DynamicPawn提供的全球飞行体验令人印象深刻。但当视角聚焦到单体建筑或室内空间时,那种仿佛操控无人机般的操作方式就显…...

D2DX如何让暗黑破坏神2在4K显示器上流畅运行:5个关键技术解析
D2DX如何让暗黑破坏神2在4K显示器上流畅运行:5个关键技术解析 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 当…...