django 优化方式
前言
对于网站和Web APP来说,相同的类型的产品,响应速度越好,那么用户量就越高。不可否认的是,响应速度是用户黏粘性最好的方式之一,但往往不知道如何下手解决,希望这篇文章可以给予你一些思路
对于网站和Web APP来说最影响网站性能的就是数据库查询了,因为,而查询返回的数据集非常大时还会占据很多内存。这里从django orm的角度来探索数据库查询的优化
一、依据减少缓存的角度优化:利用QuerySet惰性
网站和Web APP,对于数据的常规处理方式肯定是数据库存储查询,反复从数据库读写数据很耗时间和计算资源。也因此开发者们设计制作出了多个数据库连接方式,其中在Django框架中ORM(语法有哪些?)占很大比重。通过它可以使用filter, exclude, get等方法进行数据库查询,从数据库中查询出来的结果一般是一个集合,这个集合叫就做 QuerySet。QuerySet是惰性的!QuerySet自带缓存!
注:Object Relational Mapping,即对象关系映射,是在pymysq之上又进行了一层封装,对于数据的操作,我们无需再去编写原生sql,取代代之的是基于面向对象的思想去编写类、对象、调用相应的方法等,ORM会将其转换/映射成原生SQL然后交给pymysql执行
- 惰性即为当被执行(print、if、len)时才会进行数据库查询,这样做的目的是防止无效数据库操作。减少数据库交互
# 惰性查询:如果只是书写了orm语句,在后面根本没有用到该语句所查询出来的参数,那么orm会自动识别出来,直接不执行。# 举例:res = models.Book.objects.all() # 这时orm是不会走数据库的print(res) # 只有当要用到的上述orm语句的结果时,才回去数据库查询。- QuerySet被执行后,其查询结果会载入内存并保存在QuerySet内置的cache中。再次使用就不需要重新去查询了。减少缓存
- 如果查出的 QuerySet只用一次,可以使用 iterator() 去来防止占用太多的内存
- if与exists()都可以判断查询结果是否存在,但两者使用却又很大的不相同。if会触发整个queryset的缓存,而exists()只会返回True或False检视查询结果是否存在而不会缓存查询结果
- len()与count()方法均能统计查询结果数量。count()是从数据库层面直接获取查询结果数量而不需要返回整个queryset数据集一般来说会更快。len()会导致queryset的执行,需要先将整个数据集载入内存方可计算,但如果queryset数据集已经缓存在内存当中了len()则会更快
- 当查询到的queryset非常大时,会占用大量的内存,使用values和values_list按需提取数据(1个或个别多字段,而非全字段)。values和values_list返回的是字典形式字符串数据,而不是对象集合
- only(A)包含与,查A走一次数据库,查B走多次数据库。defer(A)不包含与,查A走多次数据库,查B走一次数据库
- 相比于使用save()方法,update()不需要先缓存整个queryset
- aggregate和annotate方法主要用于组合查询,我们使用aggregate完成对查询集(queryset)的某些字段进行计算,使用annotate进行分组并追加统计字段,如
class Student(models.Model):name = models.CharField(max_length=20)age = models.IntegerField()hobbies = models.ManyToManyField(Hobby)class Hobby(models.Model):name = models.CharField(max_length=20)from django.db.models import Max, Min, Avg, Sum, Count
#####################aggregate应用###############################
# 学生平均年龄, 自定义key
Student.objects.aggregate(average_age = Avg('age')) # { 'average_age': 12 }# 同时获取学生年龄均值, 最大值和最小值, 返回字典
Student.objects.aggregate(Avg('age‘), Max('age‘), Min('age‘))
# { 'age__avg': 12, 'age__max': 18, 'age__min': 6, }# 根据Hobby反查学生最大年龄。查询字段student和age间有双下划线
Hobby.objects.aggregate(Max('student__age')) # { 'student__age__max': 12 }#####################annotate应用###############################
# 按学生分组,统计每个学生爱好数量,并自定义key
Student.objects.annotate(hobby_count_by_student=Count('hobbies'))# 按爱好分组,再统计每组学生最大年龄
Hobby.objects.annotate(Max('student__age'))#####################annotate&filter应用###############################
# 先按爱好分组,再统计每组学生数量, 然后筛选出学生数量大于1的爱好。
Hobby.objects.annotate(student_num=Count('student')).filter(student_num__gt=1)# 先按爱好分组,筛选出以'd'开头的爱好,再统计每组学生数量。
Hobby.objects.filter(name__startswith="d").annotate(student_num=Count('student‘))#####################annotate&order_by应用###############################
# 先按爱好分组,再统计每组学生数量, 然后按每组学生数量大小对爱好排序。
Hobby.objects.annotate(student_num=Count('student‘)).order_by('student_num')# 统计最受学生欢迎的5个爱好。
Hobby.objects.annotate(student_num=Count('student‘)).order_by('-student_num')[:5]#####################annotate&values应用###############################
# 按学生名字分组,统计每个学生的爱好数量。
Student.objects.values('name').annotate(Count('hobbies'))你还可以使用values方法从annotate返回的数据集里提取你所需要的字段,如下所示:
# 按学生名字分组,统计每个学生的爱好数量。
Student.objects.annotate(hobby_count=Count('hobbies')).values('name', 'hobby_count')
- select_related&prefetch_related使用
假设现在有文章表(Article)、类别表(Category)、标签表(Tag)。它们关系是文章与类别是一对多关系,文章与标签是多对多关系
- 常规写法,错倒是没错。然而使用Article.objects.all()查询得到的只是Article表的数据,并没有包含Category表和Tag表的数据。因此每一次打印article.category.name和tag.name都会重新去查询一遍Category表和Tag表,造成了很大不必要的浪费
# 查询类别、标签信息
articles = Article.objects.all()
for article in articles:print(article.title)print(article.category.name)for tag in article.tags.all():print(tag.name)
- 标准写法,select_related可查询一对多、一对一的关系,不可以多对多关系。处理的方式是inner join连表。实现打印类别是无需再去查数据库,因为数据已经一次性获取出来了
# 查询类别
articles = Article.objects.all().select_related('category')# 获取id=13的文章对象同时,获取其相关category信息
Article.objects.select_related('category').get(id=13)# 获取id=13的文章对象同时,获取其相关作者名字信息
Article.objects.select_related('author__name').get(id=13)# 获取id=13的文章对象同时,获取其相关category和相关作者名字信息。下面方法等同
Article.objects.select_related('category', 'author__name').get(id=13)
Article.objects.select_related('category').select_related('author__name').get(id=13)# 使用select_related()可返回所有相关主键信息,all()非必需
Article.objects.all().select_related()# 获取Article信息同时获取blog信息,filter方法和selected_related方法顺序不重要
Article.objects.filter(pub_date__gt=timezone.now()).select_related('blog')
Article.objects.select_related('blog').filter(pub_date__gt=timezone.now())
- 标准写法,prefetch_related弥补多对多下的数据查询
# 查询类别及标签
articles = Article.objects.all().select_related('category').prefecth_related('tags')# 文章列表及每篇文章的tags对象名字信息
Article.objects.all().prefetch_related('tags__name')# 获取id=13的文章对象同时,获取其相关tags信息
Article.objects.prefetch_related('tags').get(id=13)用Prefetch方法可以给prefetch_related方法额外添加额外条件和属性
# 获取文章列表及每篇文章相关的名字以P开头的tags对象信息
Article.objects.all().prefetch_related(Prefetch('tags', queryset=Tag.objects.filter(name__startswith="P"))
)# 文章列表及每篇文章的名字以P开头的tags对象信息, 放在article_p_tag列表
Article.objects.all().prefetch_related(Prefetch('tags', queryset=Tag.objects.filter(name__startswith="P")), to_attr='article_p_tag'
)
- F函数不引入内存
- 更新数据时
例1
article = Article.objects.get(title='文章2')
article.thumb_count += 1
article.save()例2 使用F()函数
Article.objects.filter(title='文章1').update(thumb_count=F('thumb_count')+1)# 很明显使用F()函数的执行效率会更高,只需要一条sql完全的数据库操作,而例1则需要先查询,缓存,然后再更新
# 例1的方法是存在竞态条件的,如第一个线程完成取值、更新值、保存新值,而第二个线程操作还是使用就的值来进行操作,使用F()函数的话,因为是数据库层面的原子操作,第二个线程再来取值那也是取到更新后的值了
- 表达式应用时
# 同一数据不同字段比较
article = Article.objects.filter(thumb_count__gt=F('view_count'))# 两个操作数都是常数和F()函数的加、减、乘、除、取模、幂计算等算术操作
article = Article.objects.filter(view_count__gt=F('thumb_count') * 2)# 配合annotate使用
article = Article.objects.annotate(all_count=F('view_count') + F('thumb_count'))
二、利用索引
合适的索引可以加快数据的检索速度。无论是在Django还是在原生SQL查询上都支持检查某条语句是否有用到索引,语法为explain
2.1、Django中
Blog.objects.filter(title='My Blog').explain(verbose=True)
2.2、原生SQL中
explain select * from user where user_no ='00022139'
三、ORM相较于原生SQL语法有性能欠缺
注:Django也支持原生SQL语法:raw
结束!
相关文章:

django 优化方式
前言 对于网站和Web APP来说,相同的类型的产品,响应速度越好,那么用户量就越高。不可否认的是,响应速度是用户黏粘性最好的方式之一,但往往不知道如何下手解决,希望这篇文章可以给予你一些思路 对于网站和…...
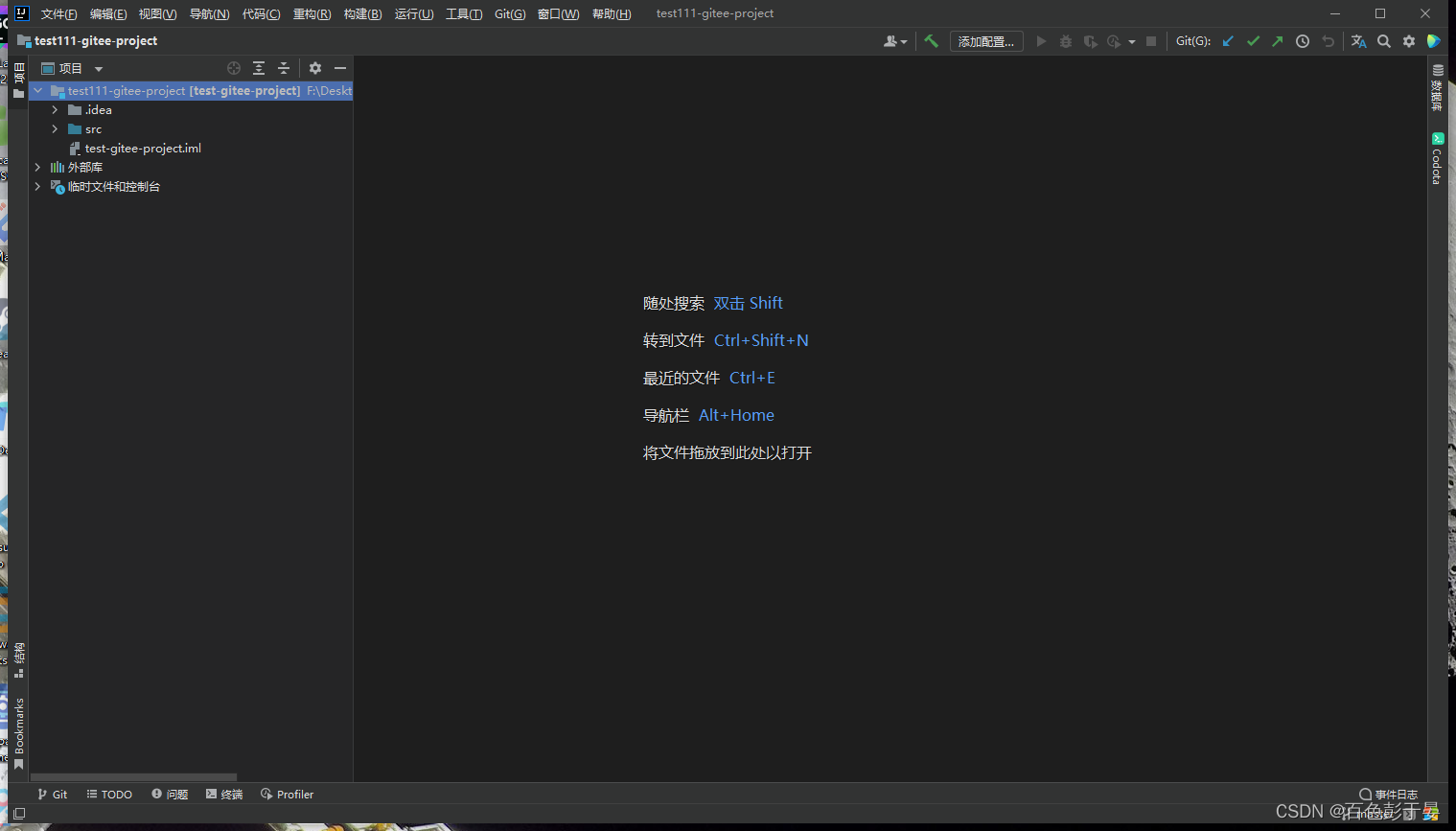
IDEA中怎么使用git下载项目到本地,通过URL克隆项目(giteegithub)
点击 新建>来自版本控制的项目 点击后会弹出这样一个窗口 通过URL拉取项目代码 打开你要下载的项目仓库 克隆>复制 gitee github也是一样的 返回IDEA 将刚刚复制的URL粘贴进去选择合适的位置点击克隆 下载完成...

09. Docker Compose
目录 1、前言 2、安装Docker Compose 2.1、Docker Compose版本 2.2、下载安装 3、初试Docker Compose 3.1、传统方案部署应用 3.2、使用编排部署应用 3.3、其他命令 3.3.1、ps 3.3.2、images 3.3.3、depends_on 3.3.4、scale 4、小结 1、前言 随着应用架构的不段…...

如何在shell脚本将node_modules里的文件复制一份到public文件里
项目背景:由于公司网络不连接公网,所以在绘制地图大屏项目时,需要我们将边界线数据包也部署起来,来获取边界线数据 解决方案: 1.让后端写个接口或者找个地方将数据包放到服务器即可 2.将数据包放到vue项目的public文…...

监控Redis的关键指标
Redis 也是一个对外服务,所以 Google 的四个黄金指标同样适用于 Redis。 1、延迟 在软件工程架构中,之所以选择 Redis 作为技术堆栈的一员,大概率是想要得到更快的响应速度和更高的吞吐量,所以延迟数据对使用 Redis 的应用程序至…...

Openlayers和leaflet如何选用?
在地图处理这块,Openlayers和Leaflet是非常有名的两个开源的JS框架,他们各有各的优势和劣势,对于刚刚步入此行业的开发者而言怎么选择框架呢? 作者做过一定的探索,在这里将成果分享给大家。 Openlayers 简介 Openlayers是一个基于Javacript开发,免费、开源的前端地图开…...

跟我学C++中级篇——三五法则
一、三五法则 三五法则,这个叫着有点上头,说实话,这个三五法则,未来会不会变成三六或者四七法则,没人知道,反正现在是三五法则。在《cPrimer》第四版中,叫三法则,在第五版第13.1.4章…...
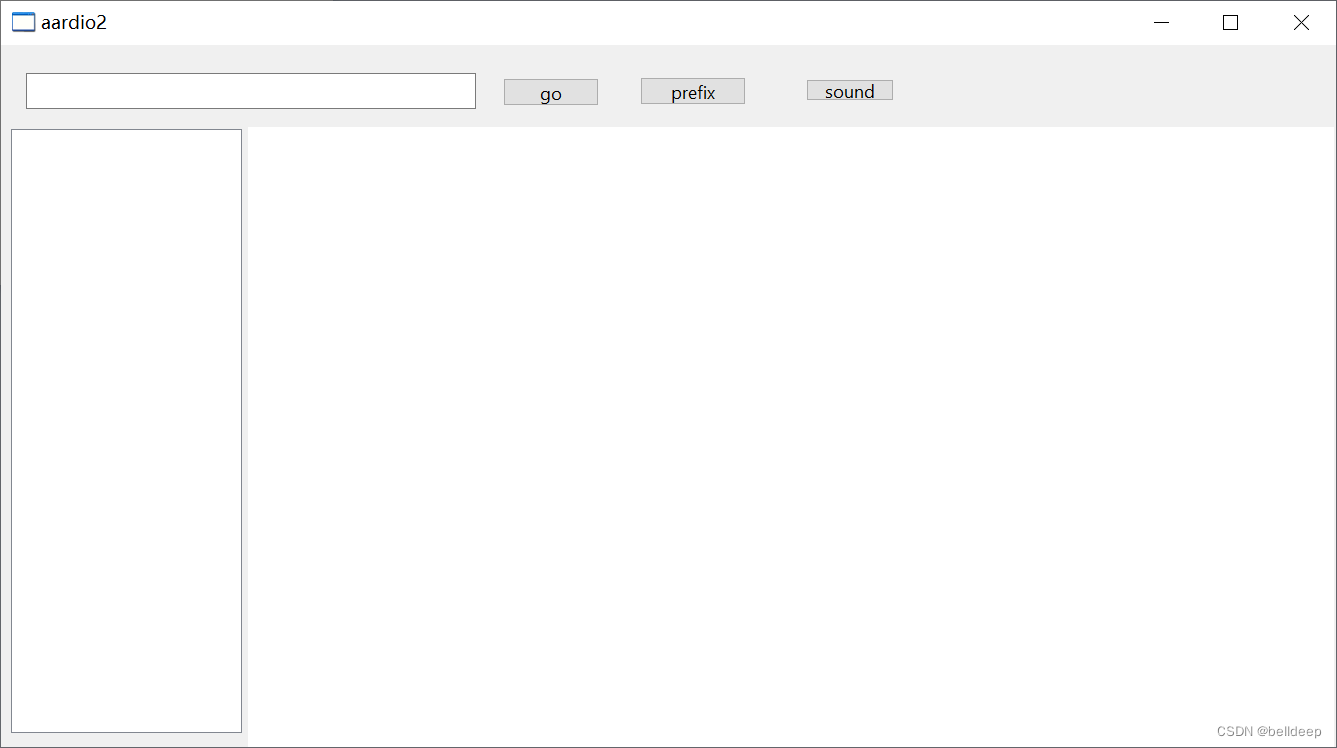
aardio:用 WebView 模仿 mdict 界面
aardio:用 WebView 模仿 mdict 界面 import win.ui; /*DSG{{*/ mainForm win.form(text"aardio2";right889;bottom467) mainForm.add( button{cls"button";text"go";left335;top22;right399;bottom41;z2}; button2{cls"button…...

linq中的操作符
LINQ(Language Integrated Query)是一种用于.NET平台的查询语言,用于查询和操作各种数据源,如集合、数据库和XML。LINQ提供了一组标准查询操作符,用于执行各种查询操作。 LINQ(Language Integrated Query&…...
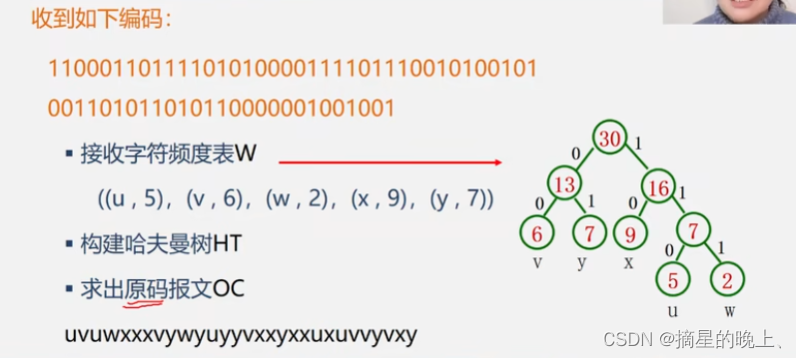
数据结构【哈夫曼树】
哈夫曼树 哈夫曼树的概念哈夫曼树的构造构造算法的实现哈夫曼树应用哈夫曼编码哈夫曼编码的算法实现 哈夫曼树的概念 最优二叉树也称哈夫曼 (Huffman) 树,是指对于一组带有确定权值的叶子结点,构造的具有最小带权路径长度的二叉树。权值是指一个与特定结…...
SpringMVC基于SpringBoot的最基础框架搭建——包含数据库连接
SpringMVC基于SpringBoot的最基础框架搭建——包含数据库连接 背景目标依赖配置文件如下项目结构如下相关配置如下启动代码如下Controller如下启动成功接口调用成功 背景 工作做了一段时间,回忆起之前有个公司有线下笔试,要求考生做一个什么功能&#x…...

deepspeed zero3
zero3。它是纵向切分权重(intra-layer,每一层的权重切成n块)。但是这样会增加通讯时间。你可以根据自己的模型,估算下切分后的通讯量和通讯时间。其次,pipeline并行一般指横向切分权重(inter-layer…...
代驾小程序怎么做
代驾小程序是一款专门为用户提供代驾服务的手机应用程序。它具有以下功能: 1. 预约代驾:代驾小程序允许用户在需要代驾服务时提前进行预约。用户可以选择出发地点、目的地以及预计用车时间,系统会自动匹配最合适的代驾司机,并确保…...

探索 AJAX 技术:实现动态数据交互的前端利器
简介: AJAX(Asynchronous JavaScript and XML)技术在 Web 前端开发中扮演着重要的角色,它通过异步通信和动态内容更新,为用户带来更好的交互体验。本篇笔记将详细探索 AJAX 技术,并通过生动的代码演示来展示…...
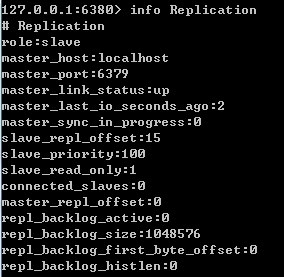
深度学习Redis(3):主从复制
前言 在前面的两篇文章中,分别介绍Redis内存模型和Redis持久化 在Redis的持久化中曾提到,Redis高可用的方案包括持久化、主从复制(及读写分离)、哨兵和集群。其中持久化侧重解决的是Redis数据的单机备份问题(从内存到…...

php笔记1
php环境 PHP作为一种服务器端脚本语言,可以在各种操作系统上运行。搭建PHP网站的环境,你需要以下几个要素: Web服务器:常见的选择有Apache、Nginx和IIS。你需要安装和配置其中一个服务器软件。PHP解释器:PHP是一种解…...

2023 ChinaJoy 圆满闭幕,FairGuard游戏加固亮相 BTOB 展区
提振行业 产业复苏 2023年7月28日至7月31日,第二十届中国国际数码互动娱乐展览会( ChinaJoy)于上海新国际博览中心圆满举办。本届ChinaJoy作为疫情结束后的第一个国际性数字娱乐领域的重要产业盛会,对于提振行业信心、加快产业复苏、增进国际间的交流与…...
数据规约策略
有很多概念平时一直在说,但是具体的应用场景却一直不明确,这会导致我们在实际应用过程中对应该使用的方法不够明确,在此对常用的几种数据挖掘方法使用场景进行分类和整合。 数据降维 为什么要降维 数据稀疏,维度高高维数据采用…...

服务器带宽独享跟共享有什么区别103.36.166.x
独享带宽 独享带宽针对对带宽有较高的要求,其业务的内容和性质决定只有使用独立的带宽资源才能满足品质的需求,而这种只给单独客户使用的带宽资源称为独享带宽. 使用独享带宽,整个带宽资源归属于一个客户 独享带宽的优点是可自由使用带宽量…...

【cluster_block_exception】写操作elasticsearch索引报错
【cluster_block_exception】操作elasticsearch索引b报错 背景导致原因:解决方法: 背景 今天线上elk的数据太多,服务器的空间不足了。所以打算删除一些没用用的数据。我是用下面的request: POST /{index_name}/_delete_by_query…...

AI Agent在智能风控中的实战:多智能体欺诈检测与预警
AI Agent在智能风控中的实战:多智能体欺诈检测与预警 你有没有过明明是正常交易却被银行冻结账户的糟糕体验?或是听说过某电商平台上线新活动首日就被黑产团伙薅走数千万补贴的新闻?随着黑产欺诈向团伙化、专业化、动态化演进,传统依赖规则引擎、单模型机器学习的风控体系已…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

第3篇:系统透视——信息部门如何构建“税务友好型”IT架构
本篇导读:如果你是信息总监或IT负责人,请通读全文,尤其是“系统合规设计的三必须”和“现场检查SOP”;如果你是财税人员,请重点阅读“研产供销全链条的系统对接要求”和“与IT部门的协作要点”;如果你是老板…...

rk35xx 通过recovery升级问题
Firefly 的 recovery 库是一个核心组件,它构建了一个独立的微型 Linux 系统,专门用于在设备主系统之外执行高可靠性的固件升级。简单来说,它的工作流程是:主系统通过命令触发,将升级指令写入特定分区并重启;…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...

武汉国电华美串联谐振试验装置,现场用着心里有底
在高压试验现场干了这么多年,这位老师傅常说,一台好的串联谐振装置,就是试验人员的胆。面对GIS、大型变压器、超高压电缆这些大电容试品,没有趁手的谐振设备,交流耐压试验根本没法干。16875kVA/225kV这个规格ÿ…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...

JWT弱密钥爆破实战:从HS256签名原理到CTF权限提升
1. 这不是密码学考试,而是一场“密钥猜谜”实战JWT(JSON Web Token)在现代Web系统中早已不是可选项,而是默认配置。登录成功后返回一串形如eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjMsIm5hbWUiOiLnlKjliYkiLCJpYX…...

【大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型?】
大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型? 随着大模型技术的快速发展,越来越多的企业开始将 AI 能力融入到业务流程中。然而,面对市场上众多的大模型产品,企业往往面临着 “选择困难…...
)
嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(3)
接前一篇文章:嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(2) 节点查找 API:如何在设备树中定位目标节点 有了数据结构基础,现在我们可以开始讲具体的API了。第一步是找到你要操作的节点。就像你想操…...