Python3 高级教程 | Python3 正则表达式(一)
目录
一、Python3 正则表达式
(一)re.match函数
(二)re.search方法
(三)re.match与re.search的区别
二、检索和替换
(一)repl 参数是一个函数
(二)compile 函数
(三)findall
(四)re.finditer
(五)re.split
三、正则表达式对象
re.RegexObject
re.MatchObject
四、正则表达式修饰符 - 可选标志
五、正则表达式模式
六、正则表达式实例
(一)字符匹配
(二)字符类
(三)特殊字符类
一、Python3 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
(一)re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例
#!/usr/bin/python
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
以上实例运行输出结果为:
(0, 3) None
实例
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs"
# .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符
# (.*?) 表示"非贪婪"模式,只保存第一个匹配到的子串
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")
以上实例执行结果如下:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
(二)re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例
#!/usr/bin/python3
import re
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配
以上实例运行输出结果为:
(0, 3) (11, 14)
实例
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs"
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print ("searchObj.group() : ", searchObj.group())
print ("searchObj.group(1) : ", searchObj.group(1))
print ("searchObj.group(2) : ", searchObj.group(2))
else:
print ("Nothing found!!")
以上实例执行结果如下:
searchObj.group() : Cats are smarter than dogs searchObj.group(1) : Cats searchObj.group(2) : smarter
(三)re.match与re.search的区别
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
实例
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
matchObj = re.search( r'dogs', line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
以上实例运行结果如下:
No match!! search --> matchObj.group() : dogs
二、检索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 编译时用的匹配模式,数字形式。
前三个为必选参数,后两个为可选参数。
实例
#!/usr/bin/python3
import re
phone = "2004-959-559 # 这是一个电话号码"
# 删除注释
num = re.sub(r'#.*$', "", phone)
print ("电话号码 : ", num)
# 移除非数字的内容
num = re.sub(r'\D', "", phone)
print ("电话号码 : ", num)
以上实例执行结果如下:
电话号码 : 2004-959-559
电话号码 : 2004959559
(一)repl 参数是一个函数
以下实例中将字符串中的匹配的数字乘以 2:
实例:
#!/usr/bin/python
import re
# 将匹配的数字乘以 2
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s))
执行输出结果为:
A46G8HFD1134
(二)compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:
re.compile(pattern[, flags])
参数:
- pattern : 一个字符串形式的正则表达式
- flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
-
- re.I 忽略大小写
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M 多行模式
- re.S 即为' . '并且包括换行符在内的任意字符(' . '不包括换行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和' # '后面的注释
实例
>>>import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print( m ) # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
在上面,当匹配成功时返回一个 Match 对象,其中:
group([group1, …])方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用group()或group(0);start([group])方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;end([group])方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;span([group])方法返回(start(group), end(group))。
再看看一个例子:
>>>import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web')
>>> print( m ) # 匹配成功,返回一个 Match 对象
<_sre.SRE_Match object at 0x10bea83e8>
>>> m.group(0) # 返回匹配成功的整个子串
'Hello World'
>>> m.span(0) # 返回匹配成功的整个子串的索引
(0, 11)
>>> m.group(1) # 返回第一个分组匹配成功的子串
'Hello'
>>> m.span(1) # 返回第一个分组匹配成功的子串的索引
(0, 5)
>>> m.group(2) # 返回第二个分组匹配成功的子串
'World'
>>> m.span(2) # 返回第二个分组匹配成功的子串索引
(6, 11)
>>> m.groups() # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World')
>>> m.group(3) # 不存在第三个分组
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
(三)findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
语法格式为:
re.findall(pattern, string, flags=0)
或
pattern.findall(string[, pos[, endpos]])
参数:
- pattern 匹配模式。
- string 待匹配的字符串。
- pos 可选参数,指定字符串的起始位置,默认为 0。
- endpos 可选参数,指定字符串的结束位置,默认为字符串的长度。
查找字符串中的所有数字:
实例
import re
result1 = re.findall(r'\d+','runoob 123 google 456')
pattern = re.compile(r'\d+') # 查找数字
result2 = pattern.findall('runoob 123 google 456')
result3 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)
print(result3)
输出结果:
['123', '456']
['123', '456']
['88', '12']
多个匹配模式,返回元组列表:
实例
import re
result = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10')
print(result)
[('width', '20'), ('height', '10')]
(四)re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags=0)
参数:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
实例
import re
it = re.finditer(r"\d+","12a32bc43jf3")
for match in it:
print (match.group() )
输出结果:
12
32
43
3
(五)re.split
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
re.split(pattern, string[, maxsplit=0, flags=0])
参数:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| maxsplit | 分割次数,maxsplit=1 分割一次,默认为 0,不限制次数。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
实例
>>>import re
>>> re.split('\W+', 'runoob, runoob, runoob.')
['runoob', 'runoob', 'runoob', '']
>>> re.split('(\W+)', ' runoob, runoob, runoob.')
['', ' ', 'runoob', ', ', 'runoob', ', ', 'runoob', '.', '']
>>> re.split('\W+', ' runoob, runoob, runoob.', 1)
['', 'runoob, runoob, runoob.']
>>> re.split('a*', 'hello world') # 对于一个找不到匹配的字符串而言,split 不会对其作出分割
['hello world']
三、正则表达式对象
re.RegexObject
re.compile() 返回 RegexObject 对象。
re.MatchObject
group() 返回被 RE 匹配的字符串。
- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
四、正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
五、正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式。
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'\t',等价于 \\t )匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 匹配n个前面表达式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 |
| re{ n,} | 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | 匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功。 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配数字字母下划线 |
| \W | 匹配非数字字母下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]。 |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等。 | 匹配一个换行符。匹配一个制表符, 等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
六、正则表达式实例
(一)字符匹配
| 实例 | 描述 |
|---|---|
| python | 匹配 "python". |
(二)字符类
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
(三)特殊字符类
| 实例 | 描述 |
|---|---|
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
相关文章:
)
Python3 高级教程 | Python3 正则表达式(一)
目录 一、Python3 正则表达式 (一)re.match函数 (二)re.search方法 (三)re.match与re.search的区别 二、检索和替换 (一)repl 参数是一个函数 (二)comp…...

奥威BI系统:零编程建模、开发报表,提升决策速度
奥威BI是一款非常实用的、易用、高效的商业智能工具,可以帮助企业快速获取数据、分析数据、展示数据。值得特别注意的一点是奥威BI系统支持零编程建模、开发报表,是一款人人都能用的大数据分析系统,有助于全面提升企业的数据分析挖掘效率&…...
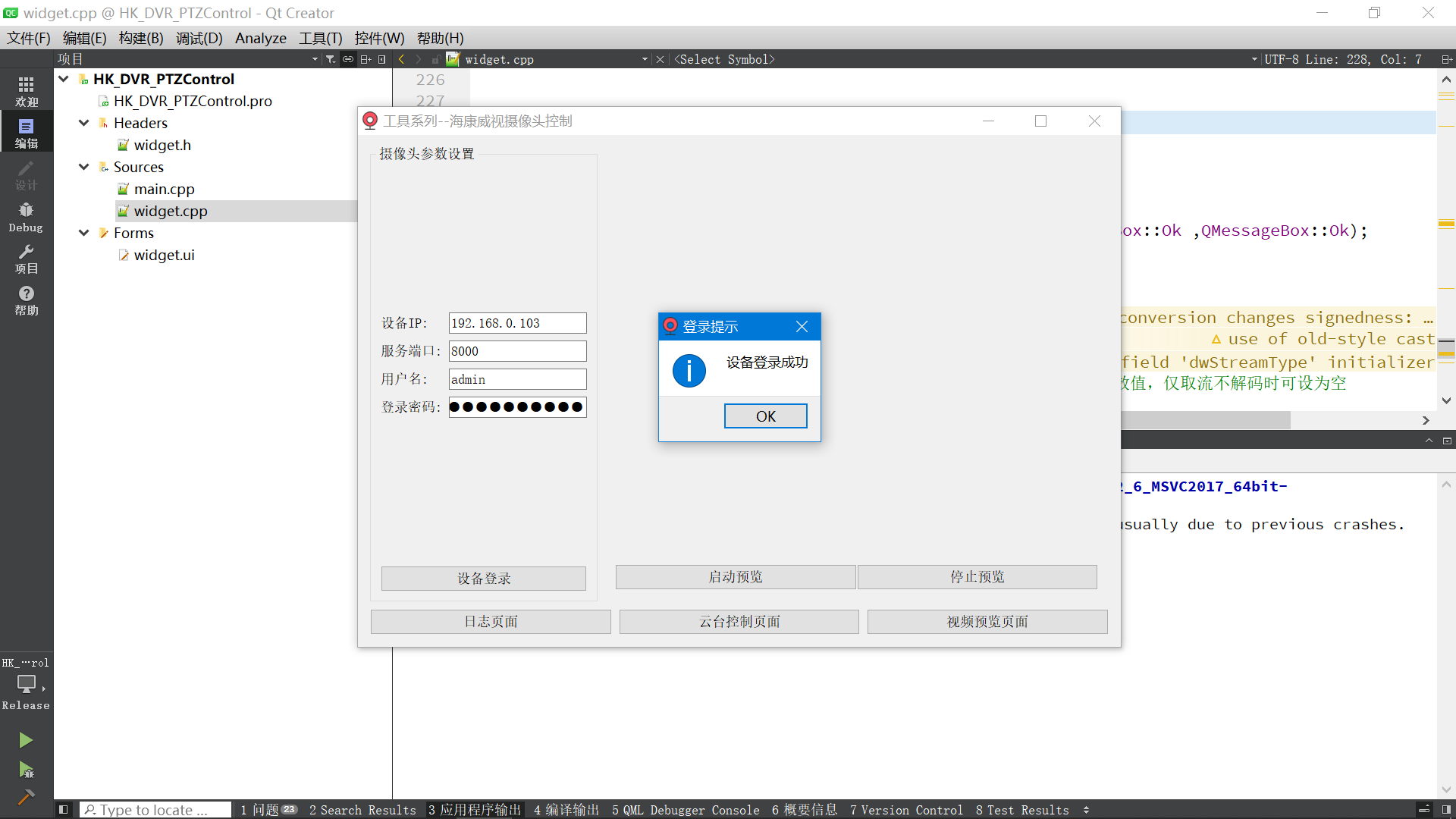
海康威视摄像头二次开发_云台控制_视频画面实时预览(基于Qt实现)
一、项目背景 需求:需要在公司的产品里集成海康威视摄像头的SDK,用于控制海康威视的摄像头。 拍照抓图、视频录制、云台控制、视频实时预览等等功能。 开发环境: windows-X64(系统) + Qt5.12.6(Qt版本) + MSVC2017_X64(使用的编译器) 海康威视提供了设备网络SDK,设备网…...
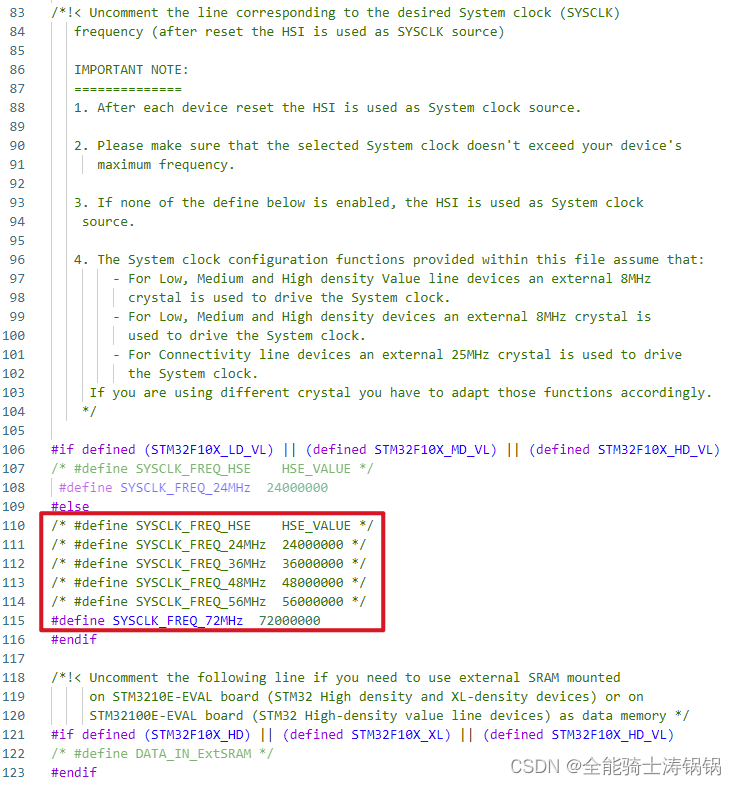
单片机外部晶振故障后自动切换内部晶振——以STM32为例
单片机外部晶振故障后自动切换内部晶振——以STM32为例 作者日期版本说明Dog Tao2023.08.02V1.0发布初始版本 文章目录 单片机外部晶振故障后自动切换内部晶振——以STM32为例背景外部晶振与内部振荡器STM32F103时钟系统STM32F407时钟系统 代码实现系统时钟设置流程时钟源检测…...
)
Matlab实现决策树算法(附上多个完整仿真源码)
决策树是一种常见的机器学习算法,它可以用于分类和回归问题。在本文中,我们将介绍如何使用Matlab实现决策树算法。 文章目录 1. 数据预处理2. 构建决策树模型3. 测试模型4. 可视化决策树5. 总结6. 完整仿真源码下载 1. 数据预处理 在使用决策树算法之前…...

java中异步socket类的实现和源代码
java中异步socket类的实现和源代码 我们知道,java中socket类一般操作都是同步进行,常常在read的时候socket就会阻塞直到有数据可读或socket连接断开的时候才返回,虽然可以设置超时返回,但是这样比较低效,需要做一个循环来不停扫描…...

ElasticSearch7.6入门学习笔记
在学习ElasticSearch之前,先简单了解一下Lucene: Doug Cutting开发 是apache软件基金会4 jakarta项目组的一个子项目 是一个开放源代码的全文检索引擎工具包不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的…...

《面试1v1》ElasticSearch架构设计
🍅 作者简介:王哥,CSDN2022博客总榜Top100🏆、博客专家💪 🍅 技术交流:定期更新Java硬核干货,不定期送书活动 🍅 王哥多年工作总结:Java学习路线总结…...

tomcat和nginx的日志记录请求时间
当系统卡顿时候,我们需要分析时间花费在哪个缓解。项目的后端接口可以记录一些时间,此外,在我们的tomcat容器和nginx网关上也可以记录一些有关请求用户,请求时间,响应时间的数据,可以提供更多的信息以便于排…...
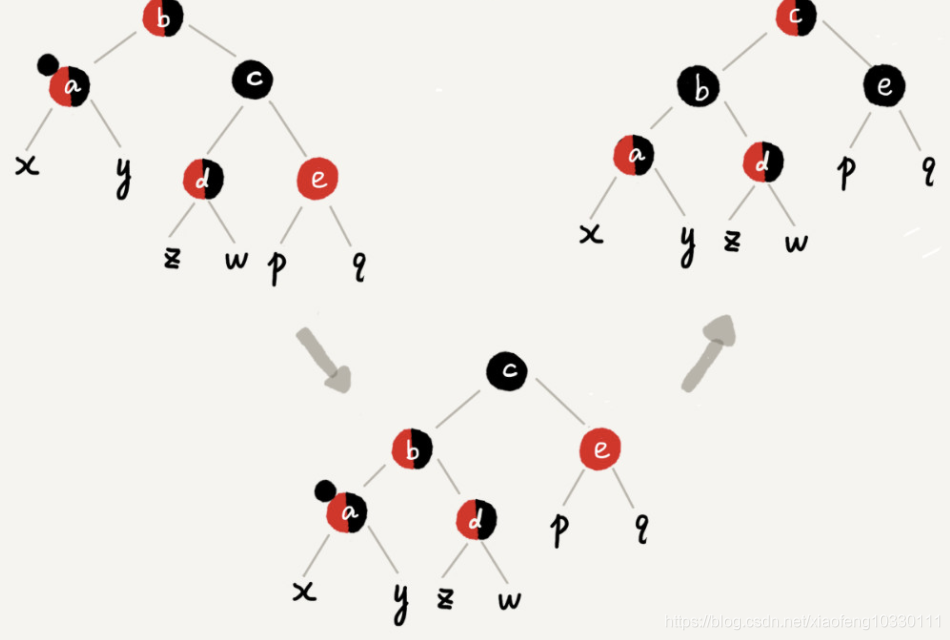
数据结构——红黑树基础(博文笔记)
数据结构在查找这一章里介绍过这些数据结构:BST,AVL,RBT,B和B。 除去RBT,其他的数据结构之前的学过,都是在BST的基础上进行微小的限制。 1.比如AVL是要求任意节点的左右子树深度之差绝对值不大于1,由此引出…...

盘点帮助中心系统可以帮到我们什么呢?
在线帮助中心系统是一种强大的软件系统,可以让我们用来组织、管理、发布、更新和维护企业的宝贵知识库和用户文档。今天looklook就详细讲讲,除了大众所熟知的这些,帮助中心系统还有什么特别作用呢? 帮助中心系统的作用 1.快速自助…...
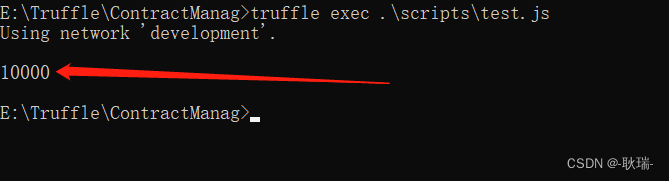
Web3 solidity编写交易所合约 编写ETH和自定义代币存入逻辑 并带着大家手动测试
上文 Web3 叙述交易所授权置换概念 编写transferFrom与approve函数我们写完一个简单授权交易所的逻辑 但是并没有测试 其实也不是我不想 主要是 交易所也没实例化 现在也测试不了 我们先运行 ganache 启动一个虚拟的区块链环境 先发布 在终端执行 truffle migrate如果你跟着我…...
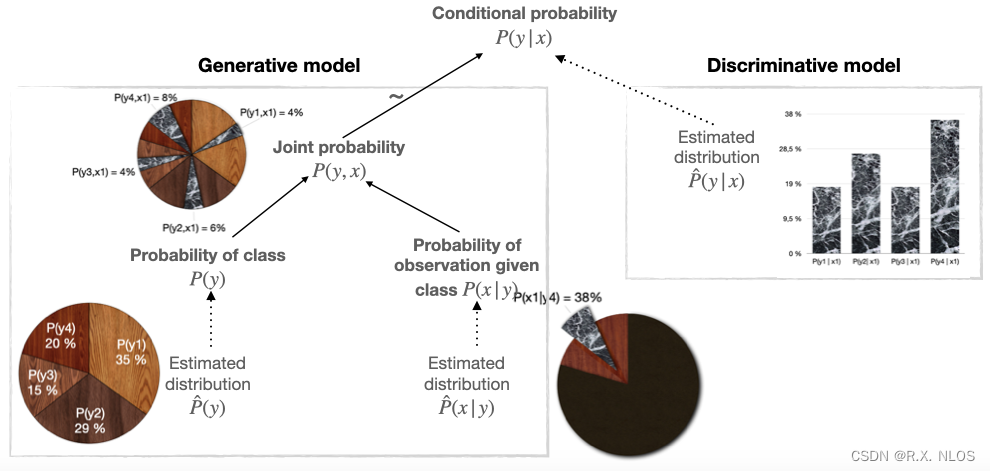
概念解析 | 生成式与判别式模型在低级图像恢复与点云重建中的角力:一场较量与可能性探索
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:生成式模型与判别式模型在低级图像恢复/点云重建任务中的优劣与特性。 生成式与判别式模型在低级图像恢复与点云重建中的角力:一场较量与可能性探索 1. 背景介绍 机器学习…...
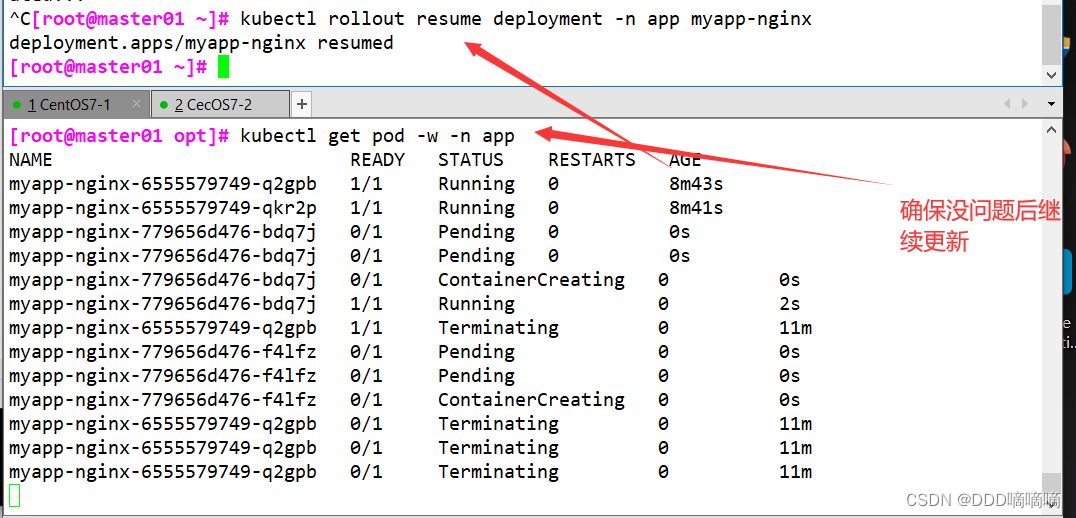
【云原生】kubectl命令的详解
目录 一、陈述式资源管理方式1.1基本查看命令查看版本信息查看资源对象简写查看集群信息配置kubectl自动补全node节点查看日志 1.3基本信息查看查看 master 节点状态查看命名空间查看default命名空间的所有资源创建命名空间app删除命名空间app在命名空间kube-public 创建副本控…...
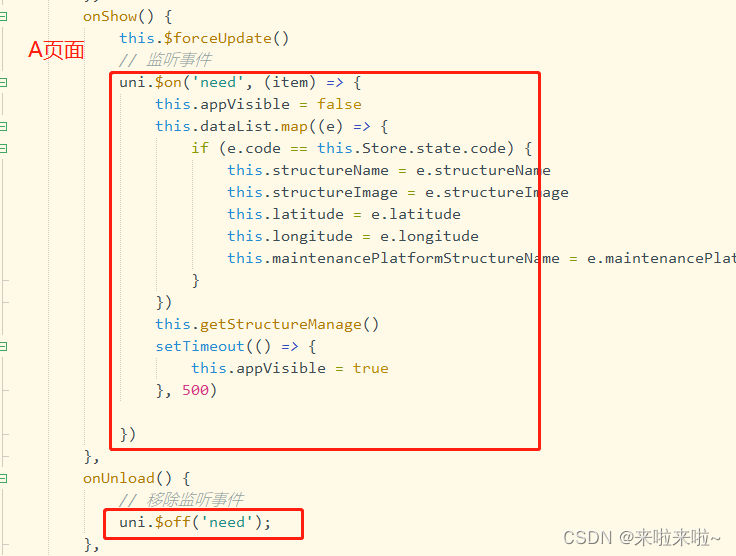
uniapp两个单页面之间进行传参
1.单页面传参:A --> B url: .....?code JSON.stringify(param), 2.单页面传参B–>Auni.$emit() uni.$on()...

uniapp运行项目到iOS基座
2022年9月,因收到苹果公司警告,目前开发者已无法在iOS真机设备使用未签名的标准基座,所以现在要运行到 IOS ,也需要进行签名。 Windows系统,HBuilderX 3.6.20以下版本,无法像MacOSX那样对标准基座进行签名…...
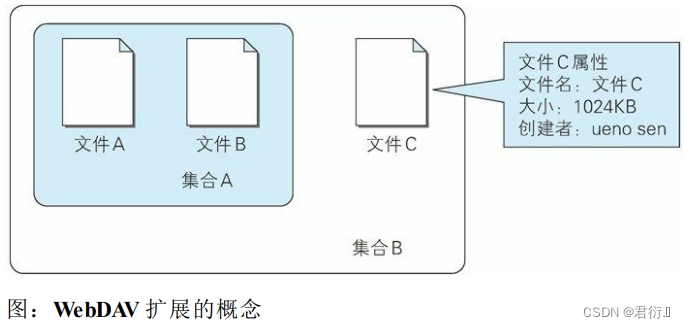
HTTP——九、基于HTTP的功能追加协议
HTTP 一、基于HTTP的协议二、消除HTTP瓶颈的SPDY1、HTTP的瓶颈Ajax 的解决方法Comet 的解决方法SPDY的目标 2、SPDY的设计与功能3、SPDY消除 Web 瓶颈了吗 三、使用浏览器进行全双工通信的WebSocket1、WebSocket 的设计与功能2、WebSocket协议 四、期盼已久的 HTTP/2.01、HTTP/…...

Redis 在电商秒杀场景中的应用
Redis 在电商秒杀场景中的应用 一、简介1.1 简介1.2 场景应用 二、Redis 优势与挑战2.1 优势2.2 秒杀场景的挑战 三、应用场景分析3.1 库存预热代码示例 3.2 分布式锁3.3 消息队列 四、系统设计方案4.1 架构设计4.2 技术选型4.3 数据结构设计 五、Redis 性能优化5.1 集群部署5.…...
大麦订单生成器 大麦一键生成订单
后台一键生成链接,独立后台管理 教程:修改数据库config/Conn.php 不会可以看源码里有教程 下载源码程序:https://pan.baidu.com/s/16lN3gvRIZm7pqhvVMYYecQ?pwd6zw3...
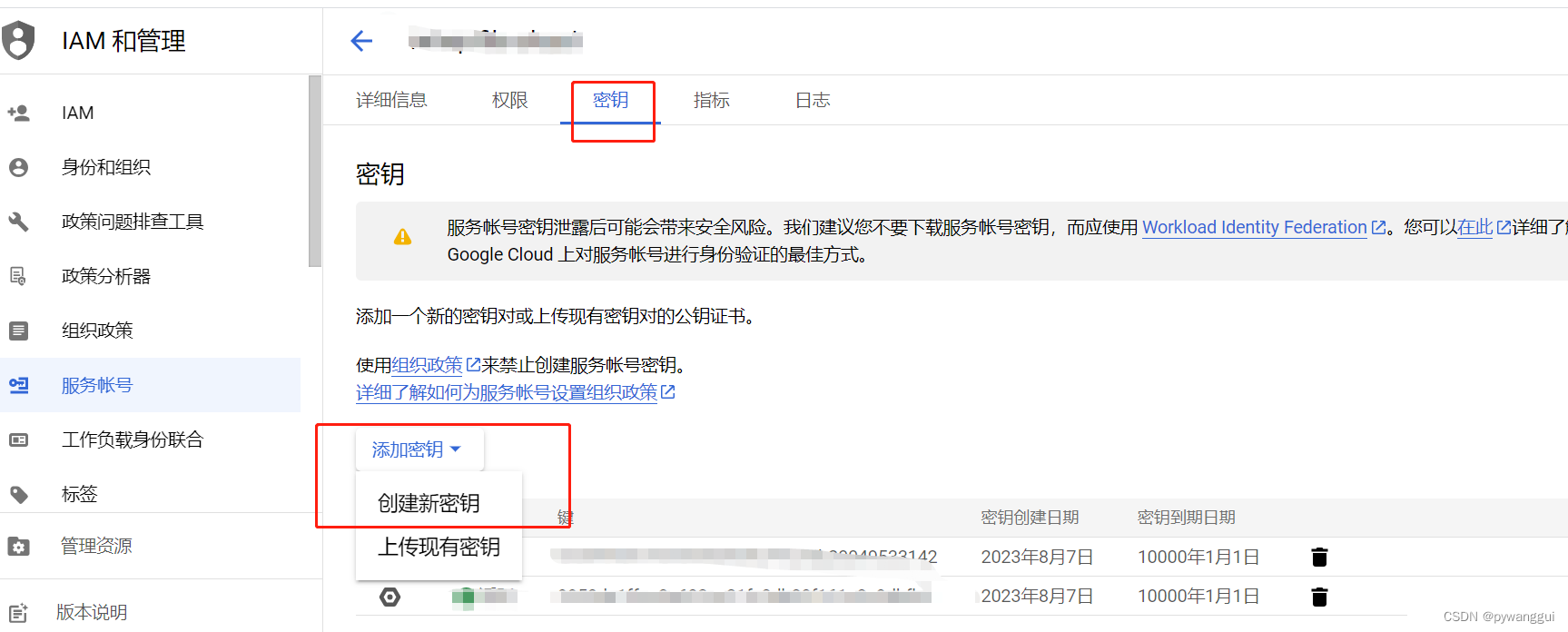
Java实现Google cloud storage 文件上传,Google oss
storage 控制台位置 创建一个bucket 点进bucket里面,权限配置里,公开访问,在互联网上公开,需要配置角色权限 新增一个访问权限 ,账号这里可以模糊搜索, 角色配置 给allUser配置俩角色就可以出现 在互联…...

[智能体-81]:工程化智能体 = 模型做脑力拆解 + 框架做流程落地。前者是决策者,后者是管理者,tools/function call是内部员工;mcp server是外部资源;
一、全角色人设 & 对应技术组件角色定位对应技术模块核心职责决策者(脑力大脑)大模型 LLM理解目标、任务拆解、逻辑判断、分支决策、内容生成,负责 “想方案、定步骤”管理者(流程总管)智能体编排框架(…...

0.2毫秒快速启动的操作系统
在工业控制以及航空航天等核心场景,极速启动就是高可靠系统的生命线。0.2毫秒超快启动搭配硬件看门狗,让设备在掉电重启、异常恢复时瞬时归位,关键任务永不延误! https://www.bilibili.com/video/BV11mLY6VERt/?spm_id_from333.1…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...
 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例)
招行+工行:ReAct(Reasoning + Acting) 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例
下面我把 ReAct(Reasoning Acting) 讲清楚,并结合 ** 金融场景(含自进化智能体)** 给出可直接用的案例与话术,适合分享 / 汇报。一、ReAct 是什么(一句话)ReAct 推理(T…...

Lovable电商网站搭建:如何用不到3人技术团队,72小时内上线PCI-DSS合规MVP版本?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署能力。本章将指导你从零开始搭建一个具备商品展示、…...

3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南
3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

你的差异基因结果可靠吗?用MetaVolcanoR给多个GEO数据集做一次‘交叉验证’吧
你的差异基因结果可靠吗?用MetaVolcanoR给多个GEO数据集做一次"交叉验证"当你在GEO数据库中下载了三个肺癌研究的差异表达结果,却发现三个DEG列表的重叠基因不到20%——这种令人沮丧的场景每天都在全球实验室上演。单项研究的差异分析结果就像…...

原来专业的赛事专用匹克球厂家有这么多门道?
引言在匹克球运动蓬勃发展的当下,专业赛事专用匹克球的选择至关重要。很多人可能不知道,看似普通的赛事专用匹克球背后,其实隐藏着诸多门道。接下来,我们就一起深入探究专业赛事专用匹克球厂家的秘密。核心技术与材料的门道专业赛…...

告别硬编码!在UE5 GAS中实现动态技能键位绑定:从DataAsset配置到运行时热更新的完整流程
告别硬编码!在UE5 GAS中实现动态技能键位绑定:从DataAsset配置到运行时热更新的完整流程在当代RPG游戏开发中,技能系统的灵活性和可配置性往往决定了项目的迭代效率。传统硬编码的键位绑定方式不仅增加了程序与策划的沟通成本,更在…...