Sqlserver_Oracle_Mysql_Postgresql不同关系型数据库之主从延迟的理解和实验
关系型数据库主从节点的延迟是否和隔离级别有关联,个人认为两者没有直接关系,主从延迟在关系型数据库中一般和这两个时间有关:事务日志从主节点传输到从节点的时间+事务日志在从节点的应用时间
事务日志从主节点传输到从节点的时间,相关因素有以下2点:
1、事务写入主节点日志文件的条件,有的数据库(oracle\sqlserver\postgresql)是事务一部分完成就会写入日志文件,有的数据库(mysql)是必须等事务完全完成才会写入日志文件
2、主从节点之间网络带宽、可用cpu\memory\disk资源
事务日志在从节点的应用时间,相关因素有以下2点:
1、从节点的可用cpu\memory\disk资源
2、事务日志在从节点的并发应用机制
问题:假设一个主库上的一个insert事务需要执行 10 分钟才能提交完成,那这个insert事务新增的数据行一定延迟 10 分钟才能到达从库,这个结论正确还是错误?
答案:经过实验验证,这句话的理解需要针对不同数据库来说,sqlserver、oracle、postgresql而言是错误的,mysql而言的话是对的,具体见本文最后的实践验证
oracle写online redo log条件
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/21/cncpt/process-architecture.html#GUID-B6BE2C31-1543-4504-9763-6FFBBF99DC85
1、事务提交
2、发生online redo log切换。
3、每隔三秒。
4、重做日志缓冲区已满三分之一或包含1 MB的缓冲数据。
5、在(Database Writer Process)DBW可以写入脏缓冲区之前,数据库必须将与缓冲区更改相关联的重做记录写入磁盘(预写协议)。如果DBW发现一些重做记录没有被写入,它会通知 LGWR 将记录写入磁盘,并等待LGWR完成后再将数据缓冲区写入磁盘。
sqlserver写日志条件
官方文档:https://learn.microsoft.com/en-us/sql/relational-databases/sql-server-transaction-log-architecture-and-management-guide?view=sql-server-2017
1、关联的脏页从缓冲区缓存中删除并写入磁盘之前,必须将这条些日志记录写入磁盘,比如checkpoint触发刷新页,刷新页之前必须得先把日志缓冲区的日志写入磁盘
2、事务提交
3、日志缓冲区已满
mysql写binlog条件
官方文档:https://dev.mysql.com/doc/refman/8.0/en/binary-log.html
事务提交了才会写入binlog,statement 格式的binlog,最后会有 COMMIT;而row格式的binlog,最后会有一个XID event;所以事务不能跨bin log,一个完整的事务的所有内容必须都写入一个bin log。
postgresql写wal log条件
官方文档:无,这是最让人吐槽的地方,postgresql的官方文档做得太单薄了,并且查看了postgresql进程walwriter的源码也没看到源码中有walwriter会在什么场景下被触发的内容
1、wal缓存写满时
2、在事务提交时
3、wal日志切换比如select pg_switch_wal()时
4、checkpoint刷新数据缓存到数据文件之前
备注:以上四种情况可以通过实验过程得出,这些条件满足时,会触发walwriter进程把wal缓存写入wal日志文件
Oracle
https://docs.oracle.com/en/database/oracle/oracle-database/21/sbydb/introduction-to-oracle-data-guard-concepts.html#GUID-D284E617-3F4F-4128-98F5-A3EB88772BF5
主从原理或逻辑理解:当Primary数据库触发日志写进程(LGWR)把事务写入日志文件online redo log同时触发LNSn process(Data Guard network server process)传输redo buffer到备库的RFS(remote file server)或当Primary数据库触发日志写进程(LGWR)把事务写入日志文件online redo log同时触发LNSn process传输online redo log到备库的RFS或当Primay数据库触发online redo log归档时同时触发ARC0传输主库的archive log到备库的RFS或当Primay数据库触发online redo log归档时同时触发备库的RFS通过fal_server参数主动去把主库的archive log传输到备库的RFS;备库再看有无standby redolog file,有的话,备库的RFS中的数据被写入备库standby redolog file再通过MRP(Media Recovery process)写入物理备库或通过LSP(Logical Standby Process)写入逻辑备库或通过ARC0(Archive process)写入备库的archive log,没有的话,备库的ARCn进程会等待主库切换日志时把备库的RFS中的数据一并归档到备库的archive log,再通过MRP写入物理备库或通过LSP写入逻辑备库。所有这些都是由一个核心参数LOG_ARCHIVE_DEST_n来控制,它定义Primary数据库redo数据传输到达的目的地standby地址和Primary数据库redo数据是否实时传输到standby
查询延迟,备库执行:select SEQUENCE#,applied,FIRST_TIME,NEXT_TIME from v$archived_log order by 1 desc
Sqlserver
https://learn.microsoft.com/en-us/sql/database-engine/availability-groups/windows/availability-modes-always-on-availability-groups?view=sql-server-2017
主从原理或逻辑理解:在异步提交模式下运行,则主副本不会等待任何辅助副本强制写入日志, 而会在将日志记录写入本地日志文件后,立即将事务确认发送到客户端。在同步提交模式下,事务将一直等到辅助副本已将日志强制写入到磁盘中才会向客户端发送事务确认。
查询延迟,主库执行:
select ar.replica_server_name, db_name(drs.database_id) dbname,
drs.log_send_queue_size,drs.log_send_rate, drs.redo_queue_size,drs.redo_rate,
drs.redo_queue_size/drs.redo_rate/60 redo_delay_minitues
from sys.dm_hadr_database_replica_states drs
join sys.availability_replicas ar on drs.replica_id=ar.replica_id where drs.is_local=0
Mysql
https://dev.mysql.com/doc/refman/8.0/en/replication-implementation.html
主从原理或逻辑理解:
在备库 B 上通过 change master 命令,设置主库 A 的 IP、端口、用户名、密码,以及要从哪个位置开始请求 binlog,这个位置包含文件名和日志偏移量。
在备库 B 上执行 start slave 命令,这时候备库会启动两个线程,就是io_thread(即备库执行show slave status时显示的Slave_IO_Running)和sql_thread(即备库执行show slave status时显示的Slave_SQL_Running)。其中 io_thread 负责与主库建立连接。
主库 A 校验完用户名、密码后,开始按照备库 B 传过来的位置,从本地读取 binlog,发给 B。
备库 B 拿到主库发送过来的 binlog 后,写到本地中转日志文件(relay log)。
sql_thread 读取中转日志,解析出日志里的命令,并执行。
查询延迟,备库执行:show slave status
“同步延迟”。与数据同步有关的时间点主要包括以下三个:主库 A 执行完成一个事务,写入 binlog,我们把这个时刻记为 T1;之后传给备库 B,我们把备库 B 接收完这个 binlog 的时刻记为 T2;备库 B 执行完成这个事务,我们把这个时刻记为 T3。所谓主备延迟,就是同一个事务,在备库执行完成的时间和主库执行完成的时间之间的差值,也就是 T3-T1。你可以在备库上执行 show slave status 命令,它的返回结果里面会显示 seconds_behind_master,用于表示当前备库延迟了多少秒。seconds_behind_master 的计算方法是这样的:每个事务的 binlog 里面都有一个时间字段,用于记录主库上写入的时间;备库取出当前正在执行的事务的时间字段的值,计算它与当前系统时间的差值,得到 seconds_behind_master。可以看到,其实 seconds_behind_master 这个参数计算的就是 T3-T1。所以,我们可以用 seconds_behind_master 来作为主备延迟的值,这个值的时间精度是秒。如果主备库机器的系统时间设置不一致,那么备库连接到主库的时候,会通过执行 SELECT UNIX_TIMESTAMP() 函数来获得当前主库的系统时间。如果这时候发现主库的系统时间与自己不一致,备库在执行seconds_behind_master计算的时候会自动扣掉这个差值。因为主库上必须等事务执行完成才会写入 binlog,再传给备库。所以,如果一个主库上的语句执行 10 分钟,那这个事务很可能就会导致从库延迟 10 分钟。做过insert大量数据的一个事务的测试,主库需要73分钟完成这个insert事务,主库的这个insert事务的日志拷贝到从库耗时3分钟,从库应用完这个日志耗时19分钟,从库总计延迟22分钟。同样的服务器也做过测试delete大量数据的一个事务的测试,主库需要200分钟完成这个delete事务,主库的这个delete事务的日志拷贝到从库耗时5分钟,从库应用完这个日志耗时500分钟,从库总计延迟505分钟。
Postgresql
http://postgres.cn/docs/13/backup.html
http://postgres.cn/docs/13/continuous-archiving.html
http://postgres.cn/docs/13/warm-standby.html#STREAMING-REPLICATION
主从原理或逻辑理解:
将一个使用pg_basebackup获取到的PostgreSQL数据库集簇的基础备份而搭建的基于文件日志传送的后备服务器转变成流复制slave服务器的步骤是把该slave服务器recovery.conf文件中的primary_conninfo设置指向master服务器。这样slave服务器可以连接到master服务器上的伪数据库replication。当slave服务器被启动并且primary_conninfo被正确设置,slave服务器将在重放完归档中所有可用的WAL文件之后连接到master服务器。如果连接被成功建立,你将在slave服务器中看到一个walreceiver进程,并且在master服务器中有一个相应的walsender进程。
流复制允许一台后备服务器比使用基于文件的日志传送(日志传送是异步的,即 WAL 记录是在事务提交后才被传送。)更能保持为最新的状态。后备服务器连接到主服务器,主服务器则在 WAL 记录产生时即将它们以流式传送给后备服务器而不必等到 WAL 文件被填充。 默认情况下流复制是异步的,在这种情况下主服务器上提交一个事务与该变化在后备服务器上变得可见之间存在短暂的延迟。不过这种延迟比基于文件的日志传送方式中要小得多,在后备服务器的能力足以跟得上负载的前提下延迟通常低于一秒。如果你使用的流复制没有基于文件的连续归档,该服务器可能在后备机收到 WAL 段之 前回收这些旧的 WAL 段。如果发生这种情况,后备机将需要重新从一个新的基础备 份初始化。通过设置wal_keep_segments为一个足够高的值来确保旧 的 WAL 段不会被太早重用或者为后备机配置一个复制槽,可以避免发生这种情况。如果设置了一个后备机可以访问的 WAL 归档,就不需要这些解决方案,因为该归档可以 为后备机保留足够的段,后备机总是可以使用该归档来追赶主控机。 一旦流复制已经被配置,配置同步复制就只需要一个额外的配置步骤:synchronous_standby_names必须被设置为一个非空值。synchronous_commit也必须被设置为on,但由于这是默认值,通常不需要改变。这样的配置将导致每一次提交都等待确认消息,以保证后备服务器已经将提交记录写入到持久化存储中。将synchronous_commit设置为remote_write将导致每次提交都等待后备服务器已经接收提交记录并将它写出到其自身所在的操作系统的确认,但并非等待数据都被刷出到后备服务器上的磁盘。这种设置提供了比on要弱一点的持久性保障:在一次操作系统崩溃事件中后备服务器可能丢失数据,尽管它不是一次PostgreSQL崩溃。不过,在实际中它是一种有用的设置,因为它可以减少事务的响应时间。只有当主服务器和后备服务器都崩溃并且主服务器的数据库同时被损坏的情况下,数据丢失才会发生。
查询延迟,备库执行:select case when pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn() then 0 else EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp()) end as wal_delay_seconds;–此查询语句虽显粗糙但是仍然可以作为参考来使用,实际的延迟应该是主库上的当前WAL写位置和备库接收到的最后一个WAL位置来计算这个滞后量
问题:假设一个主库上的一个insert事务需要执行 10 分钟才能提交完成,那这个insert事务新增的数据行一定延迟 10 分钟才能到达从库,这个结论正确还是错误?
实验验证
针对sqlserver、oracle、postgresql而言是错误的,因为sqlserver、oracle、postgresql主节点的事务不是非要提交了才会写入日志,在主节点事务运行过程中产生的日志已经慢慢同步到了从节点,从节点也会慢慢应用这一部分已经同步过来的日志,等主节点事务提交的瞬间,可能从节点已经正常接收到了主节点提交之前产生的99%的日志并成功应用,主节点事务提交的瞬间产生的最后一部分日志传输到从节点并且从节点应用完这最后一部分日志也不需要多长时间,因为该事务在主库需要10分钟在从库也需要10分钟,但是主从的10分钟几乎是同时进行的,比如主库1:01开始跑,1:11分结束,主节点在1:01产生的日志可能在1:02分已经传到从节点,主节点1:11产生的日志,在1:12分也传到了从节点,主节点1:01-1:11产生的所有日志,在1:0-1:12已经写入从节点了。所以只要主从节点之间网络正常、从节点可用cpu\memory\disk资源没有压力的情况下,主从之间可能几乎没有延迟;比如如下实践,主从资源一致且都是没有跑任何其他会话的干净环境,Sqlserver主节点需要10分钟完成的一个insert事务,insert数据几乎没有任何延迟就到了从节点,Postgresql主节点需要10分钟完成的一个insert事务,insert数据几乎没有任何延迟就到了从节点
Sqlsever的AG为例子
CREATE TABLE testtable1 (h1 int,h2 char(200),h3 char(200));
begin transaction insert1
declare @i int
set @i=1
while @i<1000000
begininsert into testtable1 (h1,h2,h3)values(@i,'hhhhhh2','hhhhhh3');set @i=@i+1 end
commit transaction insert1
该事务耗时10分钟,但是AG主节点的数据到几乎是没有延迟就同步到AG从节点了,主节点所有1000000条写入完成commit提交后,这1000000条立即也同步到从节点了。但是主库事务没有commit完成之前,主库执行select count() from dba_test.dbo.testtable1会堵塞,但是主库执行select count() from dba_test.dbo.testtable1 with(nolock)不会堵塞且可以查到数据事务过程中慢慢写入的数据比如100条,1000条这样的,但是从节点执行select count() from dba_test.dbo.testtable1或select count() from dba_test.dbo.testtable1 with(nolock)都不会堵塞且查不到任何一条数据
所以Sqlserver的延迟,Sqlserver关于同步延迟我们看到两个指标:sys.dm_hadr_database_replica_states.log_send_queue_size/sys.dm_hadr_database_replica_states.log_send_rate和sys.dm_hadr_database_replica_states.redo_queue_size/sys.dm_hadr_database_replica_states.redo_rate,两者相加就是总的延迟,但是当主节点的事务只要产生了日志就会写入主节点日志文件发送到从节点,从而导致主从日志几乎一致,剩下的就看从节点解析日志的速度了。
Postgresql的流复制为例子
CREATE TABLE public.testtable1(h1 int,h2 char(200),h3 char(200),h4 char(200),h5 char(200),h6 char(200),h7 char(200),h8 char(200),h9 char(200),h10 char(200));
CREATE PROCEDURE public.autoInsert() LANGUAGE plpgsql
AS $$
declare i int;
begini = 1;while i< 5000001 loopinsert into public.testtable1 values (i,'hhhh2','hhhh3','hhhh4','hhhh5','hhhh6','hhhh7','hhhh8','hhhh9','hhhh10');i = i+1;end loop;
END$$;call public.autoInsert();
备注1:上述begin…end是一个整体事务,也就是说上面5000000条记录要么一起成功要么一起失败
备注2:上述call public.autoInsert();需要10分钟的过程中,其他会话查询public.testtable1表,查询不到新插入的任何一条数据,但是此时wal日志在不停的生成新的wal文件,说明postgresql的wal日志不像mysql的bin log日志,mysql是事务完成才会写入bin log日志,而postgresql是事务运行过程中就会写入wal日志
该存储过程里面是一个整体事务,主节点需要10分钟执行完这个存储过程,比如1:00开始执行,1:10分钟后执行完,1:10分钟主库查询public.testtable1有5000000条数据,Postgresql从节点在1:11分钟就查到了public.testtable1有5000000条数据,说明Postgresql流复制主节点的数据到几乎是没有延迟就同步到从节点了。但是主库事务没有commit完成之前,从节点执行select count(*) from public.testtable1不会堵塞但是查不到任何一条数据,在主节点事务运行期间,主节点不断生成wal日志和表testtable1文件超过1GB大小时不停地生成的表oid对应数据文件oid.1、oid.2、oid.3…,从节点也不断接收主节点的wal日志,并且从节点表testtable1也不停地生成的表oid对应数据文件oid.1、oid.2、oid.3…
针对mysql而言的话是对的,因为mysql的同步用的是bin-log,而mysql事务不能跨bin-log,也就是mysql的某个事务完成了才会写入bin-log文件并只会写入一个bin-log文件,如果mysql事务在主节点需要10分钟,那么这个事务完成后才会写入binlog文件,这个事务的内容通过主节点传输到从节点后(mysql不是一次只传输一个完全写满的binlog文件,主节点一旦生成一个新的binlog文件就会传输到从节点,后面再把慢慢落地到主节点binlog中的内容一点点传输到从节点的binlog文件),而从节点可用cpu\memory\disk资源没有压力的情况下应用完这个事务日志对应的binlog也大概需要10分钟,这样主从之间就延迟了10分钟。比如主库1:01开始跑,1:11分结束,主节点在1:01产生的日志也是在1:11分才能写入bin log,这个时候1:11才能传到从节点,10分钟解析后数据最终在1:21写进了从节点的表,但是实际查询下来可能延迟可能会比这个更大或更小,比如如下实践,主从资源一致且都是没有跑任何其他会话的干净环境,其中Mysql主库的事务执行了73分钟,但是Mysql从库只用了22分钟就把Mysql主库同步过来的日志全部relay完成了,且做个另外一个实验把数据量在加大的情况下,主节点的事务执行了3小时,但是Mysql从库缺用了10多个小时才把Mysql主库同步过来的日志全部relay完成。
mysql> show variables like '%log_bin_basename%';
+------------------+-------------------+
| Variable_name | Value |
+------------------+-------------------+
| log_bin_basename | /var/lib/mysql/on |
+------------------+-------------------+mysql> show variables like '%max_binlog_size%';
+-----------------+------------+
| Variable_name | Value |
+-----------------+------------+
| max_binlog_size | 1073741824 |
+-----------------+------------+
主节点
CREATE TABLE testtable1 (h1 int(11),h2 char(200),h3 char(200),h4 char(200),h5 char(200),h6 char(200),h7 char(200),h8 char(200),h9 char(200),h10 char(200),h11 char(200),h12 char(200),h13 char(200),h14 char(200),h15 char(200),h16 char(200),h17 char(200),h18 char(200),h19 char(200),h20 char(200))DELIMITER $$
CREATE PROCEDURE autoInsert()
BEGINDECLARE i int default 1;START TRANSACTION;select sysdate();WHILE(i < 4000000) DOinsert into testtable1 (h1,h2,h3,h4,h5,h6,h7,h8,h9,h10,h11,h12,h13,h14,h15,h16,h17,h18,h19,h20) value (i,'hhhhhhhhhhh2','hhhhhhhhhhh3','hhhhhhhhhhh4','hhhhhhhhhhh5','hhhhhhhhhhh6','hhhhhhhhhhh7','hhhhhhhhhhh8','hhhhhhhhhhh9','hhhhhhhhhhh10','hhhhhhhhhhh11','hhhhhhhhhhh12','hhhhhhhhhhh13','hhhhhhhhhhh14','hhhhhhhhhhh15','hhhhhhhhhhh16','hhhhhhhhhhh17','hhhhhhhhhhh18','hhhhhhhhhhh19','hhhhhhhhhhh20');SET i = i+1;END WHILE;COMMIT;select sysdate();
END$$
DELIMITER ;
–备注1:MySQL默认的行分隔符是分号,遇到分号就执行分号前面的一段语句,而存储过程、方法中可能有好几个分号,若不重新设置’分隔符’,存储过程中遇到一个分号就会执行一次导致存储过程代码被拆开执行从而引发语法格式不完整之类的报错最后导致存储过程报错。如果希望一段代码作为一个整体执行,就在脚本最前面加上delimiter$$并在最后END后面再加$$,使完整代码被前后两个$$包裹起来当成一个整体
–备注2:执行完语句块后再用delimiter ;把分隔符恢复成系统默认的分号
mysql> call autoInsert();
+---------------------+
| sysdate() |
+---------------------+
| 2023-02-20 23:48:59 |
+---------------------+
1 row in set (0.15 sec)+---------------------+
| sysdate() |
+---------------------+
| 2023-02-21 01:02:04 |
+---------------------+
1 row in set (1 hour 13 min 5.47 sec)
–备注,这个存储过程执行了73分钟,73分钟期间主从的count()都0,这73分钟期间从库执行show slave status\G;显示Seconds_Behind_Master都是0,当主执行完成后主库查询count()有值,从节点查询count()没有值,且在主库binlog日志被完全写入到从库的relaylog后,从库每隔2分钟执行一次show slave status\G;总计执行了10次,每次执行完就发现这个Seconds_Behind_Master值越来越大,从最初的100到后来的1500,第11次执行时发现Seconds_Behind_Master变成了0,从节点查询count()有值了,查看文件/var/lib/mysql/tes1/testtable1.ibd的时间最后的change定格在了2023-02-21 01:24:28,也就是发现从库最终只延迟了22分钟(2023-02-21 01:24:28减去2023-02-21 01:02:04)。结论:主库的insert事务执行了73分钟,这个insert对应的主库binlog拷贝到从库花了3分钟,从库应用这个因binlog转化而来的relaylog花了19分钟
主库对应的on.000039大小一直没变,从2023-02-21 01:02:04之后,这个文件开始变大成1.2GB后不再变大,主库对应的数据文件testtable1.ibd慢慢变大且Change一直变,最后2023-02-21 01:01:26文件不变了,也就是testtable1.ibd文件生成时间是2023-02-20 23:48:59到2023-02-21 01:01:26耗时72分钟,而binlog/var/lib/mysql/on.000039文件生成时间是2023-02-21 01:01:26到2023-02-21 01:02:04耗时1分钟,主库这个insert事务总计耗时73分钟
[root@FRSBachDEV2 ~]# date
Tue Feb 21 00:57:56 PST 2023
[root@FRSBachDEV2 ~]# du -sh /var/lib/mysql/on*
4.0K /var/lib/mysql/on.000037
1.3G /var/lib/mysql/on.000038
4.0K /var/lib/mysql/on.000039
4.0K /var/lib/mysql/on.index
[root@FRSBachDEV2 ~]# date
Tue Feb 21 01:02:11 PST 2023
[root@FRSBachDEV2 ~]# du -sh /var/lib/mysql/on*
1.3G /var/lib/mysql/on.000038
1.2G /var/lib/mysql/on.000039
4.0K /var/lib/mysql/on.000040
4.0K /var/lib/mysql/on.index
[root@FRSBachDEV2 ~]# stat /var/lib/mysql/tes1/testtable1.ibdFile: ‘/var/lib/mysql/tes1/testtable1.ibd’Size: 16584278016 Blocks: 32391176 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 134403462 Links: 1
Access: (0640/-rw-r-----) Uid: ( 27/ mysql) Gid: ( 27/ mysql)
Context: system_u:object_r:mysqld_db_t:s0
Access: 2023-02-21 01:03:12.889656103 -0800
Modify: 2023-02-21 01:01:26.777336361 -0800
Change: 2023-02-21 01:01:26.777336361 -0800Birth: -
从库对应的FRSBachDEV3-relay-bin.000008大小在2023-02-20 23:48:59-2023-02-21 01:02:04期间一直没变,从2023-02-21 01:02:04之后,这个文件开始慢慢变大,直到2023-02-21 01:05:13变成1.2GB后不再变大,这个过程耗时3分钟(2023-02-21 01:05:13-2023-02-21 01:02:04),这3分钟就是把主库的binlog传输到从库的relaylog。从库涉及的表对应的文件/var/lib/mysql/tes1/testtable1.ibd的change时间,这个change时间2023-02-21 01:24:28之后不再改变说明从库的relay结束了,这个过程耗时19分钟(2023-02-21 01:24:28-2023-02-21 01:05:13),这19分钟就是从库的relaylog应用到从库的数据文件,也就是从库总计延迟3+19=22分钟
[root@FRSBachDEV3 ~]# date
Tue Feb 21 00:51:41 PST 2023
[root@FRSBachDEV3 ~]# du -sh /var/lib/mysql/FRSBachDEV3-relay-bin*
4.0K /var/lib/mysql/FRSBachDEV3-relay-bin.000007
4.0K /var/lib/mysql/FRSBachDEV3-relay-bin.000008
4.0K /var/lib/mysql/FRSBachDEV3-relay-bin.index
[root@FRSBachDEV3 ~]# date
Tue Feb 21 01:02:22 PST 2023
[root@FRSBachDEV3 ~]# du -sh /var/lib/mysql/FRSBachDEV3-relay-bin*
4.0K /var/lib/mysql/FRSBachDEV3-relay-bin.000007
257M /var/lib/mysql/FRSBachDEV3-relay-bin.000008
4.0K /var/lib/mysql/FRSBachDEV3-relay-bin.index
[root@FRSBachDEV3 ~]# date
Tue Feb 21 01:03:15 PST 2023
[root@FRSBachDEV3 ~]# du -sh /var/lib/mysql/FRSBachDEV3-relay-bin*
4.0K /var/lib/mysql/FRSBachDEV3-relay-bin.000007
1.1G /var/lib/mysql/FRSBachDEV3-relay-bin.000008
4.0K /var/lib/mysql/FRSBachDEV3-relay-bin.index
[root@FRSBachDEV3 ~]# date
Tue Feb 21 01:05:13 PST 2023
[root@FRSBachDEV3 ~]# du -sh /var/lib/mysql/FRSBachDEV3-relay-bin*
4.0K /var/lib/mysql/FRSBachDEV3-relay-bin.000007
1.2G /var/lib/mysql/FRSBachDEV3-relay-bin.000008
4.0K /var/lib/mysql/FRSBachDEV3-relay-bin.000009
4.0K /var/lib/mysql/FRSBachDEV3-relay-bin.000010
4.0K /var/lib/mysql/FRSBachDEV3-relay-bin.000011
4.0K /var/lib/mysql/FRSBachDEV3-relay-bin.index
[root@FRSBachDEV3 ~]# stat /var/lib/mysql/tes1/testtable1.ibdFile: ‘/var/lib/mysql/tes1/testtable1.ibd’Size: 16584278016 Blocks: 32391176 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 201383739 Links: 1
Access: (0640/-rw-r-----) Uid: ( 998/ mysql) Gid: ( 1000/ mysql)
Context: system_u:object_r:mysqld_db_t:s0
Access: 2023-02-21 01:25:04.934937964 -0800
Modify: 2023-02-21 01:24:28.783469597 -0800
Change: 2023-02-21 01:24:28.783469597 -0800
从库在主库执行过程中的73分钟,查询从库,发现从库的Master_Log_File,Read_Master_Log_Pos,Relay_Log_File,Relay_Log_Pos,Relay_Master_Log_File,Exec_Master_Log_Pos,Seconds_Behind_Master这7个值一直没变
mysql> show slave status\G;
*************************** 1. row ***************************Master_Log_File: on.000039Read_Master_Log_Pos: 338Relay_Log_File: FRSBachDEV3-relay-bin.000008Relay_Log_Pos: 540Relay_Master_Log_File: on.000039Exec_Master_Log_Pos: 338Seconds_Behind_Master: 0
73分钟之后从库每次执行show slave status\G;发现从库的Master_Log_File,Read_Master_Log_Pos,Relay_Log_File,Relay_Log_Pos,Relay_Master_Log_File,Exec_Master_Log_Pos,Seconds_Behind_Master这7个值大致变化如下,
mysql> show slave status\G;
*************************** 1. row ***************************Master_Log_File: on.000039Read_Master_Log_Pos: 658801586Relay_Log_File: FRSBachDEV3-relay-bin.000008Relay_Log_Pos: 540Relay_Master_Log_File: on.000039Exec_Master_Log_Pos: 338Seconds_Behind_Master: 142
mysql> show slave status\G;
*************************** 1. row ***************************Master_Log_File: on.000040Read_Master_Log_Pos: 157Relay_Log_File: FRSBachDEV3-relay-bin.000008Relay_Log_Pos: 540Relay_Master_Log_File: on.000039Exec_Master_Log_Pos: 338Seconds_Behind_Master: 1236
mysql> show slave status\G;
*************************** 1. row ***************************Master_Log_File: on.000040Read_Master_Log_Pos: 157Relay_Log_File: FRSBachDEV3-relay-bin.000011Relay_Log_Pos: 359Relay_Master_Log_File: on.000040Exec_Master_Log_Pos: 157Seconds_Behind_Master: 0
相关文章:

Sqlserver_Oracle_Mysql_Postgresql不同关系型数据库之主从延迟的理解和实验
关系型数据库主从节点的延迟是否和隔离级别有关联,个人认为两者没有直接关系,主从延迟在关系型数据库中一般和这两个时间有关:事务日志从主节点传输到从节点的时间事务日志在从节点的应用时间 事务日志从主节点传输到从节点的时间࿰…...
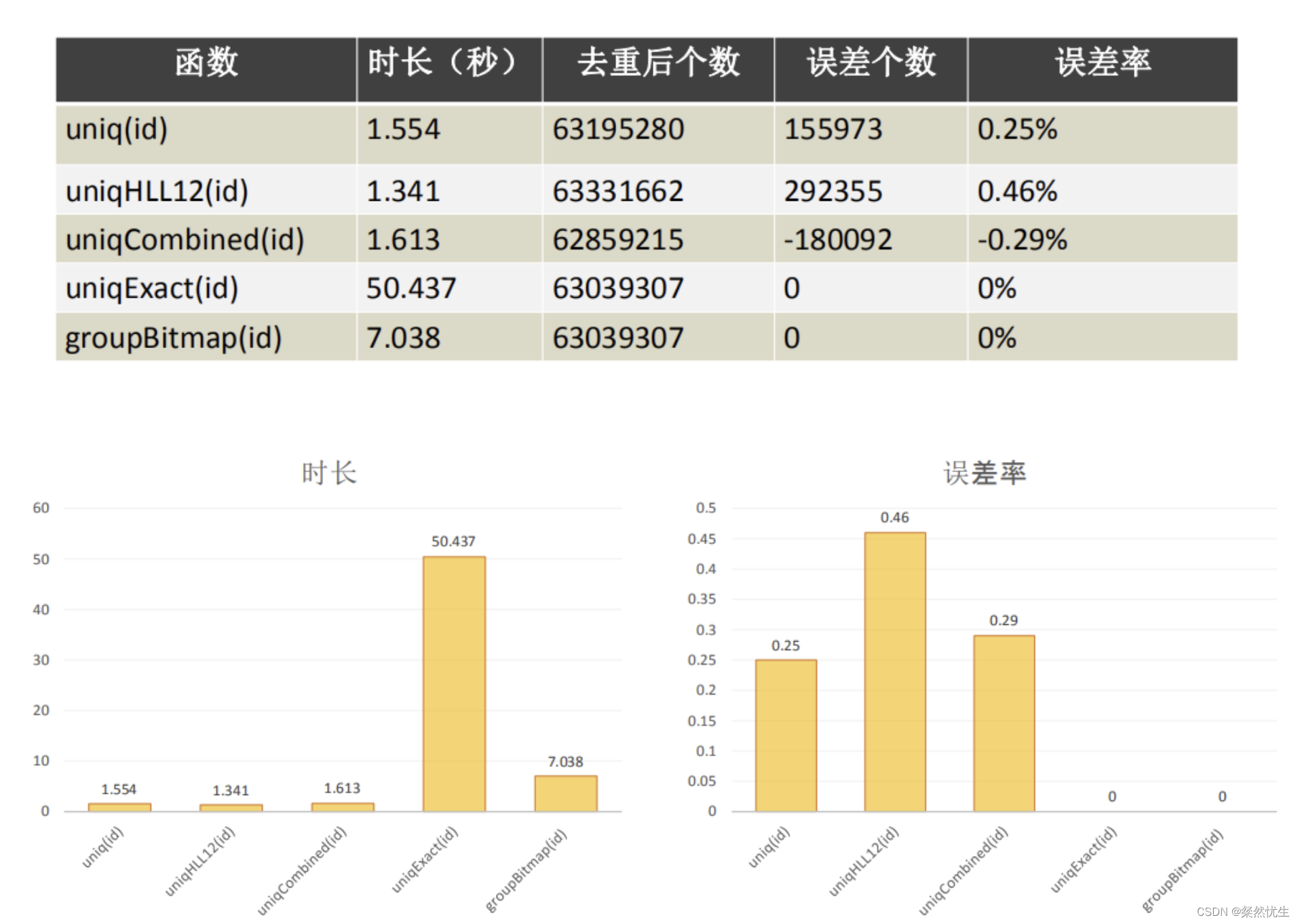
Clickhouse学习系列——一条SQL完成gourp by分组与不分组数值计算
笔者在近一两年接触了Clickhouse数据库,在项目中也进行了一些实践,但一直都没有一些技术文章的沉淀,近期打算做个系列,通过一些具体的场景将Clickhouse的用法进行沉淀和分享,供大家参考。 首先我们假设一个Clickhouse数…...

做好“关键基础设施提供商”角色,亚马逊云科技加快生成式AI落地
一场关于生产力的革命已在酝酿之中。全球管理咨询公司麦肯锡在最近的报告《生成式人工智能的经济潜力:下一波生产力浪潮》中指出,生成式AI每年可能为全球经济增加2.6万亿到4.4万亿美元的价值。在几天前的亚马逊云科技纽约峰会中,「生成式AI」…...

如何使用 ChatGPT 规划家居装修
你正在计划家庭装修项目,但不确定从哪里开始?ChatGPT 随时为你提供帮助。从集思广益的设计理念到估算成本,ChatGPT 可以简化你的家居装修规划流程。在本文中,我们将讨论如何使用 ChatGPT 有效地规划家居装修,以便你的项…...

题解 | #1002.Random Nim Game# 2023杭电暑期多校7
1002.Random Nim Game 诈骗博弈题 题目大意 Nim是一种双人数学策略游戏,玩家轮流从不同的堆中移除棋子。在每一轮游戏中,玩家必须至少取出一个棋子,并且可以取出任意数量的棋子,条件是这些棋子都来自同一个棋子堆。走最后一步棋…...

篇九:组合模式:树形结构的力量
篇九:“组合模式:树形结构的力量” 开始本篇文章之前先推荐一个好用的学习工具,AIRIght,借助于AI助手工具,学习事半功倍。欢迎访问:http://airight.fun/。 另外有2本不错的关于设计模式的资料,…...
【注册表】windows系统注册表常用修改方案
文章目录 ◆ 修改IE浏览器打印页面参数设置◆气泡屏幕保护◆彩带屏幕保护程序◆过滤IP(适用于WIN2000)◆禁止显示IE的地址栏◆禁止更改IE默认的检查(winnt适用)◆允许DHCP(winnt适用)◆局域网自动断开的时间(winnt适用)◆禁止使用“重置WEB设置”◆禁止更…...

ant-design-vue 4.x升级问题-样式丢失问题
[vue] ant-design-vue 4.x升级问题-样式丢失问题 项目环境问题场景解决方案 该文档是在升级ant-design-vue到4.x版本的时候遇到的问题 项目环境 "vue": "^3.3.4", "ant-design-vue": "^4.0.0", "vite": "^4.4.4&quo…...

【果树农药喷洒机器人】Part3:变量喷药系统工作原理介绍
本专栏介绍:免费专栏,持续更新机器人实战项目,欢迎各位订阅关注。 关注我,带你了解更多关于机器人、嵌入式、人工智能等方面的优质文章! 文章目录 一、变量喷药系统工作原理二、液压通路设计与控制系统封装2.1液压通路…...

GoogLeNet创新点总结
GoogLeNet是一种深度卷积神经网络架构,于2014年由Google团队提出,是ILSVRC(ImageNet Large Scale Visual Recognition Challenge)比赛的冠军模型,其创新点主要集中在以下几个方面: Inception模块&#…...
)
不同路径1、2、3合集(980. 不同路径 III)
不同路径一 矩形格,左上角 到 右下角。 class Solution {int [] directX new int[]{-1,1,0,0};int [] directY new int[]{0,0,-1,1};int rows;int cols;public int uniquePathsIII(int[][] grid) {if (grid null || grid.length 0 || grid[0].length 0) {ret…...

【云原生】Yaml文件详解
目录 一、YAML 语法格式1.1查看 api 资源版本标签1.2 写一个yaml文件demo1.3 详解k8s中的port 一、YAML 语法格式 Kubernetes 支持 YAML 和 JSON 格式管理资源对象JSON 格式:主要用于 api 接口之间消息的传递YAML格式:用于配置和管理,YAML 是…...

ffmpeg下载安装教程
ffmpeg官网下载地址https://ffmpeg.org/download.html 这里以windows为例,鼠标悬浮到windows图标上,再点击 Windows builds from gyan.dev 或者直接打开 https://www.gyan.dev/ffmpeg/builds/ 下载根据个人需要下载对应版本 解压下载的文件,并复制bin所在目录 新打开一个命令…...
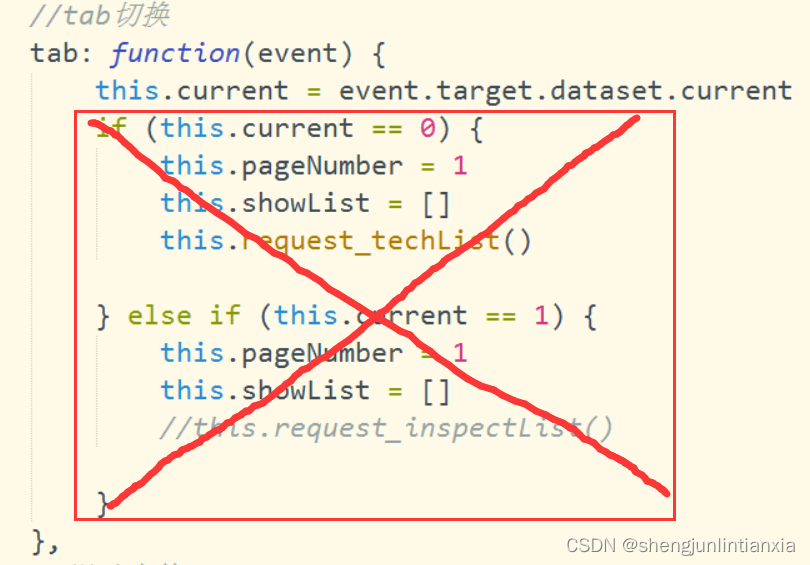
uniapp之当你问起“tab方法触发时eventchange也跟着触发了咋办”时
我相信没有大佬会在这个问题上卡两个小时吧,记下来大家就当看个乐子了。 当时问题就是,点击tab头切换的时候,作为tab滑动事件的eventchange同时触发了,使得接口请求了两次 大概是没睡好,我当时脑子老想着怎么阻止它冒…...
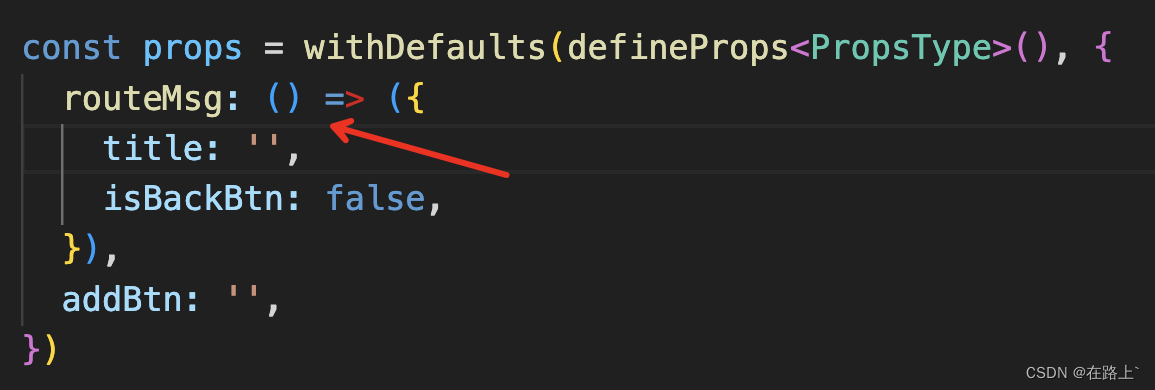
TS 踩坑之路(四)之 Vue3
一、在使用定义默认值withDefaults和defineProps 组合时,默认值设置报错 代码案例 报错信息 不能将类型“{ isBackBtn: false; }”分配给类型“(props: PropsType) > RouteMsgType”。 对象字面量只能指定已知属性,并且“isBackBtn”不在类型“(pro…...
【音视频】edge与chrome在性能上的比较
目录 结论先说 实验 结论 实验机器的cpu配置 用EDGE拉九路编辑 google拉五路就拉不出来了 资源使用情况 edge报错编辑 如果服务器端 性能也满 了,就会不回复;验证方式 手动敲 8081,不回应。 结论先说 实验 用chrome先拉九路&#…...
Docker Compose编排部署LNMP服务
目录 安装docker-ce 阿里云镜像加速器 文件 启动 安装docker-ce [rootlocalhost ~]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo --2023-08-03 18:34:32-- http://mirrors.aliyun.com/repo/Centos-7.repo 正在解析主机 m…...
git使用(常见用法)
一.下载git git官方下载跳转 安装简单,有手就行 二. git的简单使用 1. 连接远程仓库 #初始化 git init #配置账户 git config --global user.name “输入你的用户名” git config --global user.email “输入你的邮箱” git config --list #--q退出 #配置验证邮箱 ssh-key…...

用例拆分情况考虑方案
文章目录 1、方案一方案概述方案分析(1) 把对应图商地图的逻辑给分离开(2) 要使用命令行的方式执行方法 2、方案二3、最终决定 1、方案一 方案概述 每个图商(GD、BD、自建)拆分成单独的类 把参数化的几个图商类别拆分成对应的图商类,在每个类…...

一文搞懂IS-IS报文通用格式
报文格式 IS-IS报文是直接封装在数据链路层的帧结构中的。PDU可以分为两个部分,报文头和变长字段部分。其中头部又可分为通用头部和专用头部。对于所有PDU来说,通用报头都是相同的,但专用报头根据PDU类型不同而有所差别。 IS-IS的PDU有4种类…...

OffscreenCanvas黑科技:让你的网页动画性能提升300%的配置指南
OffscreenCanvas黑科技:让你的网页动画性能提升300%的配置指南 当网页动画开始卡顿,用户的体验就会直线下降。传统Canvas渲染在主线程执行,复杂的图形运算很容易阻塞UI响应。OffscreenCanvas的出现彻底改变了这一局面——它允许你将绘制逻辑转…...

当知识有了‘关系网‘:LightRAG如何让大模型‘秒懂‘你的文档?
想象一下,你有一座藏书万卷的图书馆,但你找书的方式只有一种——记住每本书某个页面的关键词,然后靠"猜"来定位。 这,就是传统RAG系统的尴尬处境。 今天要介绍的这个开源项目LightRAG,被顶会EMNLP 2025接收…...

终极指南:NanoVG渲染管线深度解析与抗锯齿技术实战
终极指南:NanoVG渲染管线深度解析与抗锯齿技术实战 【免费下载链接】nanovg Antialiased 2D vector drawing library on top of OpenGL for UI and visualizations. 项目地址: https://gitcode.com/gh_mirrors/na/nanovg NanoVG是一款基于OpenGL的轻量级抗锯…...

gotop扩展功能详解:NVIDIA GPU监控与远程数据采集终极指南
gotop扩展功能详解:NVIDIA GPU监控与远程数据采集终极指南 【免费下载链接】gotop A terminal based graphical activity monitor inspired by gtop and vtop 项目地址: https://gitcode.com/gh_mirrors/got/gotop gotop是一款功能强大的终端图形化系统监控工…...
✅)
计算机毕业设计:Python 汽车推荐系统实战 Django框架 可视化 协同过滤算法 数据分析 大数据 机器学习(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

桌面图标杂乱如何高效管理?NoFences开源工具让文件归类效率提升60%
桌面图标杂乱如何高效管理?NoFences开源工具让文件归类效率提升60% 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 每天面对布满数十个图标的电脑桌面,…...

Go语言中的Interface:面向接口编程
Go语言中的Interface:面向接口编程 1. Interface的基本概念 Interface是Go语言中用于定义行为的一种类型,它指定了一组方法签名,但不提供具体实现。Interface是Go语言实现多态和解耦的核心机制,也是面向接口编程的基础。 Go语言的…...

智能驱动,精准雾化:探秘微孔雾化片专用IC的自适应频率与无水保护
1. 微孔雾化技术的前世今生 第一次拆解家用加湿器时,我被那片直径不到3cm的金属薄片震惊了——它竟能凭空"变"出细腻的水雾。这就是微孔雾化片,通过每秒10万次以上的高频振动将液态水"打碎"成微米级颗粒。但要让这片金属薄片稳定工作…...
: 什么是 Barrier 原语 【异步!!!】)
[Python3高阶编程] - 异步编程深度学习指南二(补充1): 什么是 Barrier 原语 【异步!!!】
asyncio.Barrier 是 Python 3.11(2022 年 10 月)新增的高级同步原语,用于解决特定并发协作场景。一、Barrier 产生的背景:为什么需要它?核心问题:“多协程阶段对齐”在并发编程中,经常遇到这样的…...
)
英飞凌TC3xx SMU模块实战:如何配置看门狗超时自动复位(附寄存器详解)
英飞凌TC3xx SMU模块实战:如何配置看门狗超时自动复位(附寄存器详解) 在汽车电子和工业控制领域,系统稳定性是生死攸关的指标。想象一下,当你的ECU在高速公路上以120km/h运行时突然死机,或者工业机器人正在…...