【数据分析】pandas( 二)
目录
简介:
一,1.1来自Series字典或字典
1.2 来自ndarray或者列表的字典:
1.3来自结构化或记录数组;
1.4来自字典列表:
1.4来自元组的字典:
1.5 来自Series
二,代替构造函数:
2.1DataFrame.from_dict
2.2DataFrame.from_records
三,列表的选择,删除,添加
四,在方法链中分配新列
五,索引
六,数据对齐:
简介:
本片文章我们来介绍pandas的另一个数据类型DataFrame
DataFrame是一个二维标记数据结构,其中包含可能不同类型的列。您可以将其视为电子表格或SQL表,或者Series对象的字典。它通常是最常用的pandas对象。与Series一样,DataFrame接受许多不同类型的输入:
一维ndarray,列表,字典,或字典的Series
二维numpy.ndarray
结构化或记录数组
一个Series
其他DataFrame等
除了数据之外,您还可以选择传递索引(行标签)和列(列标签)参数。如果您传递索引和/或列,则可以保证生成的DataFrame的索引和/或列。因此,Series的字典加上特定索引将丢弃所有与传递的索引不匹配的数据。如果未传递轴标签,他们将根据常识规则从输入数据构建。
一,1.1来自Series字典或字典
生成的索引将是各个系列的索引的并集。如果有任何嵌套字典他们将首先转化为系列。如果每日有传递列,则列将是字典键的有序列表。
d={
"one":pd.Series([1.0,2.0,3.0],index=["a","b","c"]),
"two":pd.Series([1.0,2.0,3.0,4.0],index=["a","b","c","d"]),
}
df = pd.DataFrame(d)
one two a 1.0 1.0 b 2.0 2.0 c 3.0 3.0 d NaN 4.0
pd.DataFrame(d, index=["d", "b", "a"])
one two d NaN 4.0 b 2.0 2.0 a 1.0 1.0
pd.DataFrame(d, index=["d", "b", "a"], columns=["two", "three"])
two three d 4.0 NaN b 2.0 NaN a 1.0 NaN
可以通过访问index喝columns属性来分别访问行和列 标签:
df.index
Out: Index(['a', 'b', 'c', 'd'], dtype='object')df.columns
Out: Index(['one', 'two'], dtype='object')
1.2 来自ndarray或者列表的字典:
ndarray的长度必须相同。如果传递索引,他也必须与数组的长度相同,如果没有传递索引,结果将为range(n),n为数组长度。
d = {"one": [1.0, 2.0, 3.0, 4.0], "two": [4.0, 3.0, 2.0, 1.0]}pd.DataFrame(d)pd.DataFrame(d, index=["a", "b", "c", "d"])
one two 0 1.0 4.0 1 2.0 3.0 2 3.0 2.0 3 4.0 1.0one two a 1.0 4.0 b 2.0 3.0 c 3.0 2.0 d 4.0 1.0
1.3来自结构化或记录数组;
这种情况的处理方式与数组字典相同
data = np.zeros((2,), dtype=[("A", "i4"), ("B", "f4"), ("C", "a10")])
data[:] = [(1, 2.0, "Hello"), (2, 3.0, "World")]
pd.DataFrame(data)
A B C
0 1 2.0 b'Hello'
1 2 3.0 b'World'pd.DataFrame(data, index=["first", "second"])
A B C
first 1 2.0 b'Hello'
second 2 3.0 b'World'pd.DataFrame(data, columns=["C", "A", "B"])
C A B
0 b'Hello' 1 2.0
1 b'World' 2 3.0
1.4来自字典列表:
data2 = [{"a": 1, "b": 2}, {"a": 5, "b": 10, "c": 20}]
pd.DataFrame(data2)
a b c
0 1 2 NaN
1 5 10 20.0pd.DataFrame(data2, index=["first", "second"])
a b c
first 1 2 NaN
second 5 10 20.0pd.DataFrame(data2, columns=["a", "b"])
a b
0 1 2
1 5 10
1.4来自元组的字典:
可以通过传递元组字典来自动创建MultiIndexed frame
pd.DataFrame(
{
("a", "b"): {("A", "B"): 1, ("A", "C"): 2},
("a", "a"): {("A", "C"): 3, ("A", "B"): 4},
("a", "c"): {("A", "B"): 5, ("A", "C"): 6},
("b", "a"): {("A", "C"): 7, ("A", "B"): 8},
("b", "b"): {("A", "D"): 9, ("A", "B"): 10},
}
)
a b
b a c a b
A B 1.0 4.0 5.0 8.0 10.0
C 2.0 3.0 6.0 7.0 NaN
D NaN NaN NaN NaN 9.0
1.5 来自Series
结果将是一个与输入Series具有相同索引的DataFrame,并且其中一列的名称是Series的原始名称(仅当 为提供其他列名称时)
ser = pd.Series(range(3), index=list("abc"), name="ser")
pd.DataFrame(ser)
ser
a 0
b 1
c 2
二,代替构造函数:
2.1DataFrame.from_dict
DataFrame.from_dict()接受一个字典或一个近似数组序列的字典并返回一个DataFrame。他的操作类似于DataFrame构造函数,除了默认 orient参数是columns之外,还可以设置该参数index使用字典键作为行标签。
pd.DataFrame.from_dict(dict([("A", [1, 2, 3]), ("B", [4, 5, 6])]))
A B
0 1 4
1 2 5
2 3 6
通过orient='index' 键将是行标签。在这种情况下,还可以传递所需列的名称。
pd.DataFrame.from_dict(
dict([("A", [1, 2, 3]), ("B", [4, 5, 6])]),
orient="index",
columns=["one", "two", "three"],
)
one two three
A 1 2 3
B 4 5 6
2.2DataFrame.from_records
DataFrame.from_records()接收元组列表或具有结构化数据类型的ndarray。他的工作方式与普通DataFrame构造函数类似,只是生成的DataFrame 索引可能是结构化数据类型的特定字段。
data
array([(1, 2., b'Hello'), (2, 3., b'World')],
dtype=[('A', '<i4'), ('B', '<f4'), ('C', 'S10')])pd.DataFrame.from_records(data, index="C")
A B
C
b'Hello' 1 2.0
b'World' 2 3.0
三,列表的选择,删除,添加
可以将DataFrame语义视为相似索引Series对象的字典。获取设置和删除列的语法与类似的dict操作相同
df["one"]
a 1.0
b 2.0
c 3.0
d NaN
Name: one, dtype: float64df["three"] = df["one"] * df["two"]
df["flag"] = df["one"] > 2
df
one two three flag
a 1.0 1.0 1.0 False
b 2.0 2.0 4.0 False
c 3.0 3.0 9.0 True
d NaN 4.0 NaN False
也可以像字典一样删除或弹出列:
del df["two"]
three = df.pop("three")
df
one flag
a 1.0 False
b 2.0 False
c 3.0 True
d NaN False
当插入标量值时,他自然会传播以填充列:
df["foo"] = "bar"
df
one flag foo
a 1.0 False bar
b 2.0 False bar
c 3.0 True bar
d NaN False bar
当插入与Series不具有相同索引的DataFrame时,他将符合DataFrame的索引
Idf["one_trunc"] = df["one"][:2]
I df
one flag foo one_trunc
a 1.0 False bar 1.0
b 2.0 False bar 2.0
c 3.0 True bar NaN
d NaN False bar NaN
四,在方法链中分配新列
DataFrame中有一种assign()方法可以轻松创建可能从现有列派生的新列
iris = pd.read_csv("data/iris.data")
iris.head()
SepalLength SepalWidth PetalLength PetalWidth Name
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosairis.assign(sepal_ratio=iris["SepalWidth"] / iris["SepalLength"]).head()
SepalLength SepalWidth PetalLength PetalWidth Name sepal_ratio
0 5.1 3.5 1.4 0.2 Iris-setosa 0.686275
1 4.9 3.0 1.4 0.2 Iris-setosa 0.612245
2 4.7 3.2 1.3 0.2 Iris-setosa 0.680851
3 4.6 3.1 1.5 0.2 Iris-setosa 0.673913
4 5.0 3.6 1.4 0.2 Iris-setosa 0.720000
在上面的示例中,我们插入了一个预先计算的值。我们还可以传入一个只有一个参数的函数,以便在分配给的DataFrame上进行计算。
iris.assign(sepal_ratio=lambda x: (x["SepalWidth"] / x["SepalLength"])).head()
SepalLength SepalWidth PetalLength PetalWidth Name sepal_ratio
0 5.1 3.5 1.4 0.2 Iris-setosa 0.686275
1 4.9 3.0 1.4 0.2 Iris-setosa 0.612245
2 4.7 3.2 1.3 0.2 Iris-setosa 0.680851
3 4.6 3.1 1.5 0.2 Iris-setosa 0.673913
4 5.0 3.6 1.4 0.2 Iris-setosa 0.720000
assign()始终返回数据的副本,保持原始的DataFrame不变。
五,索引
| 选择 | 语法 | 结果 |
| 选择列 | df[col] | Series |
| 按标签选择行 | df.loc[label] | Series |
| 按整数位置选择行 | df.iloc[loc] | Series |
| 切片行 | df[5:10] | DataFrame |
| 通过布尔向量选择行 | df[bool_vec] | DataFrame |
例如,行选择返回一个Series,其索引是DataFrame的列
df.loc["b"]
one 2.0
bar 2.0
flag False
foo bar
one_trunc 2.0
Name: b, dtype: objectdf.iloc[2]
one 3.0
bar 3.0
flag True
foo bar
one_trunc NaN
Name: c, dtype: object
六,数据对齐:
对象之间的数据对齐会在列和索引DataFrame上自动对齐,同样,生成的对象将具有列标签和行标签的并集
df = pd.DataFrame(np.random.randn(10, 4), columns=["A", "B", "C", "D"])In [95]: df2 = pd.DataFrame(np.random.randn(7, 3), columns=["A", "B", "C"])
df + df2
A B C D
0 0.045691 -0.014138 1.380871 NaN
1 -0.955398 -1.501007 0.037181 NaN
2 -0.662690 1.534833 -0.859691 NaN
3 -2.452949 1.237274 -0.133712 NaN
4 1.414490 1.951676 -2.320422 NaN
5 -0.494922 -1.649727 -1.084601 NaN
6 -1.047551 -0.748572 -0.805479 NaN
7 NaN NaN NaN NaN
8 NaN NaN NaN NaN
9 NaN NaN NaN NaN
DataFrame和Series之间执行操作时,默认行为是对齐列上的索引,从而按行广播,
df - df.iloc[0]
A B C D
0 0.000000 0.000000 0.000000 0.000000
1 -1.359261 -0.248717 -0.453372 -1.754659
2 0.253128 0.829678 0.010026 -1.991234
3 -1.311128 0.054325 -1.724913 -1.620544
4 0.573025 1.500742 -0.676070 1.367331
5 -1.741248 0.781993 -1.241620 -2.053136
6 -1.240774 -0.869551 -0.153282 0.000430
7 -0.743894 0.411013 -0.929563 -0.282386
8 -1.194921 1.320690 0.238224 -1.482644
9 2.293786 1.856228 0.773289 -1.446531
相关文章:
)
【数据分析】pandas( 二)
目录 简介: 一,1.1来自Series字典或字典 1.2 来自ndarray或者列表的字典: 1.3来自结构化或记录数组; 1.4来自字典列表: 1.4来自元组的字典: 1.5 来自Series 二,代替构造函数: 2.1DataFram…...
ffmpeg工具实用命令
说明:ffmpeg是一款非常好用的媒体操作工具,包含了许多对于视频、音频的操作,有些视频播放器里面实际上就是使用了ffmpeg。本文介绍ffmpeg的使用以及一些较为实用的命令。 安装 ffmpeg是命令行操作的,不需要安装,可在…...

zabbix API笔记
博客园原文 python简单demo 输出id为111主机的主机群组信息 import requests import json request_headers {"Content-Type": "application/json"} zabbix_url "http://xxx.xxx.xxx.xxx:8080/zabbix/api_jsonrpc.php" get_hostgroup_from_h…...

[HDLBits] Mt2015 q4a
Module A is supposed to implement the function z (x^y) & x. Implement this module. module top_module (input x, input y, output z);assign z(x^y)&x; endmodule...
HarmonyOS NEXT,生命之树初长成
在不同的神话体系中,都有着关于生命之树的记载。 比如在北欧神话中,一株巨大的树木联结着九大世界,其被称为“尤克特拉希尔”Yggdrasill。在中国的《山海经》中,也有着“建木”的传说,它“有九欘,下有九枸&…...
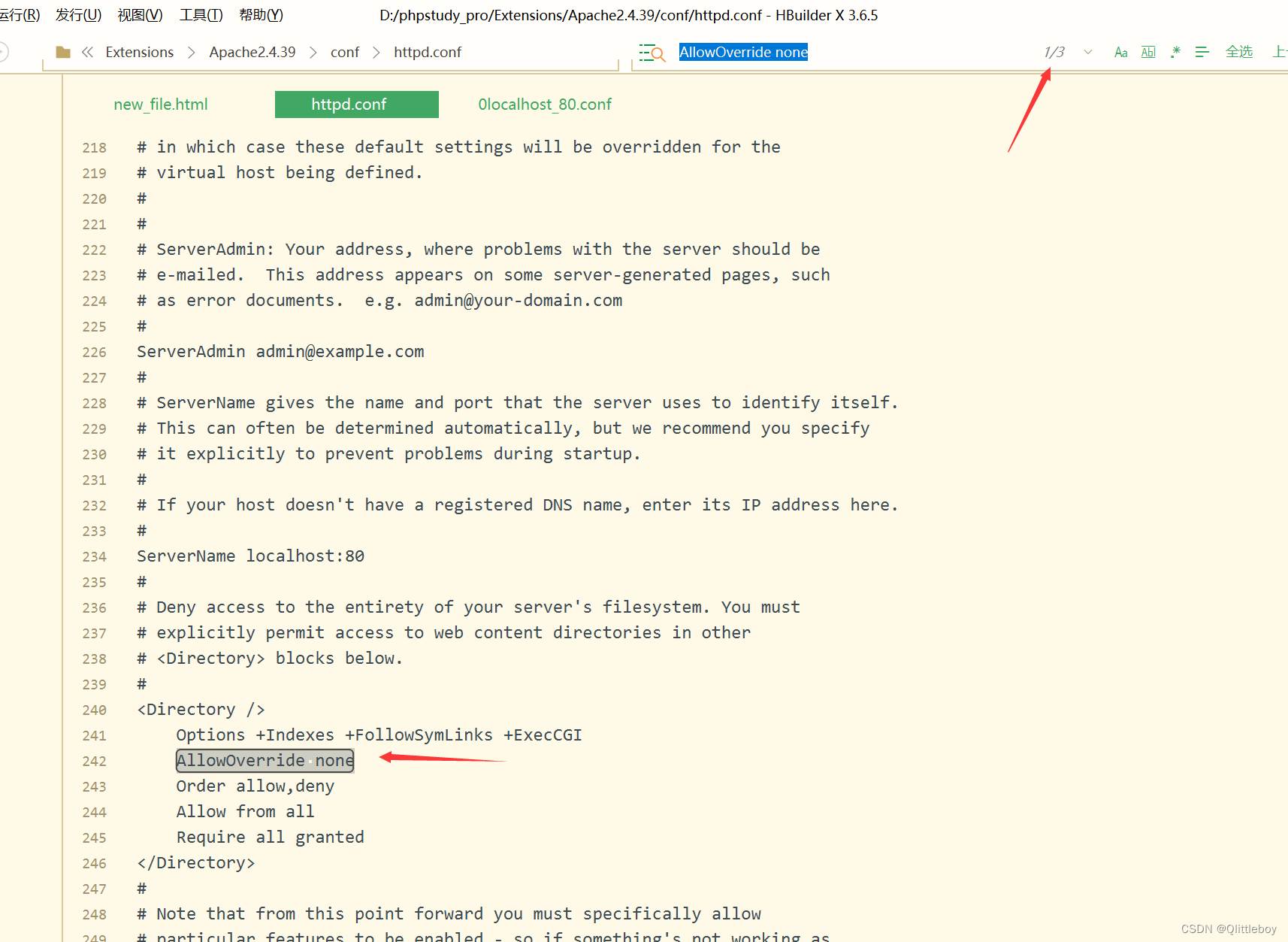
PHPstudy配置伪静态步骤,tp5.1的框架
搜索mod_rewrite.so,然后去掉前面的#(即放开注释) 2.找到index.php 同级文件.htaccess(没有就新建) 这些是tp5.1自带的内容,把它注释掉,是错误的内容,添加下面的这段配置 #<If…...
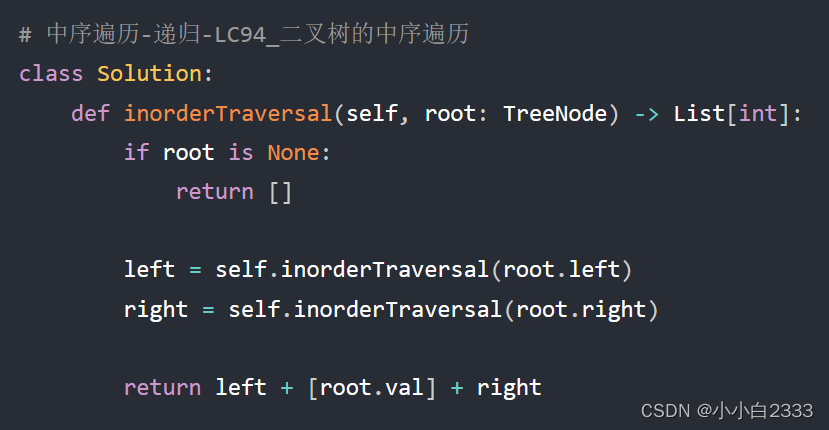
LeetCode:Hot100的python版本
94. 二叉树的中序遍历...
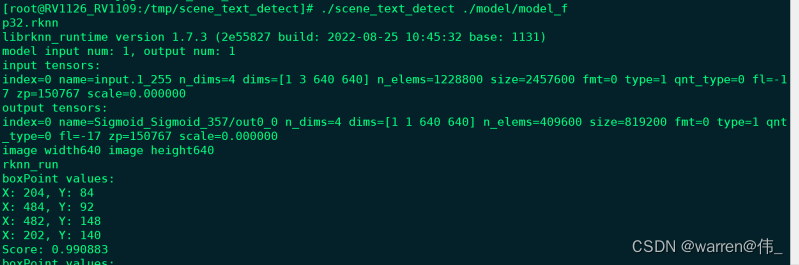
rv1126更新rknpu驱动教学
测试平台:易佰纳rv1126 38板 查看板端版本-------------------------------------------------- 1:查看npu驱动版本 dmesg | grep -i galcore,可以看到版本为6.4.3.5 2:查看rknn-server版本 strings /usr/bin/rknn_server | g…...
[机器学习]线性回归模型
线性回归 线性回归:根据数据,确定两种或两种以上变量间相互依赖的定量关系 函数表达式: y f ( x 1 , x 2 . . . x n ) y f(x_1,x_2...x_n) yf(x1,x2...xn) 回归根据变量数分为一元回归[ y f ( x ) yf(x) yf(x)]和多元回归[ y …...

Vue基于php医院预约挂号系统_6nrhh
随着信息时代的来临,过去的管理方式缺点逐渐暴露,对过去的医院预约挂号管理方式的缺点进行分析,采取计算机方式构建医院预约挂号系统。本文通过阅读相关文献,研究国内外相关技术,开发并设计一款医院预约挂号系统的构建…...

2023-08-07力扣今日六题-不错题
链接: 剑指 Offer 04. 二维数组中的查找 题意: 一个二维矩阵数组,在行上非递减,列上也非递减 解: 虽然在行列上非递减,但是整体并不有序,第一行存在大于第二行的数字,第一列存在…...

Elasticsearch搜索出现NAN异常
原因分析 Elasticsearch默认的打分,一般是不会出现异常的之所以会出现NAN异常,往往是因为我们重新计算了打分,使用了function_score核心原因是在function_score中,出现了计算异常,比如 0/0,比如log1p(x),x为负数等 真…...

(杭电多校)2023“钉耙编程”中国大学生算法设计超级联赛(6)
1001 Count 当k在区间(1n)/2的左边时,如图,[1,k]和[n-k1,n]完全相同,所以就m^(n-k) 当k在区间(1n)/2的右边时,如图,[1,n-k1]和[k,n]完全相同,所以也是m^(n-k) 别忘了特判,当k等于n时,n-k为0,然后a1a1,a2a2,..anan,所以没什么限制,那么就是m^n AC代码: #includ…...

【JavaScript 】浏览器事件处理
1. 什么是浏览器事件? 浏览器事件是指在网页中发生的各种交互和动作,例如用户点击按钮、页面加载完成、输入框文本变化等。通过处理这些事件,可以编写相应的JavaScript代码来实现特定的功能和行为。 2. 常见的浏览器事件 以下是一些常见的浏览器事件及其用途的详细介绍: c…...

(力扣)用两个队列实现栈---C语言
分享一首歌曲吧,希望在枯燥的刷题生活中带给你希望和勇气,加油! 题目: 请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty&#…...

使用 RediSearch 在 Redis 中进行全文检索
原文链接: 使用 RediSearch 在 Redis 中进行全文检索 Redis 大家肯定都不陌生了,作为一种快速、高性能的键值存储数据库,广泛应用于缓存、队列、会话存储等方面。 然而,Redis 在原生状态下并不支持全文检索功能,这使…...
[Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序
1.今天开发了一套服务程序,使用的是Odbc连接MySql数据库, 在我本机用VS打开程序时,访问一切正常,当发布出来装在电脑上,连接数据库时提示: [Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定…...
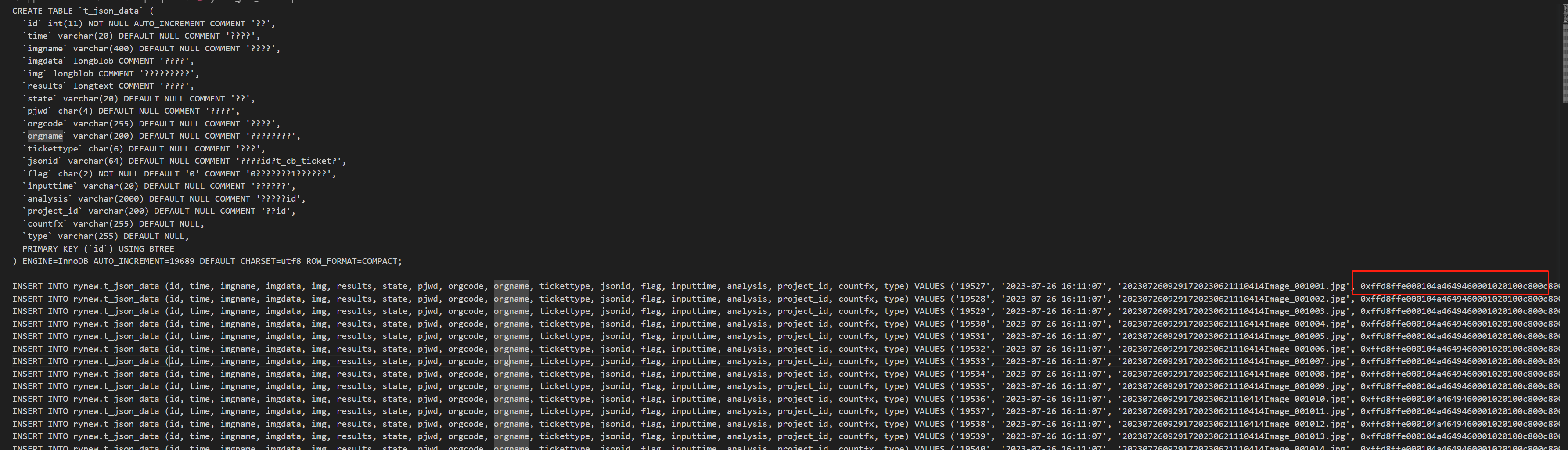
springboot生成表结构和表数据sql
需求 业务背景是需要某单机程序需要把正在进行的任务导出,然后另一台电脑上单机继续运行,我这里选择的方案是同步SQL形式,并保证ID随机,多个数据库不会重复。 实现 package com.nari.web.controller.demo.controller;import cn…...
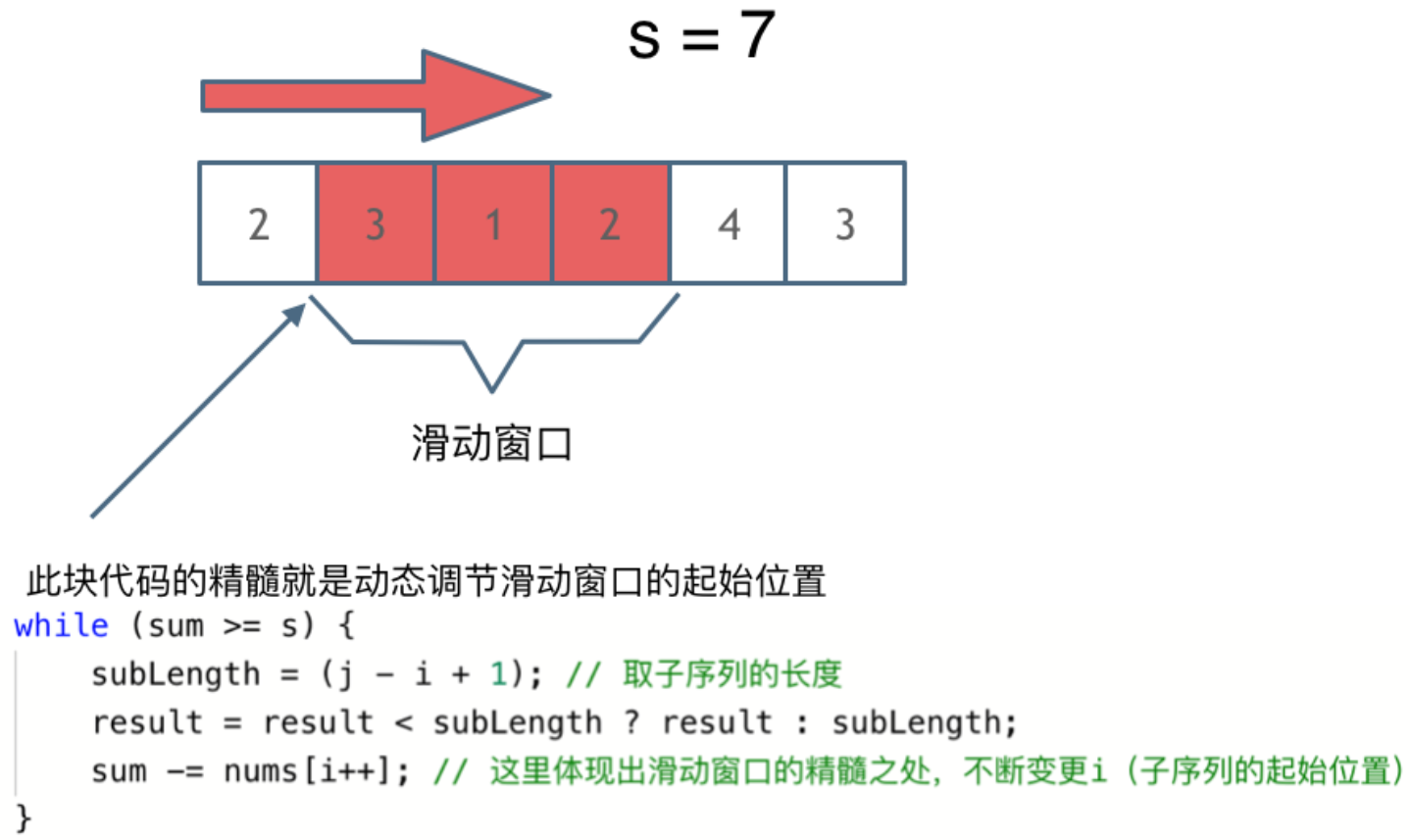
代码随想录—力扣算法题:209长度最小的子数组.Java版(示例代码与导图详解)
版本说明 当前版本号[20230808]。 版本修改说明20230808初版 目录 文章目录 版本说明目录209.长度最小的子数组思路暴力解法滑动窗口 两种方法的区别总结 209.长度最小的子数组 力扣题目链接 更多内容可点击此处跳转到代码随想录,看原版文件 给定一个含有 n 个…...

81 | Python可视化篇 —— Seaborn数据可视化
Seaborn是Python中一个基于Matplotlib的高级数据可视化库,它提供了更简单的API和更美观的图形样式,适用于数据探索和展示。在本教程中,我们将介绍Seaborn的基本概念和用法,并通过一些示例演示如何使用Seaborn来创建各种图表和图形。 文章目录 1. 导入Seaborn库和数据2. 数据…...

深度学习遥感图像语义分割:从数据准备到模型优化
深度学习遥感图像语义分割:从数据准备到模型优化 摘要:随着遥感传感器技术的飞速发展,海量高分辨率遥感图像数据的获取越来越便捷,如何高效、精准地从这些数据中提取地物信息成为遥感解译领域的核心挑战。深度学习凭借其强大的特征自主学习能力,尤其是卷积神经网络(CNN)…...

深度解析ArtPlayer.js:5个高级视频播放器实战技巧
深度解析ArtPlayer.js:5个高级视频播放器实战技巧 【免费下载链接】ArtPlayer :art: ArtPlayer.js is a modern and full featured HTML5 video player 项目地址: https://gitcode.com/gh_mirrors/ar/ArtPlayer ArtPlayer.js是一款功能全面且高度可定制的现代…...
)
STM32CubeMX配置I2C驱动ADS1115,从零开始实现高精度电压采集(附完整工程源码)
STM32CubeMX配置I2C驱动ADS1115:从零实现工业级电压采集系统 在嵌入式开发中,高精度模拟信号采集一直是工程师面临的挑战。当我们需要测量微弱电压信号或实现多通道同步采集时,STM32内置ADC往往难以满足精度要求。本文将手把手教你使用STM32C…...

如何使用Redis优化Trigger.dev任务队列:提升AI工作流性能的完整指南
如何使用Redis优化Trigger.dev任务队列:提升AI工作流性能的完整指南 【免费下载链接】trigger.dev Trigger.dev – build and deploy fully‑managed AI agents and workflows 项目地址: https://gitcode.com/gh_mirrors/tr/trigger.dev Trigger.dev是一个强…...

物联网服务选型指南:从核心模块解析到实战避坑
1. 物联网服务选型:从数据孤岛到智能系统的桥梁在物联网项目里摸爬滚打了十几年,我见过太多项目卡在“服务选型”这个环节。很多工程师朋友,硬件玩得转,代码写得溜,但一到要把设备连上网,让数据跑起来&…...

长期使用Taotoken聚合服务对开发者日常工作效率的积极影响观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对开发者日常工作效率的积极影响观察 1. 引言:从分散管理到统一接入的转变 在模型应用开发过…...

PowerVR Series2NX NNA架构解析:终端AI加速器的能效与工程实践
1. 项目概述:从“看得见”到“看得懂”的芯片革命在移动设备、智能摄像头乃至汽车座舱里,我们早已习惯了人脸解锁、实时美颜、物体识别这些功能。这些功能背后,都离不开一个核心引擎:神经网络加速器。今天要聊的,就是I…...

如何用memtest_vulkan快速检测GPU显存稳定性:终极免费测试指南
如何用memtest_vulkan快速检测GPU显存稳定性:终极免费测试指南 【免费下载链接】memtest_vulkan Vulkan compute tool for testing video memory stability 项目地址: https://gitcode.com/gh_mirrors/me/memtest_vulkan 当你的游戏突然崩溃、AI训练意外中断…...

别再手动搬数据了!STM32CubeMX配置SDIO DMA,让FatFs文件读写性能翻倍
STM32CubeMX实战:用DMA解锁SD卡与FatFs的终极性能 在嵌入式系统开发中,存储性能往往是制约整体效率的关键瓶颈。想象一下这样的场景:你的设备正在以最高优先级处理传感器数据,同时需要将采集结果实时写入SD卡。此时如果采用传统的…...

终极免费打字练习软件Qwerty Learner:提升英语输入速度的完整指南
终极免费打字练习软件Qwerty Learner:提升英语输入速度的完整指南 【免费下载链接】qwerty-learner 为键盘工作者设计的单词记忆与英语肌肉记忆锻炼软件 / Words learning and English muscle memory training software designed for keyboard workers 项目地址: …...