HIVE学习
1.什么是HIVE
1.HIVE是什么?
Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
大白话: HIVE就是一个类似于Navicat的可视化客户端,
2.HIVE本质
Hive是一个Hadoop客户端,用于将HQL(Hive SQL)转化成MapReduce程序。
(1)Hive中每张表的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce(也可配置为Spark或者Tez)
(3)执行程序运行在Yarn上
3.架构
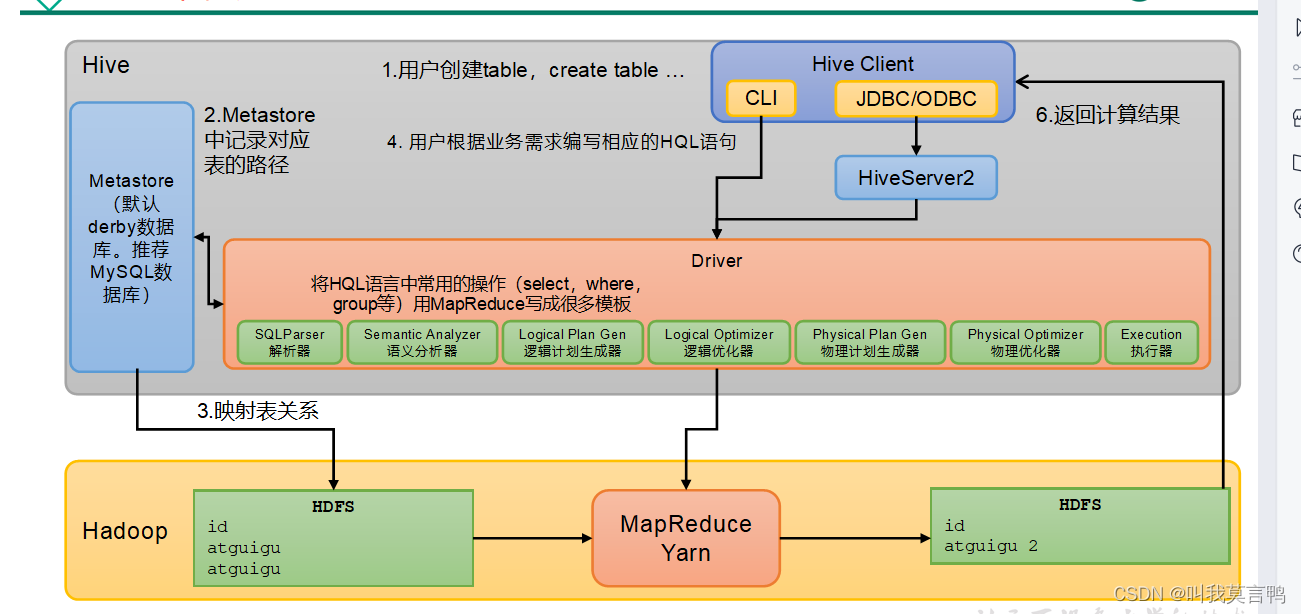
2.HIVE的配置
1.首先,如果我们只是想在LINUX本机上运行HIVE,是不需要配置任何配置文件的
2.当然,我们一般都需要修改一下使用的数据库 mysql安装就不多赘述了,这里说一下配置文件
2.1 Mysql配置到HIVE上
1.导入驱动包
lib文件夹就是专门存储包的目录
cp /opt/software/mysql-connector-java-5.1.37.jar $HIVE_HOME/lib
将MySQL的JDBC驱动拷贝到Hive的lib目录下。
2.修改配置文件
和连接池大差不差
URL DRIVER username password 工作目录
vim $HIVE_HOME/conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><!-- Hive默认在HDFS的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property>
</configuration>
3.初始化元数据库
bin/schematool -dbType mysql -initSchema -verbose
3.配置HiveServer2
1. 作用
Hive的hiveserver2服务的作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到Hiveserver2。
其实就是用真正的可视化软件连接HIVE,就需要这样
比如DataGrip
2.配置
因为在生产环境下,我们需要开启用户模拟功能(哪个用户访问HIVE,就用哪个用户去访问HADOOP,就跟QQ登录一样)
hivesever2的模拟用户功能,依赖于Hadoop提供的proxy user(代理用户功能),只有Hadoop中的代理用户才能模拟其他用户的身份访问Hadoop集群。因此,需要将hiveserver2的启动用户设置为Hadoop的代理用户
也就是说,用户必须自己拥有访问HADOOP的权利,HIVE才能模拟他去访问,这样就必须修改HADOOP的配置文件core-site.xml
- 配置1
<!--配置所有节点的atguigu用户都可作为代理用户-->
<property><name>hadoop.proxyuser.atguigu.hosts</name><value>*</value>
</property><!--配置atguigu用户能够代理的用户组为任意组-->
<property><name>hadoop.proxyuser.atguigu.groups</name><value>*</value>
</property><!--配置atguigu用户能够代理的用户为任意用户-->
<property><name>hadoop.proxyuser.atguigu.users</name><value>*</value>
</property>
- 配置2 hive-site.xml
<!-- 指定hiveserver2连接的host -->
<property><name>hive.server2.thrift.bind.host</name><value>hadoop102</value>
</property><!-- 指定hiveserver2连接的端口号 -->
<property><name>hive.server2.thrift.port</name><value>10000</value>
</property>
3. 测试
bin/beeline -u jdbc:hive2://hadoop102:10000 -n atguigu
下面是执行后的消息,如果没出现这个,回头看日志,不要只看Server2的,
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.3 by Apache Hive
0: jdbc:hive2://hadoop102:10000>
4.MetaStore服务
Hive的metastore服务的作用是为Hive CLI或者Hiveserver2提供元数据访问接口。
1. 2种模式
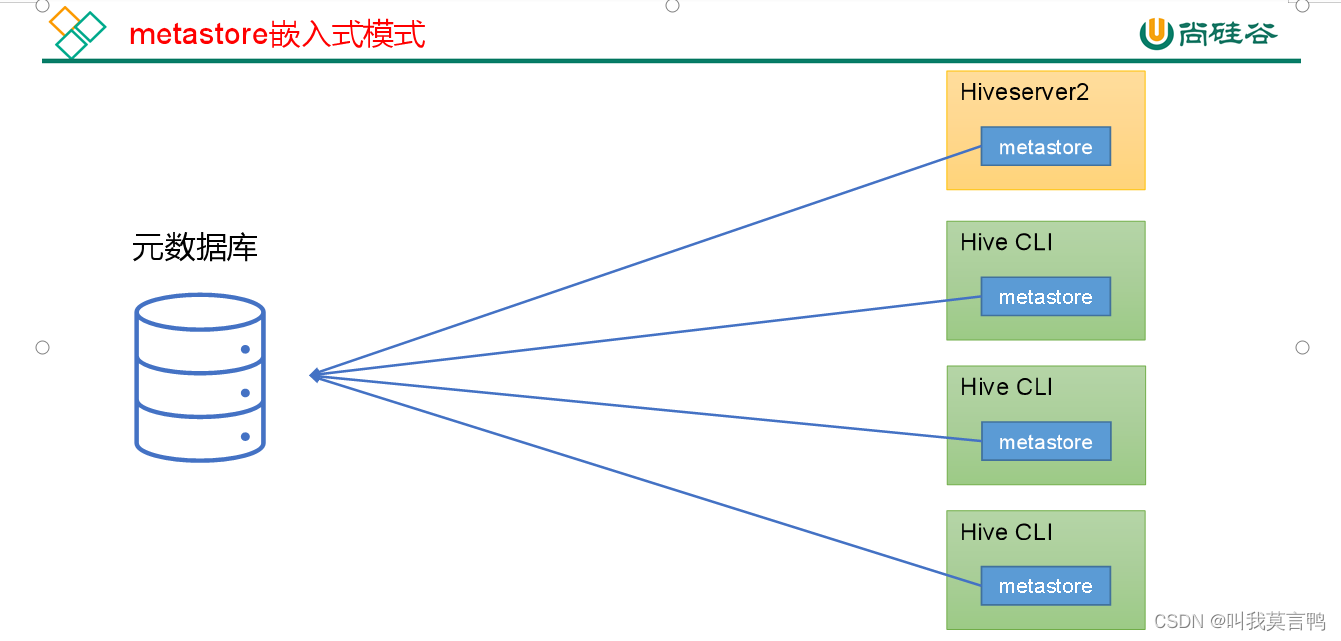
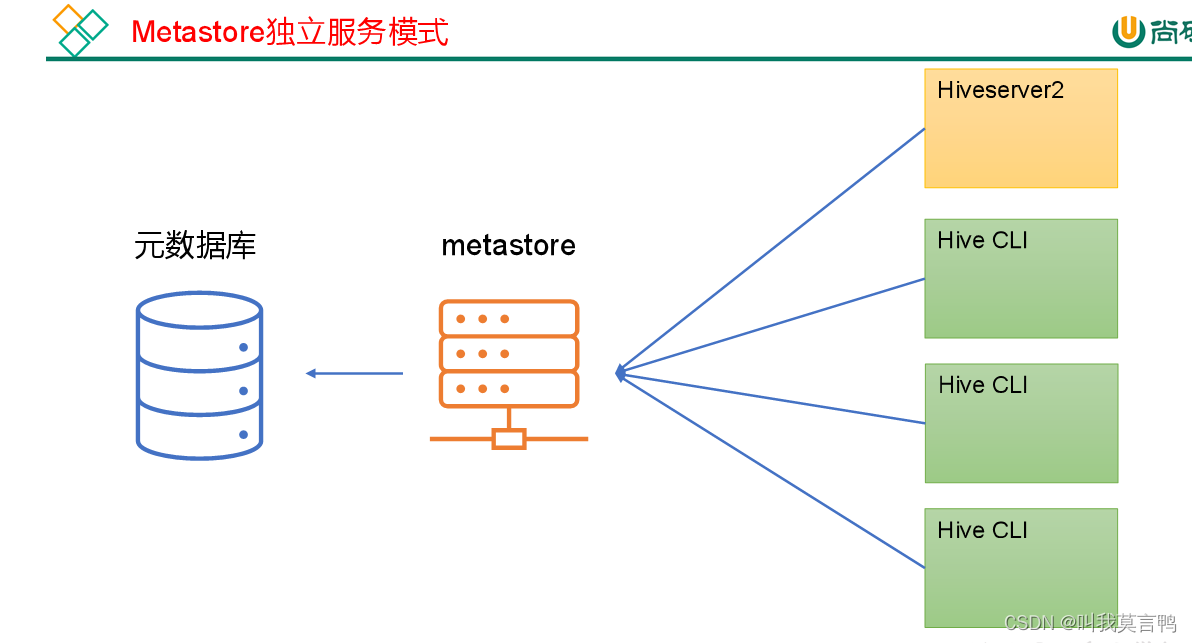
2. 两种模式的分析
- 嵌入式: 每个Hive CLI都直接连接元数据库
- 独立服务:都通过Metastore对源数据库信息访问
两者的区别
- 安全性 嵌入式都具有读写权限,过于危险,独立服务相对优秀
- IO压力 嵌入式元数据库一力承担IO压力,同时他要进行读写,所以对源数据库的要求过高,而独立服务将IO交给metastore来做,相对优秀
3.修改配置
嵌入式,只要保证HIVE能连接数据库即可
- hive.site
<!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property>
- 独立服务模式单独添加(上面的还是要配的,必须连数据库)
注意:主机名需要改为metastore服务所在节点,端口号无需修改,metastore服务的默认端口就是9083。
<!-- 指定metastore服务的地址 -->
<property><name>hive.metastore.uris</name><value>thrift://hadoop102:9083</value>
</property>
4.测试
1.先启动metastore
在看数据库
hive --service metastore
3.配置相关
1.参数配置
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
1.查看参数配置
hive>set;
2.设置参数
命令行添加-hiveconf param=value
或者使用set 参数名=参数
如果没有"=参数", 就是查看这个参数
只是本次Hive有效,不是永久修改


2.日志配置
1.HIVE默认日志存储
Hive的log默认存放在/tmp/atguigu/hive.log目录下(当前用户名下)
2.修改Hive的log存放日志到/opt/module/hive/logs
[atguigu@hadoop102 conf]$ pwd
/opt/module/hive/conf[atguigu@hadoop102 conf]$ mv hive-log4j2.properties.template hive-log4j2.properties
3.修改日志存放位置
[atguigu@hadoop102 conf]$ vim hive-log4j2.properties// 修改的配置
property.hive.log.dir=/opt/module/hive/log
3.修改JVM堆内存设置
HIVE默认申请256M,需要改大
修改$HIVE_HOME/conf下的hive-env.sh.template为hive-env.sh
[atguigu@hadoop102 conf]$ pwd
/opt/module/hive/conf[atguigu@hadoop102 conf]$ mv hive-env.sh.template hive-env.sh
将hive-env.sh其中的参数 export HADOOP_HEAPSIZE修改为2048,重启Hive
# The heap size of the jvm stared by hive shell script can be controlled via:
export HADOOP_HEAPSIZE=2048
4.关闭HADOOP虚拟内存检查
什么是虚拟内存??虚拟内存就是当内存不够使用时, 将一部分硬件的物理磁盘拿出来当做内存,就叫虚拟内存.其实没啥用,
这个需要设置YARN,因为yarn是负责内存调度的 yarn-site.xml
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
相关文章:
HIVE学习
1.什么是HIVE 1.HIVE是什么? Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。 大白话: HIVE就是一个类似于Navicat的可视化客户端, 2.HIVE本质 Hive是一个Hadoop客户端&a…...

逆了个天了,阿里开源自然语言写SQL的神器级别工具快用起来
Chat2DB 是一款有开源免费的多数据库客户端工具,支持windows、mac本地安装,也支持服务器端部署,web网页访问。和传统的数据库客户端软件Navicat、DBeaver 相比Chat2DB集成了AIGC的能力,能够将自然语言转换为SQL,也可以…...

85. 最大矩形
题目描述 给定一个仅包含 0 和 1 、大小为 rows x cols 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。 示例 1: 输入:matrix [["1","0","1","0","0"],["1…...
Vue [Day5]
自定义指令 全局注册 和 局部注册 inserted在指令所在的元素 被插入到页面中时,触发 main.js import Vue from vue import App from ./App.vueVue.config.productionTip false// 1.全局注册指令 Vue.directive(focus, {// inserted在指令所在的元素 被插入到页…...

备战大型攻防演练,“3+1”一套搞定云上安全
在重大活动保障期间,企业不仅要面对愈发灵活隐蔽的新型攻击挑战,还要在人员、精力有限的情况下应对不分昼夜的高强度安全运维任务。如何在这种多重压力下,从“疲于应付”迈向“胸有成竹”呢? 知己知彼,百战不殆&#…...

网络_每日一学——网络的整体概述
今天我们将继续探讨网络相关的知识。网络是由许多设备互相连接而成的,可以传输数据的系统。通过网络,我们可以远程访问他人的计算机、浏览网页、发送电子邮件等。网络是信息时代中不可或缺的一部分。 在网络中,每个设备都有一个唯一的标识符…...

【ChatGPT 指令大全】怎么使用ChatGPT来帮我们写作
在数字化时代,人工智能为我们的生活带来了无数便利和创新。在写作领域,ChatGPT作为一种智能助手,为我们提供了强大的帮助。不论是作文、文章,还是日常函电,ChatGPT都能成为我们的得力助手,快速提供准确的文…...
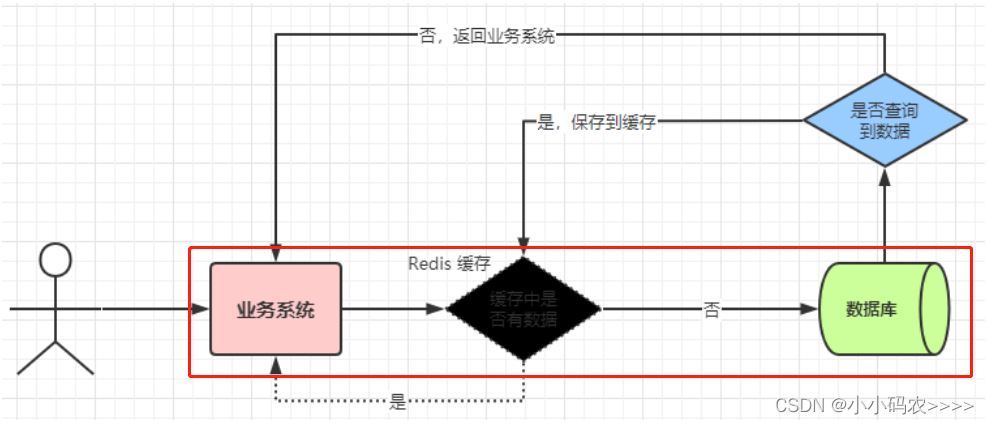
Redis 如何解决缓存雪崩、缓存击穿、缓存穿透难题
前言 Redis 作为一门热门的缓存技术,引入了缓存层,就会有缓存异常的三个问题,分别是缓存击穿、缓存穿透、缓存雪崩。我们用本篇文章来讲解下如何解决! 缓存击穿 缓存击穿: 指的是缓存中的某个热点数据过期了,但是此…...
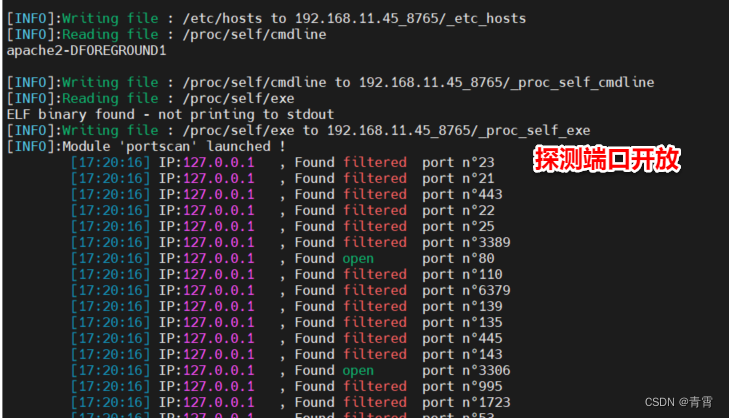
SSRF(服务器端请求伪造)漏洞
CSRF漏洞与SSRF漏洞的主要区别在于伪造目标的不同。 一、SSRF是什么 SSRF漏洞:(Server-Side Request Forgery,服务器端请求伪造)是一种由攻击者构造形成由服务端发起请求的一个安全漏洞。一般情况下,SSRF攻击的目标是从…...

【Axure动态面板】利用动态面板实现树形菜单的制作
利用动态面板,简单制作高保真的树形菜单。 一、先看效果 https://1poppu.axshare.com 二、实现思路 1、菜单无非就是收缩和展开,动态面板有个非常好的属性:fit to content,这个属性的含义是:面板的大小可以根据内容多少…...

Android 实现 RecyclerView下拉刷新,SwipeRefreshLayout上拉加载
上拉、下拉的效果图如下: 使用步骤 1、在清单文件中添加依赖 implementation ‘com.android.support:recyclerview-v7:27.1.1’ implementation “androidx.swiperefreshlayout:swiperefreshlayout:1.0.0” 2、main布局 <LinearLayout xmlns:android"http…...
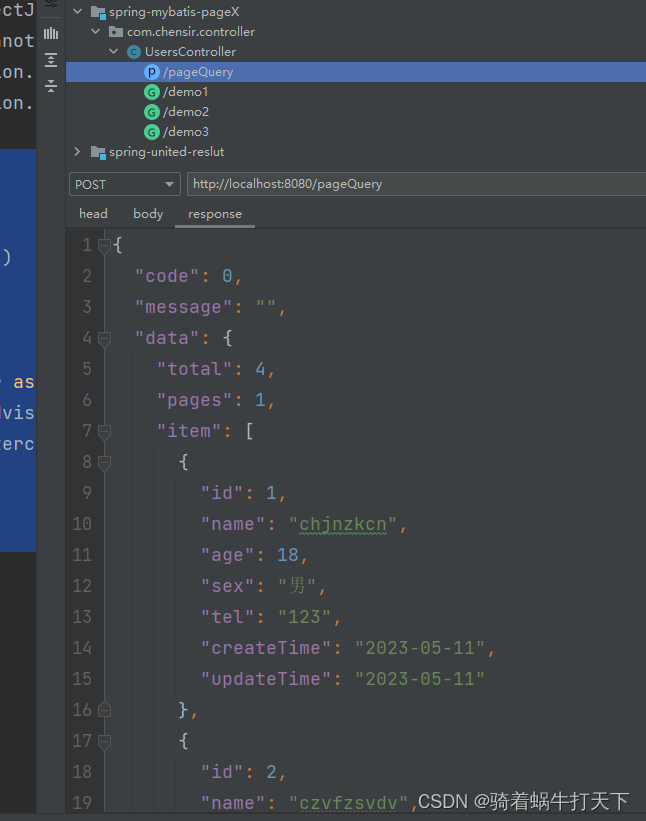
使用MethodInterceptor和ResponseBodyAdvice做分页处理
目录 一、需求 二、代码实现 父pom文件 pom文件 配置文件 手动注册SqlSessionFactory(MyBatisConfig ) 对象 实体类Users 抽象类AbstractQuery 查询参数类UsersQuery 三层架构 UsersController UsersServiceImpl UsersMapper UsersMapper.…...

WEB集群——LVS-DR 群集、nginx负载均衡
1、基于 CentOS 7 构建 LVS-DR 群集。 2、配置nginx负载均衡。 一、 LVS-DR 群集 1、LVS-DR工作原理 LVS-DR(Linux Virtual Server Director Server) 名称缩写说明 虚拟IP地址(Virtual IP Address) VIPDirector用于向客户端计算机提供服务的IP地址真实…...

倒计时87天!软考初级信息处理技术员2023下半年报名考试攻略
软考初级信息处理技术员2023下半年报名条件: 1、凡遵守中华人民共和国宪法和各项法律,恪守职业道德,具有一定计算机技术应用能力的人员,均可根据情况报名参加相应专业类别、级别的考试。 2、获准在中华人民共和国境内就业的外籍…...
【腾讯云 Cloud Studio 实战训练营】使用Cloud Studio构建SpringSecurity权限框架
1.Cloud Studio(云端 IDE)简介 Cloud Studio 是基于浏览器的集成式开发环境(IDE),为开发者提供了一个永不间断的云端工作站。用户在使用 Cloud Studio 时无需安装,随时随地打开浏览器就能在线编程。 Clou…...
c语言每日一练(4)
五道选择题 1、有以下代码,程序的输出结果是( ) #include <stdio.h> int main() {int a 0, b 0;for (a 1, b 1; a < 100; a){if (b > 20) break;//1if (b % 3 1)//2{b b 3;continue;}b b-5;//3}printf("%d\n", a);return 0; } A.1…...

VB字符转换
都是类型转换,转换成数值类型 VAL是根据情况来系统自动决定转换成什么类型, CDbl是转换成双精度浮点数据类型 VB中C带头的强制转换函数有: CBool(expression) ---- 转换成布尔型 CByte(expression) ---- 转换成字节型 CCur(expression) --…...
【C++进阶之路】map与set的基本使用
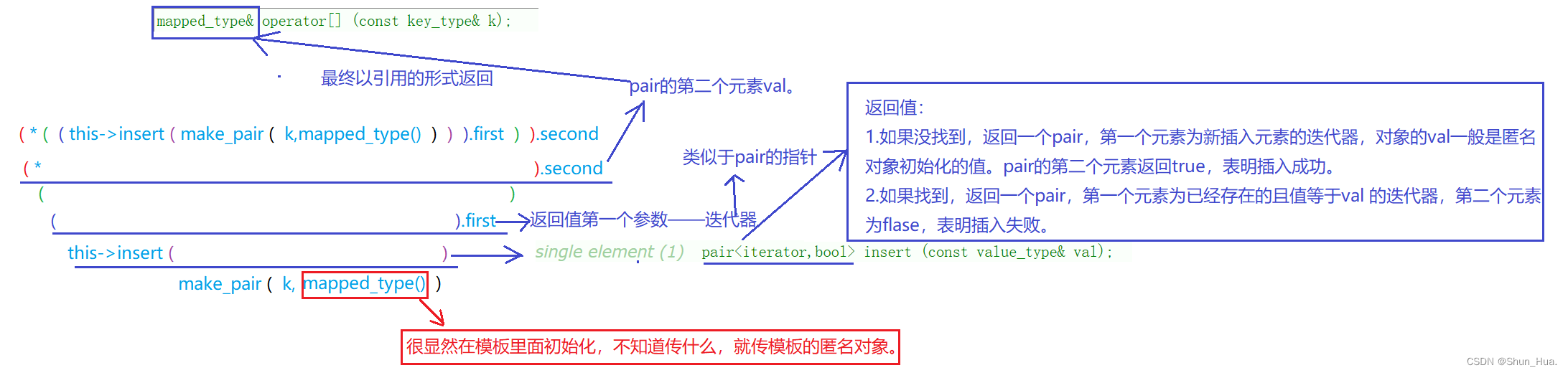
文章目录 一、set系列1.set①insert②find③erase④lower_bound与upper_bound 2.multiset①count②equal_range 二、map系列1.map①insert1.插入pair的四种方式2.常用两种方式 ②[]2.multimap①count②equal_range 一、set系列 1.set ①insert 函数分析(C98&…...

代码随想录算法训练营day56
文章目录 Day56两个字符串的删除操作题目思路代码 编辑距离题目思路代码 Day56 两个字符串的删除操作 583. 两个字符串的删除操作 - 力扣(LeetCode) 题目 给定两个单词 word1 和 word2,找到使得 word1 和 word2 相同所需的最小步数&#…...

通话降噪算法在手机和IOT设备上的应用和挑战
随着电子产品的升级换代,用户对通话质量的要求也越来越高。通话降噪算法对通话质量起到了关键核心的作用。计算资源的提升使得深度学习模型在便携式的低功耗芯片上面跑起来了,器件成本降低让IoT设备开始使用骨导传感器,,那怎么样才…...

会议纪要整理不清?如何将会议成果转化为可落地任务
身边不少HR朋友都有过纪要整理的困扰,一场会议或面谈后,花费大量时间整理,最终产出的纪要却零散杂乱,无法提炼可落地的任务,导致会议效果大打折扣。结合半年多的实测体验,整理出一套零基础也能上手的高效方…...

深入解析Arm Cortex-A53 Cache架构:从原理到多核一致性与性能优化实践
1. 项目概述:为什么我们需要深入理解A53的Cache?在嵌入式系统和移动计算领域,Arm Cortex-A53处理器是一个绕不开的名字。作为Armv8-A架构下的“小核”常青树,它以其出色的能效比,广泛存在于从智能手表到智能电视&#…...

为什么你的Perplexity搜索总返回噪音结果?7步精准提示工程诊断流程
更多请点击: https://intelliparadigm.com 第一章:Perplexity搜索结果噪音现象的本质剖析 Perplexity 作为基于大语言模型的语义搜索引擎,其结果页中高频出现的“噪音”并非传统关键词匹配失准所致,而是源于其底层推理机制与用户…...

从RTL Viewer到仿真波形:用Quartus II给你的Verilog代码做一次‘可视化体检’
从RTL Viewer到仿真波形:用Quartus II给你的Verilog代码做一次‘可视化体检’ 在数字电路设计的浩瀚宇宙中,Verilog代码就像工程师手中的魔法咒语,但如何确认这些咒语真正转化成了预期的电路结构?Quartus II提供的RTL Viewer与仿真…...

非规则区域上空间分数阶偏微分方程的有限元方法【附仿真】
✨ 长期致力于空间分数阶导数、高维问题、有限元方法、非规则区域、非结构化网格、非光滑解研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)二维非规则…...

如何彻底掌控你的微信聊天记录:开源工具WeChatMsg的完整解决方案
如何彻底掌控你的微信聊天记录:开源工具WeChatMsg的完整解决方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trendin…...

明日方舟自动化助手MAA:3步解放双手,让游戏回归乐趣
明日方舟自动化助手MAA:3步解放双手,让游戏回归乐趣 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: ht…...

从ZEMAX到SOLIDWORKS:手把手教你搞定红外平行光管的跨软件光机设计流程
从ZEMAX到SOLIDWORKS:红外平行光管光机协同设计全流程解析 在光学工程领域,红外平行光管的设计往往需要跨越光学仿真与机械实现两大专业领域。这种"光机协同设计"过程既考验工程师对光学原理的理解,又要求熟练掌握专业软件间的数据…...

生态学家都在用的R包MixSIAR:手把手教你用贝叶斯模型搞定食物网溯源
生态数据分析实战:用MixSIAR实现贝叶斯食物网溯源 河口湿地的鱼类究竟以藻类还是陆源有机物为主要食物?这个看似简单的问题背后,隐藏着复杂的生态关系网络。传统稳定同位素分析方法虽然能提供部分答案,但当面对多个潜在食物源和不…...

UE5新手也能搞定的Niagara特效:用模板10分钟做出一个会动的烟雾
UE5 Niagara特效速成:10分钟打造动态烟雾的极简指南 第一次打开Unreal Engine的Niagara特效系统时,我被密密麻麻的节点和参数吓退了三次。直到发现模板库里的"Simple Sprite Burst",才意识到原来制作专业级特效可以如此简单——就像…...