深入JVM - JIT分层编译技术与日志详解
深入JVM - JIT分层编译技术与日志详解
文章目录
- 深入JVM - JIT分层编译技术与日志详解
- 1. 背景简介
- 2. JIT 编译器
- 2.1. 客户端版本的编译器: C1
- 2.2. 服务端版本的编译器: C2
- 2.3. Graal JIT 编译器
- 3. 分层编译技术(Tiered Compilation)
- 3.1. 汇聚两种编译器的优点
- 3.2. 精准优化(Accurate Profiling)
- 3.3. 代码缓存池(Code Cache)
- 3.4. 逆优化(Deoptimization)
- 4. 编译级别(Compilation Levels)
- 4.1. Level 0 - 解释后的代码
- 4.2. Level 1 - C1简单编译的代码
- 4.3. Level 2 - 受限后C1编译的代码
- 4.4. Level 3 - C1完全编译的代码
- 4.5. Level 4 - C2编译的代码
- 5. 编译器参数设置
- 5.1. 禁用分层编译
- 5.2. 设置各个层级编译的触发阈值(Threshold)
- 6. 方法编译
- 6.1. 编译日志格式
- 6.2. 演示代码
- 6.3. 解读编译日志
- 6.3.1. 时间戳
- 6.3.2. 级别1
- 6.3.3. 级别3
- 6.3.4. 级别4
- 6.3.5. 栈上替换
- 6.3.6. 级别4和栈上替换
- 6.3.7. 逆优化
- 6.3.8. 级别2
- 6.3.9. 再次优化
- 6.3.9. 方法退出
- 7. 小结
- 参考文档
1. 背景简介
JVM在运行时执行字节码(bytecode)有两种模式:
- 第一种是解释执行模式(interprets), 理论上执行速度较慢, 特别是大规模的循环和计算任务;
- 另一种是编译运行模式(JIT, just-in-time compilation, 即时编译), 可以大幅度提升性能, 平均有几十倍上百倍的提升比例。
java -version 命令, 输出内容中的 mixed mode, 就是这个意思。
看看JDK11的示例:
% java -version
java version "11.0.6" 2020-01-14 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.6+8-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.6+8-LTS, mixed mode)
输出内容中的 mixed mode 表示混合模式, 也就是混合使用 编译模式和解释模式。
再看看JDK8的示例:
$ java -versionopenjdk version "1.8.0_191"
OpenJDK Runtime Environment (build 1.8.0_191-b12)
OpenJDK 64-Bit Server VM (build 25.191-b12, mixed mode)
查看解释执行和编译执行的相关启动参数:
java -X...省略部分内容...-Xint 仅解释模式执行-Xmixed 混合模式执行(默认值)-Xcomp 在首次调用时强制编译方法-Xms<大小> 设置初始 Java 堆大小-Xmx<大小> 设置最大 Java 堆大小-Xdiag 显示附加诊断消息-Xinternalversion显示比 -version 选项更详细的 JVM版本信息-XshowSettings:all显示所有设置并继续-XshowSettings:vm显示所有与 vm 相关的设置并继续-XshowSettings:system(仅 Linux)显示主机系统或容器配置并继续-Xss<大小> 设置 Java 线程堆栈大小-Xverify 设置字节码验证器的模式在一般并发量的CRUD程序中, 两种方式在宏观上可能看不出明显的性能差异, 因为时间主要消耗在CPU之外的其他地方, 比如网络和IO交互之类的等待操作。
JIT编译器可以大幅提升程序性能, 分为两款;
- 一款称之为
客户端编译器(Client Complier), 设计目标是为了让Java程序快速启动; 主要使用场景是 AWT/Swing 之类的图形界面客户端; - 另一款称为
服务端编译器(Server Complier), 设计目标是为了在整体上有更好的性能表现; 顾名思义, 主要使用场景就是长时间持续运行的服务端系统。
在老一点的 Java 版本中, 我们可以通过启动参数, 明确指定 Hotspot JVM 使用哪一款即时编译器;
为了兼容更复杂的使用场景, 达成更好的性能表现, 从 Java 7 版本开始, 引入了分层编译技术(tiered compilation)。
本文先介绍这两款JIT编译器; 再详细介绍分层编译技术(Tiered Compilation)和其中的5种编译级别; 最后通过具体示例, 分析编译日志, 深入了解JIT编译的运行原理。
2. JIT 编译器
JIT 编译器, 也就是即时编译器(JIT compiler), 作用是将执行频率较高的字节码(bytecode)编译为本地机器码(native code)。
频繁执行的代码被称为 热点代码(hotspots), 这就是 Hotspot JVM 这个名字的由来。
通过即时编译技术, Java 程序的执行性能大幅提升, 和纯编译类型的语言相差不多。
当然, 在实际的软件开发实践中, 代码质量也是对性能影响很大的一个因素。
使用高级语言开发的复杂系统, 比起用低级语言开发, 在同样的 “开发成本” 下, 高级语言系统的综合质量要优越很多。
Hotspot JVM 提供了 2 种类型的JIT编译器:
- 客户端版本的编译器: C1
- 服务端版本的编译器: C2
2.1. 客户端版本的编译器: C1
客户端版本的编译器(client compiler), 技术领域称之为 C1(编译器1), 是JVM内置的一款即时编译器, 其中一个设计目标是为了让 Java应用启动更快完成. 所以会将字节码尽可能地优化, 并快速编译为机器代码.
最初, C1主要的应用场景是生命周期较短的客户端应用程序, 对这类应用而言, 启动时间是一个很重要的非功能性需求。
在 Java8 之前的版本中, 可以指定 -client 启动参数来设置 C1 编译器, 但在Java8以及更高的Java版本中, 这个参数就没有任何作用了, 保留下来只是为了不报错, 以兼容之前的启动脚本。
验证命令:
java -client -version
2.2. 服务端版本的编译器: C2
服务端版本的编译器(server compiler), 技术领域称之为 C2(编译器2), 是一款性能更好的, JVM内置的即时编译器(JIT compiler), 适用于生命周期更长的应用程序, 主要的使用场景就是服务端应用。
C2会监测和分析编译后的代码执行情况, 通过这些分析数据, 就可以生成和替换为更优化的机器代码。
在Java8之前的版本中, 需要指定 -server 启动参数来设置 C2 编译器, 但在 Java8 以及更高的Java版本中, 这个参数就没有任何作用了, 保留下来也是为了不报错。
验证命令:
java -server -version
输出内容和前面的client模式没有
2.3. Graal JIT 编译器
Java 10及之后的版本, 开始支持 Graal JIT 编译器, 这是一款可以平替 C2 的编译器。
其特征是既支持即时编译模式(just-in-time compilation mode), 也支持预先编译模式(ahead-of-time compilation mode)。
预先编译模式就是在程序启动之前, 将Java字节码全部编译为本地代码。
3. 分层编译技术(Tiered Compilation)
相比C1编译器, 对同一个方法进行编译时, C2编译器需要消耗更多CPU和内存资源, 但可以生成高度优化,性能卓越的本地代码。
从Java 7 版本开始, JVM引入了分层编译技术, 目标是综合利用 C1 和 C2, 实现快速启动和长期高效运行之间的平衡。
3.1. 汇聚两种编译器的优点
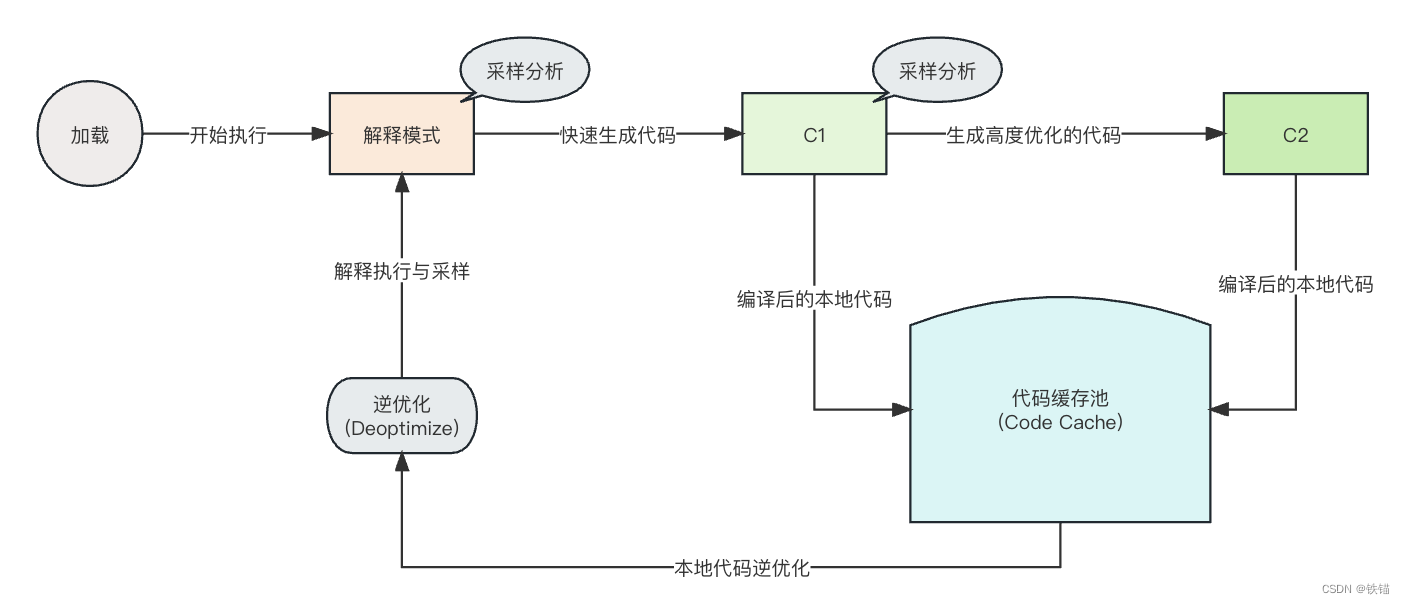
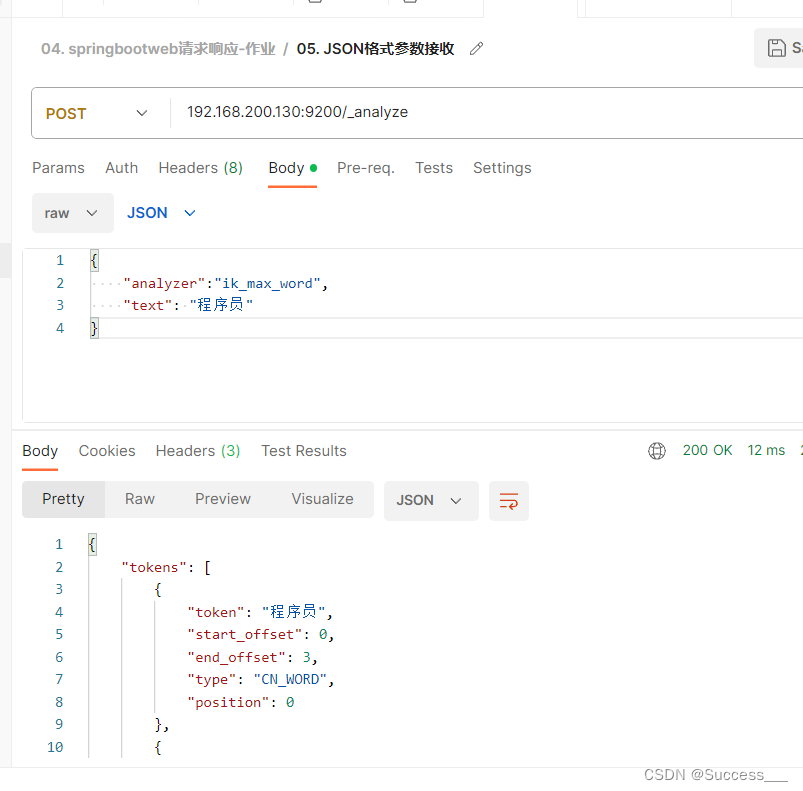
分层编译的整个过程如下图所示:

第一阶段:
应用启动之后, JVM先是解释执行所有的字节码, 并采集方法调用相关的各种信息。
接下来, JIT 编译器对采集到的数据进行分析, 找出热点代码。
第二阶段:
启动C1, 将频繁执行的方法, 快速编译为本地机器码。
第三阶段:
收集到足够的信息以后, C2介入;
C2会消耗一定的CPU时间来进行编译, 采用更激进的方式, 将代码重新编译为高度优化的本地机器码, 以提高性能。
总体来看, C1 快速提高代码执行效率, C2基于热点代码进行分析, 让编译后的本地代码性能再次提升。
3.2. 精准优化(Accurate Profiling)
分层编译的另一个好处, 是可以更准确地分析代码。
在没有分层编译的Java版本中, JVM只能在解释期间采集需要的优化信息。
有了分层编译后, JVM还在 C1 编译后的代码执行过程中采集信息。 由于编译后的代码具备了更好的性能, 也就可以容忍JVM执行更多的数据分析采样。
3.3. 代码缓存池(Code Cache)
Code cache 是JVM中的一块内存区域, 用来存储JIT编译后生成的所有本地机器码。
使用分层编译技术, 代码缓存需要的内存使用量, 增长到了原来的4倍左右。
Java 9 以及之后的版本, 将 JVM 的代码缓存池分成三块区域:
- 非Java方法使用的代码缓存区(non-method): 存储 JVM 内部的本地代码; 默认大小是 5 MB 左右, 可通过启动参数
-XX:NonNMethodCodeHeapSize指定。 - 带信息收集的代码缓存区(profiled-code): 存放 C1 编译后的本地代码; 一般来说这部分代码的存活周期并不长, 默认大小是 122 MB 左右, 可通过启动参数
-XX:ProfiledCodeHeapSize指定。 - 不带信息收集的代码缓存区(non-profiled): 存放 C2 编译和优化后的本地代码; 一般来说这部分代码的存活周期较长, 默认大小也是 122 MB 左右, 可通过启动参数
-XX:NonProfiledCodeHeapSize指定。
将代码缓存池拆分为多块, 整体性能提升了不少, 因为编译后相关的代码贴得更近(code locality), 并减少了内存碎片问题(memory fragmentation)。
- 代码贴近的相关信息可参考: Code Locality and the Ability To Navigate
3.4. 逆优化(Deoptimization)
虽然 C2 编译后是高度优化的本地代码, 一般会长时间留存, 但有时候也会发生逆优化操作。
结果就是对应的代码回退到 JVM 解释模式。
逆优化发生的原因是编译器的乐观预期被打破, 例如, 如果收集到的分析信息, 与方法的实际行为不匹配时:

在这个场景中, 一旦热点路径发生改变, JVM 就会逆优化之前编译过的, 内联优化的代码。
4. 编译级别(Compilation Levels)
JVM 内置了解释器, 以及2款JIT编译器, 共有5种可能的编译级别;
C1 可以在3种编译级别上操作, 这3种级别间的区别在于采样分析工作是否完成。
4.1. Level 0 - 解释后的代码
JVM启动之后, 解释执行所有的Java代码。 在这个初始阶段, 性能一般比不上编译语言。
但是, JIT编译器在预热阶段后启动, 并在运行时编译热代码。
JIT编译器通过分析 级别0(Level 0) 时期收集的采样信息来执行优化。
4.2. Level 1 - C1简单编译的代码
在 Level 1 这个级别, JVM使用C1编译器编译代码, 但不会进行任何分析数据采样。 JVM将级别1用于简单的方法。
很多方法没有什么复杂性, 即便是使用C2再编译一次也不会提升什么性能, 比如 Getter, Setter 之类的方法。
因此, JVM得出的结论是, 采集分析信息也无法优化性能, 所以采集了也没什么用, 干脆不植入采集逻辑。
4.3. Level 2 - 受限后C1编译的代码
在 Level 2 级别, JVM使用C1编译器编译代码, 并进行简单的采样分析。
当C2的待编译队列满了(受限), JVM就会使用这个级别。目标是尽快编译代码以提高性能。
稍后, JVM在 Level 3 级别重新编译代码, 附带完整的采样分析。
最后, 如果C2队列不再繁忙, JVM将在 Level 4 级别重新编译。
4.4. Level 3 - C1完全编译的代码
在 Level 3 级别, JVM使用 C1 编译出具有完整采样分析的代码。
级别3是 `默认编译路径`` 的一部分。
因此, 除了简单的方法, 或者编译器队列排满了, JVM在其他所有情况下都使用这个级别来编译。
JIT编译中最常见的场景, 是直接从解释后的代码(Level 0级) 跳到 Level 3 级别。
4.5. Level 4 - C2编译的代码
在 Level 4 这个级别, JVM使用C2来执行代码编译, 以获得最强的长期性能。
级别4也是 默认编译路径 的一部分。 除简单方法外, JVM用这个级别来编译其他的所有方法。
第4级代码被假定是完全优化后的代码, JVM将停止收集分析信息。
但是, 也有可能会取消优化并将其回退至 Level 0 级别。
5. 编译器参数设置
Java 8 版本之后, 默认启用了分层编译。 除非有说得过去的特殊理由, 否则不要禁用分层编译。
5.1. 禁用分层编译
通过设置 –XX:-TieredCompilation, 来禁用分级编译。
用减号(-TieredCompilation)禁用这个标志时, JVM就不会在编译级别之间转换。
所以还需要选择使用的JIT编译器: C1, 还是C2。
如果没有明确指定, JVM将根据CPU特征来决定默认的JIT编译器。
对于多核处理器或64位虚拟机, JVM将选择C2。
如果要禁用C2, 只使用C1, 不增加分析的性能损耗, 可以传入启动参数 -XX:TieredStopAtLevel=1。
要完全禁用JIT编译器, 使用解释器来运行所有内容, 可以指定启动参数 -Xint。 当然, 禁用JIT编译器会对性能产生一些负面影响。
某些情况下, 比如程序代码中使用了复杂的泛型组合, 由于JIT优化可能会擦除泛型信息, 这时候可以尝试禁用分层编译或者JIT编译。
对于并发量很小的简单CRUD程序而言, 因为CPU计算量在整个处理链路上的时间占比很小, 解释执行和编译执行的区别并不明显。
5.2. 设置各个层级编译的触发阈值(Threshold)
编译阈值(compile threshold), 是指在代码被编译之前, 方法调用需要到达的次数。
在分层编译的情况下, 可以为 2~4 的编译级别设置这些阈值。
例如, 我们可以将 Tier4 的阈值降低到1万: -XX:Tier4CompileThreshold=10000。
java -version 是一个探测JVM参数很好用的手段。
例如, 我们可以带上 -XX:+PrintFlagsFinal 标志来运行 java -version, 检查某个Java版本上的默认阈值,
Java 8 版本的参数示例如下:
java -XX:+PrintFlagsFinal -version | grep Thresholdintx BackEdgeThreshold = 100000 {pd product}intx BiasedLockingBulkRebiasThreshold = 20 {product}intx BiasedLockingBulkRevokeThreshold = 40 {product}
uintx CMSPrecleanThreshold = 1000 {product}
uintx CMSScheduleRemarkEdenSizeThreshold = 2097152 {product}
uintx CMSWorkQueueDrainThreshold = 10 {product}
uintx CMS_SweepTimerThresholdMillis = 10 {product}intx CompileThreshold= 10000 {pd product}intx G1ConcRefinementThresholdStep = 0 {product}
uintx G1SATBBufferEnqueueingThresholdPercent = 60 {product}
uintx IncreaseFirstTierCompileThresholdAt = 50 {product}
uintx InitialTenuringThreshold = 7 {product}
uintx LargePageHeapSizeThreshold = 134217728 {product}
uintx MaxTenuringThreshold = 15 {product}intx MinInliningThreshold = 250 {product}
uintx PretenureSizeThreshold = 0 {product}
uintx ShenandoahAllocationThreshold = 0 {product rw}
uintx ShenandoahFreeThreshold = 10 {product rw}
uintx ShenandoahFullGCThreshold = 3 {product rw}
uintx ShenandoahGarbageThreshold = 60 {product rw}
uintx StringDeduplicationAgeThreshold = 3 {product}
uintx ThresholdTolerance = 10 {product}intx Tier2BackEdgeThreshold = 0 {product}intx Tier2CompileThreshold = 0 {product}intx Tier3BackEdgeThreshold = 60000 {product}intx Tier3CompileThreshold = 2000 {product}intx Tier3InvocationThreshold = 200 {product}intx Tier3MinInvocationThreshold = 100 {product}intx Tier4BackEdgeThreshold = 40000 {product}intx Tier4CompileThreshold = 15000 {product}intx Tier4InvocationThreshold = 5000 {product}intx Tier4MinInvocationThreshold = 600 {product}openjdk version "1.8.0_191"
OpenJDK Runtime Environment (build 1.8.0_191-b12)
OpenJDK 64-Bit Server VM (build 25.191-b12, mixed mode)
Java 11 版本的参数示例如下:
java -XX:+PrintFlagsFinal -version | grep Thresholdintx BiasedLockingBulkRebiasThreshold = 20 {product} {default}intx BiasedLockingBulkRevokeThreshold = 40 {product} {default}
uintx CMSPrecleanThreshold = 1000 {product} {default}
size_t CMSScheduleRemarkEdenSizeThreshold = 2097152 {product} {default}
uintx CMSWorkQueueDrainThreshold = 10 {product} {default}
uintx CMS_SweepTimerThresholdMillis = 10 {product} {default}intx CompileThreshold = 10000 {pd product} {default}
double CompileThresholdScaling = 1.000000 {product} {default}
size_t G1ConcRefinementThresholdStep = 2 {product} {default}
uintx G1SATBBufferEnqueueingThresholdPercent = 60 {product} {default}
uintx IncreaseFirstTierCompileThresholdAt = 50 {product} {default}
uintx InitialTenuringThreshold = 7 {product} {default}
size_t LargePageHeapSizeThreshold = 134217728 {product} {default}
uintx MaxTenuringThreshold = 15 {product} {default}intx MinInliningThreshold = 250 {product} {default}
size_t PretenureSizeThreshold = 0 {product} {default}
uintx StringDeduplicationAgeThreshold = 3 {product} {default}
uintx ThresholdTolerance = 10 {product} {default}intx Tier2BackEdgeThreshold = 0 {product} {default}intx Tier2CompileThreshold = 0 {product} {default}intx Tier3AOTBackEdgeThreshold = 120000 {product} {default}intx Tier3AOTCompileThreshold = 15000 {product} {default}intx Tier3AOTInvocationThreshold = 10000 {product} {default}intx Tier3AOTMinInvocationThreshold = 1000 {product} {default}intx Tier3BackEdgeThreshold = 60000 {product} {default}intx Tier3CompileThreshold = 2000 {product} {default}intx Tier3InvocationThreshold = 200 {product} {default}intx Tier3MinInvocationThreshold = 100 {product} {default}intx Tier4BackEdgeThreshold = 40000 {product} {default}intx Tier4CompileThreshold = 15000 {product} {default}intx Tier4InvocationThreshold = 5000 {product} {default}intx Tier4MinInvocationThreshold = 600 {product} {default}java version "11.0.6" 2020-01-14 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.6+8-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.6+8-LTS, mixed mode)
主要关注以下几个 CompileThreshold 标志:
java -XX:+PrintFlagsFinal -version | grep CompileThreshold
intx CompileThreshold = 10000
intx Tier2CompileThreshold = 0
intx Tier3CompileThreshold = 2000
intx Tier4CompileThreshold = 15000
需要注意, 如果启用了分层编译, 那么通用的编译阈值参数 CompileThreshold = 10000 不再生效。
6. 方法编译
方法编译(method compilation)的生命周期如下图所示:
总体来说, 一个方法最初由 JVM 解释执行。 直到调用次数达到 Tier3CompileThreshold 指定的阈值。
达到阈值后, JVM就会使用C1编译器来编译该方法, 同时继续采集分析信息。
当方法调用次数达到 Tier4CompileThreshold 时, JVM使用C2编译器来编译该方法。
当然, JVM有可能会取消 C2编译器对代码的优化。 那么这个过程就可能会来回反复。
6.1. 编译日志格式
默认情况下, JVM 是禁止输出 JIT编译日志 的。 想要启用, 需要设置启动参数 -XX:+PrintCompilation。
编译日志的格式包括这些部分:
- 时间戳(Timestamp) – 编译时距离JVM启动时间的毫秒值。 很多JVM日志的时间都是这个相对时间。
- 编译ID(Compile ID) – 每个被编译的方法对应的自增ID。
- 属性状态(Attributes) – 编译任务对应的状态有5种可能的取值:
%– 栈上替换(On-stack replacement)s– 该方法是 synchronized 方法!– 方法中包含异常捕获块(exception handler)b– 阻塞模式(blocking mode)n– 本地方法标志(native method), 实际上编译的是包装方法
- 编译级别: 取值为
0到4 - 方法名称(Method name)
- 字节码大小(Bytecode size)
- 逆优化指示标志, 有2种可能的取值:
- 置为不可进入(made not entrant) – 比如发生标准的 C1 逆优化, 或者编译器的乐观推断错误。
- 置为僵死模式(made zombie) – 不再使用, 随时可清理, 垃圾收集器在释放 code cache 空间时的一种清理机制。
某一行编译日志样例如下:
# 这里为了排版进行了折行
2258 1324 % 4com.cncounter.demo.compile.TieredCompilation::main @ 2(58 bytes) made not entrant从左到右简单解读:
2258就是距离JVM启动的时间戳毫秒数;1324就是某一个方法对应的编译ID, 有多条编译记录的情况下, 可以用这个id来定位。%表示栈上替换;4表示编译级别是第4级别(取值0-4)com.cncounter.demo.compile.TieredCompilation::main表示方法@ 2这个不是必须的, 分析编译日志可以看到其他的数字, 总是和%栈上替换一起出现, 可能和栈内存槽位有关。(58 bytes)表示该方法对应的字节码为 58字节。made not entrant如果有这串字符, 就是逆优化指示标志。
JDK11执行的某一次编译日志样例可以参考文件: compile-log-sample.txt
6.2. 演示代码
下面通过一个具体的示例, 来展示方法编译的生命周期。
首先创建一个简单的 Formatter 接口:
package com.cncounter.demo.compile;public interface Formatter {<T> String format(T object) throws Exception;
}
然后创建一个 JSON 格式的简单实现类 JsonFormatter:
package com.cncounter.demo.compile;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.json.JsonMapper;public class JsonFormatter implements Formatter {private static final JsonMapper mapper = new JsonMapper();@Overridepublic <T> String format(T object) throws JsonProcessingException {return mapper.writeValueAsString(object);}
}
代码中对应的依赖可以到 https://mvnrepository.com 网站搜索:
- com.fasterxml.jackson.core
- com.fasterxml.jackson.dataformat
严格来说, 格式化和序列化是有区别的: 格式化=将对象转换为字符串; 序列化=将对象转换为字节序列。
再创建一个 XML 格式化的实现类 XmlFormatter:
package com.cncounter.demo.compile;import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.dataformat.xml.XmlMapper;public class XmlFormatter implements Formatter {private static final XmlMapper mapper = new XmlMapper();@Overridepublic <T> String format(T object) throws JsonProcessingException {return mapper.writeValueAsString(object);}}
以及一个简单的类 Article:
package com.cncounter.demo.compile;public class Article {private String name;private String author;public Article(String name, String author) {this.name = name;this.author = author;}public String getName() {return name;}public String getAuthor() {return author;}}
将这几个类准备好之后, 编写一个包含 main 方法的类, 来调用这两个格式化程序.
package com.cncounter.demo.compile;public class TieredCompilation {public static void main(String[] args) throws Exception {for (int i = 0; i < 1_000_000; i++) {Formatter formatter;if (i < 500_000) {formatter = new JsonFormatter();} else {formatter = new XmlFormatter();}formatter.format(new Article("Tiered Compilation in JVM", "CNC"));}}}
for循环中有 if 语句来判断循环次数, 先调用的是 JsonFormatter 实现, 一定次数之后, 调用的是 XmlFormatter 实现。
代码编写完成后, 执行程序时, 需要指定 JVM 启动参数 -XX:+PrintCompilation, 注意启动参数的加号(+)用来开启这个开关, 如果是减号(-)则表示关闭。
执行程序之后, 可以看到对应的编译日志。
JDK11执行的某一次编译日志样例可以参考文件: compile-log-sample.txt
6.3. 解读编译日志
提示: 多次执行同一个程序, 对应的编译日志可能都不一样, 需要具体情况具体分析。
输出的编译日志内容较多, 使用 JDK11 某一次执行的日志样例可以参考文件: compile-log-sample.txt
使用管道 | grep cncounter, 过滤出感兴趣的部分:
cat compile-log-sample.txt| grep cncounter1023 788 1 com.cncounter.demo.compile.Article::getName (5 bytes)
1025 789 1 com.cncounter.demo.compile.Article::getAuthor (5 bytes)1032 800 3 com.cncounter.demo.compile.JsonFormatter::<init> (5 bytes)
1032 801 3 com.cncounter.demo.compile.Article::<init> (15 bytes)
1041 820 3 com.cncounter.demo.compile.JsonFormatter::format (8 bytes)1122 903 4 com.cncounter.demo.compile.JsonFormatter::<init> (5 bytes)
1123 800 3 com.cncounter.demo.compile.JsonFormatter::<init> (5 bytes) made not entrant
1123 904 4 com.cncounter.demo.compile.Article::<init> (15 bytes)
1124 801 3 com.cncounter.demo.compile.Article::<init> (15 bytes) made not entrant1132 932 % 3 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes)
1133 933 3 com.cncounter.demo.compile.TieredCompilation::main (58 bytes)1146 905 4 com.cncounter.demo.compile.JsonFormatter::format (8 bytes)
1281 820 3 com.cncounter.demo.compile.JsonFormatter::format (8 bytes) made not entrant
1281 934 % 4 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes)
1285 932 % 3 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes) made not entrant1346 934 % 4 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes) made not entrant
1350 933 3 com.cncounter.demo.compile.TieredCompilation::main (58 bytes) made not entrant
1361 905 4 com.cncounter.demo.compile.JsonFormatter::format (8 bytes) made not entrant1543 1228 2 com.cncounter.demo.compile.XmlFormatter::<init> (5 bytes)
1546 1235 2 com.cncounter.demo.compile.XmlFormatter::format (8 bytes)1561 1298 % 3 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes)
1577 1310 3 com.cncounter.demo.compile.TieredCompilation::main (58 bytes)
1935 1324 % 4 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes)
1939 1298 % 3 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes) made not entrant2258 1324 % 4 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes) made not entrant
6.3.1. 时间戳
第一列表示时间戳; 表示距离JVM启动时间点的毫秒数, 可以看到编译日志输出的时间戳是有序的。
下面对其他部分进行简单的解读;
6.3.2. 级别1
最前面的2行编译日志对应 Article 类的 getName 和 getAuthor 方法:
1023 788 1 com.cncounter.demo.compile.Article::getName (5 bytes)
1025 789 1 com.cncounter.demo.compile.Article::getAuthor (5 bytes)
这两个get方法的实现很简单, 没什么优化空间。
回顾前面的知识点:
Level 1 这个级别, 表示 C1 简单编译的代码, JVM将级别1用于简单的方法。
6.3.3. 级别3
接下来的编译日志是级别3, 级别1到级别3对应的都是 C1编译器。
1032 800 3 com.cncounter.demo.compile.JsonFormatter::<init> (5 bytes)
1032 801 3 com.cncounter.demo.compile.Article::<init> (15 bytes)
1041 820 3 com.cncounter.demo.compile.JsonFormatter::format (8 bytes)
<init> 方法, 实际上就是编译器将 构造方法 和 实例初始化块 整合后生成的一个方法, 在创建对象时自动调用。
JsonFormatter 类的 format 方法也进入了级别3。
6.3.4. 级别4
接下来的编译日志是级别4, 级别4对应的是 C2编译器。
1122 903 4 com.cncounter.demo.compile.JsonFormatter::<init> (5 bytes)
1123 800 3 com.cncounter.demo.compile.JsonFormatter::<init> (5 bytes) made not entrant
1123 904 4 com.cncounter.demo.compile.Article::<init> (15 bytes)
1124 801 3 com.cncounter.demo.compile.Article::<init> (15 bytes) made not entrant
对应的方法是 <init>, 这个编译日志有点意思。
仔细看这部分日志, 可以发现, 每条级别4的编译日志之后, 都对应着一条低级别的不可进入标志(made not entrant);
原因很好理解, 升级了嘛, 老的就过时了(obsolete)。
6.3.5. 栈上替换
接下来的编译日志还是级别3。
1132 932 % 3 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes)
1133 933 3 com.cncounter.demo.compile.TieredCompilation::main (58 bytes)
这里的百分号(%)表示发生了栈上替换;
被编译的 main 方法, 正有某个线程在执行该方法, 所以发生了栈上替换。
6.3.6. 级别4和栈上替换
接下来的编译日志是级别4。
1146 905 4 com.cncounter.demo.compile.JsonFormatter::format (8 bytes)
1281 820 3 com.cncounter.demo.compile.JsonFormatter::format (8 bytes) made not entrant
1281 934 % 4 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes)
1285 932 % 3 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes) made not entrant
JsonFormatter::format 方法的编译升到了级别4, 前面介绍过。
栈上替换的 TieredCompilation::main 方法也升级到了级别4, 并将级别3的部分标记为不可进入。
6.3.7. 逆优化
接下来发生了一些预料之外的事情。
1346 934 % 4 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes) made not entrant
1350 933 3 com.cncounter.demo.compile.TieredCompilation::main (58 bytes) made not entrant
1361 905 4 com.cncounter.demo.compile.JsonFormatter::format (8 bytes) made not entrant
TieredCompilation::main 方法被JVM执行了逆优化;
回顾 main 方法的Java代码, 我们看到, 在执行了50万次循环之后, if 条件的结果改变了。
可能C2做了一些剪枝之类的激进优化, 乐观推断对应的前提条件不再有效, 于是JVM将优化过的代码回退到解释模式。
6.3.8. 级别2
接下来是 XmlFormatter 类的方法编译。
1543 1228 2 com.cncounter.demo.compile.XmlFormatter::<init> (5 bytes)
1546 1235 2 com.cncounter.demo.compile.XmlFormatter::format (8 bytes)
回顾一下, 级别2 - C1编译的受限代码;
在 Level 2 级别, JVM使用C1编译器编译代码, 并进行简单的采样分析。
可能是编译队列满了, 或者是被刚才的回退伤了心。 JVM 使用C1对 XmlFormatter::format 方法进行 Level2 的快速编译。
本次执行, 直到程序退出, 也没有对该类的方法继续优化。
6.3.9. 再次优化
又执行一段时间过后, main 方法再次升级了。
1561 1298 % 3 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes)
1577 1310 3 com.cncounter.demo.compile.TieredCompilation::main (58 bytes)
1935 1324 % 4 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes)
1939 1298 % 3 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes) made not entrant
这里先是发生了级别3的栈上替换, 以及级别3的编译。
然后又发生了级别4的栈上替换, 以及低级别栈上替换的过时标记。
6.3.9. 方法退出
最后, main 方法执行结束, 对应的方法栈也就不在了。
2258 1324 % 4 com.cncounter.demo.compile.TieredCompilation::main @ 2 (58 bytes) made not entrant
所以栈上替换的 Level 4 优化方法, 也被标记为不可进入。
7. 小结
本文简要介绍了 JVM 中的分层编译技术。
包括两种类型的JIT编译器, 以及分层编译技术如何组合使用他们, 以达成最佳效果。
还详细介绍了5种不同的编译级别, 以及相关的JVM调优参数。
最后是一个具体的案例, 通过打印和分析编译日志, 深入学习了Java方法编译和优化的整个生命周期。
相关的示例代码, 也可以参考: https://github.com/eugenp/tutorials/tree/master/core-java-modules/core-java-lang-4
参考文档
- https://www.baeldung.com/jvm-tiered-compilation
- https://docs.azul.com/prime/analyzing-tuning-warmup
- https://opensource.com/article/22/8/interpret-compile-java
- https://www.oracle.com/technical-resources/articles/java/architect-evans-pt1.html
- https://blog.joda.org/2011/08/printcompilation-jvm-flag.html
- https://gist.github.com/chrisvest/2932907
相关文章:
深入JVM - JIT分层编译技术与日志详解
深入JVM - JIT分层编译技术与日志详解 文章目录 深入JVM - JIT分层编译技术与日志详解1. 背景简介2. JIT 编译器2.1. 客户端版本的编译器: C12.2. 服务端版本的编译器: C22.3. Graal JIT 编译器 3. 分层编译技术(Tiered Compilation)3.1. 汇聚两种编译器的优点3.2. 精准优化(Ac…...
临时文档2
java 中 IO 流分为几种? 按照流的流向分,可以分为输入流和输出流;按照操作单元划分,可以划分为字节流和字符流;按照流的角色划分为节点流和处理流。 Java Io流共涉及40多个类,这些类看上去很杂乱,但实际…...
[深度学习入门]PyTorch深度学习[数组变形、批量处理、通用函数、广播机制]
目录 一、前言二、数组变形2.1 更改数组的形状2.1.1 reshape2.1.2 resize2.1.3 T(转置)2.1.4 ravel2.1.5 flatten2.1.6 squeeze2.1.7 transpose 2.2 合并数组2.2.1 append2.1.2 concatenate2.1.3 stack 三、批量处理四、通用函数4.1 math 与 numpy 函数的性能比较4.2 循环与向量…...

男孩向妈妈发脾气爸爸言传身教
近日,广东的一个家庭中发生了一件引人深思的事情。 一个男孩因为游戏没有通关,向妈妈发脾气,结果被爸爸发现并带到一边教育。 爸爸对孩子说:“她凭什么要承受你给的负能量,凭什么你心情不好就可以对着她发脾气…...

uniapp实现自定义导航内容高度居中(兼容APP端以及小程序端与胶囊对齐)
①效果图如下 1.小程序端与胶囊对齐 2.APP端内容区域居中 注意:上面使用的是colorui里面的自定义导航样式。 ②思路: 1.APP端和小程序端走不同的方法,因为小程序端要计算不同屏幕下右侧胶囊的高度。 2.其次最重要的要清晰App端和小程序端…...

Python调用外部电商API的详细步骤
Python是一种高级编程语言,非常适合用于集成API,即应用程序编程接口。API通常是由网站和各种软件提供的接口,可以让不同的程序之间进行数据交换和通信。在Python中调用API,可以帮助我们轻松地获取数据,并将其整合到我们…...
什么是NVME
1. 概念 NVM Express(NVMe),或称非易失性内存主机控制器接口规范(Non-Volatile Memory express),,是一个逻辑设备接口规范。他是与AHCI类似的、基于设备逻辑接口的总线传输协议规范(相当于通讯协议中的应用层…...

交叉编译驱动和应用出现警告提示错误“cc1:all warnings being treated as errors”解决方法
最近新玩的rk3588的板子,编译驱动时出现了警告提示错误“cc1:all warnings being treated as errors”,导致编译失败,仔细看了一下,就是内部出现了一个警告,一个未使用的变量出现的警告,导致了驱动编译失败,但是如果这样其他驱动会不会也这样,然后就写了一个printk的de…...
基于nodejs+vue+uniapp微信小程序的短视频分享系统
开发语言 node.js 框架:Express 前端:Vue.js 数据库:mysql 数据库工具:Navicat 开发软件:VScode 3.1小程序端 用户注册页面,输入用户的个人信息点击注册即可。 注册完成后会返回到登录页面,用户输入自己注…...
ElasticSearch:环境搭建步骤
1、拉取镜像 docker pull elasticsearch:7.4.0 2、创建容器 docker run -id --name elasticsearch -d --restartalways -p 9200:9200 -p 9300:9300 -v /usr/share/elasticsearch/plugins:/usr/share/elasticsearch/plugins -e "discovery.typesingle-node" elasti…...
剑指 Offer 37. 序列化二叉树
文章目录 题目描述简化题目思路分析 题目描述 请实现两个函数,分别用来序列化和反序列化二叉树。 你需要设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将…...
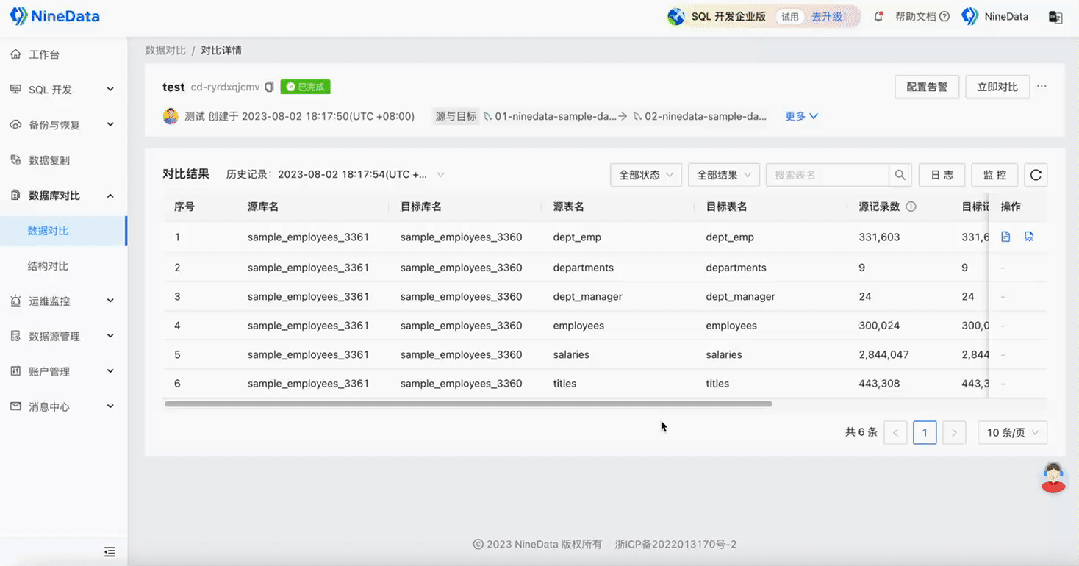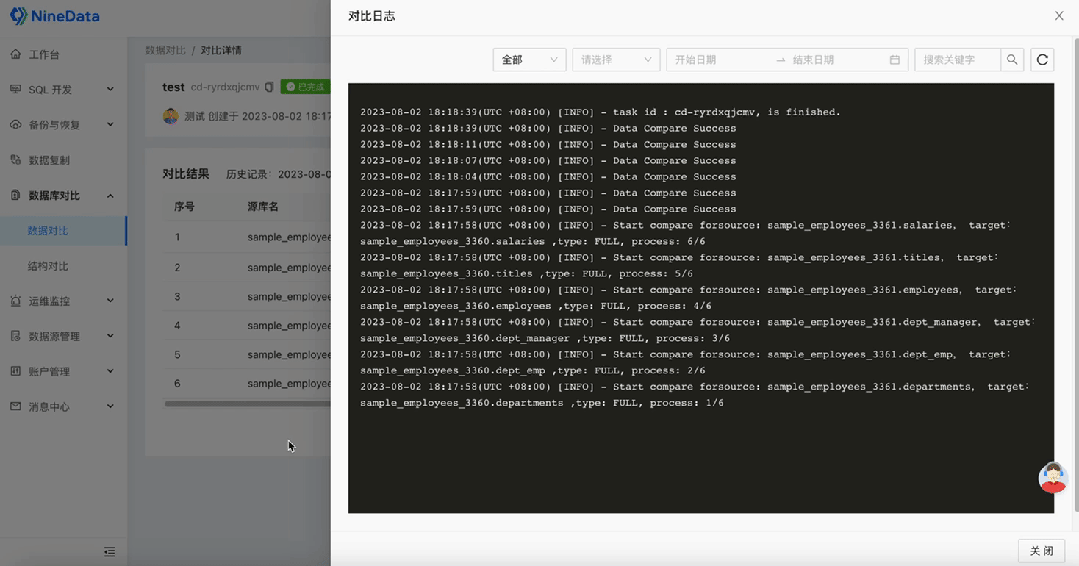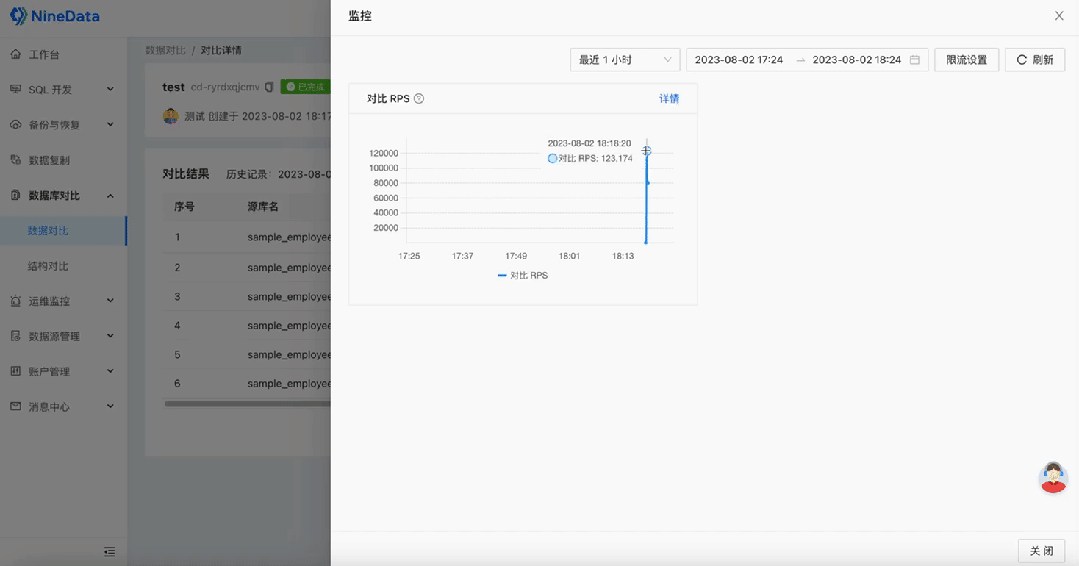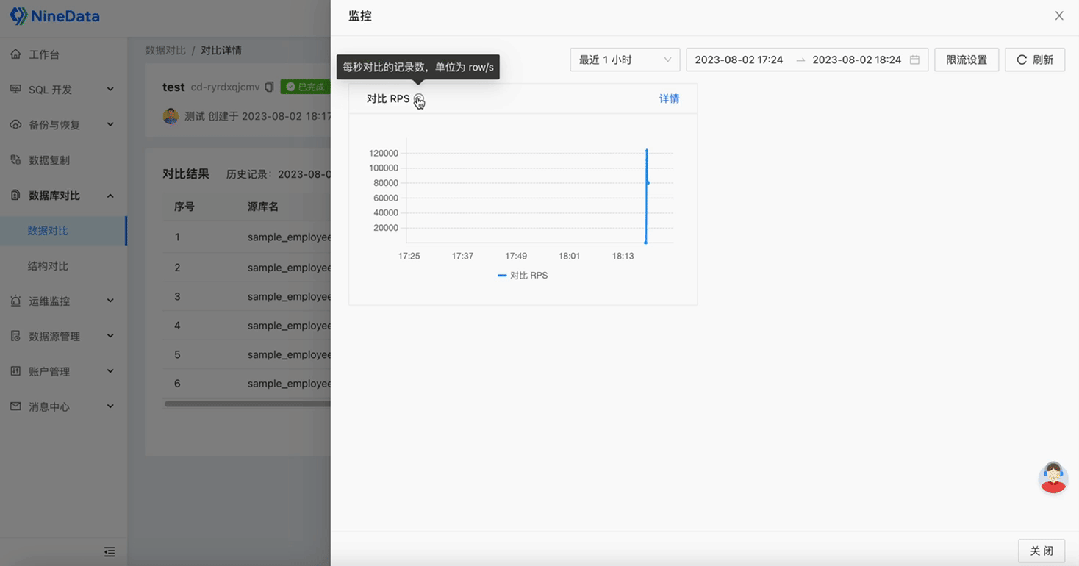
如何快速完成MySQL数据的差异对比|NineData
在现代商业环境中,数据库是企业存储核心数据的重要工具,而 MySQL 作为最受欢迎的关系型数据库管理系统,广泛应用于各行各业。在容灾、数据迁移、备份恢复等场景下,为了确保两端或多端之间数据的一致性,通常需要对数据进…...

Vue3项目中将html元素转换为word
下载插件 html转word插件 pnpm i --save html-docx-js-typescript生成临时链接 pnpm i file-saver代码部分 html部分,为要下载的部分用id做唯一标识 <div :id"mode-${chart.id}"><pre><VueShowdown :markdown"chart.content&quo…...
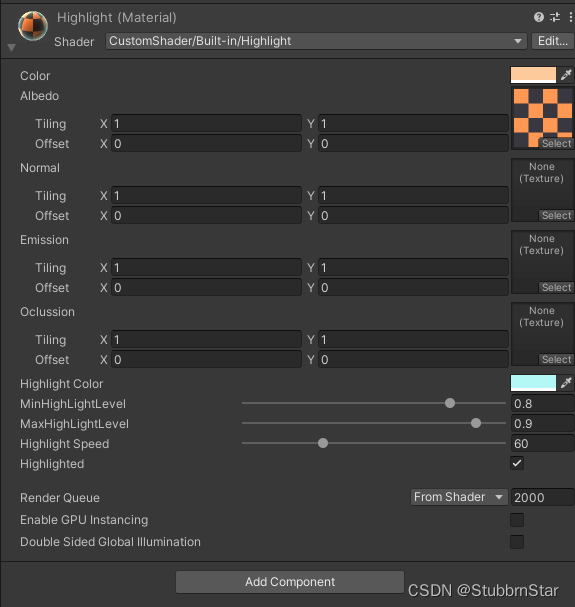
Unity-Shader-高亮Highlight
常用Shader-高亮,可动态调整高亮颜色、高亮强度范围/等级、高亮闪烁速度、高亮状态 Shader "CustomShader/Highlight" {Properties{_Color("Color", Color) (0.9044118,0.6640914,0.03325041,0)_Albedo("Albedo", 2D) "white…...

Linux操作系统(二):操作系统结构与内核设计
在(一)详解CPU中介绍了操作系统所基于的硬件CPU后,本部分学习操作系统的架构。在计算机系统中,操作系统的架构通常包括以下几个主要组件: 内核(Kernel) 进程管理(Process Management…...
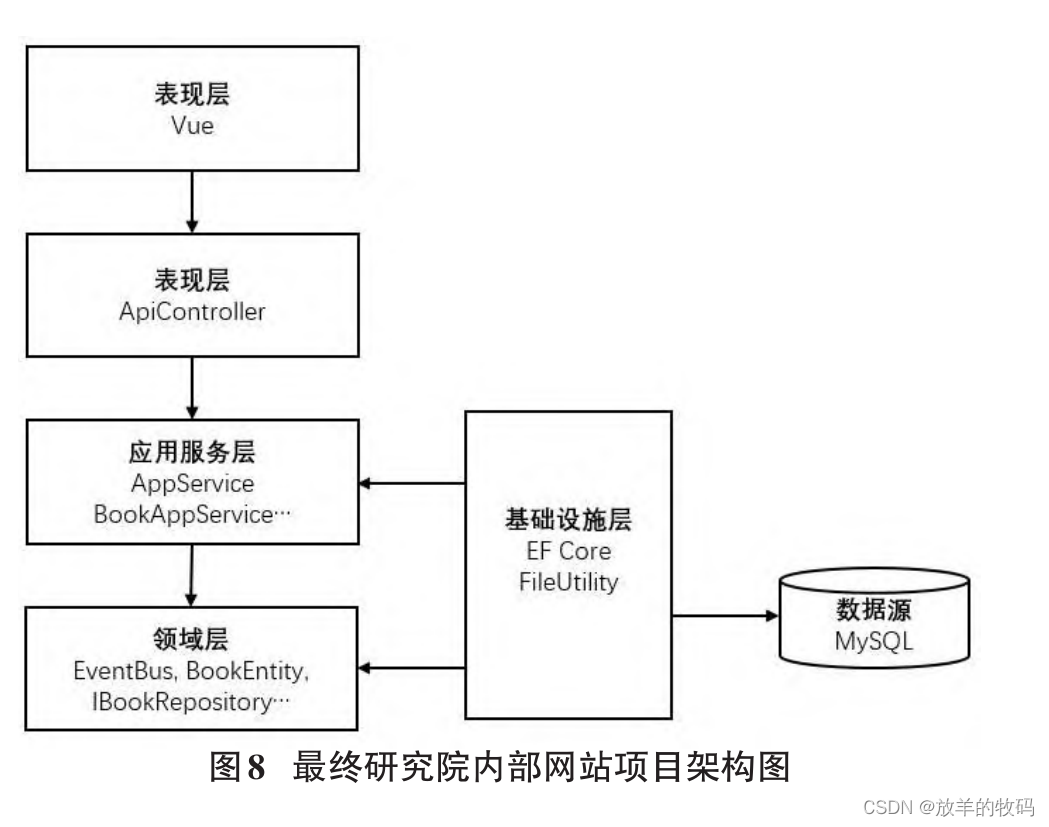
小研究 - 领域驱动设计DDD在IT企业内部网站开发中的运用(二)
在企业内部网站的建设过程中,网站后端最初采用传统的表模式的开发方式。这种方式极易导致站点的核心业务逻辑和业务规则分布在架构的各个层和对象中,这使得系统业务逻辑的复用性不高。为了解决这个问题,作者在后期的开发过程中引入了领域驱动…...

在Qt中实现鼠标监听与交互
文章目录 概述1. 包含头文件2. 实现鼠标事件函数3. 使用示例4. 应用场景 概述 鼠标监听是在Qt应用程序中实现用户交互的关键部分之一。通过捕获鼠标事件,您可以响应用户的点击、移动和释放动作,实现各种交互效果。本篇博文将详细介绍在Qt中如何进行鼠标…...

力扣hot100刷题记录
二刷hot100,坚持每天打卡!!! 1. 两数之和 // 先求差,再查哈希表 public int[] twoSum(int[] nums, int target) {Map<Integer,Integer> map new HashMap<>();for(int i 0;i<nums.length;i){int key …...

阿里云国际站视频直播服务是什么呢?
阿里云国际站视频直播是什么呢?下面一起来看一下: 视频直播服务(ApsaraVideo Live)是基于前瞻的内容接入、分发网络和大规模分布式实时转码技术打造的音视频直播平台,提供便捷接入、高清流畅、超低延时、高并发的音视频…...

python实现简单的爬虫功能
前言 Python是一种广泛应用于爬虫的高级编程语言,它提供了许多强大的库和框架,可以轻松地创建自己的爬虫程序。在本文中,我们将介绍如何使用Python实现简单的爬虫功能,并提供相关的代码实例。 如何实现简单的爬虫 1. 导入必要的…...
)
AIAgent架构中的多目标优化难题(工业级Agent系统92%失败源于此)
第一章:AIAgent架构中的多目标优化 2026奇点智能技术大会(https://ml-summit.org) 在现代AI Agent系统中,单一指标优化已无法满足复杂场景需求——响应延迟、推理准确性、资源消耗、用户意图对齐度与长期任务成功率往往相互冲突。多目标优化(…...

KP09 Encoder使用教程
注意:请不要同时将两个typec口接入数据线。 2026.3.22更新 汉化版VIAL改键软件,链接:VIAL汉化版——VIAL-JL – yoonas blog 2026.3.23更新 组合键设置 默认功能 1、默认键位 键盘有九个按键,两个旋钮,旋钮可以按下。上…...

算法面试通关秘籍:30场CV面试总结的深度学习要点
算法面试通关秘籍:30场CV面试总结的深度学习要点 大家好,我是资深AI讲师与学习规划师。专注计算机视觉教学与算法研发,过去三年我帮超过2500名有Python 基础的入门者,从"像素是什么"到"独立跑通CV项目"。今天…...

免费降AI率哪个好?嘎嘎降AI、比话降AI、率零实测推荐
免费降AI率哪个好?嘎嘎降AI、比话降AI、率零实测推荐 “免费降AI率到底用哪个好?”——这个问题最近被问烂了。 在各种毕业论文群里、知乎上、小红书上,到处都是这个问题。答案五花八门,有推荐这个的有推荐那个的,但大…...

如何使用 material-components-web 构建响应式 Material Design 排版系统
如何使用 material-components-web 构建响应式 Material Design 排版系统 【免费下载链接】material-components-web Modular and customizable Material Design UI components for the web 项目地址: https://gitcode.com/gh_mirrors/ma/material-components-web mater…...

PyFluent完整指南:如何用Python代码彻底改变你的CFD仿真工作流
PyFluent完整指南:如何用Python代码彻底改变你的CFD仿真工作流 【免费下载链接】pyfluent Pythonic interface to Ansys Fluent 项目地址: https://gitcode.com/gh_mirrors/pyf/pyfluent PyFluent作为Ansys Fluent的Python接口,为计算流体动力学工…...
)
华大HC32F460单片机工程搭建全流程(Keil MDK版,附资源包)
华大HC32F460单片机开发环境搭建实战指南(Keil MDK版) 第一次接触华大HC32F460系列单片机时,最令人头疼的莫过于工程搭建这个看似简单却暗藏玄机的环节。作为国产32位MCU中的佼佼者,HC32F460凭借其出色的性能和丰富的外设资源&…...

Earth Online网站下载ENVISAT ASAR数据:批量下载32景影像的实战经验与效率优化
Earth Online平台批量获取ENVISAT ASAR数据的工程化实践 当我们需要处理覆盖大区域或长时间序列的ENVISAT ASAR数据时,单景影像的手动下载方式会立即暴露出效率瓶颈。以一次典型的极地冰川监测项目为例,研究团队可能需要获取跨越5个冰盖区域、每季度2景的…...

ams OSRAM 将娱乐与工业灯具业务出售给 Ushio
事件核心摘要交易双方:ams OSRAM(卖方,奥地利/德国半导体巨头) vs. Ushio, Inc.(买方,日本光学技术公司)。交易内容:出售 Entertainment & Industry Lamps(娱乐与工业…...

Qwen-Image-Edit-2511-Unblur-Upscale应用场景:证件照、老照片、合影修复全搞定
Qwen-Image-Edit-2511-Unblur-Upscale应用场景:证件照、老照片、合影修复全搞定 1. 引言:图像修复的痛点与解决方案 你是否遇到过这样的困扰?珍贵的家庭老照片已经泛黄模糊,证件照因为拍摄条件限制显得不够清晰,或者…...