[深度学习入门]PyTorch深度学习[数组变形、批量处理、通用函数、广播机制]
目录
- 一、前言
- 二、数组变形
- 2.1 更改数组的形状
- 2.1.1 reshape
- 2.1.2 resize
- 2.1.3 T(转置)
- 2.1.4 ravel
- 2.1.5 flatten
- 2.1.6 squeeze
- 2.1.7 transpose
- 2.2 合并数组
- 2.2.1 append
- 2.1.2 concatenate
- 2.1.3 stack
- 三、批量处理
- 四、通用函数
- 4.1 math 与 numpy 函数的性能比较
- 4.2 循环与向量运算比较
- 五、广播机制
- 六、小结
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序
一、前言
本文为PyTorch深度学习中[Numpy基础]的下篇,主要讲解数组变形、批量处理、通用函数和广播机制的相关知识。
上期回顾:
深度学习入门PyTorch深度学习——Numpy基础 (上)
二、数组变形
在机器学习以及深度学习的任务中,通常需要将处理好的数据以模型能接收的格式输入给模型,然后由模型通过一系列的运算,最终返回一个处理结果。
然而,由于不同模型所接收的输人格式不一样,往往需要先对其进行一系列的变形和运算,从而将数据处理成符合模型要求的格式。在矩阵或者数组的运算中,经常会遇到需要 把多个向量或矩阵按某轴方向合并,或展平(如在卷积或循环神经网络中,在全连接层之前,需要把矩阵展平) 的情况。
下面介绍几种常用的数据变形方法。
2.1 更改数组的形状
修改指定数组的形状是Numpy中最常见的操作之一,常见的方法有很多,下表列出了一些常用函数。
| 函数 | 描述 |
|---|---|
| arr.reshape | 重新将向量arr维度进行改变,不修改向量本身 |
| arr.resize | 重新将向量arr 维度进行改变,修改向量本身 |
| arr.T | 对向量arr进行转置 |
| arr.ravel | 对向量arr进行展平,即将多维数组变成1维数组,不会产生原数组的副本 |
| arr.flatten | 对向量arr进行展平,即将多维数组变成1维数组,返回原数组的副本 |
| arr.squeeze | 只能对维数为1的维度降维。对多维数组使用时不会报错,但是不会产生任何影响 |
| arr.transpose | 对高维矩阵进行轴对换 |
下面,我们来看一些实例。
2.1.1 reshape
改变向量的维度(不修改向量本身):
import numpy as np
arr -np.arange(10)
print(arr)
#将向量arr维度变换为2行5列print(arr.reshape(2,5))
#指定维度时可以只指定行数或列数,其他用-1代替
print(arr.reshape(5,-1))
print(arr.reshape(-1,5))
输出结果:
[0 1 2 3 4 5 6 7 8 9]
[[0 1 2 3 4]
[5 6 7 8 9]]
[[0 1][2 3][4 5][6 7][8 9]]
[[0 1 2 3 4][5 6 7 8 9]]
值得注意的是,reshape函数不支持指定行数或列数,所以 -1在这里是必要的 。且所指定的行数或列数一定要能被整除,例如上面代码如果修改为arr.reshape(3,-1)即为错误的。
2.1.2 resize
改变向量的维度(修改向量本身):
import numpy as np
arr=np.arange(10)
print(arr)
#将向量arr维度变换为2行5列arr.resize(2,5)
print(arr)
输出结果:
[0 1 2 3 4 5 6 7 8 9]
[[0 1 2 3 4][5 6 7 8 9]]
2.1.3 T(转置)
向量转置:
import numpy as np
arr=np.arange(12).reshape(3,4)
#向量arr为3行4列
print(arr)
#将向量arr进行转置为4行3列
print(arr.T)
输出结果:
[[0 1 2 3][4 5 6 7][8 9 10 11]]
[[0 4 8][1 5 9][2 6 10][3 7 11]]
2.1.4 ravel
向量展平:
import numpy as np
arr=np.arange(6).reshape(2,-l)
print(arr)
# 并按照列优先,展平
print("按照列优先,展平")
print (arr.ravel('F"))
# 按照行优先,展平
print("按照行优先,展平")
print(arr.ravel())
输出结果:
[0 1 2 3 4 5]
# 按照列优先,展平
[ 0 3 1 4 2 5]
# 按照行优先,展平
[0 1 2 3 4 5]
2.1.5 flatten
把矩阵转换为向量,这种需求经常出现在卷积网络与全连接层之间。
import numpy as np
a=np.floor(10*np.random.random((3,4)))
print(a)
print(a.flatten())
输出结果:
[[4. 0. 8. 5.][1. 0. 4. 8.][8. 2. 3. 7.]]
[4. 0. 8. 5. 1. 0. 4. 8. 8. 2. 3. 7.]
2.1.6 squeeze
这是个主要用来降维的函数,把矩阵中含1的维度去掉。在PyTorch中还有一种与之相反的操作———torch.unsqueeze,这个后面再来介绍。
arr=np.arange(3).reshape(3,1)
print(arr.shape) #(3,1)
print(arr.squeeze().shape) #(3,)
arr1=np.arange(6).reshape(3,1,2,1)
print(arrl.shape) #(3,1,2,1)
print(arr1.squeeze().shape) #(3,2)
2.1.7 transpose
对高维矩阵进行轴对换,这个在深度学习中经常使用,比如把图片中表示颜色顺序的RGB改为GBR。
import numpy as np
arr2=np.arange(24).reshape(2,3,4)
print(arr2.shape) #(2,3,4)
print(arr2.transpose(1,2,0).shape) #(3,4,2)
2.2 合并数组
合并数组也是最常见的操作之一,下表列举了常见的用于数组或向量合并的方法。
| 函数 | 描述 |
|---|---|
| np.append | 内存占用大 |
| np.concatenate | 没有内存问题 |
| np.stack | 沿着新的轴加入一系列数组 |
| np.hstack | 堆栈数组垂直顺序(行) |
| np.vstack | 堆栈数组垂直顺序(列) |
| np.dstack | 堆栈数组按顺序深入(沿第3维) |
| np.vsplit | 将数组分解成垂直的多个子数组的列表 |
说明:
(1)append、concatenate 以及 stack 都有一个 axis参数,用于控制数组的合并方式是按行还是按列。
(2)对于append和 concatenate,待合并的数组必须有相同的行数或列数(满足一个即可)。
(3)stack 、hstack 、 dstack 要求待合并的数组必须具有相同的形状(shape)。下面选择一些常用函数进行说明。
2.2.1 append
合并一维数组:
import numpy as np
a=np.array([1,2,3])
b=np.array([4,5,6])
c=np.append(a,b)
print(c)
#[1 2 3 4 5 6]
合并多维数组:
import numpy as np
a=np.arange(4).reshape(2,2)
b=np.arange(4).reshape(2,2)
# 按行合并
c=np.append(a,b,axis=0)
print('按行合并后的结果')
print(c)
print('合并后数据维度',c.shape) # 按列合并
d=np.append(a,b,axis=l)
print('按列合并后的结果')
print(d)
print('合并后数据维度',d.shape)
输出结果:
按行合并后的结果
[[0 1][2 3][0 1][2 3]]
合并后数据维度 (4,2)
按列合并后的结果
[[0 1 0 1][2 3 2 3]]
合并后数据维度 (2,4)
2.1.2 concatenate
沿指定轴链接数组或矩阵:
import numpy as np
a=np.array([[1,2],[3,4]])
b=np.array([[5,6]])
c=np.concatenate((a,b),axis=0)
print(c)
d=np.concatenate((a,b.T),axis=1)
print(d)
输出结果:
[[12][3 4][5 6]]
[[1 2 5][3 4 6]]
2.1.3 stack
沿指定轴堆叠数组或矩阵:
import numpy as np
a=np.array([[1, 2],[3, 4]])
b=np.array([[5, 6],[7, 8]])
print(np.stack((a,b),axis=0))
输出结果:
[[[1 2][3 4]][[5 6][7 8]]]
三、批量处理
在深度学习中,由于源数据都比较大,所以通常需要用到批处理。如利用批量来计算梯度的随机梯度法(SGD)就是一个典型应用。深度学习的计算一般比较复杂,并且数据量一般比较大,如果一次处理整个数据,较大概率会出现资源瓶颈。
为了更有效地计算,一般将整个数据集分批次处理。与处理整个数据集相反的另一个极端是每次只处理一条记录。这种方法也不科学,一次处理一条记录无法充分发挥GPU、Numpy的平行处理优势。
因此,在实际使用中往往采用批量处理(Mini-Batch)的方法。
如何把大数据拆分成多个批次呢? 可采用如下步骤:
(1)得到数据集
(2)随机打乱数据
(3)定义批大小
(4)批处理数据集
下面我们通过一个示例来具体说明:
import numpy as np
# 生成10000个形状为2x3的矩阵
data_train=np.random.randn(10000,2,3)
#这是一个3维矩阵,第1个维度为样本数,后两个是数据形状print(data_train.shape)
# (10000,2,3)
# 打乱这10000条数据
np.random.shuffle(data_train)
# 定义批量大小
batch_size=100
# 进行批处理
for i in range(0,len(data_train),batch_size):x_batch_sum=np.sum(data_train[i:i+batch_size])print("第{}批次,该批次的数据之和:(}".format(i,x_batch_sum))
最后5行结果:
第9500批次,该批次的数据之和:17.63702580438092
第9600批次,该批次的数据之和:-1.360924607368387
第9700批次,该批次的数据之和:-25.912226239266445
第9800批次,该批次的数据之和:32.018136957835814
第9900批次,该批次的数据之和:2.9002576614446935
【说明】批次从0开始,所以最后一个批次是9900。
四、通用函数
Numpy提供了两种基本的对象,即 ndarray 和 ufunc 对象。前文已经介绍了ndarray,本节将介绍Numpy的另一个对象通用函数(ufunc)。
ufunc是universal function的缩写,它是一种能对数组的每个元素进行操作的函数。许多ufunc函数都是用C语言级别实现的,因此它们的计算速度非常快。此外,它们比 math 模块中的函数更灵活。
math模块的输入一般是标量,但Numpy中的函数可以是向量或矩阵,而利用向量或矩阵可以避免使用循环语句,这点在机器学习、深度学习中非常重要。
下表为Numpy中常用的几个通用函数。
| 函数 | 使用方法 |
|---|---|
| sqrt | 计算序列化数据的平方根 |
| sin,cos | 三角函数 |
| abs | 计算序列化数据的绝对值 |
| dot | 矩阵运算 |
| log,log10,log2 | 对数函数 |
| exp | 指数函数 |
| cumsum,cumproduct | 累计求和、求积 |
| sum | 对一个序列化数据进行求和 |
| mean | 计算均值 |
| median | 计算中位数 |
| std | 计算标准差 |
| var | 计算方差 |
| corrcoef | 计算相关系数 |
4.1 math 与 numpy 函数的性能比较
import time
import math
import numpy as npx=[i * 0.001 for i in np.arange (1000000)]
start=time.clock()
for i,t in enumerate(x):
x[i]=math.sin(t)
print("math.sin:",time.clock()-start)x=[i*0.001 for i in np.arange (1000000)]=np.array(x)
start=time.clock()np.sin(x)
print("numpy.sin:",time.clock()-start)
打印结果:
math.sin:0.5169950000000005
numpy.sin:0.05381199999999886
4.2 循环与向量运算比较
充分使用Python的 Numpy库中的内建函数(Built-in Function),来实现计算的向量化,可大大地提高运行速度。Numpy库中的内建函数使用了SIMD指令。如下使用的向量化要比使用循环计算速度快得多。如果使用GPU,其性能将更强大,不过Numpy不支持GPU…
PyTorch支持GPU,后面有机会将介绍PyTorch 如何使用GPU来加速算法。
import time
import numpy as np
x1=np.random.rand(1000000)
x2=np.random.rand(1000000)
# 使用循环计算向量点积
tic=time.process_time()
dot=0
for i in range(len(xl)):dot+=x1[i]*x2[i]
toc=time.process_time()
print("dot="+str(dot)+"\n for loop----- Computation time = " +str(1000*(toc-tic))+""ms "" )
# 使用numpy函数求点积
tic=time.process_time()
dot=0
dot=np.dot(x1,x2)
toc=time.process_time()
print("dot="+str(dot)+"\n verctor version---- Computation time = "+str(1000*(toc-tic))+"ms")
输出结果:
dot=250215.601995for loop----- Computation time=798.3389819999998 msdot=250215.601995
verctor version---- Computation time=1.885051999999554 ms
从运行结果上来看,使用for 循环的运行时间大约是向量运算的400倍。因此,在深度学习算法中,一般都使用向量化矩阵进行运算。
五、广播机制
Numpy 的 Universal functions 中要求输人的数组shape是一致的,当数组的shape不相等时,则会使用广播机制。不过,调整数组使得shape一样,需要满足一定的规则,否则将出错。这些规则可归纳为以下4条。
(1)让所有输入数组都向其中 shape最长的数组看齐,不足的部分则通过在前面加1补齐,如:
a: 2×3×2
b:3×2
则b向a看齐,在b的前面加1,变为:1×3×2
(2)输出数组的shape是输入数组shape的各个轴上的最大值;
(3)如果输人数组的某个轴和输出数组的对应轴的长度相同或者某个轴的长度为1时,这个数组能被用来计算,否则出错;
(4)当输入数组的某个轴的长度为1时,沿着此轴运算时都用(或复制)此轴上的第一组值。
广播在整个Numpy中用于决定如何处理形状迥异的数组,涉及的算术运算包括(+,-,*,/…)。这些规则说得很严谨,但不直观,下面我们结合图形与代码来进一步说明。
目的:A+B,其中A为4×1矩阵,B为一维向量( 3,)。
要相加,需要做如下处理:
根据规则1,B需要向看齐,把B变为(1,3 )
根据规则2,输出的结果为各个轴上的最大值,即输出结果应该为(4,3)矩阵,那么A如何由(4,1)变为(4,3)矩阵?B又如何由(1,3)变为(4,3)矩阵?
根据规则4,用此轴上的第一组值(要主要区分是哪个轴),进行复制(但在实际处理中不是真正复制,否则太耗内存,而是采用其他对象如ogrid对象,进行网格处理)即可,详细处理过程如下图所示。
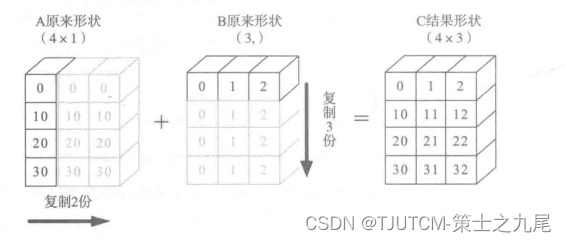
代码实现:
import numpy as np
A=np.arange(0,40,10).reshape(4,1)
B=np.arange(0,3)
print("A矩阵的形状:{},B矩阵的形状:{}",format(A.shape,B.shape))
C=A+B
print("c矩阵的形状:{}".format(C.shape))
print(C)
运行结果:
A矩阵的形状:(4,1),B矩阵的形状:(3,)
c矩阵的形状:(4,3)
[[0 1 2]
[10 11 12]
[20 21 22]
[30 31 32]]
六、小结
本章主要介绍了Numpy模块的常用操作,尤其涉及对矩阵的操作,这些操作在后续程序中经常使用。Numpy内容很丰富,这里只列了一些主要内容,如果你想了解更多内容,可登录Numpy的官网(http://www.Numpy.org/)查看更多内容。
最近在学习深度学习的优化算法,不知道大家想最先看哪一个…请在下方投个票吧!
相关文章:
[深度学习入门]PyTorch深度学习[数组变形、批量处理、通用函数、广播机制]
目录 一、前言二、数组变形2.1 更改数组的形状2.1.1 reshape2.1.2 resize2.1.3 T(转置)2.1.4 ravel2.1.5 flatten2.1.6 squeeze2.1.7 transpose 2.2 合并数组2.2.1 append2.1.2 concatenate2.1.3 stack 三、批量处理四、通用函数4.1 math 与 numpy 函数的性能比较4.2 循环与向量…...

男孩向妈妈发脾气爸爸言传身教
近日,广东的一个家庭中发生了一件引人深思的事情。 一个男孩因为游戏没有通关,向妈妈发脾气,结果被爸爸发现并带到一边教育。 爸爸对孩子说:“她凭什么要承受你给的负能量,凭什么你心情不好就可以对着她发脾气…...

uniapp实现自定义导航内容高度居中(兼容APP端以及小程序端与胶囊对齐)
①效果图如下 1.小程序端与胶囊对齐 2.APP端内容区域居中 注意:上面使用的是colorui里面的自定义导航样式。 ②思路: 1.APP端和小程序端走不同的方法,因为小程序端要计算不同屏幕下右侧胶囊的高度。 2.其次最重要的要清晰App端和小程序端…...

Python调用外部电商API的详细步骤
Python是一种高级编程语言,非常适合用于集成API,即应用程序编程接口。API通常是由网站和各种软件提供的接口,可以让不同的程序之间进行数据交换和通信。在Python中调用API,可以帮助我们轻松地获取数据,并将其整合到我们…...
什么是NVME
1. 概念 NVM Express(NVMe),或称非易失性内存主机控制器接口规范(Non-Volatile Memory express),,是一个逻辑设备接口规范。他是与AHCI类似的、基于设备逻辑接口的总线传输协议规范(相当于通讯协议中的应用层…...

交叉编译驱动和应用出现警告提示错误“cc1:all warnings being treated as errors”解决方法
最近新玩的rk3588的板子,编译驱动时出现了警告提示错误“cc1:all warnings being treated as errors”,导致编译失败,仔细看了一下,就是内部出现了一个警告,一个未使用的变量出现的警告,导致了驱动编译失败,但是如果这样其他驱动会不会也这样,然后就写了一个printk的de…...
基于nodejs+vue+uniapp微信小程序的短视频分享系统
开发语言 node.js 框架:Express 前端:Vue.js 数据库:mysql 数据库工具:Navicat 开发软件:VScode 3.1小程序端 用户注册页面,输入用户的个人信息点击注册即可。 注册完成后会返回到登录页面,用户输入自己注…...
ElasticSearch:环境搭建步骤
1、拉取镜像 docker pull elasticsearch:7.4.0 2、创建容器 docker run -id --name elasticsearch -d --restartalways -p 9200:9200 -p 9300:9300 -v /usr/share/elasticsearch/plugins:/usr/share/elasticsearch/plugins -e "discovery.typesingle-node" elasti…...
剑指 Offer 37. 序列化二叉树
文章目录 题目描述简化题目思路分析 题目描述 请实现两个函数,分别用来序列化和反序列化二叉树。 你需要设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将…...
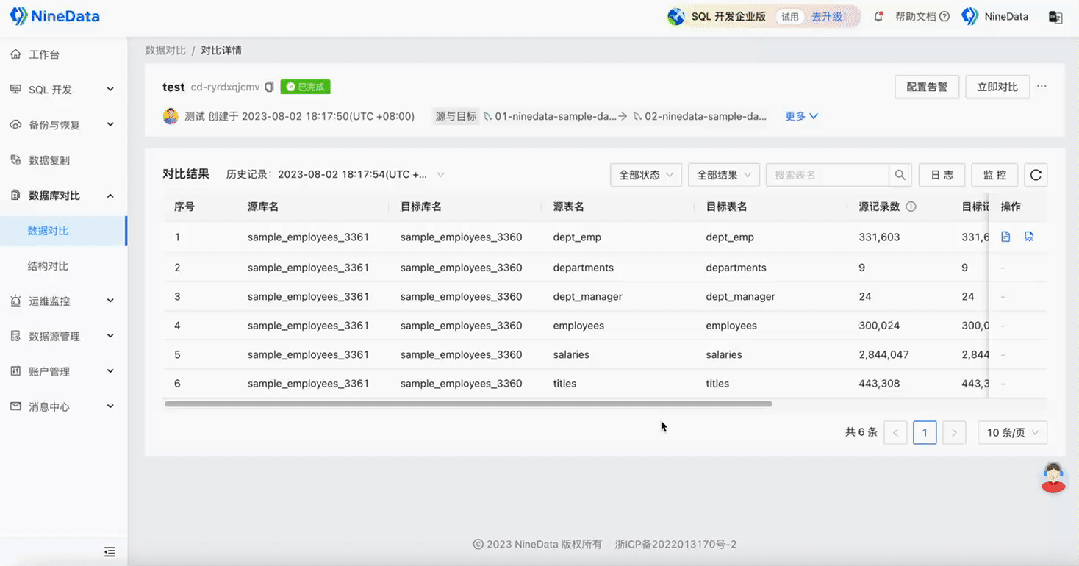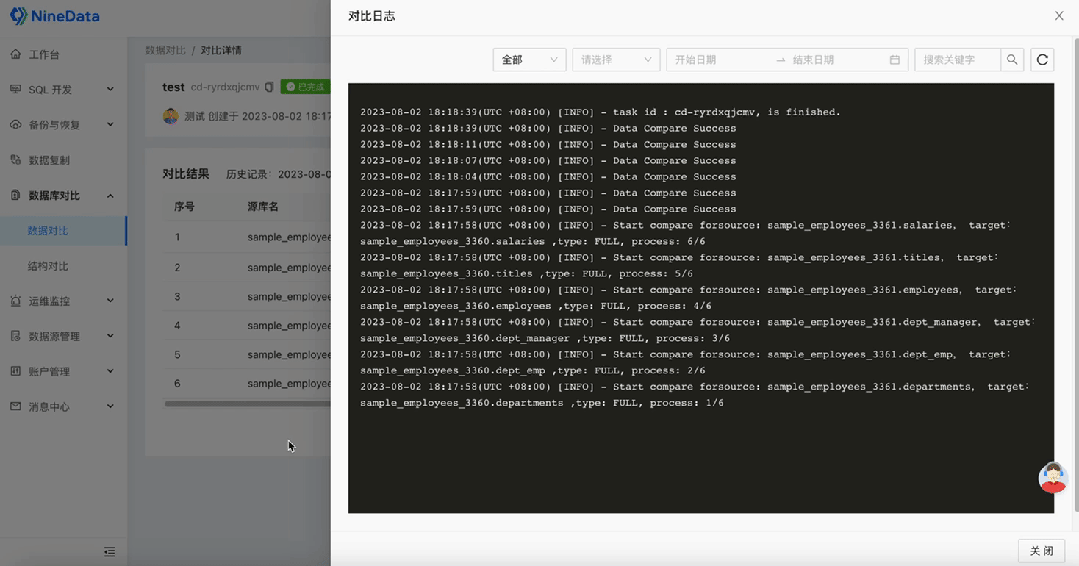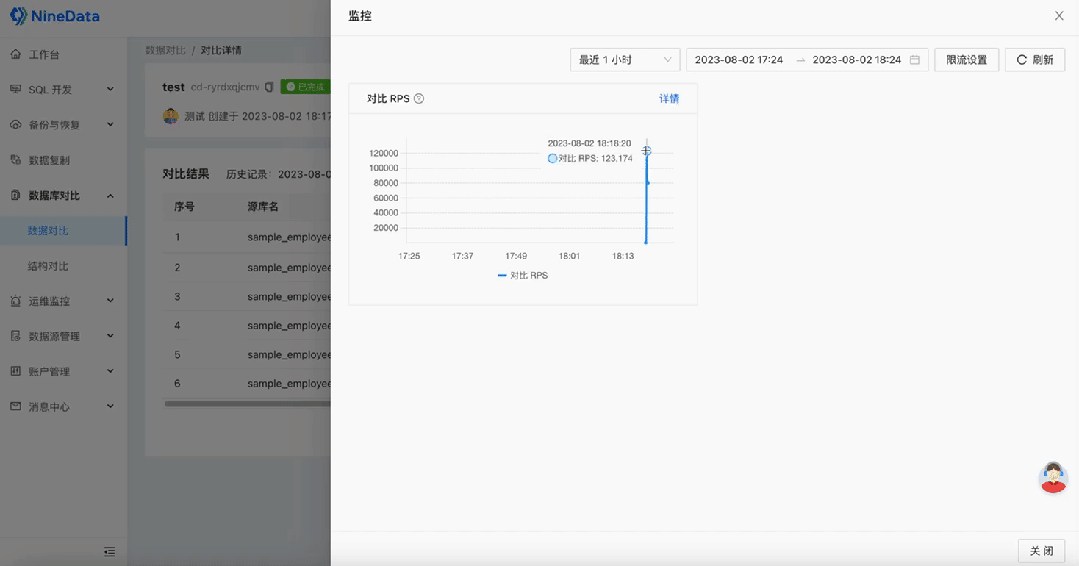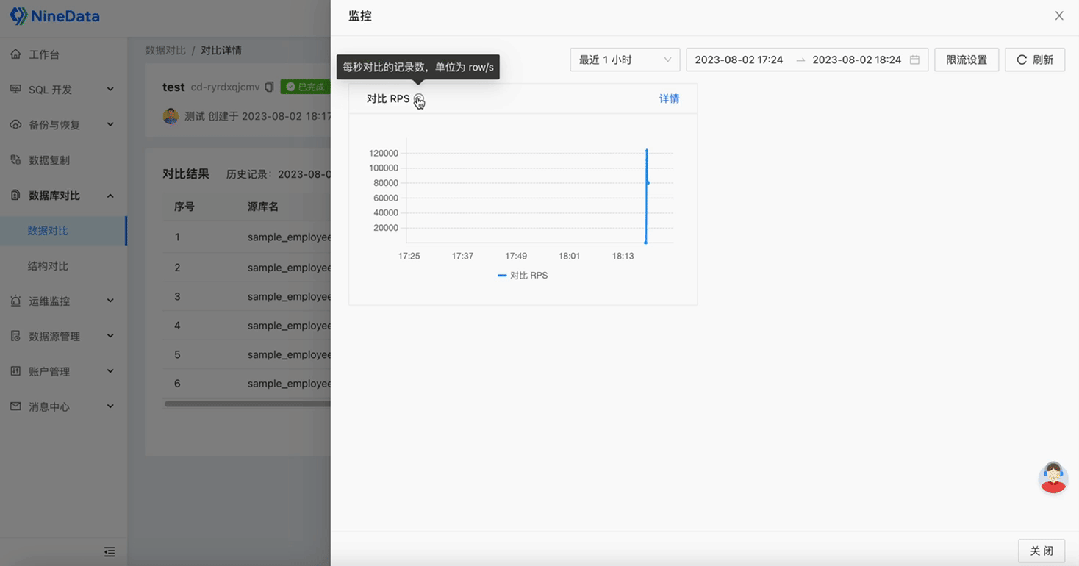
如何快速完成MySQL数据的差异对比|NineData
在现代商业环境中,数据库是企业存储核心数据的重要工具,而 MySQL 作为最受欢迎的关系型数据库管理系统,广泛应用于各行各业。在容灾、数据迁移、备份恢复等场景下,为了确保两端或多端之间数据的一致性,通常需要对数据进…...

Vue3项目中将html元素转换为word
下载插件 html转word插件 pnpm i --save html-docx-js-typescript生成临时链接 pnpm i file-saver代码部分 html部分,为要下载的部分用id做唯一标识 <div :id"mode-${chart.id}"><pre><VueShowdown :markdown"chart.content&quo…...
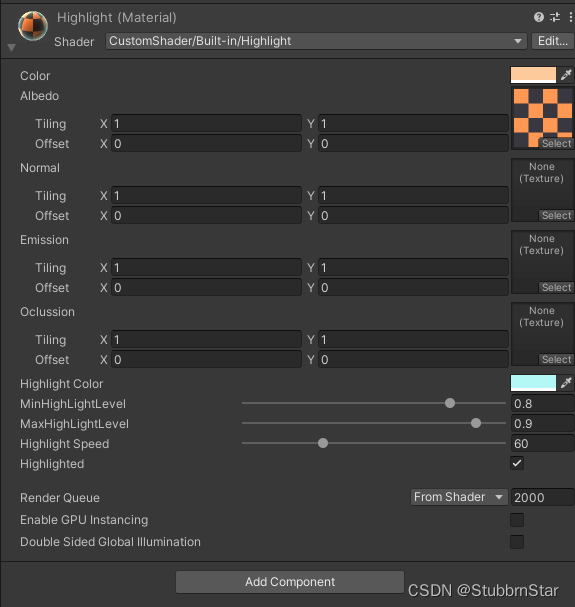
Unity-Shader-高亮Highlight
常用Shader-高亮,可动态调整高亮颜色、高亮强度范围/等级、高亮闪烁速度、高亮状态 Shader "CustomShader/Highlight" {Properties{_Color("Color", Color) (0.9044118,0.6640914,0.03325041,0)_Albedo("Albedo", 2D) "white…...

Linux操作系统(二):操作系统结构与内核设计
在(一)详解CPU中介绍了操作系统所基于的硬件CPU后,本部分学习操作系统的架构。在计算机系统中,操作系统的架构通常包括以下几个主要组件: 内核(Kernel) 进程管理(Process Management…...
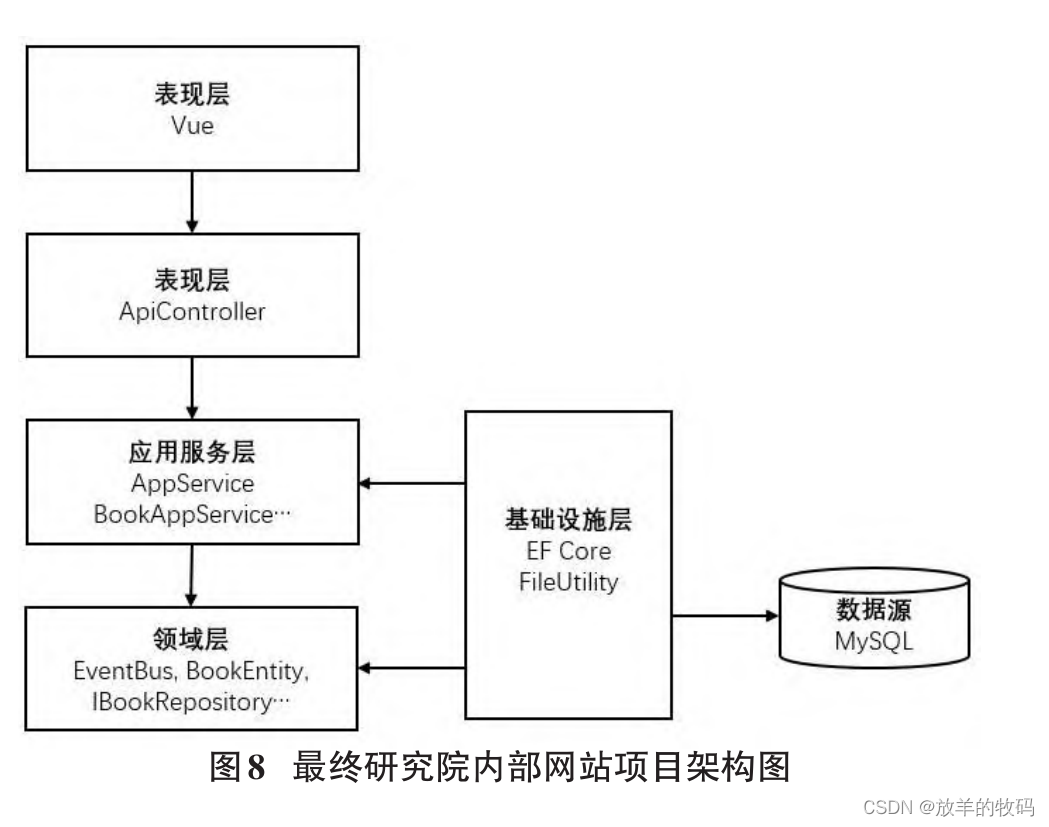
小研究 - 领域驱动设计DDD在IT企业内部网站开发中的运用(二)
在企业内部网站的建设过程中,网站后端最初采用传统的表模式的开发方式。这种方式极易导致站点的核心业务逻辑和业务规则分布在架构的各个层和对象中,这使得系统业务逻辑的复用性不高。为了解决这个问题,作者在后期的开发过程中引入了领域驱动…...

在Qt中实现鼠标监听与交互
文章目录 概述1. 包含头文件2. 实现鼠标事件函数3. 使用示例4. 应用场景 概述 鼠标监听是在Qt应用程序中实现用户交互的关键部分之一。通过捕获鼠标事件,您可以响应用户的点击、移动和释放动作,实现各种交互效果。本篇博文将详细介绍在Qt中如何进行鼠标…...

力扣hot100刷题记录
二刷hot100,坚持每天打卡!!! 1. 两数之和 // 先求差,再查哈希表 public int[] twoSum(int[] nums, int target) {Map<Integer,Integer> map new HashMap<>();for(int i 0;i<nums.length;i){int key …...

阿里云国际站视频直播服务是什么呢?
阿里云国际站视频直播是什么呢?下面一起来看一下: 视频直播服务(ApsaraVideo Live)是基于前瞻的内容接入、分发网络和大规模分布式实时转码技术打造的音视频直播平台,提供便捷接入、高清流畅、超低延时、高并发的音视频…...

python实现简单的爬虫功能
前言 Python是一种广泛应用于爬虫的高级编程语言,它提供了许多强大的库和框架,可以轻松地创建自己的爬虫程序。在本文中,我们将介绍如何使用Python实现简单的爬虫功能,并提供相关的代码实例。 如何实现简单的爬虫 1. 导入必要的…...

AI文档识别技术之表格识别 (一)
AI文档识别技术之表格识别(一) 文章目录 文章目录 AI文档识别技术之表格识别(一)1. 表格识别原理介绍1.1 表格类型分类1.2 识别原理 2. 整体识别流程2.1 流程图2.2 图像处理部分大致流程 3. 将表格转换为html与json格式输出3.1 html格式3.2 json格式3.3 表格识别实例 前言 此文…...

uni-app 支持 app端, h5端,微信小程序端 图片转换文件格式 和 base64
uni-app 支持 app端 h5端,微信小程序端 图片转换文件格式 和 base64,下方是插件市场的地址app端 h5端,微信小程序端 图片转换文件格式 和 base64 - DCloud 插件市场 https://ext.dcloud.net.cn/plugin?id13926...

在浏览器中创作专业演示文稿:PPTist完全指南
在浏览器中创作专业演示文稿:PPTist完全指南 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, allowing for the edi…...

保姆级教程:新手小白学习人工智能,推荐哪些入门书籍和课程?适合零基础的有哪些?
保姆级教程:新手小白学习人工智能,推荐哪些入门书籍和课程?适合零基础的有哪些? 标签:#人工智能、#深度学习、#自然语言处理、#神经网络、#机器学习、#计算机视觉、#ai### 一、零基础必看入门书籍:侧重易懂…...

S32DS中集成RTD 扩展包
S32系列MCU在进行软件开发时,我们可以选择使用S32DS的IDE开发环境,在使用的时候我们通常还需要RTD的包,那么如何把RTD的扩展包集成到S32DS中呢,今天我们就来详细的说明一下这个步骤,方便大家参考。 首先在下载安装包的…...

小语言模型基础:适合轻量化场景的 AI
文章目录小语言模型基础:适合轻量化场景的 AI一、啥是小语言模型?说白了就是"轻量级选手"二、2025-2026年SLM爆发:各大厂都在卷啥?2.1 微软Phi-4:数据质量党の胜利2.2 谷歌Gemma 3n:多模态小钢炮…...

从 219 秒到 1.3 秒!CausVid:首个媲美双向扩散的流式视频生成模型深度解析
前言 你是否有过这样的经历:输入一段文本生成视频,盯着屏幕等了 3 分多钟才看到结果?这就是传统双向视频扩散模型的致命痛点 —— 生成 128 帧视频需要 219 秒,且必须等全部内容生成完毕才能观看,更别提中途修改提示词…...

IoT-Technical-Guide:物联网平台API限流与防护策略终极指南
IoT-Technical-Guide:物联网平台API限流与防护策略终极指南 【免费下载链接】IoT-Technical-Guide :honeybee: IoT Technical Guide --- 从零搭建高性能物联网平台及物联网解决方案和Thingsboard源码分析 :sparkles: :sparkles: :sparkles: (IoT Platform, SaaS, MQ…...

Oracle VM VirtualBox快速上手指南——从下载到安装的完整流程
1. 为什么选择Oracle VM VirtualBox 如果你正准备学习Oracle数据库,或者需要在本地搭建一个隔离的测试环境,虚拟机无疑是最佳选择。而众多虚拟机软件中,Oracle VM VirtualBox凭借其完全免费和轻量易用的特性,成为入门级用户的首选…...

多模态RAG:让AI看懂图也能读懂话
不只是文字,还能“看图说话” 你有没有想过,AI不仅能读文字,还能看图、听声音,甚至把它们串起来理解?这背后就有“多模态RAG”的功劳。传统RAG(检索增强生成)主要处理文本——你问一个问题&…...
)
避坑指南:STM32CUBEMX串口配置常见问题及解决方案(USART/printf重定向)
STM32CubeMX串口开发实战:从原理到调试的完整避坑手册 第一次在STM32CubeMX里配置串口时,我盯着那个115200的波特率数值发呆了十分钟——这个看似简单的数字背后,隐藏着多少新手会踩的坑?从时钟树配置到DMA缓冲区,从p…...

2026年户外广告机市场:这五大厂家正悄然改变行业格局
当你在繁华的商圈、繁忙的交通枢纽,甚至是在社区门口,看到一块块高清亮丽的屏幕,正精准地推送着各类信息时,你是否想过,支撑这些“城市之眼”背后的技术力量正在经历一场深刻的变革?2026年的户外广告机市场…...