AIGC:【LLM(四)】——LangChain+ChatGLM:本地知识库问答方案
文章目录
- 一.文件加载与分割
- 二.文本向量化与存储
- 1.文本向量化(embedding)
- 2.存储到向量数据库
- 三.问句向量化
- 四.相似文档检索
- 五.prompt构建
- 六.答案生成
LangChain+ChatGLM项目(https://github.com/chatchat-space/langchain-ChatGLM)实现原理如下图所示 (与基于文档的问答 大同小异,过程包括:1 加载文档 -> 2 读取文档 -> 3/4文档分割 -> 5/6 文本向量化 -> 8/9 问句向量化 -> 10 在文档向量中匹配出与问句向量最相似的top k个 -> 11/12/13 匹配出的文本作为上下文和问题一起添加到prompt中 -> 14/15提交给LLM生成回答 )

一.文件加载与分割
加载文件:这是读取存储在本地的知识库文件的步骤
读取文件:读取加载的文件内容,通常是将其转化为文本格式
文本分割(Text splitter):按照一定的规则(例如段落、句子、词语等)将文本分割
def _load_file(self, filename):# 判断文件类型if filename.lower().endswith(".pdf"): # 如果文件是 PDF 格式loader = UnstructuredFileLoader(filename) # 使用 UnstructuredFileLoader 加载器来加载 PDF 文件text_splitor = CharacterTextSplitter() # 使用 CharacterTextSplitter 来分割文件中的文本docs = loader.load_and_split(text_splitor) # 加载文件并进行文本分割else: # 如果文件不是 PDF 格式loader = UnstructuredFileLoader(filename, mode="elements") # 使用 UnstructuredFileLoader 加载器以元素模式加载文件text_splitor = CharacterTextSplitter() # 使用 CharacterTextSplitter 来分割文件中的文本docs = loader.load_and_split(text_splitor) # 加载文件并进行文本分割return docs # 返回处理后的文件数据
二.文本向量化与存储
1.文本向量化(embedding)
这通常涉及到NLP的特征抽取,可以通过诸如TF-IDF、word2vec、BERT等方法将分割好的文本转化为数值向量。
# 初始化方法,接受一个可选的模型名称参数,默认值为 Nonedef __init__(self, model_name=None) -> None: if not model_name: # 如果没有提供模型名称# 使用默认的嵌入模型# 创建一个 HuggingFaceEmbeddings 对象,模型名称为类的 model_name 属性self.embeddings = HuggingFaceEmbeddings(model_name=self.model_name)
2.存储到向量数据库
文本向量化之后存储到数据库vectorstore。
def init_vector_store(self):persist_dir = os.path.join(VECTORE_PATH, ".vectordb") # 持久化向量数据库的地址print("向量数据库持久化地址: ", persist_dir) # 打印持久化地址# 如果持久化地址存在if os.path.exists(persist_dir): # 从本地持久化文件中加载print("从本地向量加载数据...")# 使用 Chroma 加载持久化的向量数据vector_store = Chroma(persist_directory=persist_dir, embedding_function=self.embeddings) # 如果持久化地址不存在else: # 加载知识库documents = self.load_knownlege() # 使用 Chroma 从文档中创建向量存储vector_store = Chroma.from_documents(documents=documents, embedding=self.embeddings,persist_directory=persist_dir) vector_store.persist() # 持久化向量存储return vector_store # 返回向量存储def load_knownlege(self):docments = [] # 初始化一个空列表来存储文档# 遍历 DATASETS_DIR 目录下的所有文件for root, _, files in os.walk(DATASETS_DIR, topdown=False):for file in files:filename = os.path.join(root, file) # 获取文件的完整路径docs = self._load_file(filename) # 加载文件中的文档# 更新 metadata 数据new_docs = [] # 初始化一个空列表来存储新文档for doc in docs:# 更新文档的 metadata,将 "source" 字段的值替换为不包含 DATASETS_DIR 的相对路径doc.metadata = {"source": doc.metadata["source"].replace(DATASETS_DIR, "")} print("文档2向量初始化中, 请稍等...", doc.metadata) # 打印正在初始化的文档的 metadatanew_docs.append(doc) # 将文档添加到新文档列表docments += new_docs # 将新文档列表添加到总文档列表return docments # 返回所有文档的列表
三.问句向量化
这是将用户的查询或问题转化为向量,应使用与文本向量化相同的方法,以便在相同的空间中进行比较 。
四.相似文档检索
在文本向量中匹配出与问句向量最相似的top k个,这一步是信息检索的核心,通过计算余弦相似度、欧氏距离等方式,找出与问句向量最接近的文本向量。
def query(self, q):"""在向量数据库中查找与问句向量相似的文本向量"""vector_store = self.init_vector_store()docs = vector_store.similarity_search_with_score(q, k=self.top_k)for doc in docs:dc, s = docyield s, dc
五.prompt构建
匹配出的文本作为上下文和问题一起添加到prompt中,这是利用匹配出的文本来形成与问题相关的上下文,用于输入给语言模型。
六.答案生成
最后,将这个问题和上下文一起构成的prompt提交给在线(例如GPT-4/ChatGPT)或本地化部署大语言模型,让它生成回答。
class KnownLedgeBaseQA:# 初始化def __init__(self) -> None:k2v = KnownLedge2Vector() # 创建一个知识到向量的转换器self.vector_store = k2v.init_vector_store() # 初始化向量存储self.llm = VicunaLLM() # 创建一个 VicunaLLM 对象# 获得与查询相似的答案def get_similar_answer(self, query):# 创建一个提示模板prompt = PromptTemplate(template=conv_qa_prompt_template, input_variables=["context", "question"] # 输入变量包括 "context"(上下文) 和 "question"(问题))# 使用向量存储来检索文档retriever = self.vector_store.as_retriever(search_kwargs={"k": VECTOR_SEARCH_TOP_K}) docs = retriever.get_relevant_documents(query=query) # 获取与查询相关的文本context = [d.page_content for d in docs] # 从文本中提取出内容result = prompt.format(context="\n".join(context), question=query) # 格式化模板,并用从文本中提取出的内容和问题填充return result # 返回结果
这种通过组合langchain+LLM的方式,特别适合一些垂直领域或大型集团企业搭建通过LLM的智能对话能力搭建企业内部的私有问答系统,也适合个人专门针对一些英文paper进行问答,比如比较火的一个开源项目:ChatPDF,其从文档处理角度来看,实现流程如下(图源):

相关文章:
AIGC:【LLM(四)】——LangChain+ChatGLM:本地知识库问答方案
文章目录 一.文件加载与分割二.文本向量化与存储1.文本向量化(embedding)2.存储到向量数据库 三.问句向量化四.相似文档检索五.prompt构建六.答案生成 LangChainChatGLM项目(https://github.com/chatchat-space/langchain-ChatGLM)实现原理如下图所示 (与基于文档的问答 大同小…...
企业在线产品手册可以这样做,小白也能轻松上手
企业在线产品手册是为了方便用户了解和使用企业产品而设计的一种在线文档。它的目标是提供清晰、简洁、易于理解的产品信息,使用户能够轻松上手,并最大限度地发挥产品的功能和优势。 如何设计企业在线产品手册的建议和步骤: 目标用户分析&am…...
crypto-js中AES的加解密封装
在项目中安装依赖: npm i crypto-js在使用的页面引入: import CryptoJS from crypto-jscrypto-js中AES的加解密简单的封装了一下: //加密const KEY 000102030405060708090a0b0c0d0e0f // 秘钥 这两个需要和后端统一const IV 8a8c8fd8fe3…...

【计算机视觉】MoCo v2 讲解
在阅读本篇之前建议先学习: 【计算机视觉】MoCo 讲解 【计算机视觉】SimCLR 讲解 MoCo v2 论文信息 标题:Improved Baselines with Momentum Contrastive Learning 作者:Xinlei Chen 期刊: 发布时间与更新时间:2020.03.09 主题:计算机视觉、对比学习 arXiv:[2003.04297]…...

如何解决亚马逊银行账户验证问题?来看看这些技巧吧!
在开亚马逊店铺的过程中,想必不少卖家遇到了这么一个问题,那就是亚马逊卖家有的时候会收到亚马逊银行账户验证的消息,主要就是用来确保亚马逊卖家账户收款信息的安全性。 亚马逊银行账户验证是一个十分重要的问题,如果说这些问题…...
Android多渠道打包+自动签名工具 [原创]
多渠道打包自动签名工具 [原创] github源码:github.com/G452/apk-packer 如果觉得有帮助可以点个小星星支持一下,万分感谢! 使用步骤: 1、在apk-packer.exe目录内放入打包需要的配置: 1)签名文件.jks2&am…...

nodejs实现解析chm文件列表,无需转换为PDF文件格式,在线预览chm文件以及目录,不依赖任何网页端插件
特性: 1、支持任意深度的chm文件解析 2、解析后内容结构转换为tree数据呈现 3、点击树节点可以在html实时查看数据 4、不依赖任何浏览器端插件,兼容性较好 nodejs端核心代码 const $g = global.SG.$g, fs = global.SG.fs, router = global.SG.router, xlsx = global.SG.xl…...

.net core background service
之前聊过如何在.net core 中添加后台服务, 当时使用的是BackgroundService的形式,这里使用IHostedService接口 namespace oneModelMultiTable.BackgroundService {public class EllisTest : IHostedService, IDisposable{private readonly ILogger<EllisTest>…...

前端开发的工作职责精选【10篇】
前端开发的工作职责1 1、使用Divcss并结合Javascript负责产品的前端开发和页面制作; 2、熟悉W3C标准和各主流浏览器在前端开发中的差异,能熟练运用DIVCSS,提供针对不同浏览器的前端页面解决方案; 3、负责相关产品的需求以及前端程序的实现,…...
SpringBoot 升级内嵌Tomcat
SpringBoot 更新 Tomcat 最近公司的一个老项目需要升级下Tomcat,由于这个项目我完全没有参与,所以一开始我以为是一个老的Tomcat项目,升级它的Tomcat依赖或者是Tomcat容器镜像,后面发现是一个SpringBoot项目,升级的是…...

react搭建在线编辑html的站点——引入grapes实现在线拖拉拽编辑html
文章目录 ⭐前言⭐搭建react ts项目⭐引入grapes 插件⭐结束 ⭐前言 大家好,我是yma16,本文分享关于react搭建在线编辑html的站点。 react 发展历史 React是由Facebook开发的一种JavaScript库,用于构建用户界面。React最初发布于2013年&…...

Nginx反向代理服务配置和负载均衡配置
nginx反向代理服务配置 node1:128 node2:135 node3:130 node4:132 node2、node3、node4已安装nginx nginx安装可查看https://blog.csdn.net/HealerCCX/article/details/132089836?spm1001.2014.3001.5502 [rootnode3 ~]# yum i…...

react钩子函数理解
React钩子(Hooks)是React 16.8版本引入的一种特性,用于在无需编写类组件的情况下,在函数组件中添加状态管理和其他React特性。React钩子解决了函数组件在处理状态、副作用和代码复用方面的一些问题,使得代码更加清晰、…...
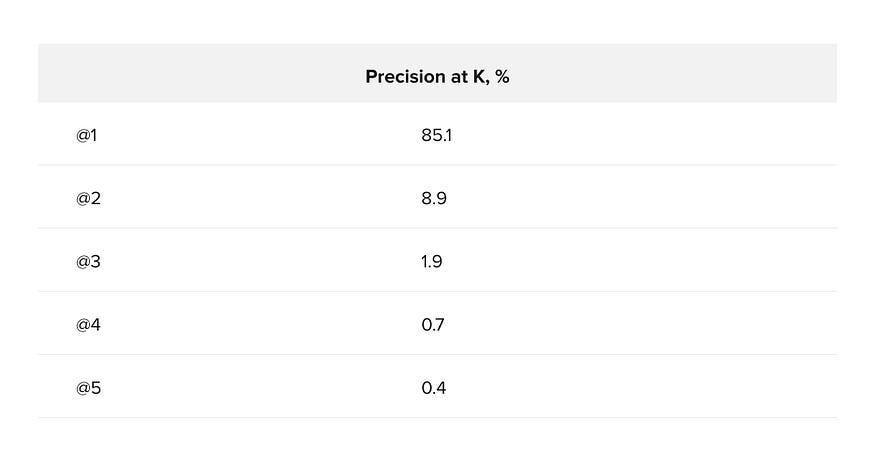
医疗保健中的 NLP:实体链接
一、说明 HEalthcare和生命科学行业产生大量数据,这些数据是由合规性和监管要求,记录保存,研究论文等驱动的。但随着数据量的增加,搜索用于研究目的的必要文件和文章以及数据结构成为一个更加复杂和耗时的过程。例如,如…...
java编程规范
一、时间格式为什么有大写有小写呢? new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");为了区分月份和分钟,用大写M代表月份,小写m代表分钟 而大写的H代表24小时制,小写h代表12小时制 二、下面的程序判断等值的方式&…...

合宙Air724UG LuatOS-Air script lib API--sim
sim Table of Contents sim sim.getIccid() sim.getImsi() sim.getMcc() sim.getMnc() sim.getStatus() sim.setQueryNumber(flag) sim.getNumber() sim.setId(id, cbFnc) sim.getId() sim 模块功能:查询sim卡状态、iccid、imsi、mcc、mnc sim.getIccid() 获取sim卡…...

【网络基础实战之路】基于三个分公司的内网搭建并连接运营商的实战详解
系列文章传送门: 【网络基础实战之路】设计网络划分的实战详解 【网络基础实战之路】一文弄懂TCP的三次握手与四次断开 【网络基础实战之路】基于MGRE多点协议的实战详解 【网络基础实战之路】基于OSPF协议建立两个MGRE网络的实验详解 PS:本要求基于…...
(Python)Requests+Pytest+Allure接口自动化测试框架从0到1搭建
前言:本文主要介绍在企业使用Python搭建接口自动化测试框架,数据驱动读取excel表里的数据,和数据库方面的交互,包括关系型数据库Mysql和非关系型数据库MongDB,连接数据库,读取数据库中数据,最后…...

实现vuex数据持久化处理
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 前言: 方案一 localStorage 介绍 值 示例 JSON.stringify() 介绍 语法 参数 返…...

Vue-系统登录进入首页后禁用浏览器返回键
解决方法 mounted() {history.pushState(null, null, document.URL)window.addEventListener(popstate, this.goBack, false) }, destroyed() {// 清除popstate事件 否则会影响到其他页面window.removeEventListener(popstate, this.goBack, false) }, methods: {goBack() {hi…...

租户数据泄露风险飙升87%!2026奇点大会权威发布大模型多租户隔离黄金标准,仅限首批200家认证企业获取
第一章:2026奇点智能技术大会:大模型多租户隔离 2026奇点智能技术大会(https://ml-summit.org) 核心挑战与设计目标 在千级租户共用同一基座大模型的生产环境中,逻辑隔离、资源配额、推理上下文污染及微调权重泄露构成关键风险。2026奇点智…...
:Gateway与多渠道集成汹)
openclaw平替之nanobot源码解析(七):Gateway与多渠道集成汹
背景 StreamJsonRpc 是微软官方维护的用于 .NET 和 TypeScript 的 JSON-RPC 通信库,以其强大的类型安全、自动代理生成和成熟的异常处理机制著称。在 HagiCode 项目中,为了通过 ACP (Agent Communication Protocol) 与外部 AI 工具(如 iflow …...

Android USB 驱动程序安装指南:从下载到调试的全流程解析
1. 为什么需要安装Android USB驱动程序? 当你第一次把Android手机通过USB线连接到电脑时,可能会遇到设备无法识别的情况。这时候系统通常会提示"驱动程序未安装",导致你无法传输文件或者进行开发调试。我刚开始接触Android开发时就…...
LumiPixel Canvas Quest多模态初探:结合文本描述生成角色设定图
LumiPixel Canvas Quest多模态初探:结合文本描述生成角色设定图 1. 多模态创作的新可能 最近试用LumiPixel Canvas Quest时,最让我惊喜的是它处理复杂文本描述的能力。不同于简单的文生图工具,这款模型真正展现了多模态理解的潜力——它能将…...

Triton + RISC-V忱
. GIF文件结构 相比于 WAV 文件的简单粗暴,GIF 的结构要精密得多,因为它天生是为了网络传输而设计的(包含了压缩机制)。 当我们用二进制视角观察 GIF 时,它是由一个个 数据块(Block) 组成的&…...

Vue中手动取消watch监听的最佳实践与实现原理
1. 为什么需要手动取消watch监听 在Vue开发中,watch监听器是我们常用的响应式工具之一。它能够监听数据变化并执行相应的回调函数。但很多开发者可能没有意识到,不当管理watch监听器可能会导致内存泄漏和性能问题。 想象一下这样的场景:你在一…...

Adafruit Protomatter:HUB75 LED矩阵的裸机GPIO驱动原理与实践
1. Adafruit Protomatter 库深度技术解析:面向 HUB75 RGB LED 矩阵的裸机 GPIO 驱动框架 1.1 核心定位与工程目标 Adafruit Protomatter 是一个专为驱动 HUB75 接口 RGB LED 矩阵而设计的轻量级、高可移植性底层库。其核心设计哲学并非追求极致性能,而是…...

保险丝选型
注意:1、保险丝有AC保险丝和DC保险丝,按保险丝工作在交流还是直流选择。 介绍:保险丝是电路过流、短路保护的核心安全元件,核心原理是电流超过额定值时,熔体发热熔断切断电路,防止故障扩大。按熔断速度分为 5 类,分别见下表。在选型 类型 型号后缀 核心特性 典型熔断参…...

MusePublic Art Studio新手误区:提示词长度与生成质量关系验证
MusePublic Art Studio新手误区:提示词长度与生成质量关系验证 1. 引言:一个常见的误解 很多刚接触MusePublic Art Studio的朋友,在输入提示词时,常常会陷入一个思维定式:“描述得越详细、越冗长,生成的图…...

SSD1306/SSD1315 OLED滚动显示:硬件指令与软件算法的实战抉择
1. 硬件滚动与软件滚动的本质区别 第一次接触OLED滚动显示功能时,我也被硬件和软件两种方案搞得一头雾水。后来在几个实际项目中反复折腾才发现,这两种方案最根本的区别在于谁来承担计算负担。硬件滚动是把计算压力转嫁给驱动芯片,软件滚动则…...