MongoDB
MongoDB
应用场景
在传统数据库(Mysql),在数据操作的 **High performance 对数据库高并发读写的需求、Hugu Storage 对海量数据的高效率存储和访问的需求、High Scalability && High Availability 对数据库高扩展和高可用性的需求。**这个时候传统数据库例如mysql就显得力不从心。
High performance
比如我们常说的618 11:11,
Huge Storage 海量的数据
Mysql对于海量数据和高效存储的访问需求就有一些力不从心。
High Scalability && High Availability 对数据库高扩展和高可用性的需求
高可扩展性
在传统的Mysql数据库我们如果要进行扩展我们非常困难, 因为我们的表与表是对应的,列也固定了,扩展的代价非常的高。而我们MongoDB是一个松散的情况,我不需要在我一开始就把我的列确认好。
高可用性
应用场景
**社交场景:**使用MongoDB存储用户信息,以及发表朋友圈,通过地理位置索引实现附近人,地点等功能。
**游戏场景:**我们游戏都有一个需求那就是低延迟,那么我们可以通过MongoDB存储用户的信息,用户的装备,游戏币等直接以内嵌数组的形式存储,方便查询高效率存储和访问,显然mysql做到这点代价要高很多。
**物流场景:**使用MongoDB存储订单信息,订单状态在运送的过程中会不断更新,以MOngoDB内嵌数组的形式来存储,一次查询就能将订单的所有变更都读取出来。
**游戏直播:**存储点赞和互动信息
以上总结我们当一下情况下就可以选择MongoDB
(1) 数据量大
(2)读写很频繁
(3)价值较低的数据,是事物要求不高。
(4)海量数据
对于以上的数据我们就可以选择MongoDB
MongoDB的缺点
MongoDB对事物的操作很不好
MongoDB的简介
MongoDB是一个开源、高性能、无模式(不像传统数据库一样需要列)的文档数据库,当初的设计就是用于简化开发和方便扩展,是NoSQL的数据库一种,是最像关系型数据库的非关系数据库。
MongoDB它的数据结构非常的松散,是一种类似JSON的格式叫BSON。所以他可以存储复杂的数据库又相当的灵活。
MongoDB记录的就是一个文档,它是由一个字段和值组成(field:value)的数据结构,MongoDB的文档类似JSON对象,所以一个文档可以认为是一个对象,字段的数据类型就是字符型,它的值除了使用基本的一些类型外还可以使用其他文档、普通数组和文档数组。
| MongoDB关键词 | 解释 |
|---|---|
| database | 数据库 |
| collection | 集合 |
| document | 文档 |
| field | 域 |
| index | 索引 |
| 嵌入文档 | mongodb不像mysql一样可以使用join进行连接,Mongodb使用嵌入式文档来代替多表连接 |
| primary key | mongoDb自动将——id字段设置为主键 |
Linux安装MongoDB ON Ubantu
1.去官网下载tgz
2.解压mongodb
tar -xvf mongo......... .tgz
3.创建几个目录,粉嫩别来存储数据和日志
# 存储目录
mkdir -p /mongodb/single/data/db
# 日志存储目录
mkdir -p /mongodb/single/log
5.创建配置文件
vi /mongodb/single/mongod.conf
#数据库路径
dbpath=/mongodb/single/data/db
#日志输出文件路径
logpath=/mongodb/single/log/mongod.log
#错误日志采用追加模式
logappend=true
#启用日志文件,默认启用
journal=true
#这个选项可以过滤掉一些无用的日志信息,若需要调试使用请设置为false
quiet=true
#端口号 默认为27017
port=27017
#允许远程访问(你的服务器局域网ip)
bind_ip=xxxxxx
#开启子进程
fork=true
#开启认证,必选先添加用户,先不开启(不用验证账号密码)
#auth=true
根据我们的配置文件启动mongodb
/home/bryan/Documents/lib/mongod -f /home/bryan/DOcuments/mongod/single/mongod.conf
文档CURD
Document数据结构和json基本一致
所有在集合中的数据都是BSON格式也就是JSON的二进制
文档的插入
单个插入
dp.test1.insert(<document or array of documents>,{ writeConcern: <document>,ordered: <boolean>}
)
| Parameter | type | Description |
|---|---|---|
| document | document or array | 要插入到集合中的文档或文档数组 |
| writerConcern | document | 插入的时候选择的一个性能和可靠性的级别 |
| ordered | boolean | 是否排序 |
批量插入
dp.test1.insertMany([<document 1>,<document 2>,.......],{ writeConcern: <document>,ordered: <boolean>}
)
查询
查询所有
dp.test1.find()
指定查询
db.c1.find({"item": "card"})
若我们想控制哪些字段显示哪些不现实
db.c1.find({"item": "card"},{"item":1,"qty":1,"_id":0})
1代表显示,0代表不显示
更新
覆盖修改
db.c1.update({"_id":1},{"qty":100})
我们会发现除了qty字段其他字段都没有了
局部修改
db.c1.update({_id:1},{$set:{"item":"q"}})
这样就不会丢失其他列的顺序了,但是只会修改一个字段
db.c1.update({"qty":NumberInt(15)},{$set:{"item":"11112"}},{multi:true})
这样就会更新所有;
自增或者自减
db.c1.update({"_id":NumberInt(1),"item":"Math"},{$inc:{"qty":NumberInt(1)}})
db.c1.update({"_id":NumberInt(1),"item":"Math"},{$inc:{"qty":NumberInt(-1)}})
删除
db.c1.remove({"qty":NumberInt(15),"item":"11112"})
分页查询
统计
db.c1.count(query,option)
Query: 查询条件
option:选项
db.c1.count()
db.c1.count({"_id":1})
分页
限制查询几条
db.c1.find().limit(3)
跳过几个查询几个
db.c1.find().skip(3).limit(3)
排序
生序
db.c1.find().sort({"_id":1})
降序
db.c1.find().sort({"_id":-1})
如果limit 和 ship和sort一起用,他们的优先级为
db.c1.find().sort({"_id":1}).skip(3).limit(3)
更复杂的查询
正则的复杂查询
通过正则查询包含a的内容
db.c1.find({"item":/a/})
查询以a开头的
db.c1.find({"item":/^a/})
操作符查询
在我们mongodb我们的操作符号也需要转移
| 符号 | to |
|---|---|
| > | $gt |
| < | $lt |
| >= | $gte |
| <= | $lte |
| != | $ne |
db.c1.find({"_id":{$gte : 10}})
包含查询
包含5 6 7的数据
db.c1.find({"_id":{$in : [5,6,7]}})
不包含5 6 7的数据
db.c1.find({"_id":{$nin : [5,6,7]}})
And
db.c1.find({$and: [{_id: {$lt: NumberInt(10)}},{_id: {$gt: NumberInt(2)}}]})
or
db.c1.find({$or: [{_id: {$lt: NumberInt(10)}},{_id: {$gt: NumberInt(2)}}]})
索引
索引是为了提高mongoDB高效的查询,如果没有索引,MongoDB必须执行全集合扫描,扫描集合中每一个文档,找到语言查询语句匹配的数据,这样效率是十分低的,特别在海量的数据情况下这对我们来说是致命的。
他和mysql不同的是MongoDB采用的是B-Tree 而Mysql采用的是B+Tree
单字段索引 普通索引,
将某个字段设置为索引,该索引直接对应了数据的物理内存地址。
复合索引
复合索引对字段的顺序有很大的意义,比如说{userid: 1,score:-1}我们先根据userid郑旭排序,然后在userid的值内在对score进行倒叙排序,当查询条件比较多的时候就应该使用复合索引
地理空间索引
为了支持地理空间坐标的有效查询,MongDB提供了两种特殊的索引,返回结果的时候使用平米那集合的二维索引和返回结果的时候使用地球几何的二面索引。
文本索引
MongoDB提供了一种文本索引类型,支持在集合中所搜字符串的内存,这些文娥本索引不存储特定语言的停止词汇例如the a or,而将集合中的词作为词干,值存储词根
Hash索引
不支持范围查找,只能通过该值计算出指定存储位置进行查找
索引类型
在索引里,1是生序,0是降序
**Name:**索引名字
**Unique:**唯一索引
**backgound:**索引创建的过程中会堵塞其他数据库的操作
**spare:**对文档中不存在的字段数据不启动索引,这个参数要特别注意,如果指定为true的话,我在索引字段中不会查询出不包含对应字段的文档,默认为之false
**Expire After:**多少秒后过期
获取索引
db.c1.getIndexes()
创建单字段索引
db.c1.createIndex({qty:1})
创建复合索引
db.c1.createIndex({qty:1,_id:-1})
删除索引
根据规则去删除
我们设置的索引是什么规则,那么我们就通过什么规则进行删除
db.c1.dropIndex({qty:1})
通过name进行删除
db.c1.dropIndex("qty_1__id_-1")
db.c1.getIndexes()
执行计划
执行计划就是分析查询性能(Analyyze query performance),通常使用执行计划(解析计划、Explain Plan)来查看查询的情况,如查询耗费的时间、是否基于索引查询等。
db.conllection.find(query,options).explain(options)
我们看到返回结果首先要关心的就是winningPlan
如果stage为collscan就代表全集合扫描
如果stage为fetch就代表使用了索引
涵盖查询
如果我们使用了索引只返回索引字段,那么就不会扫描索引文档查询内存,直接返回索引,这样查询效率就是非常的高
小Demo 文档评论
表的设计
| _id | Id | ObjectId or String | MongoDB主键字段 |
|---|---|---|---|
| articled | 博文Id | String | |
| content | 评论内容 | String | |
| userid | 评论人ID | String | |
| nickname | 昵称 | String | |
| createdatetime | 评论日期 | Date | |
| likenum | 点赞数量 | int32 | |
| replynum | 回复数量 | int32 | |
| state | 状态 | String | 0可见1不可以 |
| parentId | 上级iD | String |
技术选型
mongodb-driver
<!-- https://mvnrepository.com/artifact/org.mongodb/mongodb-driver -->
<dependency><groupId>org.mongodb</groupId><artifactId>mongodb-driver</artifactId><version>3.12.11</version>
</dependency>
SpringDateMongoDB
<!-- https://mvnrepository.com/artifact/org.springframework.data/spring-data-mongodb -->
<dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-mongodb</artifactId><version>4.0.1</version>
</dependency>
配置文件
spring:data:mongodb:host: 192.168.40.141database: c1port: 27017
实体类
package com.example.studymongodb.entry;import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.index.Indexed;
import org.springframework.data.mongodb.core.mapping.Document;import java.io.Serializable;
import java.util.Date;@Document(collection = "c1")
public class C1 implements Serializable {@Idprivate Long id; //主键private String content; //评论内容private Date publishtime; //发布时间@Indexed //单字段索引private String userID; //发布人private String nickname; //别名private Date createDateTime; //创建时间private Long likenum; //点赞数量private Long replynum; //回复数量private Integer state; //回复数量private Long articleId; //回复博文idpublic Long getId() {return id;}public void setId(Long id) {this.id = id;}public String getContent() {return content;}public void setContent(String content) {this.content = content;}public Date getPublishtime() {return publishtime;}public void setPublishtime(Date publishtime) {this.publishtime = publishtime;}public String getUserID() {return userID;}public void setUserID(String userID) {this.userID = userID;}public String getNickname() {return nickname;}public void setNickname(String nickname) {this.nickname = nickname;}public Date getCreateDateTime() {return createDateTime;}public void setCreateDateTime(Date createDateTime) {this.createDateTime = createDateTime;}public Long getLikenum() {return likenum;}public void setLikenum(Long likenum) {this.likenum = likenum;}public Long getReplynum() {return replynum;}public void setReplynum(Long replynum) {this.replynum = replynum;}public Integer getState() {return state;}public void setState(Integer state) {this.state = state;}public Long getArticleId() {return articleId;}public void setArticleId(Long articleId) {this.articleId = articleId;}@Overridepublic String toString() {return "C1{" +"id=" + id +", content='" + content + '\'' +", publishtime=" + publishtime +", userID='" + userID + '\'' +", nickname='" + nickname + '\'' +", createDateTime=" + createDateTime +", likenum=" + likenum +", replynum=" + replynum +", state=" + state +", articleId=" + articleId +'}';}public C1() {}public C1(Long id, String content, Date publishtime, String userID, String nickname, Date createDateTime, Long likenum, Long replynum, Integer state, Long articleId) {this.id = id;this.content = content;this.publishtime = publishtime;this.userID = userID;this.nickname = nickname;this.createDateTime = createDateTime;this.likenum = likenum;this.replynum = replynum;this.state = state;this.articleId = articleId;}
}
编写MongoDBDao层
import com.example.studymongodb.entry.C1;
import org.springframework.data.mongodb.repository.MongoRepository;public interface C1Repository extends MongoRepository<C1,Long> {
}
MongoRepository<T,TD> T代表着实体类型,TD代表着主键类型
基本的CRUD
import com.example.studymongodb.entry.C1;
import com.example.studymongodb.mongodao.C1Repository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import javax.annotation.Resource;
import java.util.List;public class C1Service {private C1Repository c1Repository;//保存评论public void savedis(C1 c1){c1Repository.save(c1);}//更新评论public void updatedis(C1 c1){c1Repository.save(c1);}//根据id删除评论public void delteDisById(Long id){c1Repository.deleteById(id);}//查询所有评论public List<C1> getAll(){List<C1> all = c1Repository.findAll();return all;}//通过id查询评论public C1 getC(Long id){C1 c1 = c1Repository.findById(id).get();return c1;}}
通过上级id分页查询评论
一定要叫这个名字,findBy属性名字。否则会解析不到
public interface C1Repository extends MongoRepository<C1,Long> {/*** 通过上级id查询子评论* @param parentId* @param pageable* @return*/Page<C1> findByParentId(Long parentId, Pageable pageable);
}
@Test
void test1(){Page<C1> byParentId = c1Repository.findByParentId(1l, PageRequest.of(0, 2));System.out.println(byParentId.getContent()); //数据内容System.out.println(byParentId.getTotalElements()); //总数据个数
}
使用MongoTemplate来实现点赞
Spring Date MongoDB
常用注解
@Ducoment 指定集合
@Document(collection= “”) 指定集合
@Document(collection = "c1")
public class C1 implements Serializable {.....
}
@Indexed 设置单独索引
@Indexedprivate Long id;
@Id 设置主键
@Id
private Date publishtime; //发布时间
@CompoundIndex(def = “{‘userId’:1,‘nickname’:-1}”) 复合索引
@Document(collection = "c1")
@CompoundIndex(def = "{'userId':1,'nickname':-1}")
public class C1 implements Serializable {.....
}
副本集 Replica Sets
副本及就是有自动故障修复的主从集群,通俗来讲,就是多台机器进行统一数据的异步同步,让多台机器有同一数据的多个副本,当主库挂掉不需要我们人为操作它就可以自动切换主库,也就是将从库变成主库,而且还可以用副本作为只读数据库,实现读写分离操作,提高负载
副本集有2个类型
主节点,主要负责数据操作的主要连接点,可读写。
从节点类型:数据的备份节点,可以读或者选举。
三种角色
主要成员:主要接受所有的写操作,也就是主节点
副本成员:从主节点通过复制操作以维护相同的数据,也称为备份数据,不可以写操作,但是可以读(需要配置)也是从节点类型。
仲裁者:不保留任何数据,只作为投票使用,也是一个从节点类型。
当我们主线主节点故障或者主节点网络不可达(默认心跳为10秒)或者主节点关机了就会选举新的主节点。
必须获取到大多数节点的投票才能成为主节点,如果票数相等就判断谁是最新插入的数据是俄称为主节点。
分片集群
分片时跨多台机器分布数据的方法,MongoDb使用分片来支持具有非常大的数据集和高吞吐量操作的部署。
也就是说将数据拆分,分散在不同的机器。
主要有3个属性
分片(存储):每个分享包含分片的数据的自己,每个分片都可以部署为副本集。
mongos(路由) mongos充当查询路由器,在客户端应用程序和分片集合之间提供接口
config servers(调度的配置):就是存放配置信息,知道我哪个数据在哪个分片,我的路由应该如何去调取
安全认证
在mongodb默认角色有一些权限
**read:**只能读
**readWrite:**能读能写
**userAdmin:**能用数据库和用户的创建
**root:**超级管理员
首先选择我们要授权的库
use ZuiBlog
相关文章:

MongoDB
MongoDB 应用场景 在传统数据库(Mysql),在数据操作的 **High performance 对数据库高并发读写的需求、Hugu Storage 对海量数据的高效率存储和访问的需求、High Scalability && High Availability 对数据库高扩展和高可用性的需…...
python 迭代器生成器
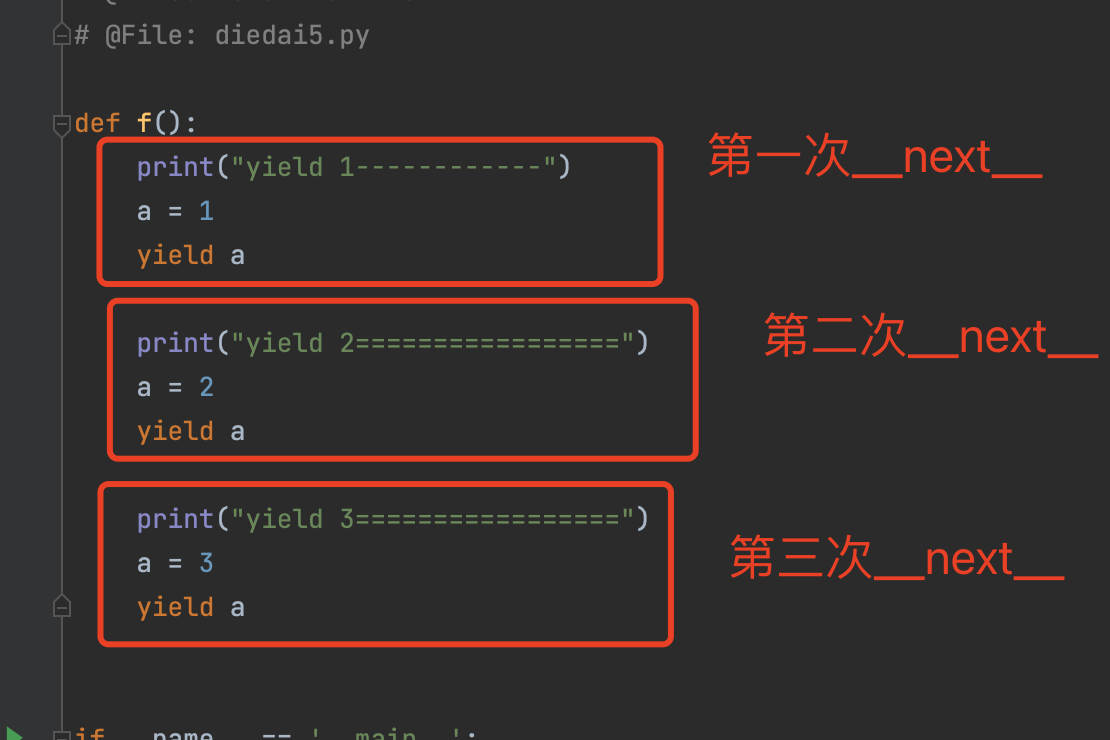
目录 一、可迭代对象 1.1 判断是否为可迭代对象 二、迭代器 2.1 判断对象是否是一个迭代器 2.2 手写一个迭代器 2.3 迭代器应用场景 三、生成器 3.1 生成器介绍 3.2 使用yield 关键字 生成器,来实现迭代器 3.3 生成器(yield关键字)…...

Iceberg基于Spark MergeInto语法实现数据的增量写入
SPARK SQL 基本语法 示例SQL如下 MERGE INTO target_table t USING source_table s ON s.id t.id //这里是JOIN的关联条件 WHEN MATCHED AND s.opType delete THEN DELETE // WHEN条件是对当前行进行打标的匹配条件 WHEN MATCHED AND s.opType update THEN…...
 对象)
JavaScript Array(数组) 对象
JavaScript 中的 Array(数组)对象是一种用来存储一系列值的容器,它可以包含任意类型的数据,包括数字、字符串、对象等等。通过使用数组对象,我们可以轻松地组织和处理数据,以及进行各种操作,比如…...

Debian如何更换apt源
中科大 deb https://mirrors.ustc.edu.cn/debian/ stretch main non-free contrib deb https://mirrors.ustc.edu.cn/debian/ stretch-updates main non-free contrib deb https://mirrors.ustc.edu.cn/debian/ stretch-backports main non-free contrib deb-src https://mirr…...

Connext DDSPersistence Service持久性服务
DDS持久性服务,它保存了DDS数据样本,以便即使发布应用程序已经终止,也可以稍后将其发送到加入系统的订阅应用程序。 简介Persistence Service是一个Connext DDS应用程序,它将DDS数据样本保存到临时或永久存储中,因此即使发布应用程序已经终止,也可以稍后将其交付给加入系…...
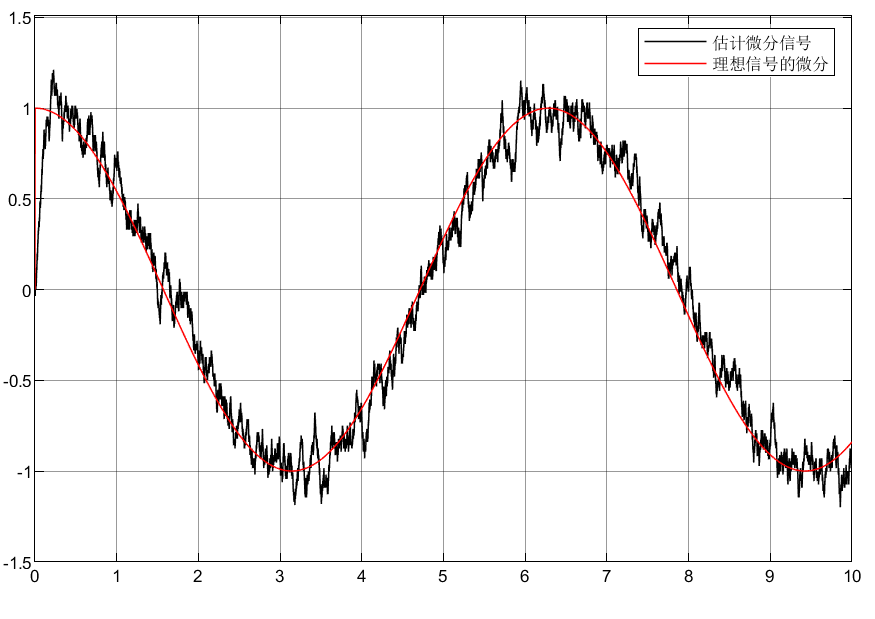
自抗扰控制ADRC之微分器TD
目录 前言 1 全程快速微分器 1.1仿真分析 1.2仿真模型 1.3仿真结果 1.4结论 2 Levant微分器 2.1仿真分析 2.2仿真模型 2.3仿真结果 3.总结 前言 工程上信号的微分是难以得到的,所以本文采用微分器实现带有噪声的信号及其微分信号提取,从而实现…...

链表学习之复制含随机指针的链表
链表解题技巧 额外的数据结构(哈希表);快慢指针;虚拟头节点; 复制含随机指针的链表 该链表节点的结构如下: class ListRandomNode { public:ListRandomNode() : val(0), next(nullptr), random(nullptr…...
【人脸检测】Yolov5Face:优秀的one-stage人脸检测算法
论文题目:《YOLO5Face: Why Reinventing a Face Detector》 论文地址:https://arxiv.org/pdf/2105.12931.pdf 代码地址:https://github.com/deepcam-cn/yolov5-face 1.简介 近年来,CNN在人脸检测方面已经得到广泛的应用。但是许多…...
【Unity3d】Unity与Android之间通信
在unity开发或者sdk开发经常遇到unity与移动端原生层之间进行通信,这里把它们之间通信做一个整理。 关于Unity与iOS之间通信,参考【Unity3d】Unity与iOS之间通信 Unity(c#)调用Android (一)、编写Java代码 实际上,任何已经存在的Java代码…...
Allegro如何更改DRC尺寸大小操作指导
Allegro如何更改DRC尺寸大小操作指导 在做PCB设计的时候,DRC可以辅助设计,有的时候DRC的尺寸过大会影响视觉,Allegro支持将DRC的尺寸变小或者改大 如下图,DRC尺寸过大 如何改小,具体操作如下 点击Setup选择Design Parameters...

Mongodb WT_PANIC: WiredTiger library panic
文章目录故障现象排查过程1.查看Log2.同步恢复数据故障现象 周五突然收到Mongo实例莫名奇妙挂了告警,一般都是RS复制集架构模式(5节点),查看此实例角色为SECONDAR,挂了暂时不影响线上业务,但还是需要尽快修…...
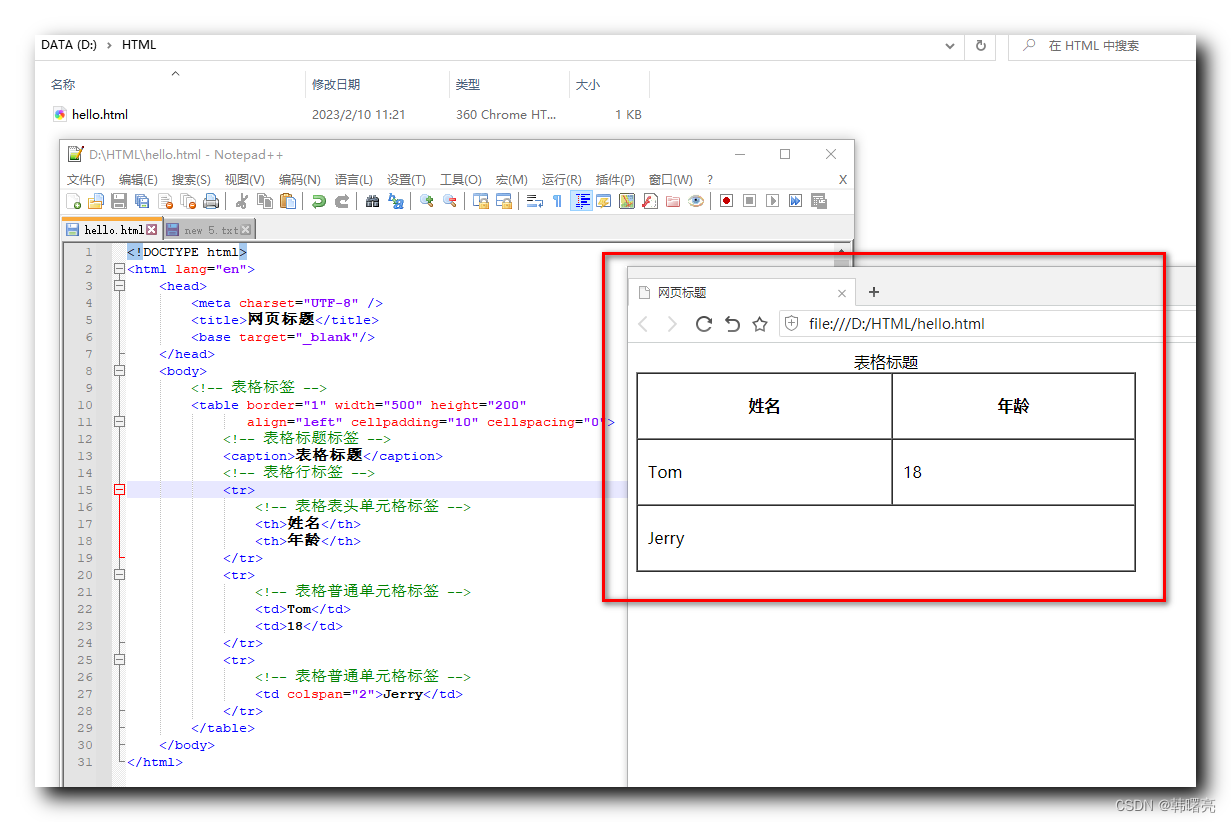
【HTML】HTML 表格总结 ★★★ ( 表格标签 | 行标签 | 单元格标签 | 表格标签属性 | 表头单元格标签 | 表格标题标签 | 合并单元格 )
文章目录一、表格标签组成 ( 表格标签 | 行标签 | 单元格标签 )二、table 表格属性 ( border 属性 | align 属性 | width 属性 | height 属性 )三、表头单元格标签四、表格标题标签五、合并单元格1、合并单元格方式2、合并单元格顺序3、合并单元格流程六、合并单元格示例1、原始…...

linux013之文件和目录的权限管理
用户、组、文件目录的关系: 简介:用户和组关联,组合文件目录关联,这样就实现了用户对文件的权限管理。首先来看一下,一个文件或目录的权限是怎么查看的,ls -l, 如下,这个信息怎么看呢…...
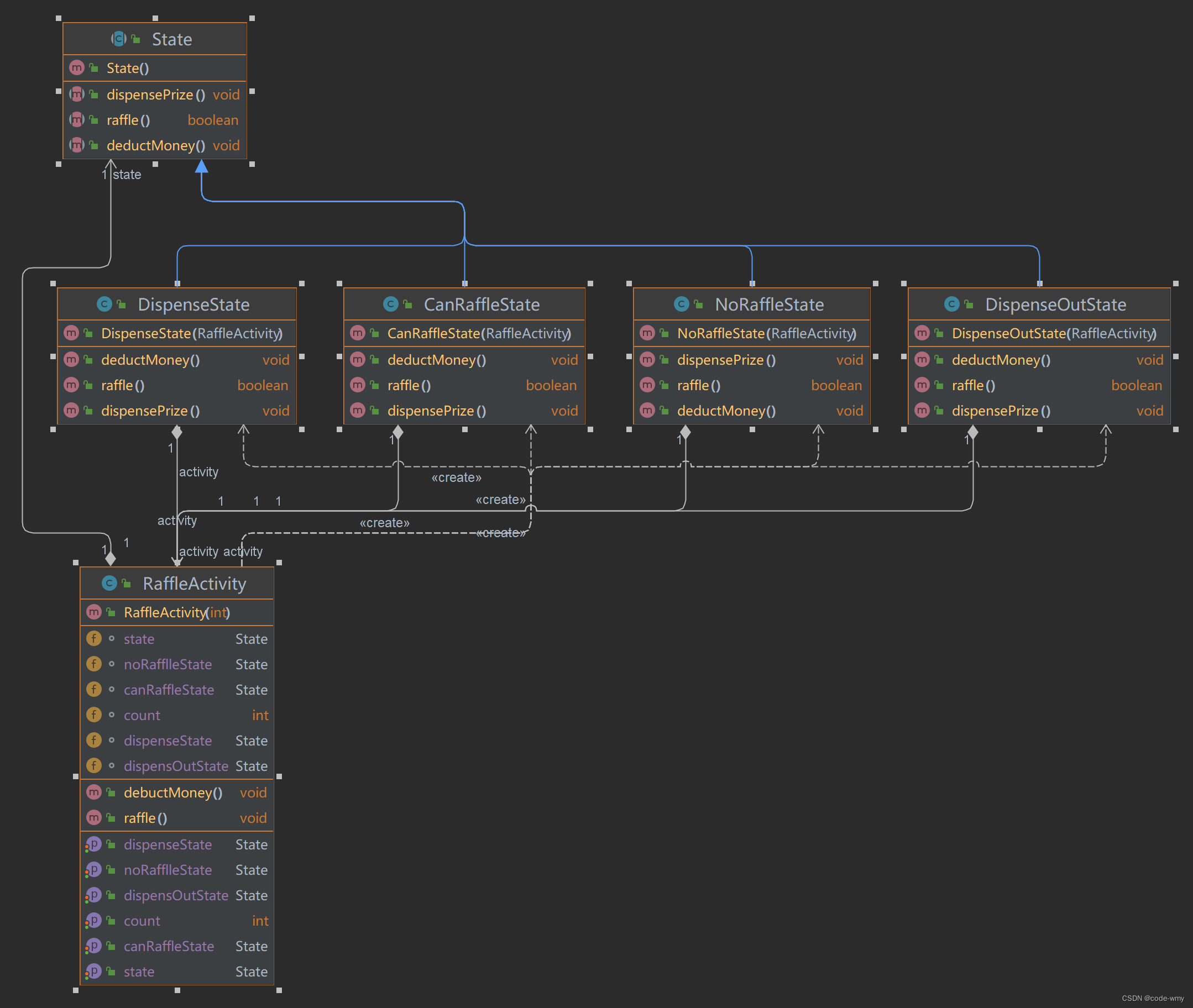
设计模式之状态模式
什么是状态模式 状态模式是指允许一个对象在其内部状态改变时改变他的行为,对象看起来似乎改变了整个类。 状态模式将一个对象在不同状态下的不同行为封装在一个个状态类中,通过设置不同的状态对象可以让环境对象拥有不同的行为,而状…...

XQuery 选择 和 过滤
XML实例文档 我们将在下面的例子中继续使用这个 "books.xml" 文档(和上面的章节所使用的 XML 文件相同)。 在您的浏览器中查看 "books.xml" 文件。 选择和过滤元素 正如在前面的章节所看到的,我们使用路径表达式或 FL…...

室友打了一把王者的时间,我理清楚了grep,find,管道|,xargs的区别与联系,用的时候不知道为什么要这样用
目录 问题引入 find和grep的基本区别 xargs命令 Linux命令的标准输入 vs 命令行参数 举例总结 问题引入 在自己做项目的过程中,想使用linux命令统计下一个目录下html文件的数量,在思考应该使用grep还是find去配合wc指令统计文件数量,后来…...
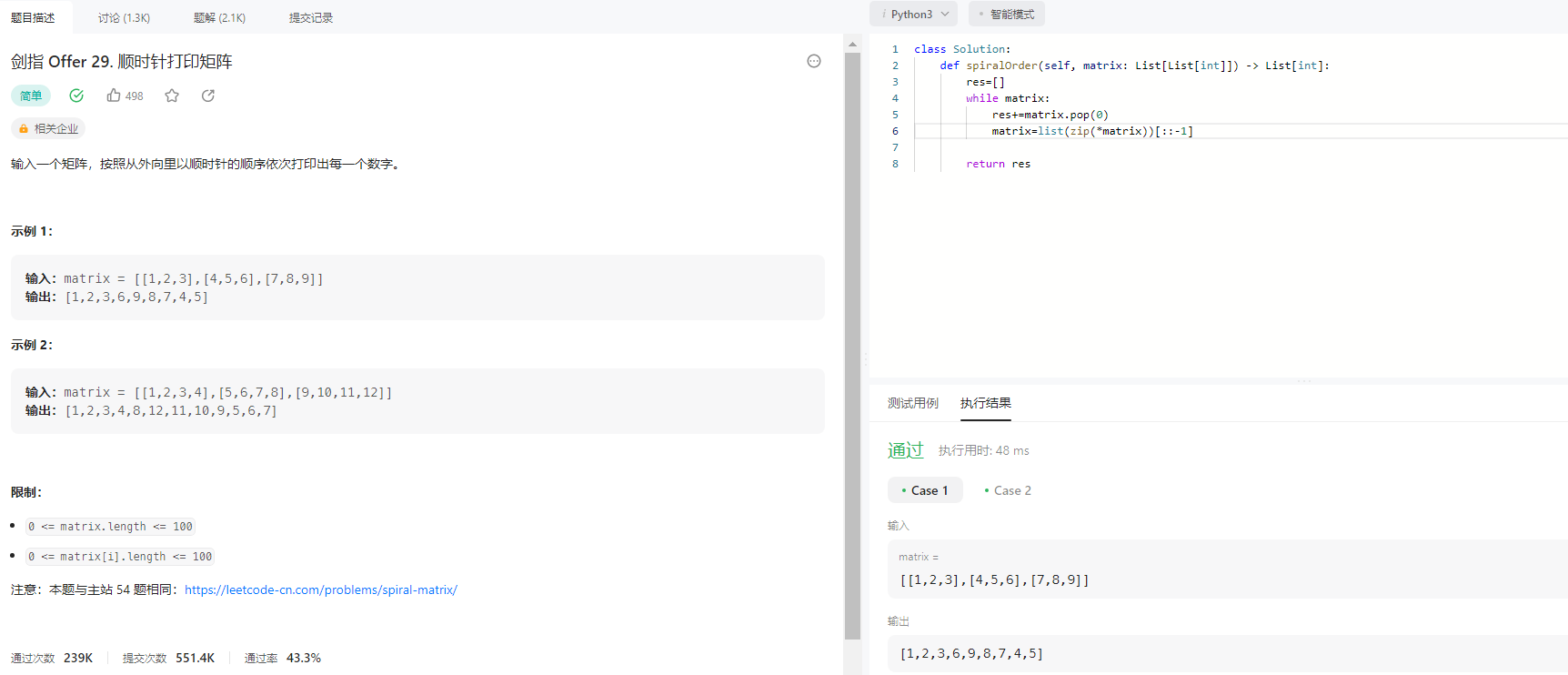
python 刷题时常见的函数
collections.OrderedDict 1. move_to_end() move_to_end() 函数可以将指定的键值对移动到最前面或者最后面,即最左边或最右边 。 2. popitem() popitem()可以完成元素的删除操作,有一个可选参数last(默认为True),…...

Python之列表推导式和列表排序
Python中的列表推导式,是小编比较喜欢的一种,他能大大减少你的代码量来得到你想要的结果,下面说说列表中常用的几种推导式 列表排序 Python开发中会经常用到排序操作,这里提供两种方式供大家参考,对象的sort()方法和…...

力扣(LeetCode)240. 搜索二维矩阵 II(C++)
题目描述 枚举 枚举整个矩阵,找到等于 target 的元素,则 return true ,否则 return false。 class Solution { public:bool searchMatrix(vector<vector<int>>& matrix, int target) {int n matrix.size(), m matrix[0]…...

MSP 盈利、留客、提口碑,核心就盯这12个 KPI
很多 MSP(托管服务提供商)都会陷入一个误区,手里握着一堆散落在各个看板的运营数据,却始终搞不清哪些指标能真正帮自己提升服务质量、拉高利润、留住客户。忙忙碌碌做了一堆报表,最终还是凭感觉做决策,业务…...

动感软膜天花技术白皮书:从异形设计到商业照明的实战解析
动感软膜天花技术白皮书:从异形设计到商业照明的实战解析动感软膜天花的科技内核与市场演进当人们走进现代商业空间,头顶那片既能模拟蓝天白云软膜天花效果,又能实现动态光影变幻的顶面系统,正是动感软膜天花技术的具象化呈现。这…...

基于Rust的飞书多智能体协作平台:中文联网搜索与智能交接实战
1. 项目概述:一个面向飞书深度集成的智能体协作平台 如果你正在寻找一个能无缝接入飞书、支持中文联网搜索、并且能让多个AI智能体协同工作的本地化开源项目,那么 hongyuatcufe/moltis-feishu 这个分支绝对值得你花时间研究。它不是一个简单的聊天机器…...

Godot开发者必备:awesome-godot资源库高效使用指南
1. 项目概述:一个开源游戏引擎的“宝藏库” 如果你正在使用或考虑使用 Godot 引擎进行游戏开发,那么你很可能已经听说过 awesome-godot 这个项目。它不是一个可以直接运行的软件,也不是一个插件,而是一个由社区共同维护的、结构…...

别再只用BigGantt了!这个免费JIRA甘特图插件Gantt Suite,配置简单速度快
轻量高效的JIRA甘特图解决方案:Gantt Suite全面评测与迁移指南 在项目管理领域,甘特图作为可视化排期的黄金标准已有百年历史。然而当这一经典工具遇上现代敏捷开发平台JIRA时,许多团队却陷入了两难境地——要么忍受BigGantt等老牌插件的臃肿…...

星际软件开发:为火星殖民地编写第一批代码
一、引言:当测试左移到大气层之外2041年,第一批火星殖民者即将启程。他们携带的不仅是氧气和速食,还有一座预装在密封舱里的微型数据中心。在这片红色荒漠上,代码将比氧气更早醒来——生命维持系统的控制逻辑、通讯中继的协议栈、…...

软件设计师下午题训练1-3题 练习真题训练10
一、2019下1、问题1E1:帮买顾问E2:车辆交易系统E3:物流商2、问题2D1:线索表D2:订单表D3:路线表D4:合约表D5:物流商表3、问题3数据流 起点 终点物流信息 P5 …...

【独家】Lindy内部SLO白皮书泄露:自主工作流SLA达标率低于99.95%的5个致命信号
更多请点击: https://intelliparadigm.com 第一章:Lindy AI Agent自主工作流的核心架构与SLO哲学 Lindy AI Agent 的核心架构基于“自治闭环”(Autonomous Closed Loop)范式,将任务规划、工具调用、状态反馈与自校准能…...
原理、影响与防护策略全解析)
FPGA单粒子翻转(SEU)原理、影响与防护策略全解析
1. 是什么在“骚扰”我的FPGA?——深入解析单粒子翻转作为一名在电子设计领域摸爬滚打了十几年的工程师,我经手过不少高可靠性的项目,从地面通信基站到近地轨道的载荷设备都有涉及。在这些项目中,有一个幽灵般的问题总是如影随形&…...

Windows 10 PL2303驱动修复终极指南:3种方案解决串口设备兼容性问题
Windows 10 PL2303驱动修复终极指南:3种方案解决串口设备兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 PL2303驱动修复方案是解决Windows 10系…...