Datawhale组队学习:大数据 D2——分布式文件系统(HDFS)
妙趣横生大数据 Day2
- 三、Hadoop 分布式文件系统(HDFS)
- 1. 分布式文件系统
- 2. HDFS 简介
- 3. HDFS 体系结构
- 4. HDFS存储原理
- 数据冗余存储
- 数据存储策略
- 数据错误与恢复
- 5. HDFS数据读写过程
- 读写过程
- HDFS故障类型和其检测方法
- HDFS编程实验
- 1. 本地和集群文件间操作
- 2. 基本文件操作
- 3. Hadoop 系统操作
Datawhale
大数据技术相关内容的导论课程:妙趣横生大数据 Juicy Big Data
三、Hadoop 分布式文件系统(HDFS)
1. 分布式文件系统
分布式文件系统:管理网络中跨多台计算机存储的文件系统;解决海量数据的高效存储。
文件采取“块”的方式存储,块是数据读取的基本单元。HDFS默认一个块大小为64MB(普通文件系统磁盘块为512字节),设计比较大的块的目的是为了最小化寻址开销;同时也要避免块过大影响MapReduce并行速度。
设计:“客户机/服务器”(Client/Server)
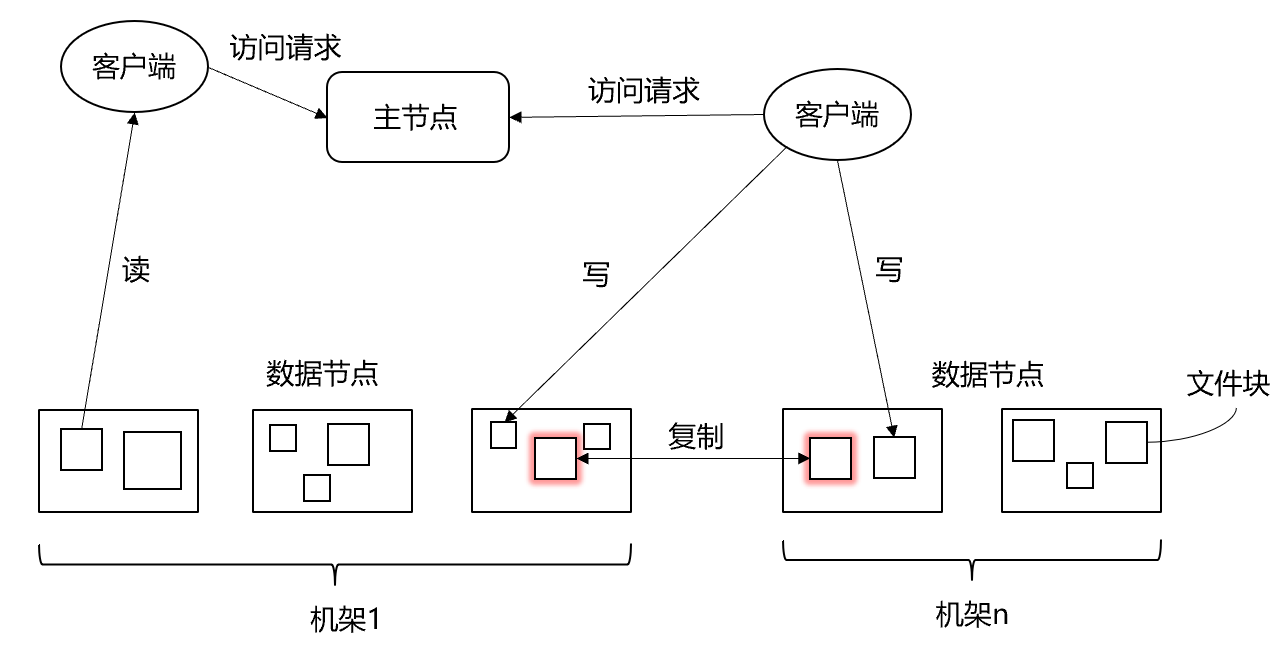
物理结构:
- 主节点(Master Node),名称节点(NameNode)
- 文件和目录的创建、删除和重命名
- 管理数据节点和文件快的映射关系
- 从节点(Worker Node),数据节点(DataNode)
- 数据的存储和读取
- 分布式文件系统采用多副本存储,以保证数据完整性
- 分布式文件系统为大规模数据存储设计(TB级文件)
2. HDFS 简介
HDFS(Hadoop Distribute File System)
- 是大数据领域中以分布式方式存储超大数据量文件的存储系统
- HDFS是Hadoop和其他组件的数据存储层
优点:
- 兼容廉价的硬件设备:实现在硬件故障的情况下也能保障数据的完整性
- 流数据读写:不支持随机读写的操作
- 大数据集:数据量一般在GB、TB以上的级别
- 简单的文件模型:一次写入、多次读取
- 强大的跨平台兼容性:采用
Java语言实现
局限性:
- 不适合低延迟数据访问:流式数据读取,较高延迟
- 无法高效存储大量小文件:影响元数据减少效率、增加Mpa任务线程管理开销、数据节点间跳跃频繁影响性能
- 不支持多用户写入及任意修改文件:一个文件只有一个写入者,只允许对文件追加操作
3. HDFS 体系结构
主从(Master/Slave)结构模型
一个HDFS集群包括:
- 一个名称节点(NameNode)
- 若干个数据节点(DataNode)
- 周期性发送“心跳”信息,报告状态
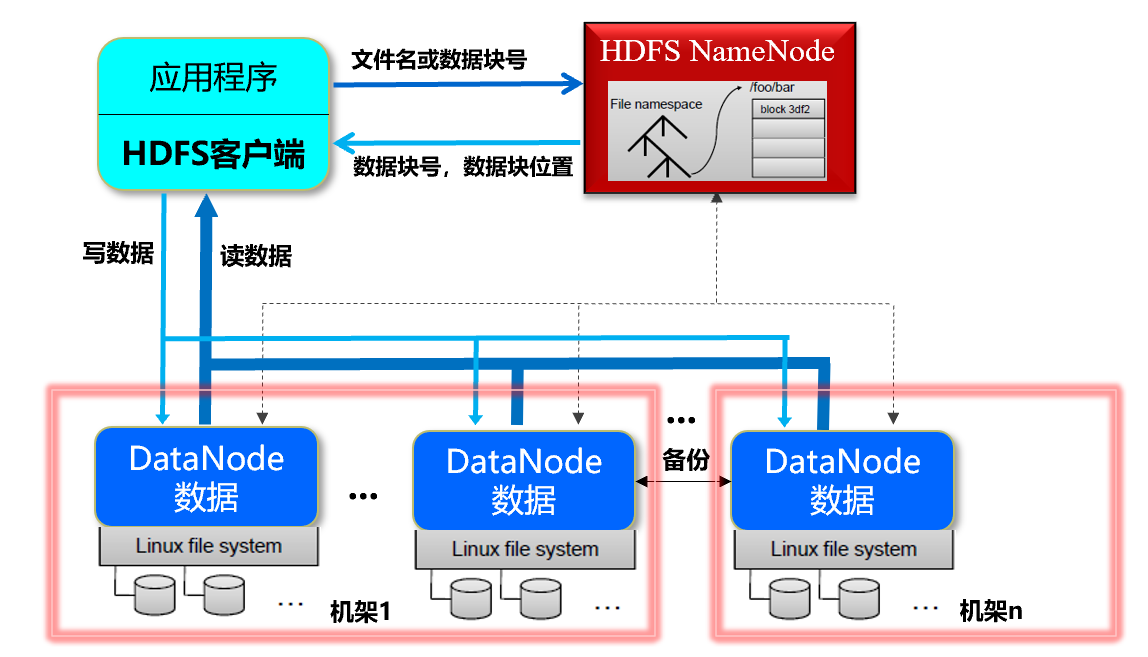
【说明】用户使用 HDFS,
客户端存储时:
- 一个文件分为若干个数据块存储
- 每个数据块分布存储到若干个 DataNode 上
客户端读取时:
- 根据文件名从 NameNode 获取 数据块 和 数据块位置(DataNode)
- 访问 DataNode 获取数据
【优点】提高了数据访问速度,读取一个文件时从不同 DataNode 上并发访问
4. HDFS存储原理
数据冗余存储
多副本方式,一个数据块的多个副本被分布到不同的数据节点上
- 加快数据传输速度
- 容易检出数据错误
- 保证数据的可靠性
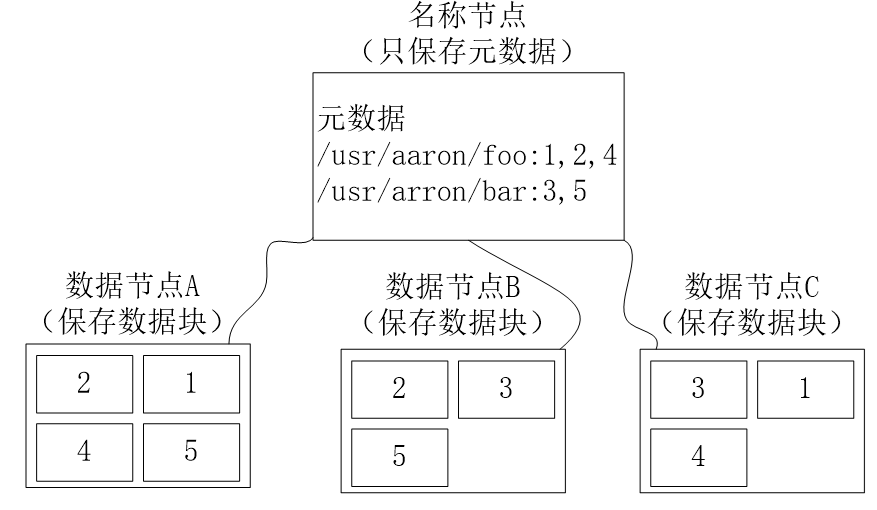
数据存储策略
-
数据存储
-
HDFS采用了以 **机架(Rack)**为基础的数据存放策略,一个HDFS集群通常包含多个机架
- 不同机架之间的数据通信需要经过交换机或路由器
- 同一机架的不同机器之间数据通信不需要交换机或路由器(通信带宽比不同机架间通信带宽大)
-
HDFS 默认每个数据节点都是在不同机架上
-
缺点:写入数据的时候不能充分利用同一机架内部机器之间的带宽
-
优点:1. 很高的数据可靠性
2. 多机架并行读取数据,提高数据读取速度
3. 更容易实现系统内部负载均衡和错误纠正
-
-
HDFS默认的冗余复制因子是 3
- 每一个文件会被同时保存到 3 个地方
- 两份副本放在同一个机架的不同机器上面
- 第三个副本放在不同机架的机器上面
- 每一个文件会被同时保存到 3 个地方
-
-
数据读取
- HDFS提供了一个确定DataNode所属机架 ID 的 API,读取时就近读取
-
数据复制
- 流水线复制(第一个DataNode写入数据后,会根据列表中DataNode将数据和列表传给第二个DataNode,以此类推)
数据错误与恢复
-
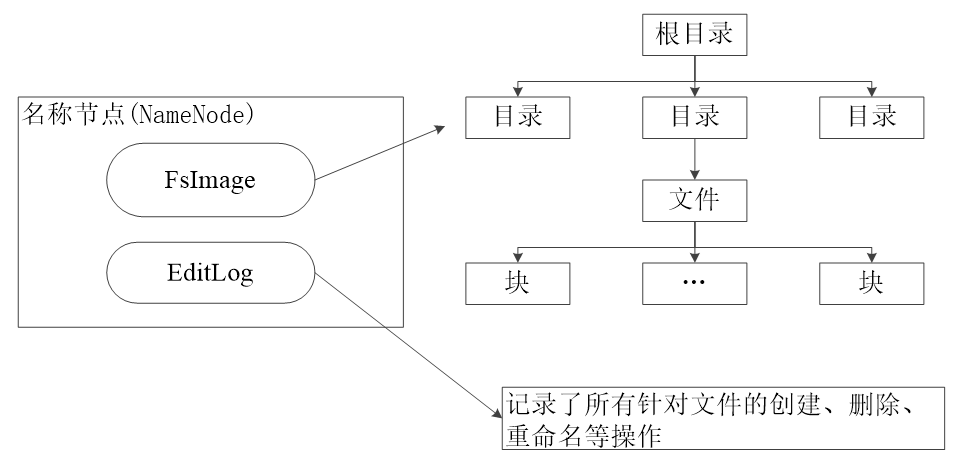
NameNode 出错
- NameNode 元数据信息同步存储到其他文件系统
- 第二名称节点
-
DataNode 出错
- NameNode 没收到 DataNode 的‘心跳’信息,便定义为‘宕机’,数据标记为不可读,取消 I/O 请求
- 名称节点检查发现某个数据的副本数量小于冗余因子时,启动数据冗余复制生成新的副本
-
数据出错
- 网络传输和磁盘错误
md5和sha1校验、信息文件校验
5. HDFS数据读写过程
读写过程
翻译经典 HDFS 原理讲解漫画 之一----系统构成和写数据过程_笑寒x的博客-CSDN博客
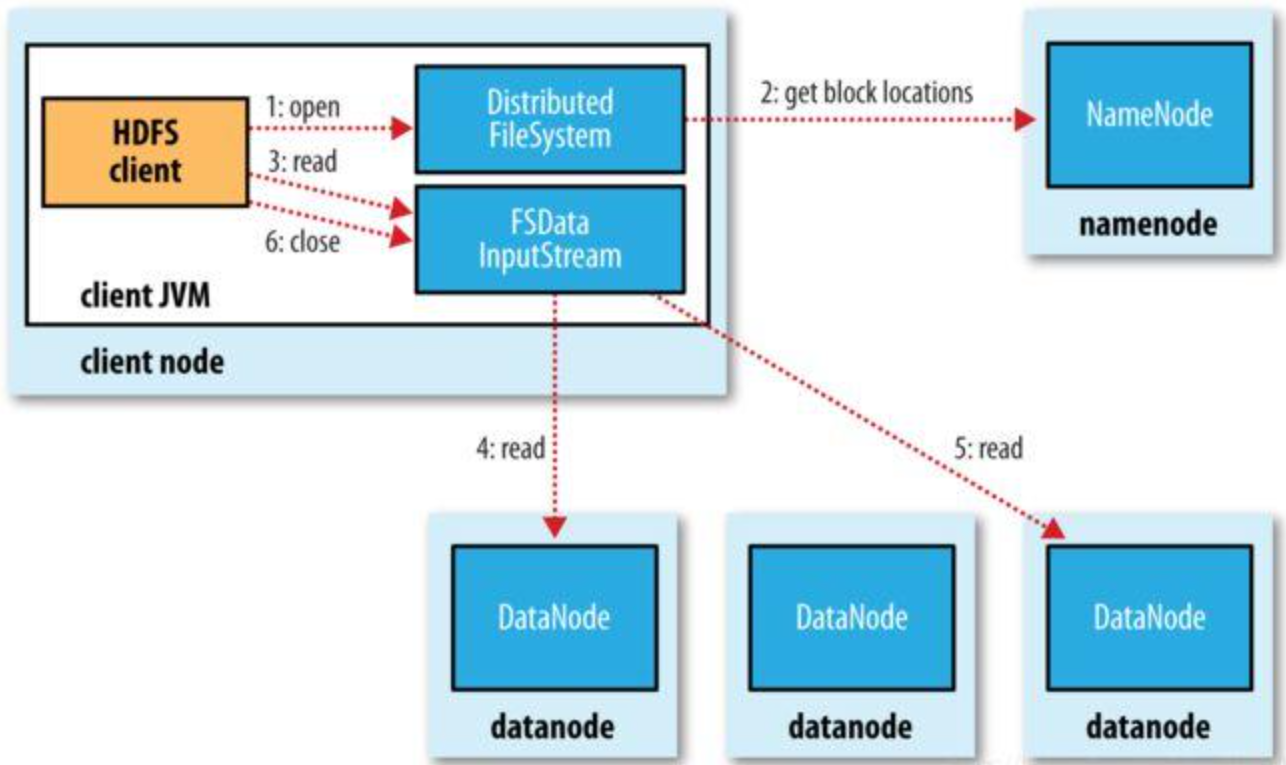
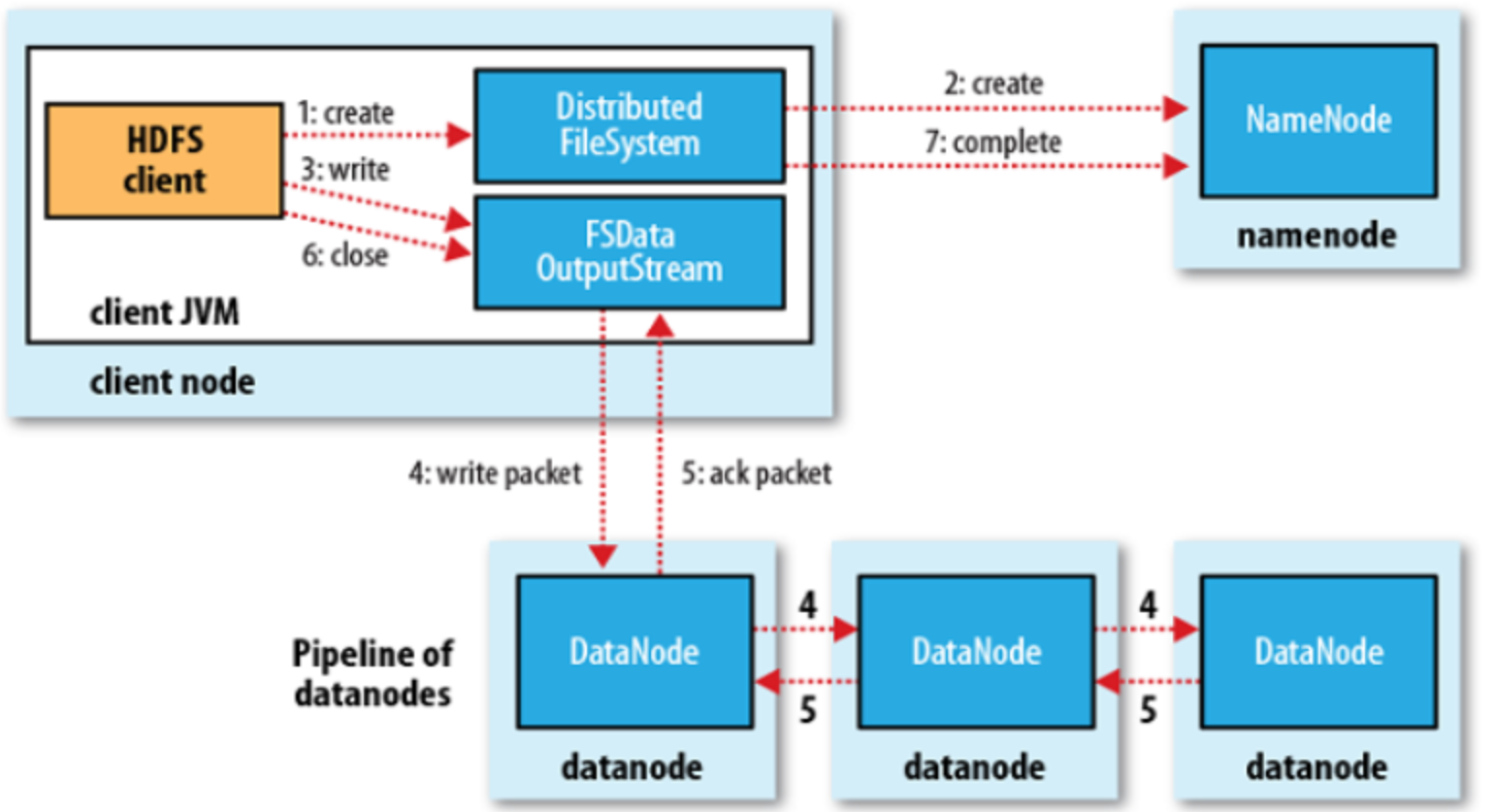
HDFS故障类型和其检测方法
- 读写故障的处理
- 读:从其他备份的节点读取(NameNode会返回数据块存在的所有DataNode)
- 写:没有收到DataNode接受数据块的应答信号,调整通道跳过这个节点
翻译经典 HDFS 原理讲解漫画 之二----读数据和容错_笑寒x的博客-CSDN博客
-
DataNode故障处理
-
NameNode 表
- 数据块列表:数据块N —— 存储在 DN1, DN2, DN3
- DataNode列表:DATANODE 1 —— 存储数据块1,…,数据块N
-
持续更新这两个表
-
数据未充分备份会启动DataNode备份(前提是HDFS至少存在一个备份)
-
-
副本布局策略
- 第一个:就近
- 后续:不同机架(每个机架最多存储两份副本)
翻译经典 HDFS 原理讲解漫画 之三—容错和副本布局策略_笑寒x的博客-CSDN博客
HDFS编程实验
1. 本地和集群文件间操作
# 拷贝目录到集群
hadoop fs -put <local dir> <hdfs dir>
# 拷贝文件
hadoop fs -put <local file> <hdfs dir># 拷贝到本地
hadoop fs -get < hdfs file or dir > < local file or dir># 拷贝并移除
hadoop fs -moveFromLocal <local src> <hdfs dst>


2. 基本文件操作
# 查看
hadoop fs -ls / # -R: 包含子目录下文件# 删除
hadoop fs -rm -r <hdfs dir> ...
hadoop fs -rm <hdfs file> ...# 创建
hadoop fs -mkdir <hdfs path># 复制
hadoop fs -cp <hdfs file or dir>... <hdfs dir># 移动
hadoop fs -mv <hdfs file or dir>... <hdfs dir>
# 统计路径下的目录个数,文件个数,文件总计大小
hadoop fs -count <hdfs path>#显示文件夹和文件的大小
hadoop fs -du <hdsf path># 查看文件
hadoop fs -cat /demo.txt
hadoop fs -tail -f /demo.txt# 更改权限
hadoop fs -chown user:group /datawhale
hadoop fs -chmod 777 /datawhale
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ObVAZO1S-1676724750207)(HDFS/image-20230218171901366.png)]](https://img-blog.csdnimg.cn/683538375ed349de99e8ece10c41820a.png#pic_center)
# 本地文件内容追加到hdfs文件系统中的文本文件
hadoop fs -appendToFile <local file> <hdfs file>
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H9cJuM6m-1676724750207)(HDFS/image-20230218202538200.png)]](https://img-blog.csdnimg.cn/2cf7535a6b5c45d8804a9e97da5cb307.png#pic_center)
这里遇到一个错误:Failed to APPEND_FILE /p1 for DFSClient_NONMAPREDUCE_985284284_1 on 192.168.137.101 because lease recovery is in progress. Try again later.
解决:hdfs dfs -appendToFile error 问题解决_故事の尾音的博客-CSDN博客_hdfs appendtofile
# 修改 hdfs-stie.xml 文件
<!-- appendToFile追加 -->
<property><name>dfs.support.append</name><value>true</value>
</property><property><name>dfs.client.block.write.replace-datanode-on-failure.policy</name><value>NEVER</value>
</property>
<property><name>dfs.client.block.write.replace-datanode-on-failure.enable</name><value>true</value>
</property>
3. Hadoop 系统操作
# 改变文件在hdfs文件系统中的副本个数
hadoop fs -setrep -R 3 <hdfs path># 查看对应路径的状态信息
hdoop fs -stat [format] < hdfs path ># %b:文件大小
# %o:Block大小
# %n:文件名
# %r:副本个数
# %y:最后一次修改日期和时间# 手动启动内部的均衡过程(DataNode 数据保存不均衡)
hadoop balancer # 或 hdfs balancer# 管理员通过 dfsadmin 管理HDFS
hdfs dfsadmin -help
hdfs dfsadmin -report
hdfs dfsadmin -safemode <enter | leave | get | wait>
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WPScNjvH-1676724750207)(HDFS/image-20230218204809616.png)]](https://img-blog.csdnimg.cn/b94e06de44f84f5c9fa6ddc7d1cd09a5.png#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IjuanMXa-1676724750208)(HDFS/image-20230218205017836.png)]](https://img-blog.csdnimg.cn/609cfeaf796446e9aa9f5d7eb0f3afb6.png#pic_center)
Datawhale
大数据技术相关内容的导论课程:妙趣横生大数据 Juicy Big Data
相关文章:
Datawhale组队学习:大数据 D2——分布式文件系统(HDFS)
妙趣横生大数据 Day2三、Hadoop 分布式文件系统(HDFS)1. 分布式文件系统2. HDFS 简介3. HDFS 体系结构4. HDFS存储原理数据冗余存储数据存储策略数据错误与恢复5. HDFS数据读写过程读写过程HDFS故障类型和其检测方法HDFS编程实验1. 本地和集群文件间操作2. 基本文件操作3. Hado…...
CCIE重认证-300-401-拖图题全
拖图 拖图题 编程 snippet;192.168.5.0,mask 255.255.255.0;number是192.168.5.0;mask是255.255.255.0 snippets;edit-config对config,loopback对name 100,address对primary,mask…...

如何动态的创建类?type的其他用法?什么是元类,如何自定义元类?
1、python中一切都是对象,类也不例外,type是object的子类,是创建类的类。 如何动态的创建一个类? 用脚丫子创建 用脑子创建 不会 不知道什么事动态类 大家可能会有一堆的疑惑,是的我也是有很多疑惑那让我们一起来探个…...

XCP实战系列介绍15-XCP故障排查指导
本文框架 1.概述2. 通过调试器排查2.1 打开Det功能2.2 如何确定Det ErrorCode3. 通过XCP应答报文排查3.1 FE报文组成及故障码对应关系3.2 举个例子1.概述 前面几篇文章我们介绍了基于Davinci开发工具的XCP配置指导,配好了,代码也生成了,但是程序一定能正常跑起来吗?就算软…...

吉林大学软件需求分析与规范(Software Requirements Analysis Specification)
chapter0课程简介:◼ 软件工程专业核心课程之一◼ 软件工程课程体系最前端课程◼ 主要内容:需求的基本概念,需求的分类,需求工程的基本过程,需求获取的方法、步骤、技巧,需求分析和建模技术,需求…...
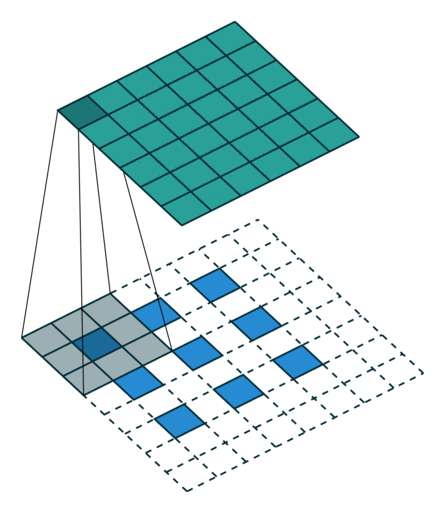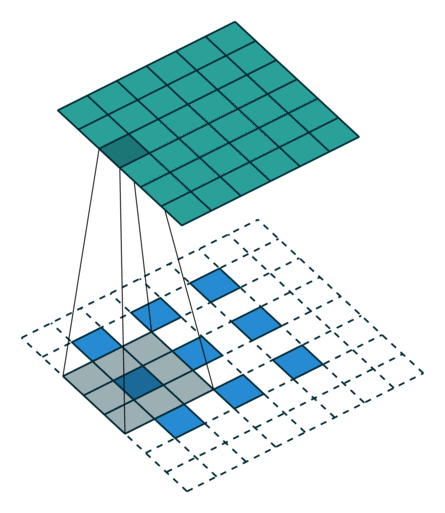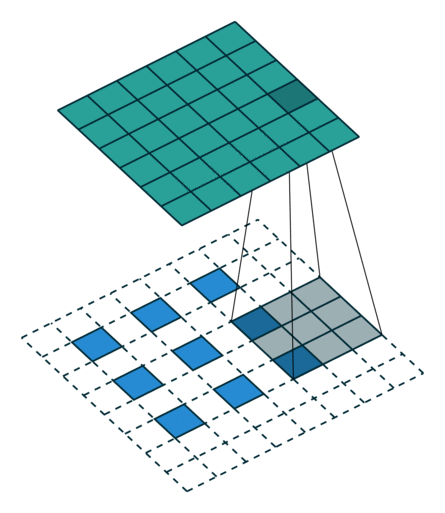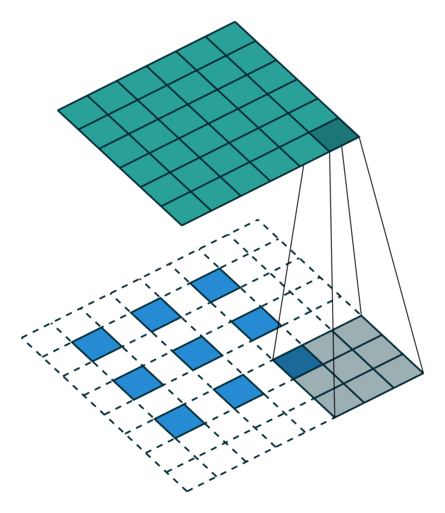
PyTorch - Conv2d 和 MaxPool2d
文章目录Conv2d计算Conv2d 函数解析代码示例MaxPool2d计算函数说明卷积过程动画Transposed convolution animationsTransposed convolution animations参考视频:土堆说 卷积计算 https://www.bilibili.com/video/BV1hE411t7RN 关于 torch.nn 和 torch.nn.function t…...
)
leetcode Day2(昨天实习有点bug,心态要崩了)
int carry 0;for(int i a.size() - 1, j b.size() - 1; i > 0 || j > 0 || carry; --i, --j) {int x i < 0 ? 0 : a[i] - 0;int y j < 0 ? 0 : b[j] - 0;int sum (x y carry) % 2;carry (x y carry) / 2;str.insert(0, 1, sum 0);}return str;加一&a…...

另一种思考:为什么不选JPA、MyBatis,而选择JDBCTemplate
以下内容转载自:https://segmentfault.com/a/1190000018472572 作者:scherman 因为项目需要选择数据持久化框架,看了一下主要几个流行的和不流行的框架,对于复杂业务系统,最终的结论是,JOOQ是总体上最好的…...

LeetCode 338. 比特位计数
给你一个整数 n ,对于 0 < i < n 中的每个 i ,计算其二进制表示中 1 的个数 ,返回一个长度为 n 1 的数组 ans 作为答案。 示例 1: 输入:n 2 输出:[0,1,1] 解释: 0 --> 0 1 --> …...
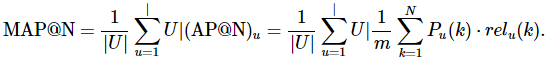
排序评估指标——NDCG和MAP
在搜索和推荐任务中,系统常返回一个item列表。如何衡量这个返回的列表是否优秀呢? 例如,当我们检索【推荐排序】,网页返回了与推荐排序相关的链接列表。列表可能会是[A,B,C,G,D,E,F],也可能是[C,F,A,E,D],现在问题来了…...

[Android Studio] Android Studio Virtual Device(AVD)虚拟机的功能试用
🟧🟨🟩🟦🟪 Android Debug🟧🟨🟩🟦🟪 Topic 发布安卓学习过程中遇到问题解决过程,希望我的解决方案可以对小伙伴们有帮助。 🚀write…...
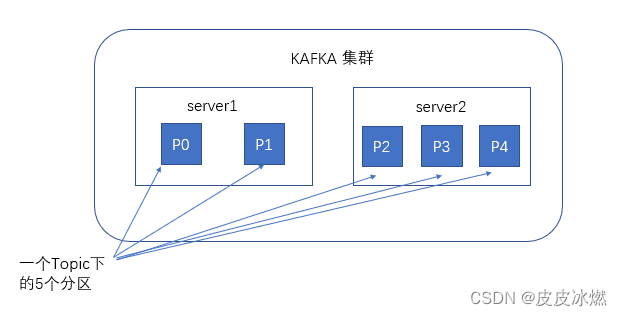
kafka-3-kafka应用的核心要点和内外网访问
kafka实战教程(python操作kafka),kafka配置文件详解 Kafka内外网访问的设置 1 kafka简介 根据官网的介绍,ApacheKafka是一个分布式流媒体平台,它主要有3种功能: (1)发布和订阅消息流,这个功能类似于消息队列&#x…...
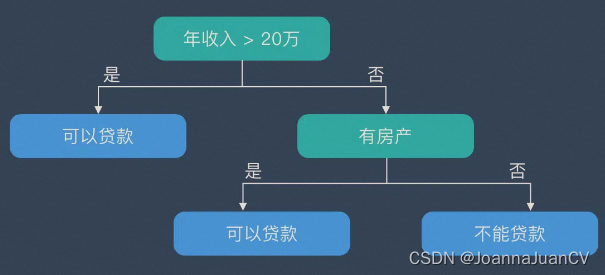
VS2017+OpenCV4.5.5 决策树-评估是否发放贷款
决策树是一种非参数的监督学习方法,主要用于分类和回归。 决策树结构 决策树在逻辑上以树的形式存在,包含根节点、内部结点和叶节点。 根节点:包含数据集中的所有数据的集合内部节点:每个内部节点为一个判断条件,并且…...

Prometheus 记录规则和警报规则
前提环境: Docker环境 涉及参考文档: Prometheus 录制规则Prometheus 警报规则 语法检查规则 promtool check rules /path/to/example.rules.yml一:录制规则语法 groups 语法: groups:[ - <rule_group> ]rule_group…...

(API)接口测试的关键技术
接口测试也就是API测试,从名字上可以知道是面向接口的测试活动。所以在讲API测试之前,我们应该说清楚接口是什么,那么接口就是有特定输入和特定输出的一套逻辑处理单元,而对于接口调用方来说,不用知道自身的内部实现逻…...

快速排序算法原理 Quicksort —— 图解(精讲) JAVA
快速排序是 Java 中 sort 函数主要的排序方法,所以今天要对快速排序法这种重要算法的详细原理进行分析。 思路:首先快速排序之所以高效一部分原因是利用了离散数学中的传递性。 例如 1 < 2 且 2 < 3 所以可以推出 1 < 3。在快速排序的过程中巧…...

linux环境搭建私有gitlab仓库
搭建之前,需要安装相应的依赖包,并且要启动sshd服务(1).安装policycoreutils-python openssh-server openssh-clients [rootVM-0-2-centos ~]# sudo yum install -y curl policycoreutils-python openssh-server openssh-clients [rootVM-0-2-centos ~]…...

SpringSecurity授权
文章目录工具类使用自定义失败处理代码配置跨域其他权限授权hasAnyAuthority自定义权限校验方法基于配置的权限控制工具类 import javax.servlet.http.HttpServletResponse; import java.io.IOException;public class WebUtils {/*** 将字符串渲染到客户端** param response 渲…...

学习 Python 之 Pygame 开发坦克大战(一)
学习 Python 之 Pygame 开发坦克大战(一)Pygame什么是Pygame?初识pygame1. 使用pygame创建窗口2. 设置窗口背景颜色3. 获取窗口中的事件4. 在窗口中展示图片(1). pygame中的直角坐标系(2). 展示图片(3). 给部分区域设置颜色5. 在窗口中显示文字6. 播放音…...

2.5|iot冯|方元-嵌入式linux系统开发入门|2.13+2.18
一、 Linux 指令操作题(共5题(共 20 分,每小题 4分)与系统工作、系统状态、工作目录、文件、目录、打包压缩与搜索等主题相关。1.文件1.1文件属性1.2文件类型属性字段的第1个字符表示文件类型,后9个字符中,…...

ARM动态内存控制器与SDRAM地址映射技术详解
1. ARM动态内存控制器基础解析动态内存控制器(Dynamic Memory Controller,简称DMC)是现代嵌入式系统中管理SDRAM等易失性存储器的核心组件。作为处理器与存储设备之间的桥梁,DMC通过高效的地址映射技术实现两者间的数据通信。在AR…...

ElevenLabs账号被限频?紧急修复手册:3分钟绕过Rate Limit限制,解锁Pro级语音并发权限
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs超写实语音生成教程 ElevenLabs 是当前业界领先的 AI 语音合成平台,其模型在语调自然度、情感表达力与跨语言一致性方面表现卓越。本章将指导你完成从 API 接入到高质量语音生成的…...

Resolink MCP:基于MCP协议与Playwright的AI浏览器自动化实践
1. 项目概述:当AI助手学会“动手”——Resolink MCP的浏览器自动化革命如果你和我一样,每天在Cursor、Claude这类AI编程助手的陪伴下写代码,那你一定遇到过这样的场景:你正和AI热烈讨论一个技术方案,突然需要去浏览器里…...
)
【仅开放72小时】:Gemini Workspace与Microsoft Entra ID双向同步的密钥轮换脚本(含自动审计日志生成器)
更多请点击: https://intelliparadigm.com 第一章:Gemini Workspace整合方案概述 Gemini Workspace 是 Google 推出的面向企业级 AI 协作的统一平台,其核心价值在于将 Gemini 模型能力深度嵌入办公套件(如 Gmail、Drive、Docs、M…...

氛围编程实战:用AI工具栈快速构建可部署应用
1. 项目概述:什么是“氛围编程”?如果你对“氛围编程”这个词感到陌生,或者觉得它听起来有点玄乎,那太正常了。我第一次听到时,也以为又是哪个硅谷弄潮儿发明的新潮黑话。但当我真正开始实践,并在几个月内从…...

3步掌握SubtitleOCR:从视频到可编辑字幕的智能转换指南
3步掌握SubtitleOCR:从视频到可编辑字幕的智能转换指南 【免费下载链接】SubtitleOCR 快如闪电的硬字幕提取工具。仅需苹果M1芯片或英伟达3060显卡即可达到10倍速提取。A very fast tool for video hardcode subtitle extraction 项目地址: https://gitcode.com/g…...

SkillSync MCP:为AI技能市场构建自动化安全门禁系统
1. 项目概述:为AI技能市场装上“安全门” 如果你和我一样,是Claude Code、Cursor这类AI编程助手的深度用户,那你一定对“技能”(Skills)这个概念不陌生。简单来说,技能就是一些预定义的提示词模板或工具脚…...

3分钟搞定浏览器二维码:Chrome QRCode插件的终极使用秘籍
3分钟搞定浏览器二维码:Chrome QRCode插件的终极使用秘籍 【免费下载链接】chrome-qrcode :zap: A Chrome plugin to Genrate QRCode of URL / Text, or Decode the QRcode in website. 一个Chrome浏览器插件,用于生成当前URL或者选中内容的二维码&#…...

ARM CoreSight DAP-Lite调试架构与双协议切换技术
1. ARM CoreSight DAP-Lite技术架构解析作为ARM调试体系的核心组件,DAP-Lite(Debug Access Port Lite)是嵌入式系统开发中连接调试工具与片上资源的桥梁。我在实际芯片调试中发现,这个仅约2mm面积的IP模块,却能实现传统…...

Vitis HLS里给LED闪烁函数‘打标签’:深入解读ap_hs与ap_none协议的选择与实战影响
Vitis HLS中LED闪烁函数接口协议深度解析:ap_hs与ap_none的硬件实现差异与工程选择 在FPGA开发中,Vitis HLS作为高级综合工具,能够将C代码转换为可综合的硬件描述语言。然而,许多开发者在使用过程中常常忽略一个关键细节——函数…...