顺丰科技数据治理实践
01
顺丰数据治理体系演进路线
顺丰做数据治理十多年,数据治理体系的模块是逐步来建设的。十年前,我们就已经建了数仓,同步做了元数据管理,数据质量管理,以及数据安全的管理。顺丰数据治理的演进路线分 3 个阶段。
第一阶段:
2020 年前,我们主要在进行数据平台的搭建,关键领域能力的建设。关键领域能力建设方面,包括元数据管理、主数据管理、数据质量管理、数据安全。
第二阶段:
2020、2021 及 2022 年上半年,在加强领域能力建设的同时,我们更多的把数据治理的工作和业务更紧密的结合在一起,我们发现,在数据治理体系建设的过程中,如果没有业务的参与,该工作就变成了一个纯科技的工作,难以得到有效的落地。因此,在 2020 到 2021 年,我们成立了专职的数据治理团队,进行数据治理体系能力的建设。这个专职的团队,有科技方和业务方共同参与,业务方包含了顺丰科技各条业务线上的业务、财务、采购、人资、市场人员等。
第三阶段:
2022 年下半年及以后,顺丰科技在深层次的进行着整个数据治理体系的完善。这个阶段,工作聚焦在资产管理、数据标准建设、还有主数据 OneID 的打通。组织建设上,我们成立了集团层面即顺丰数运层面的数据治理委员会,来统筹运作数据治理体系的建设。
我们建设数据治理体系的目标是:
一,构建长治久安的数据治理体系,实现数据安全便捷共享。
二,整合沉淀公司的公共数据资产。
三,快速响应,便捷支持业务、支持前台研发的数据需求。
02
顺丰数据治理整体框架
顺丰数据治理的整体框架中,最顶层的设计战略主要是政策规范。顺丰有顺丰集团的数据治理总纲,基于总纲,还制定了主数据管理规范、指标口径管理规范、数据安全管理政策等各类政策规范。
数据治理领域主要包含元数据管理、主数据管理、交易数据管理、指标数据管理、以及数据安全、数据质量、数据标准。我之前参与过华润、华为、碧桂园的数据治理工作,在数据治理领域方面,各公司大同小异,有些公司不包含交易数据,有些公司会包含数据服务,数据模型管理等。在顺丰主要关注元数据、主数据、交易数据、指标数据的安全、质量和标准的管理。
在数据治理组织层面,我们有顺丰的数据治理委员会和专职的数据治理工作组,也有相应的业务方和平台方。
在平台工具层面,我们有主数据管理平台、元数据管理平台、数据质量管理工具和数据市场。这些和其他的公司基本类似。
1. 政策规范
顺丰数据治理总纲是数据治理体系的纲领文件,顺丰数据治理体系的相应的规范政策都是在数据治理体系总纲的指导下,来进行编写的,包括主数据的管理规范,数据安全的管理制度,数据质量的管理要求,数据标准的管理办法,及指标口径的管理规范。
如主数据的管理规范,基于顺丰集团主数据管理规范的要求,针对每一类主数据,我们制定了相应的主数据管理办法:如客户主数据管理办法、供应商主数据管理办法、人资主数据管理办法、财务主数据管理办法,用户主数据管理办法等。管理办法涉及主数据管理的目的、管理组织、管理的属性标准等,我们以此来构建主数据管理规范的内容。
2. 治理组织建设
我们成立了集团层的数据治理委员会。
首先它包含了业务侧的治理工作组,科技侧的治理工作组。这是两个虚拟组织,各由其业务领域的业务专家,各科技研发中心的技术专家组成。同样它包含 3 个实体组织:业务数据 Owner、业务科技 Owner、平台方。业务数据 Owner 参考了我们的 GPO(流程 Owner)的概念,业务部门的核心领导就是业务数据 Owner,业务数据 Owner 来承载业务数据的定义、分类、保护、使用及授权。业务科技 Owner 是业务数据 Owner 对应的科技研发中心。比如供应商数据的业务数据 Owner 是集团采购供应链中心,业务科技 Owner 是采购与综合解决方案研发中心。平台方由大数据平台研发中心的专职人员组成,主要是负责协助业务数据 Owner,业务科技 Owner 来做数据治理体系的整体的建设。
这是我们在组织层面做的事情。这么做是因为,关于数据治理的很多建设工作,包括标准的制定,如果仅仅是科技侧来制定这个标准,标准有时会慢慢的变形;同样,数据质量想要达到闭环,从业务走到科技,从科技再回到业务,实现质量的闭环,需要多方的参与,否则数据质量问题就会重复的出现;更重要的一个原因是,建设数据治理体系,我们需要一个组织,有一个一把手来统筹运作,规划指引。
顺丰数据治理委员会的主任是顺丰集团的 CIO,它的成员包括顺丰科技各条线的业务领导,科技领导,我们成立了这样一个组织,来推进数据治理体系的工作。
03
数据治理各领域能力介绍
1. 主数据管理平台
主数据管理平台,从 2019 年开始,经过 3 年的建设。平台的定位在于主数据标准的管理,主数据线上化管理,统一标准的主数据服务。主数据标准管理用于管理制定的各类主数据的标准。IT 数字化建设过程中会存在一些没有源头,没有 Owner 的主数据,均需要做线上化管理。目前已有 100 多个主题纳入主数据管理平台,包含了 2700 多个安全属性,服务对接给下游 400 多个系统,分发服务大概 2400 多万次/天,查询服务大概 5000 多万次/天。
2. 数据质量管理平台
数据质量管理平台,主要的功能包括数据质量问题的管理、问题分析、问题处理、规则管理、规则配置、监控告警管理、质量分析报告等。
监控规则区分了强依赖和弱依赖。质量平台的监控规则和调度的作业完全绑定在一起,质量平台会监控关键作业的运行情况。平台可对关键作业产生的表的数据波动,数据置信,进行平衡性校验,唯一性校验,空值校验等。在质量管理平台上可配置监控作业,系统配置的监控作业进行监控并出具报告。如果监控作业触碰强依赖的规则,系统就会对作业进行阻断,否则只是触碰弱依赖的规则,系统不做干预,作业将继续执行。这是一个数据质量平台监控系统和调度管理以及元数据管理的血缘分析和影响分析结合的一个应用。
质量平台还提供了个人定制的数据质量专题看板。平台支持用户根据个人关心的作业进行个性化的配置,并查看实时、日、周、月等时间维度的监控结果数据。
3. 数据市场
顺丰科技的数据市场,在其他公司称为数据字典、或数据地图。这是一个数据资产线上化的工作。我们把公司所有的数据(含源系统来的 ODS 数据),指标、模型、报表,按照数据治理架构从主题域、主题、业务对象、实体、属性,进行划分并展示,即对技术元数据和业务元数据进行整合展示。该系统在顺丰的应用情况很好,科技侧的同事用该系统来查看模型数据、表数据,业务方的同事可用来查询指标数据,指标的业务分类、规范命名、数据口径、数据源表,结果呈现的报表,用途等。
可以参考示例。指标板块可以看到指标分类、技术负责人、业务负责人、指标口径、分析维度等。点开详情,可以看到指标的业务属性、技术属性,管理属性三部分。报表板块可以看到其归属组织、技术负责人、业务负责人、使用情况等。模型表板块偏科技侧,可以看表的创建人,使用情况,包含字段,可以进行详情查询。系统将模型表上下游的血缘分析,即关联的表都显示出来。报表和模型表板块,支持用户申请权限。数据市场涉及的用户非常的广,科技侧的用户和业务用户,他们正需要一些跨业务领域的数据共享,数据市场提供了数据共享和权限申请的功能。
4. 数据安全—数据分类分级管理规范制定与落地
在数据安全视角,把数据分为两类,个人数据和业务数据。
个人数据完全遵循个人隐私保护条例和个人数据安全保护法的规定。个人数据安全级别分为 C1、C2、C3、C4。敏感个人数据对应 C4 级别、商业联系个人数据、一般个人数据对应 C3 级别。其中个人身份信息、个人政治面貌,政治倾向、个人生理上的一些信息,个人联系信息、个人位置信息均属于敏感个人信息对应 C4 级别,会得到严格的管控。
业务数据从财务影响、营运影响、声誉影响 3 个方面进行划分,同样分为 C1、C2、C3、C4 级别。业务数据的安全级可以升降调整。业务数据 Owner 负责以数据的安全为目的根据数据的标准制定相应的级别以及安全的管控策略,对数据进行有效的安全管理。
以上是对顺丰科技数据治理体系框架的介绍,以及数据治理各领域能力的介绍,以下是数据治理实践分享。
04
数据治理工作的关键要素
1. 数据治理工作的关键要素
以下介绍顺丰数据治理的实践。顺丰科技数据治理工作进行多年,我们踩过坑,走过弯路,有了些心得和总结,跟大家做一下分享。首先介绍数据治理工作进行的关键要素。
基于我们的经验,结合了美的、华为、阿里和腾讯的一些数据治理专家的访谈资料,参考《华为数据治理之道》《DAMA 数据管理知识体系指南》等一些文献,结合了顺丰科技多年的数据治理工作实践,我们将数据治理工作开展和推进的关键要素,总结为 4 点:
第一,高层领导的支持特别关键。整个数据治理体系的建设,要想有效的落地,得到很好的推进,必须有公司高层领导的持续关注和支持。在顺丰,数据治理委员会的主任由顺丰集团的 CIO 担任。
第二,比较关键的是运营组织保障常态化治理,包含业务和技术。虽然数据治理的一些产品, 数据质量、元数据、数据安全等是偏科技的,但是实际上要想数据治理工作有效推进,就要有业务的参与。
第三,要考核与激励双结合。针对数据质量,顺丰有数据质量健康度的考核。针对各个主题域的数据质量,顺丰都进行了健康度的评价打分,并对结果进行晾晒。
第四,长短结合,综合推进,分阶段实施。
以上是我们认为的四大关键要素,接下来分享顺丰数据治理工作的组织领导机制。
2. 数据治理工作的关键要素:组织领导机制
第一,一把手工程,需要得到高层领导的参与。
第二,数据确权,意思是要明确数据的责任主体。在顺丰,数据的 Owner最开始是科技侧,现在是业务方。接下来要明确“谁产生数据,谁为质量负责”。这句话喊了多年,直到最近才逐步落地和得到尊崇。产生数据的业务部门并不使用数据,而是下游在使用数据。下游使用数据的时候,会真正的关心数据的质量,会发现数据质量没办法闭环的情况。因此,就产生了“谁产生数据,谁为质量负责”的口号。
第三,业务侧与科技侧协同。以上提到了“长短结合,综合推进”。顺丰也是这样做的。
3. 数据治理工作的关键要素:治理的方式和切入点
第一,自下而上,解决数据领域的问题。首先从实际的解决数据应用过程中的数据质量问题入手,然后去看它具体属于数据治理领域当中的哪些问题,识别其属于数据标准的问题、或者是元数据、数据服务,亦或主数据管理的问题。这样自下而上解决实际的数据问题,来推进顺丰数据治理各个领域能力的建设。
第二,自上而下,统筹规划数据治理体系建设。单纯的自下而上,数据治理工作便成了构建解决数据问题的产品,各个产品间应用的关联度不高。因此,需要自上而下的统筹规划的工作模式。
05
顺丰主数据治理分享
顺丰在主数据管理方面做的工作,主要做了 4 步:
第一,识别主数据,明确主数据的业务数据 Owner, 业务科技 Owner, 确定权责。
第二,梳理主数据的属性,制定主数据的属性标准。
第三,确定可信的业务源系统,客户主数据在顺丰叫 CDM,合同主数据在顺丰叫 CMDM,供应商主数据在顺丰叫 SRM。
第四,我们对业务源系统中标准的落地、信息录入的管控、数据服务的提供,进行质量监控。同时,质量平台针对相应的数据做系统级的质量监控。
基本上做完这 4 步之后,主数据的质量就能得到显著的提升。
顺丰的主数据治理:
1. 主数据的识别视角和管理范围
要确定主数据的 Owner,首先要识别主数据的范围。顺丰从业务视角、管控视角、技术视角,三个视角来识别顺丰集团的主数据。
从技术视角,参考 IBM 提出的企业数据管理模型,即从参与方、协议、条件、位置、分类、产品等方面确定企业数据划分的主题域。
从管控视角,指从人、财、物的管控三个方面来确定企业数据划分的主题域。人的管控如有哪些人员哪些组织,财的管控如成本中心会计科目等,物的管控指提供哪些产品、有哪些物料、提供了哪些服务。
从业务视角看,指从公司的多个业务领域的价值链来确定主题域。顺丰有多个 BU,如物流领域业务价值链,基于其基本活动收件、分拣、运输、派件和售后等,以及相应的辅助活动人资、IT、采购、法务等确定主数据。另一个价值链,如商业服务价值链,基于商业活动的开发、采购、仓储、门店、配送、营销等来确定主数据及主题域。
用以上 3 个视角穷举公司的主数据,识别出顺丰的主数据。伙伴类的主数据:客户、供应商等;管理类的主数据:员工、利润中心、成本中心、会计科目等;业务类的主数据:包装材料、BOM、辅料、商品、产品服务等,以及其他类的主数据,用户、资产、项目系统等。
2. 主数据 Owner 及职责分工
我们针对这些主数据来进行业务 Owner 的确定,如图中基于主数据分类,确定其业务数据 Owner 和业务科技 Owner,明确工作的标准和职责。
3. 主数据的管控模式设计
在主数据管理划分职责之后,对主数据的管控模式进行设计。在顺丰,主数据的管控模式,主要是注册发布式,和共同控制式两种。注册发布式,用于有唯一的业务源系统的主数据的管理。像客户、员工数据,有唯一的业务源系统。客户主数据有 CDM 系统、员工主数据有HR系统,在业务源系统把数据的标准定好落地,数据先提供给 MDM,再给到主数据管理平台,之后给到下游 400 多家的系统使用。共同控制式,用于有多个业务源系统的主数据的管理。像合同数据,我们有销售类合同、非销售类合同、成本类的合同、销售类的合同等,合同分散在不同的系统中,它在主数据管理平台上,首先进行统一标准的整合和标准的 Mapping,然后再提供给下游的系统使用。顺丰目前主要使用以上两种模式。除了这两种模式外,常用的还有集中管理式、数据合并式。如华润万家的门店主数据管理使用了集中管理式。
4. 主数据的管理成熟度评估
针对主数据的管理成熟度评估,从数据标准管理、质量管理、数据安全、数据流量、数据确权 5 个方面进行。如标准管理包含标准制定、标准管理、标准查询、标准引用,质量管理包含质量评估、影响分析等。评估即基于评价体系,对某个主数据在这 5 个方面各部分的完成情况打分。比如客户主数据,有明确的业务数据 Owner,有业务科技 Owner,有平台方,做了主数据属性的安全分级和隐私保护,也做了数据质量评估。主数据成熟度评估之后, 公司会做一个整体的晾晒排名。
相关文章:

顺丰科技数据治理实践
01 顺丰数据治理体系演进路线 顺丰做数据治理十多年,数据治理体系的模块是逐步来建设的。十年前,我们就已经建了数仓,同步做了元数据管理,数据质量管理,以及数据安全的管理。顺丰数据治理的演进路线分 3 个阶段。 第…...
Nginx+Tomcat负载均衡、动静分离实例详细部署
一、反向代理两种模式 四层反向代理 基于四层的iptcp/upd端口的代理 他是http块同一级,一般配置在http块上面。 他是需要用到stream模块的,一般四层里面没有自带,需要编译安装一下。并在stream模块里面添加upstream 服务器名称,…...

Java多线程(3)---锁策略、CAS和JUC
目录 前言 一.锁策略 1.1乐观锁和悲观锁 ⭐ 两者的概念 ⭐实现方法 1.2读写锁 ⭐概念 ⭐实现方法 1.3重量级锁和轻量级锁 1.4自旋锁和挂起等待锁 ⭐概念 ⭐代码实现 1.5公平锁和非公平锁 1.6可重入锁和不可重入锁 二.CAS 2.1为什么需要CAS 2.2CAS是什么 ⭐CAS…...

Linux:Shell编辑之文本处理器(awk)
目录 绪论 1、用法 1.1 格式选项 1.2 awk 常用内置变量 1.3 awk的打印功能 1.4 奇偶打印 1.5 awk运算 1.6 awk的内置函数:getline 1.7 文本过滤打印 1.8 awk条件判断打印 1.9 三元表达式,类似于java 1.10 awk的精确筛选 1.11 awk和tr比较改变…...
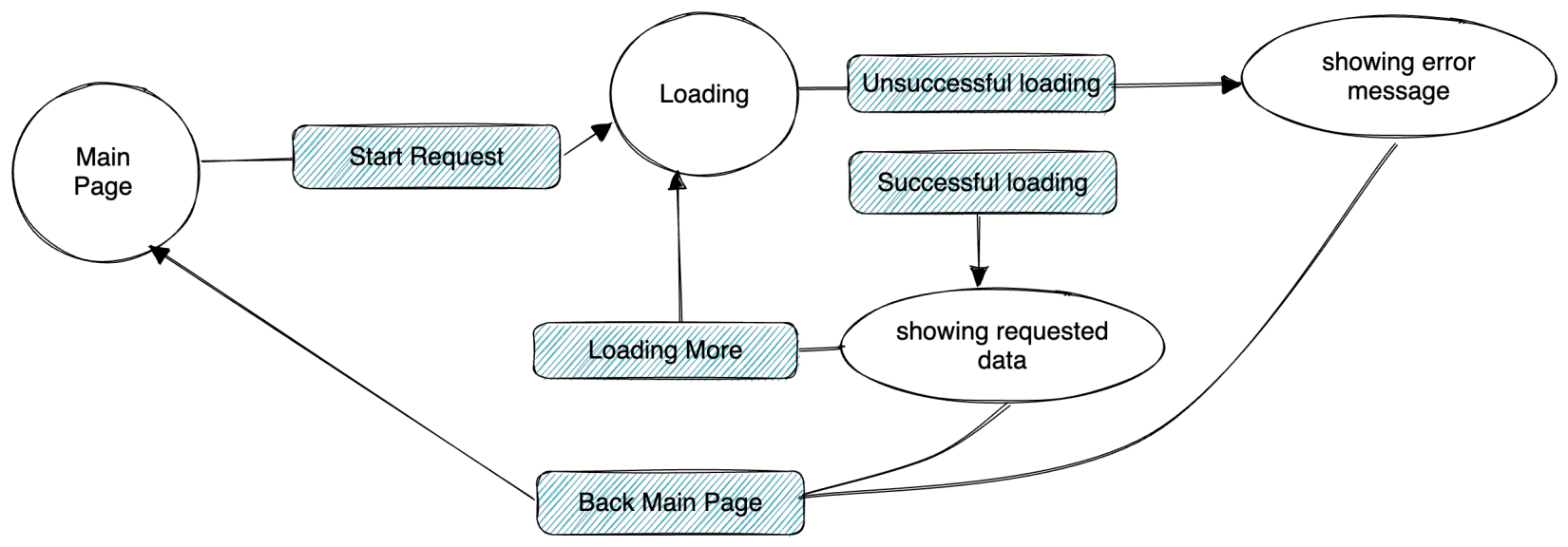
探索FSM (有限状态机)应用
有限状态机(FSM) 是计算机科学中的一种数学模型,可用于表示和控制系统的行为。它由一组状态以及定义在这些状态上的转换函数组成。FSM 被广泛用于计算机程序中的状态机制。 有限状态机(FSM)应用场景 在各种自动化系统…...

6.continue break
6.1continue 关键字 continue 关键字用于立即跳出本次循环,继续下一次循环(本次循环体continue之后的代码会少执行一次)。 例如:吃5个包子,第3个有虫子,就扔掉第3个包子,继续吃第4个第5个包子…...

如何在Linux中强制关闭卡住的PyCharm
在使用PyCharm进行Python开发时,有时可能会遇到卡顿或无响应的情况。当PyCharm卡住时,我们需要强制关闭它以恢复正常操作。今天,我们将介绍在Linux系统中如何强制关闭PyCharm的几种方法。 1. 使用键盘快捷键 在PyCharm所在的窗口中…...

c# Excel数据的导出与导入
搬运:Datagrideview 数据导出Excel , Exel数据导入 //------------------------------------------------------------------------------------- // All Rights Reserved , Copyright (C) 2013 , DZD , Ltd . //----------------------------------------------------------…...

Kotlin~Mediator中介者模式
概念 创建一个中介来降低对象之间的耦合度,关系”多对多“变为“一对多”。 角色介绍 Mediator:抽象中介者,接口或者抽象类。ConcreteMediator:中介者具体实现,实现中介者接口,定义一个List管理Colleagu…...

石子合并问题
一.试题 在一个园形操场的四周摆放N堆石子(N≤100),现要将石子有次序地合并成一堆。规定 每次只能选相邻的两堆合并成新的一堆,并将新的一堆的石子数,记为该次合并的得分。 编一程序,由文件读入…...

剑指Offer-搜索与回溯算法
文章目录 剑指 Offer 32 - I. 从上到下打印二叉树题意:解:代码: 剑指 Offer 32 - II. 从上到下打印二叉树 II题意:解:代码: 剑指 Offer 32 - III. 从上到下打印二叉树 III题意:解:代…...

【云原生】Docker 详解(三):Docker 镜像管理基础
Docker 详解(三):Docker 镜像管理基础 1.镜像的概念 镜像可以理解为应用程序的集装箱,而 Docker 用来装卸集装箱。 Docker 镜像含有启动容器所需要的文件系统及其内容,因此,其用于创建并启动容器。 Dock…...
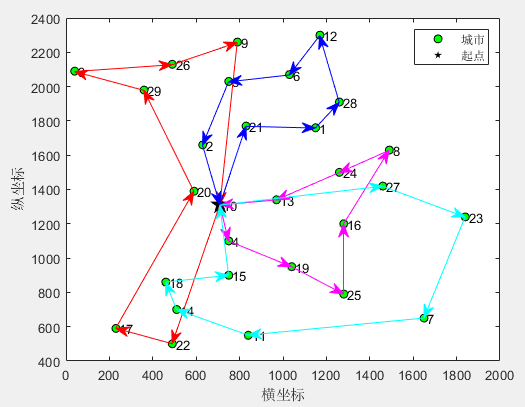
SD-MTSP:蜘蛛蜂优化算法SWO求解单仓库多旅行商问题MATLAB(可更改数据集,旅行商的数量和起点)
一、蜘蛛蜂优化算法SWO 蜘蛛蜂优化算法(Spider wasp optimizer,SWO)由Mohamed Abdel-Basset等人于2023年提出,该算法模型雌性蜘蛛蜂的狩猎、筑巢和交配行为,具有搜索速度快,求解精度高的优势。蜘蛛蜂优化算…...
) 使用】)
【ARM 嵌入式 编译系列 3.1 -- GCC __attribute__((used)) 使用】
文章目录 __attribute__((used)) 属性介绍代码演示编译与输出GCC 编译选项 上篇文章:ARM 嵌入式 编译系列 3 – GCC attribute((weak)) 弱符号使用 下篇文章:ARM 嵌入式 编译系列 3.2 – glibc 学习 __attribute__((used)) 属性介绍 在普通的 C/C 程序中…...
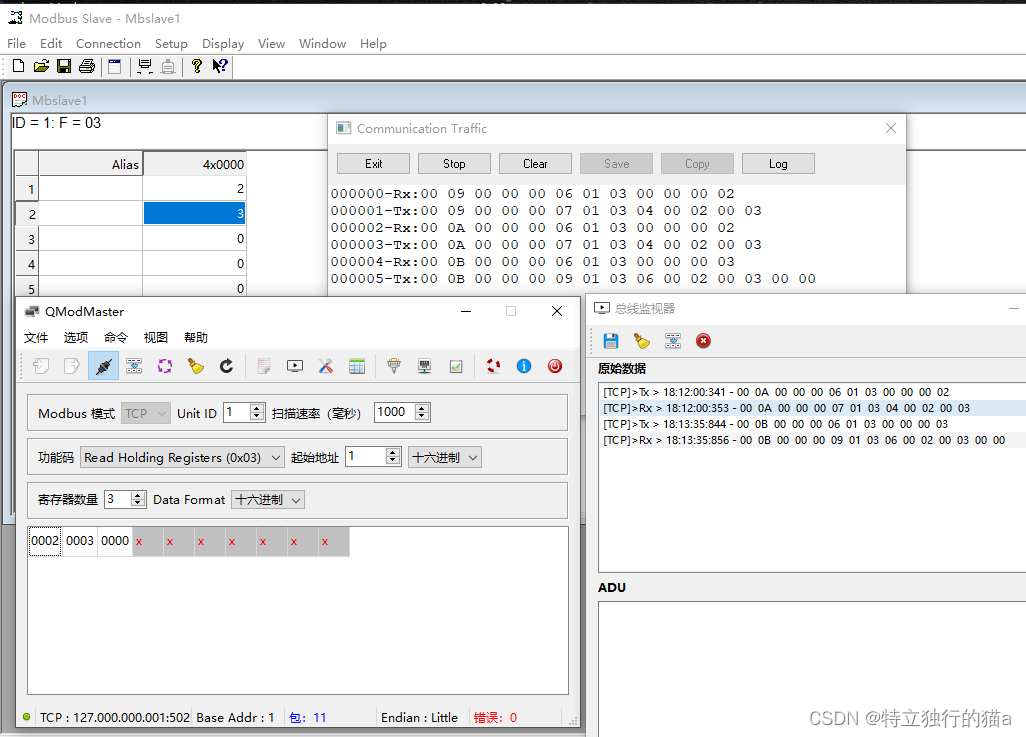
C++ ModBUS TCP客户端工具 qModMaster 介绍及使用
qModMaster工具介绍 QModMaster是一个基于Qt的Modbus主站(Master)模拟器,用于模拟和测试Modbus TCP和RTU通信。它提供了一个直观的图形界面,使用户能够轻松设置和发送Modbus请求,并查看和分析响应数据。 以下是QModM…...
笔记本电脑如何把sd卡数据恢复
在使用笔记本电脑过程中,如果不小心将SD卡里面的重要数据弄丢怎么办呢?别着急,本文将向您介绍SD卡数据丢失常见原因和恢复方法。 ▌一、SD卡数据丢失常见原因 - 意外删除:误操作或不小心将文件或文件夹删除。 - 误格式化&#…...

【2023 华数杯全国大学生数学建模竞赛】 B题 不透明制品最优配色方案设计 39页论文及python代码
【2023 华数杯全国大学生数学建模竞赛】 B题 不透明制品最优配色方案设计 39页论文及python代码 1 题目 B 题 不透明制品最优配色方案设计 日常生活中五彩缤纷的不透明有色制品是由着色剂染色而成。因此,不透明制品的配色对其外观美观度和市场竞争力起着重要作用。…...
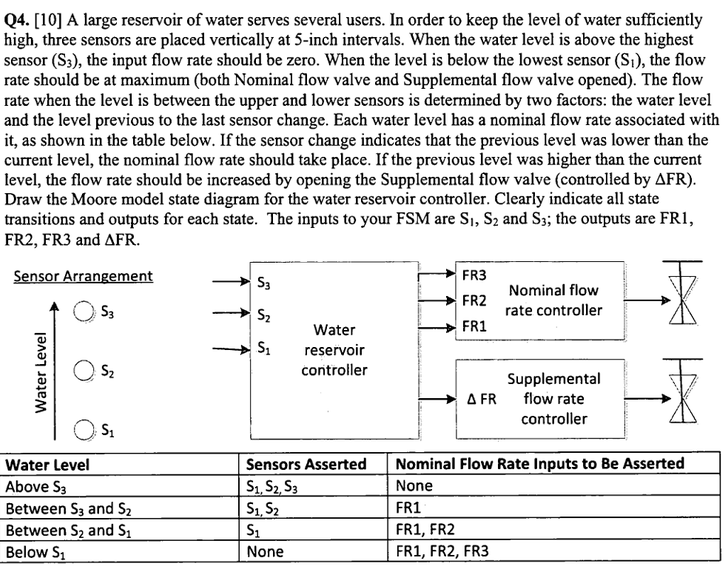
Exams/ece241 2013 q4
蓄水池问题 S3 S2 S1 例如:000 代表 无水 ,需要使FR3, FR2, FR1 都打开(111) S3 S2 S1 FR3 FR2 FR1 000 111 001 011 011 001 111 000 fr代表水变深为…...
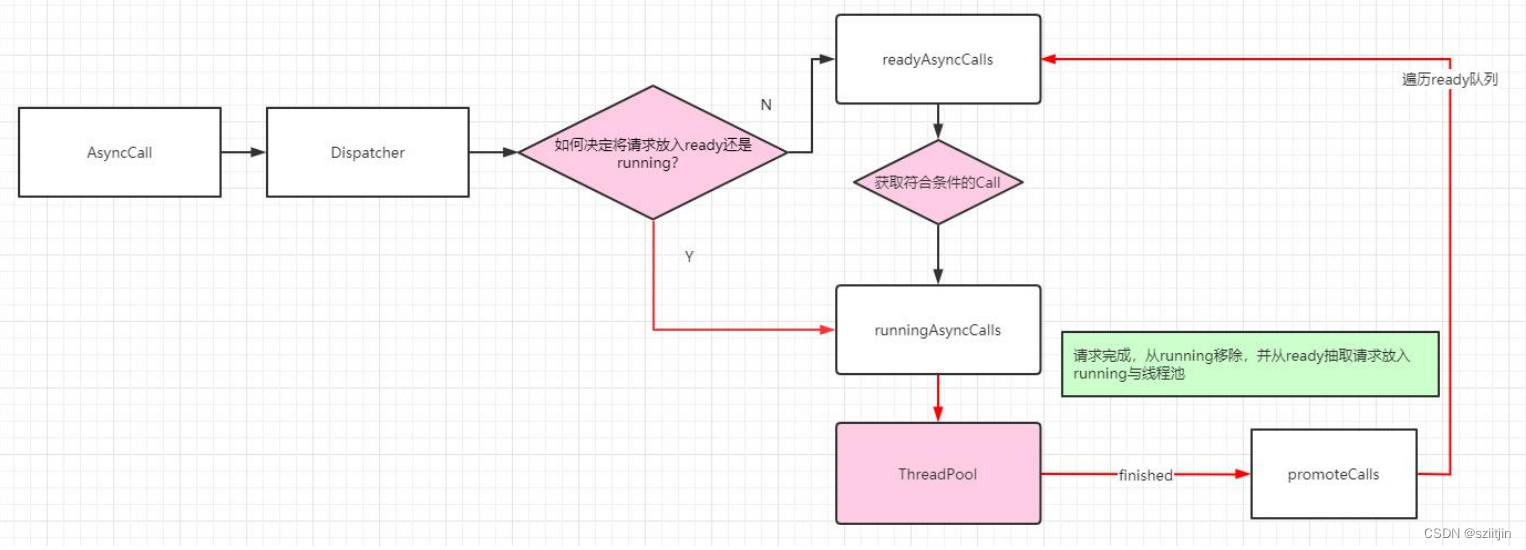
Android OkHttp源码分析--分发器
OkHttp是当下Android使用最频繁的网络请求框架,由Square公司开源。Google在Android4.4以后开始将源码中 的HttpURLConnection底层实现替换为OKHttp,同时现在流行的Retrofit框架底层同样是使用OKHttp的。 OKHttp优点: 1、支持Http1、Http2、Quic以及Web…...
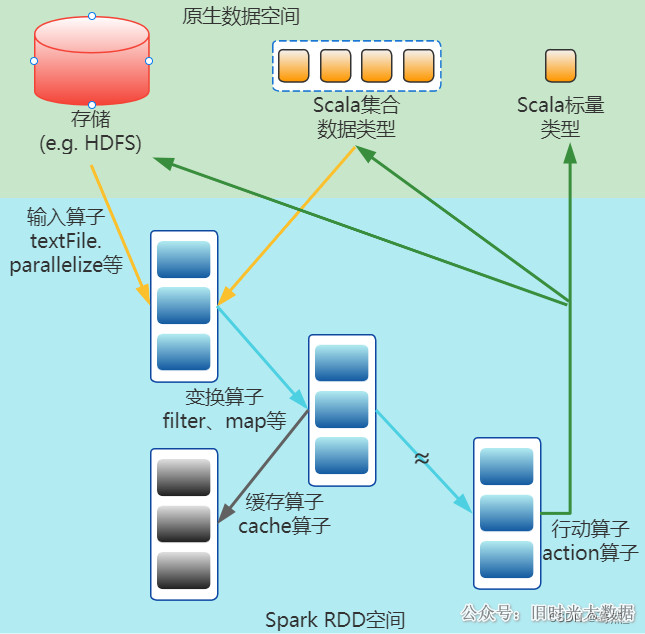
大数据面试题:说下Spark中的Transform和Action,为什么Spark要把操作分为Transform和Action?
面试题来源: 《大数据面试题 V4.0》 大数据面试题V3.0,523道题,679页,46w字 可回答:Spark常见的算子介绍一下 参考答案: 我们先来看下Spark算子的作用: 下图描述了Spark在运行转换中通过算…...

AndroidControl应用场景扩展:从手机控制到平板、手表等设备
AndroidControl应用场景扩展:从手机控制到平板、手表等设备 【免费下载链接】AndroidControl 超强群控,可以实时查看和控制安卓手机的安卓远程控制软件,致力于完成一个高端的安卓群控软件 可以群控,录制运行脚本等等功能...... …...

别再死记硬背Agent Types了!用LangChain 0.0.340实战,5分钟搞懂ReAct与Conversational Agent的区别
别再死记硬背Agent Types了!用LangChain 0.0.340实战,5分钟搞懂ReAct与Conversational Agent的区别 当开发者第一次接触LangChain的Agent系统时,往往会被各种Agent Types搞得晕头转向。官方文档列出了近十种不同类型的Agent,从Zer…...

从Nessus到OpenVAS:一个开源漏洞扫描器的‘前世今生’与实战入门指南
从Nessus到OpenVAS:开源漏洞扫描器的技术演进与实战解析 在网络安全领域,漏洞扫描工具如同数字世界的"体检仪器",而OpenVAS作为当前最活跃的开源漏洞评估系统,其技术基因可追溯至商业产品Nessus。这种独特的"血缘关…...

写给做审批系统的你:状态和权限一旦没分层,后面一定越来越乱
Activiti/Flowable 工作流实战:业务状态和流程状态怎么保持一致?再讲清 RBAC 数据权限 工作流项目真正难的地方,往往不是“怎么发起流程”,而是“流程跑起来之后,状态别乱、权限别乱、数据别乱”。 这个项目里我能明显…...

VSCode量子插件配置踩坑实录:92%开发者忽略的3项核心环境校验与自动修复方案
更多请点击: https://intelliparadigm.com 第一章:VSCode量子插件配置踩坑实录:92%开发者忽略的3项核心环境校验与自动修复方案 VSCode 量子开发插件(如 Q# Extension、Quantum Development Kit)在启用时频繁报错&…...
)
从实验室到论文:手把手教你用MP DSS构建小鼠肠炎模型(附详细步骤与DAI评分避坑指南)
从实验室到论文:手把手教你用MP DSS构建小鼠肠炎模型(附详细步骤与DAI评分避坑指南) 在炎症性肠病研究领域,动物模型的构建质量直接影响实验数据的可靠性。作为被8000多篇文献验证的金标准,DSS诱导的小鼠肠炎模型因其与…...

[AutoSar]BSW_Memory_Stack_007 FEE 模块核心机制:顺序写入与翻页策略详解
1. FEE模块在AutoSar架构中的核心作用 在汽车电子系统中,数据存储的可靠性直接关系到车辆功能的正常运行。FEE(Flash EEPROM Emulation)作为AutoSar BSW层的关键模块,承担着模拟EEPROM存储行为的重要职责。不同于传统EEPROM芯片&a…...

OpenHarmony 4.0系统应用调试:搞定签名后,如何用hdc一键替换SystemUI的7个HAP包?
OpenHarmony 4.0系统应用高效调试:从签名到部署的全链路实践 在OpenHarmony 4.0的开发过程中,系统应用的调试往往是最具挑战性的环节之一。特别是像SystemUI这样由多个HAP模块组成的复杂系统应用,开发者经常陷入"修改-构建-部署-测试&qu…...

基于安卓的农业气象灾害预警系统毕设
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在设计并实现一种基于安卓操作系统的农业气象灾害预警系统以提升农业生产活动中的灾害应对能力与决策效率。随着全球气候变化加剧及极端天气事件频发农业…...

还在手动逐字整理会议纪要?2026年这5款真香AI工具,3分钟搞定2小时会议录音
很多人选AI转写整理工具,上来就先比订阅价格,觉得越便宜越好,其实这完全是误区啊。我们用工具是为了省时间,要算的是「每小时录音处理成本」和「你自己的时间价值」——你自己手动整理2小时会议录音,少说要2小时&#…...