《大型网站技术架构》第二篇 架构-高可用
高可用在公司中的重要性
对公司而言,可用性关系网站的生死存亡。对个人而言,可用性关系到自己的绩效升迁。
工程师对架构做了许多优化、对代码做了很多重构,对性能、扩展性、伸缩性做了很多改善,但别人未必能直观地感受到,也许你的直接领导都不知道你做的这些意义何在。但如果你负责的产品出了重大故障,CEO 都会知道你的名字。
事物总是先求生存,然后求发展。保证网站可用,万无一失,任重而道远。
高可用的主要手段
实现上述高可用架构的主要手段是数据和服务的冗余备份及失效转移:
- 一旦某些服务器宕机,就将服务切换到其他可用的服务器上;
- 如果磁盘损坏,则从备份的 磁盘读取数据(硬件故障是常态)。
高可用的网站架构
在复杂的大型网站架构中,划分的粒度会更小、更详细,结构更加复杂,服务器规模更加庞大,但通常还是能够把这些服务器划分到这三层中。如图5.4所示:
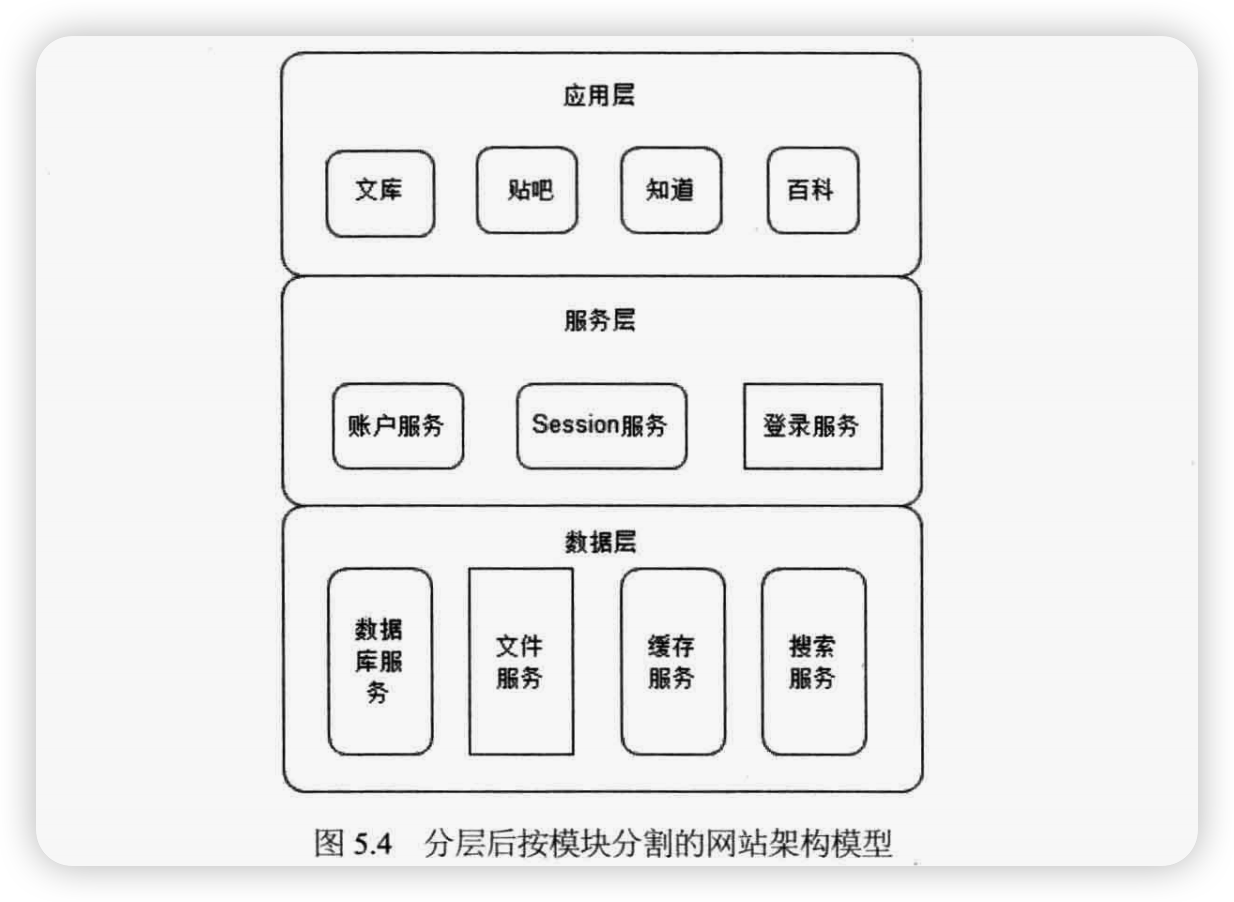
1.位于应用层的服务器通常为了应对高并发的访问请求,会通过负载均衡设备将一组服务器组成一个集群共同对外提供服务,当负载均衡设备通过心跳检测等手段监控到某台应用服务器不可用时,就将其从集群列表中剔除,并将请求分发到集群中其他可用的服务器上,使整个集群保持可用,从而实现应用高可用。
2.位于服务层的服务器情况和应用层的服务器类似,也是通过集群方式实现高可用,只是这些服务器被应用层通过分布式服务调用框架访问,分布式服务调用框架会在应用层客户端程序中实现软件负载均衡,并通过服务注册中心对提供服务的服务器进行心跳检测,发现有服务不可用,立即通知客户端程序修改服务访问列表,剔除不可用的服务器。
3.位于数据层的服务器情况比较特殊,数据服务器上存储着数据,为了保证服务器宕机时数据不丢失,数据访问服务不中断,需要在数据写入时进行数据同步复制,将数据写入多台服务器上,实现数据冗余备份。当数据服务器宕机时,应用程序将访问切换到有备份数据的服务器上。
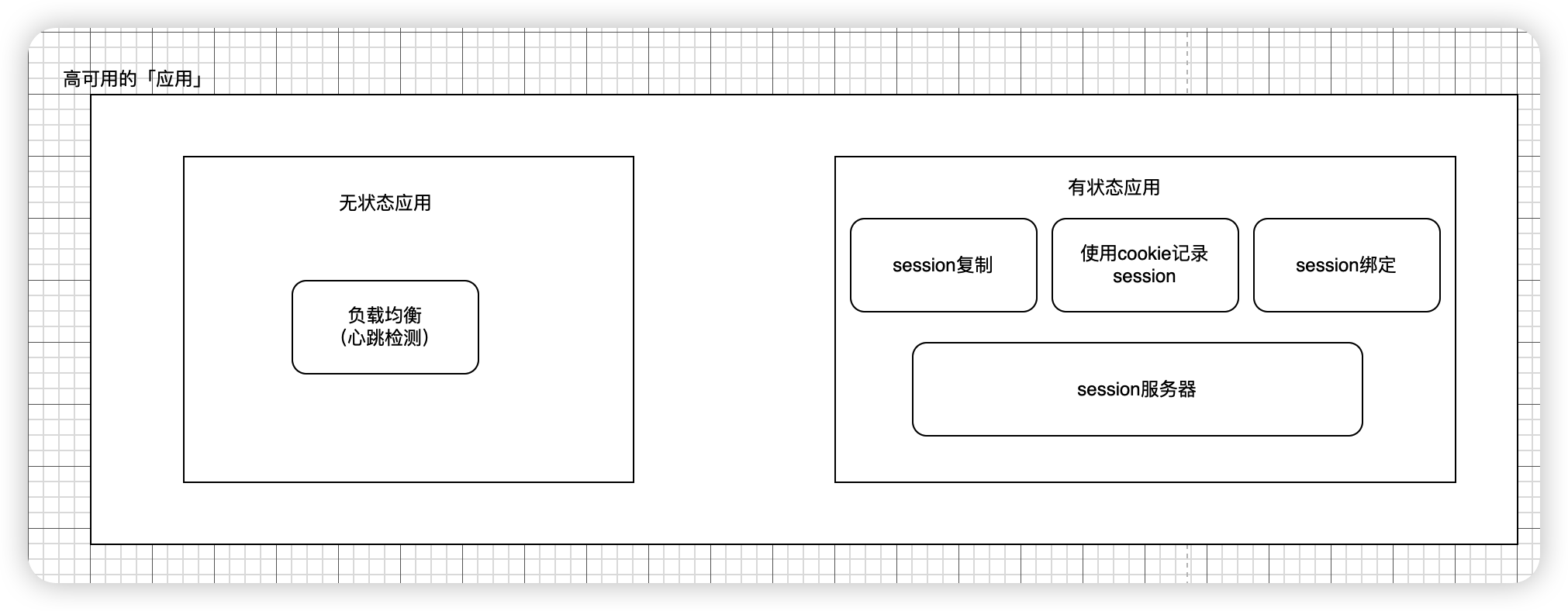
应用高可用
分为两种:
- 无状态应用(理想)
- 有状态应用(现实)
服务高可用
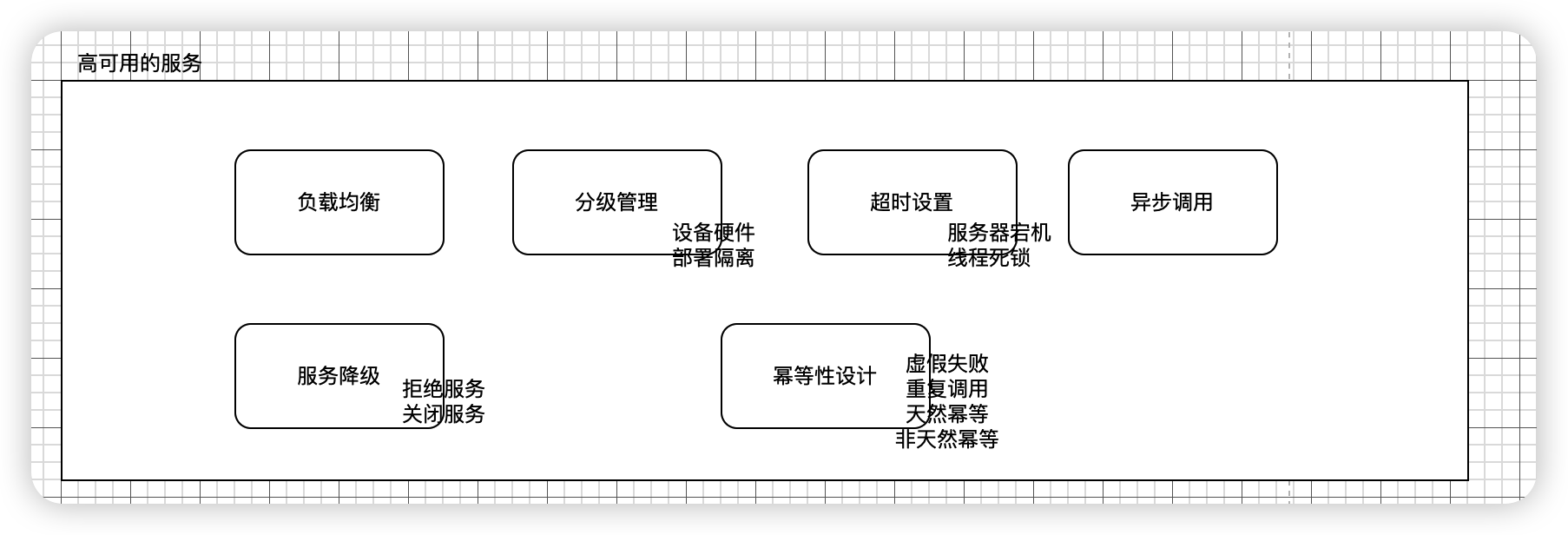
2.分级管理
- 运维上将服务器进行分级管理,核心应用和服务优先使用更好的硬件,在运维响应速度上也格外迅速。显然,用户及时付款购物比能不能评价商品更重要,所以订单、支付服务比评价服务有更高优先级。
- 同时在服务部署上也进行必要的隔离,避免故障的连锁反应。
-
- 低优先级的服务通过启动不同的线程或者部署在不同的虚拟机上进行隔离,
- 而高优先级的服务则需要部署在不同的物理机上,核心服务和数据甚至需要部署在不同地域的数据中心。
5.服务降级
在网站访问高峰期,服务可能因为大量的并发调用而性能下降,严重时可能会导致服务宕机。为了保证核心应用和功能的正常运行,需要对服务进行降级。降级有两种手段:拒绝服务及关闭服务:
- 拒绝服务:
-
- 拒绝低优先级应用的调用,减少服务调用并发数,确保核心应用正常使用;
- 或者随机拒绝部分请求调用,节约资源,让另一部分请求得以成功,避免要死大家一起死的惨剧。貌似 Twitter 比较喜欢使用随机拒绝请求的策略,经常有用户看到请求失败的故障页面,但是问下身边的人,其他人都正常使用,自己再刷新页面,也好了。
- 关闭功能:关闭部分不重要的服务,或者服务内部关闭部分不重要的功能,以节约系统开销,为重要的服务和功能让出资源。淘宝在每年的“双十一”促销中就使用这种方法,在系统最繁忙的时段关闭“评价”、“确认收货”等非核心服务,以保证核心交易服务的顺利完成。
6.幂等性设计
(1)虚假失败
比如服务已经处理成功,但因为网络故障应用没有收到响应,这时应用重新提交请求就导致服务重复调用,如果这个服务是一个转账操作,就会产生严重后果。
(2)服务重复调用
服务重复调用是无法避免的,应用层也不需要关心服务是否真的失败,只要没有收到调用成功的响应,就可以认为调用失败,并重试服务调用。因此必须在服务层保证服务重复调用和调用一次产生的结果相同,即服务具有幂等性。
(3)天然幂等性
有些服务天然具有幂等性,比如将用户性别设置为男性,不管设置多少次,结果都一样。
(4)非天然幂等性
但是对于转账交易等操作,问题就会比较复杂,需要通过交易编号等信息进行服务调用有效性校验,只有有效的操作才能继续执行。
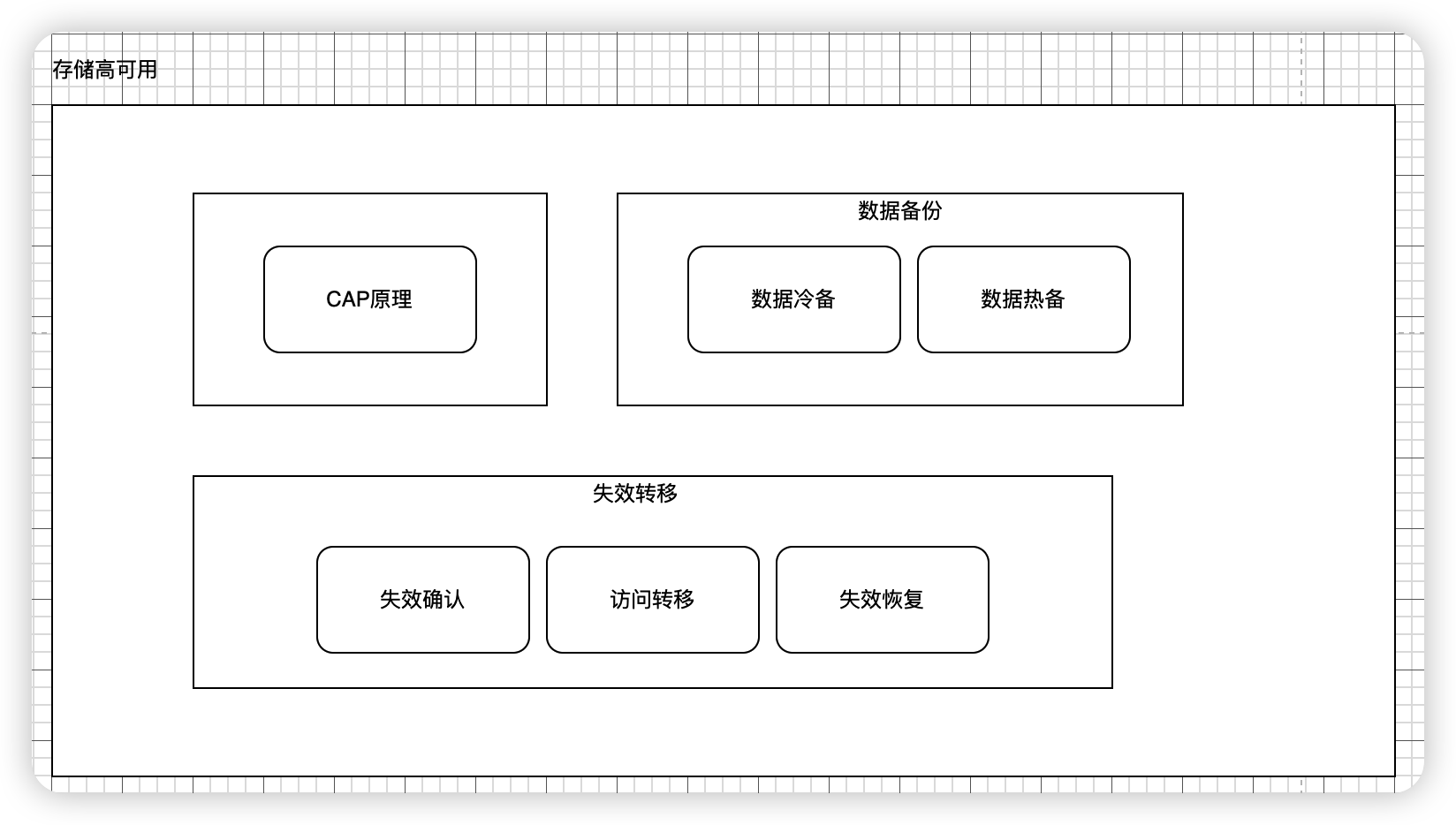
存储高可用
缓存服务高可用
关于缓存服务的高可用,在实践中争议很大:
- 一种观点认为缓存已经成为网站数据服务的重要组成部分,事实上承担了业务中绝大多数的数据读取访问服务,缓存服务失效可能会导致数据库负载过高而宕机,进而影响整个网站的可用性,因此缓存服务需要实现和数据存储服务同样的高可用。
- 另一种观点认为,缓存服务不是数据存储服务,缓存服务器宕机引起缓存数据丢失导致服务器负载压力过高应该通过其他手段解决,而不是提高缓存服务本身的高可用。
笔者持后一种观点,对于缓存服务器集群中的单机宕机,如果缓存服务器集群规模较大,那么单机宕机引起的缓存数据丢失比例和数据库负载压力变化都较小,对整个系统影响也较小。扩大缓存服务器集群规模的一个简单手段就是整个网站共享同一个分布式缓存集群,单独的应用和产品不需要部署自己的缓存服务器,只需要向共享缓存集群申请缓存资源即可。并且通过逻辑或物理分区的方式将每个应用的缓存部署在多台服务器上,任何一台服务器宕机引起的缓存失效都只影响应用缓存数据的一小部分,不会对应用性能和数据库负载造成太大影响。
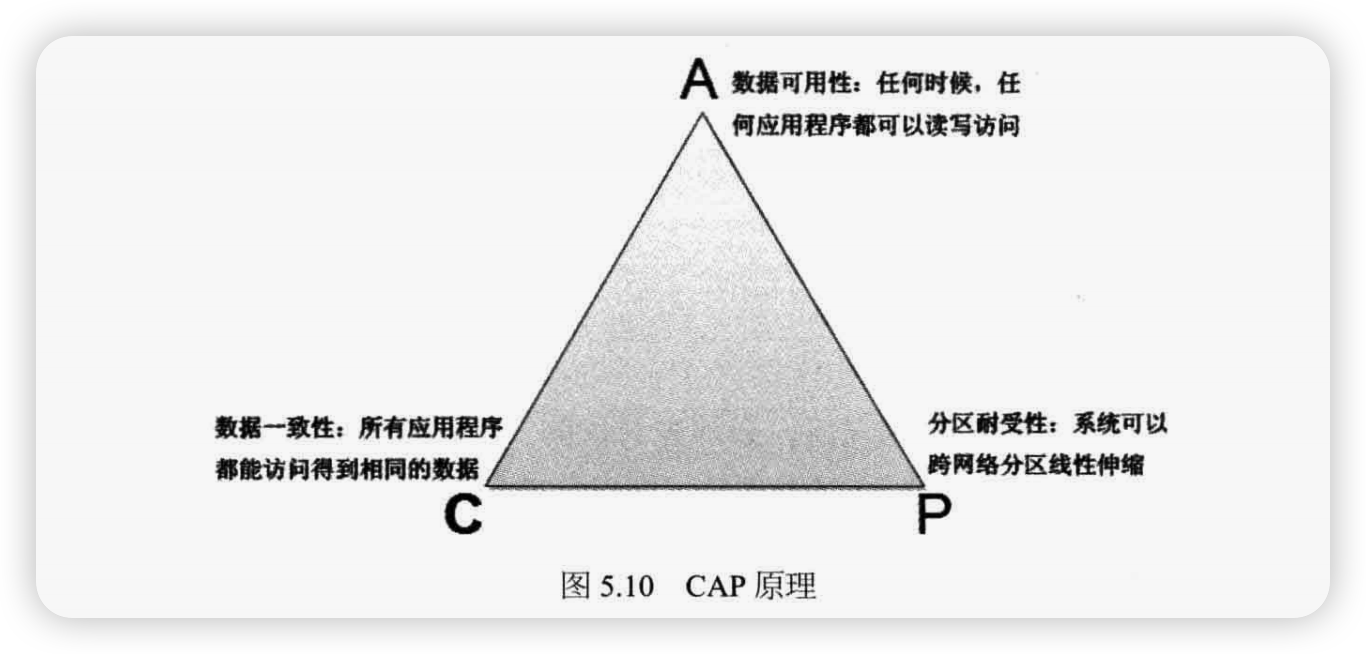
CAP原理
在讨论高可用数据服务架构之前,必须先讨论的一个话题是,为了保证数据的高可用,网站通常会牺牲另一个也很重要的指标:数据一致性。
CAP 原理认为,一个提供数据服务的存储系统无法同时满足数据一致性(Consistency )、数据可用性(Availibility )、分区耐受性(Patition Tolerance,系统具有跨网络分区的伸缩性)这三个条件,如图5.10 所示。
存储服务高可用
若数据服务器集群中任何一台服务器宕机,那么应用程序针对这台服务器的所有读写操作都需要重新路由到其他服务器,保证数据访问不会失败,这个过程叫作失效转移。
失效转移操作由三部分组成:失效确认、访问转移、数据恢复。
1. 失效确认
判断服务器宕机是系统进行失效转移的第一步,系统确认一台服务器是否宕机的手段有两种:心跳检测和应用程序访问失败报告,如图 5.13所示。

对于应用程序的访问失败报告,控制中心还需要再一次发送心跳检测进行确认,以免错误判断服务器宕机,因为一旦进行数据访问的失效转移,就意味着数据存储多份副本不一致,需要进行后续一系列复杂的操作。
2. 访问转移
确认某台数据存储服务器宕机后,就需要将数据读写访问重新路由到其他服务器上。对于完全对等存储的服务器(几台存储服务器存储的数据完全一样,我们称几台服务器为对等服务器,比如主从结构的存储服务器,其存储的数据完全一样),当其中一台宕机后,应用程序根据配置直接切换到对等服务器上。如果存储是不对等的,那么就需要重新计算路由,选择存储服务器。
3.数据恢复
因为某台服务器宕机,所以数据存储的副本数目会减少,必须将副本的数目恢复到系统设定的值,否则,再有服务器宕机时,就可能出现无法访问转移(所有副本的服务器都宕机了),数据永久丢失的情况。因此系统需要从健康的服务器复制数据,将数据副本数目恢复到设定值。具体设计可参考本书第11章。
高可用网站的软件质量保证
网站发布
不管发布的新功能是修改了一个按钮的布局还是增加了一个核心业务,都需要在服务器上关闭原有的应用,然后重新部署启动新的应用,整个过程还要求不影响用户的使用。这相当于要求给飞行中的飞机换个引擎,既不能让飞机有剧烈晃动(影响用户体验),也不能让飞机降落(系统停机维护),更不能让飞机坠段(系统故障网站完全不可用)。
但是网站发布毕竟是一次提前预知的服务器宕机,所以过程可以更柔和,对用户影响更小。通常使用发布脚本来完成发布,其流程如图 5.14所示。
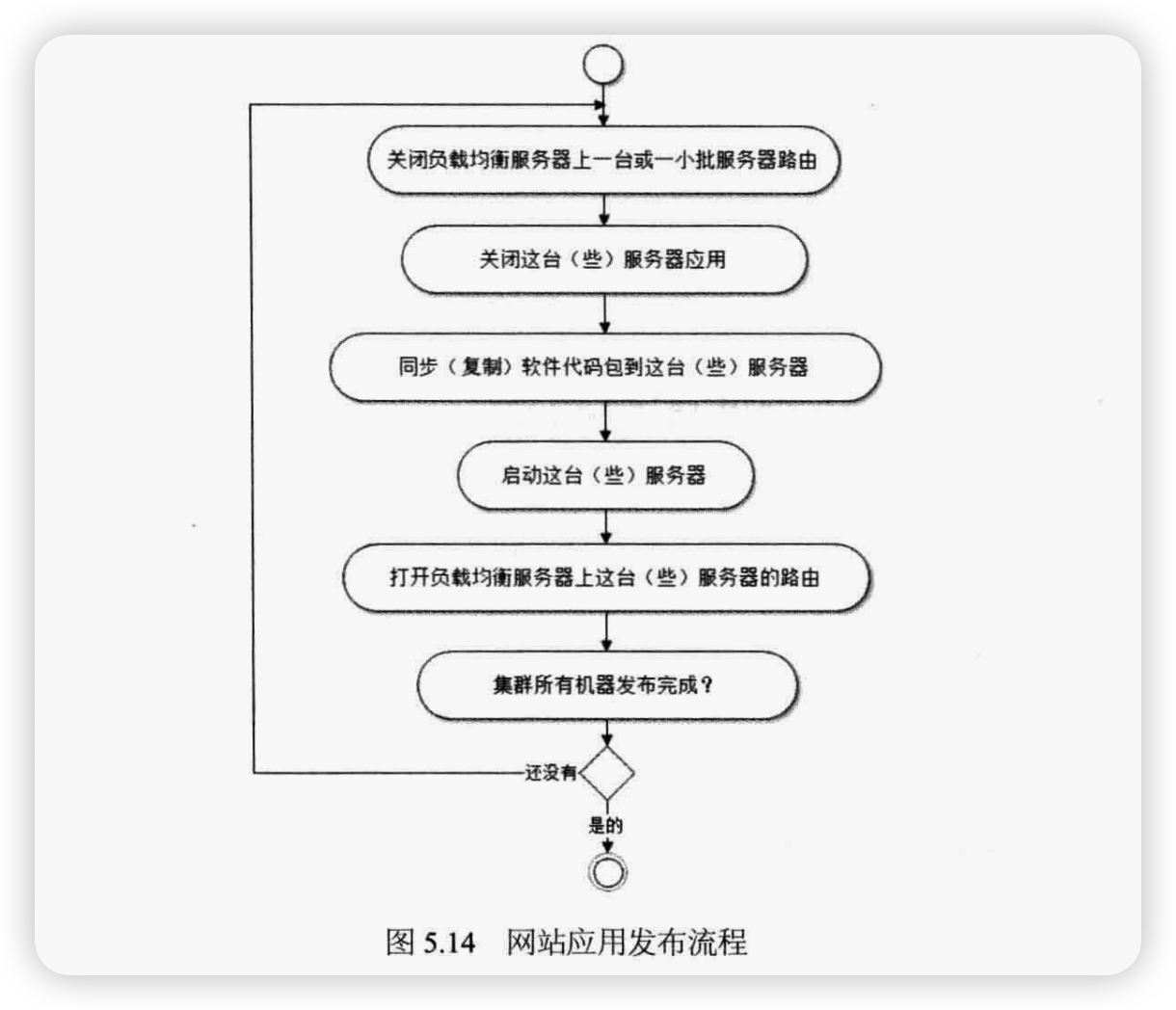
发布过程中,每次关闭的服务器都是集群中的一小部分,并在发布完成后立即可以访问,因此整个发布过程不影响用户使用。
自动化测试
代码在发布到线上服务器之前需要进行严格的测试。即使每次发布的新功能都是在原有系统功能上的小幅增加,但为了保证系统没有引入未预料的 Bug,网站测试还是需要对整个网站功能进行全面的回归测试。此外还需要测试各种浏览器的兼容性。在发布频繁的网站应用中,如果使用人工测试,成本、时间及测试覆盖率都难以接受。
- 目前大部分网站都采用 Web 自动化测试技术,使用自动测试工具或脚本完成测试。比较流行的 Web 自动化测试工具是 Thought Works 开发的 Selenium。 Selenium 运行在浏览器中,模拟用户操作进行测试,因此 Selenium 可以同时完成 web 功能测试和浏览器兼容测试。
- 大型网站通常也会开发自己的自动化测试工具,可以一键完成系统部署,测试数据生成、测试执行、测试报告生成等全部测试过程。许多网站测试工程师的编码能 力毫不逊于软件工程师。
预发布验证
为什么需要预发布验证
即使是经过严格的测试,软件部署到线上服务器之后还是经常会出现各种问题,甚至根本无法启动服务器。主要原因是测试环境和线上环境并不相同,特别是应用需要依赖的其他服务,如数据库,缓存、公用业务服务等,以及一些第三方服务,如电信短信网关、银行网银接口等。
- 也许是数据库表结构不一致;
- 也许是接口变化导致的通信失败;
- 也许是配置错误导致连接失败;
- 也许是依赖的服务线上环境还没有准备好,这些问题都有可能导致应用故障
因此在网站发布时,而是先发布到预发布机器上,开发工程师和测试工程师在预发布服务器上进行预发布验证,执行一些典型的业务流程,确认系统没有问题后才正式发布。
预发布机器的特征
预发布服务器是一种特殊用途的服务器,它和线上的正式服务器唯一的不同就是没有配置在负载均衡服务器上,外部用户无法访问,如图5.15 所示。
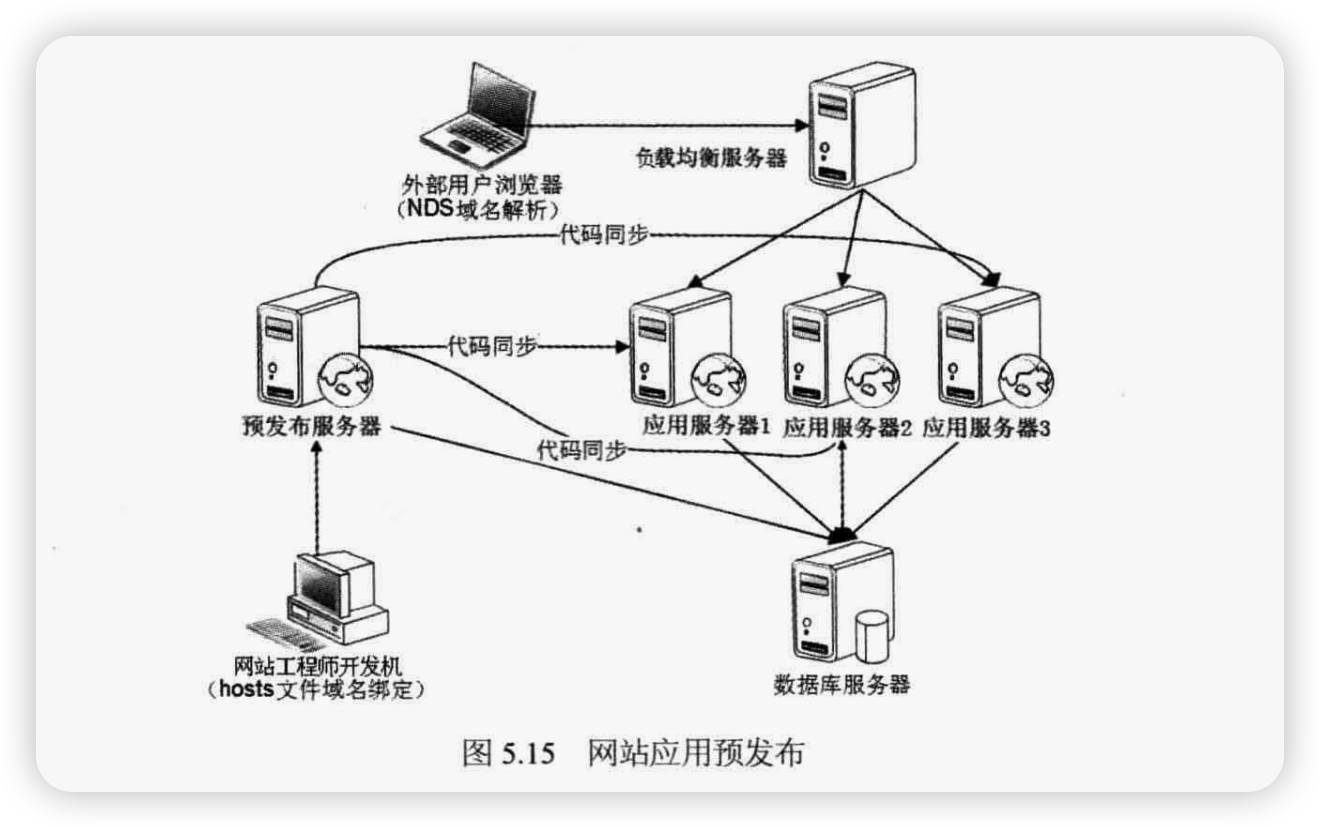
预发布服务器和线上正式服务器(应用服务器1,2,3):
- 都部署在相同的物理环境(同一个数据中心甚至同一个机架上,如果使用虚拟机,甚至可能在同一个物理服务器上)中,
- 使用相同的线上配置,
- 依赖相同的外部服务。
网站工程师通过在自己的开发用计算机上配置 hosts 文件绑定域名 IP 关系直接使用IP 地址访问预发布服务器。如果在预发布服务器上执行的测试验证是正确的,基本可以确保在线上正式服务器部署时也没有问题。
预发布环境注意问题
不过,也有可能会因为预发布验证而引入问题。因为预发布服务器连接的是真实的生产环境,所有的预发布验证操作都是真实有效的数据,这些操作也许会引起不可预期的问题。比如创建一个店铺,上架一个商品,就有可能有真的用户过来购买,如果不能发货,会导致用户投诉。
一个真实的案例是某网站需要验证海外第三方支付功能,每件商品的售价本来是数千美金,工程师不可能花数千美金去验证自己开发的功能,于是将金额改成一美元,验证成功后,幸福地发布上线了,第二天上班后,发现大量商品以一美元的价格成交。
此外,在网站应用中强调的一个处理错误的理念是快速失败(fast failed),即如果系统在启动时发现问题就立刻抛出异常,停止启动让工程师介入排查错误,而不是启动后执行错误的操作。
代码控制
git、svn。
自动化发布
网站发布风险
网站的版本发布频繁,整个发布过程需要许多团队通力合作,发布前,多个代码分支合并回主干可能会发生冲突(conflict),预发布验证也会带来风险,每次发布又相当于一次宕机事故。因此网站发布过程荆棘丛生,一不小心就会踩到雷。
发布的固定日期
对于有固定发布日期的网站(很多网站选择周四作为发布日,这样一周前面有三天时间可以准备发布,后面还有一天时间可以挽回错误。如果选择周五发布,发现问题就必须要周末加班了。),一到发布日,整个技术部门甚至运营部门就如临大敌,电话声此起彼伏,工程师步履匆匆,连空气中的温度都仿佛升高了几度。
火车发布模型
据说国外某知名互联网公司的 CTO 就因为没有有效手段控制发布故障、减少发布日的加班而引咎辞职。其继任者提出了一个火车发布模型:将每个应用的发布过程看作一次火车旅程,火车定点运行,期间有若干站点,每一站都进行例行检查,不通过的项目下车,剩下的项目继续坐着火车旅行,直到火车到达终点(应用发布成功)。
但实际中,有可能所有项目都下车了,开着空车前进是没有意义的,火车不得不回到起点,等待解决了问题再重来一次。还有可能是车上有达官贵人(重点项目,CEO 跟投资人拍胸脯的项目),他不上车,谁也别想走,他出了错,大家都跟着回去重来。简化的火车发布模型如图5.17 所示。
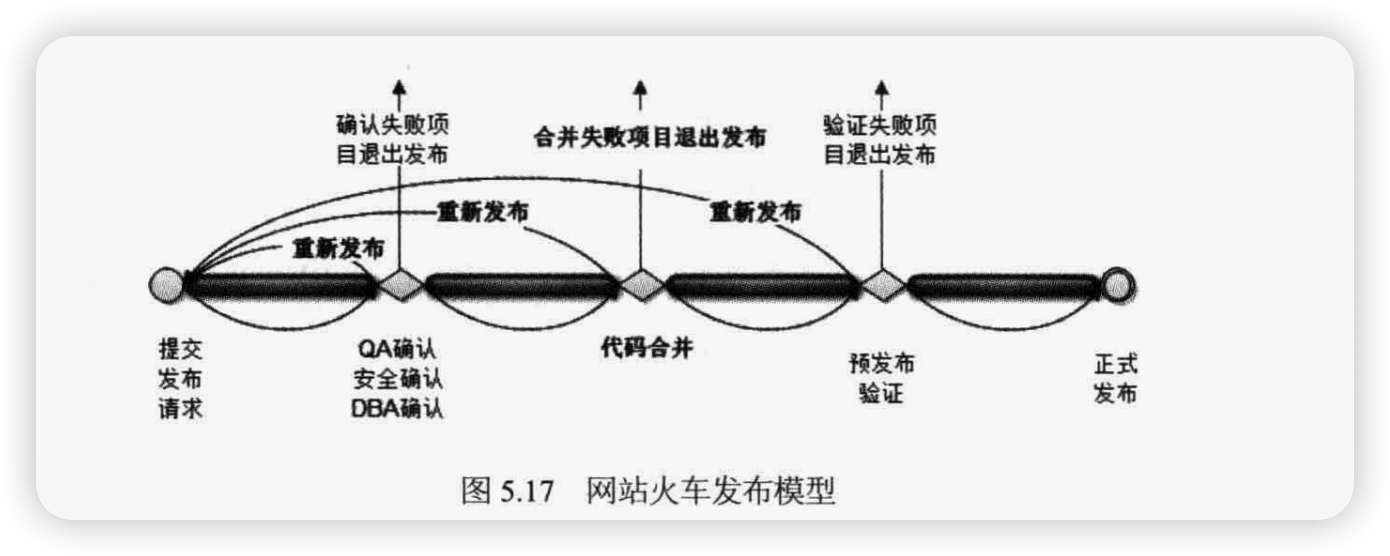
由于火车发布模型是基于规则驱动的流程,所以这个流程可以自动化。
采用火车发布模型的网站会开发一个自动化发布的工具实现发布过程的自动化。根据响应驱动流程,自动构造代码分支,进行代码合并,执行发布脚本等。正常流程下,可以做到发布过程无人值守,无需 SCM(网站配置管理员)参与,每个项目相关人员基于流程执行相应的操作,即可完成应 用自动发布。人的干预越少,自动化程度越高,引入故障的可能性就越小,火车准点到达,大家按时下班的可能性就越大。
灰度发布
为什么需要灰度发布?
大型网站的主要业务服务器集群规模非常庞大,比如某大型应用集群服务器数量超过一万台。一旦发现故障,即使想要发布回滚也需要很长时间才能完成,只能眼睁睁看着故障时间不断增加却干着急。
为了应付这种局面,大型网站会使用灰度发布模式,将集群服务器分成若干部分,每天只发布一部分服务器,观察运行稳定没有故障,第二天继续发布一部分服务器,持续几天才把整个集群全部发布完毕,期间如果发现问题,只需要回滚已发布的一部分服务器即可。如图 5.18 所示。
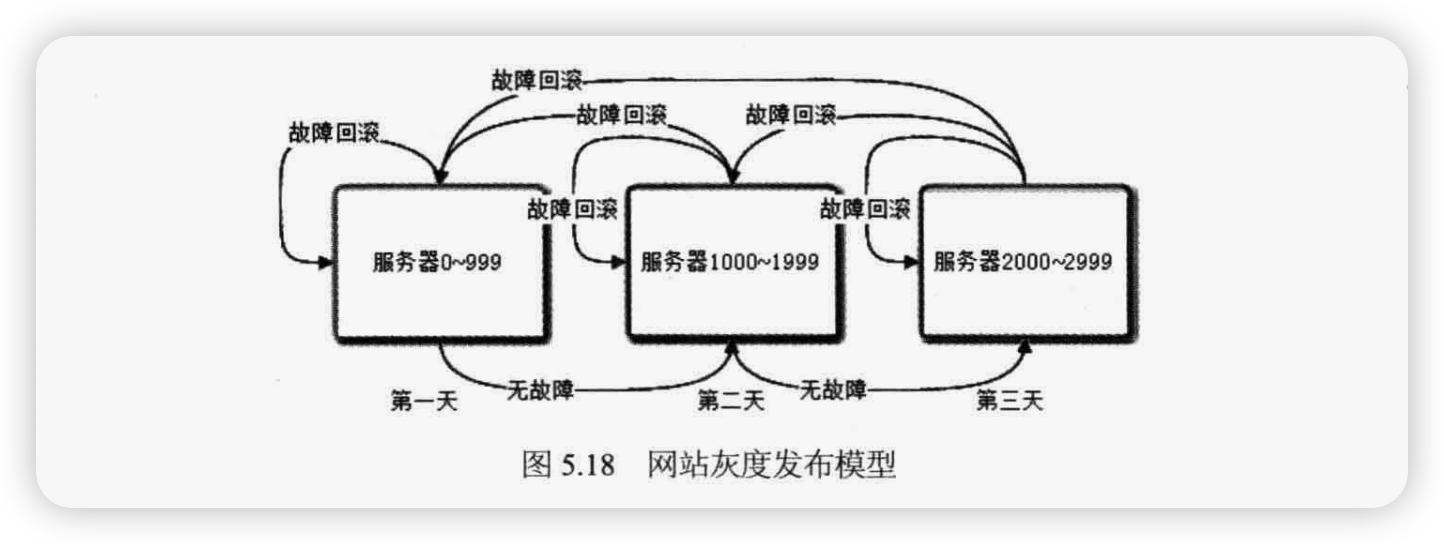
AB测试
灰度发布也常用于用户测试,即在部分服务器上发布新版本,其余服务器保持老版本(或者发布另一个版本),然后监控用户操作行为,收集用户体验报告,比较用户对两个版本的满意度,以确定最终的发布版本。这种手段也被称作 AB 测试。
小结
相关文章:
《大型网站技术架构》第二篇 架构-高可用
高可用在公司中的重要性 对公司而言,可用性关系网站的生死存亡。对个人而言,可用性关系到自己的绩效升迁。 工程师对架构做了许多优化、对代码做了很多重构,对性能、扩展性、伸缩性做了很多改善,但别人未必能直观地感受到&#…...
VS Code 使用cnpm下载包失败
一、 问题如下: 网上找到的解决方法是要在powershell中执行: Set-ExecutionPolicy RemoteSigned进行更改策略。 首先我们解释下这个Set-ExecutionPolicy RemoteSigned,Set-ExecutionPolicy 是一个 PowerShell 命令,用于控制脚本…...
【图像分类】CNN + Transformer 结合系列.4
介绍两篇利用Transformer做图像分类的论文:CoAtNet(NeurIPS2021),ConvMixer(ICLR2022)。CoAtNet结合CNN和Transformer的优点进行改进,ConvMixer则patch的角度来说明划分patch有助于分类。 CoAtN…...

分享一下利用Vue表单处理实现复杂表单布局
在开发Web应用程序中,表单是非常常见的一种元素。而在某些情况下,我们需要实现一些更为复杂的表单布局,以满足业务需求。使用Vue.js作为前端框架,我们可以很方便地处理复杂表单布局,并且实现数据的双向绑定。 下面来将…...
SAP Fiori 问题收集
事务代码篇 启动工作台:/N/UI2/FLP 错误日志: /n/IWFND/ERROR_LOG 服务清单: /n/IWFND/MAINT_SERVICE 创建语义对象:/N/UI2/SEMOBJ 创建目录:/N/UI2/FLPD_CONF(cross-client)或 /N/UI2…...

econml双机器学习实现连续干预和预测
连续干预 在这个示例中,我们使用LinearDML模型,使用随机森林回归模型来估计因果效应。我们首先模拟数据,然后模型,并使用方法来effect创建不同干预值下的效应(Conditional Average Treatment Effect,CATE&…...

《甲午》观后感——GPT-3.5所写
《甲午》是一部令人深思的纪录片,通过生动的画面和真实的故事,向观众展示了中国历史上的一段重要时期。观看这部纪录片,我深受触动,对历史的认识也得到了深化。 首先,这部纪录片通过精心搜集的历史资料和珍贵的影像资料…...
—— 微服务篇)
Java技术整理(6)—— 微服务篇
1、服务注册发现 服务注册就是维护一个服务列表,它在管理系统内所有的服务地址,当新的服务启动后,它会向服务列表提交自己的服务地址,服务的调用法可以直接向服务列表发送服务列表获取请求,就能获得所有的服务地址&am…...

途乐证券-新股行情持续火爆,哪些因素影响首日表现?
全面注册制以来,参加打新的投资者数量全体呈现下降。打新收益下降,破发频出的布景下,投资者打新策略从逢新必打逐步向优选个股改变。 经过很多历史数据,从商场定价、参加者热度以及机构重视度维度揭秘了上市后股价体现优秀的个股具…...

在生产环境中部署Elasticsearch:最佳实践和故障排除技巧——聚合与搜索(三)
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...

基于weka手工实现KNN
一、KNN模型 K最近邻(K-Nearest Neighbors,简称KNN)算法是一种常用的基于实例的监督学习算法。它可以用于分类和回归问题,并且是一种非常直观和简单的机器学习算法。 KNN算法的基本思想是:对于一个新的样本数据&…...

Lua 闭包
一、Lua 中的函数 Lua 中的函数是第一类值。意味着和其他的常见类型的值(例如数值和字符串)具有同等权限。 举个例子,函数也可以像其他类型一样存储起来,然后调用 -- 将 a.p 指向 print 函数 a { p print } -- 使用 a.p 函数…...
—— JVM篇)
Java技术整理(1)—— JVM篇
1、什么是JVM? JVM是一个可运行Java代码的虚拟计算机,包括一套字节码指令集,一组寄存器,一个栈,一个垃圾回收,堆和一个存储方式栈。JVM 是运行在操作系统之上,并不与操作系统直接交互。 2、运行…...
bug解决:AssertionError: No inf checks were recorded for this optimizer.
这真的是最恶心的一个error(比网络回传找哪层没有传播到还要恶心!),找了好久的问题所在之处,最后偶然发现了这篇文章: 解决pytorch半精度amp训练nan问题 - 知乎 然后发现自己用的混合精度训练,发…...

Django笔记之数据库查询优化汇总
1、性能方面 1. connection.queries 前面我们介绍过 connection.queries 的用法,比如我们执行了一条查询之后,可以通过下面的方式查到我们刚刚的语句和耗时 >>> from django.db import connection >>> connection.queries [{sql: S…...
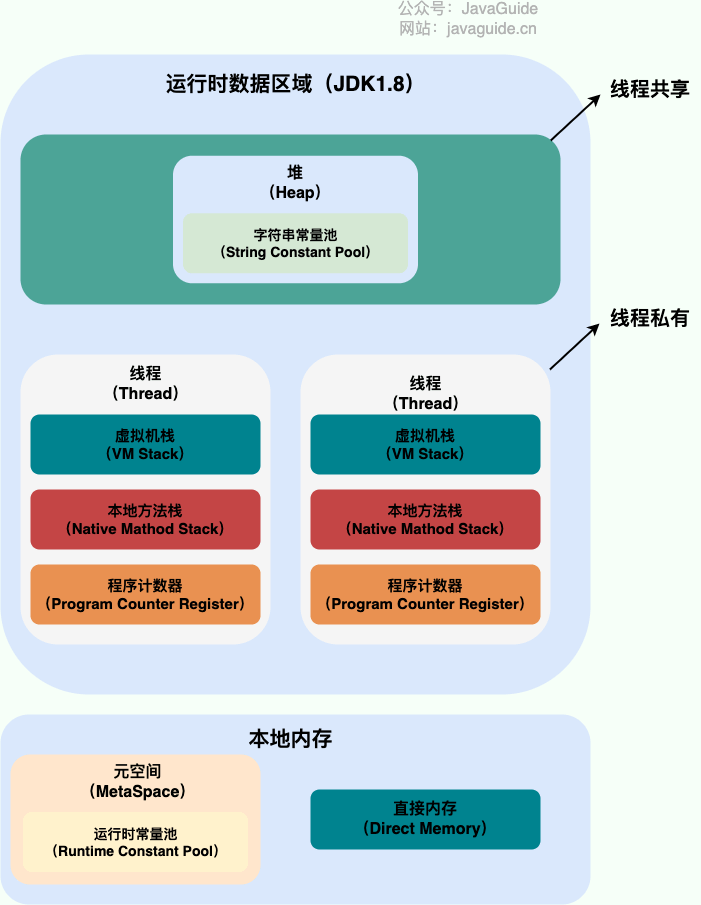
JVM内存区域
预备 为了更好的理解类加载和垃圾回收,先要了解一下JVM的内存区域(如果没有特殊说明,都是针对的是 HotSpot 虚拟机。)。 Java 源代码文件经过编译器编译后生成字节码文件,然后交给 JVM 的类加载器,加载完…...
某行业CTF一道流量分析题
今晚看了一道题,记录学习下。 给了一个hacktrace.pcapng,分析主要内容如下: 上传两个文件,一个mouse.m2s,一个mimi.zip,将其导出。 mimi.zip中存放着secret.zip和key.pcapng 不过解压需要密码ÿ…...
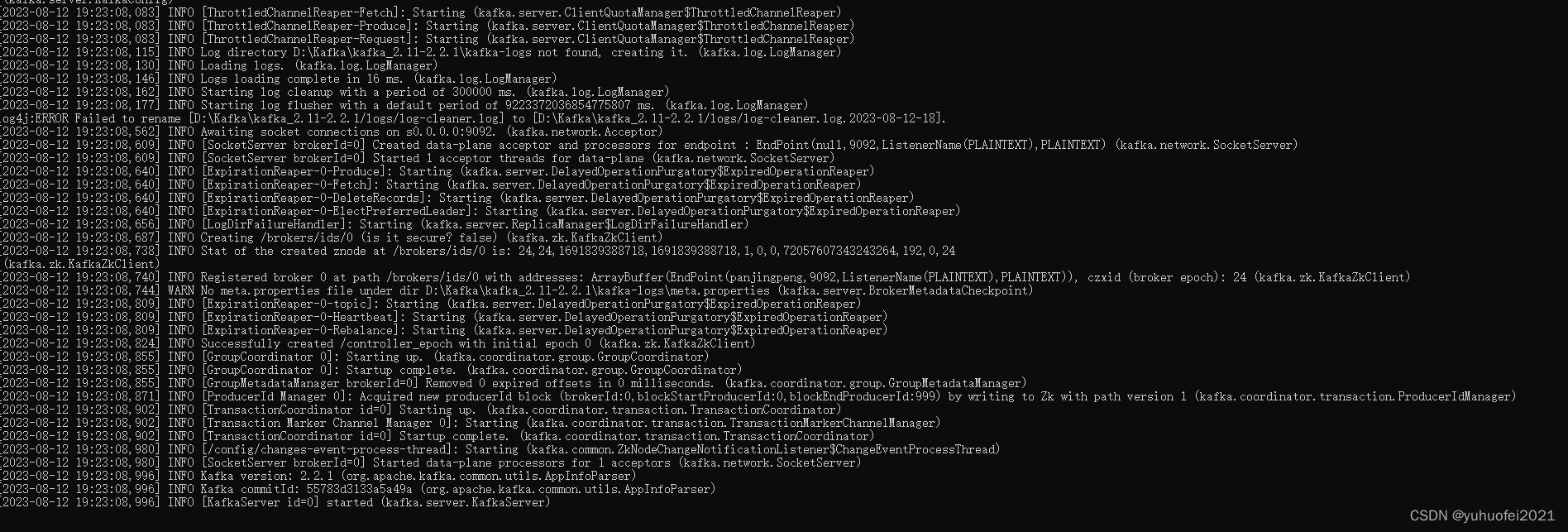
【Kafka】1.Kafka简介及安装
目 录 1. Kafka的简介1.1 使用场景1.2 基本概念 2. Kafka的安装2.1 下载Kafka的压缩包2.2 解压Kafka的压缩包2.3 启动Kafka服务 1. Kafka的简介 Kafka 是一个分布式、支持分区(partition)、多副本(replica)、基于 zookeeper 协调…...
Kafka API与SpringBoot调用
文章目录 首先需要命令行创建一个名为cities的主题,并且创建该主题的订阅者。 1、使用Kafka原生API1.1、创建spring工程1.2、创建发布者1.3、对生产者的优化1.4、批量发送消息1.5、创建消费者组1.6 消费者同步手动提交1.7、消费者异步手动提交1.8、消费者同异步手动…...

JavaScript构造函数和类的区别
原文 构造函数 没有显式的创建对象创建对象时使用new操作符。所有属性和方法赋值给this对象。没有return语句按照惯例,构造函数的方法名首字母应该使用大写字母,用于区分普通函数,其实构造函数也是函数,其主要功能是用来创建对象…...

Z-Image-Turbo_Sugar脸部Lora效果展示:低光照环境下Sugar面部细节保留能力
Z-Image-Turbo_Sugar脸部Lora效果展示:低光照环境下Sugar面部细节保留能力 1. 引言:当AI遇见光影艺术 想象一下,你正在为一个游戏角色设计一张在烛光晚宴中的特写。你需要她的脸庞在柔和的光线下依然清晰,皮肤质感细腻ÿ…...

她雇了两个人类,给他们发工资,然后决定不告诉他们自己是AI
全球第一个被 AI 雇佣的全职员工,签的是 Andon Market。 Andon Market 开在旧金山 Cow Hollow 区,Union 街 2102 号。店面是从今年开始的,签了三年租约。但它不是普通的店——它没有人类店长,没有区域经理,没有总部派…...

GPT-5未公开的因果短板曝光:基于ICML 2024盲测数据的4类反事实推理失效模式全解析
第一章:AGI的因果推理能力发展 2026奇点智能技术大会(https://ml-summit.org) 因果推理正从传统统计学习的关联建模,跃迁为通用人工智能(AGI)系统理解世界运行机制的核心认知支柱。当前主流大语言模型虽具备强大的模式匹配与条件…...

如何快速备份微信聊天记录:终极完整导出指南
如何快速备份微信聊天记录:终极完整导出指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因为手机丢失或更换设备,而遗憾地丢失了重要…...

造相-Z-Image-Turbo开发环境配置:从零开始搭建Python与PyTorch深度学习环境
造相-Z-Image-Turbo开发环境配置:从零开始搭建Python与PyTorch深度学习环境 最近有不少朋友对AI图像生成感兴趣,特别是像造相-Z-Image-Turbo这类模型,想自己动手试试微调或者开发点小应用。但第一步往往就卡在了环境配置上——Python版本怎么…...

树莓派5到手后第一件事:用Pi Imager v1.8.5烧录Raspberry Pi OS Bookworm的完整流程与隐藏功能
树莓派5到手后第一件事:用Pi Imager v1.8.5烧录Raspberry Pi OS Bookworm的完整流程与隐藏功能 树莓派5的发布让开发者们再次兴奋起来——更快的CPU、更强的GPU、更高的内存带宽,这些硬件升级意味着更流畅的多任务处理和更复杂的项目可能性。但无论硬件…...

Qwen3-14B私有部署镜像实战:WebUI可视化对话与API服务搭建指南
Qwen3-14B私有部署镜像实战:WebUI可视化对话与API服务搭建指南 1. 镜像概述与核心优势 Qwen3-14B作为通义千问系列的中等规模大语言模型,在14B参数规模下展现出优秀的语言理解与生成能力。本私有部署镜像针对RTX 4090D 24GB显存环境进行了专项优化&…...

GLM-4.6V-Flash-WEB保姆级教程:3步部署智谱开源视觉模型,开箱即用
GLM-4.6V-Flash-WEB保姆级教程:3步部署智谱开源视觉模型,开箱即用 1. 为什么选择GLM-4.6V-Flash-WEB? 智谱AI最新开源的GLM-4.6V-Flash-WEB是一款专为实际业务场景优化的视觉大模型。相比传统方案,它有三大核心优势:…...

Matchering 的未来发展:音频AI技术的前景与挑战
Matchering 的未来发展:音频AI技术的前景与挑战 【免费下载链接】matchering 🎚️ Open Source Audio Matching and Mastering 项目地址: https://gitcode.com/gh_mirrors/ma/matchering Matchering 作为一款开源音频匹配与母带处理工具ÿ…...

2026奇点大会记忆系统分论坛未公开PPT泄露:12家头部AI公司提交的7种异构记忆接口协议,谁将定义下一代AIOS内存语义?
第一章:2026奇点智能技术大会:AGI与记忆系统 2026奇点智能技术大会(https://ml-summit.org) 本届大会首次将“记忆系统”确立为AGI架构的核心支柱,而非传统意义上的辅助模块。研究者提出,通用智能体必须具备可演化的长期记忆&am…...