【图像分类】CNN + Transformer 结合系列.4
介绍两篇利用Transformer做图像分类的论文:CoAtNet(NeurIPS2021),ConvMixer(ICLR2022)。CoAtNet结合CNN和Transformer的优点进行改进,ConvMixer则patch的角度来说明划分patch有助于分类。
CoAtNet: Marrying Convolution and Attention for All Data Sizes, NeurIPS2021
论文:https://arxiv.org/abs/2106.04803
CoAtNet: Marrying Convolution and Attention for All Data Sizes
代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch
解读:【图像分类】2021-CoAtNet NeurlPS_relative attention_說詤榢的博客-CSDN博客
CoAtNet论文详解附代码实现 - 知乎
论文导读:CoAtNet是如何完美结合 CNN 和 Transformer的 - 知乎 (zhihu.com)
简介
本文证明,尽管 Transformers 具有更强的model capacity(模型能力),但因为缺乏inductive bias(归纳偏置)特性,它的泛化性要落后于 CNN。为了有效地结合二者的长处,论文提出CoAtNets,它的构建主要基于两个关键想法:(1)可以通过简单的 relative attention(相对注意力)将 depthwise Convolution(深度卷积)和 self-Attention(自注意力)自然统一;(2)在提升泛化性、能力和效率方面,按照一定的原则,垂直摆放卷积层和注意力层会非常有效。实验证明,CoAtNets 在多个数据集上,根据不同的资源要求,可以取得 SOTA 的效果。例如,CoAtNet 在 ImageNet 上取得了 86.0 % top-1 准确率,无需额外的数据,如果使用了 JFT 数据,则可达到 89.77 % top-1准确率,超越目前所有的 CNN 和 Transformers。
动机
自从AlexNet,CNN已经成为计算机视觉领域最主要的模型结构。同时,随着自注意力模型如 Transformers 在 NLP 领域取得成功,许多工作都尝试将注意力机制引入计算机视觉,并逐渐超越CNN。实验证明,在数据量充足的情况下,Transformer模型可以比CNN模型的能力更强。但是,在给定数据和计算量的前提下,transformer都没有超过SOTA卷积模型。例如在数据较少的数据集上,transformer表现差于CNN。这表明Transformer可能缺乏归纳偏置特性。而该特性存在于CNN结构中。所以一些工作尝试将卷积网络的归纳偏置融合到transformer模型中,在注意力层中强加上局部感受野,或通过隐式或显式的卷积操作来增强注意力和FFN层,但是,这些方法都关注在某个特性的注入上,缺乏对卷积和注意力结合时各自角色的理解。
本文作者从机器学习的两个基本面,系统地研究了卷积和注意力融合的问题:
- generalization(泛化性)
- model capacity(模型能力)
研究显示得益于归纳偏置先验,卷积网络的泛化性更强,收敛速度更快,而注意力层则拥有更强的模型能力,对大数据集更有益。将卷积和注意力层结合,可以取得更好的泛化性和模型能力;但是,问题是如何将二者有效结合,实现准确率和效率的平衡。
本文作者探讨了以下两点:
- 利用简单的相对注意力,深度卷积可以有效地融合入注意力层。
- 以适当的方式直接堆叠卷积层和注意力层,效果可能惊人地好,泛化性和能力都更高。
CoAtNet由此诞生,具备CNN和transformer的优势。
CoAtNet方法
网络模型
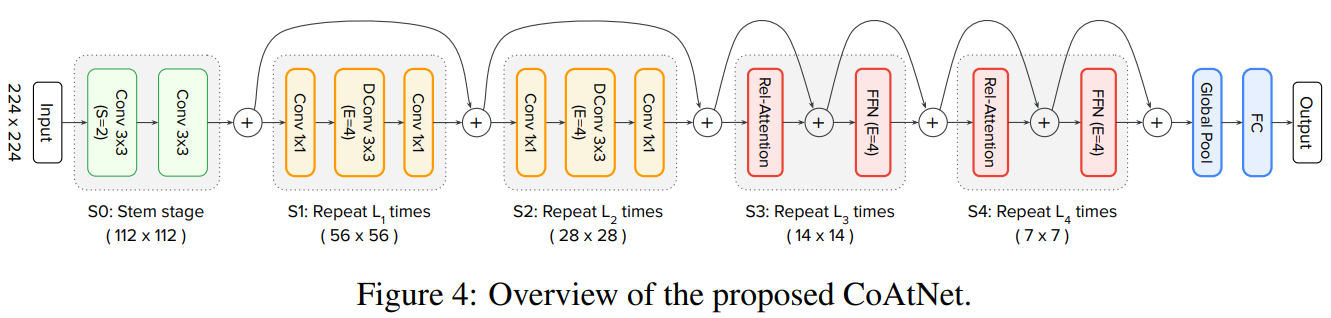
CoAtNet模型由C-C-T-T的形式构成。其中C表示Convolution,T表示Transformer。
其中,block数量以及隐藏层维度不同,CoAtNet有一系列不同容量大小的模型。如表所示
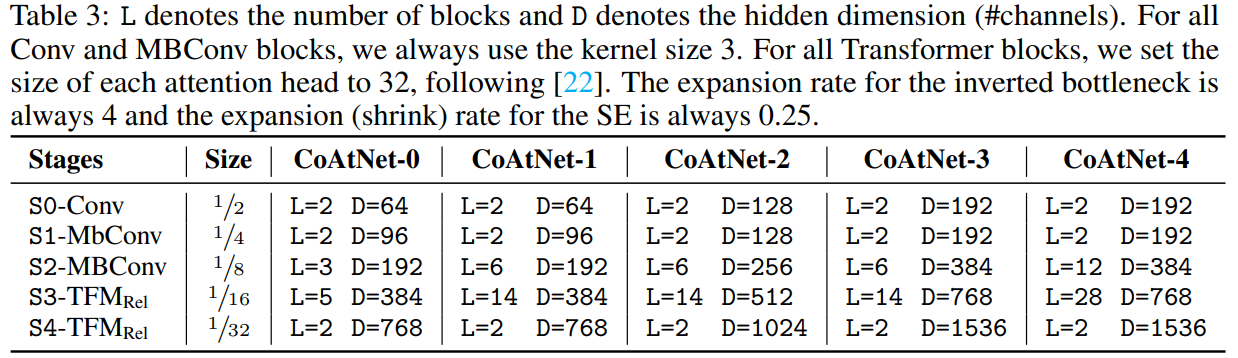
其中,Conv和MBConv模块的卷积核大小为3。Transformer注意力头的大小为32。inverted bottleneck的维度扩展比例为4。SE模块 shrink比例为0.25。
如何完美地将卷积和transformer结合呢?作者将该问题拆分为以下两部分:
- 如何将卷积和自注意力结合在一个计算模块内?
- 如何将不同类别的计算模型垂直的堆叠在一起,形成一个完整的网络。
融合卷积和自注意力
对于卷积,作者主要关注在 MBConv 模块,它利用深度卷积来获取空间联系。因为 Transformers 的 FFN 模块和 MBConv 都使用 “inverted bottleneck” 设计,首先将输入的通道大小扩展4倍,然后将它映射回原来的通道大小,这样可以使用残差连接。
除了都使用inverted bottleneck,作者也注意到,深度卷积和自注意力都可以表示为一个预先定义好的感受野内的数值加权和。卷积需要一个固定的卷积核,从局部感受野中获取信息:

其中,分别是i位置的输入和输出。L(i)表示i位置的相邻区域,即中心点为i的3X3网络。
为了比较,自注意力的感受野涵盖所有的空间位置,根据一对点的归一化后的相似度来计算权值:
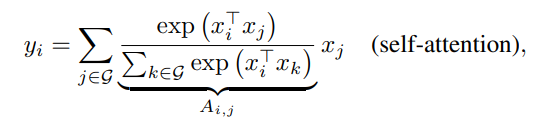
其中G表示全局位置空间。
在研究如何将他们最优地结合之前,先分析一下它们各自的优劣:
- 首先,深度卷积核
是一个与输入无关的静态参数,而注意力
动态的依赖输入的表征。因此,自注意力可以很容易地获取不同空间位置的相互关系,当处理高级别任务时这是非常必须的性质。但是,这种灵活性也带来了容易过拟合的风险,尤其是当数据有限时。
- 其次,给定一对空间点( i , j ) ,相应的卷积权重
只关心二者的相对偏移,即i − j,而不是 i 或 j 的具体数值。通常是指平移不变性,可以在有限的数据集上提升泛化性。因为使用了绝对位置 embedding,标准 ViT 缺少该特性。这就部分解释了为何当数据集有限时,卷积网络通常要比 Transformer 的表现好。
- 最后,感受野大小也是自注意力和卷积的最根本区别。一般而言,较大的感受野能提供更多的语义信息,模型能力就更强。因此,人们将自注意力应用在视觉领域的关键原因就是,它能提供全局感受野。但是,较大的感受野需要非常多的计算量。以全局感受野为例,复杂度相对于空间大小是指数的,这就限制了它的应用范围。

最理想的模型应该具备表1的三点特性。根据等式1和等式2的相似性,最直接的想法就是将在Softmax归一化之前或之后全局静态卷积核和自适应的注意力矩阵相加。如下所示:
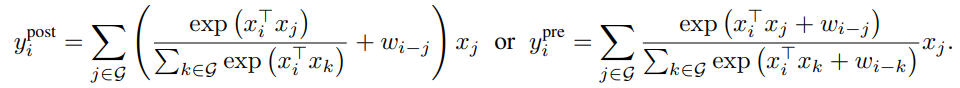
注意,为了确保全局卷积核不会造成参数量爆炸,作者将表示为一个标量,而非等式1中的向量。好处是,通过计算pairwise点积注意力,这样计算开支是最低的。
垂直堆叠网络层
得到一个简洁地将卷积和注意力结合的方式后,下一步就该思考如何利用它们。
如上所述,全局关系相对于空间大小呈指数复杂度。因此,如果直接在原始输入图像上使用等式3的相对注意力,计算会非常慢。要想构建出一个可行的网络,主要有三个选项:
- A:先进行下采样降低空间大小,然后当特征图达到可控的范围后,再使用全局相对注意力。
- B:强行加上局部注意力,将注意力中的全局感受野G约束在一个局部范围L内,就像卷积一样。
- C:将指数增长的 Softmax 注意力替换为线性注意力变体,它对于空间大小只有线性复杂度。
作者实验发现,B和C没有得到合理的效果。对于B,实现局部注意力会带来很多严重的形状变换操作,造成大量的内存读取。在 TPU 加速器上,该操作会非常慢,不仅无法实现全局注意力的加速,也会伤害模型的能力。对于C,实验发现没有取得合理效果。
因此,作者主要针对A选项进行优化。下采样操作可以是一个步长很大的卷积操作(如VIT,步长=16)或者是一个使用逐步池化的多阶段网络。
基于这些选项,作者设计了5个变体的网络结构,并做了实验比较。
- 当用 ViT 时,利用相对注意力直接堆叠 L个 Transformer 模块,记做VIT_REL 。
- 当使用多阶段池化时,我们模拟ConvNets,构建一个有5个阶段的网络(S0,S1,S2,S3 & S4),从S0 到S4 其空间分辨率是逐渐下降的。在每个阶段开始位置,空间大小缩小2倍,增加通道数。第一个阶段S0是一个简单的2层CNN,S1使用 MBConv 模块和 squeeze-excitation 操作,其空间大小对于全局注意力来说太大了。从S2 到S4,可以用 MBConv 或者 Transformer 模块,要求是卷积阶段必须在 Transformer 阶段之前。这个要求是基于一个先验得到的,卷积更擅长处理早期阶段中很常见的局部模式。这样随着 Transformer 阶段的增加,我们就有4种变体,C-C-C-C, C-C-C-T, C-C-T-T 和 C-T-T-T,其中C和T分别表示卷积和Transformer。
作者主要从泛化能力和模型能力对5个变体进行实验。
针对泛化性,本文研究了训练损失和测试精度之间的误差。如果两个模型有着相同的训练损失,那么测试精度更高的模型就应该有着更强的泛化性,因为它对没见过的数据泛化更好。当数据有限时,泛化能力就非常重要。
针对模型能力,作者评估了模型拟合大型数据集上的能力。当训练数据充足时,过拟合就不再是个问题,能力强的模型越有可能取得更好的效果。一般而言,模型越大,能力就越强,所以为了比较公平些,本文保证5个变体模型的大小是差不多的。
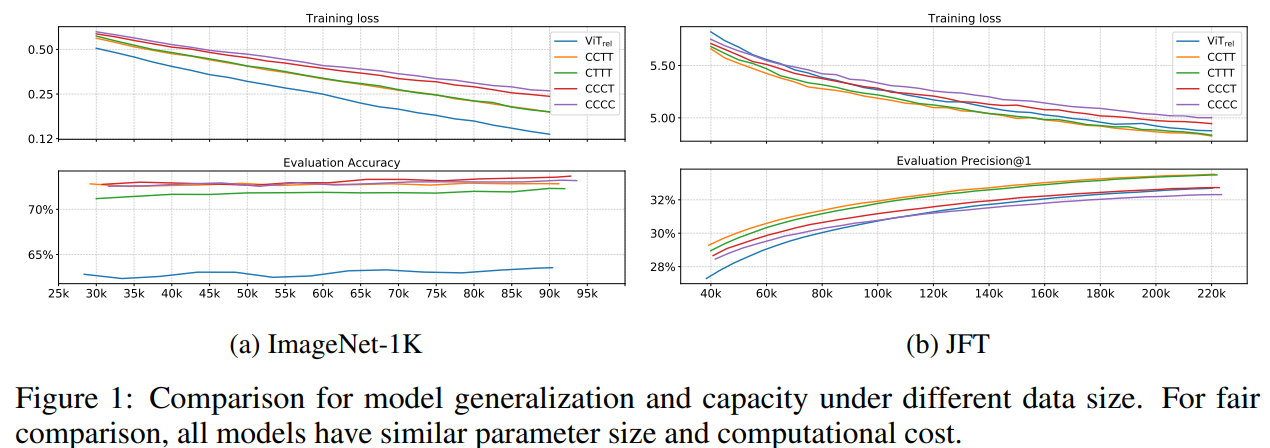
图1展示了模型在不同数据集规模下的泛化能力和模型能力。
从ImageNet上的结果可以看出,对于泛化能力,结论有:
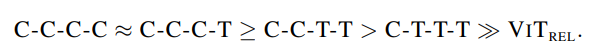
VIT_REL要比其它变体差好多,作者猜测这可能是因为在它激进的下采样过程中,缺失了低层级的信息。在多阶段变体中,整体趋势是,模型中卷积越多,泛化性越好。
针对模型能力,结论有:
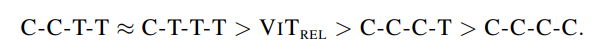
这说明,简单地增加 Transformer 模块并不一定会带来更强的模型能力。一方面,尽管初始化的很糟糕,VIT_REL最终追赶上了另两个带有 MBConv 的变体,表明 Transformer 模块的能力很强。另一方面,C-C-T-T 和C-T-T-T明显优于VIT_REL,表明 ViT 如果步长过大,会丢失很多信息,不利于模型的能力。C-C-T-T ≈C-T-T-T表明,对于低层级信息而言,静态局部操作如卷积的能力可与自适应全局注意力机制相当,但能大幅度降低计算量和内存占用。
最后,为了在C-C-T-T和C-T-T-T之间做决定,作者进行了可迁移性测试,作者在 ImageNet-1K 上对两个在 JFT 数据集上预训练的模型进行微调,训练了30个epochs,比较它们的迁移效果。从表2可以看到,C-C-T-T的效果要好于C-T-T-T,尽管它们的预训练表现差不多。

根据泛化性,模型能力,可迁移性和效率,作者在CoAtNet中采用了C-C-T-T多阶段方案。
关键代码
import torch
import torch.nn as nn
from einops import rearrange
from einops.layers.torch import Rearrange
from collections import OrderedDict"""
代码来源 https://github.com/KKKSQJ/DeepLearning
"""
__all__ = ["coatnet_0", "coatnet_1", "coatnet_2", "coatnet_3", "coatnet_4"]def conv_3x3_bn(in_c, out_c, image_size, downsample=False):stride = 2 if downsample else 1layer = nn.Sequential(nn.Conv2d(in_c, out_c, 3, stride, 1, bias=False),nn.BatchNorm2d(out_c),nn.GELU())return layerclass SE(nn.Module):def __init__(self, in_c, out_c, expansion=0.25):super(SE, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(out_c, int(in_c * expansion), bias=False),nn.GELU(),nn.Linear(int(in_c * expansion), out_c, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * yclass MBConv(nn.Module):def __init__(self,in_c,out_c,image_size,downsample=False,expansion=4):super(MBConv, self).__init__()self.downsample = downsamplestride = 2 if downsample else 1hidden_dim = int(in_c * expansion)if self.downsample:# 只有第一层的时候,进行下采样# self.pool = nn.MaxPool2d(kernel_size=2,stride=2)self.pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.proj = nn.Conv2d(in_c, out_c, 1, 1, 0, bias=False)layers = OrderedDict()# expandexpand_conv = nn.Sequential(nn.Conv2d(in_c, hidden_dim, 1, stride, 0, bias=False),nn.BatchNorm2d(hidden_dim),nn.GELU(),)layers.update({"expand_conv": expand_conv})# Depwise Convdw_conv = nn.Sequential(nn.Conv2d(hidden_dim, hidden_dim, 3, 1, 1, groups=hidden_dim, bias=False),nn.BatchNorm2d(hidden_dim),nn.GELU(),)layers.update({"dw_conv": dw_conv})# selayers.update({"se": SE(in_c, hidden_dim)})# projectpro_conv = nn.Sequential(nn.Conv2d(hidden_dim, out_c, 1, 1, 0, bias=False),nn.BatchNorm2d(out_c))layers.update({"pro_conv": pro_conv})self.block = nn.Sequential(layers)def forward(self, x):if self.downsample:return self.proj(self.pool(x)) + self.block(x)else:return x + self.block(x)class Attention(nn.Module):def __init__(self,in_c,out_c,image_size,heads=8,dim_head=32,dropout=0.):super(Attention, self).__init__()inner_dim = dim_head * headsproject_out = not (heads == 1 and dim_head == in_c)self.ih, self.iw = image_size if len(image_size) == 2 else (image_size, image_size)self.heads = headsself.scale = dim_head ** -0.5# parameter table of relative position biasself.relative_bias_table = nn.Parameter(torch.zeros((2 * self.ih - 1) * (2 * self.iw - 1), heads))coords = torch.meshgrid((torch.arange(self.ih), torch.arange(self.iw)))coords = torch.flatten(torch.stack(coords), 1)relative_coords = coords[:, :, None] - coords[:, None, :]relative_coords[0] += self.ih - 1relative_coords[1] += self.iw - 1relative_coords[0] *= 2 * self.iw - 1relative_coords = rearrange(relative_coords, 'c h w -> h w c')relative_index = relative_coords.sum(-1).flatten().unsqueeze(1)"""PyTorch中定义模型时,self.register_buffer('name', Tensor),该方法的作用是定义一组参数,该组参数的特别之处在于:模型训练时不会更新(即调用 optimizer.step() 后该组参数不会变化,只可人为地改变它们的值),但是保存模型时,该组参数又作为模型参数不可或缺的一部分被保存。"""self.register_buffer("relative_index", relative_index)self.attend = nn.Softmax(dim=-1)self.qkv = nn.Linear(in_c, inner_dim * 3, bias=False)self.proj = nn.Sequential(nn.Linear(inner_dim, out_c),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):# [q,k,v]qkv = self.qkv(x).chunk(3, dim=-1)# q,k,v:[batch_size, num_heads, num_patches, head_dim]q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=self.heads), qkv)# [batch_size, num_heads, ih*iw, ih*iw]# 时间复杂度:O(图片边长的平方)dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale# Use "gather" for more efficiency on GPUsrelative_bias = self.relative_bias_table.gather(0, self.relative_index.repeat(1, self.heads))relative_bias = rearrange(relative_bias, '(h w) c -> 1 c h w', h=self.ih * self.iw, w=self.ih * self.iw)dots = dots + relative_biasattn = self.attend(dots)out = torch.matmul(attn, v)out = rearrange(out, 'b h n d -> b n (h d)')out = self.proj(out)return outclass FFN(nn.Module):def __init__(self, dim, hidden_dim, dropout=0.):super(FFN, self).__init__()self.ffn = nn.Sequential(nn.Linear(dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.ffn(x)class Transformer(nn.Module):def __init__(self,in_c,out_c,image_size,heads=8,dim_head=32,downsample=False,dropout=0.,expansion=4,norm_layer=nn.LayerNorm):super(Transformer, self).__init__()self.downsample = downsamplehidden_dim = int(in_c * expansion)self.ih, self.iw = image_sizeif self.downsample:# 第一层进行下采样self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.proj = nn.Conv2d(in_c, out_c, 1, 1, 0, bias=False)self.attn = Attention(in_c, out_c, image_size, heads, dim_head, dropout)self.ffn = FFN(out_c, hidden_dim)self.norm1 = norm_layer(in_c)self.norm2 = norm_layer(out_c)def forward(self, x):x1 = self.pool1(x) if self.downsample else xx1 = rearrange(x1, 'b c h w -> b (h w) c')x1 = self.attn(self.norm1(x1))x1 = rearrange(x1, 'b (h w) c -> b c h w', h=self.ih, w=self.iw)x2 = self.proj((self.pool2(x))) if self.downsample else xx3 = x1 + x2x4 = rearrange(x3, 'b c h w -> b (h w) c')x4 = self.ffn(self.norm2(x4))x4 = rearrange(x4, 'b (h w) c -> b c h w', h=self.ih, w=self.iw)out = x3 + x4return outclass CoAtNet(nn.Module):def __init__(self,image_size=(224, 224),in_channels: int = 3,num_blocks: list = [2, 2, 3, 5, 2], # Lchannels: list = [64, 96, 192, 384, 768], # Dnum_classes: int = 1000,block_types=['C', 'C', 'T', 'T']):super(CoAtNet, self).__init__()assert len(image_size) == 2, "image size must be: {H,W}"assert len(channels) == 5assert len(block_types) == 4ih, iw = image_sizeblock = {'C': MBConv, 'T': Transformer}self.s0 = self._make_layer(conv_3x3_bn, in_channels, channels[0], num_blocks[0], (ih // 2, iw // 2))self.s1 = self._make_layer(block[block_types[0]], channels[0], channels[1], num_blocks[1], (ih // 4, iw // 4))self.s2 = self._make_layer(block[block_types[1]], channels[1], channels[2], num_blocks[2], (ih // 8, iw // 8))self.s3 = self._make_layer(block[block_types[2]], channels[2], channels[3], num_blocks[3], (ih // 16, iw // 16))self.s4 = self._make_layer(block[block_types[3]], channels[3], channels[4], num_blocks[4], (ih // 32, iw // 32))# 总共下采样32倍 2^5=32self.pool = nn.AvgPool2d(ih // 32, 1)self.fc = nn.Linear(channels[-1], num_classes, bias=False)for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm, nn.LayerNorm)):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def forward(self, x):x = self.s0(x)x = self.s1(x)x = self.s2(x)x = self.s3(x)x = self.s4(x)x = self.pool(x)x = torch.flatten(x, 1)x = self.fc(x)return xdef _make_layer(self, block, in_c, out_c, depth, image_size):layers = nn.ModuleList([])for i in range(depth):if i == 0:layers.append(block(in_c, out_c, image_size, downsample=True))else:layers.append(block(out_c, out_c, image_size, downsample=False))return nn.Sequential(*layers)def coatnet_0(num_classes=1000):num_blocks = [2, 2, 3, 5, 2] # Lchannels = [64, 96, 192, 384, 768] # Dreturn CoAtNet((224, 224), 3, num_blocks, channels, num_classes=num_classes)def coatnet_1(num_classes=1000):num_blocks = [2, 2, 6, 14, 2] # Lchannels = [64, 96, 192, 384, 768] # Dreturn CoAtNet((224, 224), 3, num_blocks, channels, num_classes=num_classes)def coatnet_2(num_classes=1000):num_blocks = [2, 2, 6, 14, 2] # Lchannels = [128, 128, 256, 512, 1026] # Dreturn CoAtNet((224, 224), 3, num_blocks, channels, num_classes=num_classes)def coatnet_3(num_classes=1000):num_blocks = [2, 2, 6, 14, 2] # Lchannels = [192, 192, 384, 768, 1536] # Dreturn CoAtNet((224, 224), 3, num_blocks, channels, num_classes=num_classes)def coatnet_4(num_classes=1000):num_blocks = [2, 2, 12, 28, 2] # Lchannels = [192, 192, 384, 768, 1536] # Dreturn CoAtNet((224, 224), 3, num_blocks, channels, num_classes=num_classes)def count_parameters(model):return sum(p.numel() for p in model.parameters() if p.requires_grad)if __name__ == '__main__':from torchsummary import summarydevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")img = torch.randn(1, 3, 224, 224).to(device)model = coatnet_0().to(device)out = model(img)summary(model, input_size=(3, 224, 224))print(out.shape, count_parameters(model))# net = coatnet_1()# out = net(img)# print(out.shape, count_parameters(net))## net = coatnet_2()# out = net(img)# print(out.shape, count_parameters(net))## net = coatnet_3()# out = net(img)# print(out.shape, count_parameters(net))## net = coatnet_4()# out = net(img)# print(out.shape, count_parameters(net))
实验



Patches Are All You Need? ICLR 2022
论文:https://arxiv.org/abs/2201.09792
代码:https://github.com/locuslab/convmixer
解读:【图像分类】2022-ConvMixer ICLR_說詤榢的博客-CSDN博客
Patches are all you need? - 知乎 (zhihu.com)
简介
ViT和MLP-Mixer都表现出强大的性能,它们的一个共同点就是都将图像划分为Patches输入。论文提出一个问题: 模型的性能是否与使用补丁作为输入表示有关
本文提出ConvMixer,一个极其简单的模型,类似于ViT和更基本的MLP-Mixer,它直接操作补丁作为输入,分离空间和通道维度的混合,并在整个网络中保持相同的大小和分辨率。ConvMixer只使用标准的卷积来实现混合步骤。ConvMixer在类似的参数计数和数据集大小方面优于ViT、MLP-Mixer和它们的一些变体,此外还优于ResNet等经典视觉模型。

ConvMixer方法
ConvMixer 由一个 patch 嵌入层和一个简单的全卷积块的重复应用组成。

ConvMixer包括一个patch embedding层,然后重复应用一个简单的卷积块。
![]()
ConvMixer 采用深度可分离卷积的思想,主要由depthwise convolution和pointwise convolution组成,此外也使用了Batch Normalization和 Residual connection等技术,激活函数采用GELU,其中最值得注意的是 ConvMixer采用7×7或9×9 等比较大的卷积核。

代码表示

参数设计
ConvMixer的实例化依赖于四个参数:
- Patch Embedding的通道维度h hh
- ConvMixer层的重复次数d dd
- 控制模型中特征分辨率的patch大小p pp
- depthwise卷积的卷积核大小k。

关键代码
import torch.nn as nnclass Residual(nn.Module):def __init__(self, fn):super().__init__()self.fn = fndef forward(self, x):return self.fn(x) + xdef ConvMixer(dim, depth, kernel_size=9, patch_size=7, n_classes=1000):return nn.Sequential(nn.Conv2d(3, dim, kernel_size=patch_size, stride=patch_size),nn.GELU(),nn.BatchNorm2d(dim),*[nn.Sequential(Residual(nn.Sequential(nn.Conv2d(dim, dim, kernel_size, groups=dim, padding="same"),nn.GELU(),nn.BatchNorm2d(dim))),nn.Conv2d(dim, dim, kernel_size=1),nn.GELU(),nn.BatchNorm2d(dim)) for i in range(depth)],nn.AdaptiveAvgPool2d((1,1)),nn.Flatten(),nn.Linear(dim, n_classes))def ConvMixer(h,d,k,p,n):S,C,A=Sequential,Conv2d,lambda x:S(x,GELU(),BatchNorm2d(h))R=type('',(S,),{'forward':lambda s,x:s[0](x)+x})return S(A(C(3,h,p,p)),*[S(R(A(C(h,h,k,groups=h,padding=k//2))),A(C(h,h,1))) for iin range(d)],AdaptiveAvgPool2d(1),Flatten(),Linear(h,n))实验
相关文章:
【图像分类】CNN + Transformer 结合系列.4
介绍两篇利用Transformer做图像分类的论文:CoAtNet(NeurIPS2021),ConvMixer(ICLR2022)。CoAtNet结合CNN和Transformer的优点进行改进,ConvMixer则patch的角度来说明划分patch有助于分类。 CoAtN…...

分享一下利用Vue表单处理实现复杂表单布局
在开发Web应用程序中,表单是非常常见的一种元素。而在某些情况下,我们需要实现一些更为复杂的表单布局,以满足业务需求。使用Vue.js作为前端框架,我们可以很方便地处理复杂表单布局,并且实现数据的双向绑定。 下面来将…...
SAP Fiori 问题收集
事务代码篇 启动工作台:/N/UI2/FLP 错误日志: /n/IWFND/ERROR_LOG 服务清单: /n/IWFND/MAINT_SERVICE 创建语义对象:/N/UI2/SEMOBJ 创建目录:/N/UI2/FLPD_CONF(cross-client)或 /N/UI2…...

econml双机器学习实现连续干预和预测
连续干预 在这个示例中,我们使用LinearDML模型,使用随机森林回归模型来估计因果效应。我们首先模拟数据,然后模型,并使用方法来effect创建不同干预值下的效应(Conditional Average Treatment Effect,CATE&…...

《甲午》观后感——GPT-3.5所写
《甲午》是一部令人深思的纪录片,通过生动的画面和真实的故事,向观众展示了中国历史上的一段重要时期。观看这部纪录片,我深受触动,对历史的认识也得到了深化。 首先,这部纪录片通过精心搜集的历史资料和珍贵的影像资料…...
—— 微服务篇)
Java技术整理(6)—— 微服务篇
1、服务注册发现 服务注册就是维护一个服务列表,它在管理系统内所有的服务地址,当新的服务启动后,它会向服务列表提交自己的服务地址,服务的调用法可以直接向服务列表发送服务列表获取请求,就能获得所有的服务地址&am…...

途乐证券-新股行情持续火爆,哪些因素影响首日表现?
全面注册制以来,参加打新的投资者数量全体呈现下降。打新收益下降,破发频出的布景下,投资者打新策略从逢新必打逐步向优选个股改变。 经过很多历史数据,从商场定价、参加者热度以及机构重视度维度揭秘了上市后股价体现优秀的个股具…...

在生产环境中部署Elasticsearch:最佳实践和故障排除技巧——聚合与搜索(三)
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...

基于weka手工实现KNN
一、KNN模型 K最近邻(K-Nearest Neighbors,简称KNN)算法是一种常用的基于实例的监督学习算法。它可以用于分类和回归问题,并且是一种非常直观和简单的机器学习算法。 KNN算法的基本思想是:对于一个新的样本数据&…...

Lua 闭包
一、Lua 中的函数 Lua 中的函数是第一类值。意味着和其他的常见类型的值(例如数值和字符串)具有同等权限。 举个例子,函数也可以像其他类型一样存储起来,然后调用 -- 将 a.p 指向 print 函数 a { p print } -- 使用 a.p 函数…...
—— JVM篇)
Java技术整理(1)—— JVM篇
1、什么是JVM? JVM是一个可运行Java代码的虚拟计算机,包括一套字节码指令集,一组寄存器,一个栈,一个垃圾回收,堆和一个存储方式栈。JVM 是运行在操作系统之上,并不与操作系统直接交互。 2、运行…...
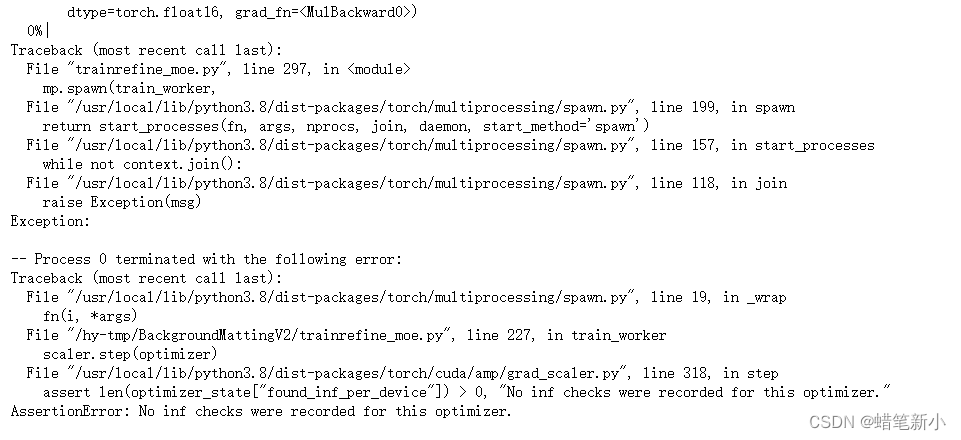
bug解决:AssertionError: No inf checks were recorded for this optimizer.
这真的是最恶心的一个error(比网络回传找哪层没有传播到还要恶心!),找了好久的问题所在之处,最后偶然发现了这篇文章: 解决pytorch半精度amp训练nan问题 - 知乎 然后发现自己用的混合精度训练,发…...

Django笔记之数据库查询优化汇总
1、性能方面 1. connection.queries 前面我们介绍过 connection.queries 的用法,比如我们执行了一条查询之后,可以通过下面的方式查到我们刚刚的语句和耗时 >>> from django.db import connection >>> connection.queries [{sql: S…...
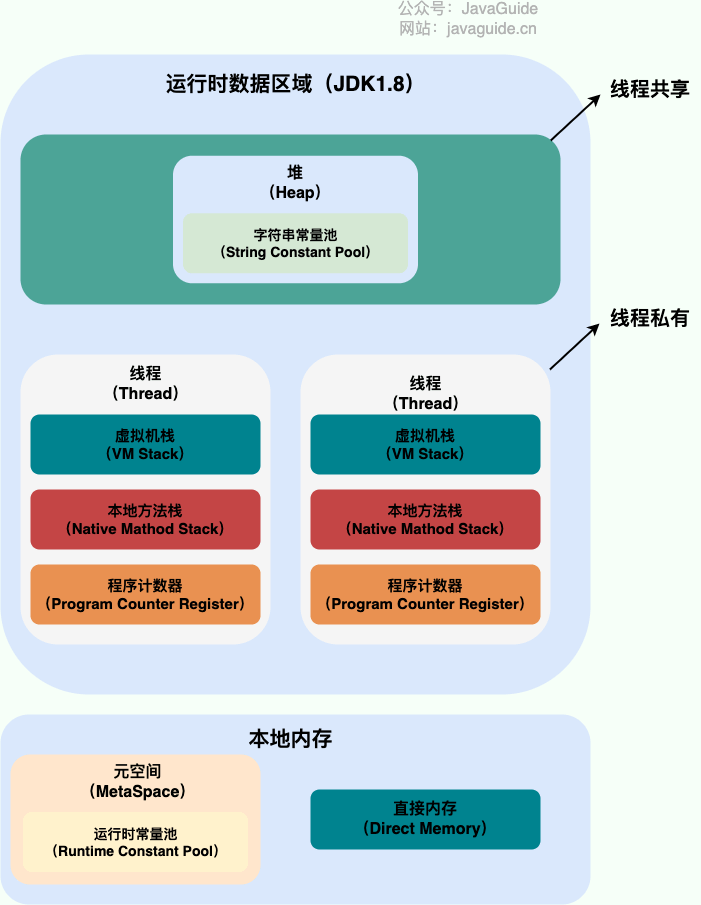
JVM内存区域
预备 为了更好的理解类加载和垃圾回收,先要了解一下JVM的内存区域(如果没有特殊说明,都是针对的是 HotSpot 虚拟机。)。 Java 源代码文件经过编译器编译后生成字节码文件,然后交给 JVM 的类加载器,加载完…...
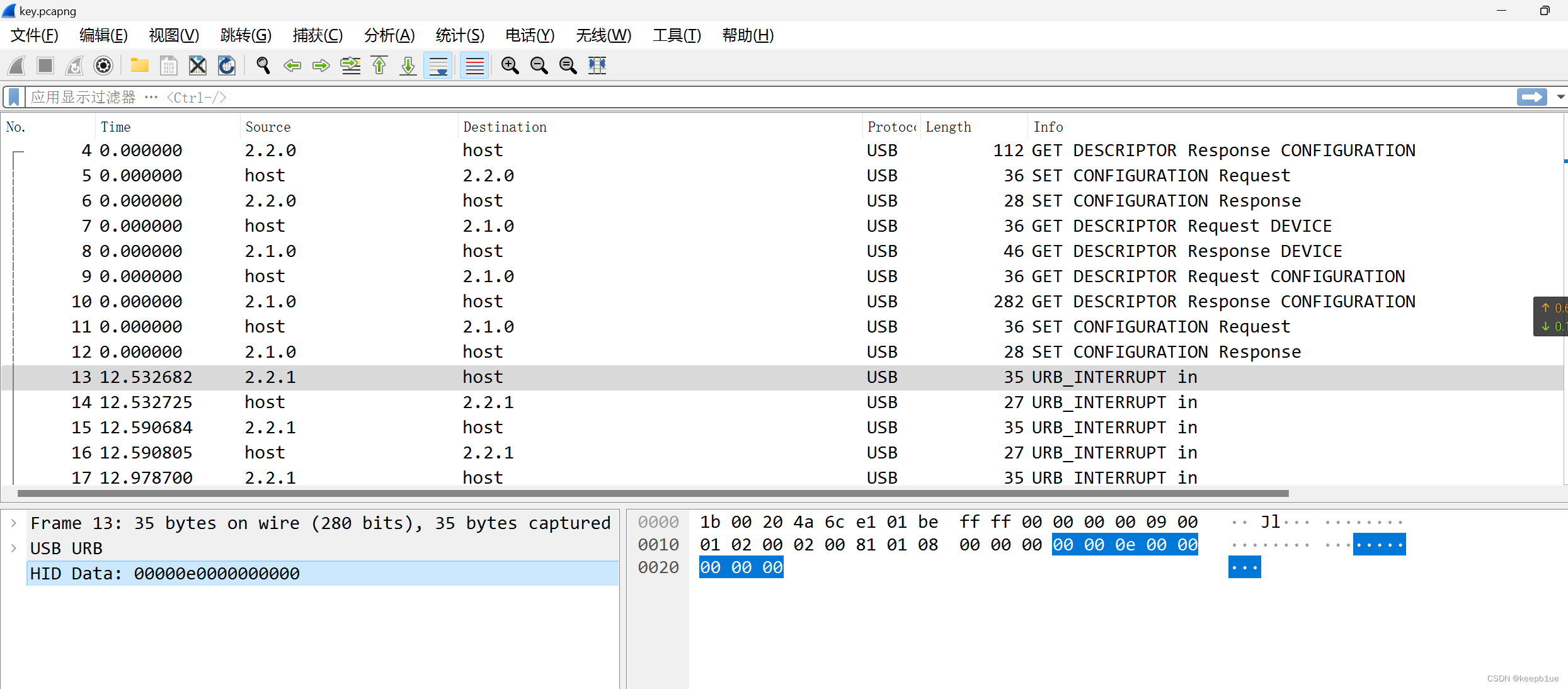
某行业CTF一道流量分析题
今晚看了一道题,记录学习下。 给了一个hacktrace.pcapng,分析主要内容如下: 上传两个文件,一个mouse.m2s,一个mimi.zip,将其导出。 mimi.zip中存放着secret.zip和key.pcapng 不过解压需要密码ÿ…...
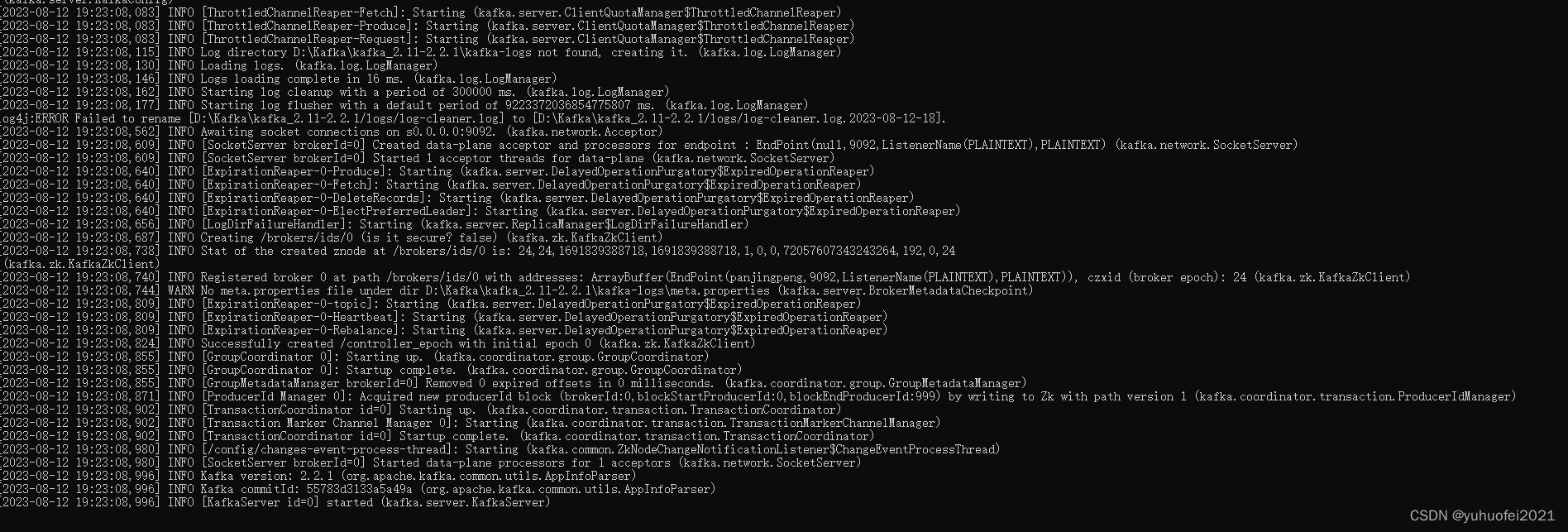
【Kafka】1.Kafka简介及安装
目 录 1. Kafka的简介1.1 使用场景1.2 基本概念 2. Kafka的安装2.1 下载Kafka的压缩包2.2 解压Kafka的压缩包2.3 启动Kafka服务 1. Kafka的简介 Kafka 是一个分布式、支持分区(partition)、多副本(replica)、基于 zookeeper 协调…...
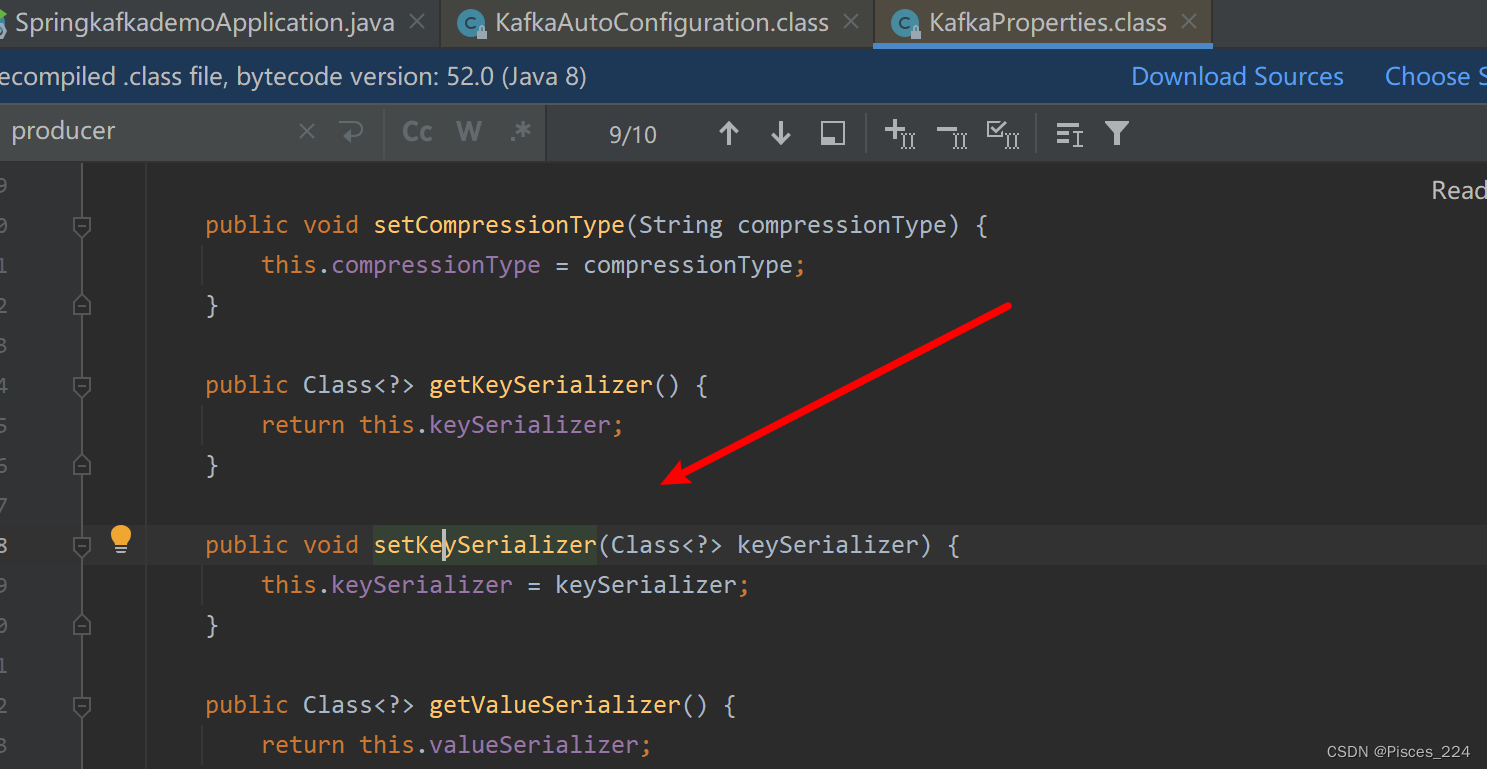
Kafka API与SpringBoot调用
文章目录 首先需要命令行创建一个名为cities的主题,并且创建该主题的订阅者。 1、使用Kafka原生API1.1、创建spring工程1.2、创建发布者1.3、对生产者的优化1.4、批量发送消息1.5、创建消费者组1.6 消费者同步手动提交1.7、消费者异步手动提交1.8、消费者同异步手动…...

JavaScript构造函数和类的区别
原文 构造函数 没有显式的创建对象创建对象时使用new操作符。所有属性和方法赋值给this对象。没有return语句按照惯例,构造函数的方法名首字母应该使用大写字母,用于区分普通函数,其实构造函数也是函数,其主要功能是用来创建对象…...
Spring与Spring Bean
Spring 原理 它是一个全面的、企业应用开发一站式的解决方案,贯穿表现层、业务层、持久层。但是 Spring 仍然可 以和其他的框架无缝整合。 Spring 特点 轻量级 控制反转 面向切面 容器 框架集合 Spring 核心组件 Spring 总共有十几个组件核心容器(Spring core) S…...
并发相关面试题
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 如何理解volatile关键字 在并发领域中,存在三大特性:原子性、有序性、可见性。volatile关键字用来修饰对象的属性…...

如何高效解密QQ音乐加密格式:qmcdump完整实战指南
如何高效解密QQ音乐加密格式:qmcdump完整实战指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump qmcdump是…...
)
手把手教你搞定OpenStack Train版离线部署:从零搭建私有云(附完整yum源制作)
企业级OpenStack Train离线部署实战:从yum源构建到私有云落地 在数字化转型浪潮中,企业对于私有云的需求日益增长。OpenStack作为开源云计算平台的标杆,其灵活性和可扩展性备受青睐。但对于许多金融机构、军工单位或严格隔离的生产环境而言&a…...

嵌入式Linux实战:基于IMX6ULL与ZigBee的智能仓储环境监控系统
1. 项目背景与核心价值 在工业4.0时代,仓储管理正经历着从传统人工操作向智能化转型的关键阶段。去年我接手了一个食品企业的仓库改造项目,他们的痛点非常典型:冷链仓库温度波动导致货物损耗、人工巡检效率低下、异常响应延迟等问题频发。这正…...

Supabase 异步与同步客户端对比:如何选择最适合你的开发模式
Supabase 异步与同步客户端对比:如何选择最适合你的开发模式 【免费下载链接】supabase-py Python Client for Supabase. Query Postgres from Flask, Django, FastAPI. Python user authentication, security policies, edge functions, file storage, and realtim…...

YOLO12实战案例:YOLO12用于数字孪生工厂中设备状态视觉感知
YOLO12实战案例:YOLO12用于数字孪生工厂中设备状态视觉感知 1. 引言:当数字孪生遇到“火眼金睛” 想象一下,你是一家大型制造工厂的负责人。车间里,上百台设备日夜不停地运转,从冲压机到焊接机器人,从传送…...

Claude Code 有什么功能?能力全解析
在AI工具百花齐放的今天,像库拉KULAAI(t.kulaai.cn)这样的聚合平台为用户提供了便捷的一站式体验入口。而Claude Code作为Anthropic推出的AI编程助手,正在重新定义开发者的工作方式。本文将深入解析其核心功能与实战价值。一、核心功能:不只是…...

终极 HashiCorp Otto 项目常见问题解决方案:从安装到部署的完整指南
终极 HashiCorp Otto 项目常见问题解决方案:从安装到部署的完整指南 【免费下载链接】otto Development and deployment made easy. 项目地址: https://gitcode.com/gh_mirrors/otto/otto HashiCorp Otto 是一款致力于简化开发和部署流程的强大工具ÿ…...

如何让导航栏的下落动画效果更慢?
通过调整 CSS 动画的持续时间(如将 0.2s 改为 0.6s 或更长),即可平滑控制 Bootstrap 导航栏下落动画的速度,同时需配合 transform 与 opacity 实现更自然的过渡效果。 通过调整 css 动画的持续时间(如将 0.2s 改为…...

Linux输入子系统实战:从struct input_event到鼠标、键盘、触屏事件解析与编程
1. Linux输入子系统入门:从设备文件到事件流 刚接触Linux输入子系统时,我花了整整三天才搞明白/dev/input/eventX这些神秘文件背后的门道。简单来说,Linux把所有的输入设备——键盘、鼠标、触摸屏、游戏手柄——都抽象成了文件。当你按下键盘…...

别再学框架了!2026奇点大会证实:未来3年高薪岗位只筛选这7种AGI协同行为模式
第一章:2026奇点智能技术大会:AGI与编程能力 2026奇点智能技术大会(https://ml-summit.org) AGI驱动的实时代码生成范式 本届大会首次公开展示了基于多模态具身推理的AGI编程代理——SingularityCoder v3.2。该系统不再依赖静态训练数据,而…...