【python】爬取豆瓣电影Top250(附源码)
前言
在网络爬虫的开发过程中,经常会遇到需要处理一些反爬机制的情况。其中之一就是网站对于频繁访问的限制,即IP封禁。为了绕过这种限制,我们可以使用代理IP来动态改变请求的来源IP地址。在本篇博客中,将介绍如何使用代理IP的技术来爬取某瓣电影排行榜,并将结果写入Excel文件。
准备工作
首先,我们需要准备以下环境和工具:
-
Python编程语言
-
requests库:用于发送HTTP请求
-
BeautifulSoup库:用于解析HTML页面
-
openpyxl库:用于操作Excel文件
-
一个可用的代理IP池
步骤
1. 获取代理IP
使用搜索引擎搜索"免费代理IP",找到一个可用的代理IP网站。请注意,不同的网站可能有不同的获取代理IP的方式。你需要根据特定网站的规则来获取代理IP列表。
使用IP代理的必要性:
-
隐藏真实的访问源,保护个人或机构的隐私和安全。
-
绕过目标网站的访问限制,如IP封禁、地区限制等。
-
分散访问压力,提高爬取效率和稳定性。
-
收集不同地区或代理服务器上的数据,用于数据分析和对比。
爬虫是一种通过自动化方式从网站上获取数据的程序,而代理IP则是用于隐藏真实IP地址的中间服务器。
IP代理和爬虫的关系?

当你使用爬虫程序时,你的请求会发送到目标网站,并且网站可以看到你的真实IP地址。然而,如果你频繁地发送请求,可能会导致你的IP地址被封锁或限制访问。为了解决这个问题,可以使用代理IP。
代理IP充当了一个中间服务器的角色,将你的请求通过不同的IP地址发送到目标网站。这样,目标网站只能看到代理IP的地址,而不是你的真实IP地址。通过使用不同的代理IP轮换发送请求,可以减少被封锁或限制访问的风险。
另外,代理IP还可以用于绕过地理限制。有些网站或服务可能根据用户所在地区提供不同的内容或限制访问。通过使用代理IP,你可以模拟不同地区的访问,以便获取特定地区的数据。
2. 验证代理IP的可用性
将获取的代理IP列表保存到一个文件中(例如proxies.txt),然后编写代码来验证这些代理IP是否可用。我们可以通过发送请求到一个公开的IP查询API,来检查代理IP是否有效。
import requests
def check_proxy(proxy):try:response = requests.get("http://ip-api.com/json", proxies={"http": proxy, "https": proxy}, timeout=5)if response.status_code == 200:return Trueexcept requests.exceptions.RequestException:passreturn False
with open("proxies.txt", "r") as f:proxies = f.read().splitlines()
valid_proxies = []
for proxy in proxies:if check_proxy(proxy):valid_proxies.append(proxy)
print(valid_proxies)3. 爬取某瓣电影排行榜
使用valid_proxies中的代理IP,编写代码来发送HTTP请求并解析网页内容。我们可以使用BeautifulSoup库来解析HTML页面,并提取所需的信息。
导入模块:
代码导入了所需要的库,包括re用于正则表达式操作,pandas用于写入Excel文件,requests用于发送HTTP请求,lxml用于解析HTML网页内容,time用于延时操作。
import re # 正则
import pandas as pd # pandas,写入Excel文件
import requests
from lxml import etree
import time
定义函数get_html_str(url),该函数用于发送HTTP请求并获取响应内容。函数中设置了请求头模拟浏览器,并可以添加代理IP进行请求。最后返回网页源码。
def get_html_str(url):# 请求头headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}proxies = {"http": "自己填一下子",}# 添加请求头和代理IP发送请求response = requests.get(url, headers=headers, proxies=proxies) ## 获取网页源码html_str = response.content.decode()# 返回网页源码return html_str 定义函数get_data(html_str, data_list),该函数用于从网页源码中提取数据并存入列表。函数使用lxml将网页源码转换为Elements对象方便后续使用XPath进行解析。通过XPath取到所有的li标签,然后遍历每个li标签,利用XPath获取每个字段的信息,例如排名、电影名、评分等,并使用正则表达式进行字符串的提取和处理,最后将数据存入列表。
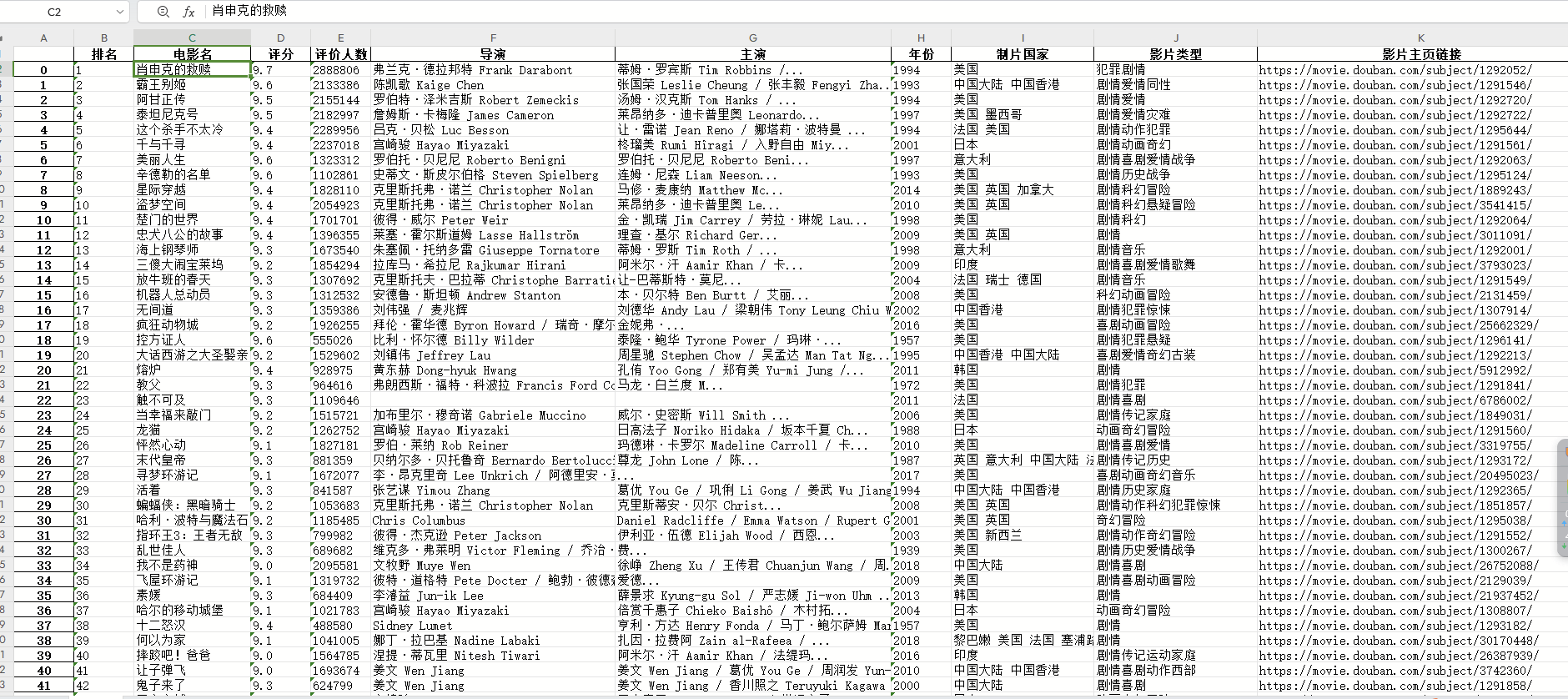
def get_data(html_str, data_list):"""提取数据写入列表"""# 将html字符串转换为etree对象方便后面使用xpath进行解析html_data = etree.HTML(html_str)# 利用xpath取到所有的li标签li_list = html_data.xpath("//ol[@class='grid_view']/li")# 打印一下li标签个数看是否和一页的电影个数对得上print(len(li_list)) # 输出25,没有问题# 遍历li_list列表取到某一个电影的对象for li in li_list:# 用xpath获取每一个字段信息# 排名ranking = li.xpath(".//div[@class='pic']/em/text()")[0]# 电影名title = li.xpath(".//div[@class='hd']/a/span[1]/text()")[0]# 评分score = li.xpath(".//span[@class='rating_num']/text()")[0]# 评价人数evaluators_number = li.xpath(".//div[@class='star']/span[4]/text()")[0]evaluators_number = evaluators_number.replace('人评价', '') # 将'人评价'替换为替换为空,更美观# 导演、主演str1 = li.xpath(".//div[@class='bd']/p[1]//text()")[0]# 利用正则提取导演名try:director = re.findall("导演: (.*?)主演", str1)[0]director = re.sub('\xa0', '', director)except:director = None# 利用正则提取主演try:performer = re.findall("主演: (.*)", str1)[0]performer = re.sub('\xa0', '', performer)except:performer = None# 上映时间、制片国家、电影类型都在这里标签下str2 = li.xpath(".//div[@class='bd']/p[1]//text()")[1]#try:# 通过斜杠进行分割str2_list = str2.split(' / ')# 年份year = re.sub('[\n ]', '', str2_list[0])# 制片国家country = str2_list[1]# 影片类型type = re.sub('[\n ]', '', str2_list[2])except:year = Nonecountry = Nonetype = Noneurl = li.xpath(".//div[@class='hd']/a/@href")[0]print({'排名': ranking, '电影名': title, '评分': score, '评价人数': evaluators_number, '导演': director,'主演': performer, '年份': year, '制片国家': country, '影片类型': type, '影片主页链接': url})data_list.append({'排名': ranking, '电影名': title, '评分': score, '评价人数': evaluators_number, '导演': director,'主演': performer, '年份': year, '制片国家': country, '影片类型': type, '影片主页链接': url}) 定义函数into_excel(data_list),该函数用于将数据列表写入Excel文件。首先创建一个DataFrame对象,然后使用to_excel()方法将DataFrame写入Excel文件。
def into_excel(data_list):# 创建DataFrame对象df = pd.DataFrame(data_list)# 写入excel文件df.to_excel('电影Top250排行.xlsx') 定义了一个主函数main(),该函数用于控制流程。在主函数中,设置了翻页,循环遍历10页的数据。通过拼接URL,调用get_html_str()函数获取网页源码,然后调用get_data()函数提取数据,并将数据存入列表。为了控制爬取速度,使用time.sleep()方法进行延时操作。最后调用into_excel()函数将数据列表写入Excel文件。
def main():data_list = [] # 空列表用于存储每页获取到的数据# 1. 设置翻页for i in range(10):url = 'https://movie.douban.com/top250?start=' + str(i * 25) + '&filter='# 2. 获取网页源码html_str = get_html_str(url)# 3. 提取数据get_data(html_str, data_list)# 4. 限制爬取的速度time.sleep(5)# 5. 写入excelinto_excel(data_list)if __name__ == "__main__":main()最终效果图
完整代码如下:
import re # 正则
import pandas as pd # pandas,写入Excel文件
import requests
from lxml import etree
import time def get_html_str(url):# 请求头headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}proxies = {"http": "自己填一下子",}# 添加请求头和代理IP发送请求response = requests.get(url, headers=headers, proxies=proxies) ## 获取网页源码html_str = response.content.decode()# 返回网页源码return html_strdef get_data(html_str, data_list):"""提取数据写入列表"""# 将html字符串转换为etree对象方便后面使用xpath进行解析html_data = etree.HTML(html_str)# 利用xpath取到所有的li标签li_list = html_data.xpath("//ol[@class='grid_view']/li")# 打印一下li标签个数看是否和一页的电影个数对得上print(len(li_list)) # 输出25,没有问题# 遍历li_list列表取到某一个电影的对象for li in li_list:# 用xpath获取每一个字段信息# 排名ranking = li.xpath(".//div[@class='pic']/em/text()")[0]# 电影名title = li.xpath(".//div[@class='hd']/a/span[1]/text()")[0]# 评分score = li.xpath(".//span[@class='rating_num']/text()")[0]# 评价人数evaluators_number = li.xpath(".//div[@class='star']/span[4]/text()")[0]evaluators_number = evaluators_number.replace('人评价', '') # 将'人评价'替换为替换为空,更美观# 导演、主演str1 = li.xpath(".//div[@class='bd']/p[1]//text()")[0]# 利用正则提取导演名try:director = re.findall("导演: (.*?)主演", str1)[0]director = re.sub('\xa0', '', director)except:director = None# 利用正则提取主演try:performer = re.findall("主演: (.*)", str1)[0]performer = re.sub('\xa0', '', performer)except:performer = None# 上映时间、制片国家、电影类型都在这里标签下str2 = li.xpath(".//div[@class='bd']/p[1]//text()")[1]#try:# 通过斜杠进行分割str2_list = str2.split(' / ')# 年份year = re.sub('[\n ]', '', str2_list[0])# 制片国家country = str2_list[1]# 影片类型type = re.sub('[\n ]', '', str2_list[2])except:year = Nonecountry = Nonetype = Noneurl = li.xpath(".//div[@class='hd']/a/@href")[0]print({'排名': ranking, '电影名': title, '评分': score, '评价人数': evaluators_number, '导演': director,'主演': performer, '年份': year, '制片国家': country, '影片类型': type, '影片主页链接': url})data_list.append({'排名': ranking, '电影名': title, '评分': score, '评价人数': evaluators_number, '导演': director,'主演': performer, '年份': year, '制片国家': country, '影片类型': type, '影片主页链接': url})def into_excel(data_list):# 创建DataFrame对象df = pd.DataFrame(data_list)# 写入excel文件df.to_excel('电影Top250排行.xlsx')def main():data_list = [] # 空列表用于存储每页获取到的数据# 1. 设置翻页for i in range(10):url = 'https://movie.douban.com/top250?start=' + str(i * 25) + '&filter='# 2. 获取网页源码html_str = get_html_str(url)# 3. 提取数据get_data(html_str, data_list)# 4. 限制爬取的速度time.sleep(5)# 5. 写入excelinto_excel(data_list)if __name__ == "__main__":main()
总结
通过使用代理IP技术,我们可以绕过网站的IP封禁限制,成功爬取某瓣电影排行榜的信息,并将结果写入Excel文件。这样,我们就可以方便地对电影信息进行整理和分析了。
相关文章:
【python】爬取豆瓣电影Top250(附源码)
前言 在网络爬虫的开发过程中,经常会遇到需要处理一些反爬机制的情况。其中之一就是网站对于频繁访问的限制,即IP封禁。为了绕过这种限制,我们可以使用代理IP来动态改变请求的来源IP地址。在本篇博客中,将介绍如何使用代理IP的技术…...

35岁职业危机?不存在!体能断崖?不担心
概述 90年,硕士毕业,干了快8年的Java开发工作。现年33岁,再过2年就要35岁。 工作这些年,断断续续也看过不少35岁找不到工作,转行,降薪入职的传闻、案例。 35岁,甚至30岁之后,体能…...

C语言——指针进阶
本章重点 字符指针数组指针指针数组数组传参和指针传参函数指针函数指针数组指向函数指针数组的指针回调函数指针和数组面试题的解析 1. 字符指针 在指针的类型中我们知道有一种指针类型为字符指针 char* int main() { char ch w; char *pc &ch; *pc w; return 0; }…...

heap pwn 入门大全 - 1:glibc heap机制与源码阅读(上)
本文为笔者学习heap pwn时,学习阅读glibc ptmalloc2源码时的笔记,与各位分享。可能存在思维跳跃或错误之处,敬请见谅,欢迎在评论中指出。本文也借用了部分外网和其他前辈的素材图片,向各位表示诚挚的感谢!如…...
树莓派RP2040 用Arduino IDE安装和编译
目录 1 Arduino IDE 1.1 IDE下载 1.2 安装 arduino mbed os rp2040 boards 2 编程-烧录固件 2.1 打开点灯示例程序 2.2 选择Raspberry Pi Pico开发板 2.3 编译程序 2.4 烧录程序 2.4.1 Raspberry Pi Pico开发板首次烧录提示失败 2.4.2 解决首次下载失败问题 2.4.2.1…...

云安全攻防(八)之 Docker Remote API 未授权访问逃逸
Docker Remote API 未授权访问逃逸 基础知识 Docker Remote API 是一个取代远程命令行界面(rcli)的REST API,其默认绑定2375端口,如管理员对其配置不当可导致未授权访问漏洞。攻击者利用 docker client 或者 http 直接请求就可以…...

2023-08-13 LeetCode每日一题(合并两个有序数组)
2023-08-13每日一题 一、题目编号 88. 合并两个有序数组二、题目链接 点击跳转到题目位置 三、题目描述 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 …...

nbcio-boot升级springboot、mybatis-plus和JSQLParser后的LocalDateTime日期json问题
升级后,运行显示项目的时候出现下面错误 2023-08-12 10:57:39.174 [http-nio-8080-exec-3] [1;31mERROR[0;39m [36morg.jeecg.common.aspect.DictAspect:104[0;39m - json解析失败Java 8 date/time type java.time.LocalDateTime not supported by default: add Mo…...

「C/C++」C/C++搭建程序框架
✨博客主页何曾参静谧的博客📌文章专栏「C/C」C/C程序设计📚全部专栏「UG/NX」NX二次开发「UG/NX」BlockUI集合「VS」Visual Studio「QT」QT5程序设计「C/C」C/C程序设计「Win」Windows程序设计「DSA」数据结构与算法「File」数据文件格式 目录 1. 分离职…...
Android 内存泄漏
名词解释 内存泄漏:即memory leak。是指内存空间使用完毕后无法被释放的现象,虽然Java有垃圾回收机制(GC),但是对于还保持着引用, 该内存不能再被分配使用,逻辑上却已经不会再用到的对象,垃圾回…...


Android上的基于协程的存储框架
在Android上,经常会需要持久化本地数据,比如我们需要缓存用户的配置信息、用户的数据、缓存数据、离线缓存数据等等。我们通常使用的工具为SharePreference、MMKV、DataStore、Room、文件等等。通过使用现有的存储框架,结合协程,我…...

虚拟现实与增强现实技术的商业应用
章节一:引言 随着科技的不断发展,虚拟现实(Virtual Reality,简称VR)与增强现实(Augmented Reality,简称AR)技术正日益成为商业领域中的重要创新力量。这两种技术为企业带来了前所未…...

每日后端面试5题 第六天
1. Java中有几种类型的流 字符流、字节流 输入流、输出流 节点流、处理流 2 .Spring支持的几种bean的作用域 五种: 1.singleton bean在每个ioc容器中只有一个实例 2.prototype 可以有多个实例 3-5在web环境中才生效 3.request 每次请求才创建bean 4.se…...

LeetCode150道面试经典题-- 两数之和(简单)
1.题目 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你可以按任意…...
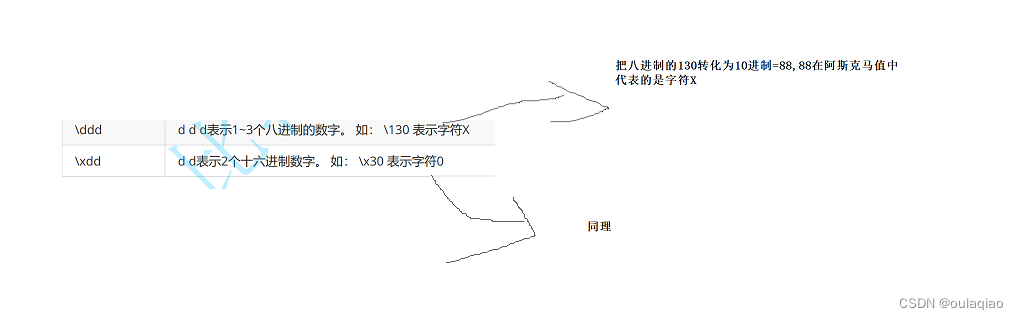
转义字符\
转移字符,就是通过字符,来转变原来字符的意思 常见的转义字符: 1、 2 注:" 的作用和他是类似的 3 4、 当打印\a时,电脑会出现一个警告,蜂鸣的声音 5、 阿斯克码表...
什么是DNS欺骗及如何进行DNS欺骗
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、什么是 DNS 欺骗?二、开始1.配置2.Ettercap启动3.操作 总结 前言 我已经离开了一段时间,我现在回来了,我终于在做一个教…...
Android核心开发之——OpenGL
OpenGL是一种用于编程计算机图形的应用程序编程接口(API)。它提供了一系列函数和方法,用于绘制2D和3D图形,以及进行渲染和图形处理。OpenGL可以跨平台使用,支持各种操作系统和硬件设备。它被广泛应用于游戏开发、虚拟现…...

公共服务领域:西安新小区业主自立业主委员会年底分红83万以及103万事件区块链资金透明监管与投票解决方案的尝试
公共服务领域:西安新小区业主自立业主委员会年底分红83万以及103万事件区块链资金透明监管与投票解决方案的尝试 作者 重庆电子工程职业学院 | 向键雄 杜小敏 前言 本项目想法来源于,西安新小区业主开出物业自立业主委员会年底分红83万以及103万事件,对于此类事件,我们刨…...

ID3 决策树
西瓜数据集D如下: 编号色泽根蒂敲声纹理脐部触感好瓜1青绿蜷缩浊响清晰凹陷硬滑是2乌黑蜷缩沉闷清晰凹陷硬滑是3乌黑蜷缩浊响清晰凹陷硬滑是4青绿蜷缩沉闷清晰凹陷硬滑是5浅白蜷缩浊响清晰凹陷硬滑是6青绿稍蜷浊响清晰稍凹软粘是7乌黑稍蜷浊响稍糊稍凹软粘是8乌黑稍蜷浊响清晰…...

NVIDIA Profile Inspector终极指南:解锁显卡隐藏性能的3个简单步骤
NVIDIA Profile Inspector终极指南:解锁显卡隐藏性能的3个简单步骤 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否觉得NVIDIA官方控制面板的设置选项太过有限?是否想要为…...

ROS机械臂集成六维力传感器的Gazebo仿真实践
1. 六维力传感器与Gazebo仿真基础 六维力传感器是机器人领域的重要感知器件,能够同时测量三个方向的力和三个方向的力矩。在机械臂应用中,它通常被安装在末端执行器附近,用于实现力控操作、碰撞检测等高级功能。Gazebo作为ROS生态中最常用的物…...

【独家解密】AIAgent因果推理模块的7个隐藏设计陷阱:92%的团队在第3层就埋下不可逆逻辑漏洞
第一章:因果推理模块在AIAgent架构中的核心定位与演进脉络 2026奇点智能技术大会(https://ml-summit.org) 在传统AI代理(AIAgent)架构中,决策逻辑长期依赖统计相关性建模,导致行为可解释性弱、反事实推断缺失及环境扰…...

Qwen2.5-7B-Instruct优化升级:高效模型缓存机制,大幅提升对话响应速度
Qwen2.5-7B-Instruct优化升级:高效模型缓存机制,大幅提升对话响应速度 1. 引言:大模型本地化部署的挑战 在本地化部署大型语言模型时,开发者常常面临两个核心挑战:显存占用过高和响应速度缓慢。特别是对于7B参数规模…...
)
别再只盯着代码了!手把手带你读懂东南大学轴承故障数据集(含8通道信号含义详解)
东南大学轴承故障数据集深度解析:从传感器信号到故障诊断实战 在工业设备健康监测领域,轴承故障诊断一直是研究热点,而高质量的数据集是算法验证和模型训练的基础。东南大学发布的轴承故障数据集因其完整的工况覆盖和多通道信号采集ÿ…...

X-AnyLabeling3.2实战:从零部署到自定义模型自动标注
1. X-AnyLabeling3.2安装与环境配置 第一次接触X-AnyLabeling这个开源标注工具时,我就被它的自动标注功能吸引了。相比传统的手动标注,它能节省80%以上的时间。不过安装过程确实有些坑要避开,这里分享我的实战经验。 首先需要准备Anaconda环境…...
)
C复习13(排序算法)
#技术笔记1.冒泡排序这个排序要能自己直接敲出来,由于每一轮有交换,导致数据就像冒泡泡一样,冒到数组的末尾,所以叫做冒泡排序。冒泡排序稳定,时间复杂度O(n^2),空间复杂度O(1) (这里就给出一种代码,从小到大的排序顺序冒了,后面都是按从小到…...

beberlei/assert与Symfony/Zend验证器的深度对比:为什么选择轻量级方案
beberlei/assert与Symfony/Zend验证器的深度对比:为什么选择轻量级方案 【免费下载链接】assert Thin assertion library for use in libraries and business-model 项目地址: https://gitcode.com/gh_mirrors/ass/assert 在现代PHP开发中,数据验…...

如何利用数据库特性防注入_使用只读事务模式执行查询
不能。只读事务仅限制写操作,无法防御SQL注入,攻击者仍可执行SELECT、UNION、延时函数等恶意查询;防注入核心是参数化查询与最小权限账户配合。只读事务真能防 SQL 注入吗不能。只读事务 SET TRANSACTION READ ONLY 或 START TRANSACTION REA…...

LCD1602液晶显示屏指令实战指南:从基础到应用
1. LCD1602液晶显示屏基础入门 第一次接触LCD1602时,我完全被它简洁的外观和强大的功能吸引了。这块只有巴掌大小的屏幕,却能清晰显示32个字符,特别适合嵌入式系统的信息展示需求。记得当时为了在Arduino项目上显示温湿度数据,我毫…...