Tesseract用OpenCV进行文本检测
我没有混日子,只是辛苦的时候没人看到罢了
一、什么是Tesseract
- Tesseract是一个开源的OCR(Optical Character Recognition)引擎,OCR是一种技术,它可以识别和解析图像中的文本内容,使计算机能够理解并处理这些文本。
- Tesseract提供了丰富的配置选项和接口,使得开发者可以根据自己的需求和场景进行定制化和集成。
- 通过使用Tesseract,你可以将一张包含文字的图像(如扫描文档、照片或截屏)输入到引擎中,然后Tesseract会通过一系列的图像处理和模式识别技术来提取出图像中的文本信息。它将识别出的文本转换为可以被计算机编辑和搜索的文本内容。
简单来说,Tesseract是一个强大的OCR引擎,适用于将图像中的文字提取出来,并将其转换为计算机可处理的文本形式。它在许多领域和应用中被广泛使用,如扫描和数字化文档、自动化数据输入、图书馆和档案管理等。
传送门
二、创建开发环境
使用conda创建一个名字为openCV的开发环境
conda create -n openCV
引入openCV包
pip install opencv-python
引入pytesseract包
三、代码实战
检测图片中的字符串并打印
先准备一张如下格式的图片

编写代码解析
testDectection.py
import cv2
import pytesseractimg = cv2.imread('1.png') # 使用opencv将图片读进来
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 将图片的颜色通道格式由BGR转化成pytesseract能识别的RGB格式
print(pytesseract.image_to_string(img)) # 调用pytesseract引擎将图片中的内容输出出来
cv2.imshow('result', img) # 显示
cv2.waitKey(0)输出

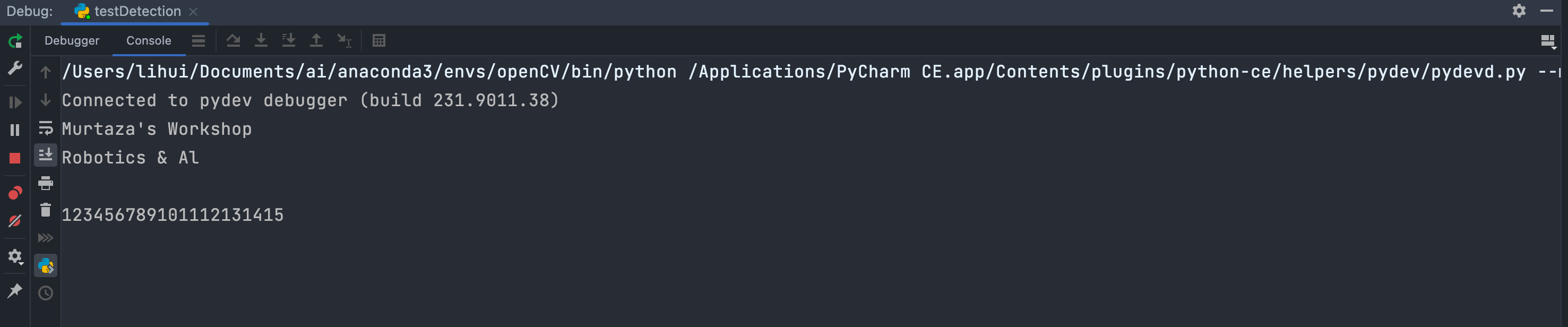
以上就是通过使用pytesseract简单获取图像原始信息的方法。
检测图中的字符并用红框标注
代码
import cv2
import pytesseractimg = cv2.imread('1.png') # 使用opencv将图片读进来
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 将图片的颜色通道格式由BGR转化成pytesseract能识别的RGB格式# Detecting Characters
hImg, wImg, _ = img.shape # 找出图片的宽度和高度
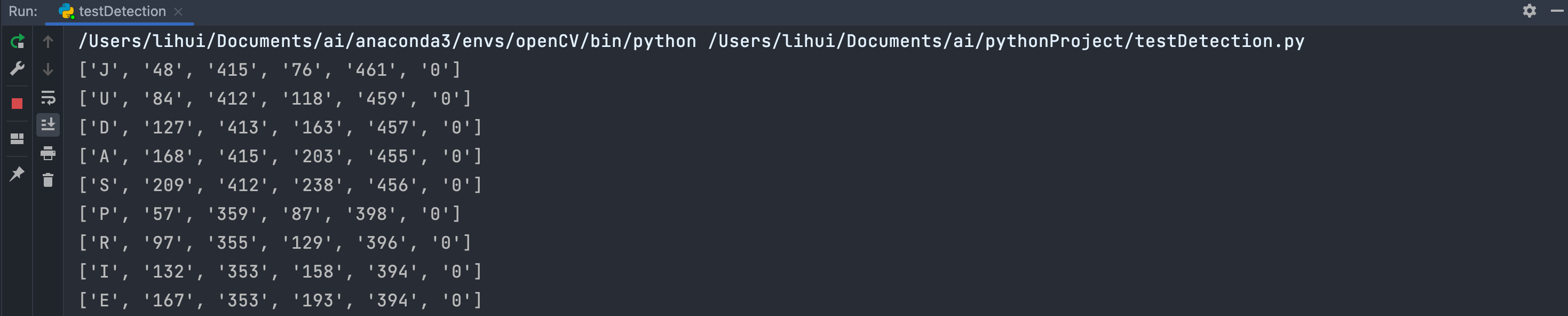
boxes = pytesseract.image_to_boxes(img) # 使用pytesseract找出图片中字符的坐标位置
for c in boxes.splitlines():c = c.split(' ')print(c)x, y, w, h = int(c[1]), int(c[2]), int(c[3]), int(c[4])cv2.rectangle(img, (x, hImg - y), (w, hImg - h), (0, 0, 255), 3) # 使用opencv画框框,使用红色,厚度为3cv2.imshow('result', img) # 显示
cv2.waitKey(0)输入两张图片
1.png

2.png

输出
每一个检测出来字符串的坐标


图像中添加识别的文本内容
import cv2
import pytesseractimg = cv2.imread('1.png') # 使用opencv将图片读进来
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 将图片的颜色通道格式由BGR转化成pytesseract能识别的RGB格式# Detecting Characters
hImg, wImg, _ = img.shape # 找出图片的宽度和高度
boxes = pytesseract.image_to_boxes(img) # 使用pytesseract找出图片中字符的坐标位置
for c in boxes.splitlines():c = c.split(' ')print(c)x, y, w, h = int(c[1]), int(c[2]), int(c[3]), int(c[4])cv2.rectangle(img, (x, hImg - y), (w, hImg - h), (0, 0, 255), 3) # 使用opencv画框框,使用红色,厚度为3cv2.putText(img, c[0], (x, hImg - y + 25), cv2.FONT_HERSHEY_COMPLEX, 1, (50, 50, 255), 2) # 向图像中添加文本cv2.imshow('result', img) # 显示
cv2.waitKey(0)关键
cv2.putText(img, c[0], (x, hImg - y + 25), cv2.FONT_HERSHEY_COMPLEX, 1, (50, 50, 255), 2)
这行代码使用OpenCV库中的putText函数向图像中添加文本。
解释如下:
img:表示要添加文本的图像。c[0]:表示要添加的文本内容,c[0]可能是一个字符串变量,用于指定要添加的文本。(x, hImg - y + 25):表示文本的起始位置,该位置是一个元组(x, y),其中x表示文本的横坐标,hImg - y + 25表示文本的纵坐标。hImg可能是整个图像的高度,y是用于定位白色文本的轮廓的顶端位置的变量。通过hImg - y + 25可以使文本出现在轮廓下方一些距离的位置。cv2.FONT_HERSHEY_COMPLEX:表示所使用的字体类型,这里使用的是复杂的字体类型。1:表示文本的字体缩放因子,1表示原始大小。(50, 50, 255):表示文本的颜色,该颜色为一个元组(B, G, R),其中B、G、R分别表示蓝色、绿色、红色通道的值。在这个例子中,文本颜色是一种深红色。2:表示文本的线宽,即文本边框的宽度。这里设置为2,使得文本边框较粗。
输出

检测连续的字符串
实际中一般不关注一个字符,更多是关注连起来的字符串
import cv2
import pytesseractimg = cv2.imread('1.png') # 使用opencv将图片读进来
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 将图片的颜色通道格式由BGR转化成pytesseract能识别的RGB格式# Detecting Characters
hImg, wImg, _ = img.shape # 找出图片的宽度和高度
boxes = pytesseract.image_to_data(img) # 使用pytesseract找出图片中字符的坐标位置
for x, c in enumerate(boxes.splitlines()):if x != 0:c = c.split()print(c)if len(c) == 12:x, y, w, h = int(c[6]), int(c[7]), int(c[8]), int(c[9])cv2.rectangle(img, (x, y), (x + w, h + y), (0, 0, 255), 3) # 使用opencv画框框,使用红色,厚度为3cv2.putText(img, c[11], (x, y), cv2.FONT_HERSHEY_COMPLEX, 1, (50, 50, 255), 2) # 向图像中添加文本cv2.imshow('result', img) # 显示
cv2.waitKey(0)
输出
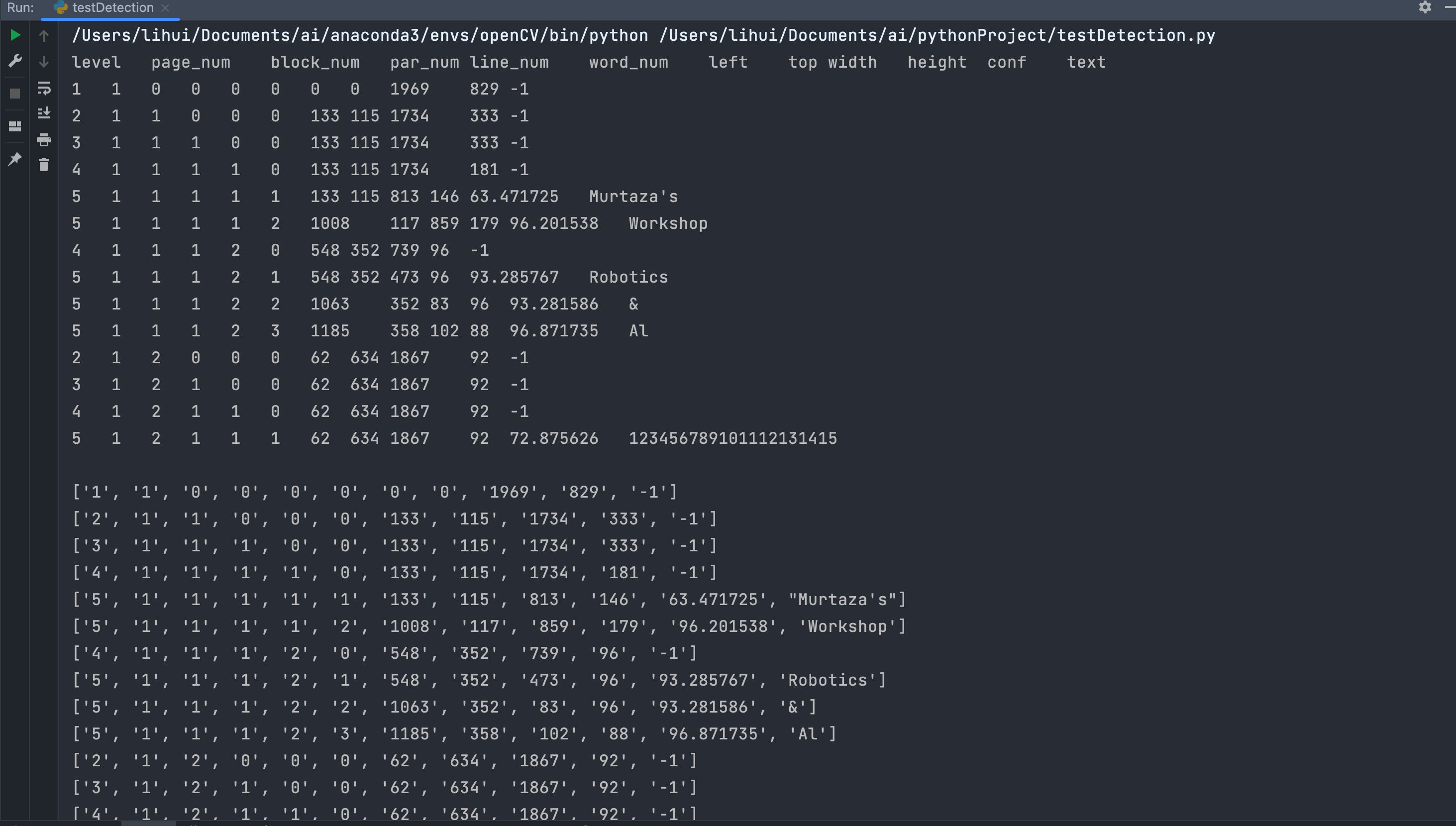
每个字段的含义:
level:代表文本在页面中的级别。这里的级别是从1开始的,表示文本的嵌套层级。page_num:代表文本所在的页码。在多页文档中,每一页都有一个唯一的页码。block_num:代表文本所在的文本块的编号。文本块是文档中的一个矩形区域,包含多个段落或行。par_num:代表文本所在的段落的编号。段落是文档中的一个文本段落,通常由一组相关的句子组成。line_num:代表文本所在行的编号。行通常是段落中的一个文本行。word_num:代表文本所在单词的编号。单词是文本的最小单位,通常由一个或多个字符组成。left:代表文本区域的左边界相对于页面的位置。top:代表文本区域的上边界相对于页面的位置。width:代表文本区域的宽度。height:代表文本区域的高度。conf:代表文本的置信度,通常在0到100之间。置信度表示OCR算法对所识别文本的可信程度。text:代表识别出的文本内容。

只识别图片中的数字
import cv2
import pytesseractimg = cv2.imread('1.png') # 使用opencv将图片读进来
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 将图片的颜色通道格式由BGR转化成pytesseract能识别的RGB格式# Detecting Characters
hImg, wImg, _ = img.shape # 找出图片的宽度和高度
cong = r'--oem 3 --psm 6 outputbase digits'
boxes = pytesseract.image_to_data(img, config=cong) # 使用pytesseract找出图片中字符的坐标位置
for x, c in enumerate(boxes.splitlines()):if x != 0:c = c.split()print(c)if len(c) == 12:x, y, w, h = int(c[6]), int(c[7]), int(c[8]), int(c[9])cv2.rectangle(img, (x, y), (x + w, h + y), (0, 0, 255), 3) # 使用opencv画框框,使用红色,厚度为3cv2.putText(img, c[11], (x, y), cv2.FONT_HERSHEY_COMPLEX, 1, (50, 50, 255), 2) # 向图像中添加文本cv2.imshow('result', img) # 显示
cv2.waitKey(0)
重点
cong = r'--oem 3 --psm 6 outputbase digits'
boxes = pytesseract.image_to_data(img, config=cong)
参数解释:
oem是一个参数,用于指定OCR引擎的OCR引擎模式(OCR Engine Mode)。OCR引擎模式控制Tesseract在文本识别过程中的行为和算法。psm是一种页分割模式(Page Segmentation Mode),用于指定OCR引擎在识别文本时如何处理页面布局和分割问题。psm参数控制Tesseract在识别文本时如何将图像分割为单个字符、单词、行和文本块。

相关文章:
Tesseract用OpenCV进行文本检测
我没有混日子,只是辛苦的时候没人看到罢了 一、什么是Tesseract Tesseract是一个开源的OCR(Optical Character Recognition)引擎,OCR是一种技术,它可以识别和解析图像中的文本内容,使计算机能够理解并处理…...

XLua案例学习
下载 xlua 之后把 asset 文件中的全部文件粘贴到项目文件Asset文件下,将tool粘贴到 asset 同级目录下 然后把 HOTFIX_ENABLE 宏打开 之后 编辑 lua 脚本 更改源代码之后先 Generate Code 然后 HotFix inject in Editor 开发过程: 首先开发业务…...

Linux:Shell编程之免交互
目录 绪论 1、here Document免交互 1.1 格式 1.2 cat结合免交互实现重定向输出到指定文件 1.3 变量替换 2、Expect免交互 2.1 三种写法 3、免交互实现普通用户切换root 3.1 send_user 4、接收参数 5、嵌入执行模式 6、ssh远程登录 绪论 免交互:不需要人…...
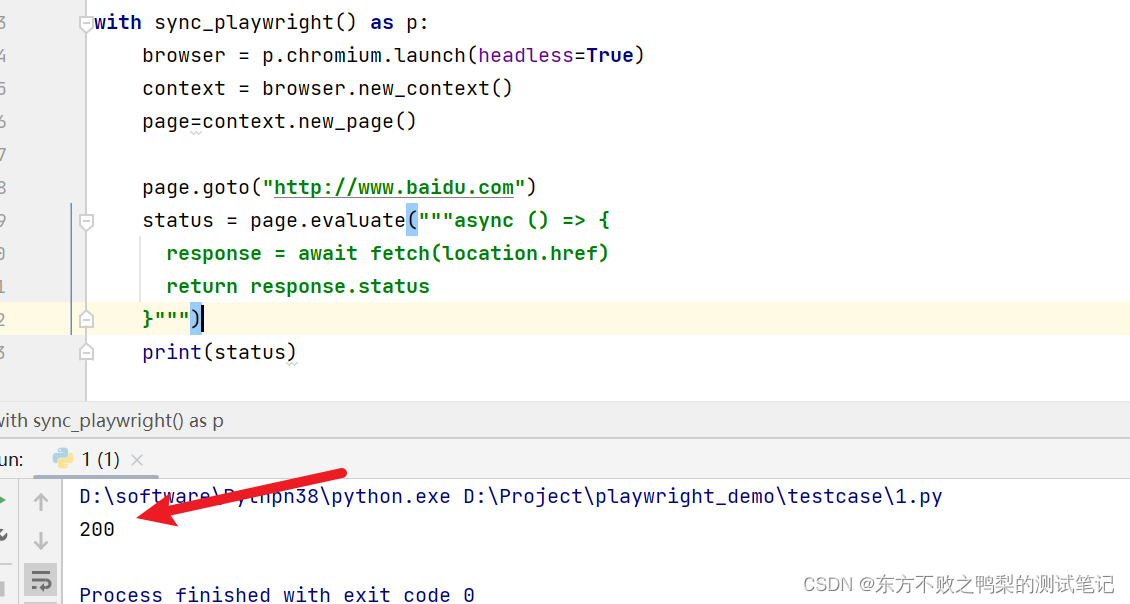
最强自动化测试框架Playwright(18)- 执行js脚本
page.evaluate() API 可以在网页上下文中运行 JavaScript 函数,并将结果带回 Playwright 环境。 href page.evaluate(() > document.location.href) 如果结果是 Promise 或函数是异步的,则计算将自动等待,直到解析…...

阿里云云主机_ECS云服务器_轻量_GPU_虚拟主机详解
阿里云云主机分为云虚拟主机、云服务器ECS、轻量应用服务器、GPU云服务器、弹性裸金属服务器、专有宿主机、FPGA云服务器、高性能计算E-HPC、无影云电脑等,阿里云百科来详细说下阿里云云主机详解: 目录 阿里云云主机 云服务器ECS 轻量应用服务器 云…...

[QT编程系列-41]:Qt QML与Qt widget 深入比较,快速了解它们的区别和应用场合
目录 1. Qt QML与Qt widget之争 1.1 出现顺序 1.2 性能比较 1.3 应用应用领域 1.4 发展趋势 1.5 QT Creator兼容上述两种设计风格 2. 界面描述方式的差别 3. QML和Widgets之间的一些比较 4. 选择QML和Widgets之间的Qt技术时,可以考虑以下几个因素ÿ…...

springboot 使用zookeeper实现分布式锁
一.添加ZooKeeper依赖:在pom.xml文件中添加ZooKeeper客户端的依赖项。例如,可以使用Apache Curator作为ZooKeeper客户端库: <dependency><groupId>org.apache.curator</groupId><artifactId>curator-framework</…...
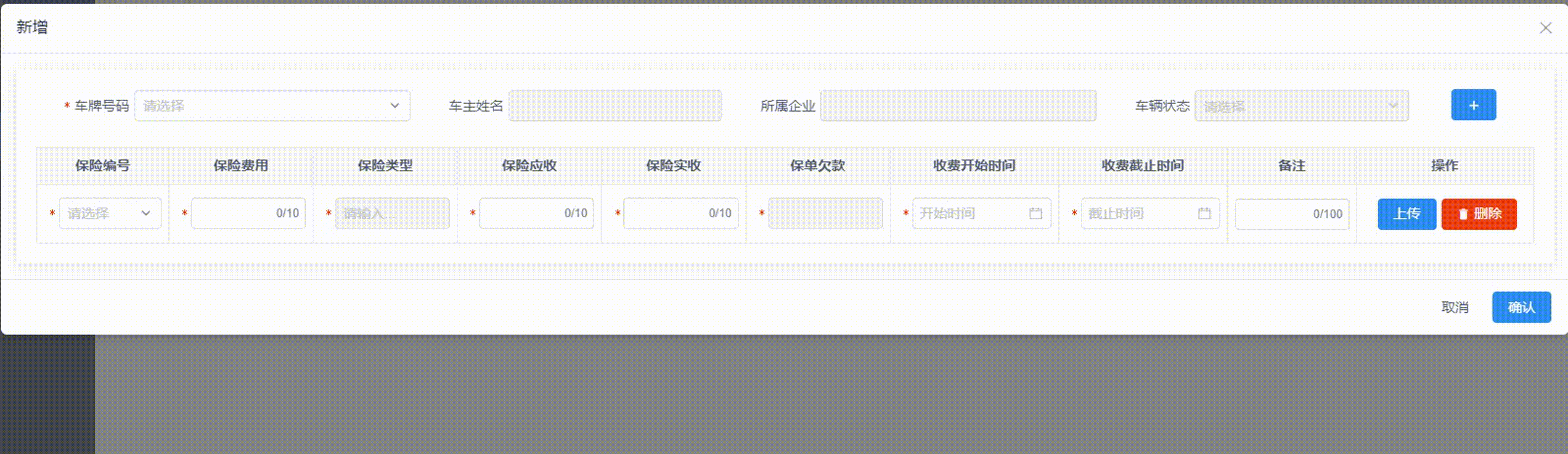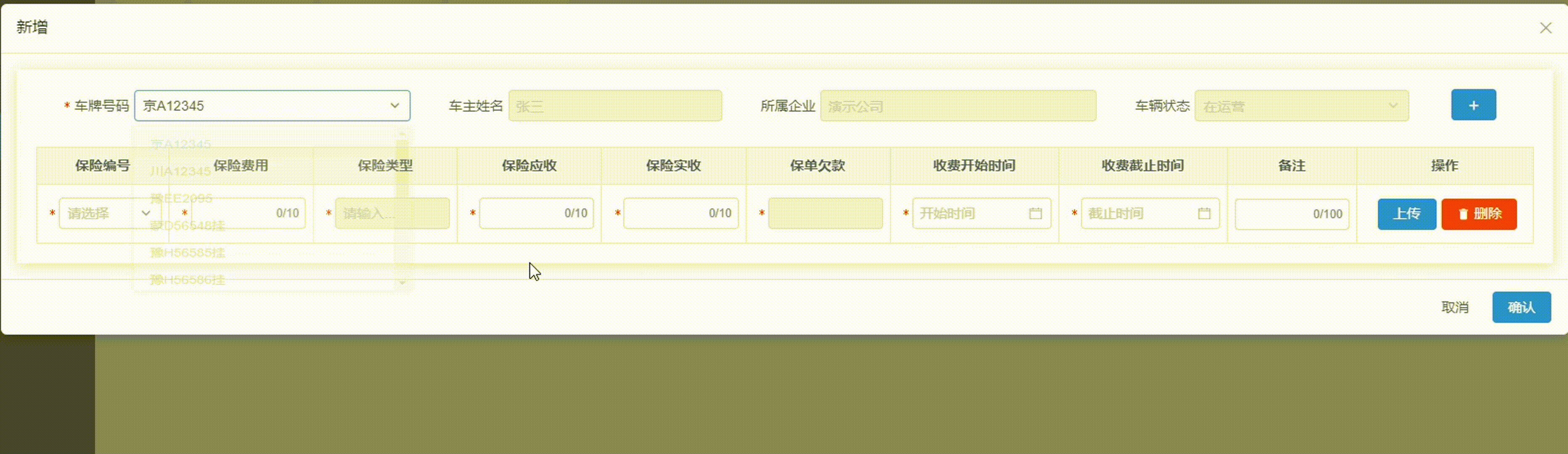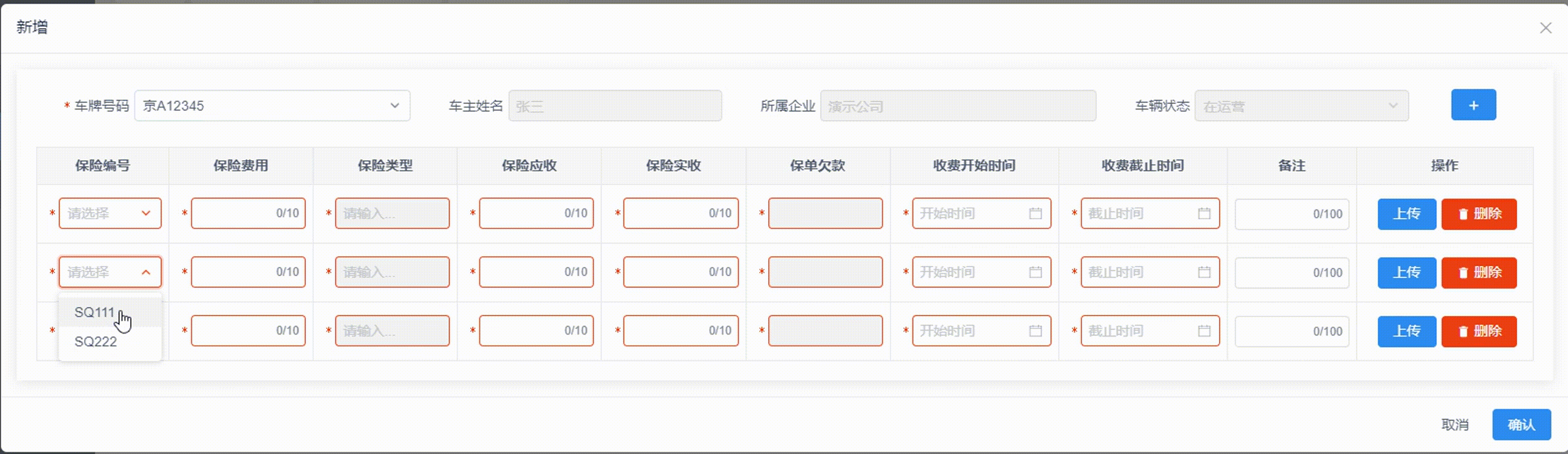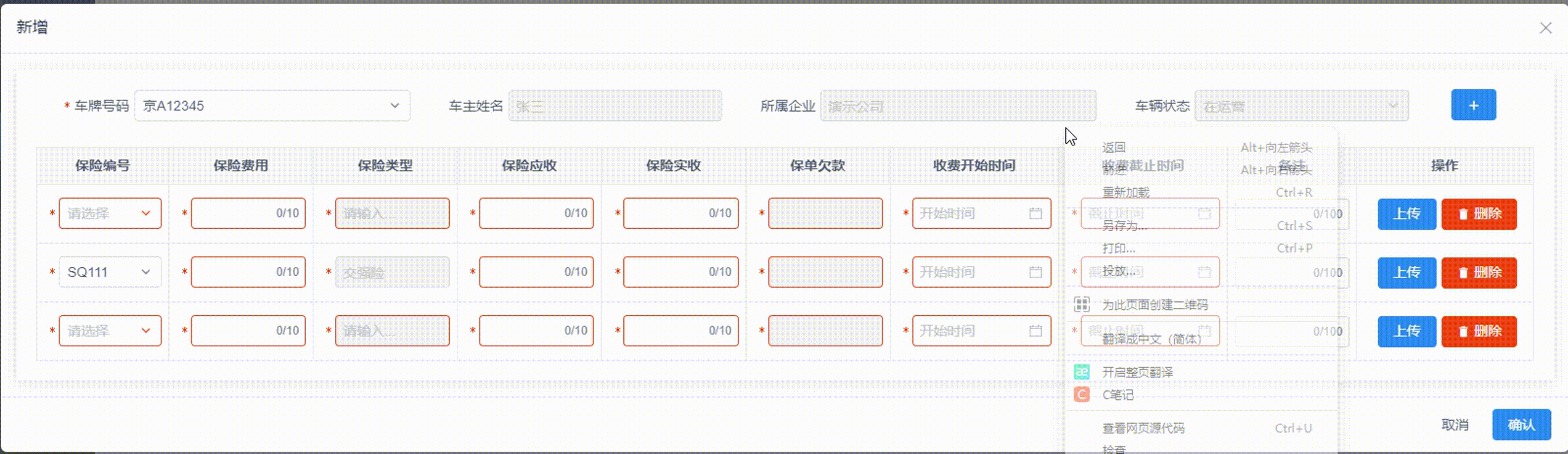
ViewUI表格Table嵌套From表单-动态校验数据合法性的解决方法
项目场景: 项目需求:在表格中实现动态加减数据,并且每行表格内的输入框,都要动态校验数据,校验不通过,不让提交数据,并且由于表格内部空间较小,我仅保留红边框提示,文字…...

服务器安装Tomcat
下载Tomcat 下载地址在这: Tomcat官网 下载完成以后把压缩包上传到服务器中(我传到了www/java),进行解压(解压到),如果没有进行指定解压到哪里,默认是到root文件夹中 tar -zxvf /www/java/apache-tomcat-9.0.103.tar.…...

【Apollo】自动驾驶的平台背景,平台介绍
作者简介: 辭七七,目前大一,正在学习C/C,Java,Python等 作者主页: 七七的个人主页 文章收录专栏: 七七的闲谈 欢迎大家点赞 👍 收藏 ⭐ 加关注哦!💖…...

docker 安装与配置
一、 环境准备 IP主机名操作系统版本docker版本192.168.168.128master01CentOS Linux release 7.9.2009 (Core)docker-20.10.15.tgz 二、安装 # 安装包获取 cd /root wget -c https://download.docker.com/linux/static/stable/x86_64/docker-20.10.15.tgz [rootmaster01 ~]…...
Titanic--细节记录三
目录 image sklearn模型算法选择路径图 留出法划分数据集 ‘留出’的含义 基本步骤和解释 具体例子 创造一个数据集 留出法划分 预测结果可视化 分层抽样 设置方法 划分数据集的常用方法 train_test_split 什么情况下切割数据集的时候不用进行随机选取 逻辑回归…...

k8s-----集群调度
目录 一:调度约束 二:Pod 启动创建过程 三:k8s调度过程 1、Predicate 有一系列的常见的算法 2、常见优先级选项 3、指定调度节点 (1)nodeName指定 (2)nodeSelector指定 四:亲和…...

01-Spark环境部署
1 Spark的部署方式介绍 Spark部署模式分为Local模式(本地模式)和集群模式(集群模式又分为Standalone模式、Yarn模式和Mesos模式) 1.1 Local模式 Local模式常用于本地开发程序与测试,如在idea中 1.2 Standalone模…...

HOT86-单词拆分
leetcode原题链接:单词拆分 题目描述 给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。 示例 1:…...

开源数据集分类汇总(医学,卫星,分割,分类,人脸,农业,姿势等)
本文汇总了医学图像、卫星图像、语义分割、自动驾驶、图像分类、人脸、农业、打架识别等多个方向的数据集资源,均附有下载链接。 该文章仅用于学习记录,禁止商业使用! 1.医学图像 疟疾细胞图像数据集 下载链接:http://suo.nz/2V…...

Linux:Firewalld防火墙
目录 绪论 1、firewalld配置模式 2、预定义服务:系统自带 3端口管理 绪论 firewalld 防火墙,包过滤防火墙,工作在网络层,centos7自带的默认的防火墙 作用是为了取代iptables 1、firewalld配置模式 运行时配置 永久配置 i…...

mysql死锁;锁表排查
概述 有时候提前终止了navicat执行线程,但是实际mysql还在执行这个线程, 需要通过mysql本身去终止. mysql:8.0 三板斧第一斧 捞点网上线程现成的执行命令 1.查询是否锁表 show OPEN TABLES where In_use > 0;2.查询进程(如果您有SUP…...
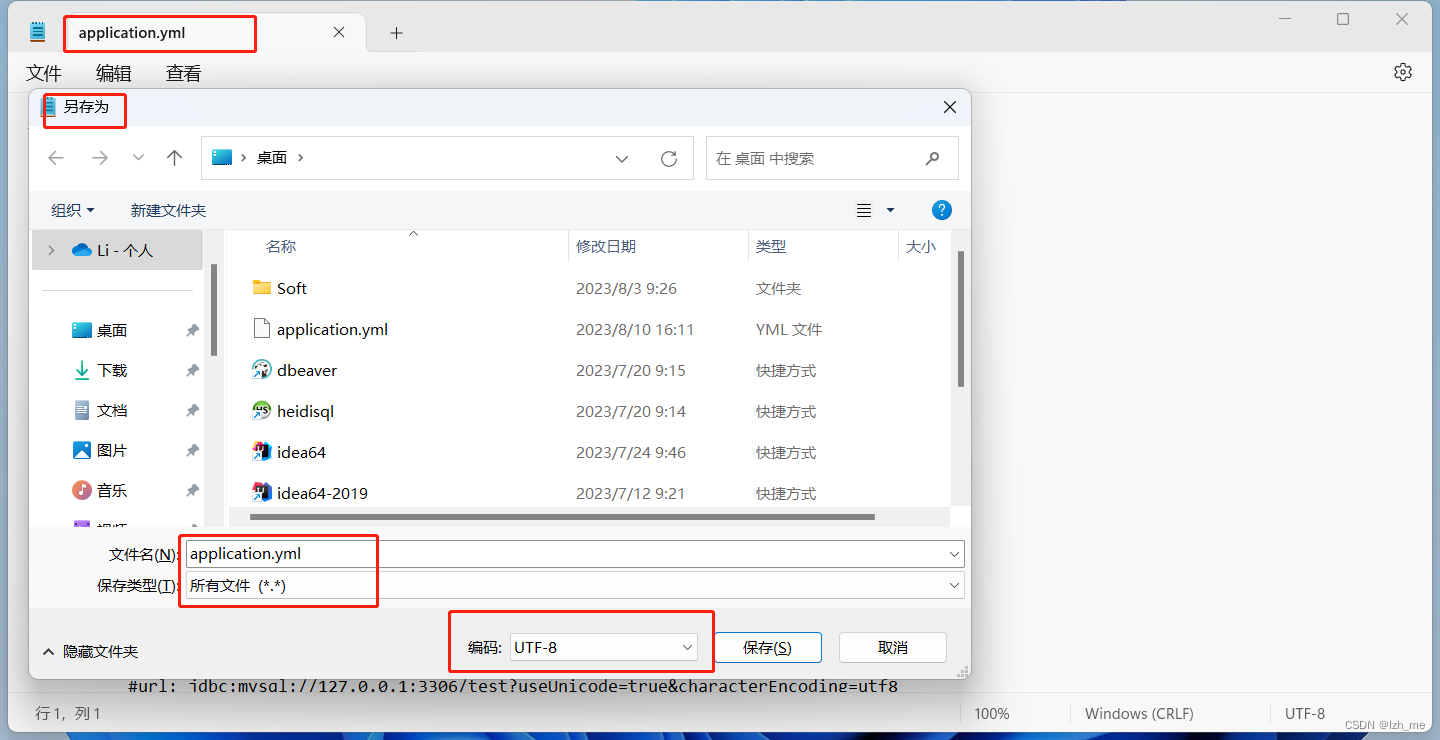
YAMLException: java.nio.charset.MalformedInputException: Input length = 1
springboot项目启动的时候提示这个错误:YAMLException: java.nio.charset.MalformedInputException: Input length 1 根据异常信息提示,是YAML文件有问题。 原因是yml配置文件的编码有问题。 需要修改项目的编码格式,一般统一为UTF-8。 或…...

无需求文档,保障测试质量的可行性做法
这篇文章,内容是:无需求文档的情况下,作为一个测试人员,应该如何做 ,才能保障测试质量不出问题,以及如何不背锅 ? 001 没有需求文档3种可能情况 : 1、公司都没产品经理࿰…...

基于GLM-4.7-Flash的Web安全漏洞检测系统
基于GLM-4.7-Flash的Web安全漏洞检测系统 1. 引言 在当今数字化时代,Web应用安全已成为企业和开发者面临的重要挑战。传统的安全检测工具往往需要复杂的配置和专业知识,让很多开发者望而却步。而随着AI技术的发展,我们现在有了更智能的解决…...

本硕毕业论文工具怎么选?实测高效组合方案推荐
一、热门专业论文工具榜单总览 从降重效果、降AI能力、学科适配度、性价比等核心维度实际体验筛选,目前主流实用的论文工具排名如下:排名工具名称核心专业能力综合评分1SpeedAI科研小助手精准降重降AI,全文格式零改动,适配全学科规…...

AI Agent开发为什么这么火:供需关系深度剖析
“钱景”是肯定有的,重点是怎么拿到offer。现在这行正处于爆发期,月薪3-4w很常见,搞得好年薪80万往上都有可能,大量高薪酬待遇岗都在招,我们这种中小厂都能给到40w税后。 不用太纠结学历,AI Agent是最近一两…...

Qwen3-ASR-1.7B快速体验:上传音频文件,秒出转写文本
Qwen3-ASR-1.7B快速体验:上传音频文件,秒出转写文本 1. 开箱即用的语音识别体验 想象一下,你只需要上传一段音频文件,几秒钟后就能得到准确的文字转写结果。这就是Qwen3-ASR-1.7B带来的神奇体验。作为阿里云通义千问团队开发的高…...

AIVideo效果展示:多风格视频生成作品,实测惊艳
AIVideo效果展示:多风格视频生成作品,实测惊艳 1. 开篇:AI视频创作的新纪元 想象一下,你只需要输入一个简单的主题,就能在几分钟内获得一部包含专业分镜、精美画面、自然配音和精准字幕的完整视频。这不是科幻电影中…...

大模型提取结构化JSON——生产级
目录 输出结构化符合预期的Json Phase 1: 提示工程约束 (Prompt Engineering) Phase 2: 原生协议控制 (Native Protocol Control) 深入浅出:如何用 Function Calling 提取结构化数据 第一步:把“提取动作”包装成一个“函数说明 (Schema)” 第二步:向大模型发起对话请…...

SGLang-v0.5.6环境配置全解析:从Python版本到模型路径设置
SGLang-v0.5.6环境配置全解析:从Python版本到模型路径设置 1. 环境准备:Python与系统配置 1.1 Python版本要求与验证 SGLang-v0.5.6需要Python 3.10或更高版本才能正常运行。这是因为它使用了Python 3.10引入的新语法特性,如结构化模式匹配等…...

精简GVCP与GVSP:FPGA实现GigE Vision相机高效采集的工程实践
1. 为什么需要精简GigE Vision协议? 第一次接触GigE Vision相机时,我被它复杂的协议栈吓了一跳。完整的GigE Vision协议包含几十种功能模块,光是协议文档就有上千页。但在实际工业视觉项目中,我们往往只需要最基础的三个功能&…...

Go语言的runtime.SetBlockProfile集成
Go语言作为一门高效、简洁的并发编程语言,其强大的运行时系统为开发者提供了丰富的性能分析工具。其中,runtime.SetBlockProfile是一个关键的功能,它能够帮助开发者捕获和分析程序中的阻塞事件,从而优化并发性能。本文将围绕这一功…...

Android应用集成:在移动端上传图片调用Ostrakon-VL-8B云服务
Android应用集成:在移动端上传图片调用Ostrakon-VL-8B云服务 你有没有想过,给你的手机应用加上一双“智能眼睛”?用户拍张照片,应用就能看懂图片里的内容,还能回答关于图片的各种问题。听起来像是科幻电影里的场景&am…...