Ceph Reef版本 RBD 性能测试:80万写IOPS(10节点、60个NVMe SSD)
2023-05-16 08:30 发表于上海
摘自:https://mp.weixin.qq.com/s/mKkPElmCktoZaRk0m0IbqA
1、背景
Ceph 社区最近冻结了即将发布的 Ceph Reef 版本,今天我们研究一下 Ceph Reef 版本在 10 个节点、60 个 NVMe 磁盘的集群上的 RBD 性能。
在确保硬件没有问题(NVMe 固件更新)后,Reef 能够保证约71GB/s的性能读取和25GB/s的性能写入(75GB/s 复制速度)。
对于小型随机 IO,Reef 提供了大约4.4M 随机读取 IOPS和800K 随机写入 IOPS(2.4M 复制速度)。
对于小型 4K 顺序同步写入,Reef 实现了低于 0.5 毫秒的平均延迟、低于 0.5 毫秒的 99% 延迟和低于 0.8 毫秒的 99.9% 延迟。
即使在商业硬件设备上执行 3 倍的同步复制,它也实现了低于 8 毫秒的最大延迟。
虽然 Reef 要比 Quincy 性能更佳,但我们也发现了一些小问题。
在 Reef 冻结期间,我们将研究这些问题,以帮助 Reef 成为迄今为止最好的 Ceph 版本。
2、介绍
在过去的几个 Ceph 版本中,Ceph 社区和 Red Hat 的 perf and scale 团队都进行了各种性能测试,以将以前的版本与我们新的预发布代码进行比较。
我们希望看到我们在性能改进的过程中没有再引入新的其他问题。
Pacific 和 Quincy 的发布对我们来说是一个比较完美的节点。因为我们通过版本的回归,并最终在发布之前确认了一些可能会有影响的问题。
捕获细微的性能问题是非常复杂的,并且当我们尝试将过去测试的结果与新结果进行比较时会变得更加困难。
在这过程中,发生了什么变化?是由于代码更改、硬件/软件架构更改还是其他原因造成的?
Performance-CI 在这里可用于尝试在问题发生时捕获问题,但它非常耗费资源,并且除非我们非常小心,否则很容易出现差错。
今天,我们将对 Quincy 和 Reef 进行简单的对比测试,我们将尝试以完全相同的方式在完全相同的硬件上进行测试,以使差异尽可能小。
3、集群设置
| Nodes | 10 x Dell PowerEdge R6515 |
| CPU | 1 x AMD EPYC 7742 64C/128T |
| Memory | 128GiB DDR4 |
| Network | 1 x 100GbE Mellanox ConnectX-6 |
| NVMe | 6 x 4TB Samsung PM983 |
| OS Version | CentOS Stream release 8 |
| Ceph Version 1 | Quincy v17.2.5 (built from source) |
| Ceph Version 2 | Reef 9d5a260e (built from source) |
所有节点都连接到同一台 Juniper QFX5200 交换机上,并通过单个 100GbE QSFP28 连接。同时我们部署了 Ceph 并使用 CBT (https://github.com/ceph/cbt/)启动了 fio 测试。
除非特别说明,否则每个节点都安装 6 个 OSD,同时 fio 运行 6 个 librbd 类型的进程。
基于英特尔的系统可以配置 "latency-performance" 以及 "network-latency" 来对系统进行调优。
这避免于 CPU C/P 状态转换带来延迟。基于 AMD Rome 的系统在这方面的调优并没有太大的改变,而且我们还没有确认 tuned 实际上限制了 C/P 状态转换,但是对于这些测试,tuned 配置文件仍然设置为 “network-latency”。
4、测试设置
CBT 需要针对所部署的 Ceph 集群调整几个参数。
首先,禁用 rbd 缓存,为每个 OSD 分配 8GB 内存,并在禁用 cephx 的情况下使用 msgr V2。
Fio 配置为首先使用大量写入预填充 RBD 卷,然后在 iodepth=128 下进行 3 次迭代测试(如下表所示),每次迭代 5 分钟。每个节点使用 6 个 fio 进程,总共使用 60 个 fio 进程,聚合 iodepth 为 7680。
一些后台进程,比如 scrub、deep scrub、pg autoscaling 和 pg balancing 会被禁用。
配置静态 16384 PG(高于通常推荐的数量)和 3x 副本的 RBD 池与每个 fio 进程 1 个 RBD 镜像一起使用。
| IO Size | Read | Write | RandRead | RandWrite |
| 4096 | X | X | X | X |
| 131072 | X | X | X | X |
| 4094304 | X | X | X | X |
5、最初的误导性结果
只要是多于单个 OSD 的集群,Ceph 会使用 crush 以伪随机方式存储数据。
虽然比较多的 PG 数量以及 PG 均衡可以帮助改善这一点,但总会有差异,一些 OSD 不可避免地需要比其他 OSD 花费更长的时间来完成他们的工作。
因此,在任何给定的时间内,集群性能通常会受到最慢或使用率最高的 OSD 的限制。这是每个 Ceph 运维人员都应该知道的事情。
我们为什么现在提出这个?在 Reef 冻结之后,我们恢复了用于 Quincy 测试的 CBT 配置,并开始运行一组新的测试。初步结果看起来相当不错。Quincy 的表现略低于预期,但与我们之前看到的相差不远 (https://ceph.io/en/news/blog/2022/rocksdb-tuning-deep-dive).。
然而,一旦我到达瓶颈,结果开始看起来有点意外。
Reef 正在使用新的 RocksDB 调优配置(https://ceph.io/en/news/blog/2022/rocksdb-tuning-deep-dive),并进行了深度测试。
当这些调优用在 Quincy 版本时,我们获得了很明显的性能改进,我们预计 Reef 版本也会有类似的改进。
在这些测试中,Reef 的表现并不比 Quincy 好,实际上也不比 Pacific 好多少。
我们运行了很多次对比测试,并试图梳理出可能解释差异的因素。
后来,我们意识到我们可能应该关注一下系统的指标。CBT 为每个测试运行一个 collectl 副本,并记录大量系统指标数据。
事实上,在运行的 RBD 和 RGW 测试之间,CBT 在长时间的测试过程中记录了超过 20GB 的指标数据。
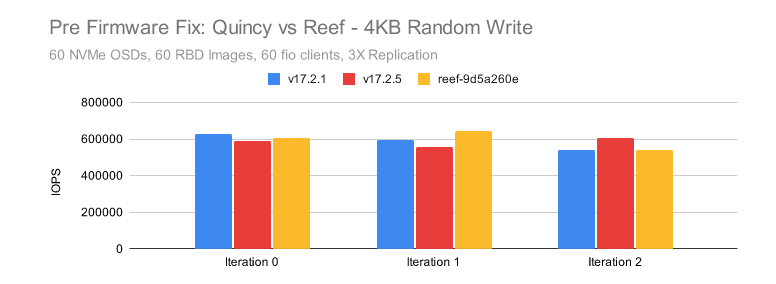
我们查看了系统中每个 NVMe 设备的性能指标。我们注意到,当第 10 个集群节点中的 nvme4 在大量写入测试中显示出较高的设备队列等待时间,但在读取测试中却没有。尤其是当在4KB 随机写入的时候,效果就更明显了:
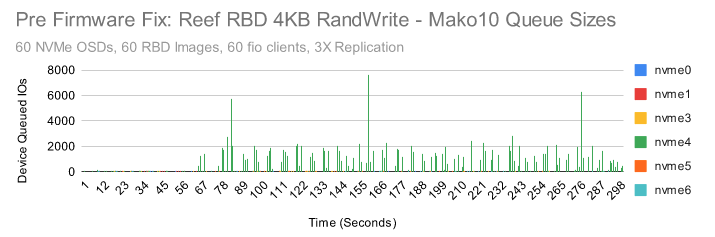
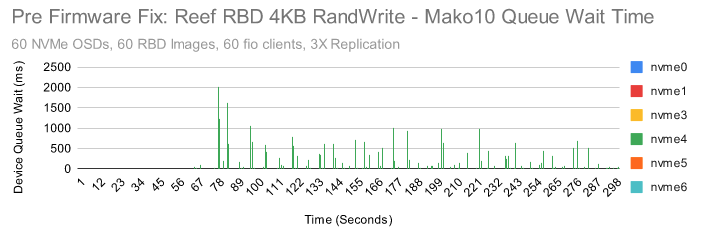
这些是 nvme4 上非常明显的延迟峰值,我们可以肯定这些与低于预期的性能有关。
这个 NVME 是目前发现的延迟最严重的一个,但其他节点中的一些 NVME 也显示出高于预期的延迟。
为了排除碎片的问题,我们对每个 NVME 进行完全安全擦除。
另外,在 Quincy 发布期间,我们从三星那里获得到了一个新的 NVME。
当我们将其安装替换到我们的集群上时,结果很明显。
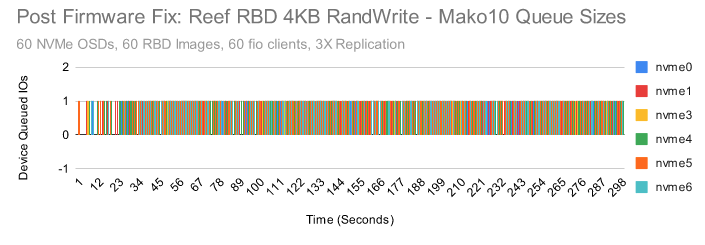
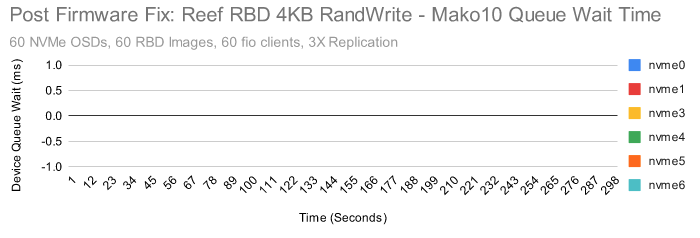
固件升级后,设备队列永远不会有超过一个 IO 等待,队列等待时间永远不会超过 0ms。
看起来固件更新解决了当前的问题,但它能够永久修复该问题吗?随着时间的推移,我们需要观察硬件的状态以确保是否永久修复了该问题。
出于本次测试的目的,我们恢复了集群到正常的性能。
另外,性能提升了多少?固件更新主要有助于 4KB 和 128KB 随机写入测试。
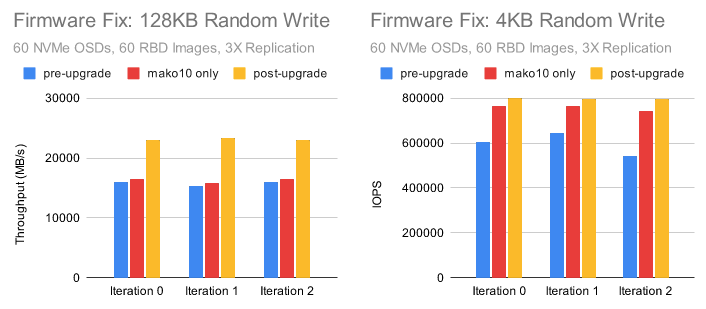
性能现在大致恢复到去年秋天在 RocksDB 调优测试中观察到的水平。
更重要的是,小型随机 IO 测试显示出非常一致的 NVMe 驱动器行为。
接下来我们将重新运行测试并进行一些对比。
6、4MB 连续吞吐量
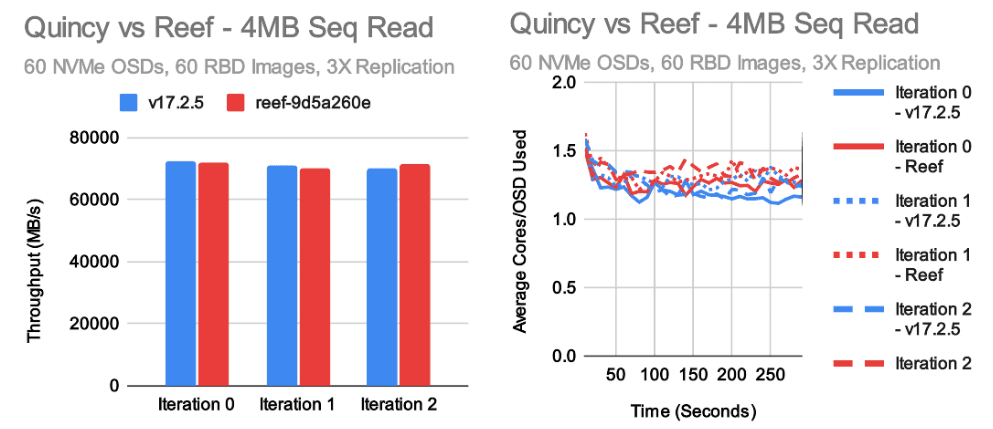
在大吞吐量测试中,Quincy 和 Reef 达到了大致相同的性能水平。
Reef 对于大量写入可能会快一点,而对于大量读取可能会慢一点。
在这两种情况下,底层集群都能够以大约 70-75GB/s 的速度执行,尽管因为我们正在进行 3X 复制,客户端可见写入吞吐量实际上约为 25GB/s。
在这些测试中,每个 OSD 的平均 CPU 消耗为 1-1.5 个核心用于读取和 3-4 个核心用于写入。
这种差异非常典型,因为 Ceph 的写入路径比读取路径更长。
7、4KB 随机 IOPS
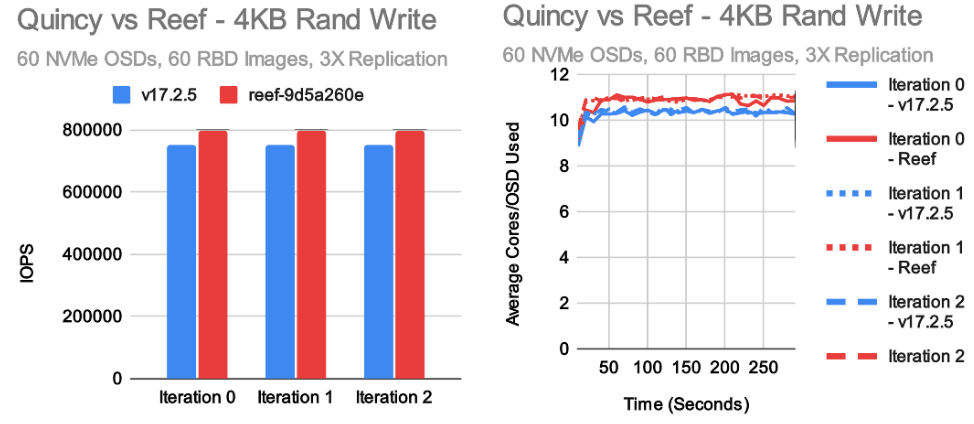
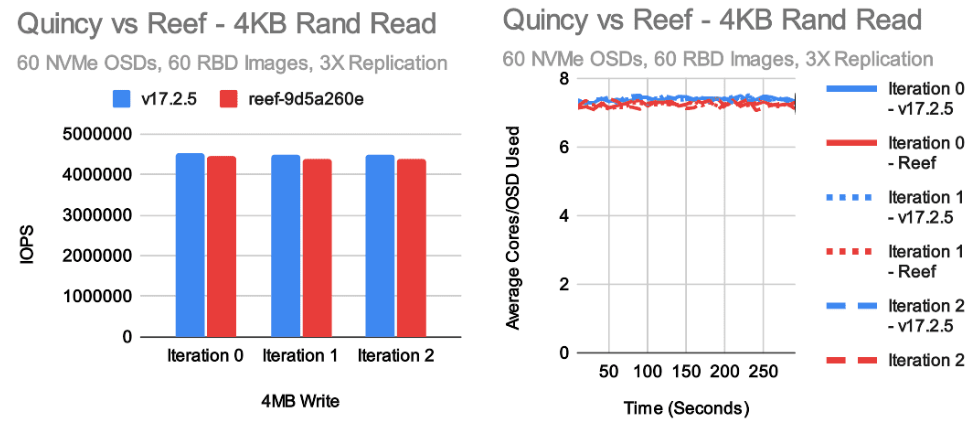
每个版本对我们来说最重要的测试是小型随机 IO 测试。
这些测试通过对 OSD 增加压力,从而确认 IO 的效率。
在这种情况下,我们总体上得到了相对较好的结果,但有几点需要注意。
在 4K 随机读取方面,Reef 仅比 Quincy 慢一点点,但非常接近。
另一方面,我们看到 4K 随机写入测试有了一定的改进,这主要是由于引入了新的 RocksDB 调优。
不过,根据去年秋天的结果,我们并没有看到像预期那样大的性能提升。在随机读取测试中,每个 OSD 的 CPU 使用率略高于 7 个内核,而在随机写入测试中,Reef 的每个 OSD 将近 11 个内核。这似乎与 Quincy 的更高性能成正比。
在测试 Ceph 的小的随机写入性能的时,加入拥有无限 CPU 资源,那么 kv_sync_thread 则会成为瓶颈,但 CPU 的消耗主要发生在 OSD 工作线程和信使线程中,因 CPU 造成的性能瓶颈场景还是比较少的。
因此,最大化写入性能是 OSD 数量、NVMe 速度、核心数量和核心速度之间的微妙平衡。
Reef 中的随机写入性能高于 Quincy,但没有我们希望的那么高。这是为什么?
还有两个额外的测试可能会提供一下原因。
就在我们冻结 Reef 之前,我们升级到最新版本的 RocksDB,因为与我们在 Quincy 中使用的旧版本相比有几个重大错误修复和改进。
我们可以简单地还原该更改,然后看看 Reef 的表现如何。
我们还可以使用我们现在在 Reef 中作为标准使用的 RocksDB 调优来运行 Quincy,看看它能在多大程度上提高 Quincy 性能。
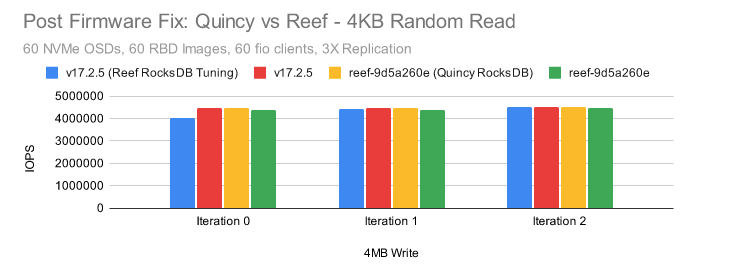
使用 Reef 调整在 v17.2.5 上运行特别慢之外,但非常接近。
当使用旧的 Quincy 版本的 RocksDB 编译 Reef 时,似乎确实有一致的性能提升,尽管很小(~2%)。
使用相同版本的 RocksDB 编译的 Quincy 和 Reef 则保持一致。
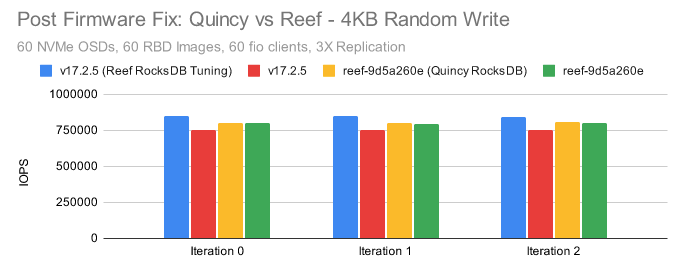
在随机写入场景中,我们看到两个非常有趣的结果。
一:当 Quincy 使用新的 RocksDB 调整默认值编译时,无论它使用哪个版本的 RocksDB,它实际上都比 Reef 快。
二:恢复到旧版本的 RocksDB 确实会带来性能提升,但同样非常小(~1-2%)。它不能完全解释当 Quincy 和 Reef 都使用新的 RocksDB 调优时出现的回归。
最终结果是 Reef 中很可能会出现小的回归,从而影响小的随机写入。
8、4KB 顺序同步写入延迟
在过去的一年里,我们收到了很多关于 Ceph 写入延迟的问题。
Ceph 可以进行 sub-millisecond 写入吗?我们看到什么样的尾延迟?
虽然我们过去对此进行过测试,但我们现在决定也进行一组快速的 4K 同步顺序写入测试。需要注意的是,这是在一个有大量可用空间和几乎零碎片的新集群上。
只有 1 个客户端在 io_depth 为 1 的情况下进行写入。
这几乎是展示 Ceph低延迟的理想场景。它不一定反映在有业务流量以及数据碎片的集群上的真实尾部延迟。
| Metric | O_DSYNC Quincy | O_SYNC Quincy | O_DSYNC Reef | O_SYNC Reef |
| Average Latency (ms) | 0.417 | 0.416 | 0.421 | 0.418 |
| 99% Latency (ms) | 0.465 | 0.461 | 0.465 | 0.469 |
| 99.9% Latency (ms) | 0.741 | 0.733 | 0.750 | 0.750 |
| Max Latency (ms) | 7.404 | 6.554 | 7.568 | 6.950 |
在这两种情况下,Quincy 和 Reef 都能够以低于 0.5 毫秒的延迟写入绝大多数 IO。
CBT 会为每次运行保存 fio 延迟图,因此我们也可以查看这些图:
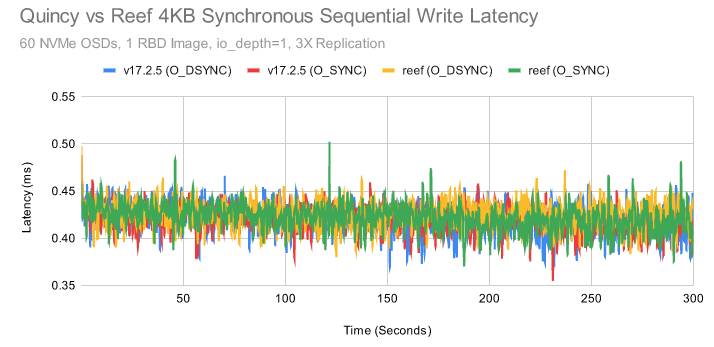
总体而言,结果非常一致,只有几个异常值。
这里需要注意的是,在 fio 中测试 librbd 时,使用 O_SYNC 和 O_DSYNC 标志可能没有太大区别。
我们联系了 Ilya Dryomov(Ceph 的 RBD 负责人)。他表示 librbd 或内核 RBD 都不需要关心,因为这些是在 VFS 层处理的。我们应该只在这些写入在所有参与的 OSD 上完全持久化后才寻求 OSD 的确认。无论如何,所有运行的性能似乎都相当。
在进行这些单客户端、io_depth=1 测试时,同时也需要关注一下网络的延迟。我们在集群中的不同节点之间进行了一些 ping 测试。
注意:ping 是 ICMP 而不是 TCP,而且 ping 也是往返的。
从 mako01 ping mako10(100GbE 接口):
| icmp_seq | Latency (ms) |
| 1 | 0.039 ms |
| 2 | 0.025 ms |
| 3 | 0.032 ms |
| 4 | 0.029 ms |
| 5 | 0.034 ms |
| 6 | 0.027 ms |
| 7 | 0.026 ms |
| 8 | 0.026 ms |
| 9 | 0.028 ms |
| 10 | 0.032 ms |
在读取的情况下,使用复制和使用 RBD 进行测试时,Ceph 仅有从客户端到主 OSD 的往返。
在写入情况下,Ceph 必须进行多次往返。1 个在客户端和主节点之间,1 个在主节点和并行的每个辅助节点之间。
在写测试中,我们应该可以看到有负载的节点的 2 次往返的平均网络延迟要更差。
因此,网络延迟很可能在这些小型同步写入测试中发挥重要作用(可能不是主导作用)。
Ceph 本身仍有改进同步写入延迟的空间,但是网络延迟在这一点上是一个有效的问题,并且随着 Ceph 本身的改进将成为一个更大的因素。
9、结论
这篇文章也是非常关注底层硬件性能和固件更新对 Reef 的影响。在进行基准测试时,了解底层硬件至关重要,如果我们没有升级所有 SSD 驱动器上的固件,我们会忽略掉很多东西(更高的写入 IOPS!)。
确保我们使用的固件是最新的,并且我们的硬件运行状态良好,然后再花一天时间运行测试。
一旦硬件处于良好的状态,Quincy 和 Reef 就会表现出差不多的性能。
两者都实现了大约 71GB/s 的大型读取和 25GB/s 的大型写入以及 3X 复制。两者还以大约 4.4-4.5M IOPS 实现了类似的 4KB 随机读取性能。
Reef 在小型随机写入方面比 Quincy 快 6-7%,这主要是由于新的 RocksDB 调整,但我们预计它会更快一些。
同时,可能还存在限制 Reef 实现更高性能的因素,我们后续将研究 Reef 冻结期间的潜在回归,并继续努力使 Reef 成为迄今为止最好的 Ceph 版本!
原文:https://ceph.io/en/news/blog/2023/reef-freeze-rbd-performance/
相关文章:
Ceph Reef版本 RBD 性能测试:80万写IOPS(10节点、60个NVMe SSD)
2023-05-16 08:30 发表于上海 摘自:https://mp.weixin.qq.com/s/mKkPElmCktoZaRk0m0IbqA 1、背景 Ceph 社区最近冻结了即将发布的 Ceph Reef 版本,今天我们研究一下 Ceph Reef 版本在 10 个节点、60 个 NVMe 磁盘的集群上的 RBD 性能。 在确保硬件没有…...
微信小程序调用map数据 并在wxml中对数组进行截取的操作
wxs文件的位置如图 实现数组截取 只保留五张图片 <wxs module"filter" src"./slicefunc.wxs"></wxs> <view class"wrap"><view class"search-box" bindtap"toSearch"><view class"v1"…...

前端项目打包
前端项目打包指的是将前端项目的源代码打包成一个或多个静态文件,以便于部署到服务器上,供用户访问。下面是一些常用的前端项目打包工具和打包步骤: 1、Webpack:Webpack 是一个强大的打包工具,可以将多个 JavaScript、…...

venv使用教程及pyvenv与python3-venv的区别
推荐使用python3-venv 原因:官方公告称——pyvenv自3.6 版本起弃用 原文:pyvenv 是针对 Python 3.3 和 3.4 创建虚拟环境的推荐工具,并在 Python 3.6 中被弃用。 Linux下创建虚拟环境(以Ubuntu为例) 首先安装依赖包 sudo apt-get instal…...

协程(一)单机--》并发--》协程
目录 一 协程的概述1.1 并行与并发1.2 线程1.3 新的思路1.4 Goroutine 二 第一个入门程序 一 协程的概述 我查看了网上的一些协程的资料,发现每个人对协程的概念都不一样,但是我认可的一种说法是:协程就是一种轻量级的线程框架(K…...

P1722 矩阵 II
题目背景 usqwedf 改编系列题。 题目描述 如果你在百忙之中抽空看题,请自动跳到第六行。 众所周知,在中国古代算筹中,红为正,黑为负…… 给定一个12n 的矩阵(usqwedf:这不是一个 2n 的队列么ÿ…...

【数据结构】树和二叉树的概念及结构
1.树概念及结构 1.1树的概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。 有一个特殊的结点&#…...

8.1.tensorRT高级(3)封装系列-模型编译过程封装,简化模型编译代码
目录 前言1. 模型编译过程封装2. 问答环节总结 前言 杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。 本次课程学习 tensorRT 高级-模型编译过程封装…...

化工行业案例 | 甄知科技助力万华化学重构IT服务价值,打造信息中心ERP!
随着科技的发展,新材料的应用领域与日俱增,近年来,全球化工新材料产业发展整体步入高技术引领、产品迭代速度快、产业规模和需求不断扩大的阶段。一体化协同与数字化转型策略是实现化工新材料生产原料自给、节能降耗、降低排放和物料成本的重…...
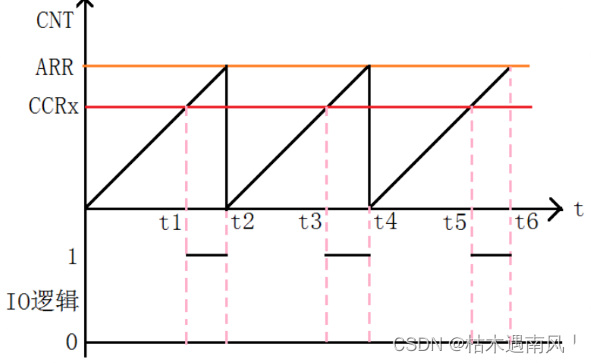
day6 STM32时钟与定时器
STM32时钟系统的概述 概念 时钟系统是由振荡器(信号源)、定时唤醒器、分频器等组成的电路。 常用的信号有晶体振荡器和RC振荡器。 意义 时钟是嵌入式系统的脉搏,处理器内核在时钟驱动下完成指令执行,状态变换等动作ÿ…...

【JavaEE进阶】SpringBoot 配置文件
文章目录 SpringBoot配置文件1. 配置文件的作用2. 配置文件的格式3. properties 配置文件说明3.1 properties 基本语法3.2 读取配置文件3.3 properties 优缺点分析 4. yml配置文件说明4.1 yml 基本语法4.2 yml 配置读取 5. properties和yml的对比 SpringBoot配置文件 1. 配置文…...

ResNet创新点总结
ResNet(Residual Networks)是深度学习中的一个重要架构,其创新点主要体现在解决了深层神经网络训练中的梯度消失和梯度爆炸问题,从而使得可以构建更深的神经网络。以下是 ResNet 的创新点总结: 1. 残差连接&#x…...
Scratch 之 3D 介绍及教程
第一章 为什么 3D 很难? 1.1 3D 难在何处? 3D 之所以会使我们觉得困难,是因为 Scratch 软件只有两个坐标轴,既:X轴、Y轴。 2维坐标系 而 3D 却拥有三个坐标轴: 3维坐标系 怎么办?很简单&…...

最强自动化测试框架Playwright(19)- 事件
Playwright允许收听网页上发生的各种类型的事件,例如网络请求,创建子页面,专用工作人员等。有几种方法可以订阅此类事件,例如等待事件或添加或删除事件侦听器。 等待事件 大多数情况下,脚本需要等待特定事件的发生。…...

静态网页和动态网页区别
1,静态网页和动态网页有何区别 1) 更新和维护 静态网页内容一经发布到网站服务器上,无论是否有用户访问,这些网页内容都是保存在网站服务器上的。如果要修改网页的内容,就必须修改其源文件,然后重新上传到服务器上。…...

美国服务器有哪些类型?
美国服务器有哪些类型?常见的服务器可分为虚拟主机、云服务器、物理服务器以及高防服务器,在海外服务器之中,使 用较多的属于美国服务器,下面我们就一起看看美国服务器有哪些及常见的美国服务器。 美国服务器有哪些? 与服务器一样&am…...

【基因检测人工智能】如何使用JAVASCRIPT在HTML文档内部增加一个段落
【基因检测人工智能】如何使用JAVASCRIPT在HTML文档内部增加一个段落 目的:采用JAVASCRIPT在一个HTML网页中增加一个段落。 下面是原来的HTML代码部分: <!DOCTYPE html> <html lang"zh-Hans"><head><meta charset&quo…...

unittest单元测试
当你在编写测试用例时,可以使用Python内置的unittest模块来进行单元测试。下面是一个逐步指南,帮助你理解如何编写和运行基本的单元测试。 导入必要的模块: 首先,你需要导入unittest模块和需要测试的模块(例如…...
每天一道leetcode:72. 编辑距离(动态规划困难)
今日份题目: 给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。 你可以对一个单词进行如下三种操作: 插入一个字符 删除一个字符 替换一个字符 示例1 输入:word1 "horse", word…...

详细介绍如何使用 OpenCV 对图像进行锐化
将了解锐化图像的过程,我们将使用内核来突出显示每个特定像素并增强其发出的颜色。它与模糊过程非常相似,只不过现在我们不是创建一个内核来平均每个像素强度,而是创建一个内核,该内核将使像素强度更高,因此对人眼来说更加突出。 了解流程的后端。 很高兴知道内核用于模糊…...
)
新手别怕!用嘉立创EDA两层板搞定ESP8266最小系统PCB(附完整工程文件)
从零开始:用嘉立创EDA轻松打造ESP8266最小系统PCB 第一次打开PCB设计软件时,那种手足无措的感觉我至今记忆犹新。密密麻麻的元件符号、复杂的布线规则、各种专业术语...作为一个刚接触硬件的爱好者,我曾一度怀疑自己是否真的能独立完成一块电…...

# 上海第一次带宠物去洗护,怎么避免被坑和乱剪毛?
在上海养宠,洗护是绕不开的刚需。尤其是第一次带毛孩子去店里,很多铲屎官心里都打鼓:怕价格不透明,怕美容师手重,更怕“一言不合就剃光”。这里整理了几个大家最关心的问题,帮你理清思路,少踩坑…...

塞尔达传说旷野之息存档编辑器:终极免费修改工具使用指南
塞尔达传说旷野之息存档编辑器:终极免费修改工具使用指南 【免费下载链接】BOTW-Save-Editor-GUI A Work in Progress Save Editor for BOTW 项目地址: https://gitcode.com/gh_mirrors/bo/BOTW-Save-Editor-GUI BOTW-Save-Editor-GUI是一款专为《塞尔达传说…...

Cogito 3B镜像免配置教程:预置中文Prompt Engineering最佳实践库
Cogito 3B镜像免配置教程:预置中文Prompt Engineering最佳实践库 1. 快速了解Cogito 3B模型 Cogito v1预览版是Deep Cogito推出的混合推理模型系列,这个3B版本在大多数标准基准测试中都表现出色,超越了同等规模下最优的开源模型。这意味着即…...

Windows与Office激活革命:KMS_VL_ALL_AIO智能解决方案深度解析
Windows与Office激活革命:KMS_VL_ALL_AIO智能解决方案深度解析 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾为Windows系统或Office办公软件那恼人的"需要激活"…...

别再只用XML-RPC了!Odoo 18里用Python requests库调用JSON-RPC接口的完整指南
别再只用XML-RPC了!Odoo 18里用Python requests库调用JSON-RPC接口的完整指南 在Odoo集成开发领域,XML-RPC长期以来都是开发者首选的通信协议。但当我们进入Odoo 18时代,JSON-RPC凭借其轻量级、易解析的特性正在成为更优选择。本文将带你全面…...

Verilog数组操作实战:从基础到高级赋值技巧
1. Verilog数组基础:从零开始理解硬件数据结构 第一次接触Verilog数组时,我完全被那些方括号搞晕了。直到在项目中真正用上数组,才发现它简直是硬件描述语言中的瑞士军刀。简单来说,Verilog数组就是一组整齐排列的数据盒子&#x…...

基于分布式ADMM算法与碳排放交易的最优潮流调度研究:MATLAB与CPLEX GUROBI仿真实现
MATLAB代码:基于分布式ADMM算法的考虑碳排放交易的电力系统优化调度研究 关键词:分布式调度 ADMM算法 交替方向乘子法 碳排放 最优潮流 仿真平台:MATLABCPLEX/GUROBI平台 主要内容:代码主要做的是一个考虑碳排放交易的最优潮流问…...

LLM应用卡在RAG瓶颈?2026奇点大会首发“动态向量化引擎”已商用,附3个生产级部署模板
第一章:2026奇点智能技术大会:大模型向量数据库 2026奇点智能技术大会(https://ml-summit.org) 大模型与向量数据库的协同演进 在2026奇点智能技术大会上,核心议题聚焦于大语言模型(LLM)与向量数据库的深度耦合机制。…...
)
中小企业必看:Gemma 4 企业级私有化部署全流程(避坑指南)
中小企业必看:Gemma 4 企业级私有化部署全流程(避坑指南) 前言 对中小企业来说,AI大模型不用追求“参数越高越好”,核心是“低成本、易部署、能商用、保隐私”——而谷歌最新开源的Gemma 4,刚好踩中所有痛…...