2023年国赛数学建模思路 - 复盘:校园消费行为分析
文章目录
- 0 赛题思路
- 1 赛题背景
- 2 分析目标
- 3 数据说明
- 4 数据预处理
- 5 数据分析
- 5.1 食堂就餐行为分析
- 5.2 学生消费行为分析
- 建模资料
0 赛题思路
(赛题出来以后第一时间在CSDN分享)
https://blog.csdn.net/dc_sinor?type=blog
1 赛题背景
校园一卡通是集身份认证、金融消费、数据共享等多项功能于一体的信息集成系统。在为师生提供优质、高效信息化服务的同时,系统自身也积累了大量的历史记录,其中蕴含着学生的消费行为以及学校食堂等各部门的运行状况等信息。
很多高校基于校园一卡通系统进行“智慧校园”的相关建设,例如《扬子晚报》2016年 1月 27日的报道:《南理工给贫困生“暖心饭卡补助”》。
不用申请,不用审核,饭卡上竟然能悄悄多出几百元……记者昨天从南京理工大学独家了解到,南理工教育基金会正式启动了“暖心饭卡”
项目,针对特困生的温饱问题进行“精准援助”。
项目专门针对贫困本科生的“温饱问题”进行援助。在学校一卡通中心,教育基金会的工作人员找来了全校一万六千余名在校本科生 9 月中旬到 11月中旬的刷卡记录,对所有的记录进行了大数据分析。最终圈定了 500余名“准援助对象”。
南理工教育基金会将拿出“种子基金”100万元作为启动资金,根据每位贫困学生的不同情况确定具体的补助金额,然后将这些钱“悄无声息”的打入学生的饭卡中,保证困难学生能够吃饱饭。
——《扬子晚报》2016年 1月 27日:南理工给贫困生“暖心饭卡补助”本赛题提供国内某高校校园一卡通系统一个月的运行数据,希望参赛者使用
数据分析和建模的方法,挖掘数据中所蕴含的信息,分析学生在校园内的学习生活行为,为改进学校服务并为相关部门的决策提供信息支持。
2 分析目标
-
1. 分析学生的消费行为和食堂的运营状况,为食堂运营提供建议。
-
2. 构建学生消费细分模型,为学校判定学生的经济状况提供参考意见。
3 数据说明
附件是某学校 2019年 4月 1 日至 4月 30日的一卡通数据
一共3个文件:data1.csv、data2.csv、data3.csv
4 数据预处理
将附件中的 data1.csv、data2.csv、data3.csv三份文件加载到分析环境,对照附录一,理解字段含义。探查数据质量并进行缺失值和异常值等方面的必要处理。将处理结果保存为“task1_1_X.csv”(如果包含多张数据表,X可从 1 开始往后编号),并在报告中描述处理过程。
import numpy as np
import pandas as pd
import os
os.chdir('/home/kesci/input/2019B1631')
data1 = pd.read_csv("data1.csv", encoding="gbk")
data2 = pd.read_csv("data2.csv", encoding="gbk")
data3 = pd.read_csv("data3.csv", encoding="gbk")
data1.head(3)
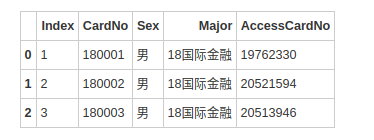
data1.columns = ['序号', '校园卡号', '性别', '专业名称', '门禁卡号']
data1.dtypes

data1.to_csv('/home/kesci/work/output/2019B/task1_1_1.csv', index=False, encoding='gbk')
data2.head(3)

将 data1.csv中的学生个人信息与 data2.csv中的消费记录建立关联,处理结果保存为“task1_2_1.csv”;将 data1.csv 中的学生个人信息与data3.csv 中的门禁进出记录建立关联,处理结果保存为“task1_2_2.csv”。
data1 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_1.csv", encoding="gbk")
data2 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_2.csv", encoding="gbk")
data3 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_3.csv", encoding="gbk")
data1.head(3)
5 数据分析
5.1 食堂就餐行为分析
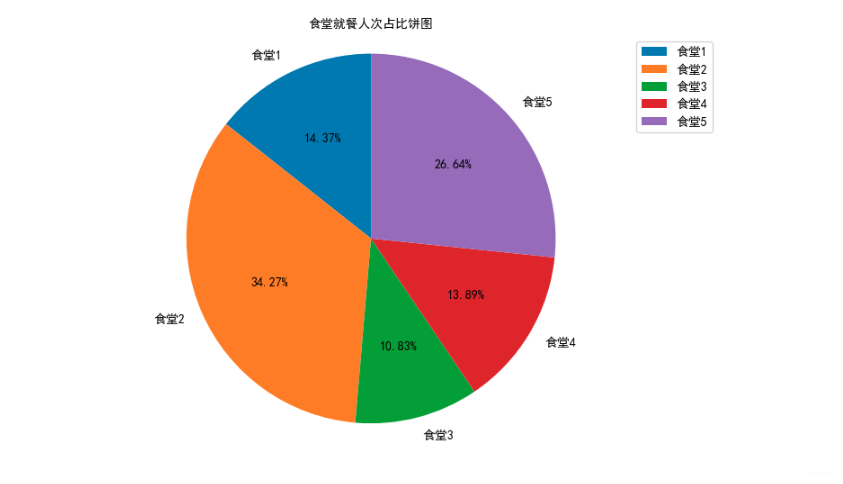
绘制各食堂就餐人次的占比饼图,分析学生早中晚餐的就餐地点是否有显著差别,并在报告中进行描述。(提示:时间间隔非常接近的多次刷卡记录可能为一次就餐行为)
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()

import matplotlib as mpl
import matplotlib.pyplot as plt
# notebook嵌入图片
%matplotlib inline
# 提高分辨率
%config InlineBackend.figure_format='retina'
from matplotlib.font_manager import FontProperties
font = FontProperties(fname="/home/kesci/work/SimHei.ttf")
import warnings
warnings.filterwarnings('ignore')
canteen1 = data['消费地点'].apply(str).str.contains('第一食堂').sum()
canteen2 = data['消费地点'].apply(str).str.contains('第二食堂').sum()
canteen3 = data['消费地点'].apply(str).str.contains('第三食堂').sum()
canteen4 = data['消费地点'].apply(str).str.contains('第四食堂').sum()
canteen5 = data['消费地点'].apply(str).str.contains('第五食堂').sum()
# 绘制饼图
canteen_name = ['食堂1', '食堂2', '食堂3', '食堂4', '食堂5']
man_count = [canteen1,canteen2,canteen3,canteen4,canteen5]
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("食堂就餐人次占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis('equal')
# 显示图像
plt.show()
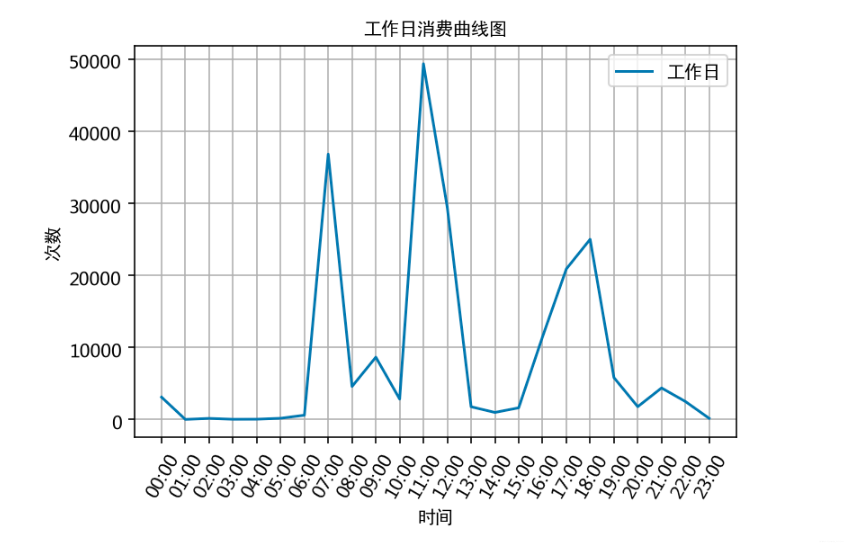
通过食堂刷卡记录,分别绘制工作日和非工作日食堂就餐时间曲线图,分析食堂早中晚餐的就餐峰值,并在报告中进行描述。

# 对data中消费时间数据进行时间格式转换,转换后可作运算,coerce将无效解析设置为NaT
data.loc[:,'消费时间'] = pd.to_datetime(data.loc[:,'消费时间'],format='%Y-%m-%d %H:%M',errors='coerce')
data.dtypes
# 创建一个消费星期列,根据消费时间计算出消费时间是星期几,Monday=1, Sunday=7
data['消费星期'] = data['消费时间'].dt.dayofweek + 1
data.head(3)
# 以周一至周五作为工作日,周六日作为非工作日,拆分为两组数据
work_day_query = data.loc[:,'消费星期'] <= 5
unwork_day_query = data.loc[:,'消费星期'] > 5work_day_data = data.loc[work_day_query,:]
unwork_day_data = data.loc[unwork_day_query,:]
# 计算工作日消费时间对应的各时间的消费次数
work_day_times = []
for i in range(24):work_day_times.append(work_day_data['消费时间'].apply(str).str.contains(' {:02d}:'.format(i)).sum())# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24):x.append('{:02d}:00'.format(i))
# 绘图
plt.plot(x, work_day_times, label='工作日')
# x,y轴标签
plt.xlabel('时间', fontproperties=font);
plt.ylabel('次数', fontproperties=font)
# 标题
plt.title('工作日消费曲线图', fontproperties=font)
# x轴倾斜60度
plt.xticks(rotation=60)
# 显示label
plt.legend(prop=font)
# 加网格
plt.grid()
# 计算飞工作日消费时间对应的各时间的消费次数
unwork_day_times = []
for i in range(24):unwork_day_times.append(unwork_day_data['消费时间'].apply(str).str.contains(' {:02d}:'.format(i)).sum())# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24): x.append('{:02d}:00'.format(i))
plt.plot(x, unwork_day_times, label='非工作日')
plt.xlabel('时间', fontproperties=font);
plt.ylabel('次数', fontproperties=font)
plt.title('非工作日消费曲线图', fontproperties=font)
plt.xticks(rotation=60)
plt.legend(prop=font)
plt.grid()
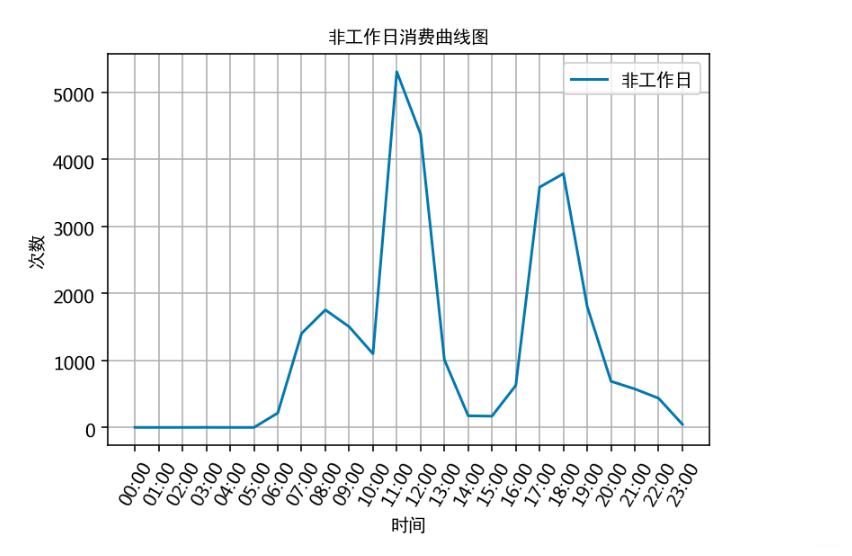
根据上述分析的结果,很容易为食堂的运营提供建议,比如错开高峰等等。
5.2 学生消费行为分析
根据学生的整体校园消费数据,计算本月人均刷卡频次和人均消费额,并选择 3个专业,分析不同专业间不同性别学生群体的消费特点。
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()

# 计算人均刷卡频次(总刷卡次数/学生总人数)
cost_count = data['消费时间'].count()
student_count = data['校园卡号'].value_counts(dropna=False).count()
average_cost_count = int(round(cost_count / student_count))
average_cost_count# 计算人均消费额(总消费金额/学生总人数)
cost_sum = data['消费金额'].sum()
average_cost_money = int(round(cost_sum / student_count))
average_cost_money# 选择消费次数最多的3个专业进行分析
data['专业名称'].value_counts(dropna=False)
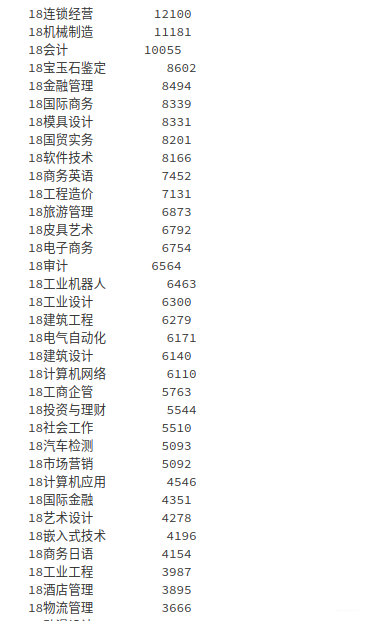
# 消费次数最多的3个专业为 连锁经营、机械制造、会计
major1 = data['专业名称'].apply(str).str.contains('18连锁经营')
major2 = data['专业名称'].apply(str).str.contains('18机械制造')
major3 = data['专业名称'].apply(str).str.contains('18会计')
major4 = data['专业名称'].apply(str).str.contains('18机械制造(学徒)')data_new = data[(major1 | major2 | major3) ^ major4]
data_new['专业名称'].value_counts(dropna=False)分析 每个专业,不同性别 的学生消费特点
data_male = data_new[data_new['性别'] == '男']
data_female = data_new[data_new['性别'] == '女']
data_female.head()
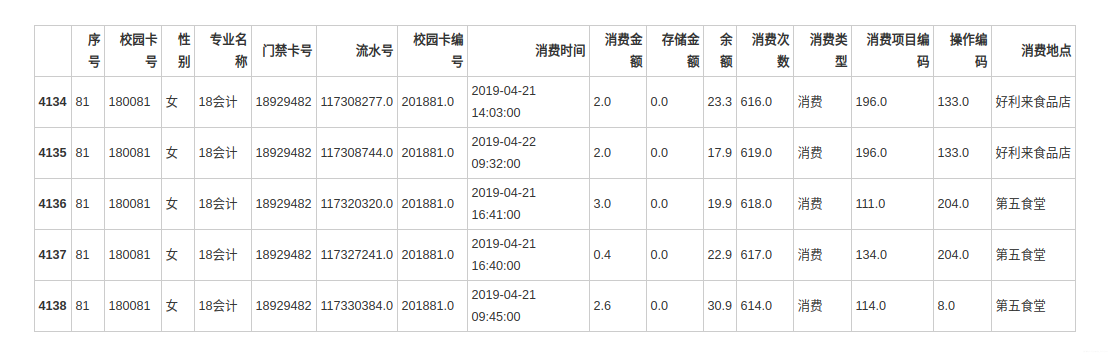
根据学生的整体校园消费行为,选择合适的特征,构建聚类模型,分析每一类学生群体的消费特点。
data['专业名称'].value_counts(dropna=False).count()
# 选择特征:性别、总消费金额、总消费次数
data_1 = data[['校园卡号','性别']].drop_duplicates().reset_index(drop=True)
data_1['性别'] = data_1['性别'].astype(str).replace(({'男': 1, '女': 0}))
data_1.set_index(['校园卡号'], inplace=True)
data_2 = data.groupby('校园卡号').sum()[['消费金额']]
data_2.columns = ['总消费金额']
data_3 = data.groupby('校园卡号').count()[['消费时间']]
data_3.columns = ['总消费次数']
data_123 = pd.concat([data_1, data_2, data_3], axis=1)#.reset_index(drop=True)
data_123.head()# 构建聚类模型
from sklearn.cluster import KMeans
# k为聚类类别,iteration为聚类最大循环次数,data_zs为标准化后的数据
k = 3 # 分成几类可以在此处调整
iteration = 500
data_zs = 1.0 * (data_123 - data_123.mean()) / data_123.std()
# n_jobs为并发数
model = KMeans(n_clusters=k, n_jobs=4, max_iter=iteration, random_state=1234)
model.fit(data_zs)
# r1统计各个类别的数目,r2找出聚类中心
r1 = pd.Series(model.labels_).value_counts()
r2 = pd.DataFrame(model.cluster_centers_)
r = pd.concat([r2,r1], axis=1)
r.columns = list(data_123.columns) + ['类别数目']# 选出消费总额最低的500名学生的消费信息
data_500 = data.groupby('校园卡号').sum()[['消费金额']]
data_500.sort_values(by=['消费金额'],ascending=True,inplace=True,na_position='first')
data_500 = data_500.head(500)
data_500_index = data_500.index.values
data_500 = data[data['校园卡号'].isin(data_500_index)]
data_500.head(10)
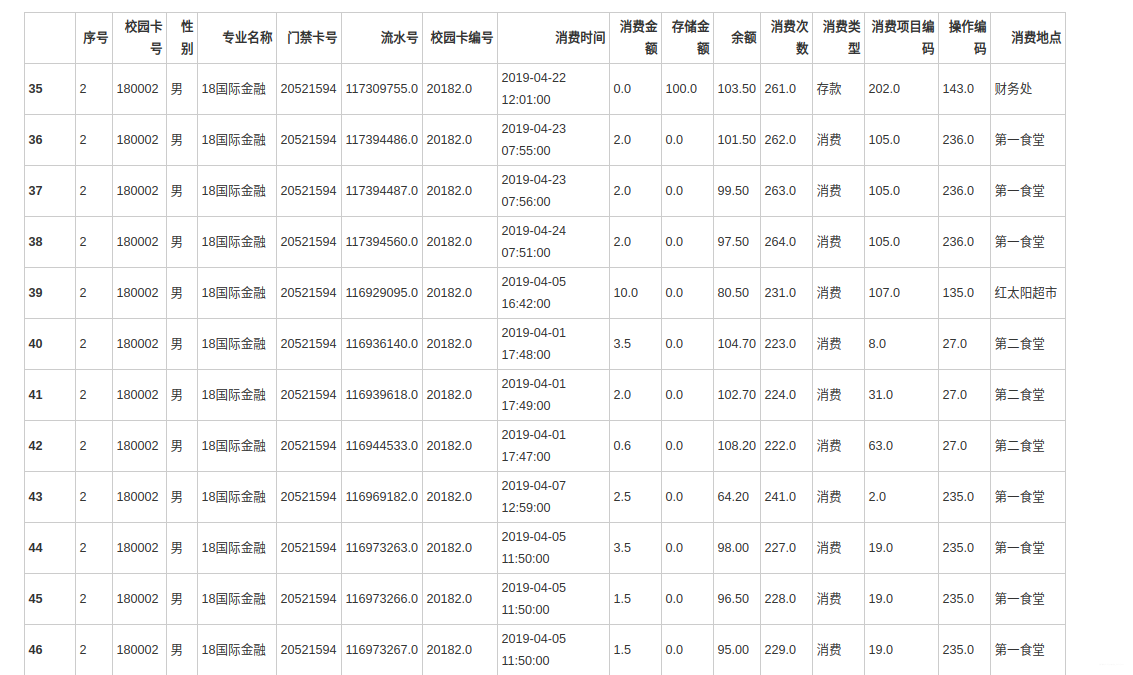
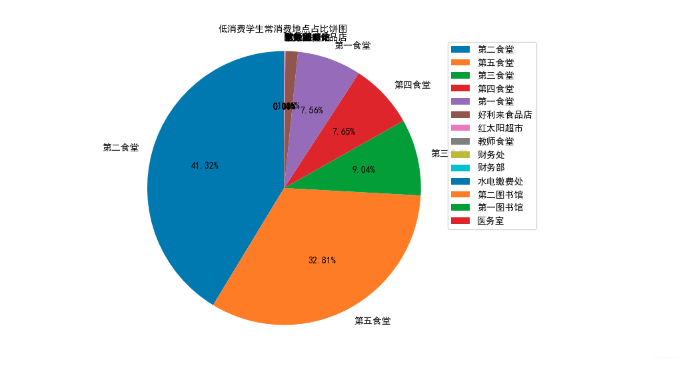
# 绘制饼图
canteen_name = list(data_max_place.index)
man_count = list(data_max_place.values)
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("低消费学生常消费地点占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis('equal')
# 显示图像
plt.show()
建模资料
资料分享: 最强建模资料


相关文章:
2023年国赛数学建模思路 - 复盘:校园消费行为分析
文章目录 0 赛题思路1 赛题背景2 分析目标3 数据说明4 数据预处理5 数据分析5.1 食堂就餐行为分析5.2 学生消费行为分析 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 赛题背景 校园一卡通是集…...

WebAPIs 第四天
1.日期对象 2.节点操作 3.M端事件 4.JS插件 一.日期对象 实例化时间对象方法时间戳 日期对象:用来表示时间的对象 作用:可以得到当前系统时间 1.1 实例化 ① 概念:在代码中发现了new关键字时,一般将这个操作称为实例化 …...

SQL 语句解析过程详解
SQL 语句解析过程详解: 1.输入SQL语句 2.词法分析------flex 使用词法分析器(由Flex生成)将 SQL 语句分解为一个个单词,这些单词被称为“标记“。标记包括关键字、标识符、运算符、分隔符等。 2.1 flex 原…...

单源最短路径【学习算法】
单源最短路径【学习算法】 前言版权推荐单源最短路径Java算法实现代码结果 带限制的单源最短路径1928. 规定时间内到达终点的最小花费LCP 35. 电动车游城市 最后 前言 2023-8-14 18:21:41 以下内容源自《【学习算法】》 仅供学习交流使用 版权 禁止其他平台发布时删除以下此…...
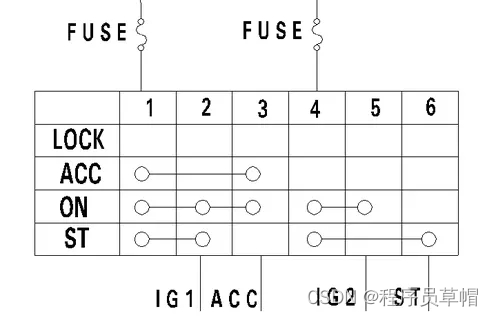
汽车上的电源模式详解
① 一般根据钥匙孔开关的位置来确定整车用电类别,汽车上电源可以分为常电,IG电,ACC电 1)常电。常电表示蓄电池和发电机输出直接供电,即使点火开关在OFF档时,也有电量供应。一般来讲模块的记忆电源及需要在车…...

【碎碎念随笔】1、回顾我的电脑和编程经历
✏️ 闲着无事,讲述一下我的计算机和代码故事 一、初识计算机 🖥️ 余家贫,耕植无钱买电脑。大约六年级暑假,我在姐姐哪儿第一次接触到了计算机(姐姐也是买的二手)。 🖥️ 计算机真有趣&#x…...
)
背上花里胡哨的书包准备面试之webpack篇(+一些常问的面试题)
目录 webpack理解? webpack构建流程? loader解决什么问题? plugin解决什么问题? 编写loader和plugin的思路? webpack热更新? 如何提高webpack的构建速度? 问git常用命令? ht…...

你知道什么是Curriculum Training模型吗
随着深度学习技术的飞速发展,研究人员在不断探索新的训练方法和策略,以提高模型的性能和泛化能力。其中,Curriculum Training(课程学习)模型作为一种前沿的训练方法,引起了广泛的关注和研究。本文将深入探讨…...

vue 大文件视频切片上传处理方法
前端上传大文件、视频的时候会出现超时、过大、很慢等情况,为了解决这一问题,跟后端配合做了一个切片的功能。 我这个切片功能是基于 minion 的,后端会把文件放在minion服务器上。具体看后端怎么做 1、在项目的 util(这个文件夹是自己创建的…...
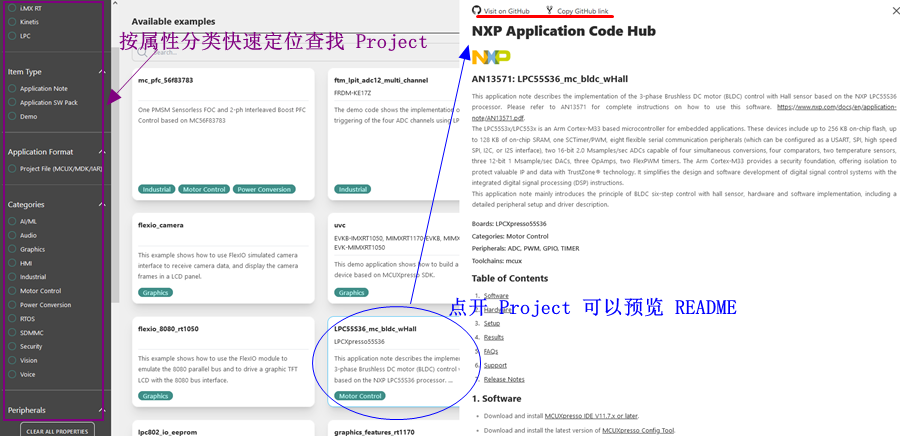
痞子衡嵌入式:AppCodeHub - 一站网罗恩智浦MCU应用程序
近日,恩智浦官方隆重上线了应用程序代码中心(Application Code Hub,简称 ACH),这是恩智浦 MCUXpresso 软件生态的一个重要组成部分。痞子衡之所以要如此激动地告诉大家这个好消息,是因为 ACH 并不是又一个恩智浦官方 github proje…...
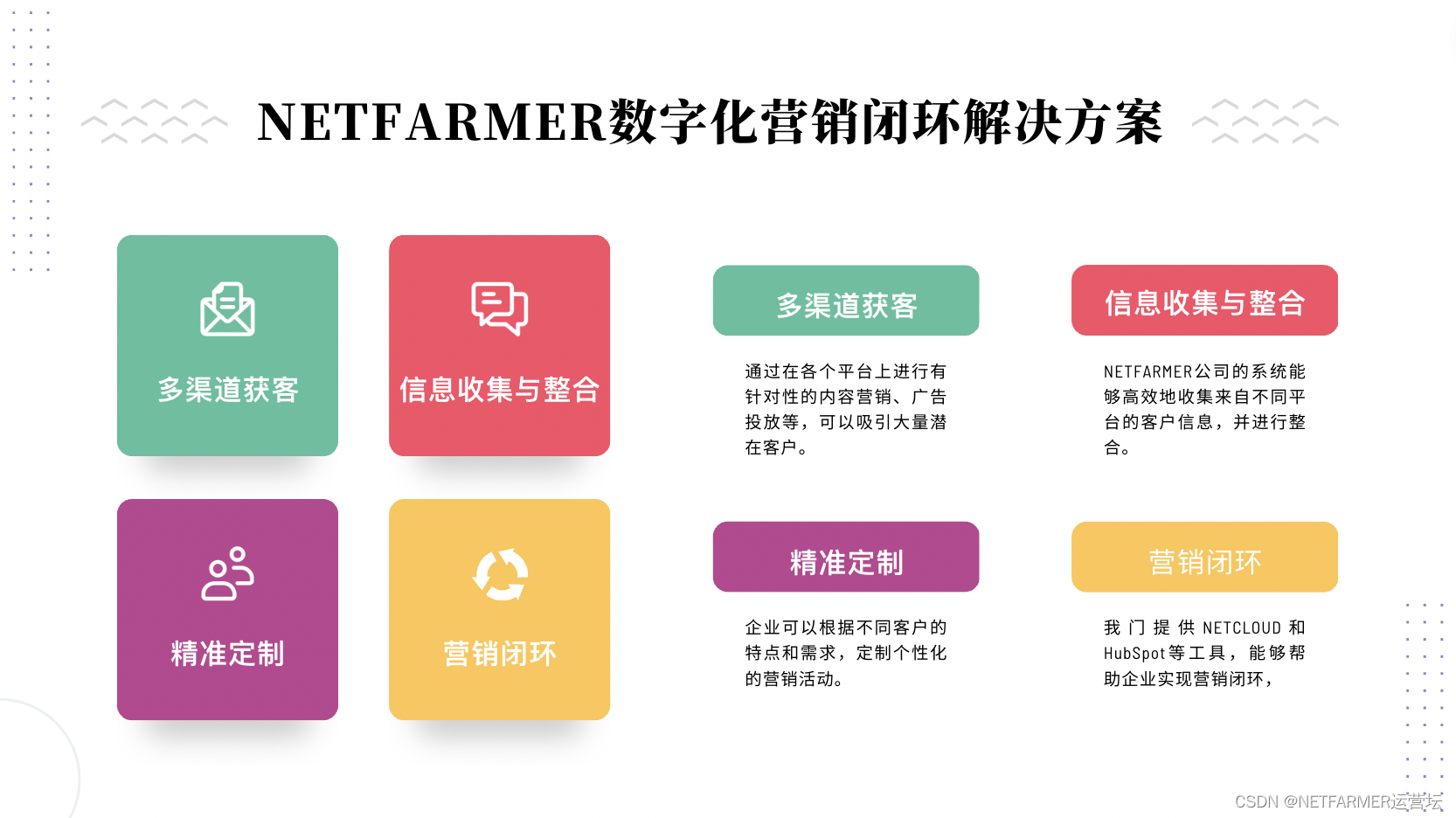
打造数字化营销闭环,破解精准获客难题
现阶段,企业需要进行数字化营销闭环,以实现更精确的客户获取。随着数字技术的迅猛发展,企业需要将在线广告、社交媒体营销和数据分析等工具相互结合,建立一个完整的数字化营销流程。通过使用客户细分、精准定位和个性化广告等手段…...
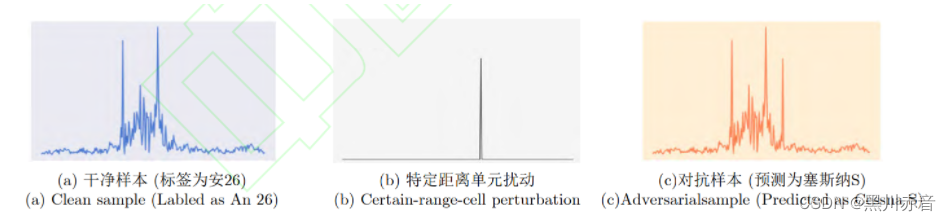
《雷达像智能识别对抗研究进展》阅读记录
(1)引言 神经网络通常存在鲁棒性缺陷,易受到对抗攻击的威胁。攻击者可以隐蔽的诱导雷达智能目标识别做出错误预测,如: a图是自行车,加上对抗扰动后神经网络就会将其识别为挖掘机。 (2&a…...
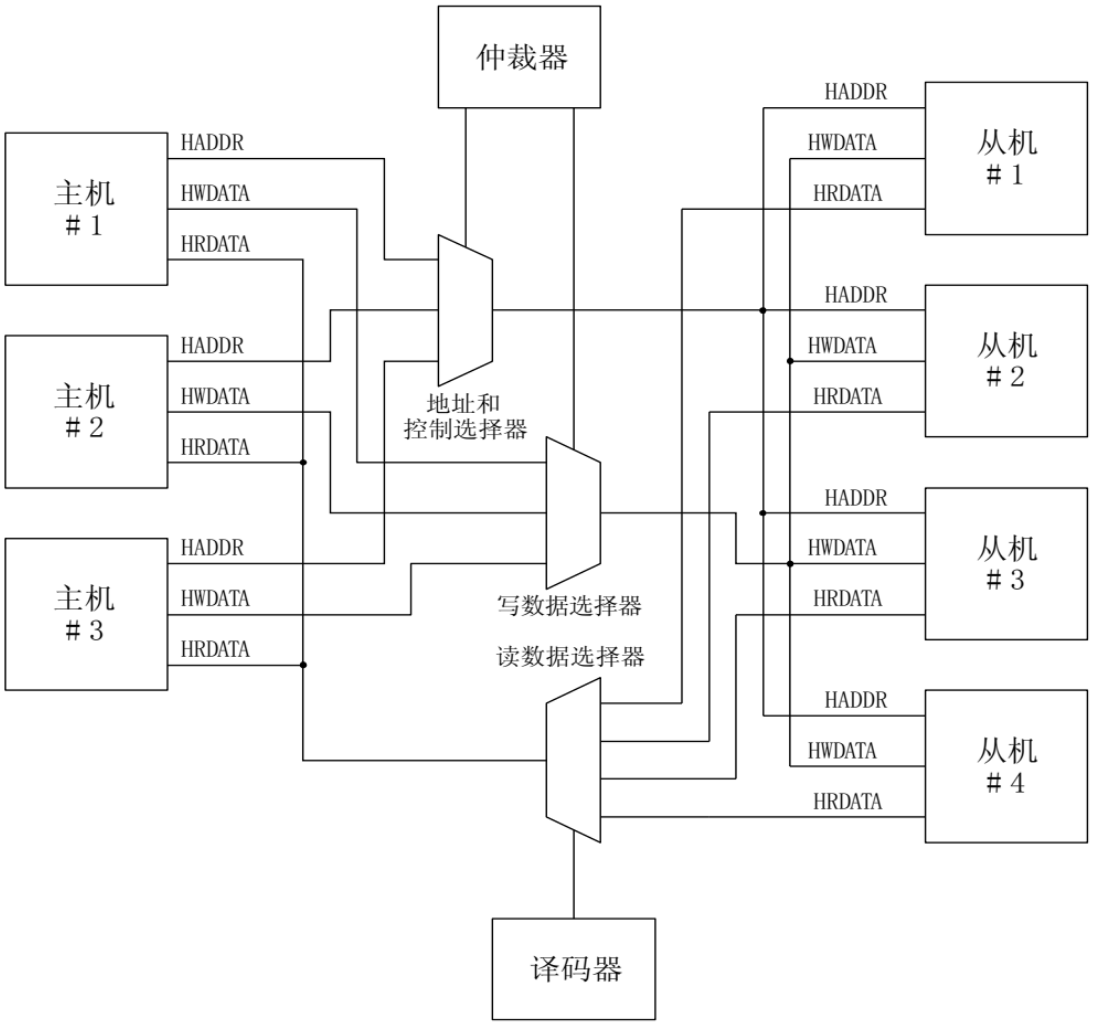
【AHB】初识 AHB 总线
AHB 与 APB、ASB同属于 AMBA 总线架构规范,该总线规范由 ARM 公司提出。 目录 一、AHB 总线 二、AHB 总线组成 三、AHB 主从通信过程 一、AHB 总线 AHB(Advanced High Performance Bus),意为高级高性能总线,能将微控制器&…...

Linux服务使用宝塔面板搭建网站,通过内网穿透实现公网访问
文章目录 前言1. 环境安装2. 安装cpolar内网穿透3. 内网穿透4. 固定http地址5. 配置二级子域名6. 创建一个测试页面 前言 宝塔面板作为简单好用的服务器运维管理面板,它支持Linux/Windows系统,我们可用它来一键配置LAMP/LNMP环境、网站、数据库、FTP等&…...
C++ 判断
判断结构要求程序员指定一个或多个要评估或测试的条件,以及条件为真时要执行的语句(必需的)和条件为假时要执行的语句(可选的)。 下面是大多数编程语言中典型的判断结构的一般形式: 判断语句 C 编程语言…...

“解引用“空指针一定会导致段错误吗?
可能有些朋友看见这个标题第一反应是嵌入式的某些内存中,0地址也是可以被正常访问的,所以对0地址的解引用不会发生错误,但我要说的情况不是这个,而是指一个真正的空指针,不仅是c/c中的0,(void*)0,NULL,还有nullptr,一个真正的空指针. 在c语言中,想获得某结构体的成员变量相对偏…...

釉面陶瓷器皿SOR/2016-175标准上架亚马逊加拿大站
亲爱的釉面陶瓷器皿和玻璃器皿制造商和卖家,亚马逊加拿大站将执行SOR/2016-175法规。这是一份新的法规,规定了含有铅和镉的釉面陶瓷器和玻璃器皿需要满足的要求。让我们一起来看一看,为什么要实行SOR/2016-175法规?这是一个保护消…...

Redux - Redux在React函数式组件中的基本使用
文章目录 一,简介二,安装三,三大核心概念Store、Action、Reducer3.1 Store3.2 Reducer3.3 Action 四,开始函数式组件中使用4.1,引入store4.1,store.getState()方法4.3,store.dispatch()方法4.4&…...

rust学习-同时执行多Future
只用 .await 来执行future,会阻塞并发任务,直到特定的 Future 完成 join!:等待所有future完成 可事实上为什么都是res1完成后再执行res2? join! 不保证并发执行,难道只负责同步等待? 示例 [package] name = "rust_demo5" version = "0.1.0" edit…...

问道管理:旅游酒店板块逆市拉升,桂林旅游、华天酒店涨停
游览酒店板块14日盘中逆市拉升,到发稿,桂林游览、华天酒店涨停,张家界涨超8%,君亭酒店涨超5%,众信游览、云南游览涨逾4%。 音讯面上,8月10日,文旅部办公厅发布康复出境团队游览第三批名单&#…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...
)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例)
别再手动编译了!Matlab一键调用CEC2017测试函数的完整配置指南(附30个函数调用示例) 算法研究者们常常需要借助标准测试函数来验证优化算法的性能,而CEC2017测试函数集因其复杂性和多维度的挑战性,成为评估算法鲁棒性的…...

HoRain云--CLAUDE.md 使用指南
🎬 HoRain云小助手:个人主页 🔥 个人专栏: 《Linux 系列教程》《c语言教程》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!…...

Arduino ADC自检:用RC电路诊断模数转换器故障
1. 项目概述:当你的体重秤开始“说谎”你有没有遇到过这样的情况:站上家里的电子体重秤,屏幕上跳出来的数字让你瞬间怀疑人生?要么是轻得离谱,要么是重得吓人,更诡异的是,它可能只在两个固定的、…...