时序预测-Informer简介
文章目录
- Informer介绍
- 1. Transformer存在的问题
- 2. Informer研究背景
- 3. Informer 整体架构
- 3.1 ProbSparse Self-attention
- 3.2 Self-attention Distilling
- 3.3 Generative Style Decoder
- 4. Informer的实验性能
- 5. 相关资料
Informer介绍
1. Transformer存在的问题
Informer实质是在Transformer的基础上进行改进,通过修改transformer的结构,提高transformer的速度。那么Transformer有什么样的缺点:
(1)self-attention的平方复杂度。self-attention的时间和空间复杂度是O(L^2),L为序列长度。
(2)对长输入进行堆叠(stack)时的内存瓶颈。多个encoder-decoder堆叠起来就会形成复杂的空间复杂度,这会限制模型接受较长的序列输入。
(3)预测长输出时速度骤降。对于Tansformer的输出,使用的是step-by-step推理得像RNN模型一样慢,并且动态解码还存在错误传递的问题。
2. Informer研究背景
论文的研究背景为:长序列预测问题。这些问题会出现在哪些地方呢:
● 股票预测(数据、规则都在变,模型都是无法预测的)
● 机器人动作的预测
● 人体行为识别(视频前后帧的关系)
● 气温的预测、疫情下的确诊人数
● 流水线每一时刻的材料消耗,预测下一时刻原材料需要多少…
那么以上需要时间线来进行实现的,无疑会想到使用Transformer来解决这些问题,Transformer的最大特点就是利用了attention进行时序信息传递。每次进行一次信息传递,我们需要执行两次矩阵乘积,也就是QKV的计算。并且我们需要思考一下,我们每次所执行的attention计算所保留下来的值是否是真的有效的吗?我们有没有必要去计算这么多attention?
那么对于现在的时间预测可以大致分为下面三种:
● 短序列预测
● 趋势预测
● 精准长序列预测

很多算法都是基于短序列进行预测的,先得知前一部分的数据,之后去预测短时间的情况。想要预测一个长序列,就不可以使用短预测,预测未来半年or一年,很难预测很准。长序列其实像是滑动窗口,不断地往后滑动,一步一步走,但是越滑越后的时候,他一直在使用预测好的值进行预测,长时间的序列预测是有难度的。
那么有哪些时间序列的经典算法:
● Prophnet:很实用的工具包,很适合预测趋势,但算的不精准。
● Arima:短序列预测还算精准,但是趋势预测不准。多标签。
以上两种一旦涉及到了长序列,都不可以使用。
● Informer中将主要致力于长序列问题的解决
可能在这里大家也会想到LSTM:但是这个模型在长序列预测中,如果序列越长,那速度肯定越慢,效果也越差。这个模型使用的为串行结构,效率很低,也会基于前面的特征来预测下一个特征,其损失函数的值也会越来越大。
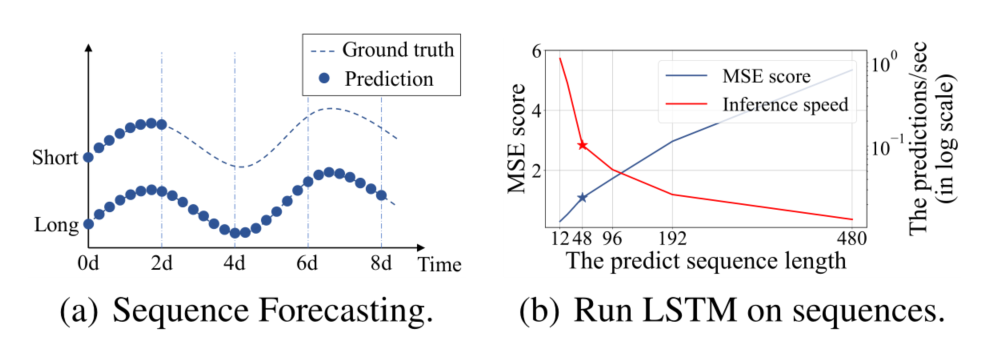
LSTM预测能力限制了LSTF的性能。例如,从长度=48开始,MSE上升得高得令人无法接受,推理速度迅速下降。
那么我们Transformer中也有提及到改进LSTM的方法,其优势和问题在于:
(1)万能模型,可直接套用,代码实现简单。
(2)并行的,比LSTM快,全局信息丰富,注意力机制效果好。
(3)长序列中attention需要每一个点跟其他点计算,如果序列太长,其效率很低。
(4)Decoder输出很麻烦,都要基于上一个预测结果来推断当前的预测结果,这对于一个长序列的预测中最好是不要出现这样的情况。
那么Informer就需要解决如下的问题:
| Transformer的缺点 | Informer的改进 |
|---|---|
| self-attention平方级的计算复杂度 | 提出ProbSparse Self-attention筛选出最重要的Q,降低计算复杂度 |
| 堆叠多层网络,内存占用瓶颈 | 提出Self-attention Distilling进行下采样操作,减少维度和网络参数的数量 |
| step-by-step解码预测,速度较慢 | 提出Generative Style Decoder,一步可以得到所有预测的 |
3. Informer 整体架构
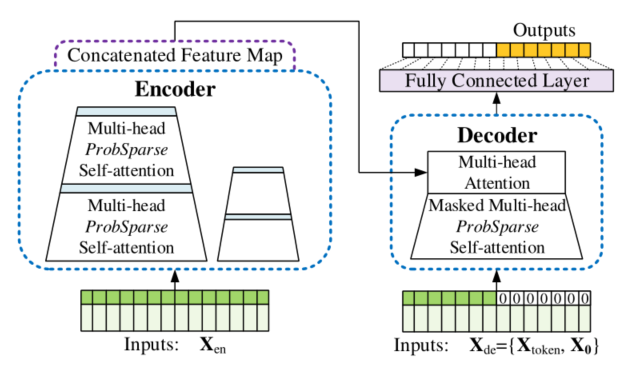
3.1 ProbSparse Self-attention
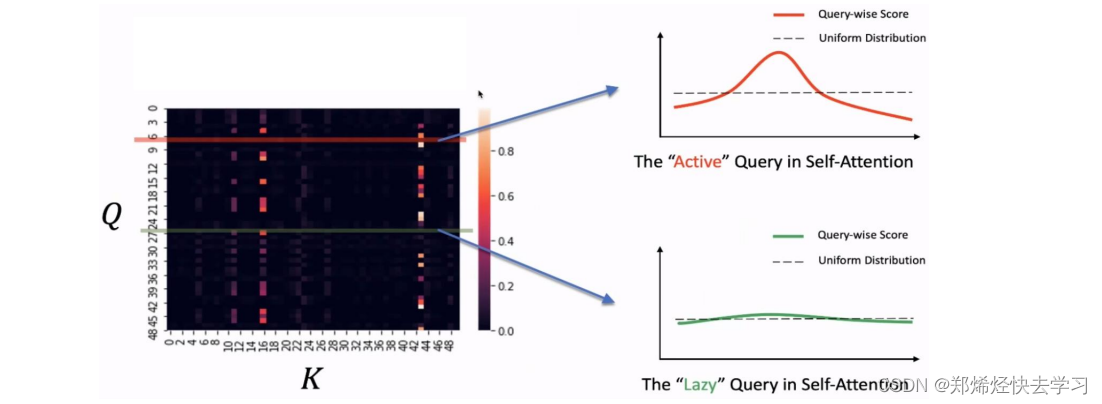
通过以下图数据可以看到,并不是每个QK的点积都是有效值,我们也不需要花很多时间在处理这些数据上:
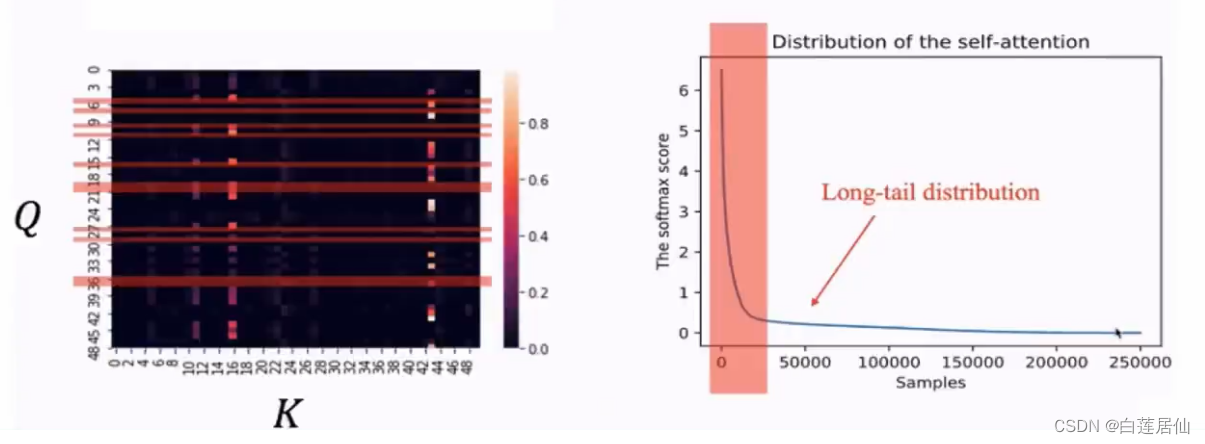
这个结果也是合理的,因为某个元素可能只和几个元素高度相关,和其他的元素并没有很显著的关联。如果我们要提高计算效率的话,我们需要关注那些有特点的那些值,那我们要怎么去关注那些有特点的值呢:
我们需要进行一次Query稀疏性的衡量:
作者从概率的角度看待自注意力,定义
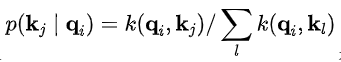
是概率的形式,即在给定第i个query的条件下key的分布。
作者认为,如果算出来的这个结果接近于均匀分布
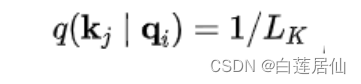
,那么就说明这个query是在偷懒,没办法选中那些重要的Key,如果反之,就说明这个Q为积极的,活跃的:
其计算公式如下:
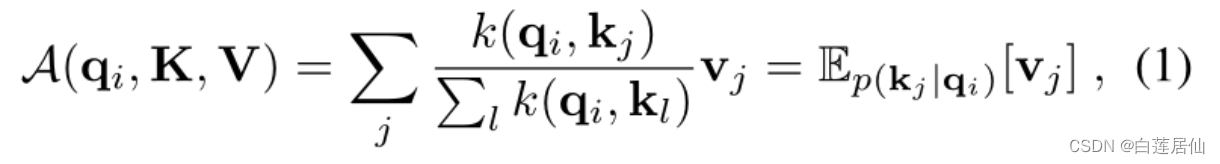
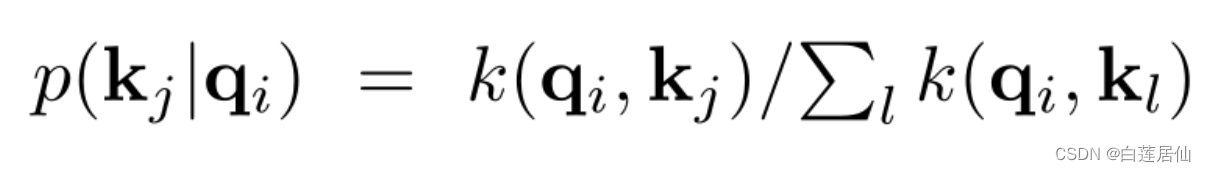
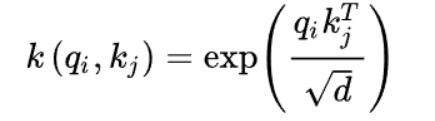
之后我们进行比较:
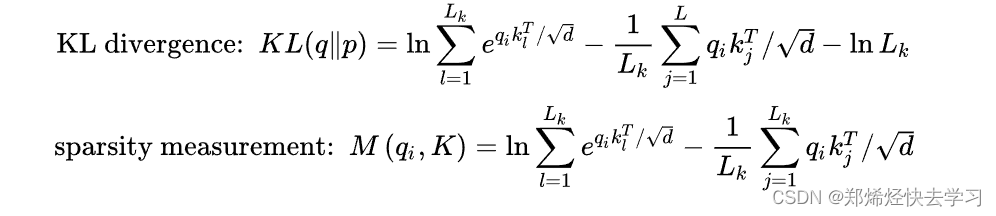
我们算出了其概率以及与均匀分布的差异,如果差异越大,那么这个Q就有机会去被关注、说明其起到了作用。那么其计算方法到底是怎么样进行的,我们要取哪些Q哪些K进行计算:
(1)输入序列长度为96,首先在K中进行采样,随机选取25个K。
(2)计算每个Q与25个K的点积,可以得到M(qi,K),现在一个Q一共有25个得分
(3)在25个得分中,选取最高分的那个Q与均值算差异。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7NwYUMzb-1691939172750)(https://cdn.jsdelivr.net/gh/Sql88/BlogImg@main/img/AgAACmAXn_S6vVNOPepOnbc96hbjQ4rH.png)]](https://img-blog.csdnimg.cn/92eef7386e9f489ca86a6852263050fa.png)
(4)这样我们输入的96个Q都有对应的差异得分,我们将差异从大到小排列,选出差异前25大的Q。
(5)那么传进去参数例如:[32,8,25,96],代表的意思为输入96个序列长度,32个batch,8个特征,25个Q进行处理。
(6)其他位置淘汰掉的Q使用均匀方差代替,不可以因为其不好用则不处理,需要进行更新,保证输入对着有输出。
以上的时间复杂度为O(L ln L):
ProbSparse Attention在为每个Q随机采样K时,每个head的采样结果是相同的,也就是采样的K是相同的。但是由于每一层self-attention都会对QKV做线性转换,这使得序列中同一个位置上不同的head对应的QK都不同,那么每一个head对于Q的差异都不同,这就使得每个head中的得到的前25个Q也是不同的。这样也等价于每个head都采取了不同的优化策略。
核心代码:
def _prob_QK(self, Q, K, sample_k, n_top): # n_top: c*ln(L_q)# 维度[batch,头数,序列长度,自动计算值]# Q [B, H, L, D]B, H, L_K, E = K.shape # [32,8,96,64]_, _, L_Q, _ = Q.shape # L_Q :96# calculate the sampled Q_K# 添加一个维度,相当于复制维度,当前维度为[batch,头数,序列长度,序列长度,自动计算值]# K.unsqueeze(-3).shape: [32, 8, 1, 96, 64]K_expand = K.unsqueeze(-3).expand(B, H, L_Q, L_K, E)# 随机取样,取值范围0~96,取样维度为[序列长度,25]index_sample = torch.randint(L_K, (L_Q, sample_k)) # real U = U_part(factor*ln(L_k))*L_q# 96个Q与25个K做计算,维度为[batch,头数,Q个数,K个数,自动计算值]K_sample = K_expand[:, :, torch.arange(L_Q).unsqueeze(1), index_sample, :]# 矩阵重组,维度为[batch,头数,Q个数,K个数]# 做点积Q_K_sample = torch.matmul(Q.unsqueeze(-2), K_sample.transpose(-2, -1)).squeeze(-2)# find the Top_k query with sparisty measurement# 分别取到96个Q中每一个Q跟K关系最大的值M = Q_K_sample.max(-1)[0] - torch.div(Q_K_sample.sum(-1), L_K)# 在96个Q中选出前25个M_top = M.topk(n_top, sorted=False)[1]# use the reduced Q to calculate Q_K# 取出Q特征,维度为[batch,头数,Q个数,自动计算值]# Q_reduce.shape:[32, 8, 25, 64] 即从96中取出25个最有用的QQ_reduce = Q[torch.arange(B)[:, None, None],torch.arange(H)[None, :, None],M_top, :] # factor*ln(L_q)# 25个Q与96个K做点积Q_K = torch.matmul(Q_reduce, K.transpose(-2, -1)) # factor*ln(L_q)*L_kreturn Q_K, M_top
3.2 Self-attention Distilling
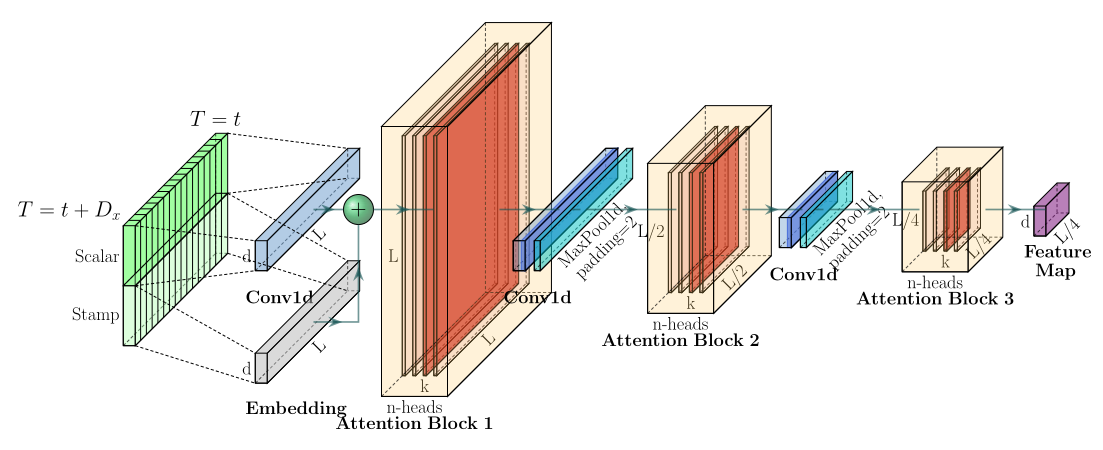
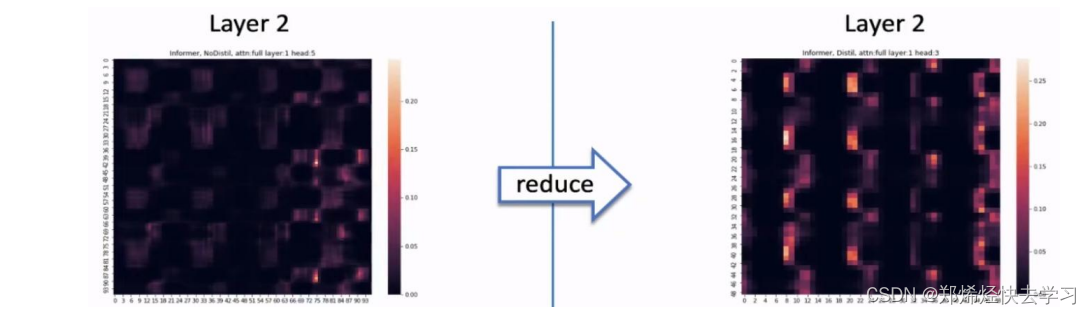
这一层类似于下采样。将我们输入的序列缩小为原来的二分之一。作者在这里提出了自注意力蒸馏的操作,具体是在相邻的的Attention Block之间加入卷积池化操作,来对特征进行降采样。为什么可以这么做,在上面的ProbSparse Attention中只选出了前25个Q做点积运算,形成Q-K对,其他Q-K对则置为0,所以当与value相乘时,会有很多冗余项。这样也可以突出其主要特征,也降低了长序列输入的空间复杂度,也不会损失很多信息,大大提高了效率。
另外,作者为了提高encoder的鲁棒性,还提出了一个strick。途中输入embedding经过了三个Attention Block,最终得到Feature Map。还可以再复制一份具有一半输入的embedding,让它让经过两个Attention Block,最终会得到和上面维度相同的Feature Map,然后把两个Feature Map拼接。作者认为这种方式对短周期的数据可能更有效一些。
3.3 Generative Style Decoder
对于Transformer其输出是先输出第一个,再基于第一个输出第二个,以此类推。这样子效率慢并且精度不高。看看总的架构图可以发现,decoder由两部分组成:第一部分为encoder的输出,第二部分为embedding后的decoder输入,即用0掩盖了后半部分的输入。
看看Embedding的操作:
● Scalar是采用conv1d将1维转换为512维向量。
● Local Time Stamp采用Transformer中的Positional Embedding。
● Gloabal Time Stamp则是上述处理后的时间戳经过Embedding。可以添加上我们的年月日时。
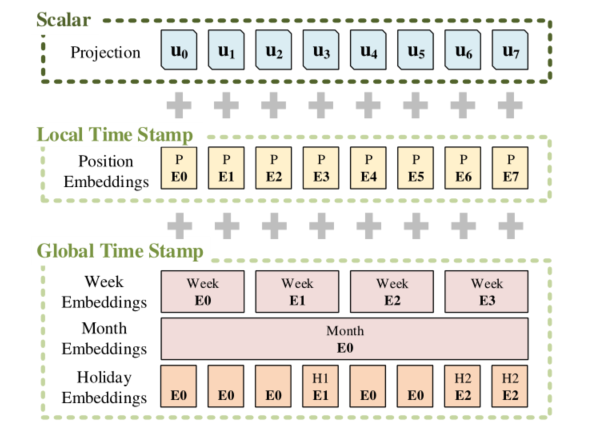
这种位置编码信息有比较丰富的返回,不仅有绝对位置编码,还包括了跟时间相关的各种编码。
最后,使用三者相加得到最后的输入(shape:[batch_size,seq_len,d_model])。
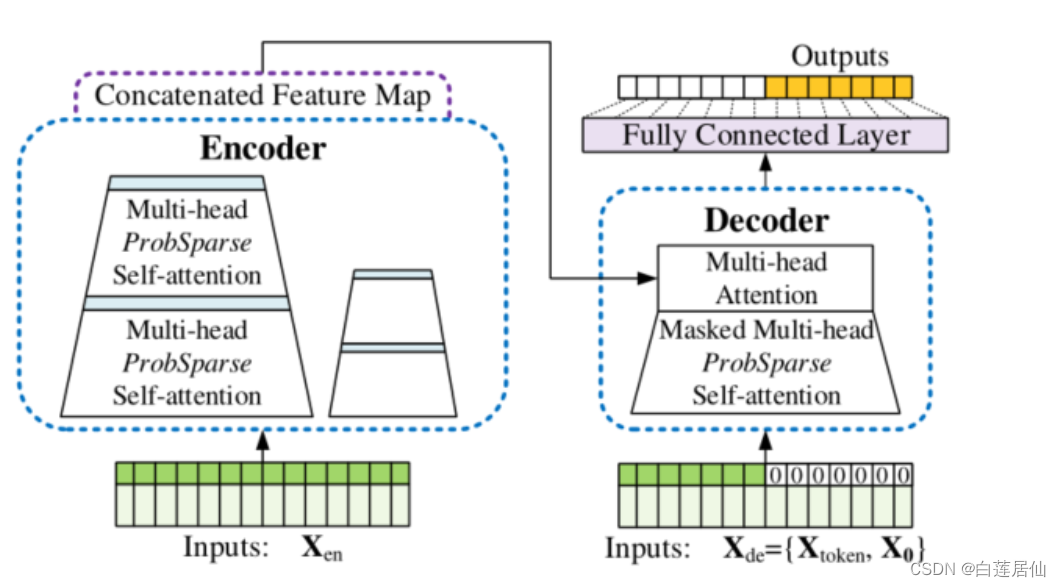
Decoder的最后一个部分是过一个linear layer将decoder的输出扩展到与vocabulary size一样的维度上,经过softmax后,选择概率最高的一个word作为预测结果。
那么假设我们有一个已经训练好的Transformer的神经网络,在预测时,传统的步骤是step by step的:
(1)给decoder输入encoder对整个句子embedding的结果和一个特殊的开始符号。decoder将产生预测,产生”I”。
(2)给decoder输入encoder的embedding结果和“I”,产生预测“am”
(3)给decoder输入encoder的embedding结果和“I am”,产生预测“a”
(4)给decoder输入encoder的embedding的结果和“I am a”,产生预测”student“。
(5)给decoder输入encoder的embedding的结果和“I am a student”,decoder应该生成句子结尾的标记,decoder应该输出“ ”。
(6)最后decoder生成了,翻译完成。
那么我们再看看Informer一步到位的预测:

提供一个start标志位:
● 要让Decoder输出预测结果,你得先告诉它从哪开始输出。
● 先给一个引导,比如要输出20-30号的预测结果,Decoder中需先给出。
● 前面一个序列的结果,例如10-20号的标签值。
其实我们可以理解为一段有效的标签值带着一群预测值进行学习,效率更高。可以说是生成式推理,作者在这里没有选择一个特定的标记来做开始序列,而是选择了一段长的序列,比如目标序列之前一段已知序列。举例来说如果我们要预测7天的,我们可以把之前5天的信息作为开始序列,那么我们上述的式子
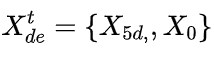
这种方法可以一步到位生成目标序列,不需要再使用动态解码。
对于Decoder输入:
源码中的decoder输入长度为72,其中前48是真实值,后24是预测值。第一步是做自身的ProbAttention,注意要加上Mask(避免未卜先知)。先计算完自身的Attention。再算与encoder的Attention即可。
4. Informer的实验性能
4个数据集(5例)的单变量长序列时间序列预测结果。

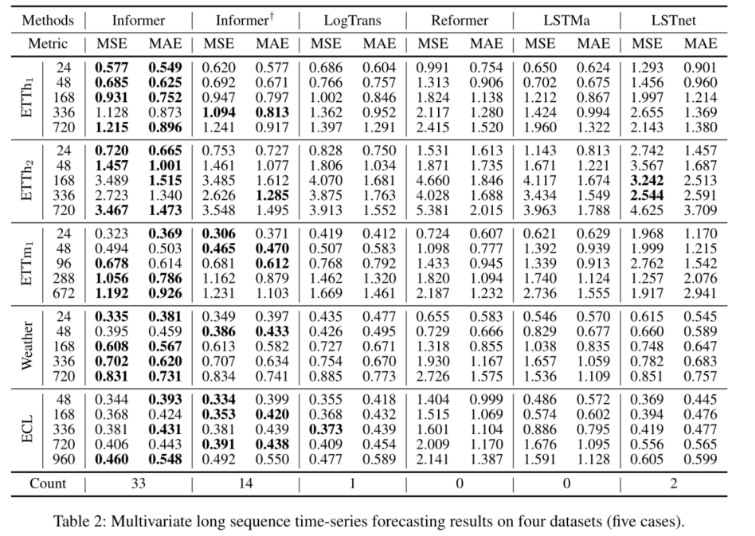
4个数据集(5例)的多变量长序列时间序列预测结果。
5. 相关资料
- Informer源码阅读及理论详解
- Informer源码
- Informer代码详解
- Transformer模型详解
相关文章:
时序预测-Informer简介
文章目录 Informer介绍1. Transformer存在的问题2. Informer研究背景3. Informer 整体架构3.1 ProbSparse Self-attention3.2 Self-attention Distilling3.3 Generative Style Decoder 4. Informer的实验性能5. 相关资料 Informer介绍 1. Transformer存在的问题 Informer实质…...

2023牛客第七场补题报告C F L M
2023牛客第七场补题报告C F L M C-Beautiful Sequence_2023牛客暑期多校训练营7 (nowcoder.com) 思路 观察到数组一定是递增的,所以从最高位往下考虑每位的1最多只有一个,然后按位枚举贪心即可。 代码 #include <bits/stdc.h> using namespac…...
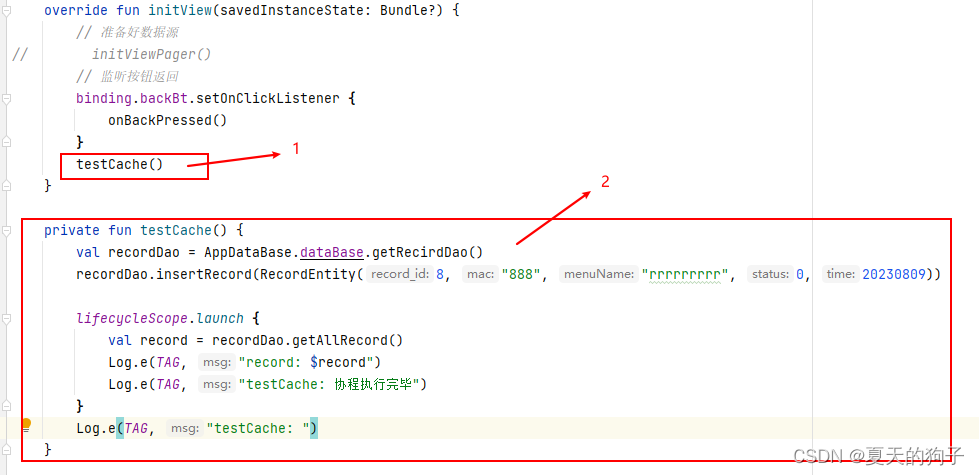
Android使用kotlin+协程+room数据库的简单应用
前言:一般主线程(UI线程)中是不能执行创建数据这些操作的,因为等待时间长。所以协程就是为了解决这个问题出现。 第一步:在模块级的build.gradle中引入 id com.android.application// roomid kotlin-androidid kotlin…...
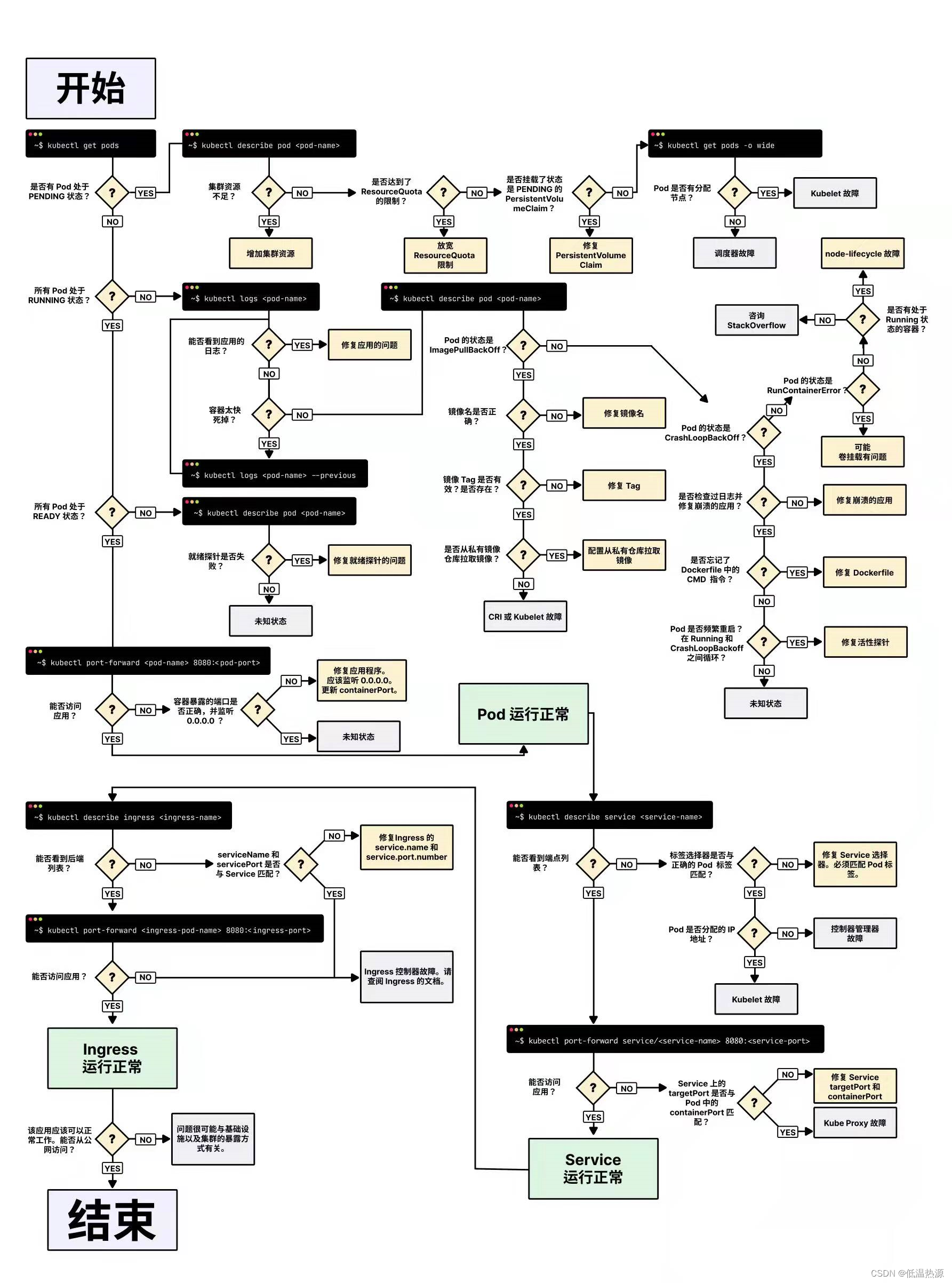
Kubernetes pod调度约束[亲和性 污点] 生命阶段 排障手段
调度约束 Kubernetes 是通过 List-Watch 的机制进行每个组件的协作,保持数据同步的,每个组件之间的设计实现了解耦。 用户是通过 kubectl 根据配置文件,向 APIServer 发送命令,在 Node 节点上面建立 Pod 和 Container。 APIServer…...
)
Matlab实现模拟退火算法(附上多个完整源码)
模拟退火算法(Simulated Annealing)是一种全局优化算法,其基本思想是通过模拟物理退火过程来寻找最优解。该算法可以应用于各种优化问题,如函数优化、组合优化、图形优化等。 文章目录 步骤简单案例完整仿真源码下载 步骤 在Mat…...
前后端分离------后端创建笔记(03)前后端对接(上)
本文章转载于【SpringBootVue】全网最简单但实用的前后端分离项目实战笔记 - 前端_大菜007的博客-CSDN博客 仅用于学习和讨论,如有侵权请联系 源码:https://gitee.com/green_vegetables/x-admin-project.git 素材:https://pan.baidu.com/s/…...

stable diffusion安装包和超火使用文档及提示词,数字人网址
一:文生图、图生图 1:stable diffusion:对喜欢二次元、美女小姐姐、大眼萌妹的人及其友好哈哈(o^^o) 1):关于安装包和模型包: 链接:https://pan.baidu.com/s/11_kguofh76gwhTBPUipepw 提取码…...

训练营:贪心篇
贪心就是:局部最优 1、455. 分发饼干 按照饼干分,从大到小,最大的给胃口最大能满足的 def findContentChildren455(g, s):g sorted(g,reverseTrue)s sorted(s,reverseTrue)j0c 0i0while(i<len(s) and j<len(g)):if s[i]>g[j]:c…...
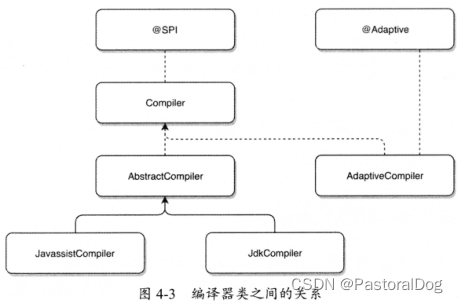
四、Dubbo扩展点加载机制
四、Dubbo扩展点加载机制 4.1 加载机制概述 Dubbo良好的扩展性与框架中针对不同场景使用合适设计模式、加载机制密不可分 Dubbo几乎所有功能组件都是基于扩展机制(SPI)实现的 Dubbo SPI 没有直接使用 Java SPI,在它思想上进行改进ÿ…...
[保研/考研机试] KY103 2的幂次方 上海交通大学复试上机题 C++实现
题目链接: KY103 2的幂次方 https://www.nowcoder.com/share/jump/437195121691999575955 描述 Every positive number can be presented by the exponential form.For example, 137 2^7 2^3 2^0。 Lets present a^b by the form a(b).Then 137 is present…...

时序预测 | MATLAB实现基于BP神经网络的时间序列预测-递归预测未来(多指标评价)
时序预测 | MATLAB实现基于BP神经网络的时间序列预测-递归预测未来(多指标评价) 目录 时序预测 | MATLAB实现基于BP神经网络的时间序列预测-递归预测未来(多指标评价)预测结果基本介绍程序设计参考资料 预测结果 基本介绍 Matlab实现BP神经网络时间序列预测未来(完整…...

组合模式(C++)
定义 将对象组合成树形结构以表示部分-整体’的层次结构。Composite使得用户对单个对象和组合对象的使用具有一致性(稳定)。 应用场景 在软件在某些情况下,客户代码过多地依赖于对象容器复杂的内部实现结构,对象容器内部实现结构(而非抽象接口)的变化…...

git上传问题记录
unable to access ‘https://github.com/songjiahao-wq/untitled.git/’: Failed to connect to github.com port 443 after 21086 ms: Couldn’t connect to serve 解决办法:修改 Git 的网络设置 打开git Bash运行,clash代理一般是下面的端口 # 注意…...

通过动态IP解决网络数据采集问题
动态地址的作用 说到Python网络爬虫,很多人都会遇到困难。最常见的就是爬取过程中IP地址被屏蔽。虽然大部分都是几个小时内自动解封的,但这对于分秒必争的python网络爬虫来说,是一个关键性的打击!当一个爬虫被阻塞时,…...

可重入锁,不可重入锁,死锁的多种情况,以及产生的原因,如何解决,synchronized采用的锁策略(渣女圣经)自适应的底层,锁清除,锁粗化,CAS的部分应用
一、💛 锁策略——接上一篇 6.分为可重入锁,不可重入锁 如果一个线程,针对一把锁,连续加锁两次,会出现死锁,就是不可重入锁,不会出现死锁,就是可重入锁。 如果一个线程,针…...
和JSON.stringify()用法)
JSON.parse()和JSON.stringify()用法
JSON.parse() 方法用于将 JSON 格式的字符串转换为 JavaScript 对象,而 JSON.stringify() 方法用于将 JavaScript 对象转换为 JSON 字符串。这两个方法可以组合使用来实现将数据从对象到字符串再到对象的转换。 示例 // 创建一个包含属性的 JavaScript 对象 var pe…...
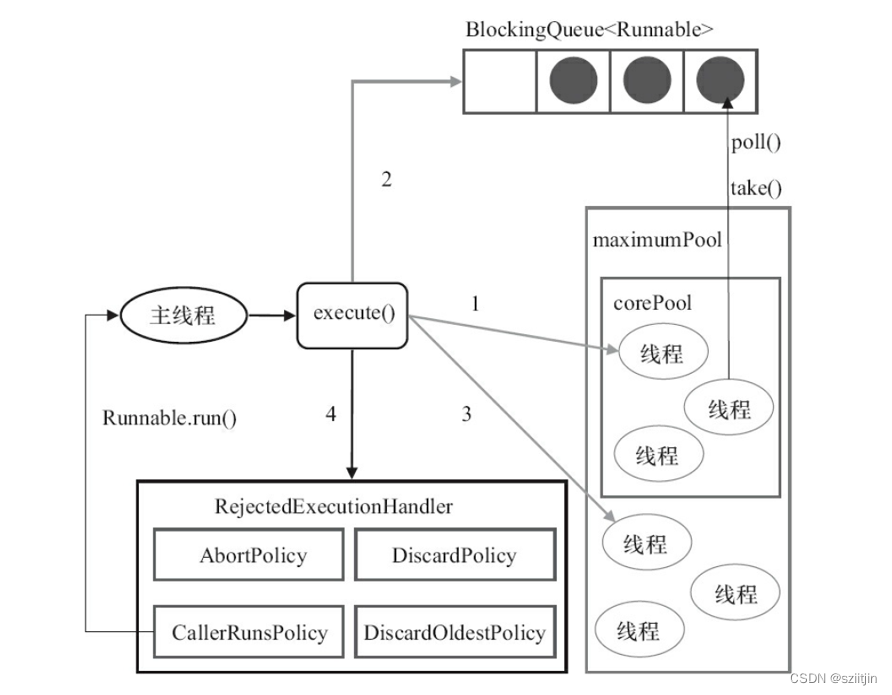
Android 并发编程--阻塞队列和线程池
一、阻塞队列 队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作…...

Playwright快速上手-1
前言 随着近年来对UI自动化测试的要求越来越高,,功能强大的测试框架也不断的涌现。本系列主讲的Playwright作为一款新兴的端到端测试框架,凭借其独特优势,正在逐渐成为测试工程师的热门选择。 本系列文章将着重通过示例讲解 Playwright python开发环境的搭建 …...
PPT颜色又丑又乱怎么办?
一、设计一套PPT时,可以从这5个方面进行设计 二、PPT颜色 (一)、PPT常用颜色分类 一个ppt需要主色、辅助色、字体色、背景色即可。 (二)、搭建PPT色彩系统 设计ppt时,根据如下几个步骤,依次选…...

python计算相关系数R
方法一: import numpy as np# 计算相关系数R def r(y_true, y_pred):y_true np.array(y_true)y_pred np.array(y_pred)corr np.corrcoef(y_true, y_pred)[0][1]return corrcorr r(yture, ypred)方法二 import scipy.stats # 计算皮尔逊相关指数,并…...

ThinkPad开机嘀嘀响或报2100/2110错误?可能是硬盘松了!自己动手检测与修复指南
ThinkPad开机嘀嘀响或报2100/2110错误?三步排查硬盘接触不良问题ThinkPad用户对那个标志性的开机"嘀嘀"声再熟悉不过——正常情况下它意味着系统自检通过。但当这个声音变成急促的报警音,伴随屏幕上出现"2100 Detection error"或&qu…...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

0.2毫秒快速启动的操作系统
在工业控制以及航空航天等核心场景,极速启动就是高可靠系统的生命线。0.2毫秒超快启动搭配硬件看门狗,让设备在掉电重启、异常恢复时瞬时归位,关键任务永不延误! https://www.bilibili.com/video/BV11mLY6VERt/?spm_id_from333.1…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理
碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝…...

三步破解百度网盘限速:免费获取真实下载链接的终极指南
三步破解百度网盘限速:免费获取真实下载链接的终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的龟速下载而苦恼吗?想要彻…...