使用 Python 在 NLP 中进行文本预处理
一、说明
自然语言处理 (NLP) 是人工智能 (AI) 和计算语言学的一个子领域,专注于使计算机能够理解、解释和生成人类语言。它涉及计算机和自然语言之间的交互,允许机器以对人类有意义和有用的方式处理、分析和响应文本或口头数据。
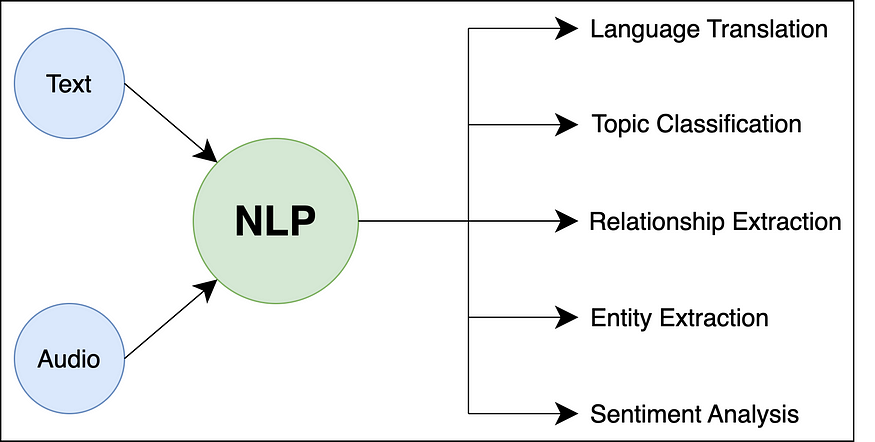
二、重要术语
NLP中使用的一些重要术语如下:
- 公文:在NLP中,文档是指单个文本单元,通常表示为段落,句子甚至单个单词。它是 NLP 任务中文本数据的基本构建块。例如,在包含客户评论的数据集中,每个单独的评论都被视为一个文档。
- 语料库: 语料库是为语言模型训练或分析而组装的文档集合。它是所研究语言或领域的代表性样本。例如,用于情绪分析的语料库可能包含从各种来源收集的数千条客户评论。
- 词汇:语料库的词汇是指整个文档集合中存在的独特单词集。它基本上表示在特定上下文中使用的单词。例如,医学文章语料库的词汇可能包括“疾病”、“治疗”和“症状”等词。
- 分割:分割是将文本块(例如段落)分解为单个句子的过程。正确的分割对于各种NLP任务至关重要,例如机器翻译或情感分析。例如,考虑文本:“我喜欢NLP。这太令人着迷了。分割会把它分成两句话:“我喜欢NLP”和“它很迷人”。
- 标记化:标记化是将句子或文本分解为单个单词或子单词的过程,称为标记。每个令牌代表一个有意义的单元,它是 NLP 预处理的基本步骤。例如,句子“自然语言处理是惊人的!”将被标记化为以下标记:[“自然”,“语言”,“处理”,“是”,“惊人”,“!”]。
- 停用词:停用词是语言中经常出现的常见词,对于 NLP 任务没有重要意义或信息。它们通常在预处理过程中被移除,以减少噪声并提高计算效率。英语中停用词的例子包括“the”、“and”、“is”等。
- 词干提取:词干提取是一种用于通过删除后缀将单词简化为其基本形式或根形式的技术。目标是简化单词,以便将同一根词的变体视为相同。但是,词干提取可能并不总是产生有意义或有效的单词。例如,在词干提取后,单词“running”和“runs”都将简化为“run”。
- 词形还原:词形还原类似于词干提取,但通过将单词简化为其基本形式或字典形式(引理)更进一步。此过程可确保生成的单词具有有效的含义。例如,在词形还原之后,“运行”和“运行”都将被词形还原为“运行”。
- NER 标记:命名实体识别 (NER) 是对文本中特定实体(例如人名、地点、组织、日期等)进行识别和分类的过程。这些实体通常使用适当的标签进行标记,例如“人员”、“位置”、“组织”等。例如,在句子“Apple Inc.总部位于库比蒂诺”中,NER标记会将“Apple Inc.”标记为组织,将“Cupertino”标记为位置。
- POS 标记:词性 (POS) 标记是为句子中的每个单词分配语法标签的过程,指示其句法角色和类别,例如名词、动词、形容词等。例如,在句子“她吃苹果”中,POS标签会将“她”标记为代词,将“吃”标记为动词,将“苹果”标记为名词。
- 分块:分块涉及将句子中的相邻单词分组为有意义的单元,例如名词短语或动词短语。这些块表示句法单元,可以帮助进一步分析或理解句子的结构。例如,在句子“大猫坐在垫子上”中,分块会将“大猫”识别为名词短语,将“坐在垫子上”标识为动词短语。
三、文本预处理
文本预处理是自然语言处理 (NLP) 中基本且必不可少的步骤。其主要目的是清理原始文本数据并将其转换为适合分析和预测建模的可呈现形式。以下是一些常见的文本预处理技术:
小写是将所有文本转换为小写的过程。这是 NLP 中常见的预处理步骤,可确保一致性并避免与区分大小写相关的问题。Python 中小写过程的实现如下:
def lowercase_text(text):return text.lower()# Test the function
input_text = "The Quick Brown Fox JUMPS Over 2 Lazy Dogs."
output_text = lowercase_text(input_text)
print(output_text) 在上面的代码中,该函数采用输入文本,并使用 Python 中可用于字符串的方法将其转换为小写。小写很有用,因为它有助于标准化文本数据并将同一单词的不同形式视为相同。例如,“Hello”、“hello”和“HELLO”在小写后都会转换为“hello”。这对于文本规范化和通过减少词汇量和以不区分大小写的方式处理单词来提高 NLP 模型的准确性至关重要。lowercase_text()lower()
删除标点符号涉及从文本中删除所有标点符号(例如逗号、句点、感叹号)。标点符号删除通常作为文本预处理的一部分执行,以清理 NLP 任务的数据。
import stringdef remove_punctuations(text):translator = str.maketrans('', '', string.punctuation)return text.translate(translator)# Test the function
input_text = "Hello, my name is John! How are you?"
output_text = remove_punctuations(input_text)
print(output_text) 在上面的代码中,我们使用函数从输入文本中删除所有标点符号。该函数使用模块中的常量来获取包含所有标点字符的字符串。然后,它使用该方法创建一个转换表,并从输入文本中删除标点符号表中的所有字符。remove_punctuations()string.punctuationstringstr.maketrans()translate()
删除特殊字符和数字涉及从文本中删除任何非字母字符(例如符号、数字)。此步骤对于文本预处理非常有用,可以专注于文本内容,而不会干扰数字或其他非字母字符。
import redef remove_special_characters_numbers(text):# Regular expression to remove non-alphabetic characters and numbersreturn re.sub(r'[^a-zA-Z\s]', '', text)# Test the function
input_text = "Hello, my name is Saif Ali and my age is 25! I was born on 1997-01-10."
output_text = remove_special_characters_numbers(input_text)
print(output_text) 在上面的代码中,我们使用函数从输入文本中删除所有特殊字符和数字。该函数使用(正则表达式)模块中的方法和正则表达式来匹配任何不是大写或小写字母或空格的字符。然后,它将这些字符替换为空字符串,有效地将它们从文本中删除。remove_special_characters_numbers()re.sub()rer'[^a-zA-Z\s]'
在处理从网页或 HTML 文档中提取的文本数据时,删除 HTML 标记非常重要。HTML 标记对文本内容没有贡献,需要将其删除以进行进一步的文本分析。
import redef remove_html_tags(text):clean_text = re.sub(r'<.*?>', '', text)return clean_text# Test the function
input_text = "<p>Hello, <b>my name</b> is <i>John</i>!</p>"
output_text = remove_html_tags(input_text)
print(output_text) 在上面的代码中,该函数使用正则表达式 () 从输入文本中删除所有 HTML 标记。正则表达式匹配以“<”开头,后跟任何字符 (“.*”)并以“>”结尾的任何模式。这将有效地删除任何 HTML 标记并保留文本内容。remove_html_tags()re.sub()r'<.*?>'
在处理来自网页或社交媒体的文本数据时,删除 URL 是一个常见的预处理步骤,其中 URL 不会向文本分析添加任何有意义的信息。
import redef remove_urls(text):clean_text = re.sub(r'http\S+|www\S+', '', text)return clean_text# Test the function
input_text = "Check out my LinkedIn account: https://www.linkedin.com/in/imsaifali/"
output_text = remove_urls(input_text)
print(output_text) 在上面的代码中,该函数使用正则表达式 () 从输入文本中删除任何 URL。正则表达式匹配任何以“http://”或“https://”开头的URL(http后跟非空格字符)或以“www”开头的URL。(www 后跟非空格字符)。这有效地从文本中删除了任何 URL。remove_urls()re.sub()r'http\S+|www\S+'\S+\S+
删除多余空格是一个文本预处理步骤,涉及删除文本中单词之间的任何不必要或过多的空格。这可确保文本干净且一致。
import redef remove_extra_spaces(text):clean_text = re.sub(r'\s+', ' ', text)return clean_text.strip()# Test the function
input_text = "Hello there, how are you?"
output_text = remove_extra_spaces(input_text)
print(output_text) 在上面的代码中,该函数使用正则表达式 () 删除一个或多个空格字符(空格、制表符、换行符)的任何序列,并将它们替换为单个空格。正则表达式匹配一个或多个空格字符。然后,该方法用于删除任何前导空格或尾随空格。remove_extra_spaces()re.sub()r'\s+'strip()
扩展收缩是将单词的收缩形式(例如,“不要”,“不能”)转换为其完整形式(例如,“不要”,“不能”)的过程。此步骤对于标准化文本和避免 NLP 任务中的潜在歧义非常有用。
contraction_mapping = {"ain't": "is not","aren't": "are not","can't": "cannot","couldn't": "could not","didn't": "did not","doesn't": "does not","don't": "do not","hadn't": "had not","hasn't": "has not","haven't": "have not","he's": "he is","he'll": "he will","he'd": "he would","i've": "I have","i'll": "I will","i'd": "I would","i'm": "I am","isn't": "is not","it's": "it is","it'll": "it will","it'd": "it would","let's": "let us","mightn't": "might not","mustn't": "must not","shan't": "shall not","she's": "she is","she'll": "she will","she'd": "she would","shouldn't": "should not","that's": "that is","there's": "there is","they're": "they are","they've": "they have","they'll": "they will","they'd": "they would","we're": "we are","we've": "we have","we'll": "we will","we'd": "we would","weren't": "were not","what's": "what is","won't": "will not","wouldn't": "would not","you're": "you are","you've": "you have","you'll": "you will","you'd": "you would","isn't": "is not","it's": "it is","that's": "that is","there's": "there is","here's": "here is","who's": "who is","what's": "what is","where's": "where is","when's": "when is","why's": "why is","how's": "how is",
}def expand_contractions(text):words = text.split()expanded_words = [contraction_mapping[word.lower()] if word.lower() in contraction_mapping else word for word in words]return ' '.join(expanded_words)# Test the function
input_text = "I can't believe it's already Friday!"
output_text = expand_contractions(input_text)
print(output_text) 在上面的代码中,我们使用函数来扩展输入文本中的收缩。该函数利用包含常见收缩及其完整形式的字典。它将输入文本拆分为单词,并检查每个单词(小写)是否存在于 .如果是这样,它将用其完整形式替换合同形式。expand_contractions()contraction_mappingcontraction_mapping
文本更正涉及修复文本数据中的常见拼写错误或其他错误。拼写检查和更正对于提高 NLP 任务的文本数据质量至关重要。
对于文本更正,我们将使用库,它为拼写检查和更正等文本处理任务提供了方便的界面。确保您已安装并安装。如果没有,请使用以下命令安装它们:TextBlobtextblobnltk
pip install textblob nltk现在,让我们更正文本:
from textblob import TextBlobdef correct_text(text):blob = TextBlob(text)corrected_text = blob.correct()return str(corrected_text)# Test the function
input_text = "I am lerning NLP with Pyhton."
output_text = correct_text(input_text)
print(output_text) 在上面的代码中,我们使用函数来更正输入文本。该函数使用库中的类从输入文本创建对象。然后将该方法应用于对象,该对象会自动执行拼写更正和其他文本更正。correct_text()TextBlobtextblobTextBlobcorrect()TextBlob
标记化是将文本分解为单个单词或标记的过程。这是 NLP 中必不可少的预处理步骤,为进一步分析准备文本。我们将使用该库,它提供了各种标记化方法。确保您已安装。如果没有,请使用以下命令安装它:nltknltk
pip install nltk现在,让我们执行标记化:
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenizedef tokenize_text(text):return word_tokenize(text)# Test the function
input_text = "The quick brown fox jumps over the lazy dog."
output_tokens = tokenize_text(input_text)
print(output_tokens) 在上面的代码中,我们使用函数来标记输入文本。该函数利用模块中的方法将文本拆分为单个单词(标记)。tokenize_text()word_tokenize()nltk.tokenize
停用词删除是一个文本预处理步骤,其中从文本中删除语义含义很少或没有语义的常用词(称为停用词),以减少干扰并专注于更有意义的单词。对于停用词删除,我们将使用该库,该库提供了各种语言的常见停用词列表。确保您已安装。如果没有,请使用以下命令安装它:nltknltk
pip install nltk现在,让我们执行停用词删除:
import nltk
nltk.download('punkt')
nltk.download('stopwords')
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))def remove_stopwords(text):words = text.split()filtered_words = [word for word in words if word.lower() not in stop_words]return ' '.join(filtered_words)# Test the function
input_text = "The quick brown fox jumps over the lazy dog."
output_text = remove_stopwords(input_text)
print(output_text) 在上面的代码中,我们使用函数从输入文本中删除停用词。该函数首先将文本拆分为单个单词,然后过滤掉从库中的语料库获取的英语停用词集中存在的单词。remove_stopwords()stopwordsnltk
词干提取是一种文本预处理技术,旨在通过删除后缀将单词简化为其基本形式或根形式。这个过程有助于减少词汇量,并将同一单词的不同形式视为相同。对于词干分析,我们将使用该库,该库提供各种词干分析器,包括波特词干分析器。确保您已安装。如果没有,请使用以下命令安装它:nltknltk
pip install nltk现在,让我们执行词干提取:
import nltk
nltk.download('punkt')
from nltk.stem import PorterStemmerdef perform_stemming(text):stemmer = PorterStemmer()words = text.split()stemmed_words = [stemmer.stem(word) for word in words]return ' '.join(stemmed_words)# Test the function
input_text = "jumps jumping jumped"
output_text = perform_stemming(input_text)
print(output_text) 在上面的代码中,我们使用函数将词干提取应用于输入文本。该函数利用了来自模块,这是一种广泛使用的词干提取算法。它将输入文本拆分为单个单词,对每个单词应用词干提取,然后将词干词干连接回单个字符串。perform_stemming()PorterStemmernltk.stem
词形还原是一种文本预处理技术,它使用词汇和形态分析将单词简化为其基本形式或根形式(引理)。与词干提取不同,词形还原可确保生成的单词是语言中的有效单词。对于词形还原,我们将使用库,它提供了一个 WordNet 词形还原器。确保您已安装。如果没有,请使用以下命令安装它:nltknltk
pip install nltk现在,让我们执行词形还原:
import nltk
nltk.download('punkt')
nltk.download('wordnet')
from nltk.stem import WordNetLemmatizerdef perform_lemmatization(text):lemmatizer = WordNetLemmatizer()words = text.split()lemmatized_words = [lemmatizer.lemmatize(word) for word in words]return ' '.join(lemmatized_words)# Test the function
input_text = "jumps jumping jumped"
output_text = perform_lemmatization(input_text)
print(output_text) 在上面的代码中,我们使用函数将词形还原应用于输入文本。该函数利用来自模块,该模块基于WordNet词汇数据库。它将输入文本拆分为单个单词,对每个单词应用词形还原,然后将词形还原的单词连接回单个字符串。perform_lemmatization()WordNetLemmatizernltk.stem
四、结论
文本预处理是自然语言处理 (NLP) 中的关键步骤,涉及将原始文本数据转换为适合分析和建模的干净且规范化的格式。基本技术包括小写、标记化、删除特殊字符和数字、删除停用词、词干提取、词形还原、删除 HTML 标记、删除 URL、扩展收缩和使用 TextBlob 等工具进行文本更正。
通过采用这些文本预处理技术,研究人员和从业者可以提高NLP任务的有效性,例如情感分析,信息检索,主题建模和文本分类。特定预处理步骤的选择可能会有所不同,具体取决于数据的性质和手头 NLP 应用程序的要求。高效的文本预处理在从文本数据中获得准确而有意义的见解方面起着至关重要的作用。
赛义夫·阿里
相关文章:
使用 Python 在 NLP 中进行文本预处理
一、说明 自然语言处理 (NLP) 是人工智能 (AI) 和计算语言学的一个子领域,专注于使计算机能够理解、解释和生成人类语言。它涉及计算机和自然语言之间的交互,允许机器以对人类有意义和有用的方式处理、分析…...
[足式机器人]Part3机构运动微分几何学分析与综合Ch03-1 空间约束曲线与约束曲面微分几何学——【读书笔记】
本文仅供学习使用 本文参考: 《机构运动微分几何学分析与综合》-王德伦、汪伟 《微分几何》吴大任 Ch01-4 平面运动微分几何学 3.1 空间曲线微分几何学概述3.1.1 矢量表示3.1.2 Frenet标架 连杆机构中的连杆与连架杆构成运动副,该运动副元素的特征点或特…...

pytest框架快速进阶篇-pytest前置和pytest后置,skipif跳过用例
一、Pytest的前置和后置方法 1.Pytest可以集成unittest实现前置和后置 importunittestimportpytestclassTestCase(unittest.TestCase):defsetUp(self)->None:print(unittest每个用例前置)deftearDown(self)->None:print(unittest每个用例后置)classmethoddefsetUpClass…...

Python 基础语法 | 常量表达式,变量,注释,输入输出
常量和表达式 我们可以把 Python 当成一个计算器,来进行一些算术运算 print(1 2 - 3) # 0 print(1 2 * 3) # 7 print(1 2 / 3) # 1.6666666666666665注意: print 是一个 Python 内置的 函数可以使用 - * / () 等运算符进行算术运算,先…...

SQL | 分组数据
10-分组数据 两个新的select子句:group by子句和having子句。 10.1-数据分组 上面我们学到了,使用SQL中的聚集函数可以汇总数据,这样,我们就能够对行进行计数,计算和,计算平均数。 目前为止,…...
)
软件测试技术之如何编写测试用例(6)
四、客户端兼容性测试 1、平台测试 市场上有很多不同的操作系统类型,最常见的有Windows、Unix、Macintosh、Linux等。Web应用系统的最终用户究竟使用哪一种操作系统,取决于用户系统的配置。这样,就可能会发生兼容性问题,同一个应…...

论文阅读——Adversarial Eigen Attack on Black-Box Models
Adversarial Eigen Attack on Black-Box Models 作者:Linjun Zhou, Linjun Zhou 攻击类别:黑盒(基于梯度信息),白盒模型的预训练模型可获得,但训练数据和微调预训练模型的数据不可得ÿ…...
-[自定义对话记忆与自定义记忆类])
自然语言处理从入门到应用——LangChain:记忆(Memory)-[自定义对话记忆与自定义记忆类]
分类目录:《自然语言处理从入门到应用》总目录 自定义对话记忆 本节介绍了几种自定义对话记忆的方法: from langchain.llms import OpenAI from langchain.chains import ConversationChain from langchain.memory import ConversationBufferMemoryllm…...

【C/C++】STL queue 非线程安全接口,危险!
STL 中的 queue 是非线程安全的,一个组合操作:front(); pop() 先读取队首元素然后删除队首元素,若是有多个线程执行这个组合操作的话,可能会发生执行序列交替执行,导致一些意想不到的行为。因此需要重新设计线程安全的…...
执行Lua脚本后一直查询不到Redis中的数据(附带问题详细排查过程,一波三折)
文章目录 执行Lua脚本后一直查询不到Redis中的数据(附带详细问题排查过程,一波三折)问题背景问题1:Lua脚本无法切库问题2:RedisTemlate切库报错问题3:序列化导致数据不一致问题4:Lua脚本中单引号…...
[高光谱]PyTorch使用CNN对高光谱图像进行分类
项目原地址: Hyperspectral-Classificationhttps://github.com/eecn/Hyperspectral-ClassificationDataLoader讲解: [高光谱]使用PyTorch的dataloader加载高光谱数据https://blog.csdn.net/weixin_37878740/article/details/130929358 一、模型加载 在…...
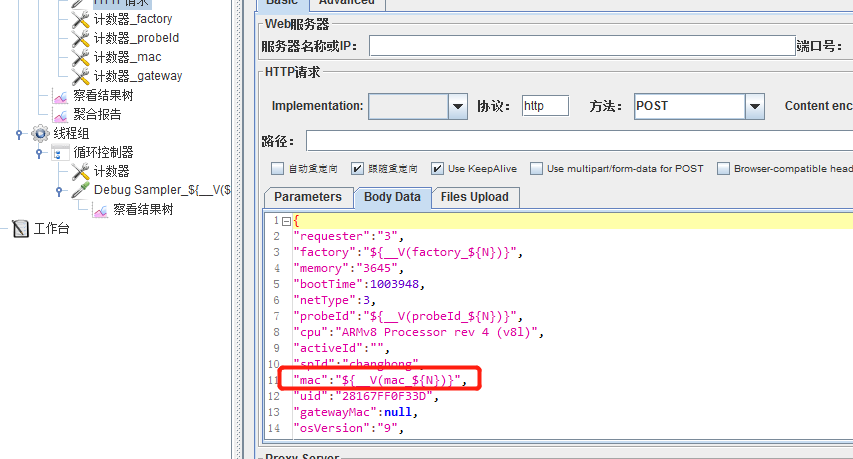
jmeter获取mysql数据
JDBC Connection Configuration Database URL: jdbc:mysql:// 数据库地址 /库名 JDBC Driver class:com.mysql.jdbc.Driver Username:账号 Password:密码 JDBC Request 字段含义 字段含义 Variable Name Bound to Pool 数据库连接池配置…...
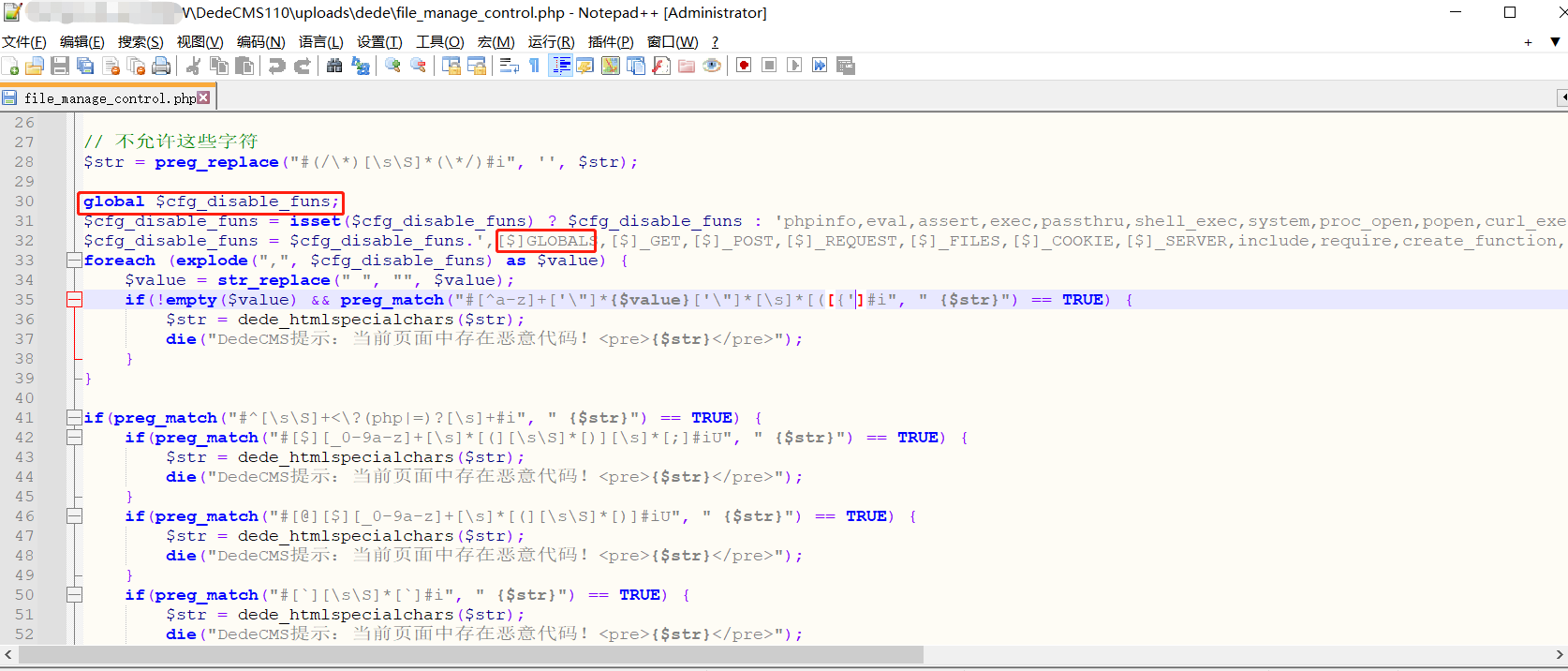
Dedecms V110最新版RCE---Tricks
前言 刚发现Dedecms更新了发布版本,顺便测试一下之前的day有没有修复,突然想到了新的tricks去实现RCE。 文章发布的时候估计比较晚了,一直没时间写了。 利用 /uploads/dede/article_string_mix.php /uploads/dede/article_template_rand.…...
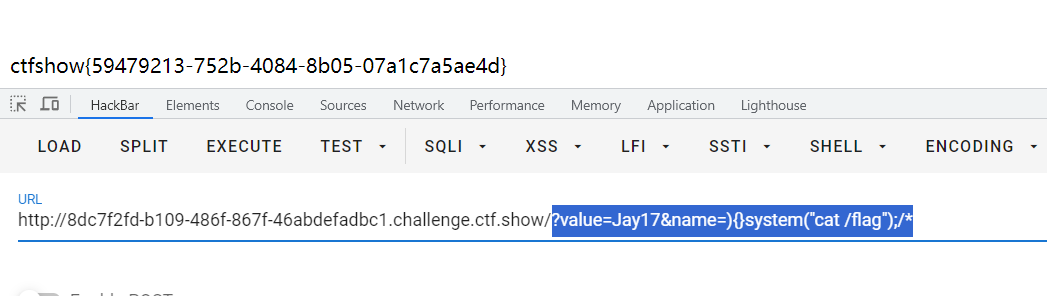
CTFshow 限时活动 红包挑战7、红包挑战8
CTFshow红包挑战7 写不出来一点,还是等了官方wp之后才复现。 直接给了源码 <?php highlight_file(__FILE__); error_reporting(2);extract($_GET); ini_set($name,$value);system("ls ".filter($_GET[1])."" );function filter($cmd){$cmd…...

Redis使用Lua脚本和Redisson来保证库存扣减中的原子性和一致性
文章目录 前言1.使用SpringBoot Redis 原生实现方式2.使用redisson方式实现3. 使用RedisLua脚本实现3.1 lua脚本代码逻辑 3.2 与SpringBoot集成 4. Lua脚本方式和Redisson的方式对比5. 源码地址6. Redis从入门到精通系列文章7. 参考文档 前言 背景:最近有社群技术交…...
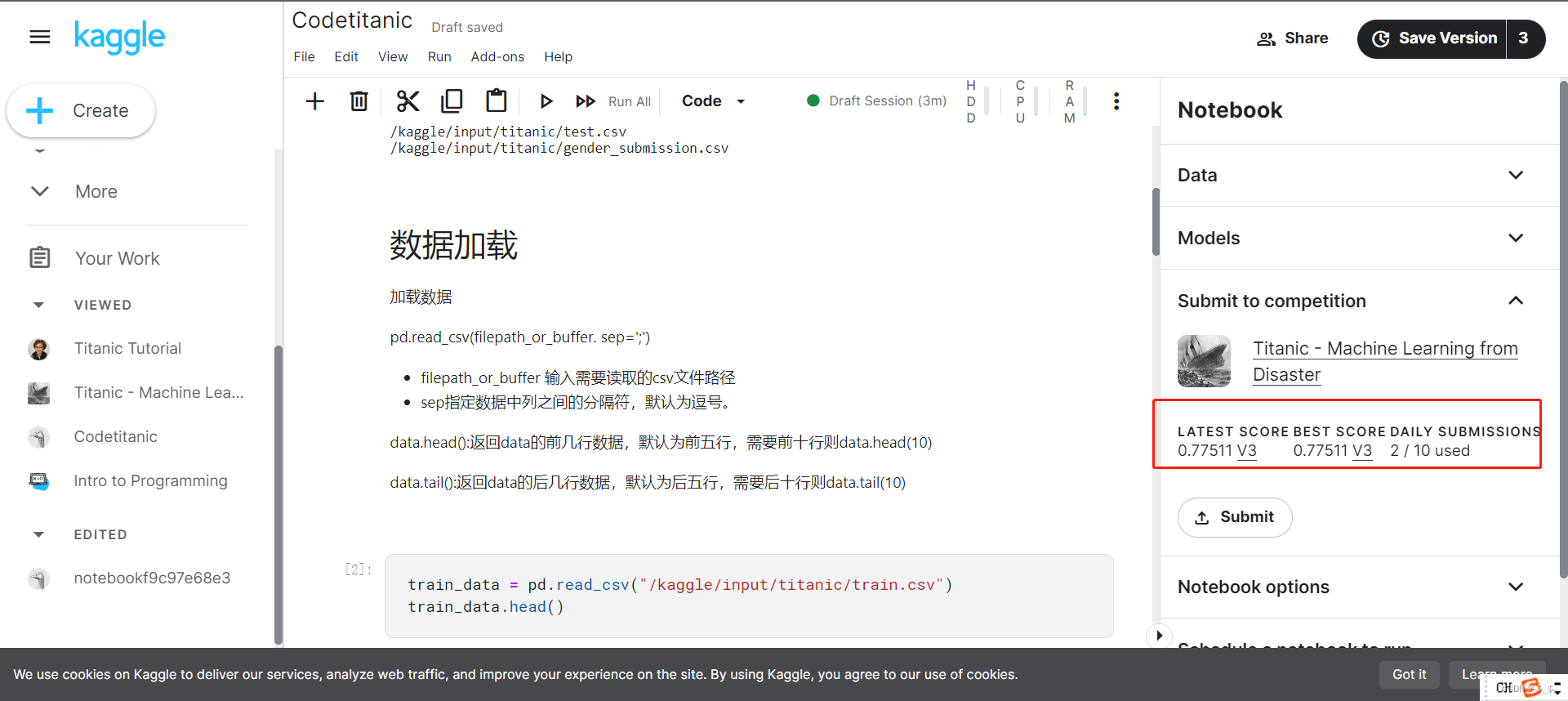
【从零开始学Kaggle竞赛】泰坦尼克之灾
目录 0.准备1.问题分析挑战流程数据集介绍结果提交 2.代码实现2.1 加载数据2.1.1 加载训练数据2.1.2 加载测试数据 2.2 数据分析2.3 模型建立与预测 3.结果提交 0.准备 注册kaggle账号后,进入titanic竞赛界面 https://www.kaggle.com/competitions/titanic 进入后界…...

输出无重复的3位数和计算无人机飞行坐标
编程题总结 题目一:输出无重复的3位数 题目描述 从{1,2,3,4,5,6,7,8,9}中随机挑选不重复的5个数字作为输入数组‘selectedDigits’,能组成多少个互不相同且无重复数字的3位数?请编写程》序,从小到大顺序,以数组形式输出这些3位…...

muduo 29 异步日志
目录 Muduo双缓冲异步日志模型: 异步日志实现: 为什么要实现非阻塞的日志...

Qt 对象序列化/反序列化
阅读本文大概需要 3 分钟 背景 日常开发过程中,避免不了对象序列化和反序列化,如果你使用 Qt 进行开发,那么有一种方法实现起来非常简单和容易。 实现 我们知道 Qt 的元对象系统非常强大,基于此属性我们可以实现对象的序列化和…...
)
从零学算法(非官方题库)
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构) B是A的子结构, 即 A中有出现和B相同的结构和节点值。 例如: 给定的树 A:3/ \4 5/ \1 2给定的树 B:4 / 1返回 true,因为 B 与 A 的一个子树拥有相…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

Agent开发面试通关攻略:吃透稳拿offer
阅读前置:2026年当下最卷也最缺人的AI岗位,一定是AI Agent开发。最近刷遍CSDN、牛客、力扣最新面经,发现一个非常明显的招聘趋势:普通大模型微调岗位饱和内卷,而AI Agent开发岗位人才严重缺口,薪资更高、竞…...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...
)
毕业设计 yolov11骨折检测医疗辅助系统(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景2.1 研究背景2.2 国内外研究现状2.3 研究意义 3 设计框架(骨折检测系统设计框架说明)3.1. 系统架构图3.2. 技术选型3.2.1 核心组件3.2.2 辅助工具 3.3. 核心模块设计3.3.1 YOLO模型训练模块训练流程图关键伪代码…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...

三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南
三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 还在为小爱音箱的"人工智障&q…...

3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南
3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...

终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题
终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否也经历过这样的…...