【量化课程】08_2.深度学习量化策略基础实战
文章目录
- 1. 深度学习简介
- 2. 常用深度学习模型架构
- 2.1 LSTM 介绍
- 2.2 LSTM在股票预测中的应用
- 3. 模块分类
- 3.1 卷积层
- 3.2 池化层
- 3.3 全连接层
- 3.4 Dropout层
- 4. 深度学习模型构建
- 5. 策略实现
1. 深度学习简介
深度学习是模拟人脑进行分析学习的神经网络。
2. 常用深度学习模型架构
- 深度神经网络(DNN)
- 卷积神经网络(CNN)
- 马尔可夫链(MC)
- 玻尔兹曼机(BM)
- 生成对抗网络(GAN)
- 长短期记忆网络(LSTM)
2.1 LSTM 介绍
长短期记忆网络(LSTM)是一种常用于处理序列数据的循环神经网络(RNN)的变体,被广泛应用于自然语言处理、语音识别、时间序列预测等任务中。
LSTM通过门控机制解决了传统RNN中的梯度问题,能够有效地处理序列数据,并在多个领域取得了显著的成果。
2.2 LSTM在股票预测中的应用
LSTM在量化预测股票方面被广泛应用。它可以利用历史股票价格和交易量等数据来学习股票价格的趋势和波动,从而进行未来的预测。
在股票预测中,LSTM可以接受时间序列数据作为输入,并通过递归地更新隐藏状态来捕获长期依赖关系。它可以通过学习历史价格和交易量等特征的模式,对未来的股票价格进行预测。
通过将股票历史数据作为训练样本,LSTM可以学习不同时间尺度上的模式,例如每日、每周或每月的波动情况。它还可以利用技术指标、市场情绪数据等辅助信息,以提高预测准确性。
在实际应用中,研究人员和投资者通过训练LSTM模型来预测股票的价格趋势、波动情况和交易信号。这些预测结果可以用于制定投资策略、风险管理和决策制定等方面。
需要注意的是,股票市场受到多种因素的影响,包括经济因素、政治事件和市场心理等。LSTM在股票预测中的应用并不是完全准确的,因此在实际应用中需要结合其他因素进行综合分析和决策。此外,过度依赖LSTM模型所做的预测结果也可能存在风险,投资者仍需谨慎分析和评估。
3. 模块分类
3.1 卷积层
卷积层是深度学习中的基本层之一,通过卷积操作对输入数据进行特征提取和特征映射,并利用参数共享和局部连接等机制提高模型的参数效率。
- 一维卷积层
- 二维卷积层
- 三维卷积层
3.2 池化层
平均池化和最大池化是卷积神经网络中常用的池化操作,用于减少特征图的维度,并提取出重要的特征信息。
- 平均池化
- 最大池化
3.3 全连接层
全连接层是神经网络中的一种常见层类型。在全连接层中,每个输入神经元与输出层中的每个神经元都有连接。每个连接都有一个权重,用于调整输入神经元对于输出神经元的影响。全连接层的输出可以通过激活函数进行非线性变换。
3.4 Dropout层
Dropout层是一种正则化技术,用于在训练过程中随机丢弃一部分输入神经元,以减少过拟合的风险。Dropout层通过随机断开神经元之间的连接来实现丢弃操作。在每个训练迭代中,Dropout层会随机选择一些神经元进行丢弃,并在前向传播和反向传播过程中不使用这些丢弃的神经元。
4. 深度学习模型构建
- 通过模块堆叠将输入层、中间层、输出层连接,然后构建模块进行初始化
- 训练模型
- 模型预测
5. 策略实现
本部分将介绍如何在BigQuant实现一个基于LSTM的选股策略
from biglearning.api import M
from biglearning.api import tools as T
from bigdatasource.api import DataSource
from biglearning.module2.common.data import Outputs
from zipline.finance.commission import PerOrder
import pandas as pd
import math# LSTM模型训练和预测
def m4_run_bigquant_run(input_1, input_2, input_3):df = input_1.read_pickle()feature_len = len(input_2.read_pickle())df['x'] = df['x'].reshape(df['x'].shape[0], int(feature_len), int(df['x'].shape[1]/feature_len))data_1 = DataSource.write_pickle(df)return Outputs(data_1=data_1)# LSTM模型训练和预测的后处理
def m4_post_run_bigquant_run(outputs):return outputs# LSTM模型训练和预测
def m8_run_bigquant_run(input_1, input_2, input_3):df = input_1.read_pickle()feature_len = len(input_2.read_pickle())df['x'] = df['x'].reshape(df['x'].shape[0], int(feature_len), int(df['x'].shape[1]/feature_len))data_1 = DataSource.write_pickle(df)return Outputs(data_1=data_1)# LSTM模型训练和预测的后处理
def m8_post_run_bigquant_run(outputs):return outputs# 模型评估和排序
def m24_run_bigquant_run(input_1, input_2, input_3):pred_label = input_1.read_pickle()df = input_2.read_df()df = pd.DataFrame({'pred_label':pred_label[:,0], 'instrument':df.instrument, 'date':df.date})df.sort_values(['date','pred_label'],inplace=True, ascending=[True,False])return Outputs(data_1=DataSource.write_df(df), data_2=None, data_3=None)# 模型评估和排序的后处理
def m24_post_run_bigquant_run(outputs):return outputs# 初始化策略
def m19_initialize_bigquant_run(context):# 从options中读取数据context.ranker_prediction = context.options['data'].read_df()# 设置佣金费率context.set_commission(PerOrder(buy_cost=0.0003, sell_cost=0.0013, min_cost=5))stock_count = 30# 根据股票数量设置权重context.stock_weights = T.norm([1 / math.log(i + 2) for i in range(0, stock_count)])context.max_cash_per_instrument = 0.9context.options['hold_days'] = 5# 处理每个交易日的数据
def m19_handle_data_bigquant_run(context, data):# 获取当日的预测结果ranker_prediction = context.ranker_prediction[context.ranker_prediction.date == data.current_dt.strftime('%Y-%m-%d')]is_staging = context.trading_day_index < context.options['hold_days']cash_avg = context.portfolio.portfolio_value / context.options['hold_days']cash_for_buy = min(context.portfolio.cash, (1 if is_staging else 1.5) * cash_avg)cash_for_sell = cash_avg - (context.portfolio.cash - cash_for_buy)positions = {e.symbol: p.amount * p.last_sale_pricefor e, p in context.perf_tracker.position_tracker.positions.items()}if not is_staging and cash_for_sell > 0:equities = {e.symbol: e for e, p in context.perf_tracker.position_tracker.positions.items()}instruments = list(reversed(list(ranker_prediction.instrument[ranker_prediction.instrument.apply(lambda x: x in equities and not context.has_unfinished_sell_order(equities[x]))])))for instrument in instruments:context.order_target(context.symbol(instrument), 0)cash_for_sell -= positions[instrument]if cash_for_sell <= 0:breakbuy_cash_weights = context.stock_weightsbuy_instruments = list(ranker_prediction.instrument[:len(buy_cash_weights)])max_cash_per_instrument = context.portfolio.portfolio_value * context.max_cash_per_instrumentfor i, instrument in enumerate(buy_instruments):cash = cash_for_buy * buy_cash_weights[i]if cash > max_cash_per_instrument - positions.get(instrument, 0):cash = max_cash_per_instrument - positions.get(instrument, 0)if cash > 0:context.order_value(context.symbol(instrument), cash)# 准备工作
def m19_prepare_bigquant_run(context):pass# 获取2020年至2021年股票数据
m1 = M.instruments.v2(start_date='2020-01-01',end_date='2021-01-01',market='CN_STOCK_A',instrument_list=' ',max_count=0
)# 使用高级自动标注器获取标签
m2 = M.advanced_auto_labeler.v2(instruments=m1.data,label_expr="""
shift(close, -5) / shift(open, -1)-1clip(label, all_quantile(label, 0.01), all_quantile(label, 0.99))where(shift(high, -1) == shift(low, -1), NaN, label)
""",start_date='',end_date='',benchmark='000300.SHA',drop_na_label=True,cast_label_int=False
)# 标准化标签数据
m13 = M.standardlize.v8(input_1=m2.data,columns_input='label'
)# 输入特征
m3 = M.input_features.v1(features="""close_0/mean(close_0,5)
close_0/mean(close_0,10)
close_0/mean(close_0,20)
close_0/open_0
open_0/mean(close_0,5)
open_0/mean(close_0,10)
open_0/mean(close_0,20)"""
)# 抽取基础特征
m15 = M.general_feature_extractor.v7(instruments=m1.data,features=m3.data,start_date='',end_date='',before_start_days=30
)# 提取派生特征
m16 = M.derived_feature_extractor.v3(input_data=m15.data,features=m3.data,date_col='date',instrument_col='instrument',drop_na=True,remove_extra_columns=False
)# 标准化基础特征
m14 = M.standardlize.v8(input_1=m16.data,input_2=m3.data,columns_input='[]'
)# 合并标签和特征
m7 = M.join.v3(data1=m13.data,data2=m14.data,on='date,instrument',how='inner',sort=False
)# 将特征转换成二进制数据
m26 = M.dl_convert_to_bin.v2(input_data=m7.data,features=m3.data,window_size=5,feature_clip=5,flatten=True,window_along_col='instrument'
)# 使用m4_run_bigquant_run函数运行缓存模式
m4 = M.cached.v3(input_1=m26.data,input_2=m3.data,run=m4_run_bigquant_run,post_run=m4_post_run_bigquant_run,input_ports='',params='{}',output_ports=''
)# 获取2021年至2022年股票数据
m9 = M.instruments.v2(start_date=T.live_run_param('trading_date', '2021-01-01'),end_date=T.live_run_param('trading_date', '2022-01-01'),market='CN_STOCK_A',instrument_list='',max_count=0
)# 抽取基础特征
m17 = M.general_feature_extractor.v7(instruments=m9.data,features=m3.data,start_date='',end_date='',before_start_days=30
)# 提取派生特征
m18 = M.derived_feature_extractor.v3(input_data=m17.data,features=m3.data,date_col='date',instrument_col='instrument',drop_na=True,remove_extra_columns=False
)# 标准化基础特征
m25 = M.standardlize.v8(input_1=m18.data,input_2=m3.data,columns_input='[]'
)# 将特征转换成二进制数据
m27 = M.dl_convert_to_bin.v2(input_data=m25.data,features=m3.data,window_size=5,feature_clip=5,flatten=True,window_along_col='instrument'
)# 使用m8_run_bigquant_run函数运行缓存模式
m8 = M.cached.v3(input_1=m27.data,input_2=m3.data,run=m8_run_bigquant_run,post_run=m8_post_run_bigquant_run,input_ports='',params='{}',output_ports=''
)# 构造LSTM模型的输入层
m6 = M.dl_layer_input.v1(shape='7,5',batch_shape='',dtype='float32',sparse=False,name=''
)# 构造LSTM模型的LSTM层
m10 = M.dl_layer_lstm.v1(inputs=m6.data,units=32,activation='tanh',recurrent_activation='hard_sigmoid',use_bias=True,kernel_initializer='glorot_uniform',recurrent_initializer='Orthogonal',bias_initializer='Zeros',unit_forget_bias=True,kernel_regularizer='None',kernel_regularizer_l1=0,kernel_regularizer_l2=0,recurrent_regularizer='None',recurrent_regularizer_l1=0,recurrent_regularizer_l2=0,bias_regularizer='None',bias_regularizer_l1=0,bias_regularizer_l2=0,activity_regularizer='None',activity_regularizer_l1=0,activity_regularizer_l2=0,kernel_constraint='None',recurrent_constraint='None',bias_constraint='None',dropout=0,recurrent_dropout=0,return_sequences=False,implementation='0',name=''
)# 构造LSTM模型的Dropout层
m12 = M.dl_layer_dropout.v1(inputs=m10.data,rate=0.2,noise_shape='',name=''
)# 构造LSTM模型的全连接层1
m20 = M.dl_layer_dense.v1(inputs=m12.data,units=30,activation='tanh',use_bias=True,kernel_initializer='glorot_uniform',bias_initializer='Zeros',kernel_regularizer='None',kernel_regularizer_l1=0,kernel_regularizer_l2=0,bias_regularizer='None',bias_regularizer_l1=0,bias_regularizer_l2=0,activity_regularizer='None',activity_regularizer_l1=0,activity_regularizer_l2=0,kernel_constraint='None',bias_constraint='None',name=''
)# 构造LSTM模型的Dropout层2
m21 = M.dl_layer_dropout.v1(inputs=m20.data,rate=0.2,noise_shape='',name=''
)# 构造LSTM模型的全连接层2
m22 = M.dl_layer_dense.v1(inputs=m21.data,units=1,activation='tanh',use_bias=True,kernel_initializer='glorot_uniform',bias_initializer='Zeros',kernel_regularizer='None',kernel_regularizer_l1=0,kernel_regularizer_l2=0,bias_regularizer='None',bias_regularizer_l1=0,bias_regularizer_l2=0,activity_regularizer='None',activity_regularizer_l1=0,activity_regularizer_l2=0,kernel_constraint='None',bias_constraint='None',name=''
)# 初始化LSTM模型
m34 = M.dl_model_init.v1(inputs=m6.data,outputs=m22.data
)# 训练LSTM模型
m5 = M.dl_model_train.v1(input_model=m34.data,training_data=m4.data_1,optimizer='RMSprop',loss='mean_squared_error',metrics='mae',batch_size=256,epochs=5,n_gpus=0,verbose='2:每个epoch输出一行记录'
)# 使用LSTM模型进行预测
m11 = M.dl_model_predict.v1(trained_model=m5.data,input_data=m8.data_1,batch_size=1024,n_gpus=0,verbose='2:每个epoch输出一行记录'
)# 使用m24_run_bigquant_run函数运行缓存模式
m24 = M.cached.v3(input_1=m11.data,input_2=m18.data,run=m24_run_bigquant_run,post_run=m24_post_run_bigquant_run,input_ports='',params='{}',output_ports=''
)# 执行交易
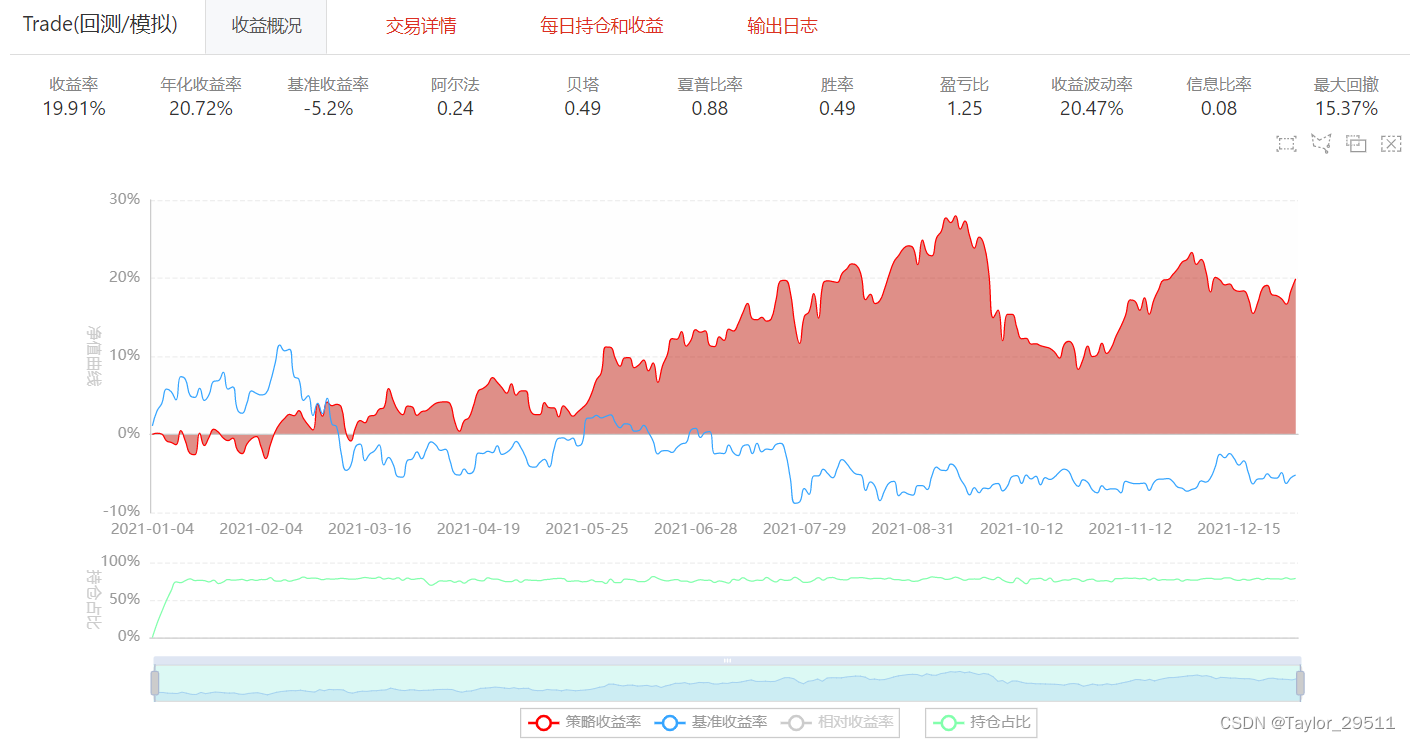
m19 = M.trade.v4(instruments=m9.data,options_data=m24.data_1,start_date='',end_date='',initialize=m19_initialize_bigquant_run,handle_data=m19_handle_data_bigquant_run,prepare=m19_prepare_bigquant_run,volume_limit=0.025,order_price_field_buy='open',order_price_field_sell='close',capital_base=1000000,auto_cancel_non_tradable_orders=True,data_frequency='daily',price_type='后复权',product_type='股票',plot_charts=True,backtest_only=False,benchmark='000300.SHA'
)
相关文章:
【量化课程】08_2.深度学习量化策略基础实战
文章目录 1. 深度学习简介2. 常用深度学习模型架构2.1 LSTM 介绍2.2 LSTM在股票预测中的应用 3. 模块分类3.1 卷积层3.2 池化层3.3 全连接层3.4 Dropout层 4. 深度学习模型构建5. 策略实现 1. 深度学习简介 深度学习是模拟人脑进行分析学习的神经网络。 2. 常用深度学习模型架…...
12-数据结构-数组、矩阵、广义表
数组、矩阵、广义表 目录 数组、矩阵、广义表 一、数组 二.矩阵 三、广义表 一、数组 这一章节理解基本概念即可。数组要看清其实下标是多少,并且二维数组,存取数据,要先看清楚是按照行存还是按列存,按行则是正常一行一行的去读…...
Idea 反编译jar包
实际项目中,有时候会需要更改jar包源码来达到业务需求,本文章将介绍一下如何通过Idea来进行jar反编译 1、Idea安装decompiler插件 2、找到decompiler插件文件夹 decompiler插件文件夹路径为:idea安装路径/plugins/java-decompiler/lib 3、…...
【Git】安装以及基本操作
目录 一、初识Git二、 在Linux底下安装Git一)centOS二)Ubuntu 三、 Git基本操作一) 创建本地仓库二)配置本地仓库三)认识工作区、暂存区、版本库四)添加文件五)查看.git文件六)修改文…...
)
Spring创建Bean的过程(2)
上一节介绍了Spring创建过程中的两个重要的接口,那么它们在创建Bean的过程中起到了什么作用呢?接下来请看: Spring有三种方式寻找 xml 配置文件,根据 xml 文件内容来构建 ApplicationContext,分别为ClassPathXmlAppli…...

Linux 终端操作命令(2)内部命令
Linux 终端操作命令 也称Shell命令,是用户与操作系统内核进行交互的命令解释器,它接收用户输入的命令并将其传递给操作系统进行执行,可分为内部命令和外部命令。内部命令是Shell程序的一部分,而外部命令是独立于Shell的可执行程序…...
【Git】大大大问题之syntax error near unexpected token `(‘ 的错误解决办法
话不多说,先上图: 如图,因为在linux环境里,文件路径中含有括号(),因此报错! 解决办法 等同于 :linux下解决bash: syntax error near unexpected token (’ 的错误&am…...
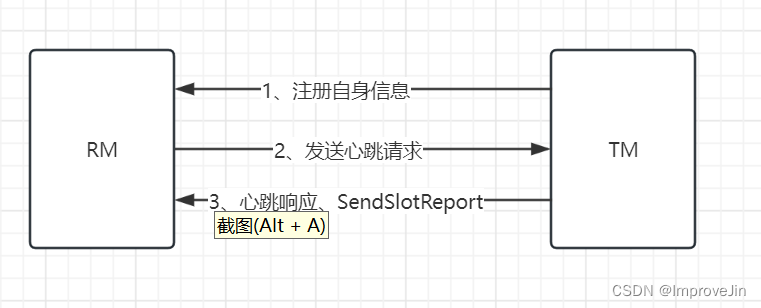
Flink源码之TaskManager启动流程
从启动命令flink-daemon.sh可以看出TaskManger入口类为org.apache.flink.runtime.taskexecutor.TaskManagerRunner TaskManagerRunner::main TaskManagerRunner::runTaskManagerProcessSecurely TaskManagerRunner::runTaskManager //构造TaskManagerRunner并调用start()方法 …...

加入微软MCPP有什么优势?
目录 专业认可 技术支持 销售和市场推广支持 培训和认证 业务机会和合作伙伴网络...

leetcode做题笔记78子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 思路一:回溯 void backtracking(int* nums, int numsSize, int** res, int* ret…...

Skywalking-9.6.0系列之本地源码编译并启动
Skywalking相信有很多人使用过,通过容器或者下载安装包进行安装的,今天从源代码角度,拉取、构建、启动。 官方文档步骤简洁明了,我这边会结合自己遇到的一些问题做出总结。 当前构建资源版本: MAC 10.15.7IDEA 2021.…...
proteus结合keil-arm编译器构建STM32单片机项目进行仿真
proteus是可以直接创建设计图和源码的,但是源码编译它需要借助keil-arm编译器,也就是我们安装keil-mdk之后自带的编译器。 下面给出一个完整的示例,主要是做一个LED灯闪烁的效果。 新建工程指定路径,Schematic,PCB layout都选择默…...

第五十三天
●剪辑——Pr 剪辑(Film editing),即将影片制作中所拍摄的大量素材,经过选择、取舍、分解与组接,最终完成一个连贯流畅、含义明确、主题鲜明并有艺术感染力的作品。 •线性编辑 将素材按时间顺序连接成新的连续画面的技术 •非线性编辑 …...

gorm基本操作
一、gorm安装 1.下载gorm go get -u gorm.io/gorm //gorm框架 go get -u gorm.io/driver/mysql //驱动2.mysql准备工作 mysql> create database godb; mysql> grant all on *.* to admin% identified by golang123!; mysql> flush privileges;3.导入gorm框架 impo…...
)
华为OD机试 - 排队游戏(Java JS Python)
题目描述 新来的老师给班里的同学排一个队。 每个学生有一个影力值。 一些学生是刺头,不会听老师的话,自己选位置,非刺头同学在剩下的位置按照能力值从小到大排。 对于非刺头同学,如果发现他前面有能力值比自己高的同学,他不满程度就增加,增加的数量等于前面能力值比…...

滚动条样式更改
::-webkit-scrollbar 滚动条整体部分,可以设置宽度啥的 ::-webkit-scrollbar-button 滚动条两端的按钮 ::-webkit-scrollbar-track 外层轨道 ::-webkit-scrollbar-track-piece 内层滚动槽 ::-webkit-scrollbar-thumb 滚动的滑块 ::-webkit-scrollbar…...
掌握Python的X篇_33_MATLAB的替代组合NumPy+SciPy+Matplotlib
numPy 通常与 SciPy( Scientific Python )和 Matplotlib (绘图库)一起使用,这种组合广泛用于替代 MatLab,是一个强大的科学计算环境,有助于我们通过 Python 学习数据科学或者机器学习。 文章目录 1. numpy1.1 numpy简介1.2 矩阵类型的nparra…...

Python解决-力扣002-两数相加
两数相加:链表表示的逆序整数求和 在这篇技术博客中,我们将讨论一个力扣(LeetCode)上的编程题目:两数相加。这个问题要求我们处理两个非空链表,它们表示两个非负整数。每个链表中的数字都是逆序存储的&…...
nginx基于源码安装的方式对静态页面、虚拟主机(IP、端口、域名)和日志文件进行配置
一.静态页面 1.更改页面内容 2.更改配置文件 3.测试 二.虚拟主机配置 1.基于IP (1)在html目录下新建目录存放测试文件 (2)修改nginx.conf文件,在htttp模块中配置两个server模块分别对应两个IP (3&am…...
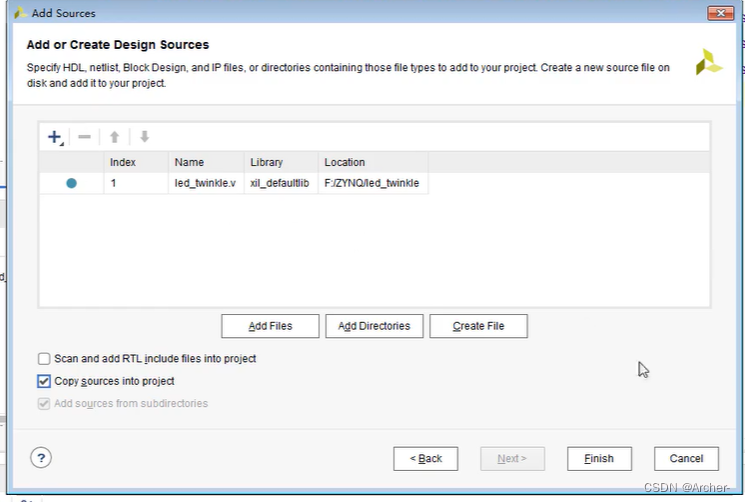
[FPAG开发]使用Vivado创建第一个程序
1 打开Vivado软件,新建项目 选择一个纯英文路径 选择合适的型号 产品型号ZYNQ-7010xc7z010clg400-1ZYNQ-7020xc7z010clg400-2 如果型号选错,可以单击这里重新选择 2 创建工程源文件 可以看到文件创建成功 双击文件打开,插入代码 modul…...

用数字逻辑门复刻柏林钟:从二进制编码到硬件实现
1. 项目概述:用数字电路复刻“柏林钟”作为一个在柏林长大的孩子,我从小就对库达姆大街上的那座“柏林钟”着迷。它不像传统时钟那样用指针或数字告诉你时间,而是通过几排不同颜色的发光方块,以一种近乎艺术的方式呈现时间。这种独…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...

榨干Codex!OpenAI工程师亲授Codex真正用法
你可能把 Codex 当编程助手用,改改代码,跑跑测试。但它的能力远不止于此。OpenAI 的客户支持工程师 Jason(jxnlco)告诉你,Codex 其实是一套完整的电脑工作系统,从语音输入到自动化,从浏览器操控…...

179个核心职位,50个公司分类,中国大模型产业全栈
最后 对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大? 答案只有一个:人工智能(尤其是大模型方向)…...

CentOS 8/Stream 8系统DNF换源后,安装软件还是慢?试试这几个排查命令和优化技巧
CentOS 8/Stream 8系统DNF换源后安装缓慢的深度排查与优化指南当你已经按照教程将CentOS 8/Stream 8的DNF源切换为国内镜像,却发现软件安装速度依然不尽如人意时,这种体验确实令人沮丧。作为长期使用CentOS系统的技术专家,我完全理解这种&quo…...

反向海淘站点常见配置故障复盘与数据一致性优化方案
摘要反向海淘独立站运行过程中,容易出现价格换算异常、页面语种错乱、商品同步失败、订单状态停滞、运费计算偏差等问题。多数故障并非系统底层缺陷,而是配置逻辑理解偏差、数据规范不统一引发。本文结合实际运维场景,汇总高频故障成因&#…...