【代码质量】认知复杂度(COGNITIVE COMPLEXITY)一种衡量可理解性的新方法
白皮书地址
摘要:圈复杂度最初是作为“可测试性和模块控制流的“可维护性”。虽然它擅长于衡量前者,但它的数学模型不能产生一个令人满意的值来衡量后者。本文描述一种打破数学度量模型的新度量模型来评估代码,以弥补圈复杂度的缺点,更准确地反映理解难度的测量方法,对于方法、类和应用程序都是有效的。
1、介绍
Thomas J. McCabe的圈复杂度长期以来,作为测量方法控制流的复杂性的标准。它最初的目的是“识别”软件模块将难以测试或维护”,同时它可以精确计算完全覆盖一个方法所需的最小测试用例数量,但是,它对可理解性的度量满足不了人们需要。这是因为具有相同圈复杂度的方法,不一定会给维护者带来同样的困难,导致一种感觉通过高估某些结构,而低估其他结构。同时,圈复杂度不再是全面的。用一种在1976年的Fortran环境中,它不包括现代语言结构,比如try/catch和λ表达式。最后,因为每种方法的最小圈复杂度得分为1,所以它是不可能知道一个具有高的聚合圈复杂度的类到底是一个易于维护的大类,还是一个具有复杂控制流的小类。除了在类水平上,人们普遍认为应用程序的圈复杂度得分,是与其代码总数相关联。换句话说,圈复杂度是在方法级别以上很少使用。作为这些问题的补救措施,认知复杂性已经制定了解决现代语言结构的方案,并在类和应用程序水平上产生有意义的价值。更重要的是,它偏离了基于评估代码的数学模型,使它可以产生评估的控制流与程序员对理解这些代码所需要的心理或认知努力的认知流对应起来。
1.1 问题讨论
用一个例子来开始引出复杂性的讨论,以下两种方法具有相同的圈复杂度,但是在可理解性方面有显著不同。
int sumOfPrimes(int max) { // +1
int total = 0;
OUT: for (int i = 1; i <= max; ++i) { // +1
for (int j = 2; j < i; ++j) { // +1
if (i % j == 0) { // +1
continue OUT;
}
}
total += i;
}
return total;
} // 圈复杂度 4
String getWords(int number) { // +1
switch (number) {
case 1: // +1
return "one";
case 2: // +1
return "a couple";
case 3: // +1
return “a few”;
default:
return "lots";
}
} // 圈复杂度 4
基于数学模型的圈复杂度,这两个方法的圈复杂度是相等的。然而,直观上很明显,sumofprime的控制流程比getWords更难理解。这就是为什么认知复杂度(Cognitive Complexity)放弃这种基于评估控制流的数学模型,而去使用一套简单、面向程序员直觉的规则。
1.2 基本准则及方法
认知复杂性评分是根据以下三个基本规则:
-
忽略简写:把多句代码缩写为一句可读的代码,不改变理解难度;
Ignore structures that allow multiple statements to be readably shorthanded into one -
对线性的代码逻辑中,出现一个打断逻辑的东西,难度+1;
Increment (add one) for each break in the linear flow of the code -
当打断逻辑的是一个嵌套时,难度+1;
Increment when flow-breaking structures are nested
以下四种不同类型,均会使认知复杂度得分加一:
- Nesting:把一段代码逻辑嵌套在另一段逻辑中;
- Structural:被嵌套的控制流结构;
- Fundamental:不受嵌套影响的语句;
- Hybrid:一些控制流结构,但不包含在嵌套中;
然而不同类型在数学上没有区别,都只是对复杂度加一。在要计算的不同类别之间进行区分,可以更轻松地了解某一处是否适用嵌套的逻辑。以下各节将进一步详细说明这些规则及其背后的原理。
1.2.1 忽略简写
认知复杂性的一个指导原则是,鼓励良好的编码实践。也就是说,需要无视或低估让代码更可读的feature(不进行复杂度计算)。“方法”本身就是一个朴素的例子,把一段代码拆的把几句抽离成一个方法,用一句方法调用代替掉,“简写”它,认知复杂度不会因为这这一次方法调用增加。同样的,认知复杂度也会忽略掉null-coalescing操作符,x?.myObject这样的操作符不增加复杂度,因为这些操作同样是把多段代码缩写为一项了。例如下面的两段代码:
MyObj myObj = null;
if (a != null) {
myObj = a.myObj;
}
MyObj myObj = a?.myObj
第一个的版本的意思需要一些时间来处理,而下边的版本一旦理解了空合并语法,下边就一目了然了。因此,认知复杂性忽略了null-coalescing操作符。
1.2.2(Increment for breaks in the linear flow) 打断线性代码流程导致的复杂
在认知复杂度的制定想法中,另一项指导原则是:结构控制会打断一条线性的流从头到尾走完,使代码的维护者需要花更大功夫来理解代码。在认定了这会导致额外负担的前提下,认知复杂度评估了以下几种会增加Structural类复杂度:
- 循环:
for, while, do while, ... - 条件:
三元运算符, if, #if, #ifdef...
另外,以下这种会计处Hybrid类复杂度:else if, elif, else, ...
但不计入Nesting类复杂度,因为这个量在计算之前的if语句时已经计过了。
这些增加复杂度,其实和圈复杂度的计算方式非常像,但是额外的,认知复杂度还会计算:
1.2.2.1 Catches
一个catch表达了控制流的一个分支,就像if一样。因此每个catch语句都会增加Structural类的认知复杂度,仅加1分,无论它catch住多少种异常。(在我们的计算中try\finally被直接忽略掉)
1.2.2.2 Switches
一个switch语句,和它附带的全部case绑在一起记为一个Structural类,来增加复杂度。
在圈复杂度下,一个switch语句被视为一系列的if-else链,因此每个case都会增加复杂度,因为会使得控制流分支增多。
但以代码维护的视角来看,一个switch:将单个变量与一组显式的值比较,要比if-else链易于理解,因为if-else链可以用任意条件做比较。就是说if-else if链必须仔细的逐个阅读条件,而switch通常是可以一目了然的。
1.2.2.3 Sequences of logical operators (一系列的逻辑操作)
出于类似的原因,认知复杂度不对每一个逻辑运算符计分,而是考虑对连续的一组逻辑操作加分。例如下面几个操作:
a && b
a && b && c && d
a || b
a || b || c || d
理解后一行的操作,不会比理解前一行的操作更难。但是对于下面两行,理解难度有质的区别:
a && b && c && d
a || b && c || d
因为boolean操作表达式混合使用时会更难理解,因此对这类操作每出现一个,认知复杂度都会不断递增。例如:
if (a // +1 for `if`
&& b && c // +1
|| d || e // +1
&& f) // +1
if (a // +1 for `if`
&& // +1
!(b && c)) // +1
尽管认知复杂度相对于循环复杂度,为类似的运算符提供了“折扣”,但它可以为所有的布尔运算符都有所增加。(例如那些变量赋值,方法调用和返回语句)
1.2.2.4 Recursion(递归)
与圈复杂度不同,认知复杂度对每一个递归调用,都增加一点Fundamental类复杂计分,不论是直接还是间接的。有两个这样做的动机:
1、递归表达了一种“元循环”,并且循环会增加认知复杂度;
2、认知复杂度希望能用于估计一个方法,其控制流难以理解的程度,而即使是一些有经验的程序员,都觉得递归难以理解;
1.2.2.5 Jumps to labels
goto, break与continue到某处label,会增加Fundamental类复杂程度。但是在代码过程中提前return,可以使代码更清晰,所以其它类型的continue\break\return都不会导致复杂程度增加。
1.2.3 Increment for nested flow-break structures(嵌套打断思路造成的复杂)
直觉看起来很明显,由连续嵌套的五个结构比,线性连续的五个if\for结构要好理解得多(不考虑执行路径上的第一个部分有几句代码)。因为这样的嵌套会增加理解代码的成本,所以认知复杂度在计算时会将其视为一个Nesting类复杂度增加。特别地,每一次有一个导致了Structural类或Hybrid类复杂的结构体,嵌套了另一个结构时,每一层嵌套都要再加一次Nesting类复杂度。例如下面的例子,这个方法本身和try这两项就不会计入Nesting类的复杂,因为它们即不是Structure类也不是Hybrid类的复杂结构:
void myMethod () {
try {
if (condition1) { // +1
for (int i = 0; i < 10; i++) { // +2 (nesting=1)
while (condition2) { … } // +3 (nesting=2)
}
}
} catch (ExcepType1 | ExcepType2 e) { // +1
if (condition2) { … } // +2 (nesting=1)
}
} // Cognitive Complexity 9
然而,对于if\for\while\catch这些结构,全部被视为Structural类和Nesting类的复杂。此外,虽然最外层的方法被忽略了,并且lambda、#ifdef等类似功能也都不会视为Structral类的增量,但是它们会计入嵌套的层级数:
void myMethod2 () {
Runnable r = () -> { // +0 (but nesting level is now 1)
if (condition1) { … } // +2 (nesting=1)
};
} // Cognitive Complexity 2
#if DEBUG // +1 for if
void myMethod2 () { // +0 (nesting level is still 0)
Runnable r = () -> { // +0 (but nesting level is now 1)
if (condition1) { … } // +3 (nesting=2)
};
} // Cognitive Complexity 4
1.2.4 The implications 含义
认知复杂度制定的主要目标,是为方法计算出一个得分,准确地反应出此方法的相对理解难度。它的次要目标,是解决现代语言结构的问题,并产生在方法级别以上也有价值的指标。 可以证明,解决现代语言结构的目标已经实现。 其他两个目标在下面进行了检查。
1.2.4.1 Intuitively ‘right’ complexity scores( 直觉上对的复杂分)
在本篇开头的时候讨论了两个圈复杂度相同的方法(但它们有着完全不同的理解难度),现在回过头来检查一下这两个方法的认知复杂度:

认知复杂度算法,给这两个方法完全不同的得分,这个得分结果更接近它们的相对理解成本。
1.2.4.2 Metrics that are valuable above the method level (方法级别之上也有用的指标)
更进一步的,因为认知复杂度不会因为方法这个结构增加,复杂度的总和开始有用了起来。现在你可以看出两个类:一个有大量的getter()\setter()方法,另一个类仅有一个极其复杂的控制流,可以简单的通过比较二者的认知复杂度就行了。认知复杂度可以成为衡量一个类或应用的相对复杂度的工具。
2、Conclusion (结论)
编写和维护代码是一个人为过程,它们的输出必须遵守数学模型,但它们本身不适合数学模型。 这就是为什么数学模型不足以评估其所需的工作量的原因。认知复杂性不同于使用数学模型评估软件可维护性的实践。 它从圈复杂度设定的先例开始,但是使用人工判断来评估应如何对结构进行计数,并决定应向模型整体添加哪些内容。 结果,它得出的方法复杂性得分比以前的模型更能吸引程序员,因为它们是对可理解性的更公平的相对评估。 此外,由于认知复杂性不收取任何方法的“入门成本”,因此它不仅在方法级别,而且在类和服务级别,都产生了更加准确的评估结果。
相关文章:
【代码质量】认知复杂度(COGNITIVE COMPLEXITY)一种衡量可理解性的新方法
白皮书地址 摘要:圈复杂度最初是作为“可测试性和模块控制流的“可维护性”。虽然它擅长于衡量前者,但它的数学模型不能产生一个令人满意的值来衡量后者。本文描述一种打破数学度量模型的新度量模型来评估代码,以弥补圈复杂度的缺点…...

什么是JavaScript中的内存泄漏和如何避免内存泄漏?
1、什么是JavaScript中的内存泄漏和如何避免内存泄漏? JavaScript中的内存泄漏是指在程序运行过程中,一些不再使用的对象或数据仍然存在于内存中,导致内存无法释放,最终导致内存耗尽。 为了避免内存泄漏,可以采取以下…...

安全头响应头(三)X-Content-Type-Options
一 X-Content-Type-Options响应头 说明:先写个框架,后续补充 思考:请求类型是 "style" 和 "script" 是什么意思? script标签 style StyleSheet JavaScript MIME type 文件扩展和Content-Type的映射关系 场景: 一个…...

13 计算机视觉-代码详解
13.2 微调 为了防止在训练集上过拟合,有两种办法,第一种是扩大训练集数量,但是需要大量的成本;第二种就是应用迁移学习,将源数据学习到的知识迁移到目标数据集,即在把在源数据训练好的参数和模型ÿ…...
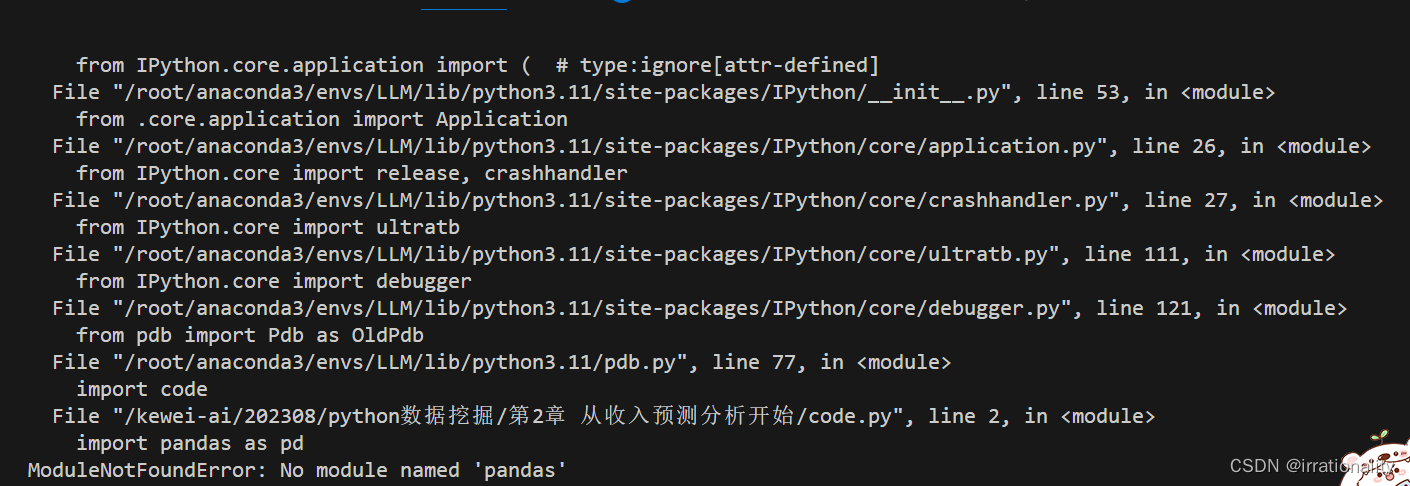
jupyter打开ipynb后,还没有运行cell,反复报错
今天遇到了一个比较奇怪的问题: 这个原因是当前目录下有一个code.py的文件,一旦打开ipynb,就是先执行code.py,而且遇到报错,还会反复执行,导致内核崩溃。...
一台阿里云服务器怎么部署多个网站?以CentOS系统为例
本文阿里云百科介绍如何在CentOS 7系统的ECS实例上使用Nginx搭建多个Web站点。本教程适用于熟悉Linux操作系统,希望合理利用资源、统一管理站点以提高运维效率的用户。比如,您可以在一台云服务器上配置多个不同分类的博客平台或者搭建多个Web站点实现复杂…...
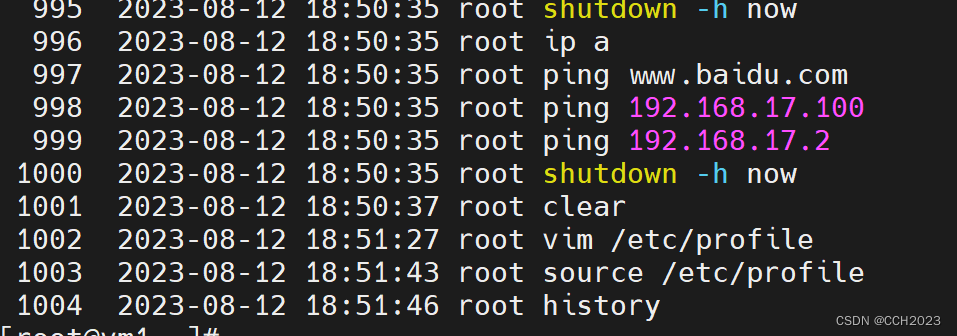
history记录日期时间和日志记录操作
history命令能查看到操作日期和时间的配置方法: 1)在/etc/profile文件中添加一行: export HISTTIMEFORMAT"%F %T whoami " 2)保存后,执行加载命令: source /etc/profile 3)然后检…...

RocketMQ 单机源码部署 自定义配置文件和端口以及acl权限配置解析
思路 1、我们首先配置完 namesrv和broker和acl认证的配置文件,然后直接使用-c指定配置文件来启动程序,就会非常明了,用户名密码要大于6,第一个用户我测试着不知道为什么始终有最高权限,大家尽量不要吧第一个用户给别人…...
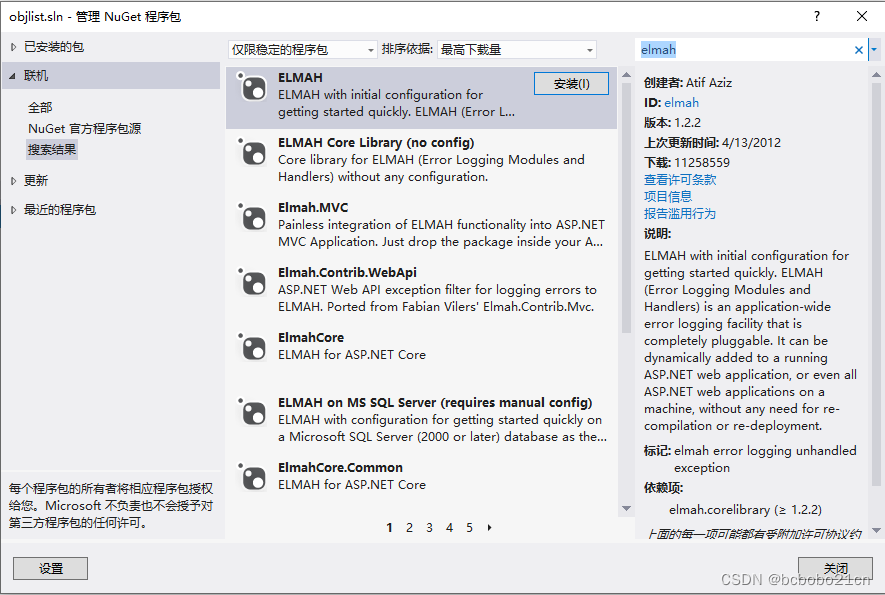
NuGet控制台命令初步使用
查看所有安装的包, 查找包,提示Nuget版本低;安装一个更高版本; 查看所有安装的包, 查找名字包含某字符串的包, 查找名字包含某字符串的包, 安装,使用-version指定版本,可…...

2023年国赛数学建模思路 - 案例:FPTree-频繁模式树算法
文章目录 算法介绍FP树表示法构建FP树实现代码 建模资料 ## 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 算法介绍 FP-Tree算法全称是FrequentPattern Tree算法,就是频繁模式树算法,…...

Positive Technologies:有针对性的攻击占非洲所有攻击的 68%
网络犯罪分子最常攻击的是非洲的金融公司和电信公司 Positive Technologies 分析了 2022–2023 年非洲遇到的各种网络安全威胁,并在圣彼得堡举行的第二届俄罗斯—非洲峰会上介绍了研究结果。根据我们的专家的介绍,非洲金融部门受到的网络攻击最多&#…...
Flink CDC系列之:TiDB CDC 导入 Elasticsearch
Flink CDC系列之:TiDB CDC 导入 Elasticsearch 一、通过docker 来启动 TiDB 集群二、下载 Flink 和所需要的依赖包三、在TiDB数据库中创建表和准备数据四、启动Flink 集群,再启动 SQL CLI五、在 Flink SQL CLI 中使用 Flink DDL 创建表六、Kibana查看Ela…...

未来混合动力汽车的发展:技术探索与前景展望
随着环境保护意识的增强和对能源消耗的关注,混合动力汽车成为了汽车行业的研发热点。混合动力汽车融合了传统燃油动力和电力动力系统,通过优化能源利用效率,既降低了燃油消耗和排放,又提供了更长的续航里程。本文将探讨混合动力汽…...

C进阶(2/7)前篇——指针进阶
前言:本文章讲解部分指针进阶内容。后续继续更新。 文章重点: 1. 字符指针 2. 数组指针 3. 指针数组 4. 数组传参和指针传参 目录 前言:本文章讲解部分指针进阶内容。后续继续更新。 指针初阶了解: 1.字符指针 1.1一道有关于字…...
C 内存分配器 mimalloc
有论文 … … https://www.microsoft.com/en-us/research/publication/mimalloc-free-list-sharding-in-action/ 可以减少内存碎片,微软研究院2019 年开源出的内存分配器 代码,适配linux...

leetcode做题笔记74搜索二维矩阵
给你一个满足下述两条属性的 m x n 整数矩阵: 每行中的整数从左到右按非递减顺序排列。每行的第一个整数大于前一行的最后一个整数。 给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则,返回 false 。 思…...

深信服数据中心管理系统 XXE漏洞复现
0x01 产品简介 深信服数据中心管理系统DC为AC的外置数据中心,主要用于海量日志数据的异地扩展备份管理,多条件组合的高效查询,统计和趋势报表生成,设备运行状态监控等功能。 0x02 漏洞概述 深信服数据中心管理系统DC存在XML外部实…...

【Kubernetes】Kubernetes的Pod进阶
Pod进阶 一、资源限制和重启策略1. 资源限制2. 资源单位2.1 CPU 资源单位2.2 内存 资源单位 3. 重启策略(restartPolicy) 二、健康检查的概念1. 健康检查1.1 探针的三种规则1.2 Probe 支持三种检查方法 2. 示例2.1 exec 方式2.2 httpGet 方式2.3 tcpSock…...

都错了!机械硬盘远比SSD更省电 最多领先94%
相信在绝大多数人的认知中,SSD固态硬盘因为没有HDD机械硬盘那样的移动部件,不但更稳定,还更省电。 但是,存储服务商Scality的研究表明,恰恰相反,HDD更省电。 他们以美光6500 ION 30.72TB QLC SSD、希捷银河…...
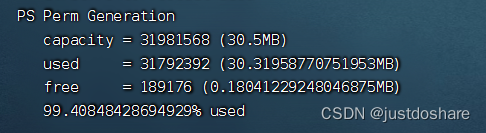
tomcat设置PermSize
最近tomcat老是报错,查看了日志出现PermGen 内存不够用,重启tomcat后查询使用情况 通过启动参数发现没有设置 PermGen,继续通过jmap查看 jmap -heap 21179 发现99%已使用,而且默认是30.5M,太小了,这里设置成256M 1. 创建setenv.sh文件 在/usr/local/tomcat/bin目录下创建一个…...

Quark:极致微型Linux卡片电脑的硬件设计、系统开发与应用实战
1. 项目概述:当“小”成为核心竞争力在嵌入式开发和创客圈子里,我们总在寻找那个“刚刚好”的硬件平台。它要足够小巧,能塞进任何灵光一现的创意里;它要足够完整,能运行一个正经的操作系统来处理复杂逻辑;它…...

JMeter接口测试实战:从登录闭环到分布式压测
1. 为什么接口测试不能只靠“点点点”——从一个被忽略的500错误说起我第一次在客户现场接手一个电商后台系统时,开发说“所有接口都测过了,Postman跑了一遍,没问题”。上线前夜,支付回调接口突然返回500,日志里只有一…...

基于“点击化学”的聚合物荧光标记定制合成
当化学成为“纽带”:基于点击化学的聚合物荧光标记定制合成关于我们的定制在生物医学成像与材料科学的前沿研究中,获得一种既能稳定发光、又能精准标记目标分子的探针,往往是实验成功的关键。我们专注于为客户提供基于点击化学的聚合物荧光标…...

紧急通知:Claude文档解析API响应延迟突增300%?立即启用这3个异步缓存+增量摘要策略保生产可用性
更多请点击: https://intelliparadigm.com 第一章:Claude复杂文档分析工作流的稳定性危机本质 当处理百页PDF、嵌套Markdown表格、多语言混合注释及跨页公式引用的法律合同时,Claude模型常在推理链中出现非确定性断裂——并非简单“超时”或…...

YOLOv11公共场所吸烟行为目标检测数据集-6496张-smoking-detection-1
YOLOv11公共场所吸烟行为目标检测数据集 📊 数据集基本信息 目标类别: [‘not_smoking’, ‘smoking’]中文类别:[‘不吸烟’, ‘吸烟’]训练集:5644 张验证集:569 张测试集:283 张总计:6496 张…...
)
【限时解密】ElevenLabs未开放的客家话语音fine-tuning沙箱环境:如何用不到200条标注语句,在72小时内将模型MOS分从3.1提升至4.4(附私有化微调checklist)
更多请点击: https://codechina.net 第一章:【限时解密】ElevenLabs未开放的客家话语音fine-tuning沙箱环境:如何用不到200条标注语句,在72小时内将模型MOS分从3.1提升至4.4(附私有化微调checklist) Eleve…...

物理标签退场,视觉原生上位:UWB vs 镜像视界无感定位・空间智能重构
物理标签退场,视觉原生上位:UWB vs 镜像视界无感定位・空间智能重构在空间智能加速重构物理世界的当下,全域感知技术正经历一场从“物理标签”到“视觉原生”的底层范式革命。长期以来,以UWB(超宽带)为代表…...

数字图像质量提升技术【附代码】
✨ 长期致力于图像质量提升、计算机图形处理器、并行加速、非均匀校正、图像超分辨、反射光消除、深度学习、生成对抗网络研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 &#…...

实测在ubuntu环境下调用taotoken api的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测在ubuntu环境下调用taotoken api的延迟与稳定性表现 本文旨在分享在Ubuntu 22.04 LTS系统环境下,使用Python脚本持…...

py每日spider案例之netease搜索接口获取
import requestsheaders = {"accept": "application/json, text/plain, */*","accept-language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7","cache-control": "no-cache",...