ZooKeeper的应用场景(命名服务、分布式协调通知)
3 命名服务
命名服务(NameService)也是分布式系统中比较常见的一类场景,在《Java网络高级编程》一书中提到,命名服务是分布式系统最基本的公共服务之一。在分布式系统中,被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象等一这些我们都可以统称它们为名字(Name),其中较为常见的就是一些分布式服务框架(如RPC、RMI)中的服务地址列表,通过使用命名服务,客户端应用能够根据指定名字来获取资源的实体、服务地址和提供者的信息等。
Java语言中的JNDI便是一种典型的命名服务。JNDI是Java命名与目录接口(Java Naming and Directory Interface)的缩写,是J2EE体系中重要的规范之一,标准的J2EE容器都提供了对JNDI规范的实现。因此,在实际开发中,开发人员常常使用应用服务器自带的JNDI实现来完成数据源的配置与管理一使用JNDI方式后,开发人员可以完全不需要关心与数据库相关的任何信息,包括数据库类型、JDBC驱动类型以及数据库账户等。
ZooKeeper提供的命名服务功能与JNDI技术有相似的地方,都能够帮助应用系统通过一个资源引用的方式来实现对资源的定位与使用。另外,广义上命名服务的资源定位都不是真正意义的实体资源一在分布式环境中,上层应用仅仅需要一个全局唯一的名字,类似于数据库中的唯一主键。 下面我们来看看如何使用ZooKeeper来实现一套分布式全局唯一ID的分配机制。
所谓ID,就是一个能够唯一标识某个对象的标识符。在我们熟悉的关系型数据库中,各个表都需要一个主键来唯一标识每条数据库记录,这个主键就是这样的唯一ID。在过去的单库单表型系统中,通常可以使用数据库字段自带的auto_increment属性来自动为每条数据库记录生成一个唯一的ID,数据库会保证生成的这个ID在全局唯一。但是随着数据库数据规模的不断增大,分库分表随之出现,而auto_increment 属性仅能针对单一表中的记录自动生成ID,因此在这种情况下,就无法再依靠数据库的auto_increment 属性来唯一标识一条记录了。于是,我们必须寻求一种能够在分布式环境下生成全局唯一ID的方法。
说起全局唯一ID,相信读者都会联想到UUID。没错,UUID是通用唯一识别码(Universally Unique Identifier) 的简称,是一种在分布式系统中广泛使用的用于唯一标识元素的标准,最典型的实现是GUID (Globally Unique ldentifier,全局唯一标识符),主流ORM框架Hibernate有对UUID的直接支持。
确实,UUID是一个非常不错的全局唯一ID生成方式,能够非常简便地保证分布式环境中的唯一性。一个标准的UUID 是一个包含32位字符和4个短线的字符串,例如“e70f1357-f260-46ff-a32d-53a086c57ade”。UUID的优势自然不必多说,我们重点来看看
它的缺陷。
(1)长度过长
UUID最大的问题就在于生成的字符串过长。显然,和数据库中的INT类型相比,存储一个UUID需要花费更多的空间。
(2)含义不明
上面我们已经看到一个典型的UUID是类似于“e70f1357- f260-46fF- a32d-53a086c57ade"的一个字符串。根据这个字符串,开发人员从字面上基本看不出任何其表达的含义,这将会大大影响问题排查和开发调试的效率。
接下来,我们结合一个分布式任务调度系统来看看如何使用ZooKeeper来实现这类全局唯一ID的生成。
通过调用ZooKeeper节点创建的API接口可以创建一个顺序节点,并且在API返回值中会返回这个节点的完整名字。利用这个特性,我们就可以借助ZooKeeper来生成全局唯一的ID了,如下图所示。

结合上图,我们来讲解对于一个任务列表的主键,使用ZooKeeper生成唯一ID 的基本步骤。
(1)所有客户端都会根据自己的任务类型,在指定类型的任务下面通过调用create()接口来创建一个顺序节点,例如创建“job-”节点。
(2)节点创建完毕后,create()接口会返回一个完整的节点名,例如“job-000000003"。
(3)客户端拿到这个返回值后,拼接上type类型,例如“type2-job 000000003”, 这就可以作为一个全局唯一的ID了。
在ZooKeeper中,每一个数据节点都能够维护--份子节点的顺序顺列,当客户端对其创建一个顺序子节点的时候ZooKeeper会自动以后缀的形式在其子节点上添加一个序号,在这个场景中就是利用了ZooKeeper的这个特性。
4 分布式协调/通知
分布式协调/通知服务是分布式系统中不可缺少的一个环节,是将不同的分布式组件有机结合起来的关键所在。对于一个在多台机器上部署运行的应用而言,通常需要一个协调者(Coordinator)来控制整个系统的运行流程,例如分布式事务的处理、机器间的互相协调等。同时,引入这样一个协调者,便于将分布式协调的职责从应用中分离出来,从而可以大大减少系统之间的耦合性,而且能够显著提高系统的可扩展性。
ZooKeeper中特有的Watcher注册与异步通知机制,能够很好地实现分布式环境下不同机器,甚至是不同系统之间的协调与通知,从而实现对数据变更的实时处理。基于ZooKeeper实现分布式协调与通知功能,通常的做法是不同的客户端都对ZooKeeper上同一个数据节点进行Watcher注册,监听数据节点的变化(包括数据节点本身及其子节点),如果数据节点发生变化,那么所有订阅的客户端都能够接收到相应的Watcher通知,并做出相应的处理。
MySQL数据复制总线:Mysql_Replicator
MySQL数据复制总线(以下简称“复制总线”)是一个实时数据复制框架,用于在不同的MySQL数据库实例之间进行异步数据复制和数据变化通知。整个系统是一个由MySQL数据库集群、消息队列系统、任务管理监控平台以及ZooKeeper 集群等组件共同构成的一个包含数据生产者、复制管道和数据消费者等部分的数据总线系统,下图所示是该系统的整体结构图。
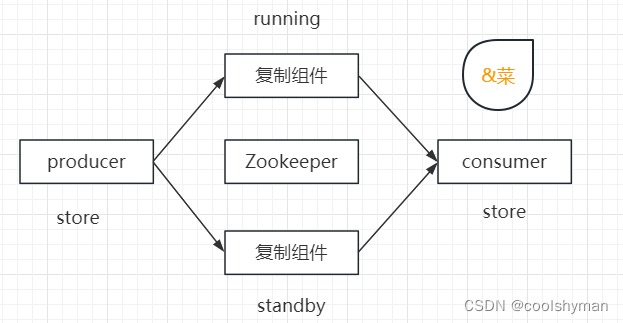
在该系统中,ZooKeeper主要负责进行一系列的分布式协调工作,在具体的实现上,根据功能将数据复制组件划分为三个核心子模块:Core、 Server 和Monitor,每个模块分别为一个单独的进程,通过ZooKeeper进行数据交换。
Core实现了数据复制的核心逻辑,其将数据复制封装成管道,并抽象出生产者和消费者两个概念,其中生产者通常是MySQL数据库的Binlog日志。
Server负责启动和停止复制任务。
Monitor负责监控任务的运行状态,如果在数据复制期间发生异常或出现故障会进行告警。
三个子模块之间的关系如下图所示。
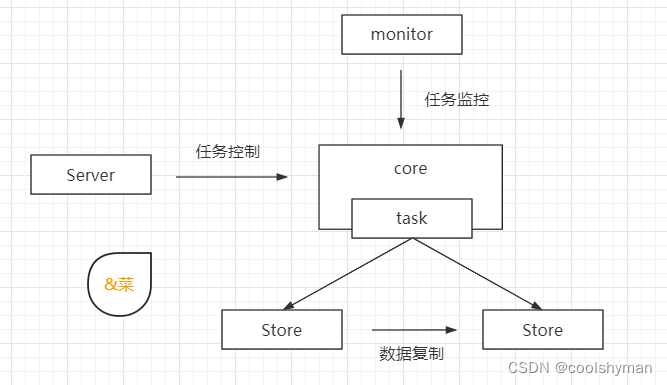
每个模块作为独立的进程运行在服务端,运行时的数据和配置信息均保存在ZooKeeper上,Web控制台通过ZooKeeper上的数据获取到后台进程的数据,同时发布控制信息。
任务注册
Core进程在启动的时候,首先会向/mysql_replicator/tasks节点(以下简称“任务列表节点”)注册任务。例如,对于一个“复制热门商品”的任务,Task 所在机器在启动的时候,会首先在任务列表节点上创建一个子节点,例如/mysql_replicator/tasks/copy_hot_item(以下简称“任务节点")。如果在注册过程中发现该子节点已经存在,说明已经有其他Task机器注册了该任务,因此自己不需要再创建该节点了。
任务热备份
为了应对复制任务故障或者复制任务所在主机故障,复制组件采用“热备份”的容灾方式,即将同一个复制任务部署在不同的主机上,我们称这样的机器为“任务机器”,主、备任务机器通过ZooKeeper互相检测运行健康状况。
为了实现上述热备方案,无论在第一步中是否创建了任务节点,每台任务机器都需要在/mysql_replicator/tasks/copy_hot_item/instances节点上将自己的主机名注册上去。注意,这里注册的节点类型很特殊,是一个临时的顺序节点。在注册完这个子节点后,通常一个完整的节点名如下: /mysql_replicator/tasks/copy_hot_item/intsances/[Hostname]-I,其中最后的序列号就是临时顺序节点的精华所在。
在完成该子节点的创建后,每台任务机器都可以获取到自己创建的节点的完成节点名以及所有子节点的列表,然后通过对比判断自己是否是所有子节点中序号最小的。如果自己是序号最小的子节点,那么就将自己的运行状态设置为RUNNING,其余的任务机器则将自己设置为STANDBY,我们将这样的热备份策略称为“小序号优先”策略。
热备切换
完成运行状态的标识后,任务的客户端机器就能够正常工作了,其中标记为RUNNING的客户端机器进行正常的数据复制,而标记为STANDBY的客户端机器则进入待命状态。这里所谓待命状态,就是说一旦标记为RUNNING的机器出现故障停止了任务执行,那么就需要在所有标记为STANDBY的客户端机器中再次按照“小序号优先”策略来选出RUNNING机器来执行,具体的做法就是标记为STANDBY的机器都需要在/mysql_replicator/tasks/copy_hot item/instances节点上注册一个“子节点列表变更”的Watcher监听,用来订阅所有任务执行机器的变化情况——一旦RUNNING机器宕机与ZooKeeper断开连接后,对应的节点就会消失,于是其他机器也就接收到了这个变更通知,从而开始新一轮的RUNNING选举。
记录执行状态
既然使用了热备份,那么RUNNING任务机器就需要将运行时的上下文状态保留给STANDBY任务机器。在这个场景中,最主要的上下文状态就是数据复制过程中的一些进度信息,例如Binlog日志的消费位点,因此需要将这些信息保存到ZooKeeper上以便共享。在Mysql_Replicator的设计中,选择了/mysq_replicator/tasks/copy_hot_item/lastCommit作为Binlog日志消费位点的存储节点,RUNNING任务机器会定时向这个节点写人当前的Binlog日志消费位点。
控制台协调
在Mysql_Replicator中,Server主要的工作就是进行任务的控制,通过ZooKeeper来对不同的任务进行控制与协调。Server会将每个复制任务对应生产者的元数据,即库名、表名、用户名与密码等数据库信息以及消费者的相关信息以配置的形式写入任务节点/mysql_replicator/tasks/copy_hot_item中去,以便该任务的所有任务机器都能够共享该复制任务的配置。
冷备切换
到目前为止我们已经基本了解了Mysql_Replicator的工作原理,现在再回过头来看上面提到的热备份。在该热备份方案中,针对一个任务,都会至少分配两台任务机器来进行热备份,但是在一定规模的大型互联网公司中,往往有许多MySQL实例需要进行数据复制,每个数据库实例都会对应一个复制任务,如果每个任务都进行双机热备份的话,那么显然需要消耗太多的机器。
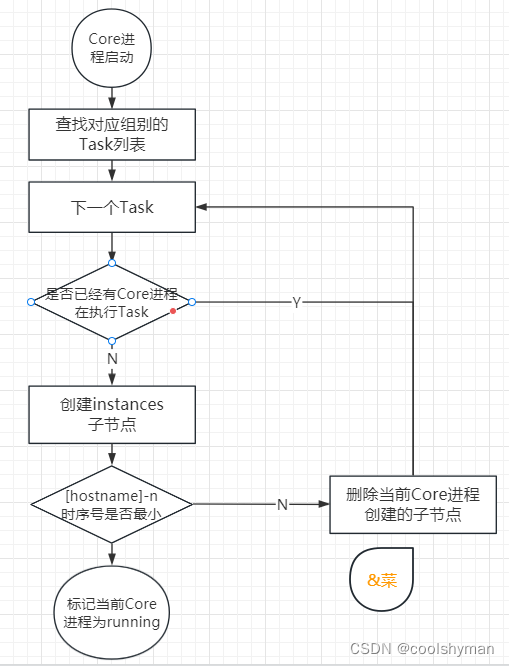
和热备份中比较大的区别在于,Core进程被配置了所属Group(组)。举个例子来说,假如一个Core进程被标记了group1,那么在Core进程启动后,会到对应的ZooKeepergroup1节点下面获取所有的Task列表,假如找到了任务“copy_hot_item”之后,就会遍历这个Task列表的instances 节点,但凡还没有子节点的,则会创建一个临时的顺序节点: /mysql_replicator/task-groups/group1/copy_hot_item/instances/[Hostname]-1——当然,在这个过程中,其他Core进程也会在这个instances节点下创建类似的子节点。和热备份中的“小序号优先”策略一样,顺序小的Core进程将自己标记为RUNNING,不同之处在于,其他Core进程则会自动将自己创建的子节点删除,然后继续遍历下一个Task节点一我们将这样的过程称为“冷备份扫描”。就这样,所有Core进程在一个扫描周期内不断地对相应的Group下面的Task进行冷备份扫描。整个过程可以通过如下图所示的流程图来表示。
冷热备份对比
从上面的讲解中,我们基本对热备份和冷备份两种运行方式都有了一定的了解,现在再来对比下这两种运行方式。在热备份方案中,针对一个任务使用了两台机器进行热备份,借助ZooKeeper的Watcher通知机制和临时顺序节点的特性,能够非常实时地进行互相协调,但缺陷就是机器资源消耗比较大。而在冷备份方案中,采用了扫描机制,虽然降低了任务协调的实时性,但是节省了机器资源。
一种通用的分布式系统机器间通信方式
在绝大部分的分布式系统中,系统机器间的通信无外乎心跳检测、工作进度汇报和系统调度这三种类型。接下来,我们将围绕这三种类型的机器通信来讲解如何基于ZooKeeper去实现一种分布式系统间的通信方式。
心跳检测
机器间的心跳检测机制是指在分布式环境中,不同机器之间需要检测到彼此是否在正常运行,例如A机器需要知道B机器是否正常运行。在传统的开发中,我们通常是通过主机之间是否可以相互PING通来判断,更复杂一点的话,则会通过在机器之间建立长连接,通过TCP连接固有的心跳检测机制来实现上层机器的心跳检测,这些确实都是一些非常常见的心跳检测方法。
下面来看看如何使用ZooKeeper来实现分布式机器间的心跳检测。基于ZooKeeper的临时节点特性,可以让不同的机器都在ZooKeeper的一个指定节点下创建临时子节点,不同的机器之间可以根据这个临时节点来判断对应的客户端机器是否存活。通过这种方式,检测系统和被检测系统之间并不需要直接相关联,而是通过ZooKeeper上的某个节点进行关联,大大减少了系统耦合。
工作进度汇报
在一个常见的任务分发系统中,通常任务被分发到不同的机器上执行后,需要实时地将自己的任务执行进度汇报给分发系统。这个时候就可以通过ZooKeeper来实现。在ZooKeeper上选择一个节点,每个任务客户端都在这个节点下面创建临时子节点,这样便可以实现两个功能:
通过判断临时节点是否存在来确定任务机器是否存活;
各个任务机器会实时地将自己的任务执行进度写到这个临时节点上去,以便中心系
统能够实时地获取到任务的执行进度。
系统调度
使用ZooKeeper,能够实现另--种系统调度模式:一个分布式系统由控制台和一些客户端系统两部分组成,控制台的职责就是需要将--些指令信息发送给所有的客户端,以控制它们进行相应的业务逻辑。后台管理人员在控制台上做的一些操作,实际上就是修改了ZooKeeper上某些节点的数据,而ZooKeeper进一步把这些数据变更以事件通知的形式发送给了对应的订阅客户端。
总之,使用ZooKeeper来实现分布式系统机器间的通信,不仅能省去大量底层网络通信和协议设计上重复的工作,更为重要的一点是大大降低了系统之间的耦合,能够非常方便地实现异构系统之间的灵活通信。
相关文章:
ZooKeeper的应用场景(命名服务、分布式协调通知)
3 命名服务 命名服务(NameService)也是分布式系统中比较常见的一类场景,在《Java网络高级编程》一书中提到,命名服务是分布式系统最基本的公共服务之一。在分布式系统中,被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象等一这…...
网络套接字
网络套接字 文章目录 网络套接字认识端口号初识TCP协议初识UDP协议网络字节序 socket编程接口socket创建socket文件描述符bind绑定端口号sockaddr结构体netstat -nuap:查看服务器网络信息 代码编译运行展示 实现简单UDP服务器开发 认识端口号 端口号(port)是传输层协…...

对话 4EVERLAND:Web3 是云计算的新基建吗?
在传统云计算的发展过程中,数据存储与计算的中心化问题,对用户来说一直存在着潜在的安全与隐私风险——例如单点故障可能会导致网络瘫痪和数据泄露等危险。同时,随着越来越多 Web3 项目应用的落地,对于数据云计算的性能要求也越来…...
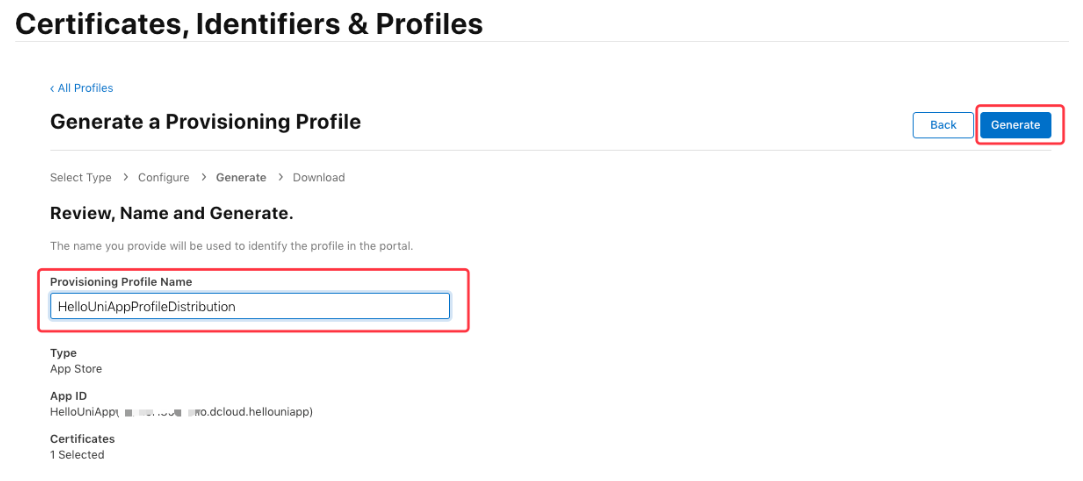
iOS申请证书(.p12)和描述文件(.mobileprovision)
打包app时,经常会用到ios证书,但很多人都苦于没有苹果电脑,即使有苹果电脑的,也会觉得苹果电脑操作也很麻烦,这里记录一下,用香蕉云编,申请证书及描述文件的过程。 香蕉云编的地址:…...

Java:PO、VO、BO、DO、DAO、DTO、POJO
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! Java:PO、VO、BO、DO、DAO、DTO、POJO PO持久化对象(Persistent Object) PO是持久化对象,用于表示数据库中的实体或表…...
c语言每日一练(8)
前言:每日一练系列,每一期都包含5道选择题,2道编程题,博主会尽可能详细地进行讲解,令初学者也能听的清晰。每日一练系列会持续更新,暑假时三天之内必有一更,到了开学之后,将看学业情…...
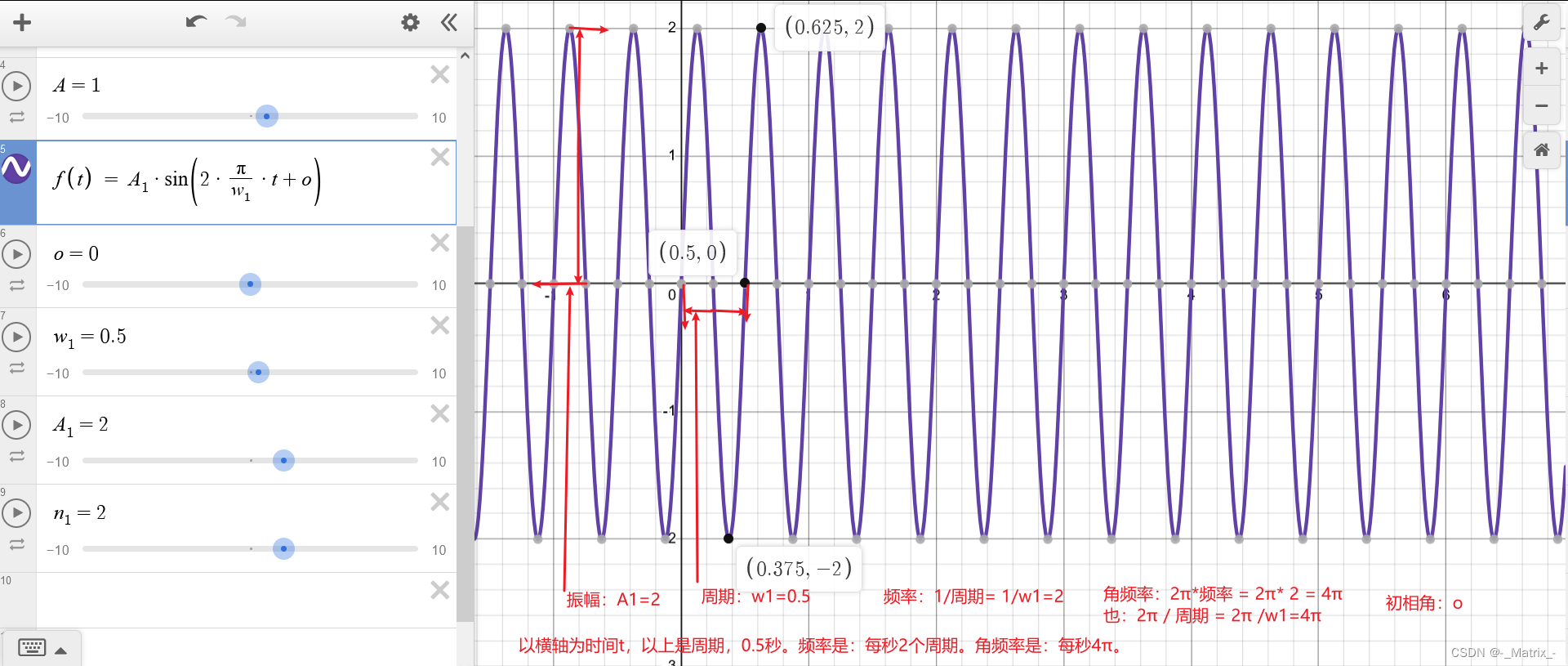
周期 角频率 频率 振幅 初相角
周期 角频率 频率 振幅 初相角 当我们谈论傅里叶级数或波形分析时,以下术语经常出现: 周期 T T T: 函数在其图形上重复的时间或空间的长度。周期的倒数是频率。 频率 f f f: 周期的倒数,即一秒内波形重复的次数。单位通常为赫兹ÿ…...

根据一棵树的两种遍历构造二叉树
题目 给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。 示例 1: 输入: preorder [3,9,20,15,7], inorder [9,3,15,20,7] 输出: [3,9,20,null,null,…...
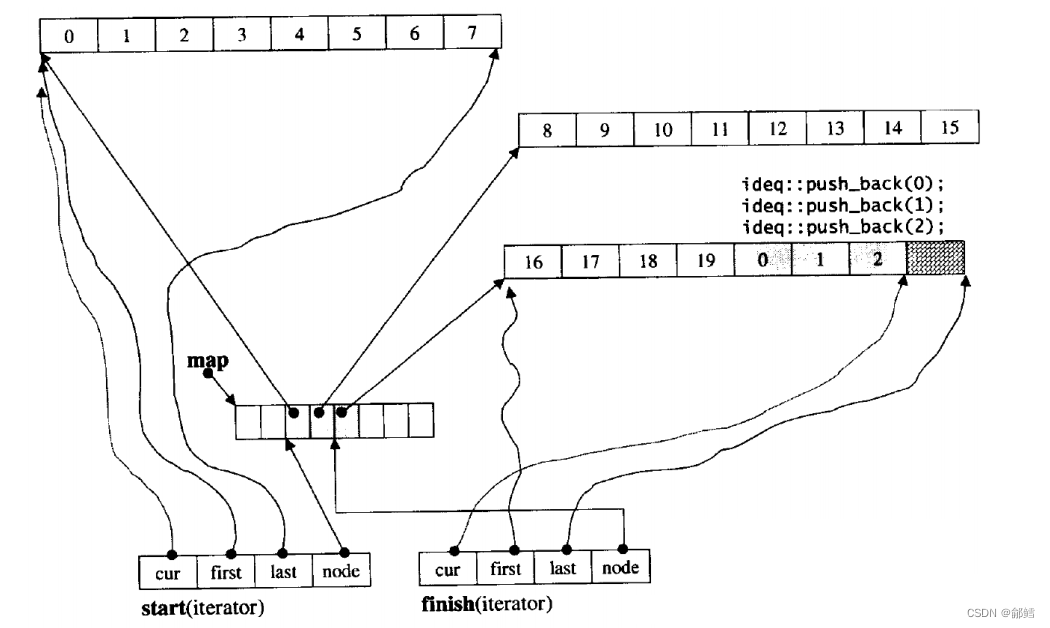
stack 、 queue的语法使用及底层实现以及deque的介绍【C++】
文章目录 stack的使用queue的使用适配器queue的模拟实现stack的模拟实现deque stack的使用 stack是一种容器适配器,具有后进先出,只能从容器的一端进行元素的插入与提取操作 #include <iostream> #include <vector> #include <stack&g…...

没学C++,如何从C语言丝滑过度到python【python基础万字详解】
大家好,我是纪宁。 文章将从C语言出发,深入介绍python的基础知识,也包括很多python的新增知识点详解。 文章目录 1.python的输入输出,重新认识 hello world,重回那个激情燃烧的岁月1.1 输出函数print的规则1.2 输入函…...

haproxy负载均衡
1、配置环境 作用环境windows测试 192.168.33.158 172.25.0.11 haproxy负载均衡haproxy:2.8.1,centos7172.25.0.31web服务器1--rs1Apache:2.4,redhat9172.25.0.32web服务器2--rs2Apache:2.4 , redhat9 2、…...
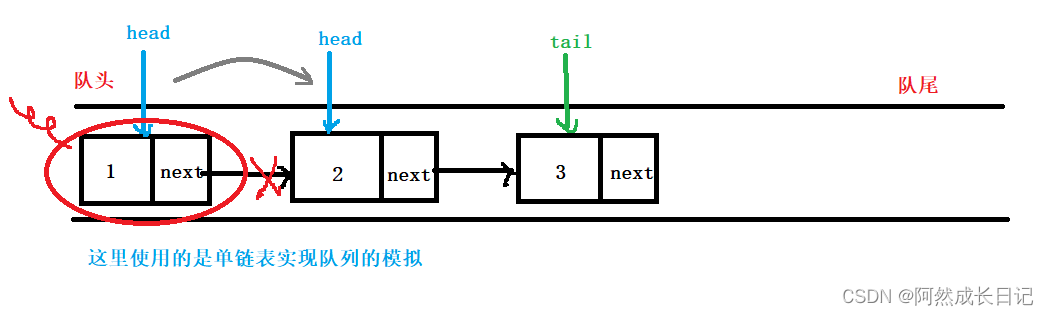
【数据结构】顺序队列模拟实现
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...
TiDB数据库从入门到精通系列之六:使用 TiCDC 将 TiDB 的数据同步到 Apache Kafka
TiDB数据库从入门到精通系列之六:使用 TiCDC 将 TiDB 的数据同步到 Apache Kafka 一、技术流程二、搭建环境三、创建Kafka changefeed四、写入数据以产生变更日志五、配置 Flink 消费 Kafka 数据 一、技术流程 快速搭建 TiCDC 集群、Kafka 集群和 Flink 集群创建 c…...
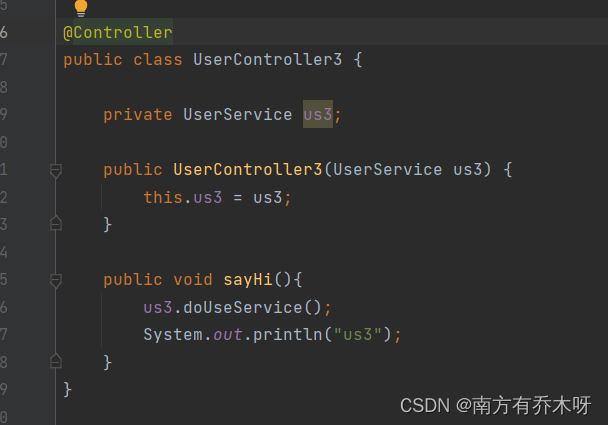
Spring对象装配
在spring中,Bean的执行流程为启动spring容器,实例化bean,将bean注册到spring容器中,将bean装配到需要的类中。 既然我们需要将bea装配到需要的类中,那么如何实现呢?这篇文章,将来阐述一下如何实…...
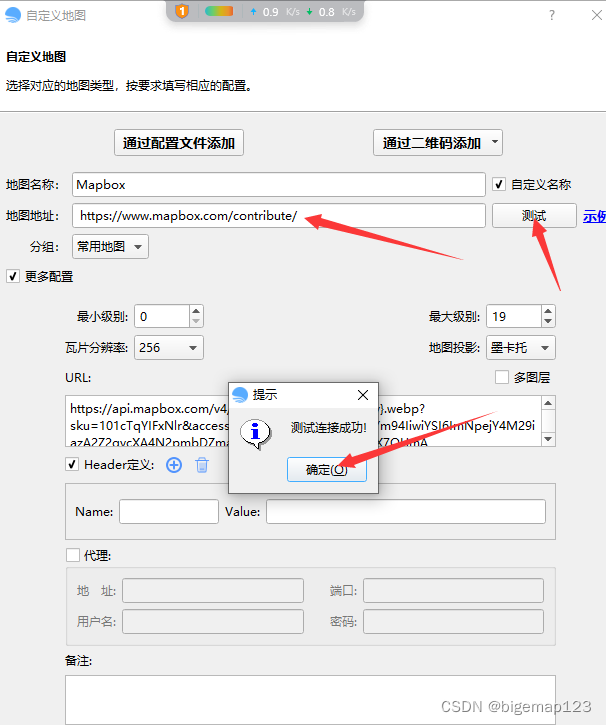
bigemap如何添加mapbox地图?
第一步 打开浏览器,找到你要访问的地图的URL地址,并且确认可以正常在浏览器中访问;浏览器中不能访问,同样也不能在软件中访问。 以下为常用地图源地址: 天地图: http://map.tianditu.gov.cn 包含&…...

python爬虫6:lxml库
python爬虫6:lxml库 前言 python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。 申明 本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好…...

Linux查找命令
find find /dir -name filename 按名字查找 find . -name “*.c” 将当前目录及其子目录下所有文件后缀为 .c 的文件列出来 find . -type f 将当前目录及其子目录中的所有文件列出 find . -ctime 20 将当前目录及其子目录下所有最近 20 天内更新过的文件列出 find / -type f -…...
在 IntelliJ IDEA 中使用 Docker 开发指南
目录 一、IDEA安装Docker插件 二、IDEA连接Docker 1、Docker for Windows 连接 2、SSH 连接 3、Connection successful 连接成功 三、查看Docker面板 四、使用插件生成镜像 一、IDEA安装Docker插件 打开 IntelliJ IDEA,点击菜单栏中的 "File" -&g…...

【并发编程】自研数据同步工具的优化:创建线程池多线程异步去分页调用其他服务接口获取海量数据
文章目录 场景:解决方案 场景: 前段时间在做一个数据同步工具,其中一个服务的任务是调用A服务的接口,将数据库中指定数据请求过来,交给kafka去判断哪些数据是需要新增,哪些数据是需要修改的。 刚开始的设…...
)
python函数、运算符等简单介绍3(无顺序)
set(集合) 集合(set) -> 负责存储【不重复的数据】,并且是【无序存储】 的容器,主要用来去重和逻辑比较 set1 {1,2,3,4,58,7,4,1,2,3,5} print(set1) print(type(set1)) # 输出结果: {1, 2, 3, 4, 5, 7, 58} <…...

从游戏画面Bug到图形学原理:一次深度测试失败的排查与透视矫正插值的深度理解
从游戏画面Bug到图形学原理:深度测试失败的排查与透视矫正插值解析 深夜调试游戏引擎时,屏幕上的三角形边缘突然出现诡异的闪烁——这种被称为"深度冲突"的现象,往往让开发者陷入漫长的调试循环。本文将以一个实际开发中的深度测试…...

从零到专业:ComfyUI中文工作流全解析与技术实践
从零到专业:ComfyUI中文工作流全解析与技术实践 【免费下载链接】ComfyUI-Workflows-ZHO 我的 ComfyUI 工作流合集 | My ComfyUI workflows collection 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-Workflows-ZHO 在AI图像生成领域࿰…...

哔咔漫画下载器:构建个人离线漫画库的完整解决方案
哔咔漫画下载器:构建个人离线漫画库的完整解决方案 【免费下载链接】picacomic-downloader 哔咔漫画 picacomic pica漫画 bika漫画 PicACG 多线程下载器,带图形界面 带收藏夹,已打包exe 下载速度飞快 项目地址: https://gitcode.com/gh_mir…...

Photoshop图层批量导出终极指南:5分钟掌握高效工作流
Photoshop图层批量导出终极指南:5分钟掌握高效工作流 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Adobe. 项目地址: http…...

Symfony String测试指南:如何编写高质量的字符串操作测试用例
Symfony String测试指南:如何编写高质量的字符串操作测试用例 【免费下载链接】string Provides an object-oriented API to strings and deals with bytes, UTF-8 code points and grapheme clusters in a unified way 项目地址: https://gitcode.com/gh_mirrors…...

思源宋体完全指南:免费开源中文字体的终极解决方案
思源宋体完全指南:免费开源中文字体的终极解决方案 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目中的中文字体授权费用而烦恼吗?或者在不同平台…...

Windows 11 LTSC微软商店安装终极指南:5分钟快速解决方案
Windows 11 LTSC微软商店安装终极指南:5分钟快速解决方案 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows 11 LTSC版本以其卓越的稳…...

一键永久保存:B站缓存视频转换终极方案,让珍贵内容不再消失
一键永久保存:B站缓存视频转换终极方案,让珍贵内容不再消失 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾有过…...

【普中 51-Ai8051 开发攻略】-- 第 30 章 OLED 液晶显示实验-硬件 IIC
(1)实验平台: 普中 51-Ai8051 开发板https://item.taobao.com/item.htm?abbucket17&id1026052331067(2)资料下载 :普中科技-各型号产品资料下载链接 前面已经使用 IO 口软件模拟 IIC 时序与 OLED 通信实现字符汉字的显示。 本章学习使用 AI805…...

Desktop Postflop:免费开源的德州扑克GTO求解器完整指南
Desktop Postflop:免费开源的德州扑克GTO求解器完整指南 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/de/desktop-postflop …...