spark的standalone 分布式搭建
一、环境准备
集群环境hadoop11,hadoop12 ,hadoop13
安装 zookeeper 和 HDFS
1、启动zookeeper
-- 启动zookeeper(11,12,13都需要启动)
xcall.sh zkServer.sh start
-- 或者
zk.sh start
-- xcall.sh 和zk.sh都是自己写的脚本
-- 查看进程
jps
-- 有QuorumPeerMain进程不能说明zookeeper启动成功
-- 需要查看zookeeper的状态
xcall.sh zkServer.sh status
-- 或者
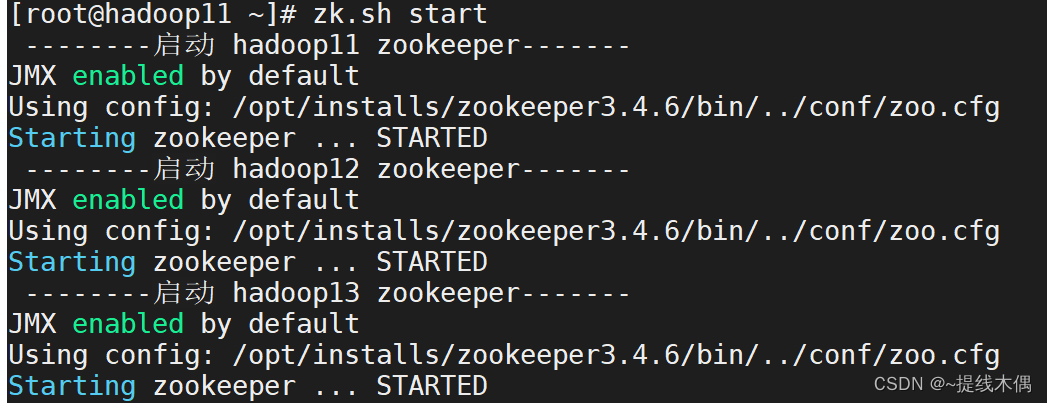
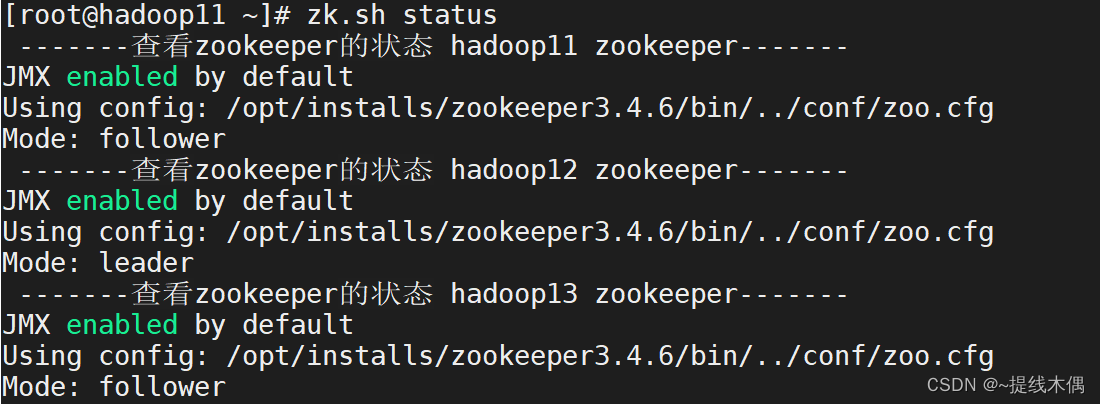
zk.sh status-------查看zookeeper的状态 hadoop11 zookeeper-------
JMX enabled by default
Using config: /opt/installs/zookeeper3.4.6/bin/../conf/zoo.cfg
Mode: follower-------查看zookeeper的状态 hadoop12 zookeeper-------
JMX enabled by default
Using config: /opt/installs/zookeeper3.4.6/bin/../conf/zoo.cfg
Mode: leader-------查看zookeeper的状态 hadoop13 zookeeper-------
JMX enabled by default
Using config: /opt/installs/zookeeper3.4.6/bin/../conf/zoo.cfg
Mode: follower-- 有leader,有follower才算启动成功
2、启动HDFS
[root@hadoop11 ~]# start-dfs.sh
Starting namenodes on [hadoop11 hadoop12]
上一次登录:三 8月 16 09:13:59 CST 2023从 192.168.182.1pts/0 上
Starting datanodes
上一次登录:三 8月 16 09:36:55 CST 2023pts/0 上
Starting journal nodes [hadoop13 hadoop12 hadoop11]
上一次登录:三 8月 16 09:37:00 CST 2023pts/0 上
Starting ZK Failover Controllers on NN hosts [hadoop11 hadoop12]
上一次登录:三 8月 16 09:37:28 CST 2023pts/0 上jps查看进程
[root@hadoop11 ~]# xcall.sh jps
------------------------ hadoop11 ---------------------------
10017 DataNode
10689 DFSZKFailoverController
9829 NameNode
12440 Jps
9388 QuorumPeerMain
10428 JournalNode
------------------------ hadoop12 ---------------------------
1795 JournalNode
1572 NameNode
1446 QuorumPeerMain
1654 DataNode
1887 DFSZKFailoverController
1999 Jps
------------------------ hadoop13 ---------------------------
1446 QuorumPeerMain
1767 Jps
1567 DataNode
1679 JournalNode
查看HDFS高可用节点状态,出现一个active和一个standby说名HDFS启动成功(或者可以访问web端=>主机名:8020来查看状态)
[root@hadoop11 ~]# hdfs haadmin -getAllServiceState
hadoop11:8020 standby
hadoop12:8020 active
二、安装Spark
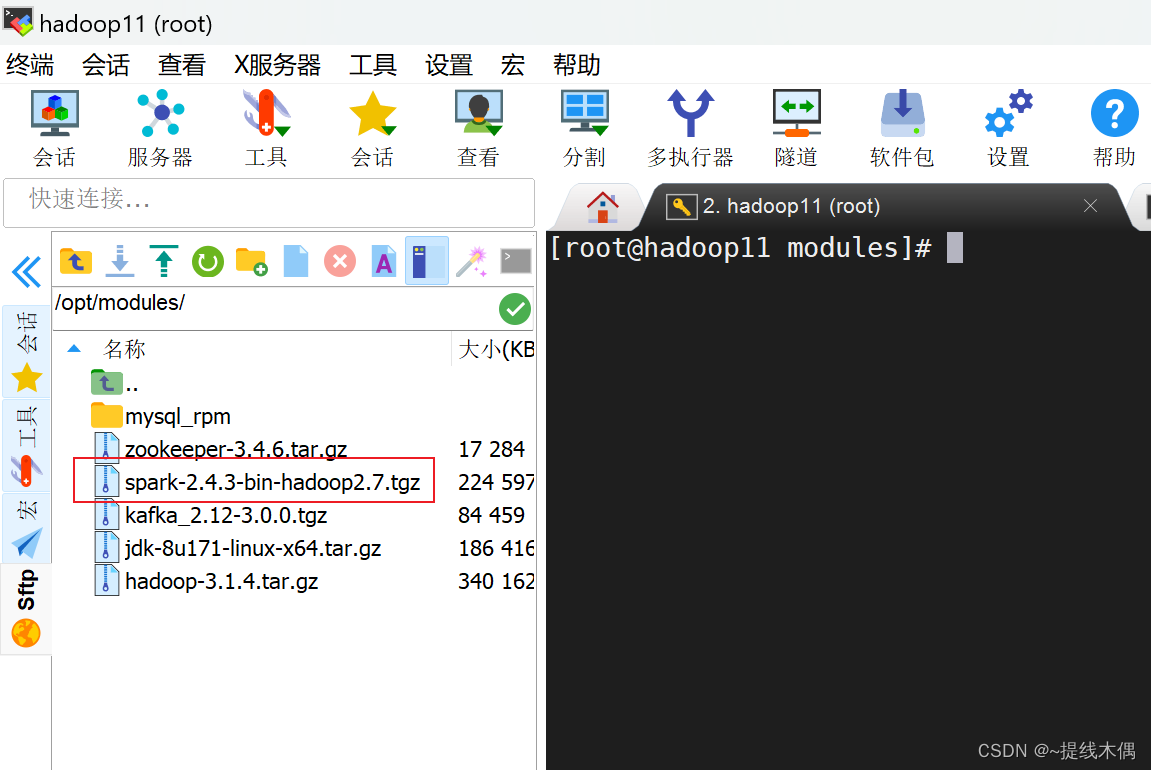
1、上传安装包到hadoop11
上传到/opt/modules目录下
我的是2.4.3版本的
2、解压
[root@hadoop11 modules]# tar -zxf spark-2.4.3-bin-hadoop2.7.tgz -C /opt/installs/
[root@hadoop11 modules]# cd /opt/installs/
[root@hadoop11 installs]# ll
总用量 4
drwxr-xr-x. 8 root root 198 6月 21 10:20 flume1.9.0
drwxr-xr-x. 11 1001 1002 173 5月 30 19:59 hadoop3.1.4
drwxr-xr-x. 8 10 143 255 3月 29 2018 jdk1.8
drwxr-xr-x. 3 root root 18 5月 30 20:30 journalnode
drwxr-xr-x. 8 root root 117 8月 3 10:03 kafka3.0
drwxr-xr-x. 13 1000 1000 211 5月 1 2019 spark-2.4.3-bin-hadoop2.7
drwxr-xr-x. 11 1000 1000 4096 5月 30 06:32 zookeeper3.4.6
3、更名
[root@hadoop11 installs]# mv spark-2.4.3-bin-hadoop2.7/ spark
[root@hadoop11 installs]# ls
flume1.9.0 hadoop3.1.4 jdk1.8 journalnode kafka3.0 spark zookeeper3.4.6
4、配置环境变量
vim /etc/profile
-- 添加
export SPARK_HOME=/opt/installs/spark
export PATH=$PATH:$SPARK_HOME/bin
-- 重新加载环境变量
source /etc/profile
5、修改配置文件
(1)conf目录下的 slaves 和 spark-env.sh
cd /opt/installs/spark/conf/
-- 给文件更名
mv slaves.template slaves
mv spark-env.sh.template spark-env.sh#配置Spark集群节点主机名,在该主机上启动worker进程
[root@hadoop11 conf]# vim slaves
[root@hadoop11 conf]# tail -3 slaves
hadoop11
hadoop12
hadoop13#声明Spark集群中Master的主机名和端口号
[root@hadoop11 conf]# vim spark-env.sh
[root@hadoop11 conf]# tail -3 spark-env.sh
SPARK_MASTER_HOST=hadoop11
SPARK_MASTER_PORT=7077

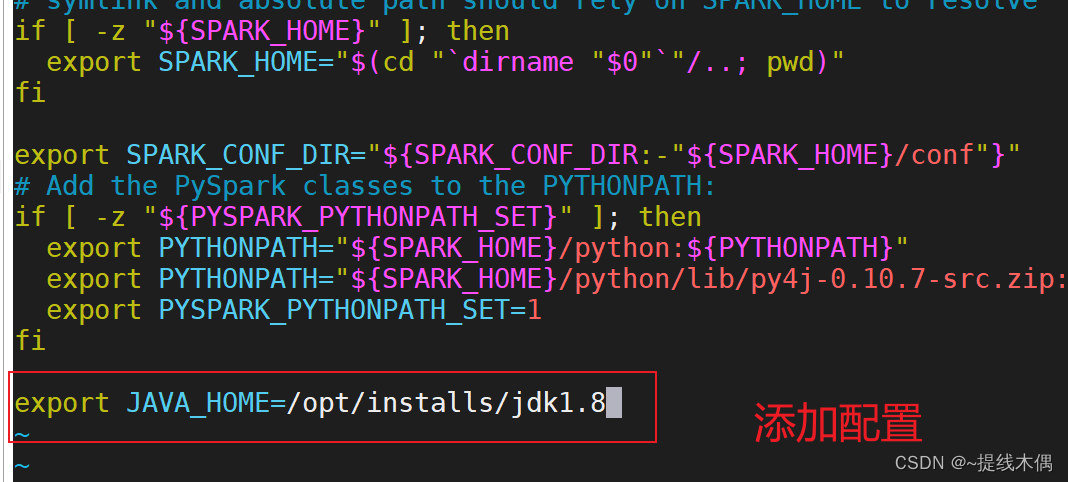
(2)sbin 目录下的 spark-config.sh
vim spark-config.sh
#在最后增加 JAVA_HOME 配置
export JAVA_HOME=/opt/installs/jdk1.8
6、配置JobHistoryServer
(1)修改配置文件
[root@hadoop11 sbin]# hdfs dfs -mkdir /spark-logs
[root@hadoop11 sbin]# cd ../conf/
[root@hadoop11 conf]# mv spark-defaults.conf.template spark-defaults.conf
[root@hadoop11 conf]# vim spark-defaults.conf
[root@hadoop11 conf]# vim spark-env.sh
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hdfs-cluster/spark-logs"
这里使用hdfs-cluster的原因:
在scala中写hdfs-cluster而不写具体的主机名,需要将hadoop中的两个配置文件拷贝到resources目录下,原因和这里的一样(需要动态寻找可用的hadoop节点,以便读写数据)
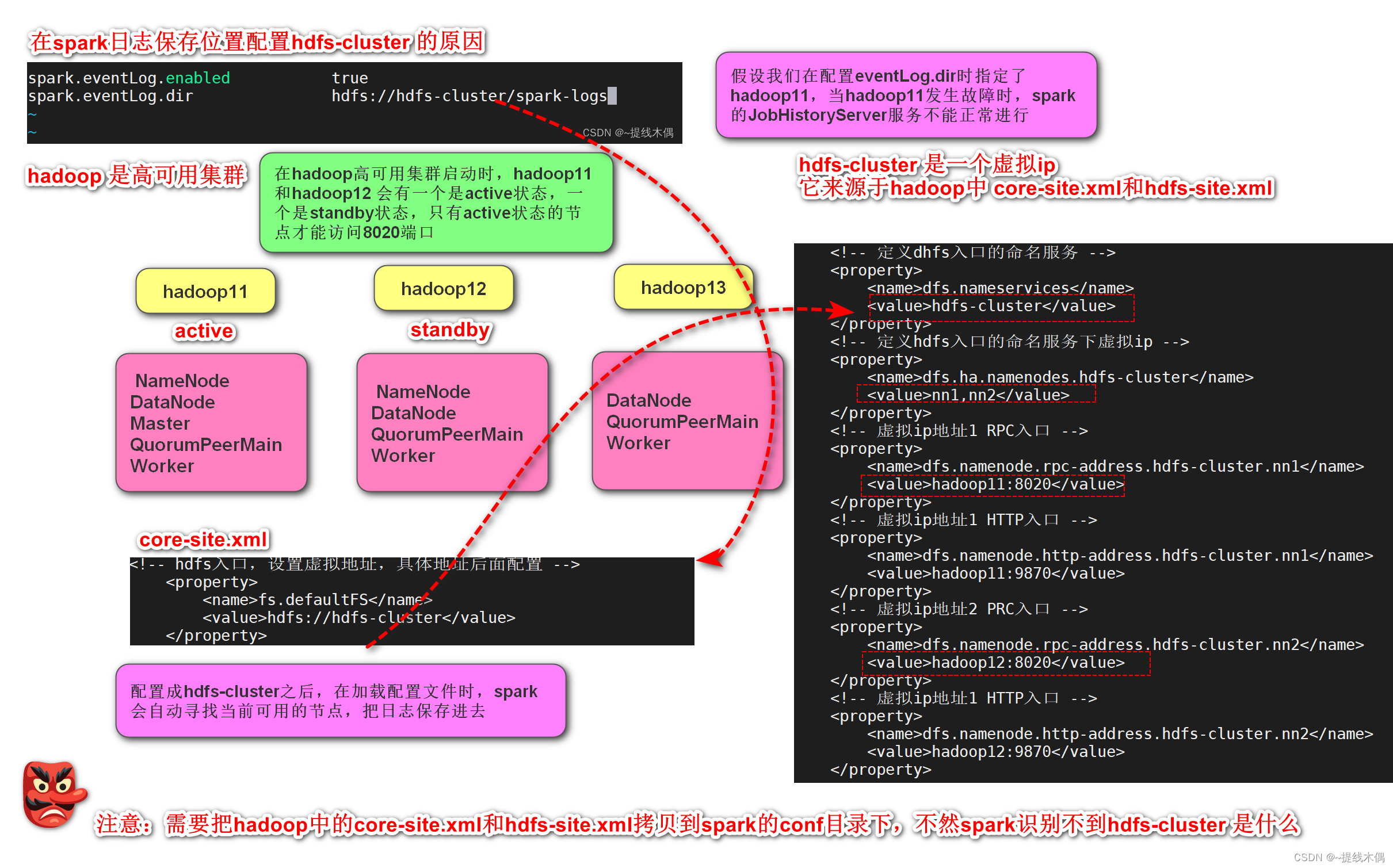
(2)复制hadoop的配置文件到spark的conf目录下
[root@hadoop11 conf]# cp /opt/installs/hadoop3.1.4/etc/hadoop/core-site.xml ./
[root@hadoop11 conf]# cp /opt/installs/hadoop3.1.4/etc/hadoop/hdfs-site.xml ./
[root@hadoop11 conf]# ll
总用量 44
-rw-r--r--. 1 root root 1289 8月 16 11:10 core-site.xml
-rw-r--r--. 1 1000 1000 996 5月 1 2019 docker.properties.template
-rw-r--r--. 1 1000 1000 1105 5月 1 2019 fairscheduler.xml.template
-rw-r--r--. 1 root root 3136 8月 16 11:10 hdfs-site.xml
-rw-r--r--. 1 1000 1000 2025 5月 1 2019 log4j.properties.template
-rw-r--r--. 1 1000 1000 7801 5月 1 2019 metrics.properties.template
-rw-r--r--. 1 1000 1000 883 8月 16 10:47 slaves
-rw-r--r--. 1 1000 1000 1396 8月 16 11:03 spark-defaults.conf
-rwxr-xr-x. 1 1000 1000 4357 8月 16 11:05 spark-env.sh7、集群分发
分发到hadoop12 hadoop13 上
myscp.sh ./spark/ /opt/installs/-- myscp.sh是脚本
[root@hadoop11 installs]# cat /usr/local/sbin/myscp.sh
#!/bin/bash# 使用pcount记录传入脚本参数个数pcount=$#
if ((pcount == 0))
thenecho no args;exit;
fi
pname=$1
#根据给定的路径pname获取真实的文件名fname
fname=`basename $pname`
echo "$fname"
#根据给定的路径pname,获取路径中的绝对路径,如果是软链接,则通过cd -P 获取到真实路径
pdir=`cd -P $(dirname $pname);pwd`
#获取当前登录用户名
user=`whoami`
for((host=12;host<=13;host++))
doecho"scp -r $pdir/$fname $user@hadoop$host:$pdir"scp -r $pdir/$fname $user@hadoop$host:$pdir
done
查看hadoop12 和hadoop13 上是否有spark
hadoop12
[root@hadoop12 ~]# cd /opt/installs/
[root@hadoop12 installs]# ll
总用量 4
drwxr-xr-x. 11 root root 173 5月 30 19:59 hadoop3.1.4
drwxr-xr-x. 8 10 143 255 3月 29 2018 jdk1.8
drwxr-xr-x. 3 root root 18 5月 30 20:30 journalnode
drwxr-xr-x. 8 root root 117 8月 3 10:06 kafka3.0
drwxr-xr-x. 13 root root 211 8月 16 11:13 spark
drwxr-xr-x. 11 root root 4096 5月 30 06:39 zookeeper3.4.6
hadoop13
[root@hadoop13 ~]# cd /opt/installs/
[root@hadoop13 installs]# ll
总用量 4
drwxr-xr-x. 11 root root 173 5月 30 19:59 hadoop3.1.4
drwxr-xr-x. 8 10 143 255 3月 29 2018 jdk1.8
drwxr-xr-x. 3 root root 18 5月 30 20:30 journalnode
drwxr-xr-x. 8 root root 117 8月 3 10:06 kafka3.0
drwxr-xr-x. 13 root root 211 8月 16 11:13 spark
drwxr-xr-x. 11 root root 4096 5月 30 06:39 zookeeper3.4.6
三、启动spark
在Master所在的机器上启动
[root@hadoop11 installs]# cd spark/sbin/
# 开启standalone分布式集群
[root@hadoop11 sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/installs/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop11.out
hadoop13: starting org.apache.spark.deploy.worker.Worker, logging to /opt/installs/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop13.out
hadoop12: starting org.apache.spark.deploy.worker.Worker, logging to /opt/installs/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop12.out
hadoop11: starting org.apache.spark.deploy.worker.Worker, logging to /opt/installs/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop11.out
#开启JobHistoryServer
[root@hadoop11 sbin]# ./start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /opt/installs/spark/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-hadoop11.out
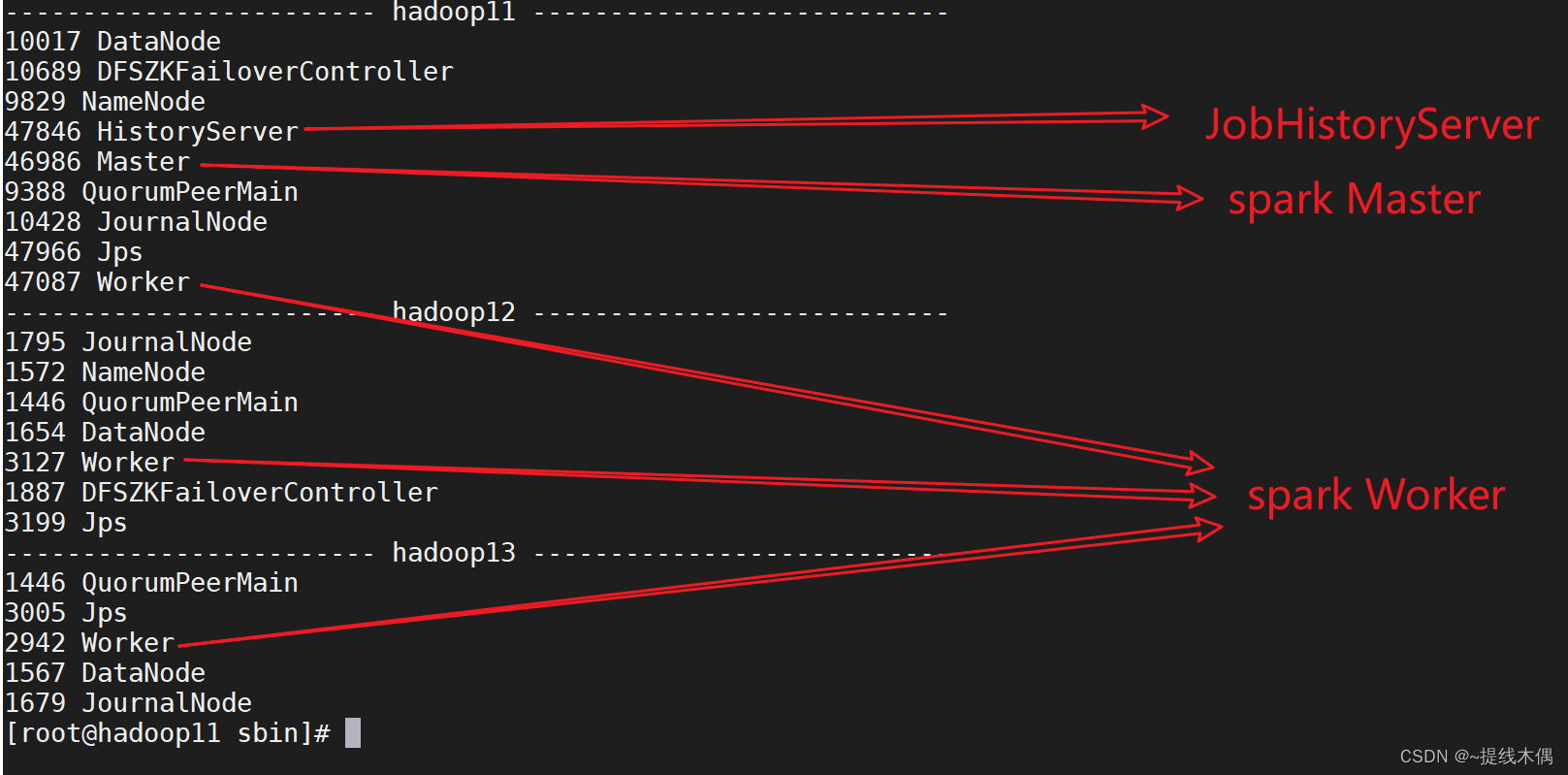
查看 web UI
查看spark的web端
访问8080端口:
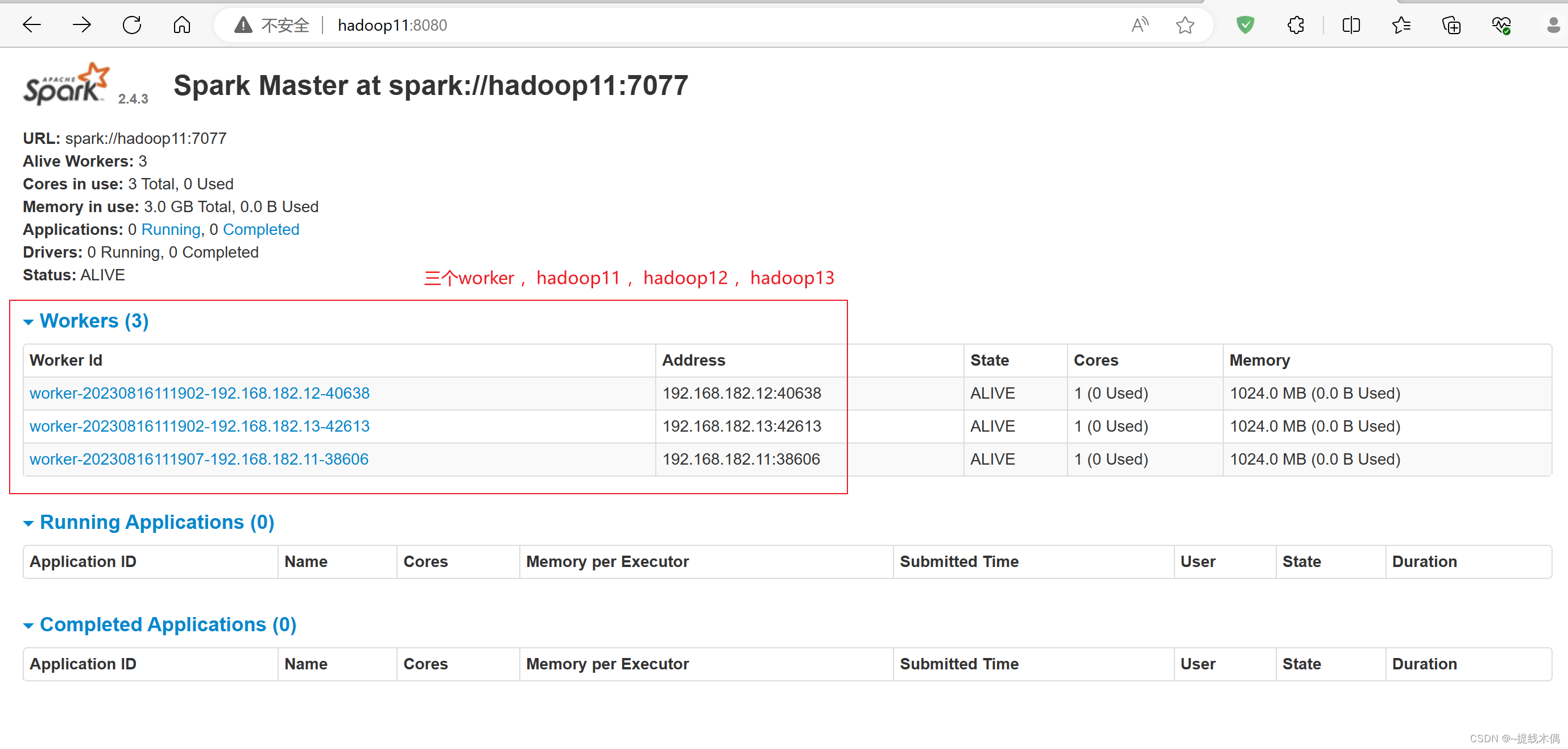
查看历史服务
访问18080端口:

四、初次使用
1、使用IDEA开发部署一个spark程序
(1)pom.xml
<dependencies><!-- spark依赖--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.4.3</version></dependency></dependencies><build><extensions><extension><groupId>org.apache.maven.wagon</groupId><artifactId>wagon-ssh</artifactId><version>2.8</version></extension></extensions><plugins><plugin><groupId>org.codehaus.mojo</groupId><artifactId>wagon-maven-plugin</artifactId><version>1.0</version><configuration><!--上传的本地jar的位置--><fromFile>target/${project.build.finalName}.jar</fromFile><!--远程拷贝的地址--><url>scp://root:root@hadoop11:/opt/jars</url></configuration></plugin><!-- maven项目对scala编译打包 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>4.0.1</version><executions><execution><id>scala-compile-first</id><phase>process-resources</phase><goals><goal>add-source</goal><goal>compile</goal></goals></execution></executions></plugin></plugins></build>
(2)sparkWordCount.scala
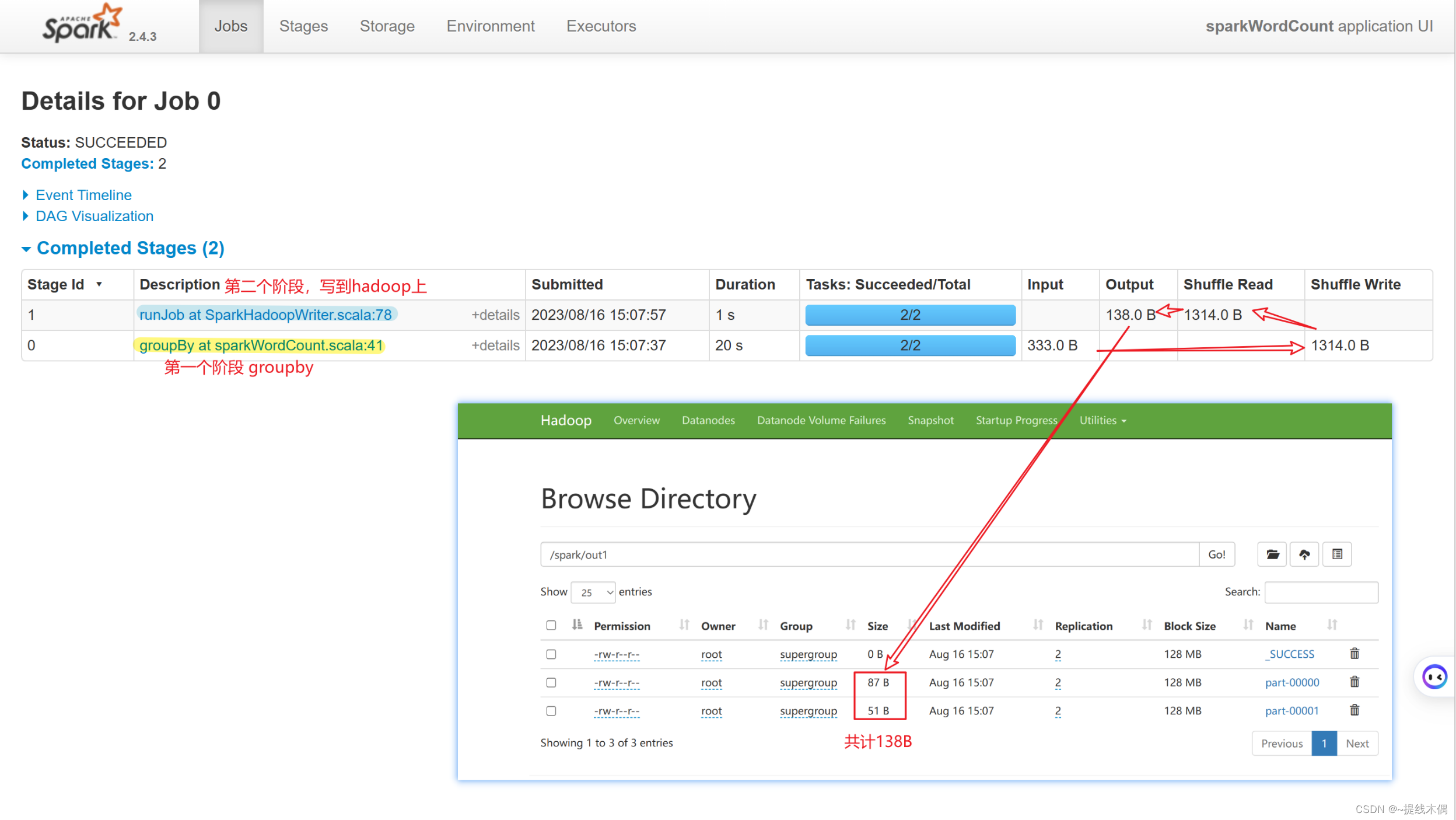
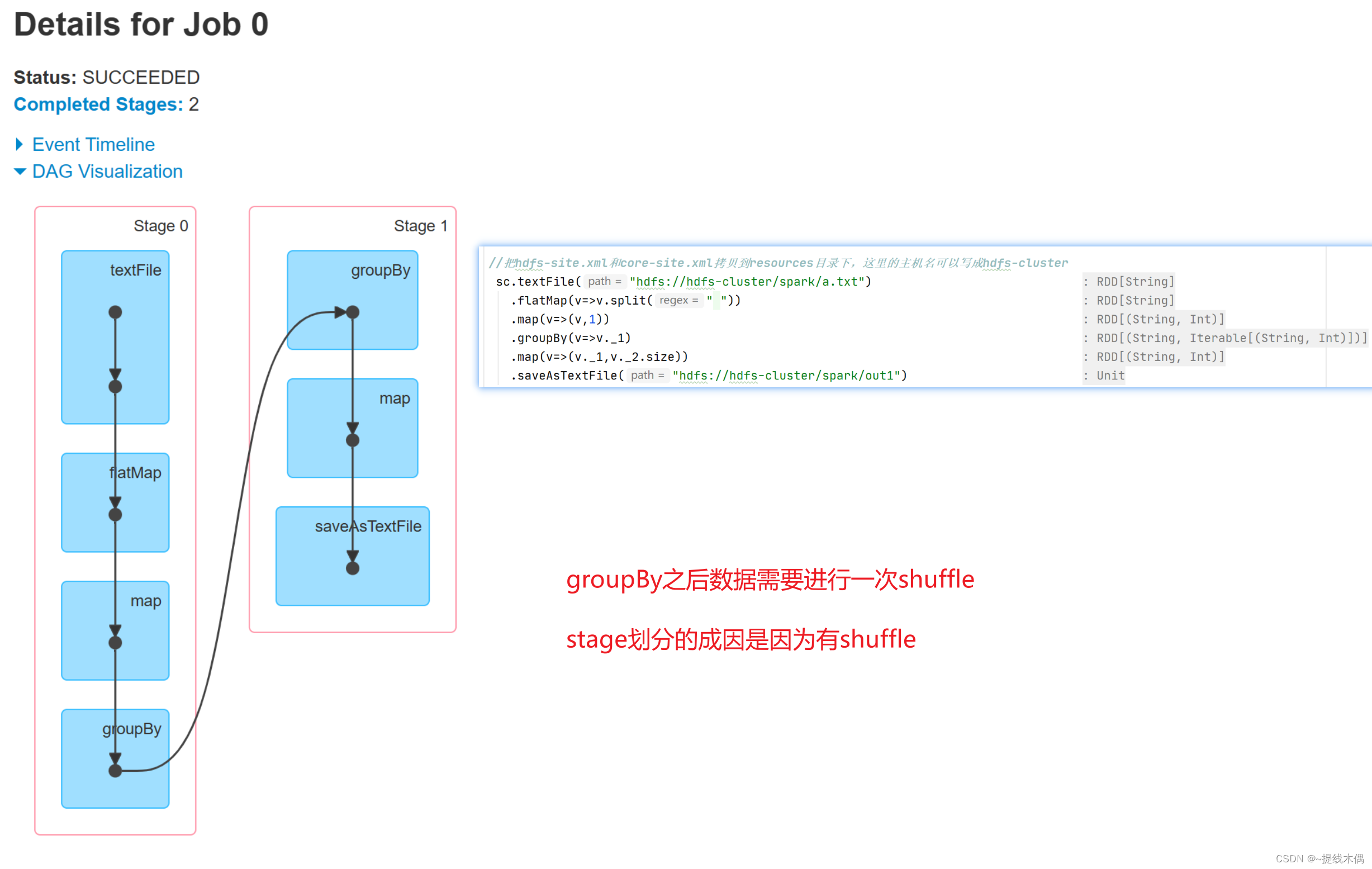
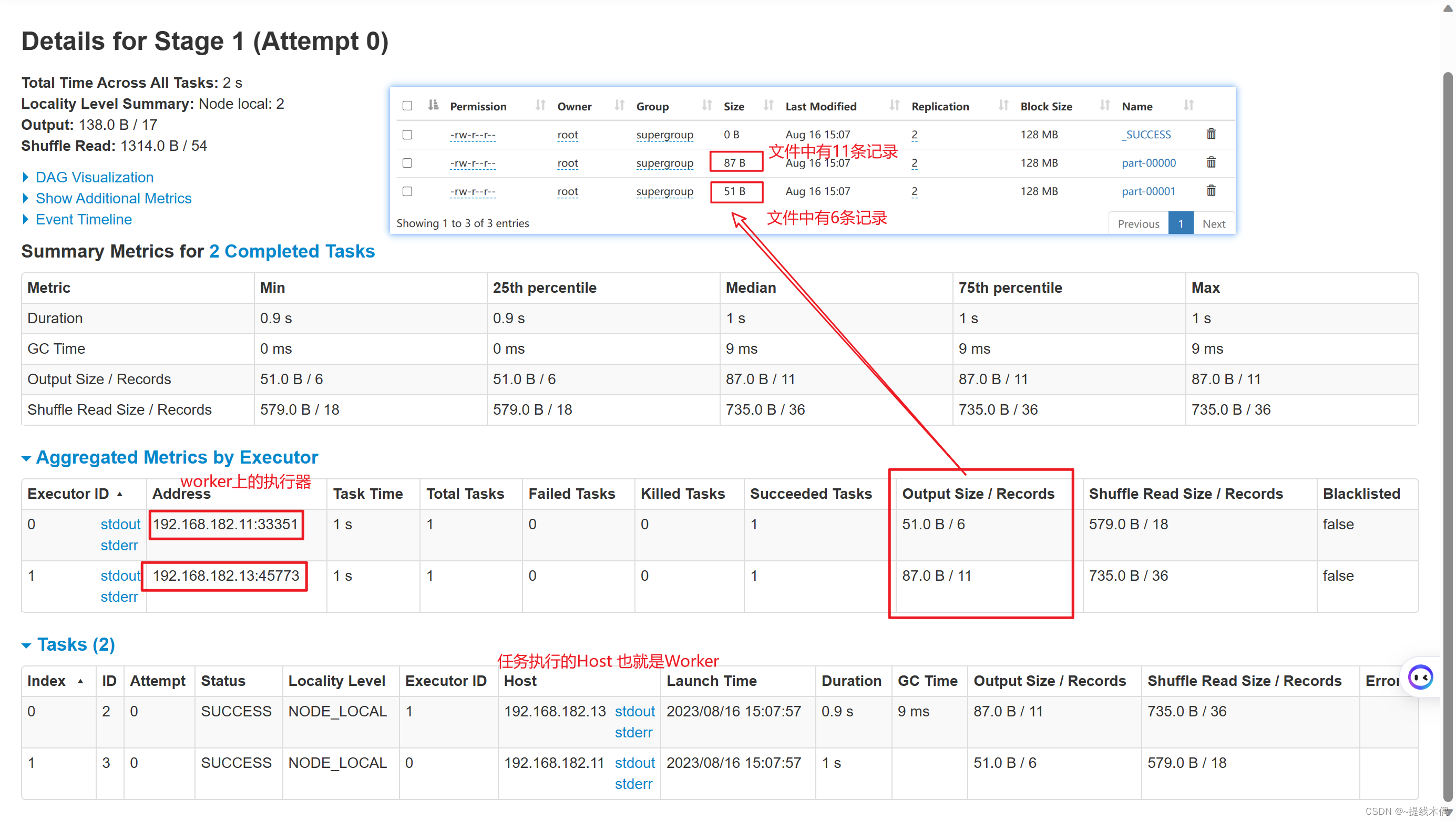
object sparkWordCount {def main(args: Array[String]): Unit = {//1.建立sparkContext对象val conf = new SparkConf().setMaster("spark://hadoop11:7077").setAppName("sparkWordCount")val sc = new SparkContext(conf)//2.对文件进行操作sc.textFile("hdfs://hadoop11:8020/spark/a.txt").flatMap(v=>v.split(" ")).map(v=>(v,1)).groupBy(v=>v._1).map(v=>(v._1,v._2.size)).saveAsTextFile("hdfs://hadoop11:8020/spark/out1")/* //把hdfs-site.xml和core-site.xml拷贝到resources目录下,这里的主机名可以写成hdfs-clustersc.textFile("hdfs://hdfs-cluster/spark/a.txt").flatMap(v=>v.split(" ")).map(v=>(v,1)).groupBy(v=>v._1).map(v=>(v._1,v._2.size)).saveAsTextFile("hdfs://hdfs-cluster/spark/out1")*///3.关闭资源sc.stop()}
(3)打包,上传
要现在hadoop11的 /opt下面新建一个jars文件夹
[root@hadoop11 hadoop]# cd /opt/
[root@hadoop11 opt]# mkdir jars
[root@hadoop11 opt]# ll
总用量 0
drwxr-xr-x. 9 root root 127 8月 16 10:39 installs
drwxr-xr-x. 2 root root 6 8月 16 14:05 jars
drwxr-xr-x. 3 root root 179 8月 16 10:33 modules
[root@hadoop11 opt]# cd jars/
(4)运行这个jar包
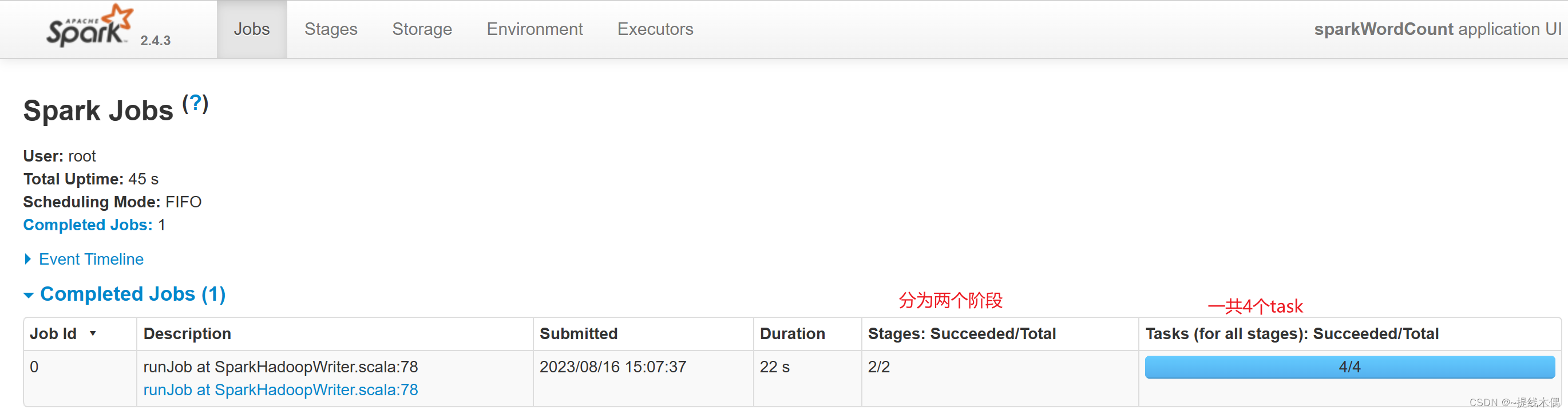
spark-submit --master spark://hadoop11:7077 --class day1.sparkWordCount /opt/jars/spark-test-1.0-SNAPSHOT.jar
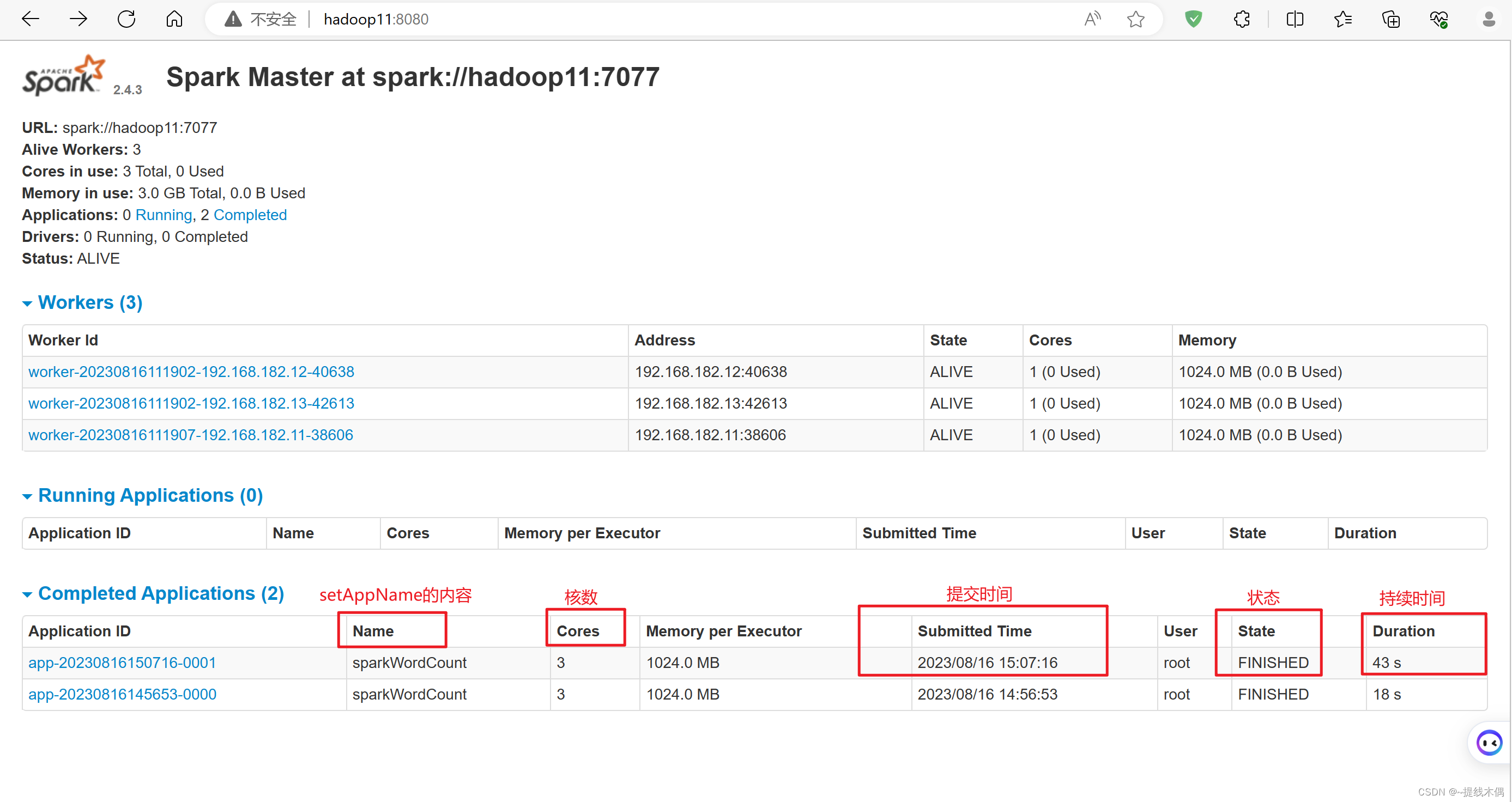
看一下8080端口:
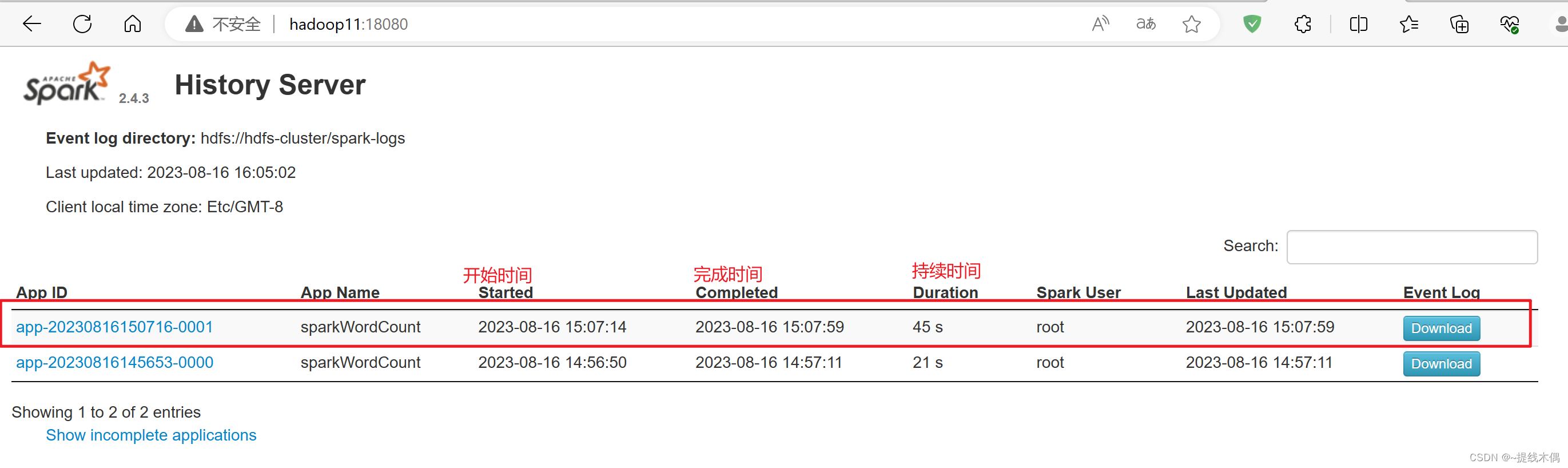
看一下18080端口:
相关文章:
spark的standalone 分布式搭建
一、环境准备 集群环境hadoop11,hadoop12 ,hadoop13 安装 zookeeper 和 HDFS 1、启动zookeeper -- 启动zookeeper(11,12,13都需要启动) xcall.sh zkServer.sh start -- 或者 zk.sh start -- xcall.sh 和zk.sh都是自己写的脚本-- 查看进程 jps -- 有…...
浅析基于视频汇聚与AI智能分析的新零售方案设计
一、行业背景 近年来,随着新零售概念的提出,国内外各大企业纷纷布局智慧零售领域。从无人便利店、智能售货机,到线上线下融合的电商平台,再到通过大数据分析实现精准推送的个性化营销,智慧零售的触角已经深入各个零售…...
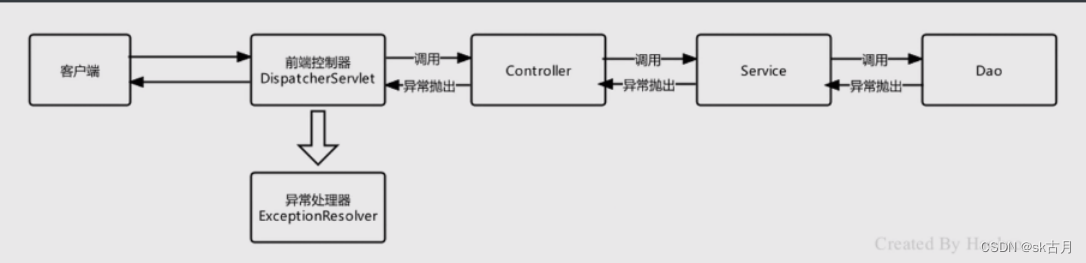
SpringMVC之异常处理
SpringMVC之异常处理 异常分为编译时异常和运行时异常,编译时异常我们trycatch捕获,捕获后自行处理,而运行时异常是不可预期的,就需要规范编码来避免,在SpringMVC中,不管是编译异常还是运行时异常ÿ…...

保险龙头科技进化论:太保的六年
如果从2013年中国首家互联网保险公司——众安在线的成立算起,保险科技在我国的发展已走进第十个年头。十年以来,在政策指引、技术发展和金融机构数字化转型的大背景下,科技赋能保险业高质量发展转型已成为行业共识。 大数据、云计算、人工智…...

升级STM32电机PID速度闭环编程:从F1到F4的移植技巧与实例解析
引言: 在嵌入式系统开发中,STM32系列微控制器广泛应用于各种应用领域。而对于直流有刷电机的控制,PID速度闭环是一种常用的控制方式。本文将以此为例,探讨如何从STM32F1系列移植到STM32F4系列,并详细介绍HAL库在不同型…...

GaussDB 实验篇+openGauss的4种1级分区案例
✔ 范围分区/range分区 -- 创建表 drop table if exists zzt.par_range; create table if not exists zzt.par_range (empno integer,ename char(10),job char(9),mgr integer(4),hiredate date,sal numeric(7,2),comm numeric(7,2),deptno integer,constraint pk_par_emp pri…...
Ruby软件外包开发语言特点
Ruby 是一种动态、开放源代码的编程语言,它注重简洁性和开发人员的幸福感。在许多方面都具有优点,但由于其动态类型和解释执行的特性,它可能不适合某些对性能和类型安全性要求较高的场景。下面和大家分享 Ruby 语言的一些主要特点以及适用的场…...
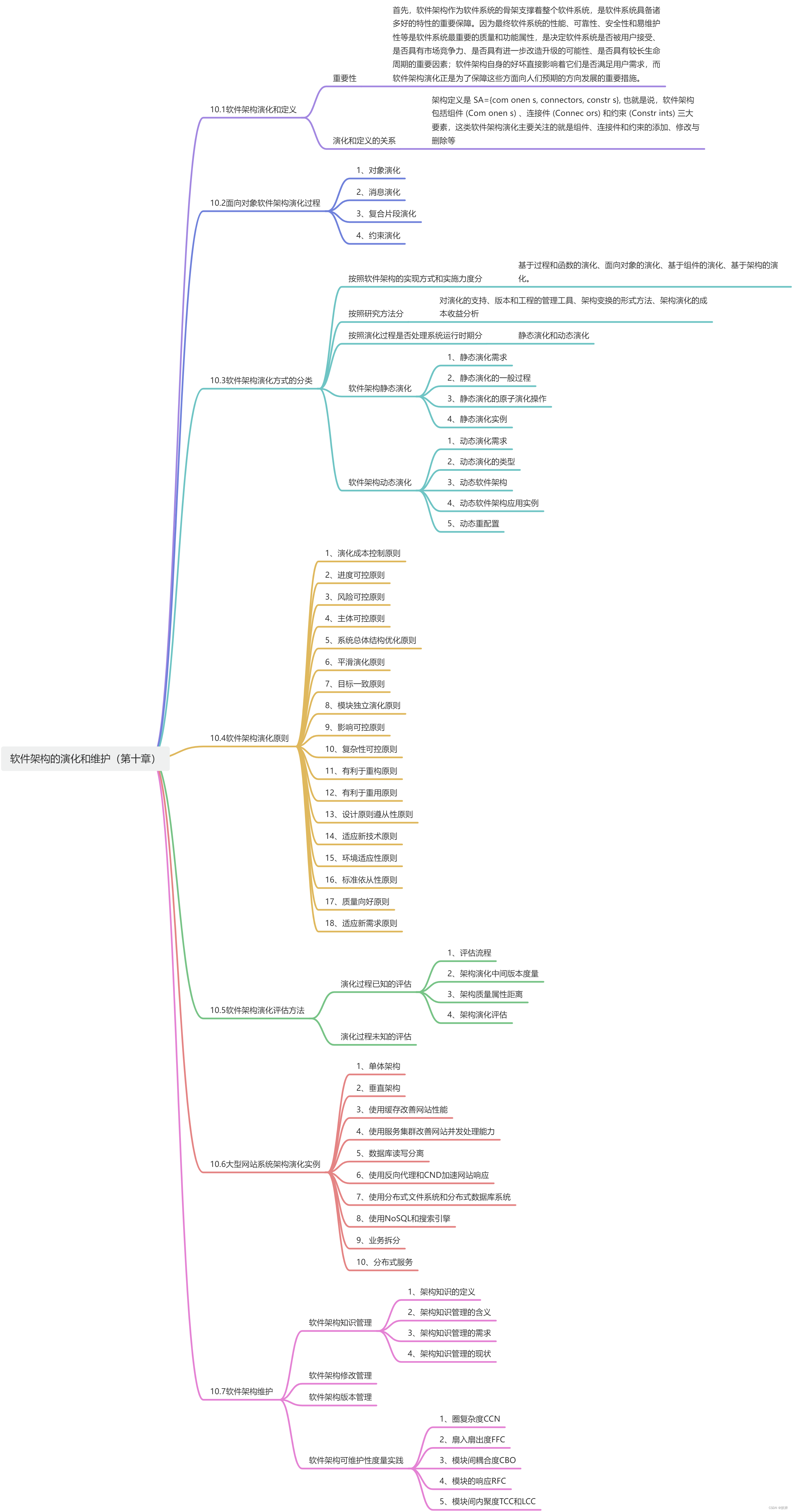
《系统架构设计师教程》重点章节思维导图
内容来自《系统架构设计师教程》,筛选系统架构设计师考试中分值重点分布的章节,根据章节的内容整理出相关思维导图。 重点章节 第2章:计算机系统知识第5章:软件工程基础知识第7章:系统架构设计基础知识第8章࿱…...

mac录屏工具,录屏没有声音的解决办法
mac录屏工具,录屏没有声音的解决办法 在使用macbook录制屏幕时,发现自带的录屏工具QuickTime Player没有声音,于是尝试了多款录屏工具,对其做一些经验总结(省流:APP Store直接可以免费下载使用Omi录屏专家…...

神经网络基础-神经网络补充概念-33-偏差与方差
概念 偏差(Bias): 偏差是模型预测值与实际值之间的差距,它反映了模型对训练数据的拟合能力。高偏差意味着模型无法很好地拟合训练数据,通常会导致欠拟合。欠拟合是指模型过于简单,不能捕捉数据中的复杂模式…...
单片机第一季:零基础13——AD和DA转换
1,AD转换基本概念 51 单片机系统内部运算时用的全部是数字量,即0 和1,因此对单片机系统而言,无法直接操作模拟量,必须将模拟量转换成数字量。所谓数字量,就是用一系列0 和1 组成的二进制代码表示某个信号大…...

小区外卖跑腿,解决最后100米配送难题
小区外卖跑腿,解决最后100米配送难题 小区外卖跑腿作为新市场环境下的创业模式,通过选择小区里的闲散人员作为骑手,解决了最后100米配送的问题。这项业务不仅包括小区业主的取快递、寄快递等日常需求,还能提供小区帮忙、小区外卖…...
ZooKeeper的应用场景(命名服务、分布式协调通知)
3 命名服务 命名服务(NameService)也是分布式系统中比较常见的一类场景,在《Java网络高级编程》一书中提到,命名服务是分布式系统最基本的公共服务之一。在分布式系统中,被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象等一这…...
网络套接字
网络套接字 文章目录 网络套接字认识端口号初识TCP协议初识UDP协议网络字节序 socket编程接口socket创建socket文件描述符bind绑定端口号sockaddr结构体netstat -nuap:查看服务器网络信息 代码编译运行展示 实现简单UDP服务器开发 认识端口号 端口号(port)是传输层协…...

对话 4EVERLAND:Web3 是云计算的新基建吗?
在传统云计算的发展过程中,数据存储与计算的中心化问题,对用户来说一直存在着潜在的安全与隐私风险——例如单点故障可能会导致网络瘫痪和数据泄露等危险。同时,随着越来越多 Web3 项目应用的落地,对于数据云计算的性能要求也越来…...
iOS申请证书(.p12)和描述文件(.mobileprovision)
打包app时,经常会用到ios证书,但很多人都苦于没有苹果电脑,即使有苹果电脑的,也会觉得苹果电脑操作也很麻烦,这里记录一下,用香蕉云编,申请证书及描述文件的过程。 香蕉云编的地址:…...

Java:PO、VO、BO、DO、DAO、DTO、POJO
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! Java:PO、VO、BO、DO、DAO、DTO、POJO PO持久化对象(Persistent Object) PO是持久化对象,用于表示数据库中的实体或表…...
c语言每日一练(8)
前言:每日一练系列,每一期都包含5道选择题,2道编程题,博主会尽可能详细地进行讲解,令初学者也能听的清晰。每日一练系列会持续更新,暑假时三天之内必有一更,到了开学之后,将看学业情…...
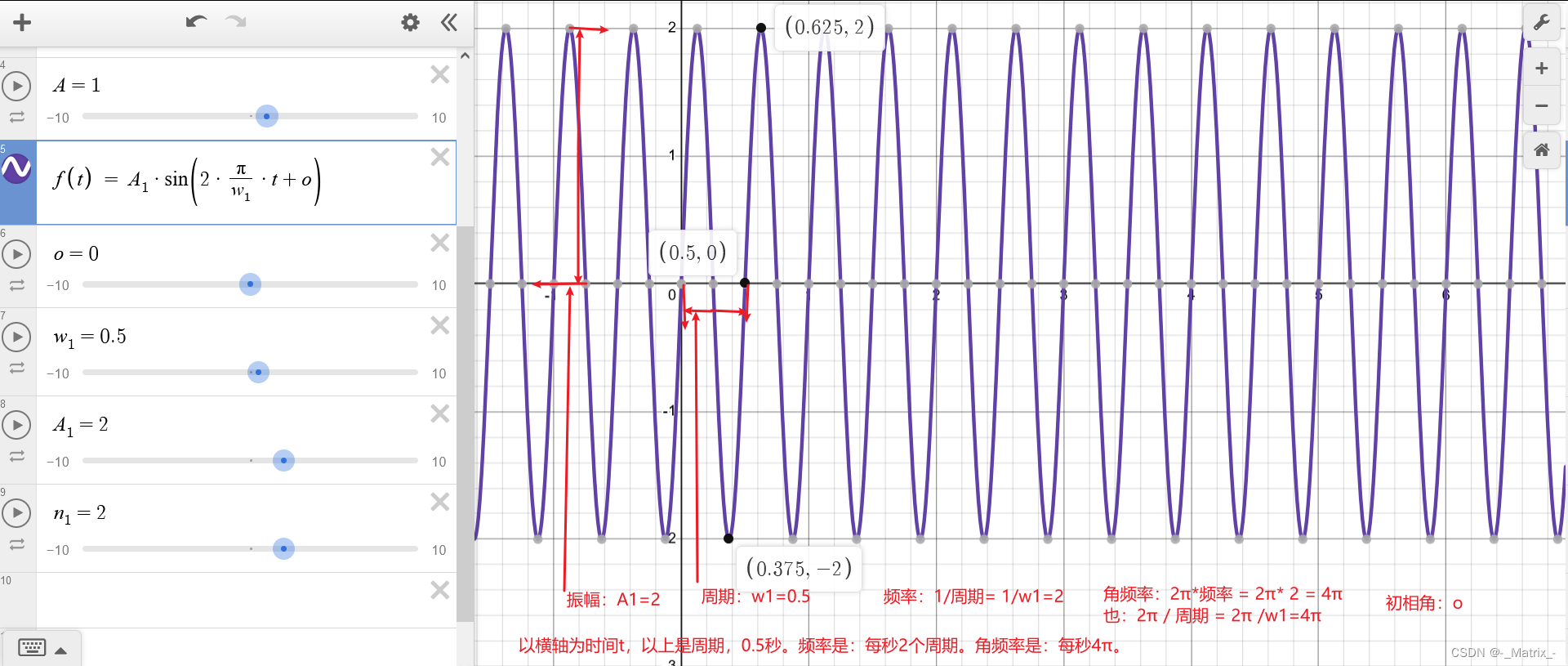
周期 角频率 频率 振幅 初相角
周期 角频率 频率 振幅 初相角 当我们谈论傅里叶级数或波形分析时,以下术语经常出现: 周期 T T T: 函数在其图形上重复的时间或空间的长度。周期的倒数是频率。 频率 f f f: 周期的倒数,即一秒内波形重复的次数。单位通常为赫兹ÿ…...

根据一棵树的两种遍历构造二叉树
题目 给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。 示例 1: 输入: preorder [3,9,20,15,7], inorder [9,3,15,20,7] 输出: [3,9,20,null,null,…...

荧光改性PEG磷脂
我们提供荧光改性PEG磷脂的定制开发与规模化制备服务,面向脂质体构建、纳米递送体系标记、膜界面行为追踪等研究与应用需求,可在分子结构设计、荧光模块选择、PEG链段调控以及磷脂骨架匹配等多个层面提供针对性方案,支持从实验室小试到中试放…...

基于MCP3421高精度ADC的电池电量监测方案设计与实践
1. 项目概述:为什么需要一个专用的电量监测板?在嵌入式开发和物联网设备中,电池供电是常态。无论是手持仪表、无线传感器节点还是便携式医疗设备,准确掌握电池的剩余电量,就像司机需要时刻关注油表一样,是确…...

Layerdivider深度解析:5步实现智能图像分层,生成专业级PSD文件
Layerdivider深度解析:5步实现智能图像分层,生成专业级PSD文件 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider Layerdivider是一款…...

Agent Runtime 九个关键设计:状态外化、上下文压缩与多智能体协同
把 Agent 从能跑到可靠,关键不在模型神准,而在状态、上下文和协作工程。 原文链接:AI 小老六 聊 Agent 时,很多讨论容易落到模型能力上:模型会不会推理,代码写得准不准,能不能理解复杂需求。这些…...

VisualCppRedist AIO:一站式解决Windows C++运行库依赖问题
VisualCppRedist AIO:一站式解决Windows C运行库依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行库是Windows系统中许多应用程序…...
)
protobufjs 编译命令选错就报错?一文搞懂 pbjs 的 -w 参数(es6 vs commonjs 实战解析)
ProtobufJS编译模块类型选型指南:ES6与CommonJS的深度对比与实战避坑 最近在Vite项目中集成Protobuf时,编译后的模块导入总是抛出The requested module does not provide an export named错误。这个问题困扰了我整整两天,最终发现根源在于pbj…...

避坑!用ArcGIS计算格网内耕地比例时,90%的人会忽略的数据连接问题
避坑!用ArcGIS计算格网内耕地比例时,90%的人会忽略的数据连接问题 在土地利用规划、农业资源评估等GIS应用中,计算规则格网内的耕地面积占比是一项基础但关键的操作。许多从业者能够顺利完成渔网创建、耕地提取和分区统计步骤,却在…...

SD-PPP终极秘籍:在Photoshop中直接召唤AI助手的实战宝典
SD-PPP终极秘籍:在Photoshop中直接召唤AI助手的实战宝典 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp 你是否曾为了给设计作品添加AI特效,不得不在Photoshop和AI工具间来回切换、导出导入…...

量子机器学习革新气象预测:高效台风轨迹建模
1. 量子机器学习在气象预测中的革新应用台风轨迹预测一直是气象学领域的重大挑战。传统数值天气预报(NWP)模型依赖于超级计算机集群,需要处理海量的大气动力学数据,计算成本高昂且能耗巨大。以台湾地区为例,每年平均遭受3.5次台风袭击&#x…...

实验干货:多因子细胞因子流式检测CBA技术
速懂CBA技术:原理简洁明了,优势一目了然CBA技术的核心运作模式,本质是“荧光微球编码技术”与“流式细胞检测技术”的有机结合。其原理可通俗解读为:以携带不同荧光强度的微球作为特异性捕获载体,每一种微球的表面都包…...