【数据结构】_7.二叉树概念与基本操作
目录
1.树形结构
1.1 树的概念
1.2 树的相关概念
1.3 树的表示
1.4 树在实际中的应用—表示文件系统的目录树结构
编辑2.二叉树
2.1 概念
2.2 特殊二叉树
2.3 二叉树的性质
2.4 二叉树的存储结构
2.4.1 顺序存储结构(数组存储结构)
2.4.2 链式存储结构
2.5 二叉树的基本操作
2.5.1 二叉树的深度优先遍历
2.5.2 二叉树的广度优先遍历
2.5.3 二叉树的结点统计
2.5.4 二叉树的叶子结点统计
2.5.5 二叉树第K层结点统计
2.5.6 获取二叉树的高度
2.5.7 检测值为value的元素是否存在
2.5.8 判断一棵树是否为完全二叉树
2.6 二叉树的非递归方法
2.6.1 非递归实现前序遍历
2.6.2 非递归实现中序遍历
2.6.3 非递归实现后序遍历
1.树形结构
1.1 树的概念
树是一种非线性数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合,把它称为树是因为它看起来像一棵倒挂的树,根在上,枝叶在下。
① 根节点是一个没有前驱结点的特殊结点;
② 除根节点外,其余结点被分为M(M>0)个互不相交的集合T1,T2,T3...Tm,其中每一个集合Ti(1<=i<=m)又是一棵结构与树类型相似的子树,每棵树的根节点有且仅有一个前驱,可以有0个或多个后继;
③ 因此,树是递归定义的;
PS:树形结构中,子树之间不能有交集,即除了根节点之外,每个结点有且仅有一个直接前驱;
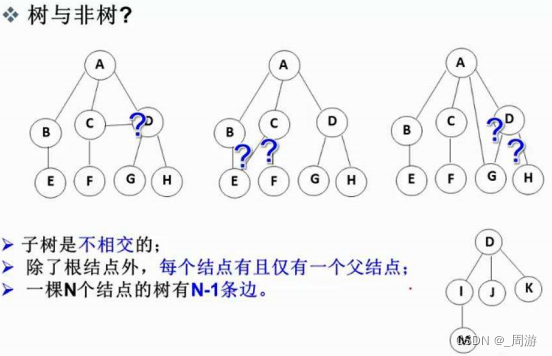
1.2 树的相关概念

(1)结点的度:一个结点含有的子树的个数,如A结点的度为6;
(2)叶结点或终端结点:度为0的结点,如H、I、P、Q、K、L、M、N;
(3)非终端结点或分支结点:度不为0的结点,如:D、E、F、G、J;
(4)双亲结点或父节点:含有子结点的结点,称该结点为其子结点的父结点,如A是B的父结点;
(5)孩子结点或子结点:一个结点含有的子树的根节点称为该结点的子结点,如B是A的子结点;
(6)兄弟结点:具有相同父结点的结点,如B和C是兄弟结点;
(7)数的度:一棵树中最大的结点的度称为数的度,如上图树的度为6;
(8)结点的层次:从根开始定义,根为第一层,根的子结点为第二层,以此类推;
(9)树的高度或深度:树中结点的最大层次,如上图树的高度或深度为4;
(10)堂兄弟结点:双亲在同一层的结点称为堂兄弟,如H和I互为堂兄弟结点;
(11)结点的祖先:从根到该结点所经分支上的所有结点,如A是所有结点的祖先;
(12)子孙:以某节点为根的子树中任一结点都成为该结点的子孙,如所有节点都是A的子孙;
(13)森林:由m(m>0)棵互不相交的树的集合称为森林;
1.3 树的表示
树的存储相较于线性表要复杂得多,既要存储值域,也要存储结点与结点之间的关系;
树有很多种表达方式,如双亲表示法、孩子表示法、孩子-双亲表示法。
最常用的是:左孩子-右兄弟表示法。
图示:

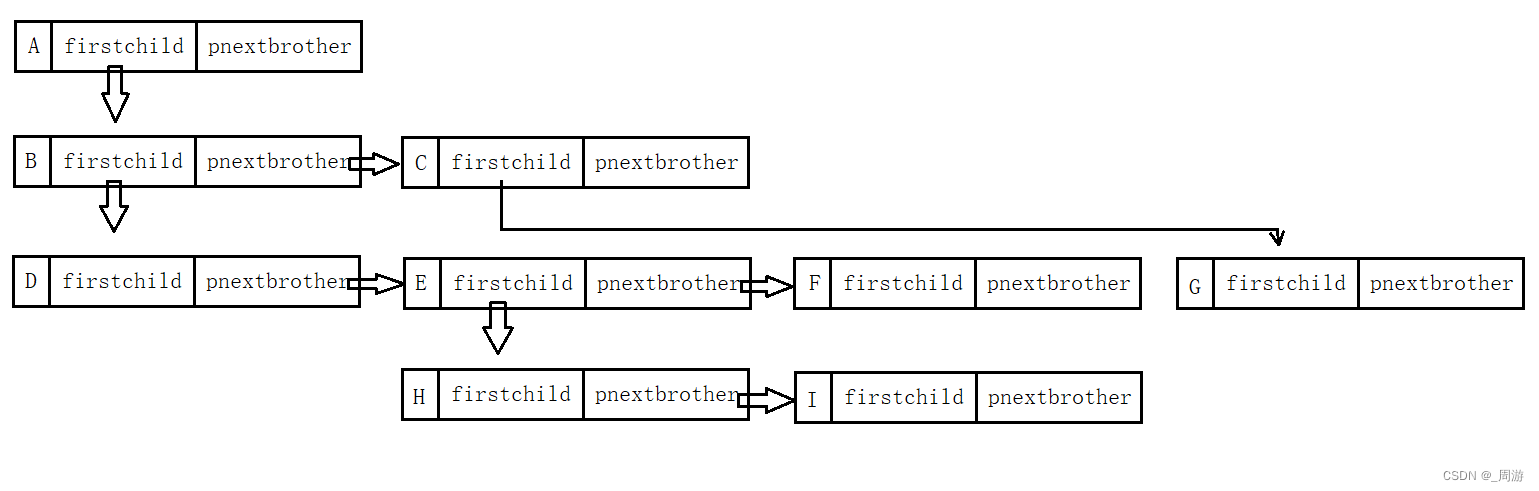
代码表示:
class Node{int val; // 数据域Node firstChild; // 第一个孩子引用Node nextBrother; // 下一个兄弟引用
}
//注意此处的兄弟指的是亲兄弟而非堂兄弟,即此处指向的兄弟有相同的祖先1.4 树在实际中的应用—表示文件系统的目录树结构

2.二叉树
2.1 概念
(1)一个二叉树的结点是一个有限集合,该集合:① 或者为空 ② 有一个根节点加上两个别称为左子树和右子树的二叉树组成;
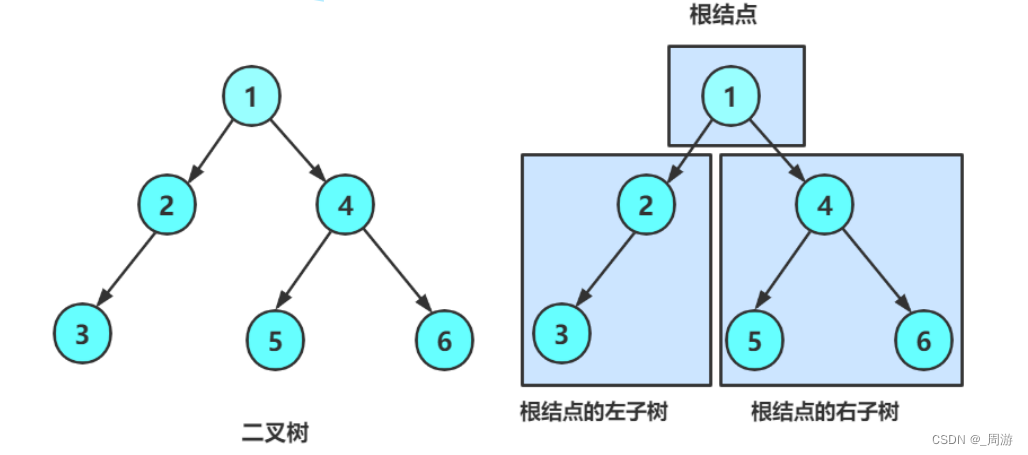
(2)特点:
① 不存在度大于2的结点;
② 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树;
(3)任意一种二叉树都是由①空树②只有根节点③只存在左子树④只存在右子树⑤左右子树均存在这五种情况复合而成;
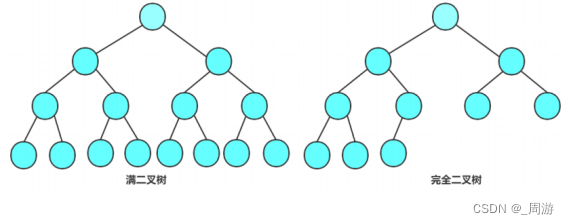
2.2 特殊二叉树
(1)满二叉树:
每层节点数都是最大值的二叉树,即满足层数为k,结点总数是2^k-1的二叉树就是完全二叉树。
(2)完全二叉树:
对于深度为k的二叉树,前k-1层的结点都是满的,最后一层不满但满足,存在的结点是从左向右是连续的。
2.3 二叉树的性质
(1)若规定根结点层数为1,则一棵非空二叉树的第i层上最多有2^(i-1)个结点;
(2)若规定根结点层数为1,则深度为h的二叉树的最大结点数是2^k-1;
(3)对任何一个二叉树,如果度为0的结点个数为n0,度为2的分支节点个数为n2,则有n0=n2+1;
(4)若规定根节点的层数为1,具有n个结点的满二叉树的深度,h=log2(n+1)(以2为底);
例1:某二叉树共有399个结点,其中199个度为2的结点,则该二叉树中的叶子节点数为(B)
A.不存在这样的二叉树 B.200 C.198 D. 199
解析:根据第三条性质,叶子结点数即度为0的结点数,根据第三条性质得答案。
例2:在具有2n个结点的完全二叉树中,叶子结点个数为(A)
A.n B.n+1 C. n-1 D.n/2
解析:度为0的结点记为n0,度为1的结点记为n1,度为2的结点记为n2,根据题意有:
n0+n1+n2=2n,结合第三条性质有:n2=n0-1,代入有2*n0-1+n1=2n,对于一个完全二叉树来
说,度为1的结点只能有0个或1个,此处若n1=0,则n0为小数,故而n1只能为1,所以度为0的结
点个数为n。
例3:一个完全二叉树结点数为531个,那么这棵树的高度为(B)
A.11 B. 10 C.8 D.12
解析:高度为h的完全二叉树,结点范围是[2^(h-1),2^h-1],代入选项进行上下限计算得答案。
例4:一个具有767个结点的完全二叉树,其叶子结点个数为(B)
A.383 B. 384 C.385 D.386
解析略,同例二思路
2.4 二叉树的存储结构
二叉树的存储有两种存储方式:
2.4.1 顺序存储结构(数组存储结构)
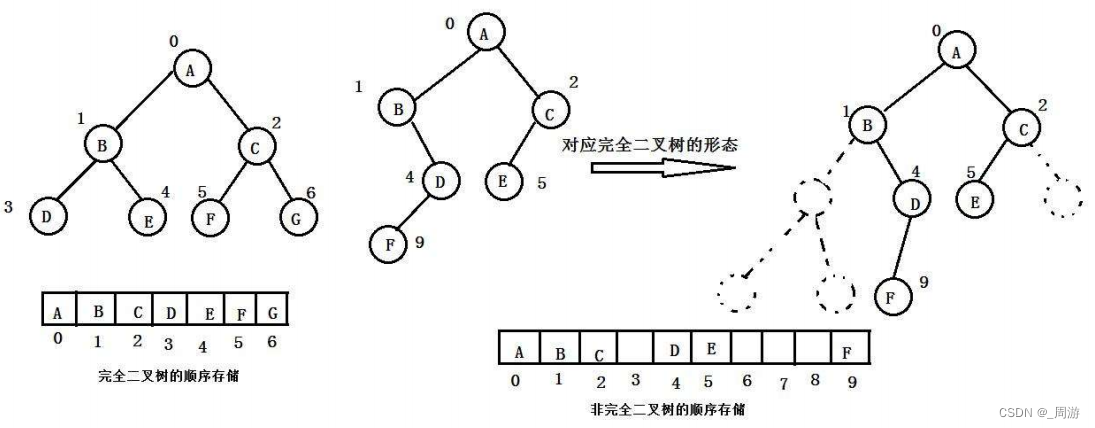
① 一般使用数组存储只适合表示完全二叉树或满二叉树,若是一般二叉树会存在很多空间浪费;
在现实使用中,只有对才会使用数组来存储;
② 二叉树的顺序存储在物理上是一个数组,在逻辑上是一个二叉树。
③ 同时顺序存储可以根据下标计算结点父子关系:
知父求子:leftchild=parent*2+1,leftchild=parent*2+2;
知子求父:(parent-1)/2;
2.4.2 链式存储结构
二叉树的链式存储是通过一个一个的结点引用起来的,常见的表示方式有:
(1)二叉表示法(孩子表示法):
class Node{int val; // 数据域Node left; // 左孩子引用(常代表以左孩子为根的整个左子树)Node right; // 右孩子引用(常代表以右孩子为根的整个右子树)
}(2)三叉表示法(孩子-双亲表示法):
class Node{int val; // 数据域Node left; // 左孩子引用(常代表以左孩子为根的整个左子树)Node right; // 右孩子引用(常代表以右孩子为根的整个右子树)Node parent; // 当前结点的根节点
}孩子-双亲表示法主要应用在平衡树,本文采取孩子表示法构建二叉树;
2.5 二叉树的基本操作
2.5.1 二叉树的深度优先遍历
深度优先遍历包括前序遍历、中序遍历与后序遍历;
前序遍历:访问根结点的操作发生在遍历其左右子树之前;(跟->左子树->右子树)
中序遍历:访问根结点的操作发生在遍历其左右子树之中;(左子树->根->右子树)
后序遍历:访问根结点的操作发生在遍历其左右子树之后;(左子树->右子树->根)

以#表示空:
前序遍历:1 2 3 # # # 4 5 # # 6 # #
中序遍历:# 3 # 2 # 1 # 5 # 4 # 6 #
后序遍历:# # 3 # 2 # # 5 # # 6 4 1
基于以下二叉树结构:
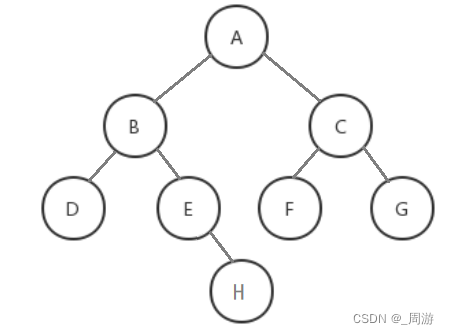
其递归实现代码如下:
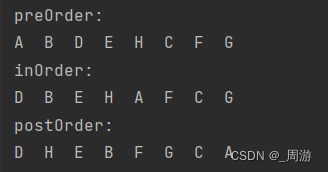
// 前序遍历:根 左子树 右子树 递归public void preOrder(TreeNode root){if(root == null){return;}System.out.print(root.val+" ");preOrder(root.left);preOrder(root.right);}// 中序public void inOrder(TreeNode root){if(root == null){return;}inOrder(root.left);System.out.print(root.val+" ");inOrder(root.right);}// 后序public void postOrder(TreeNode root){if(root == null){return;}postOrder(root.left);postOrder(root.right);System.out.print(root.val+" ");}创建对象后分别调用,输出结果为:
注:除过空返回值的写法外,也可以令深度优先遍历有返回值:
(1)遍历思路写法:
List<Character> ret = new ArrayList<>();public List<Character> preorderTraversal(TreeNode root){if(root == null){return ret;}ret.add(root.val);preorderTraversal(root.left);preorderTraversal(root.right);return ret;}(2)子问题思路写法:
public List<Character> preorderTraversal(TreeNode root){List<Character> ret = new ArrayList<>();if(root == null){return ret;}//System.out.print(root.val+" ");ret.add(root.val);List<Character> leftTree = preorderTraversal(root.left);ret.addAll(leftTree);List<Character> rightTree = preorderTraversal(root.right);ret.addAll(rightTree);return ret;}2.5.2 二叉树的广度优先遍历
创建一个队列,令cur从root开始遍历,在根节点不为空的条件下,将root入队列,依次判断root.left和root.right是否为空,非空则入队列,当队列不为空时,出栈对首元素并令root = cur;
public void levelOrder(TreeNode root){if(root == null){return;}Queue<TreeNode> queue = new LinkedList<>();queue.offer(root);while(!queue.isEmpty()){TreeNode cur = queue.poll();System.out.print(cur.val+" ");if(cur.left != null){queue.offer(cur.left);}if(cur.right != null){queue.offer(cur.right);}}}输出结果为:

2.5.3 二叉树的结点统计
(1)思路1:子问题思路:
public int size(TreeNode root){// 左树结点+右树结点+根节点// 写法1://return root == null? 0: size(root.left)+size(root.right)+1;// 写法2:if(root == null){return 0;}int leftSize = size(root.left);int rightSize = size(root.right);return leftSize + rightSize + 1;}(2)思路2:遍历思路:
public int nodeSize;public void size2(TreeNode root){if(root == null){return;}nodeSize++;size2(root.left);size2(root.right);}测试代码为:
System.out.println("子问题思路求二叉树结点:");System.out.println(binaryTree.size(binaryTree.root));System.out.println("遍历思路求二叉树结点:");binaryTree.size2(binaryTree.root);System.out.println(binaryTree.nodeSize);输出结果为:

2.5.4 二叉树的叶子结点统计
(1)思路1:子问题思路:
public int getLeafNodeCount(TreeNode root){if(root == null){return 0;}if(root.left==null && root.left == null){return 1;}int leftTreeNode = getLeafNodeCount(root.left);int rightTreeNode = getLeafNodeCount(root.right);return leftTreeNode+rightTreeNode;}(2)思路2:遍历思路:
public int leafNode = 0;public void getLeafNodeCount2(TreeNode root){if(root == null){return;}if(root.left == null && root.right == null){leafNode++;}getLeafNodeCount2(root.left);getLeafNodeCount2(root.right);}测试代码为:
System.out.println("子问题思路求叶子节点的个数为:");System.out.println(binaryTree.getLeafNodeCount(binaryTree.root));System.out.println("遍历思路求叶子结点个数为:");binaryTree.getLeafNodeCount2(binaryTree.root);System.out.println(binaryTree.leafNode);输出结果为:

2.5.5 二叉树第K层结点统计
(仅展示子问题思路)
public int getKLevelNodeCount(TreeNode root, int k){if(root == null){return 0;}if(k==1){return 1;}int leftTreeNode = getKLevelNodeCount(root.left,k-1);int rightTreeNode = getKLevelNodeCount(root.right,k-1);return leftTreeNode+rightTreeNode;}测试代码为:
TestBinaryTree binaryTree = new TestBinaryTree();binaryTree.root = binaryTree.createTree();System.out.println("请输入要查询结点的层数:");Scanner scanner = new Scanner(System.in);int k = scanner.nextInt();System.out.println("第"+k+"层结点数为:");System.out.println(binaryTree.getKLevelNodeCount(binaryTree.root,k));输出结果为:
2.5.6 获取二叉树的高度
public int getHeight(TreeNode root){// 二叉树高度是左右子树高度的较大值+1if(root==null){return 0;}int leftTreeHeight = getHeight(root.left);int rightTreeHeight = getHeight(root.right);return (leftTreeHeight>rightTreeHeight)?leftTreeHeight+1:rightTreeHeight+1;}测试代码为:
TestBinaryTree binaryTree = new TestBinaryTree();binaryTree.root = binaryTree.createTree();System.out.println("当前二叉树高度为:");System.out.println(binaryTree.getHeight(binaryTree.root));输出结果为:

2.5.7 检测值为value的元素是否存在
public TreeNode find(TreeNode root, char val){// 前序遍历二叉树if(root == null){return null;}if(root.val == val){return root;}TreeNode leftTree = find(root.left, val);if(leftTree != null){return leftTree;}TreeNode rightTree = find(root.right, val);if(rightTree != null){return rightTree;}return null;}测试代码为:
TestBinaryTree binaryTree = new TestBinaryTree();binaryTree.root = binaryTree.createTree();System.out.println("请输入要查询的value值:");char value = (char)System.in.read();TestBinaryTree.TreeNode ret = binaryTree.find(binaryTree.root, value);if(ret != null){System.out.println(ret.val);}else {System.out.println(ret);}输出结果为·:
2.5.8 判断一棵树是否为完全二叉树
创建一个队列,在根结点不为空的前提下,先将根结点入队列,然后每弹出一个队首元素,就将其左右孩子结点入队列,直到队首元素为空,若此时队列中元素全为空,则为完全二叉树,否则就不是完全二叉树;
代码:
public boolean isCompleteTree(TreeNode root){if(root == null){return true;}Queue<TreeNode> queue = new LinkedList<>();queue.offer(root); // 将根结点入队列while( !queue.isEmpty()) {// 每弹出一个队首元素,就将该元素的左右孩子入队列;TreeNode cur = queue.poll();if (cur != null) {queue.offer(cur.left);queue.offer(cur.right);} else {// 一直出队列队首元素直至队首元素为nullbreak;}}while(!queue.isEmpty()){TreeNode tmp = queue.poll();if(tmp != null){return false;}}return true;}测试代码为:
TestBinaryTree binaryTree = new TestBinaryTree();binaryTree.root = binaryTree.createTree();System.out.println("判断是否为完全二叉树:");System.out.println(binaryTree.isCompleteTree(binaryTree.root));System.out.println();输出结果为: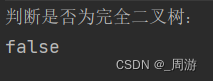
基于原二叉树,删除E结点的右孩子H结点,再次测试结果如下:
2.6 二叉树的非递归方法
2.6.1 非递归实现前序遍历
定义cur结点用于遍历二叉树,从根结点root开始,令cur依次遍历左子树,在结点左孩子不为空的前提下,将结点逐个入栈,每入栈一个结点,就打印一个结点,当遇到左孩子为空的结点后,弹出栈顶元素并令cur为其右孩子;
public void preOrderNor(TreeNode root){if(root == null){return;}TreeNode cur = root;Deque<TreeNode> stack = new ArrayDeque<>();while(cur != null || !stack.isEmpty()) {while (cur != null) {stack.push(cur);System.out.print(cur.val + " ");cur = cur.left;}// 此时为cur为空但栈不为空:// 令cur为栈顶元素的右孩子即可TreeNode top = stack.pop();cur = top.right;}}2.6.2 非递归实现中序遍历
public void inOrderNor(TreeNode root){if(root == null){return;}TreeNode cur = root;Deque<TreeNode> stack = new ArrayDeque<>();while(cur != null || !stack.isEmpty()){while(cur != null){stack.push(cur);cur = cur.left;}TreeNode top = stack.pop();System.out.print(top.val+" ");cur = top.right;}}2.6.3 非递归实现后序遍历
public void postOrderNor(TreeNode root){if(root == null){return;}TreeNode cur = root;TreeNode prev = null;Deque<TreeNode> stack = new ArrayDeque<>();while(cur != null || !stack.isEmpty()){while(cur != null){stack.push(cur);cur = cur.left;}TreeNode top = stack.peek();if(top.right == null || top.right == prev){// 栈顶元素没有右孩子,根据左->右->根,可以直接打印根结点的值System.out.print(top.val+" ");stack.pop();prev = top;}else {// 栈顶元素有右孩子,还需遍历当前栈顶元素结点的右子树cur = top.right;}}}非递归实现前中后序遍历的测试代码如下:
TestBinaryTree binaryTree = new TestBinaryTree();binaryTree.root = binaryTree.createTree();System.out.println("非递归实现前序遍历:");binaryTree.preOrderNor(binaryTree.root);System.out.println();System.out.println("非递归实现中序遍历:");binaryTree.inOrderNor(binaryTree.root);System.out.println();System.out.println("非递归实现后序遍历:");binaryTree.postOrderNor(binaryTree.root);System.out.println();输出结果如下:

相关文章:
【数据结构】_7.二叉树概念与基本操作
目录 1.树形结构 1.1 树的概念 1.2 树的相关概念 1.3 树的表示 1.4 树在实际中的应用—表示文件系统的目录树结构 编辑2.二叉树 2.1 概念 2.2 特殊二叉树 2.3 二叉树的性质 2.4 二叉树的存储结构 2.4.1 顺序存储结构(数组存储结构) 2.4.2…...
Flink之Partitioner(分区规则)
Flink之Partitioner(分区规则) 方法注释global()全部发往1个taskbroadcast()广播(前面的文章讲解过,这里不做阐述)forward()上下游并行度一致时一对一发送,和同一个算子连中算子的OneToOne是一回事shuffle()随机分配(只是随机,同Spark的shuffle不同)rebalance()轮询分配,默认机…...
tk切换到mac的code分享
文章目录 前言一、基础环境配置二、开发软件与扩展1.用到的开发软件与平替、扩展情况 总结 前言 最近换上了coding人生的第一台mac,以前一直偏好tk,近来身边的朋友越来越多的用mac了,win的自动更新越来越占磁盘了,而且win11抛弃了…...
spark的standalone 分布式搭建
一、环境准备 集群环境hadoop11,hadoop12 ,hadoop13 安装 zookeeper 和 HDFS 1、启动zookeeper -- 启动zookeeper(11,12,13都需要启动) xcall.sh zkServer.sh start -- 或者 zk.sh start -- xcall.sh 和zk.sh都是自己写的脚本-- 查看进程 jps -- 有…...
浅析基于视频汇聚与AI智能分析的新零售方案设计
一、行业背景 近年来,随着新零售概念的提出,国内外各大企业纷纷布局智慧零售领域。从无人便利店、智能售货机,到线上线下融合的电商平台,再到通过大数据分析实现精准推送的个性化营销,智慧零售的触角已经深入各个零售…...
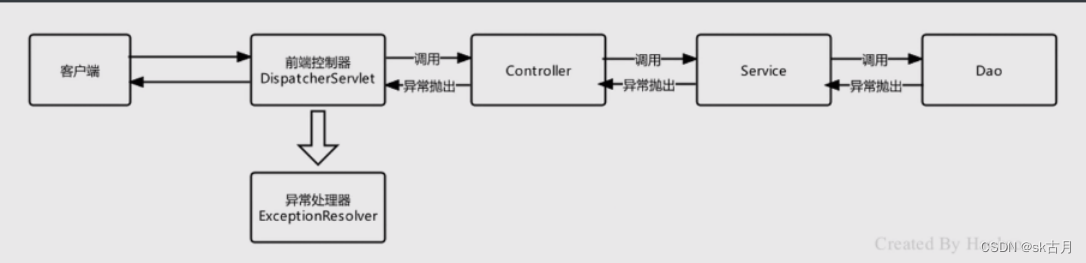
SpringMVC之异常处理
SpringMVC之异常处理 异常分为编译时异常和运行时异常,编译时异常我们trycatch捕获,捕获后自行处理,而运行时异常是不可预期的,就需要规范编码来避免,在SpringMVC中,不管是编译异常还是运行时异常ÿ…...

保险龙头科技进化论:太保的六年
如果从2013年中国首家互联网保险公司——众安在线的成立算起,保险科技在我国的发展已走进第十个年头。十年以来,在政策指引、技术发展和金融机构数字化转型的大背景下,科技赋能保险业高质量发展转型已成为行业共识。 大数据、云计算、人工智…...

升级STM32电机PID速度闭环编程:从F1到F4的移植技巧与实例解析
引言: 在嵌入式系统开发中,STM32系列微控制器广泛应用于各种应用领域。而对于直流有刷电机的控制,PID速度闭环是一种常用的控制方式。本文将以此为例,探讨如何从STM32F1系列移植到STM32F4系列,并详细介绍HAL库在不同型…...

GaussDB 实验篇+openGauss的4种1级分区案例
✔ 范围分区/range分区 -- 创建表 drop table if exists zzt.par_range; create table if not exists zzt.par_range (empno integer,ename char(10),job char(9),mgr integer(4),hiredate date,sal numeric(7,2),comm numeric(7,2),deptno integer,constraint pk_par_emp pri…...
Ruby软件外包开发语言特点
Ruby 是一种动态、开放源代码的编程语言,它注重简洁性和开发人员的幸福感。在许多方面都具有优点,但由于其动态类型和解释执行的特性,它可能不适合某些对性能和类型安全性要求较高的场景。下面和大家分享 Ruby 语言的一些主要特点以及适用的场…...
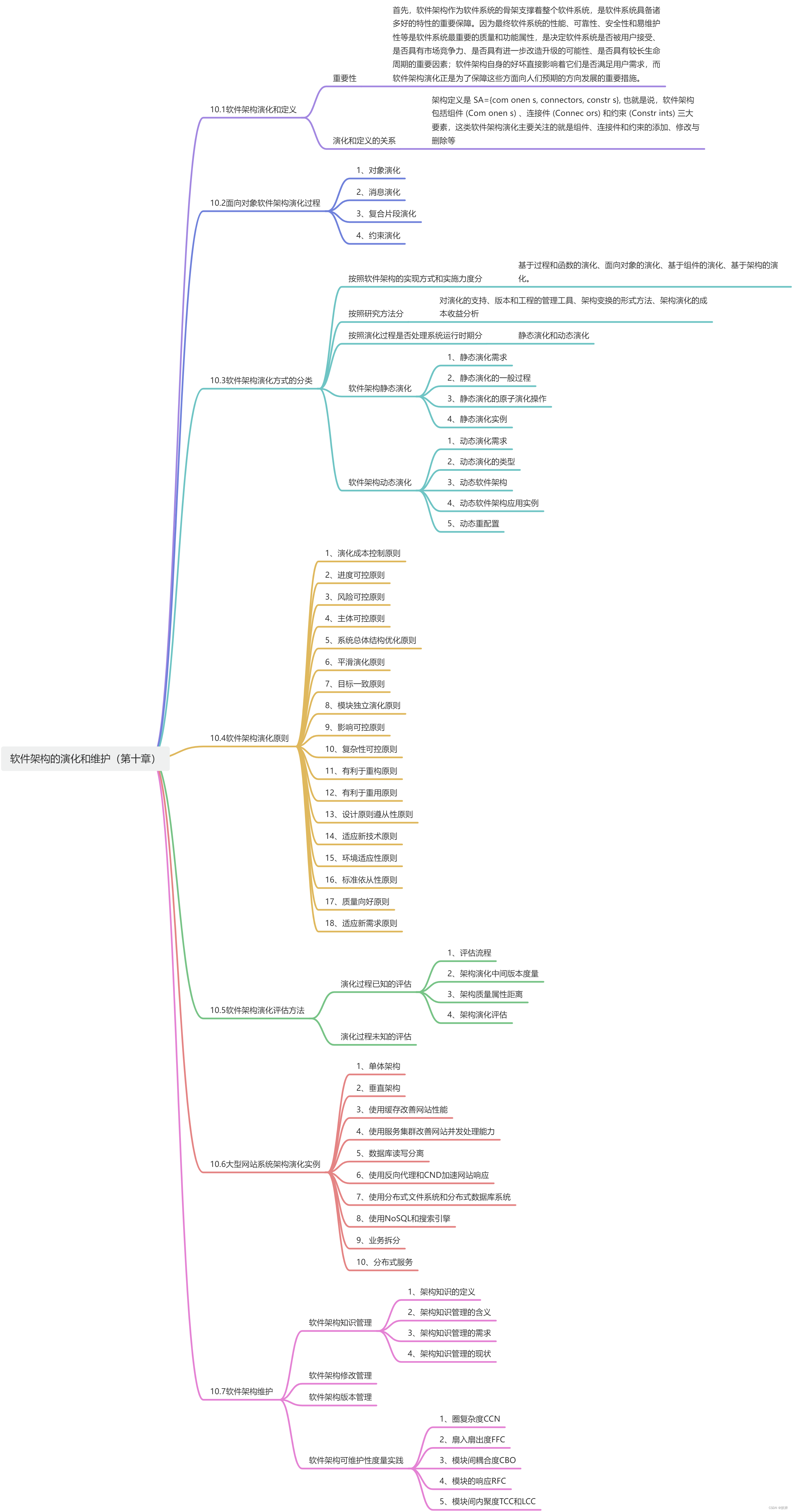
《系统架构设计师教程》重点章节思维导图
内容来自《系统架构设计师教程》,筛选系统架构设计师考试中分值重点分布的章节,根据章节的内容整理出相关思维导图。 重点章节 第2章:计算机系统知识第5章:软件工程基础知识第7章:系统架构设计基础知识第8章࿱…...

mac录屏工具,录屏没有声音的解决办法
mac录屏工具,录屏没有声音的解决办法 在使用macbook录制屏幕时,发现自带的录屏工具QuickTime Player没有声音,于是尝试了多款录屏工具,对其做一些经验总结(省流:APP Store直接可以免费下载使用Omi录屏专家…...

神经网络基础-神经网络补充概念-33-偏差与方差
概念 偏差(Bias): 偏差是模型预测值与实际值之间的差距,它反映了模型对训练数据的拟合能力。高偏差意味着模型无法很好地拟合训练数据,通常会导致欠拟合。欠拟合是指模型过于简单,不能捕捉数据中的复杂模式…...
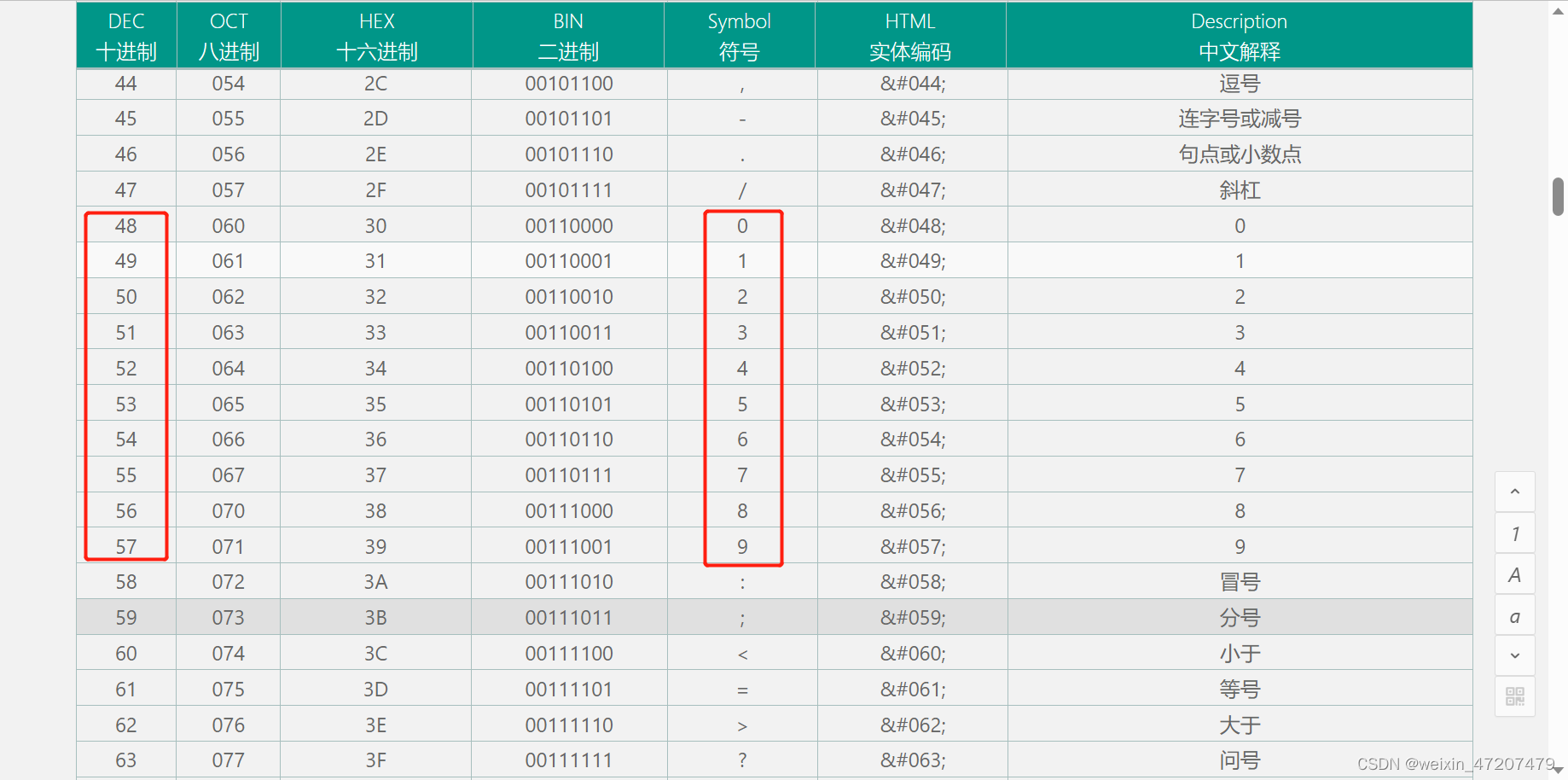
单片机第一季:零基础13——AD和DA转换
1,AD转换基本概念 51 单片机系统内部运算时用的全部是数字量,即0 和1,因此对单片机系统而言,无法直接操作模拟量,必须将模拟量转换成数字量。所谓数字量,就是用一系列0 和1 组成的二进制代码表示某个信号大…...

小区外卖跑腿,解决最后100米配送难题
小区外卖跑腿,解决最后100米配送难题 小区外卖跑腿作为新市场环境下的创业模式,通过选择小区里的闲散人员作为骑手,解决了最后100米配送的问题。这项业务不仅包括小区业主的取快递、寄快递等日常需求,还能提供小区帮忙、小区外卖…...
ZooKeeper的应用场景(命名服务、分布式协调通知)
3 命名服务 命名服务(NameService)也是分布式系统中比较常见的一类场景,在《Java网络高级编程》一书中提到,命名服务是分布式系统最基本的公共服务之一。在分布式系统中,被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象等一这…...
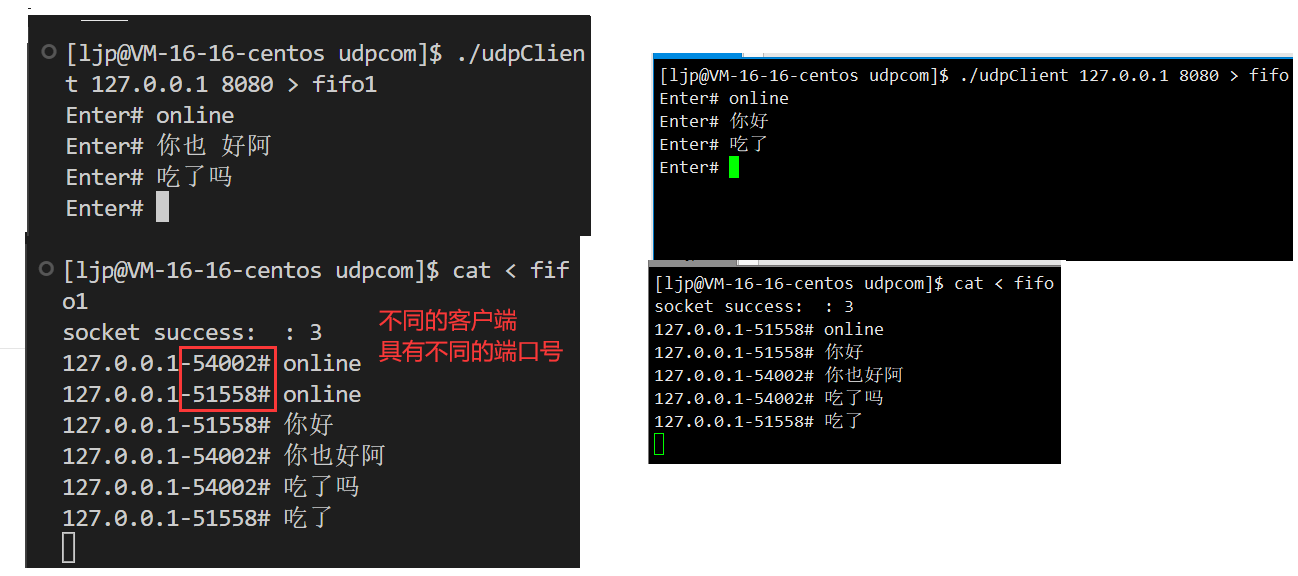
网络套接字
网络套接字 文章目录 网络套接字认识端口号初识TCP协议初识UDP协议网络字节序 socket编程接口socket创建socket文件描述符bind绑定端口号sockaddr结构体netstat -nuap:查看服务器网络信息 代码编译运行展示 实现简单UDP服务器开发 认识端口号 端口号(port)是传输层协…...

对话 4EVERLAND:Web3 是云计算的新基建吗?
在传统云计算的发展过程中,数据存储与计算的中心化问题,对用户来说一直存在着潜在的安全与隐私风险——例如单点故障可能会导致网络瘫痪和数据泄露等危险。同时,随着越来越多 Web3 项目应用的落地,对于数据云计算的性能要求也越来…...
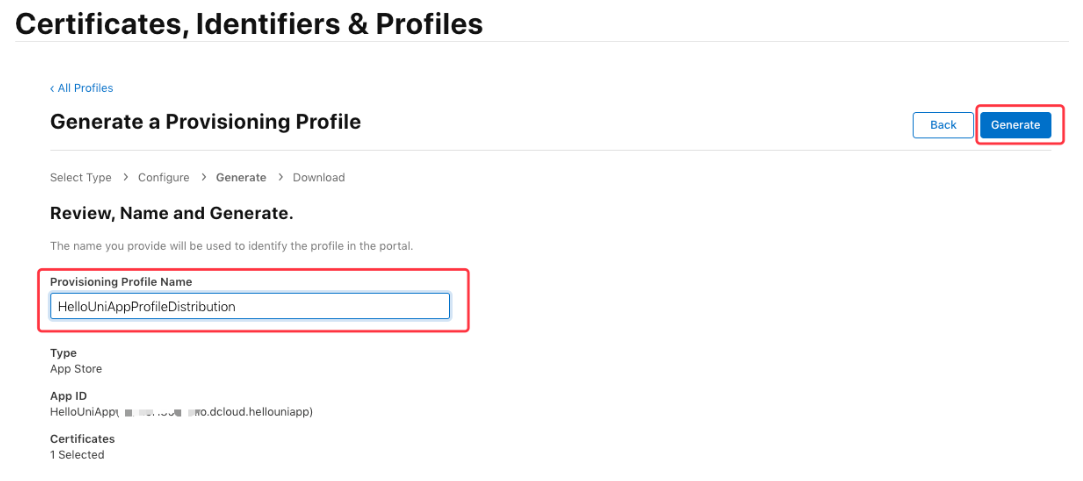
iOS申请证书(.p12)和描述文件(.mobileprovision)
打包app时,经常会用到ios证书,但很多人都苦于没有苹果电脑,即使有苹果电脑的,也会觉得苹果电脑操作也很麻烦,这里记录一下,用香蕉云编,申请证书及描述文件的过程。 香蕉云编的地址:…...

Java:PO、VO、BO、DO、DAO、DTO、POJO
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! Java:PO、VO、BO、DO、DAO、DTO、POJO PO持久化对象(Persistent Object) PO是持久化对象,用于表示数据库中的实体或表…...

别再死记硬背了!用这5个真实案例,彻底搞懂NumPy的einsum函数
别再死记硬背了!用这5个真实案例,彻底搞懂NumPy的einsum函数 当你第一次看到np.einsum(ij,jk->ik, A, B)这样的表达式时,是不是感觉像在破译外星密码?作为NumPy中最强大却也最令人困惑的函数之一,einsum(…...

Jable视频下载神器:3分钟掌握Chrome插件+本地下载器完美方案
Jable视频下载神器:3分钟掌握Chrome插件本地下载器完美方案 【免费下载链接】jable-download 方便下载jable的小工具 项目地址: https://gitcode.com/gh_mirrors/ja/jable-download 还在为无法保存Jable.tv上的精彩视频而烦恼吗?想要轻松将喜欢的…...

UNet迁移实战:如何用Labelme标注自己的数据,并快速替换官方数据集进行训练
UNet迁移实战:从Labelme标注到自定义数据集训练全流程指南 当你在GitHub上成功运行了UNet的官方Demo后,下一步自然是想让这个强大的语义分割模型为你自己的项目服务——无论是分析医学影像中的病变区域,还是识别卫星图片中的特定地物。本文将…...

GEE数据流转实战:如何用Google Drive和Assets搭建你的遥感数据处理流水线
GEE数据流转实战:构建云端遥感数据处理流水线 当遥感数据处理遇上云计算平台,一场关于效率的革命正在悄然发生。Google Earth Engine(GEE)作为全球领先的地理空间分析平台,与Google Drive和Assets的深度整合࿰…...

RT-Thread开发者大会技术解析:从RTOS内核到AIoT平台实战指南
1. 项目概述:一场国产嵌入式技术的年度盛会 2021年的RT-Thread开发者大会,对于当时国内嵌入式软件圈的从业者来说,绝对是一个绕不开的关键节点。那一年,整个行业正处在一个微妙的转折期:一方面,芯片供应链…...

深度学习编译器优化:CNN与MHA块的性能差异与实践指南
1. 深度学习编译器优化概述在深度学习模型部署的实际场景中,我们常常面临一个关键矛盾:训练框架(如PyTorch)的动态图特性虽然灵活,但在推理时会产生显著的性能开销。这正是深度学习编译器技术大显身手的领域——通过静…...

AI赋能泳装设计,今夏爆款如何诞生?
AI赋能泳装设计,今夏爆款如何诞生?随着气温攀升,泳装市场迎来销售旺季。北京先智先行科技有限公司凭借"先知大模型"、“先行AI商学院”、"先知AIGC超级工场"三大旗舰产品,正为泳装行业注入全新活力。传统泳装…...

别再只盯着AB相了!三引脚EC35编码器在智能面板上的应用与防误触设计
三引脚EC35编码器在智能面板设计中的创新应用与抗干扰实践 旋钮交互在智能家居和工业HMI领域从未失去它的魅力——当用户手指触碰到那个精致的金属环时,物理反馈带来的确定感是纯触控界面无法替代的。但传统AB相编码器的误触发问题长期困扰着产品设计师:…...

Multi-Agent 系统故障排查:常见问题与解决方案速查手册
Multi-Agent系统故障排查实战手册:从踩坑到精通的全场景解决方案 关键词 多智能体系统、故障排查、分布式系统、Agent通信故障、共识算法、容错机制、可观测性 摘要 随着大模型技术的爆发,Multi-Agent(多智能体)系统已经成为AI应用、工业互联网、分布式机器人、智能客服…...

企业级AI应用在虚拟机集群的部署,如何借助Taotoken统一API网关
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级AI应用在虚拟机集群的部署,如何借助Taotoken统一API网关 在构建企业内部的AI应用时,一个常见的架构是…...