genism word2vec方法
文章目录
- 概述
- 使用示例
- 模型的保存与使用
- 训练参数详解([原链接](https://blog.csdn.net/weixin_44852067/article/details/130221655))
- 语料库训练
概述
word2vec是按句子来处理的Sentences(句子们)
使用示例
from gensim.models import Word2Vec
#sentences 是二维的向量,这个就是要用的语料库(庞大的语料库文件在第四节说明使用方法)
sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]#进行模型训练
model = Word2Vec(sentences,vector_size = 20, window = 2 , min_count = 1, epochs=7, negative=10,sg=1)
print("cat的词向量:\n",model.wv.get_vector('cat'))
print("\n和“cat”相关性最高的前20个词语:")
print(model.wv.most_similar('cat', topn = 5))# 与孔明最相关的前20个词语
模型的保存与使用
在上一步使用示例之后,对模型进行保存和使用:
# 模型的保存与加载
model.save("word2vec.model")
#这种情况存储下来可以继续训练
model = Word2Vec.load("word2vec.model")
#只存储词向量,是key:vector的形式,无法继续训练.binary表示是否是二进制文件
model.wv.save_word2vec_format("dic_model.model",binary = False)
# 模型继续增加语料进行训练
model.train([["hello", "world"]], total_examples=1, epochs=1)
print("cat的词向量:\n",model.wv.get_vector('cat'))
训练参数详解(原链接)
classgensim.models.word2vec.Word2Vec(sentences=None, corpus_file=None, vector_size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, sample=0.001, seed=1, workers=3, min_alpha=0.0001, sg=0, hs=0, negative=5, ns_exponent=0.75, cbow_mean=1, hashfxn=<built-in function hash>, epochs=5, null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000, compute_loss=False, callbacks=(), comment=None, max_final_vocab=None, shrink_windows=True)
- sentences 可以是一个list,对于大语料集,建议使用BrownCorpus,Text8Corpus或lineSentence构建。
- vector_size word向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好。推荐值为几十到几百。
- alpha 学习率
- window 表示当前词与预测词在一个句子中的最大距离是多少。
- min_count 可以对字典做截断。词频少于min_count次数的单词会被丢弃掉,默认值为5。
- max_vocab_size 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。
- sample 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5) seed 用于随机数发生器。与初始化词向量有关。
- workers 参数控制训练的并行数。 sg 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
- hs 如果为1则会采用hierarchica·softmax技巧。如果设置为0(default),则negative
- sampling会被使用。 negative 如果>0,则会采用negative samping,用于设置多少个noise words。
- cbow_mean 如果为0,则采用上下文词向量的和,如果为1(default)则采用均值。只有使用CBOW的时候才起作用。
- hashfxn hash函数来初始化权重。默认使用python的hash函数。 epochs 迭代次数,默认为5。
- trim_rule 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受()并返回RULE_DISCARD,utils。RULE_KEEP或者utils。RULE_DEFAULT的函数。
- sorted_vocab 如果为1(default),则在分配word index 的时候会先对单词基于频率降序排序。
- batch_words 每一批的传递给线程的单词的数量,默认为10000
- min_alpha 随着训练的进行,学习率线性下降到min_alpha
语料库训练
- 使用自建语料库进行训练时,代码示例如下:
model = Word2Vec(LineSentence(open('corpus.txt', 'r',encoding = 'utf8')),vector_size = 20, window = 2 , min_count = 2, epochs=7, negative=10,sg=1)
其中,corput.txt是自己制作的预料库,LinSentence 函数在使用之前需要对待处理的文本数据进行分词(使用jieba库,使用可参考链接),并以空格分隔;函数在运行时,按行读取已经以空格分隔的文档。文档格式如图:

- 使用已有语料库可以是:
BrownCorpus和Test8Corpus
相关文章:
genism word2vec方法
文章目录 概述使用示例模型的保存与使用训练参数详解([原链接](https://blog.csdn.net/weixin_44852067/article/details/130221655))语料库训练 概述 word2vec是按句子来处理的Sentences(句子们) 使用示例 from gensim.models import Word2Vec #sent…...
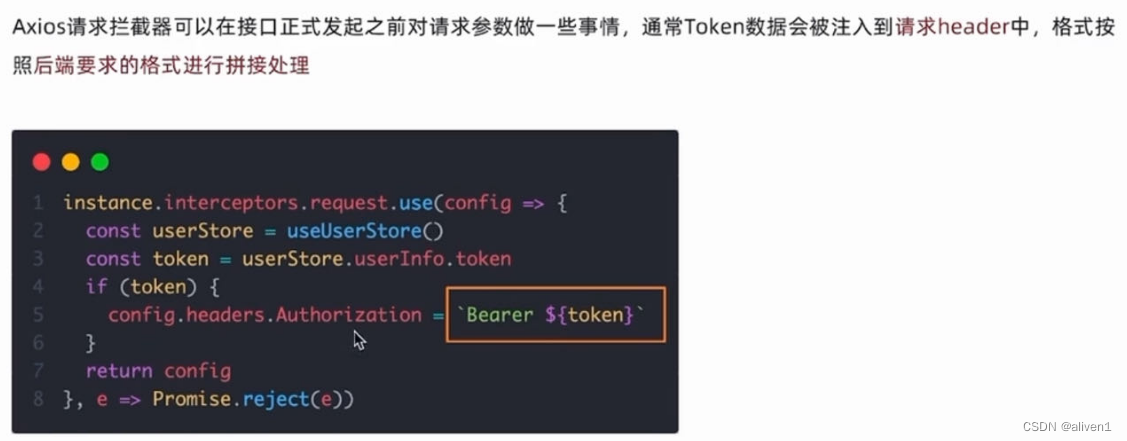
vue3自定义样式-路由-axios拦截器
基于vue,vite和elementPlus 基于elementPlus自定义样式 history模式的路由 在根目录配置jsconfig.json,添加json的配置项。输入自动联想到src目录,是根路径的别名拦截器 如果存在多个接口地址,可以配置多个axios实例 数据持久化之后&#x…...

【mysql】事务的四种特性的理解
🌇个人主页:平凡的小苏 📚学习格言:命运给你一个低的起点,是想看你精彩的翻盘,而不是让你自甘堕落,脚下的路虽然难走,但我还能走,比起向阳而生,我更想尝试逆风…...

C++中List的实现
前言 数据结构中,我们了解到了链表,但是我们使用时需要自己去实现链表才能用,但是C出现了list将这一切皆变为现。list可以看作是一个带头双向循环的链表结构,并且可以在任意的正确范围内进行增删查改数据的容器。list容器一样也是…...
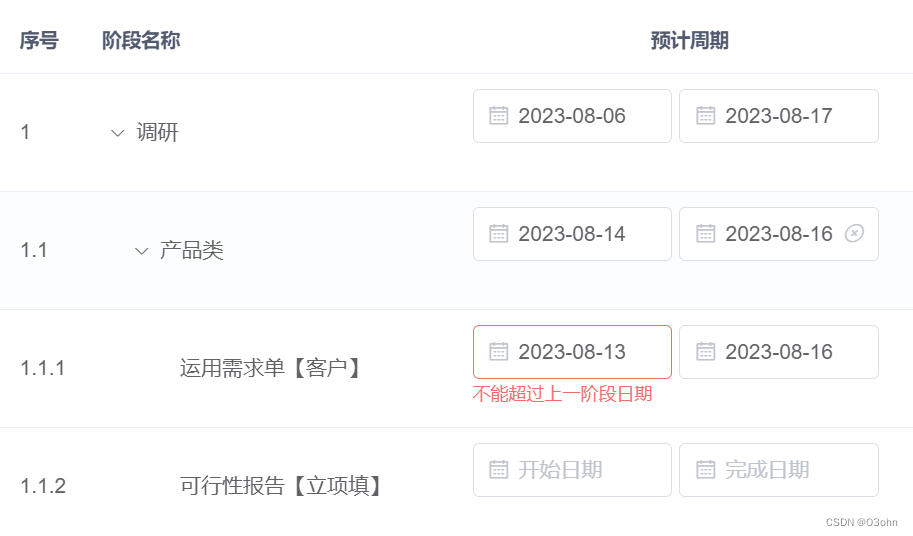
ElementUI 树形表格的使用以及表单嵌套树形表格的校验问题等汇总
目录 一、树形表格如何添加序号体现层级关系 二、树形表格展开收缩图标位置放置,设置指定列 三、表单嵌套树形表格的校验问题以及如何给校验rules传参 普通表格绑定如下:这种方法只能校验表格的第一层,树形需要递归设置子级节点prop。 树…...

解决“Unable to start embedded Tomcat“错误的完整指南
系列文章目录 文章目录 系列文章目录前言一、查看错误信息二、确认端口是否被占用三、检查依赖版本兼容性四、清理临时文件夹五、检查应用程序配置六、检查依赖冲突七、查看异常堆栈信息八、升级或降级Spring Boot版本总结前言 在使用Spring Boot开发应用程序时,有时可能会遇…...
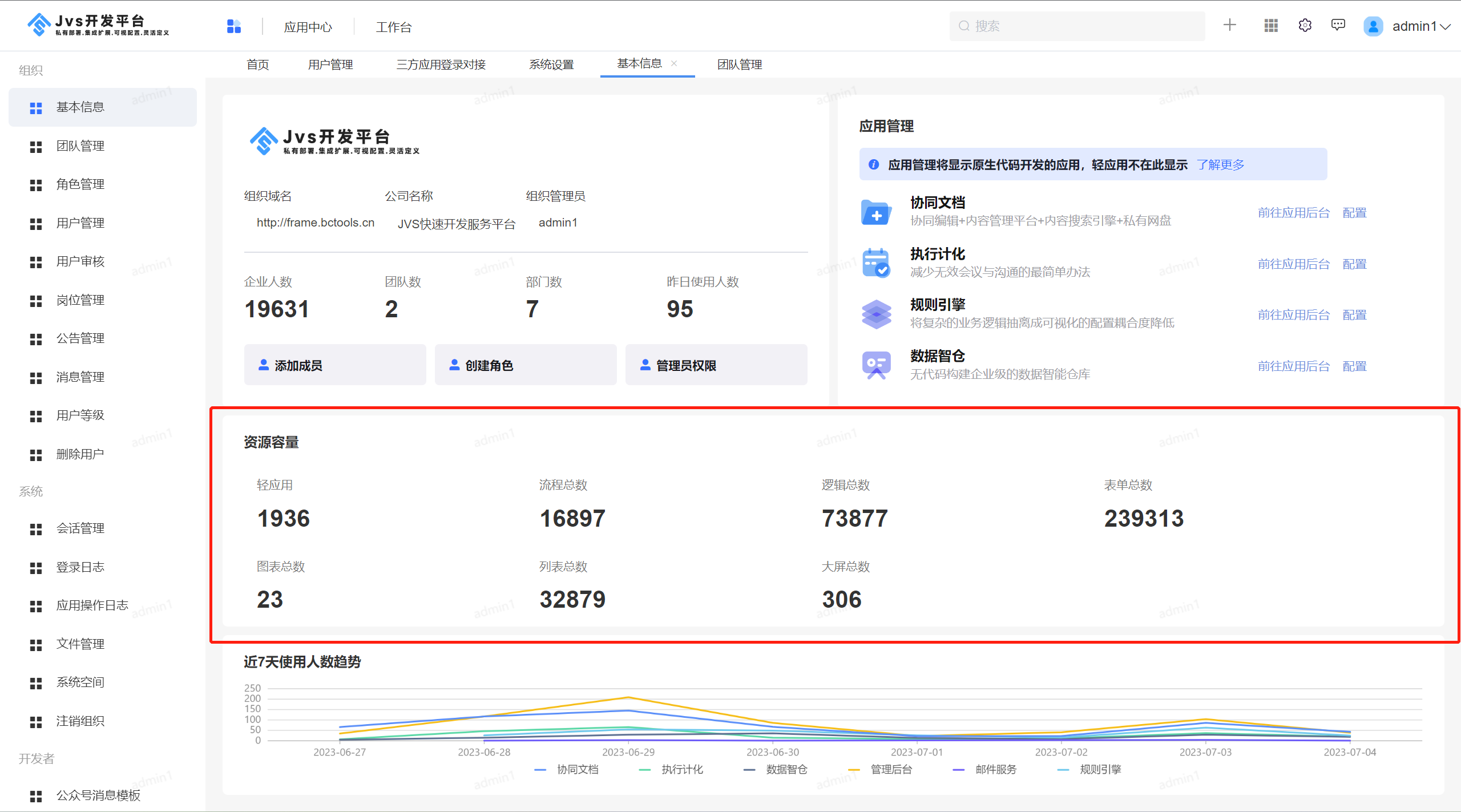
JVS开源基础框架:平台基本信息介绍
JVS是面向软件开发团队可以快速实现应用的基础开发脚手架,主要定位于企业信息化通用底座,采用微服务分布式框架,提供丰富的基础功能,集成众多业务引擎,它灵活性强,界面化配置对开发者友好,底层容…...

C++ - max_element
在C中,要找到一个数组中的最大元素,可以使用 std::max_element 函数。以下是使用步骤: 包含 <algorithm> 头文件,这里定义了 std::max_element 函数。声明一个数组,并初始化它。使用 std::max_element 函数来查找…...

聚隆转债上市价格预测
聚隆转债 基本信息 转债名称:聚隆转债,评级:A,发行规模:2.185亿元。 正股名称:南京聚隆,今日收盘价:16.64元,转股价格:18.27元。 当前转股价值 转债面值 / 转…...
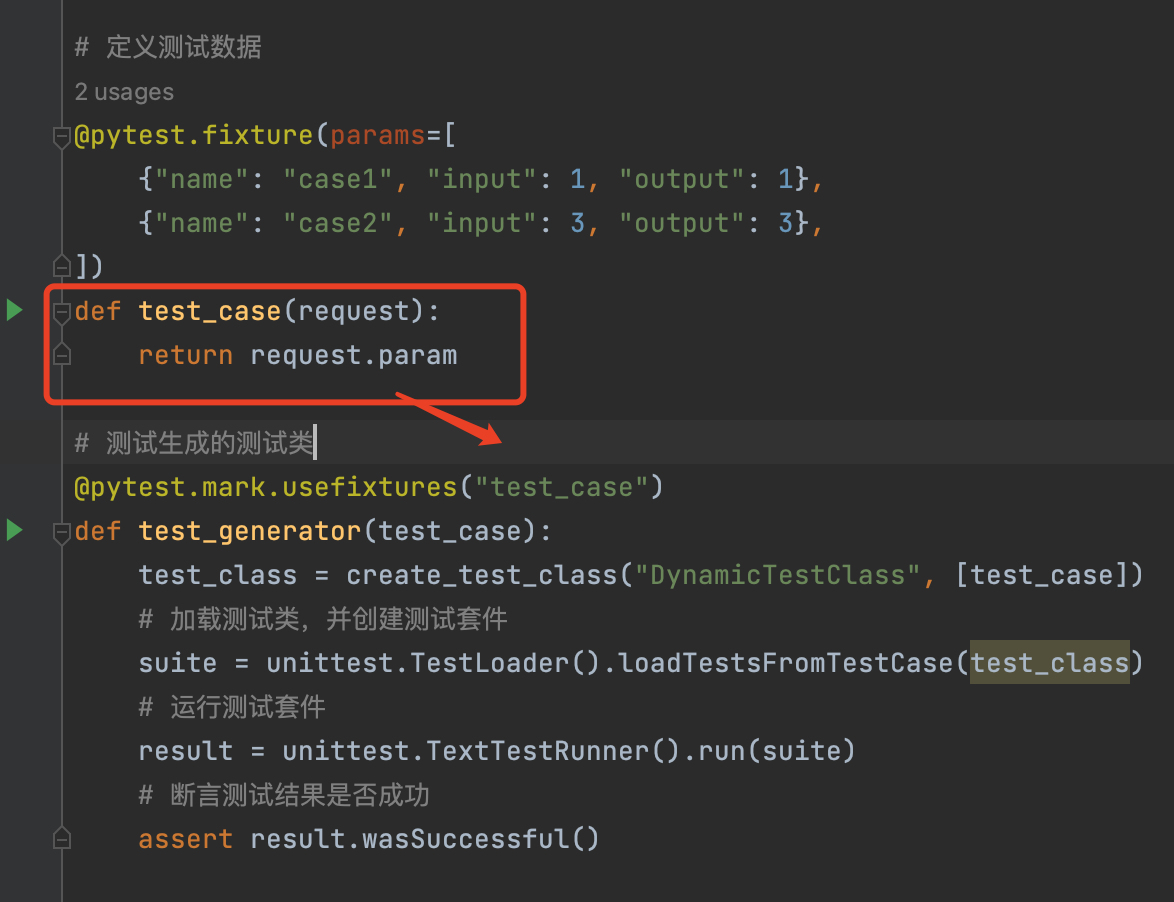
pytest自动生成测试类 demo
一、 pytest自动生成测试类 demo # -*- coding:utf-8 -*- # Author: 喵酱 # time: 2023 - 08 -15 # File: test4.py # desc: import pytest import unittest# 动态生成测试类def create_test_class(class_name:str, test_cases:list) -> type:"""生成测试类…...

服务器卡顿了该如何处理
服务器卡顿了该如何处理 当Windows系统的服务器出现卡顿问题时,以下是一些常见的故障排除步骤: 1.检查网络连接:确保服务器的网络连接正常。检查网络设备、交换机、防火墙等设备,确保它们正常运行。尝试通过其他计算机访问服务器…...

常量对象 只能调用 常成员函数
一、遇到问题: //函数声明 void ReadRanFile(CString szFilePath); const CFvArray<CString>& GetPanelGrade() const { return m_fvArrayPanelGrade; } //在另一个文件中调用ReadtRanFile这个函数 const CFsJudConfig& psJudConfig m_pFsDefJu…...

Progressive-Hint Prompting Improves Reasoning in Large Language Models
本文是LLM系列的文章,针对《Progressive-Hint Prompting Improves Reasoning in Large Language Models》的翻译。 渐进提示改进了大型语言模型中的推理 摘要1 引言2 相关工作3 渐进提示Prompting4 实验5 结论6 实现细节7 不足与未来工作8 广泛的影响9 具有不同提示…...

mysql中INSERT INTO ... ON DUPLICATE KEY UPDATE的用法,以及与REPLACE INTO 语句用法的异同
INSERT INTO ... ON DUPLICATE KEY UPDATE 是 MySQL 中一种用于插入数据并处理重复键冲突的语法。与之相似的还有 REPLACE INTO 语句。以下是它们的用法和异同点的详细说明: 一、INSERT INTO ... ON DUPLICATE KEY UPDATE INSERT INTO ... ON DUPLICATE KEY UPDAT…...
)
wireshark 实用过滤表达式(针对ip、协议、端口、长度和内容)
wireshark 实用过滤表达式(针对ip、协议、端口、长度和内容) 1. 关键字 “与”:“eq” 和 “”等同,可以使用 “and” 表示并且, “或”:“or”表示或者。 “非”:“!" 和 "not”…...
MATLAB图形窗口固定
起因是上次作图的时候写了: clc clear close all 这三个典型的刷新语句 清空工作区、命令行并且关闭图窗 就导致每次我把图窗拉到合适的位置观察,再一次点击运行都会重新刷新在出生点(x) 所以想把图窗固定在某个位置 显然更…...

【数据结构】_7.二叉树概念与基本操作
目录 1.树形结构 1.1 树的概念 1.2 树的相关概念 1.3 树的表示 1.4 树在实际中的应用—表示文件系统的目录树结构 编辑2.二叉树 2.1 概念 2.2 特殊二叉树 2.3 二叉树的性质 2.4 二叉树的存储结构 2.4.1 顺序存储结构(数组存储结构) 2.4.2…...
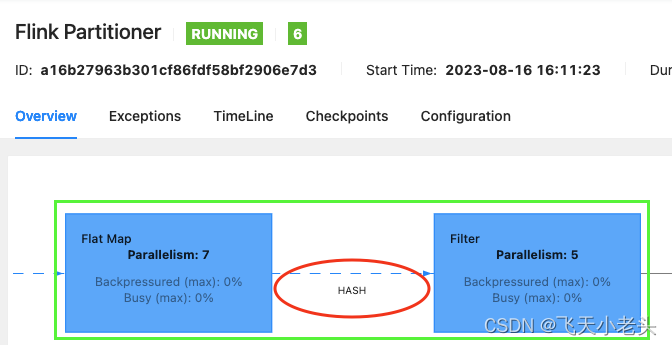
Flink之Partitioner(分区规则)
Flink之Partitioner(分区规则) 方法注释global()全部发往1个taskbroadcast()广播(前面的文章讲解过,这里不做阐述)forward()上下游并行度一致时一对一发送,和同一个算子连中算子的OneToOne是一回事shuffle()随机分配(只是随机,同Spark的shuffle不同)rebalance()轮询分配,默认机…...
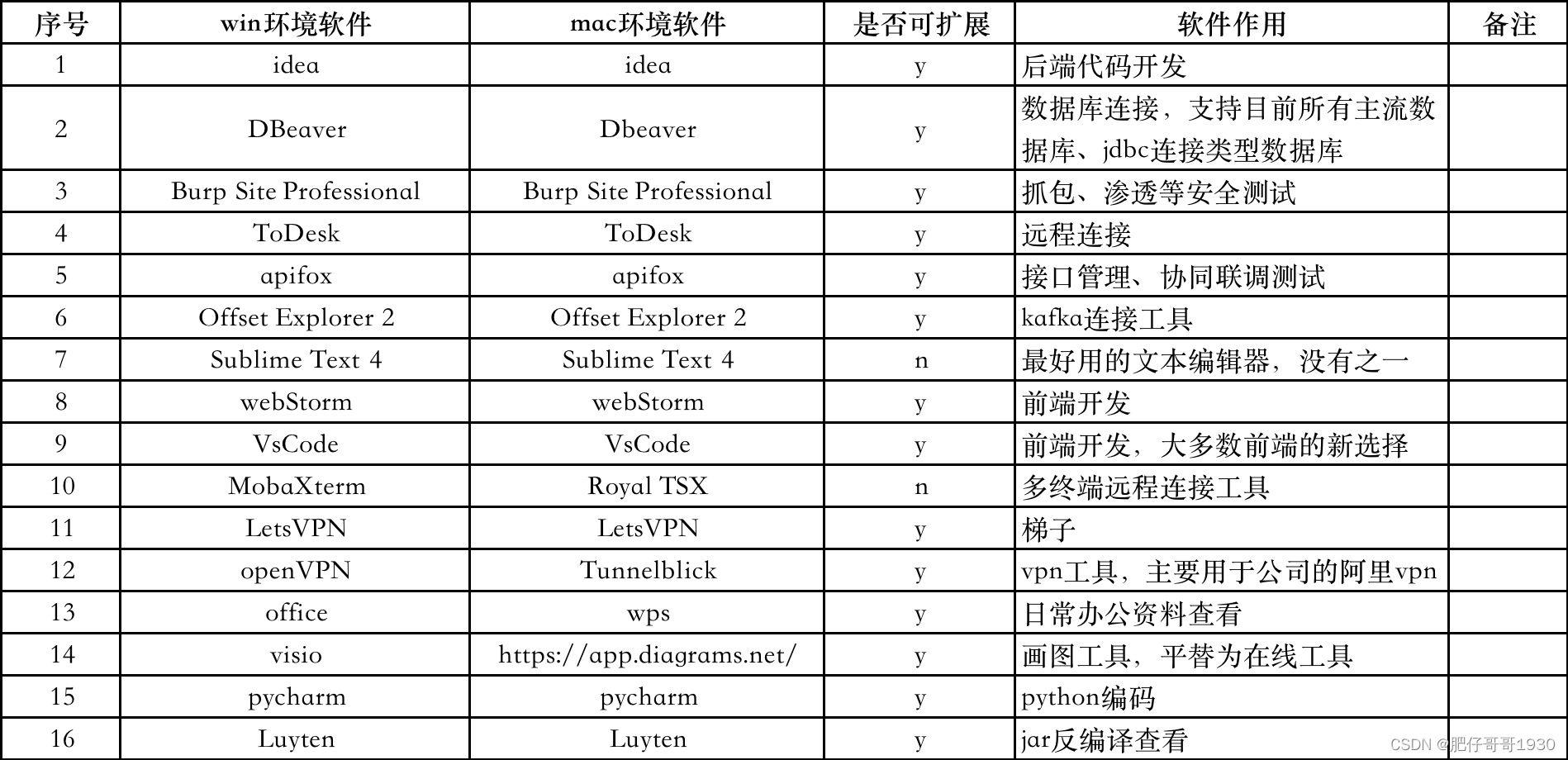
tk切换到mac的code分享
文章目录 前言一、基础环境配置二、开发软件与扩展1.用到的开发软件与平替、扩展情况 总结 前言 最近换上了coding人生的第一台mac,以前一直偏好tk,近来身边的朋友越来越多的用mac了,win的自动更新越来越占磁盘了,而且win11抛弃了…...
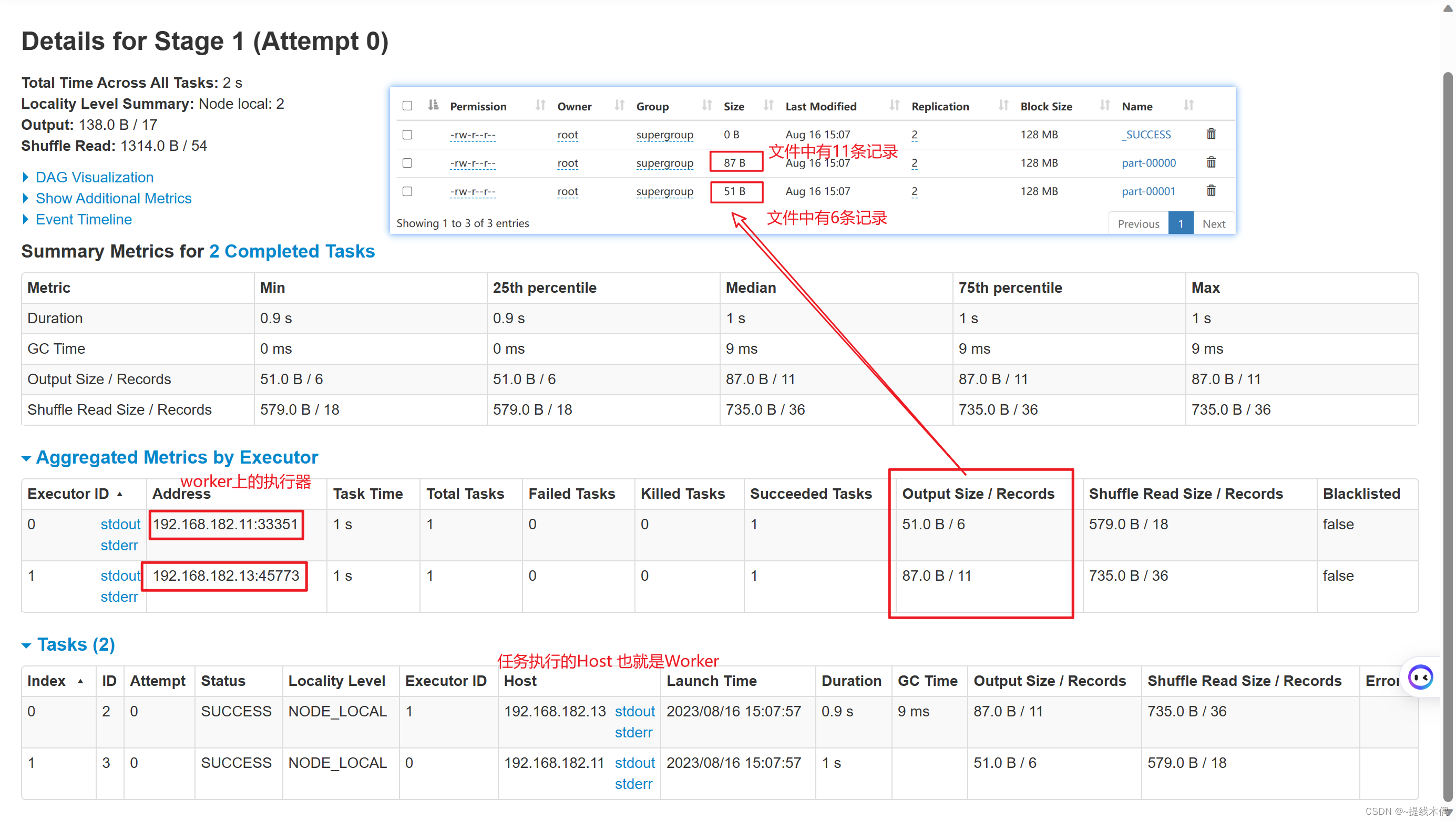
spark的standalone 分布式搭建
一、环境准备 集群环境hadoop11,hadoop12 ,hadoop13 安装 zookeeper 和 HDFS 1、启动zookeeper -- 启动zookeeper(11,12,13都需要启动) xcall.sh zkServer.sh start -- 或者 zk.sh start -- xcall.sh 和zk.sh都是自己写的脚本-- 查看进程 jps -- 有…...
)
别再只写assign了!用三种Verilog建模风格重构你的三人表决器(行为级/数据流/门级)
别再只写assign了!用三种Verilog建模风格重构你的三人表决器 三人表决器是数字电路设计中的经典案例,它能直观展示不同抽象层次的Verilog建模风格如何影响代码质量与硬件实现。很多工程师习惯性地使用assign语句完成所有设计,却忽略了Verilo…...

Excel数据导入实战:为缺失ID列批量生成标准UUID
1. 为什么需要为Excel数据批量生成UUID? 最近在处理一个数据迁移项目时,遇到了一个典型问题:从Navicat导出的Excel表格缺少主键列,导致后续数据导入时频频报错。这种情况在数据迁移、系统对接时特别常见。UUID(通用唯…...

TTK插件系统扩展指南:自定义Golden生成函数和输入数据生成函数的完整教程
TTK插件系统扩展指南:自定义Golden生成函数和输入数据生成函数的完整教程 【免费下载链接】ops-test-kit TTK(Ops Test Tool Kit)是CANN算子库提供的全链路、自动化、批量化算子测试框架,帮助开发者快速完成算子批量功能验证、性能…...

CANN ops-fft未来规划:51+接口路线图与社区发展蓝图
CANN ops-fft未来规划:51接口路线图与社区发展蓝图 【免费下载链接】ops-fft ops-fft 是 CANN (Compute Architecture for Neural Networks)算子库中提供 FFT 类计算的基础算子库,采用模块化设计,支持灵活的算子开发和…...

AMD Ryzen嵌入式COM Express模块:工业边缘计算的高性能解决方案
1. 项目概述:当工业计算遇上“锐龙”芯在工业自动化、边缘计算和高端嵌入式领域,COM Express(Computer-On-Module Express)模块一直是构建紧凑、高性能、高可靠性系统的基石。它就像一台浓缩的、标准化的“电脑主板核心”…...

工业控制新方案:电容HMI与字符LCD组合应用实战
1. 项目概述:当经典LCD遇上电容触控,工业控制的新解法最近在做一个产线设备升级的项目,客户对操作界面的要求突然拔高了不少:既要能看清复杂的工艺参数,又要求操作像手机一样流畅,还得扛得住车间里的油污、…...

5分钟搞定虚拟显示器:ParsecVDD终极指南,解锁4K游戏串流新境界
5分钟搞定虚拟显示器:ParsecVDD终极指南,解锁4K游戏串流新境界 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 你是否曾经因为物理显示器限制而无法获得完…...

PotPlayer智能字幕翻译:用百度翻译API打破语言障碍的观影体验
PotPlayer智能字幕翻译:用百度翻译API打破语言障碍的观影体验 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu 你是否曾在观…...

如何在Windows 11上免费安装安卓子系统:3步快速搭建跨平台应用中心
如何在Windows 11上免费安装安卓子系统:3步快速搭建跨平台应用中心 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA 想在Windows电脑上无缝运行手…...

养老护理员网课选哪家好?3大平台网课深度测评!
老龄化加剧下,养老护理员成为刚需职业,不少人想入行考证,但也会面临不扫问题:零基础怕学不懂、上班族缺整块时间、预算有限想性价比、备考缺题库练手…… 市面上网课、题库也很多,有的价格过高,有的内容过时…...