【数据分析入门】Numpy进阶
目录
- 一、数据重塑
- 1.1 透视
- 1.2 透视表
- 1.3 堆栈/反堆栈
- 1.3 融合
- 二、迭代
- 三、高级索引
- 3.1 基础选择
- 3.2 通过isin选择
- 3.3 通过Where选择
- 3.4 通过Query选择
- 3.5 设置/取消索引
- 3.6 重置索引
- 3.6.1 前向填充
- 3.6.2 后向填充
- 3.7 多重索引
- 四、重复数据
- 五、数据分组
- 5.1 聚合
- 5.2 转换
- 六、缺失值
- 七、合并数据
- 7.1 合并-Merge
- 7.2 连接-Join
- 7.3 拼接-Concatenate
- 7.3.1 纵向拼接
- 7.3.2 横向/纵向拼接
- 八、日期
- 九、可视化
pandas 是一个功能强大的 Python 数据分析库,为数据处理和分析提供了高效且灵活的工具。它是在 NumPy 的基础上构建的,为处理结构化数据(如表格数据)和时间序列数据提供了丰富的数据结构和数据操作方法。
pandas 提供了两种主要的数据结构:Series 和 DataFrame。Series 是一维标记型数组,类似于带标签的列表,可以存储不同类型的数据。DataFrame 是二维的表格型数据结构,类似于关系型数据库中的表格,它由多个 Series 组成,每个 Series 都有一个共同的索引。这使得 pandas 在处理和分析数据时非常方便和高效。
使用 pandas,我们就可以轻松地进行数据导入、数据清洗、数据转换、数据筛选和数据分析等操作。它提供了丰富的函数和方法,如索引、切片、聚合、合并、排序、统计和绘图等,使得数据分析变得简单而直观。
一、数据重塑
1.1 透视
假设我们有一个 DataFrame df2,其中包含了 'Date’、‘Type’ 和 ‘Value’ 这三列数据。想要将 ‘Type’ 列的唯一值作为新 DataFrame 的列,‘Date’ 列作为新 DataFrame 的索引,并将 ‘Value’ 列中对应的值填充到新 DataFrame 的相应位置上。
即 将行变为列 ,我们可以这么实现代码:
>>> df3= df2.pivot(index='Date',columns='Type', values='Value')
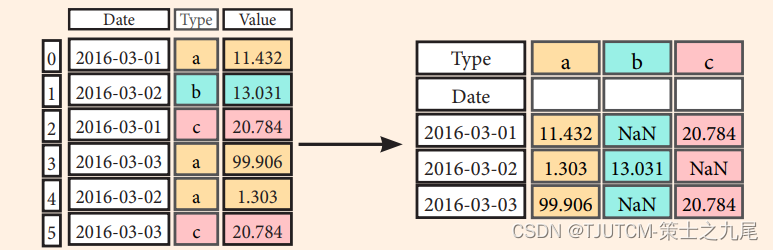
下面来对pivot() 函数的参数做一下说明:
index:指定作为新 DataFrame 索引的列名,这里是 ‘Date’ 列。
columns:指定作为新 DataFrame 列的列名,这里是 ‘Type’ 列的唯一值。
values:指定填充到新 DataFrame 中的值的列名,这里是 ‘Value’ 列。
1.2 透视表
使用了 pd.pivot_table() 函数来 创建一个透视表。pivot_table() 函数可以帮助我们在 pandas 中进行数据透视操作,并实现将一个 DataFrame 中的值按照指定的行和列进行聚合。
即 将行变为列,我们可以这么实现:
>>> df4 = pd.pivot_table(df2,values='Value',index='Date',columns='Type'])
下面来解释一下里面出现的各参数的含义:
其中,‘df2’ 是原始的 DataFrame,‘Value’ 是要聚合的数值列名,‘Date’ 是新 DataFrame 的索引列名,而 ‘Type’ 是新 DataFrame 的列名。
pd.pivot_table() 函数会将 df2 中的数据按照 ‘Date’ 和 ‘Type’ 进行分组,并计算每个组中 ‘Value’ 列的聚合值(默认为均值)。然后,将聚合后的结果填充到新的 DataFrame df4 中,其中 每一行表示一个日期,每一列表示一个类型 。
如果在透视表操作中存在重复的索引/列组合,pivot_table() 函数将会使用默认的聚合方法(均值)进行合并。如果我们想要使用其他聚合函数,可以通过传递 aggfunc 参数来进行设置,例如 aggfunc=‘sum’ 表示求和。
1.3 堆栈/反堆栈
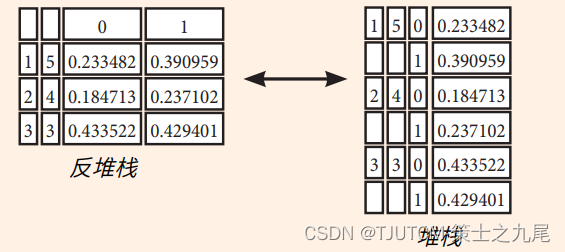
stack() 和 unstack() 是 pandas 中用于处理层次化索引的函数,可以在 多级索引的 DataFrame 中透视行和列标签。
>>> stacked = df5.stack()
# 透视列标签
# 使用 stack() 函数将列标签透视,即将列标签转换为行索引,并将相应的数据堆叠起来。这样可以创建一个具有多级索引的 Series
>>> stacked.unstack()
# 透视索引标签
# 上述代码则使用 unstack() 函数将索引标签透视,即将行索引转换为列标签,并将相应的数据重新排列。这样可以还原出原始的 DataFrame 结构
1.3 融合
我们需要 将指定的列转换为一个观察值列时,可以使用 pd.melt() 函数来将一个 DataFrame 进行融合操作(melt)。
将列转为行:
>>> pd.melt(df2,id_vars=["Date"],value_vars=["Type","Value"],value_name="Observations")

其中,df2 是原始的 DataFrame,id_vars=[“Date”] 表示保持 ‘Date’ 列不融合,作为 标识变量(也就是保持不动的列)。value_vars=[“Type”, “Value”] 指定要融合的列为 ‘Type’ 和 ‘Value’。value_name=“Observations” 表示新生成的观察值列的名称为 ‘Observations’。
pd.melt() 函数会将指定的列进行融合操作,并创建一个新的 DataFrame。融合后的 DataFrame 中会包含四列,分别是融合后的标识变量(‘Date’)、融合的列名(‘variable’)、融合的值(‘Observations’)以及原始 DataFrame 中对应的观察值。
二、迭代
df.iteritems()是一个 DataFrame 的迭代器方法,用于按列迭代 DataFrame。它返回一个生成器,每次迭代生成一个包含列索引和对应列的序列的键值对。
df.iterrows() 也是一个 DataFrame 的迭代器方法,用于按行迭代 DataFrame。它返回一个生成器,每次迭代生成一个包含行索引和对应行的序列的键值对。
>>> df.iteritems()
# (列索引,序列)键值对
>>> df.iterrows()
# (行索引,序列)键值对
下面是一些基本操作:
for column_index, column in df.iteritems():# 对每一列进行操作print(column_index) # 打印列索引print(column) # 打印列的序列for index, row in df.iterrows():# 对每一行进行操作print(index) # 打印行索引print(row) # 打印行的序列
三、高级索引
3.1 基础选择
DataFrame 中基于条件选择列的操作如下,都是一些基本的操作:
>>> df3.loc[:,(df3>1).any()]
# 选择任一值大于1的列
>>> df3.loc[:,(df3>1).all()]
# 选择所有值大于1的列
>>> df3.loc[:,df3.isnull().any()]
# 选择含 NaN值的列
>>> df3.loc[:,df3.notnull().all()]
# 选择含 NaN值的列
3.2 通过isin选择
而在很多情况下,我们所需要做的不是仅仅通过基于条件选择列这么简单的操作,所以还有必要学习 DataFrame 的进一步选择和筛选操作。
>>> df[(df.Country.isin(df2.Type))]
# 选择为某一类型的数值
>>> df3.filter(items=”a”,”b”])
# 选择特定值
>>> df.select(lambda x: not x%5)
# 选择指定元素
3.3 通过Where选择
where()是Pandas Series对象中的一个方法,也可以用于选择满足条件的子集。
>>> s.where(s > 0)
# 选择子集
3.4 通过Query选择
>>> df6.query('second > first')
# 查询DataFrame
df6.query(‘second > first’) 是 DataFrame 对象中的一个查询操作,查询 DataFrame df6 中满足条件 “second > first” 的行。其中,“second” 和 “first” 是列名,表示要比较的两个列。只有满足条件的行会被选中并返回为一个新的 DataFrame。
3.5 设置/取消索引
>>> df.set_index('Country')
# 设置索引
>>> df4 = df.reset_index()
# 取消索引
>>> df = df.rename(index=str,columns={"Country":"cntry","Capital":"cptl","Population":"ppltn"})
# 重命名DataFrame列名
3.6 重置索引
有时候我们需要重新索引 Series。
将 Series s 的索引重新排列为 [‘a’, ‘c’, ‘d’, ‘e’, ‘b’],并返回一个新的 Series。如果 原来的索引中不存在某个新索引值,对应的值将被设置为 NaN(缺失值)。
>>> s2 = s.reindex(['a','c','d','e','b'])
3.6.1 前向填充
>>> df.reindex(range(4), method='ffill')Country Capital Population0 Belgium Brussels 111908461 India New Delhi 13031710352 Brazil Brasília 2078475283 Brazil Brasília 207847528
3.6.2 后向填充
>>> s3 = s.reindex(range(5), method='bfill')0 3 1 32 33 34 3
3.7 多重索引
>>> arrays = [np.array([1,2,3]),
np.array([5,4,3])]
>>> df5 = pd.DataFrame(np.random.rand(3, 2), index=arrays)
>>> tuples = list(zip(*arrays))
>>> index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
>>> df6 = pd.DataFrame(np.random.rand(3, 2), index=index)
>>> df2.set_index(["Date", "Type"])
四、重复数据
>>> s3.unique()
# 返回唯一值
>>> df2.duplicated('Type')
# 查找重复值
>>> df2.drop_duplicates('Type', keep='last')
# 去除重复值
>>> df.index.duplicated()
# 查找重复索引
五、数据分组
5.1 聚合
>>> df2.groupby(by=['Date','Type']).mean()
>>> df4.groupby(level=0).sum()
>>> df4.groupby(level=0).agg({'a':lambda x:sum(x)/len(x),
'b': np.sum})
5.2 转换
>>> customSum = lambda x: (x+x%2)
>>> df4.groupby(level=0).transform(customSum)
六、缺失值
>>> df.dropna()
# 去除缺失值NaN
>>> df3.fillna(df3.mean())
# 用预设值填充缺失值NaN
>>> df2.replace("a", "f")
# 用一个值替换另一个值
七、合并数据

7.1 合并-Merge
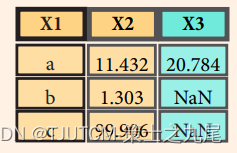
>>> pd.merge(data1, data2, how='left', on='X1')
将 data1 和 data2 两个 DataFrame 按照它们的 ‘X1’ 列进行左连接,并返回一个新的 DataFrame。左连接保留 data1 的所有行,并将 data2 中符合条件的行合并到 data1 中。如果 data2 中没有与 data1 匹配的行,则对应的列值将被设置为 NaN(缺失值)。
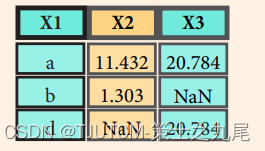
>>> pd.merge(data1, data2, how='right', on='X1')
右连接也是一种连接方式,其将 data1 和 data2 两个 DataFrame 按照它们的 ‘X1’ 列进行右连接,并返回一个新的 DataFrame。保留 data2 的所有行,并将 data1 中符合条件的行合并到 data2 中。如果 data1 中没有与 data2 匹配的行,则对应的列值将被设置为 NaN(缺失值)。

>>> pd.merge(data1, data2,how='inner',on='X1')
将 data1 和 data2 两个 DataFrame 按照它们的 ‘X1’ 列进行内连接,并返回一个新的 DataFrame就是所谓的内连接(inner join)。它 仅保留 data1 和 data2 中在 ‘X1’ 列上有匹配的行,并将它们合并到一起。
参数中的 how=‘inner’ 表示使用内连接方式进行合并。其他可能的取值还有 ‘left’、‘right’ 和 ‘outer’,分别表示左连接、右连接和接下来要介绍的外连接。on=‘X1’ 表示使用 ‘X1’ 列作为合并键(即共同的列)。
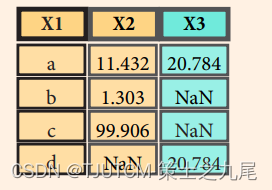
>>> pd.merge(data1, data2, how='outer',on='X1')
将 data1 和 data2 两个 DataFrame 按照它们的 ‘X1’ 列进行外连接,并返回一个新的 DataFrame。外连接(outer join)是一种合并方式,它会保留 data1 和 data2 中所有的行,并将它们根据 ‘X1’ 列的值进行合并。
在外连接中,如果某个 DataFrame 中的行在另一个 DataFrame 中找不到匹配,那么对应的列值将被设置为 NaN(缺失值),表示缺失的数据。
7.2 连接-Join
>>> data1.join(data2, how='right')
7.3 拼接-Concatenate
7.3.1 纵向拼接
>>> s.append(s2)
7.3.2 横向/纵向拼接
>>> pd.concat([s,s2],axis=1, keys=['One','Two'])
>>> pd.concat([data1, data2], axis=1, join='inner')
八、日期
>>> df2['Date']= pd.to_datetime(df2['Date'])
>>> df2['Date']= pd.date_range('2000-1-1', periods=6, freq='M')
>>> dates = [datetime(2012,5,1), datetime(2012,5,2)]
>>> index = pd.DatetimeIndex(dates)
>>> index = pd.date_range(datetime(2012,2,1), end, freq='BM')
九、可视化
Matplotlib 是一个用于绘制数据可视化图形的 Python 库。它提供了各种函数和工具,用于创建各种类型的图表,包括线图、散点图、柱状图、饼图等等。
现在我们导入 Matplotlib 库,并将其重命名为了 plt。这样,我们就可以 使用 plt 对象来调用 Matplotlib 的函数和方法,以便创建和修改图形了。
>>> import matplotlib.pyplot as plt
现在,我们试试导入 Matplotlib 库使用 Pandas 库中 Series 对象的 .plot() 方法 和 Matplotlib 库中的 plt.show() 函数 来生成并显示数据的默认图形。
>>> s.plot()
>>> plt.show()
我们也可使用 Pandas 库中 DataFrame 对象的 .plot() 方法 和 Matplotlib 库 中的 plt.show() 函数 来生成并显示数据的默认图形。
>>> df2.plot()
>>> plt.show()
相关文章:
【数据分析入门】Numpy进阶
目录 一、数据重塑1.1 透视1.2 透视表1.3 堆栈/反堆栈1.3 融合 二、迭代三、高级索引3.1 基础选择3.2 通过isin选择3.3 通过Where选择3.4 通过Query选择3.5 设置/取消索引3.6 重置索引3.6.1 前向填充3.6.2 后向填充 3.7 多重索引 四、重复数据五、数据分组5.1 聚合5.2 转换 六、…...
数据结构的图存储结构
目录 数据结构的图存储结构 图存储结构基本常识 弧头和弧尾 入度和出度 (V1,V2) 和 的区别,v2> 集合 VR 的含义 路径和回路 权和网的含义 图存储结构的分类 什么是连通图,(强)连通图详解 强连通图 什么是生成树,生…...

爬虫IP时效问题:优化爬虫IP使用效果实用技巧
目录 1. 使用稳定的代理IP服务提供商: 2. 定期检测代理IP的可用性: 3. 配置合理的代理IP切换策略: 4. 使用代理IP池: 5. 考虑代理IP的地理位置和速度: 6. 设置合理的请求间隔和并发量: 总结 在爬虫过…...
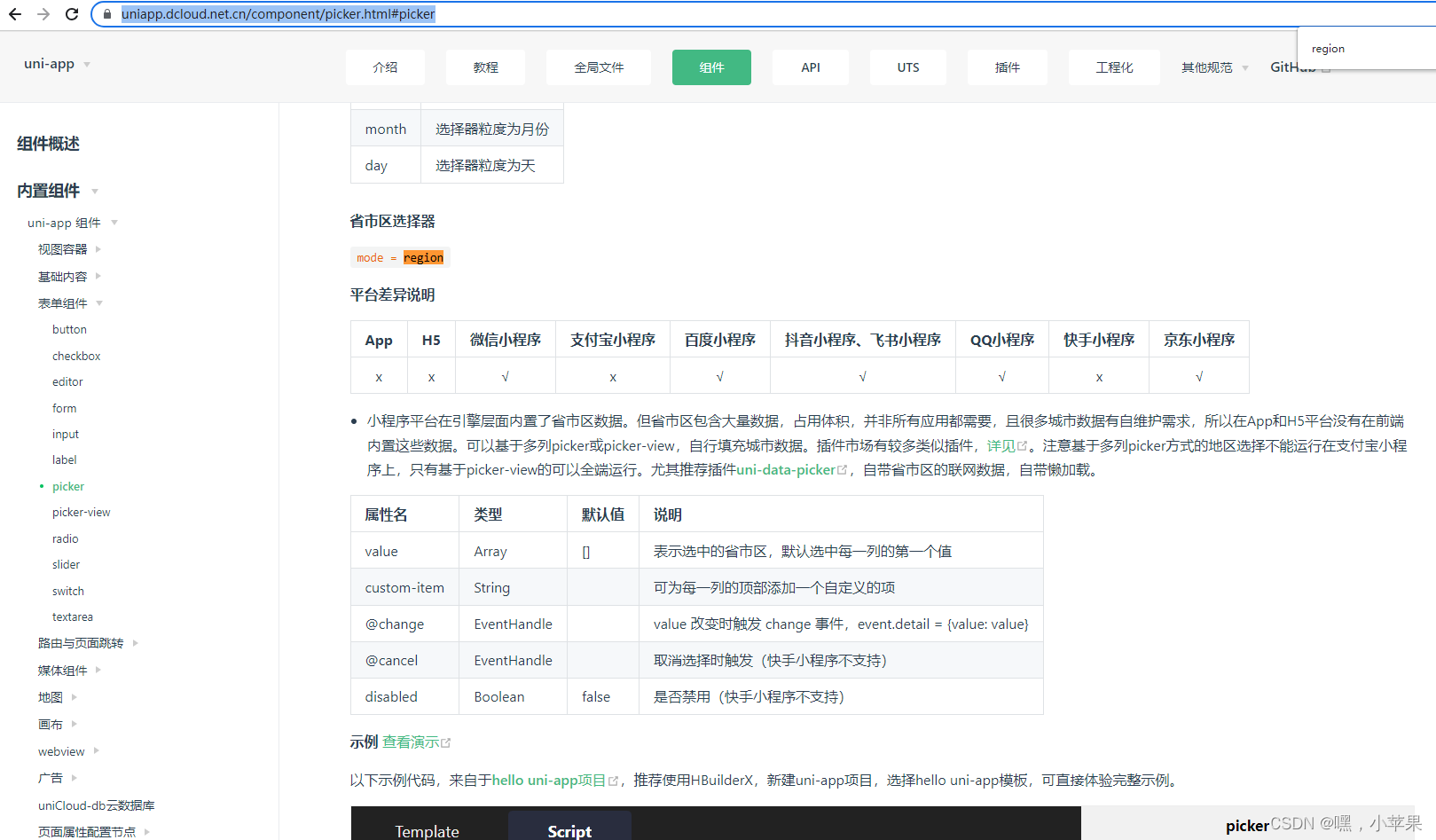
【uniapp】picker mode=“region“ 最简单的省市区 三级联动
省市区 picker template <picker mode"region" :value"date" class"u-w-440" change"bindTimeChange"><u--inputborder"bottom"class"u-fb u-f-s-28"placeholder"请选择省市区"type"te…...
解决Java中的“Unchecked cast: java.lang.Object to java.util.List”问题
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

我的创作纪念日(128天)
机缘 CSDN账号创建已有3年了,本篇是第一篇纪念文。。。有点偷懒的感觉了。。。 从第一篇文章的发布,到现在已经过了128天了,回想起当时发布文章的原因,仅仅只是因为找不到合适的云笔记,鬼使神差的想到了CSDNÿ…...

30W IP网络有源音箱 校园广播音箱
SV-7042XT是深圳锐科达电子有限公司的一款2.0声道壁挂式网络有源音箱,具有10/100M以太网接口,可将网络音源通过自带的功放和喇叭输出播放,可达到功率30W。同时它可以外接一个30W的无源副音箱,用在面积较大的场所。5寸进口全频低音…...

什么是DNS服务器的层次化和分布式?
DNS (Domain Name System) 的结构是层次化的,意味着它是由多个级别的服务器组成,每个级别负责不同的部分。以下是 DNS 结构的层次: 根域服务器(Root Servers): 这是 DNS 层次结构的最高级别。全球有13组根域…...

Django图书商城系统实战开发-部署上线操作
Django图书商城系统实战开发-打包部署 技术背景掌握 当你需要在服务器上部署Web应用程序时,Nginx是一个强大且常用的选择。Nginx是一个高性能的Web服务器和反向代理服务器,它可以处理大量的并发连接,并提供负载均衡、缓存、SSL等功能。下面…...
Springboot 实践(1)MyEclipse2019创建maven工程
项目讲解步骤,基于本机已经正确安装Java 1.8.0及MyEclipse2019的基础之上,Java及MyEclipse的安装,请参考其他相关文档,Springboot 实践文稿不再赘述。项目创建讲解马上开始。 一、首先打开MyEclipse2019,进入工作空间选…...

41 | 京东商家书籍评论数据分析
京东作为中国领先的电子商务平台,积累了大量商品评论数据,这些数据蕴含了丰富的信息。通过文本数据分析,我们可以了解用户对产品的态度、评价的关键词、消费者的需求等,从而有助于商家优化产品和服务,以及消费者作出更明智的购买决策。 本文将详细阐述如何获取京东商家评…...

【数据挖掘】如何保证数据一致性?
一、说明 我曾经在网络分析服务公司担任数据分析师。此类系统可帮助网站收集和分析客户行为数据。 不言而喻,数据是网络分析服务最宝贵的价值。我的主要目标之一是监控数据质量。 为了确保数据一切正常,我们需要关注两件事: 没有丢失或重复的…...

深度学习AIGC问答
文章目录 **.pt 和 .pth 文件区别**.pkl 和 .pth 区别深度学习中.ckpt .h5 文件的区别深度学习中.ckpt .pth 文件的区别TensorFlow框架和keras框架的区别、和关系 Pytorch模型 .pt, .pth的存加载方式 pytorch解析.pth模型文件 .pt 和 .pth 文件区别 在深度学习中,.…...
)
大数据第二阶段测试(二)
1.接到需求之后的开发流程是什么? 参考答案一 接到需求后的开发流程一般包括需求分析、设计、编码、测试和部署等步骤。首先,对需求进行全面的分析,明确需求的背景、目标和功能。然后,根据需求进行系统设计,包括数据库…...
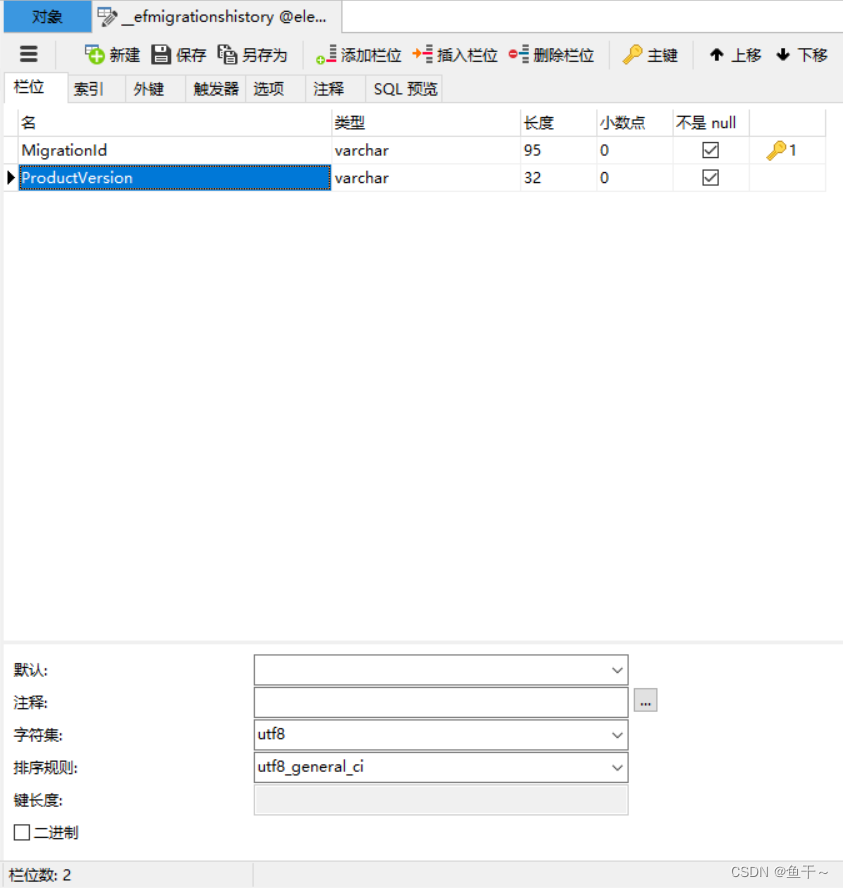
【mysql报错解决】MySql.Data.MySqlClient.MySqlException (0x80004005)或1366
场景:c#使用mysql数据库执行数据库迁移,使用了新增inserter的语句,然后报错 报错如下: 1.MySql.Data.MySqlClient.MySqlException (0x80004005): Incorrect string value: ‘\xE6\x9B\xB4\xE6\x94\xB9…’ for column ‘Migratio…...
Kafka-eagle监控平台
Kafka-Eagle简介 在开发工作中,当业务不复杂时,可以使用Kafka命令来进行一些集群的管理工作。但如果业务变得复杂,例如:需要增加group、topic分区,此时,再使用命令行就感觉很不方便,此时&#x…...

ubuntu16.04制作本地apt源离线安装
一、首先在有外网的服务器安装需要安装的软件,打包deb软件。 cd /var/cache/apt zip -r archives.zip archives sz archives.zip 二、在无外网服务器上传deb包,并配置apt源。 1、上传deb包安装lrzsz、unzip 用ftp软件连接无外网服务器协议选择sftp…...

【Leetcode】91.解码方法
一、题目 1、题目描述 一条包含字母 A-Z 的消息通过以下映射进行了 编码 : A -> "1" B -> "2" ... Z -> "26"要 解码 已编码的消息,所有数字必须基于上述映射的方法,反向映射回字母(可能有多种方法)。例如,"11106" …...

easyx图形库基础:2.基本运动+键盘交互
基本运动键盘交互 一.基本运动1.基本运动:1.如何实现动画:2.实现一个小球从左到右从右到左:(往返运动)3.实现一个五角星的移动:4.实现一个五角星自转和圆周运动的集合:(圆周运动&…...
计算机竞赛 opencv 图像识别 指纹识别 - python
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于机器视觉的指纹识别系统 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分 该项目较为新颖,适…...

TCA白皮书解读:腾讯内部CodeDog系统的演进历程
TCA白皮书解读:腾讯内部CodeDog系统的演进历程 【免费下载链接】CodeAnalysis Static Code Analysis - 静态代码分析 项目地址: https://gitcode.com/gh_mirrors/co/CodeAnalysis 腾讯云代码分析(TCA)作为一款强大的静态代码分析工具&…...

STM32 FSMC/FMC接口详解:地址映射、时序配置与实战优化
1. 项目概述:深入理解STM32的FSMC/FMC接口在嵌入式开发中,尤其是涉及大屏显示、高速数据采集或复杂外部设备交互的项目里,我们常常会遇到一个绕不开的“硬骨头”——如何让STM32单片机高效、稳定地与外部并行存储器或设备通信。这时ÿ…...

Linux主机资产标识实战指南
Linux主机资产标识实战指南本文面向具备一定 Linux 基础的技术人员,围绕主机资产标识展开,重点讨论主机命名、标签规范和资产映射。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起…...

快速开发AI应用原型时Taotoken分钟级接入的价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 快速开发AI应用原型时Taotoken分钟级接入的价值 在黑客松、内部创新日或产品早期原型开发阶段,时间是最宝贵的资源。开…...

基于MCP协议构建AI支付网关:连接Clawd与智能体的实践指南
1. 项目概述:一个连接Clawd与MCP的支付网关 最近在折腾一个很有意思的开源项目,叫 clawdpay-mcp 。这个项目在GitHub上由 Rishab87 维护,乍一看名字有点拗口,但拆解一下就能明白它的核心价值: clawdpay 和 M…...

立创泰山派RK3566开发环境实战:从交叉编译到高效文件传输
1. 立创泰山派RK3566开发环境搭建全攻略 第一次拿到立创泰山派RK3566开发板时,我和大多数嵌入式开发者一样兴奋又忐忑。这款基于Rockchip RK3566处理器的开发板性能强劲,但配套资料相对分散,特别是对于从其他平台(比如我熟悉的IMX…...

桌面整理神器:NoFences让你的Windows桌面焕然一新 [特殊字符]
桌面整理神器:NoFences让你的Windows桌面焕然一新 🚀 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是不是也厌倦了Windows桌面上杂乱无章的图标&a…...

火绒安全软件实战教程:快速查杀、全盘查杀、自定义查杀到底怎么选?
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...
的作用分析)
射频链路中 Coupler(耦合器)的作用分析
射频链路中 Coupler(耦合器)工程解析报告 ——原理、系统作用、工程实现及 Bi‑Directional Coupler 全解 1. Coupler 在射频链路里“到底起什么作用”(工程结论) Coupler 的本质作用只有一句话: 在**“不显著影响主射频链路”的前提下,抽取一小部分、方向可控的射频能量…...

QMCDump终极指南:快速免费解锁QQ音乐加密文件,重获数字音乐自由 [特殊字符]
QMCDump终极指南:快速免费解锁QQ音乐加密文件,重获数字音乐自由 🎵 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.co…...