【论文阅读】 Model Sparsity Can Simplify Machine Unlearning
Model Sparsity Can Simplify Machine Unlearning
- 背景
- 主要内容
- Contribution Ⅰ:对Machine Unlearning的一个全面的理解
- Contribution Ⅱ:说明model sparsity对Machine Unlearning的好处
- Pruning方法的选择
- sparse-aware的unlearning framework
- Experiments
- Model sparsity improves approximate unlearning
- Effectiveness of sparsity-aware unlearning
- Application: MU for Trojan model cleanse.
- Application: MU to improve transfer learning.
背景
Machine Unlearning(MU)是指出于对数据隐私保护的目的以及对"RTBF"(right to be forgotten)等数据保护方案的响应,而提出的一种数据遗忘的方法。在现实中,用户有权请求数据收集者删除其个人数据,但是仅将用户数据从数据集中删除是不够的。 原因:对model的攻击,比如成员推理攻击(membership inference attack,MIA),模型反演攻击等,能够从model反推出训练数据集的信息。 如果model A是用完整的数据集训练的,那么将用户信息从数据集中删除的同时,还需要从model A中抹除用户的数据信息。
对MU分类,可以分为exact unlearning和approximate unlearning。
- 前者即利用删除部分数据后的剩余数据集(Dr)重新训练(Retrain),得到一个新的model,因为这个model的训练并没有用到被删除的数据(Df),自然不包含Df的信息。因此通过Retain得到的model被认为是gold-standard retrained model 。 但是重训练需要很高的计算成本、时间成本,因为在模型较大、数据集较大的情况下,训练一个model是需要耗费很多计算资源,并需要很长时间的。因为仅删除几条用户数据,就直接重新训练一个model是不实际的。
- 因此有了后者,近似MU。近似二字体现出这类MU方法在遗忘的程度和计算成本等上一个trade-off。近似遗忘是指通过其他的方法,比如influence function(也是newton step)去更新模型参数,使得模型不必耗费大量计算资源去重训练,而大致从模型中,抹除Df的信息。
实际上,在近似MU的过程中,比如利用influence function,或者fasher information matrix去更新模型参数的过程中,涉及到对模型参数的hessian matrix求逆的操作(hessian matrix就是二阶偏导),如果模型参数量很大,比如百万个参数,那么这些操作的计算量依旧是很大的。 因此为了降低计算量,在基于influence function的放上上又有很多优化,涉及很多理论的推导。
主要内容
论文链接:Model Sparsity Can Simplify Machine Unlearning
这篇论文的核心内容是,使用model sparsity,缩小approximate MU和exact MU之间的gap。这篇论文的model sparsity就是利用pruning,得到稀疏的模型,再去做MU,即先prune,再unlearn。主要内容如下:
Contribution Ⅰ:对Machine Unlearning的一个全面的理解
本文将approximate MU分为了以下四类:
- Fine-tuning(FT):把原来的model θ.在剩余数据集Dr微调少量的epochs,得到unlearning后的model θu。这个过程是希望能够通过在Dr上微调以启动 catastrophic forgetting(即在增量学习、连续学习的过程中,在另外个任务上微调model参数的时候,model就忘掉了在之前任务上学到的东西),使得模型遗忘掉Df的信息(因为原始数据集是Dr+Df)。
- Gradient ascent (GA):模型训练过程中,模型参数是在往loss减小的方向移动,现在针对Df里面的数据集,将模型参数往在Df上数据点上的loss增大的方向移动。
- Influence unlearning(IU):使用influence function来表示数据点对模型参数w的影响。但是这个方法仅使用删除的数据Df不大的情况。因为influence function中用到了first-order Taylor expansion,如果数据集变化较大的话,这个近似就不准确了。
- Fisher fogetting(FF):这个方法主要是用到了fisher information matrix(FIM)……【这个方法相关的论文我没看懂】……FIM的计算量也是很大的。
这篇论文也提到,MU性能的评估指标有很多方面,再related works中各个approximate MU使用的评估指标不仅相同,也不全面,有些方法在metric A下性能可以,但在metric B下就不太优秀;而某些方法则相反。因此这篇论文希望对MU有一个全面的评估:
- Unlearning accuracy (UA):属于反映unlearning efficacy的指标。UA(θu) = 1 - AccDf(θu)。就是unlearn后的model θu对遗忘数据Df的inference accuracy。AccDf(θu)越小越好,因此UA越大越好。
- Membership inference attack(MIA)on Df:MIA-efficacy是指Df中有多少样本被MIA预测为unlearn后的model θu的non-training samples。MIA-efficacy越大越好。
- Remaining accuracy(RA):unlearn后的model θu在Dr上的inference accuracy。属于fidelity of MU。越大越好。
- Test accuracy(TA):unlearn后的model θu在test dataset(不是Df也不是Dr,是一个新的用于测试的数据集)上的inference accuracy,反应了unlearn后的model θu的generalization。
- Run-time efficiency(RTE):以retrain为baseline,看approximate MU在计算上有多少加速。
Contribution Ⅱ:说明model sparsity对Machine Unlearning的好处
model sparsity,其实就是给model的参数上✖一个mask(m),保留的wi对应mi=1,不保留的wj对应mj=0。这里先给出了基于gradient ascent的MU方法的unlearning error+model sparsity的理论分析(proposition 2):
θt是迭代更新θ过程中的某个结果,θ0是初始的model。因为mask m只有很少的项为1,因此m使得unlearning error减少了。
之后通过实验,在上面的4中approximate MU方法上,验证model sparsity对MU是有好处的,尤其是针对FT,随着sparsity rate的增加,efficacy上(UA、MIA)有很大的提升:
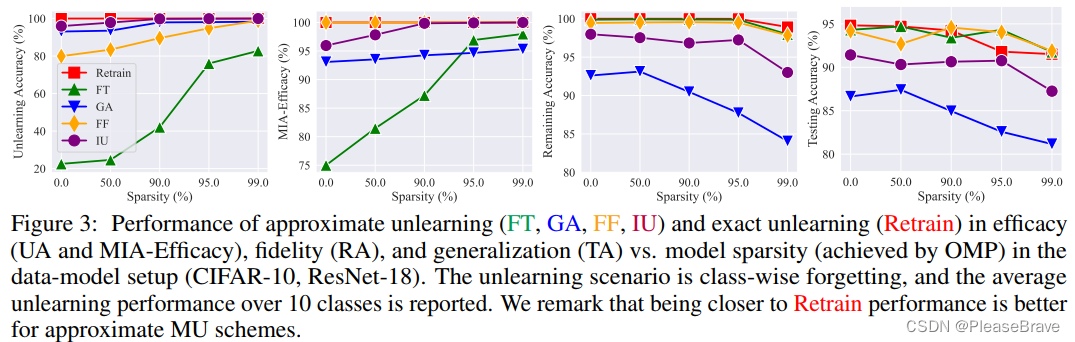
这里的实验是基于one-shot magnitude pruning(OMP)的。
Pruning方法的选择
这篇论文提到的主要方法是:先pruning,再unlearn。那么用什么pruning的方法呢?提到了三个criteria:①least dependence on the forgetting dataset (Df);因为最终是要移除model中包含的Df的信息,如果pruning的过程中过多的依赖Df的信息,那么sparse model中还是有很多Df的信息; ② lossless generalization when pruning;这个是希望pruning尽可能小的影响到TA;③ pruning efficiency,这个是希望尽可能小的影响到RTE,需要高效的pruning方法。 最终列出了三种:SynFlow (synaptic flow pruning),OMP (one-shot magnitude pruning),IMP。最终是用了SynFlow和OMP,因为这两个更优:

OMP和SynFlow在95% sparsity的时候,相对Dense模型,TA有所下降,但是UA提高很多。IMP则是TA有所上升,但是UA下降了。因此最终选择了OMP和SynFlow。因为IMP这个pruning方法对training dataset是强依赖的。
sparse-aware的unlearning framework
前面提到的都是先pruning再unlearn,后面文章提到pruning和unlearning同时进行,在unlearning的目标函数中引入一项L1-norm sparse regularization,最终MU的目标函数如下:
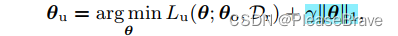
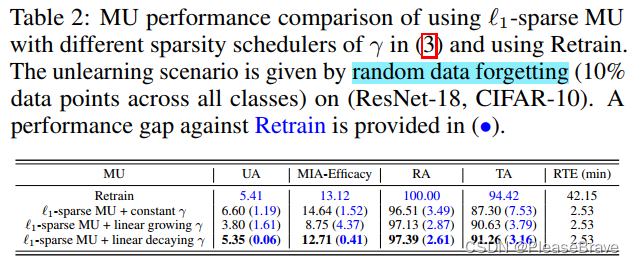
||θ||1越小的话,model也就越稀疏。这里的γ,是这个正则化项的权重,文章给了三种方案极其实验结果,最后说明“use of a linearly decreasing γ scheduler outperforms other schemes.”
Experiments
Model sparsity improves approximate unlearning
两种unlearning scenario:class-wise(Df consisting of training data points of an entire class)的和random datapoints(10% of the whole training dataset together)。
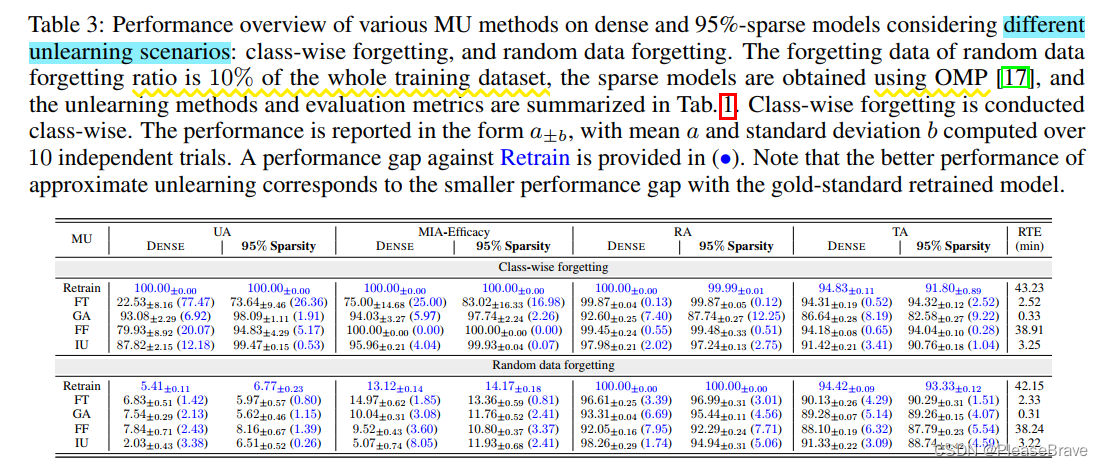
没一纵列,右边的和左边的对比,括号里是与Retain这个gold-standard的对比,数字越小越好。所以文章提出的先pruning能够boost MU performance。
Effectiveness of sparsity-aware unlearning
实验验证文章提出的pruning和unlearning同时进行的sparsity-aware unlearning方法效果:在class-wise forgetting和random data forgetting两个scenario下,与基于Fine-tuning的MU方法和Retain,在五个metric下对比:

蓝线即提出的方法,简直是五边形战士!(但是和FT比有点取巧了吧hhhhFT在dense model上性能本来就不行)。
Application: MU for Trojan model cleanse.
用MU遗忘掉adversarial examples的信息,可以实现后门的移除:
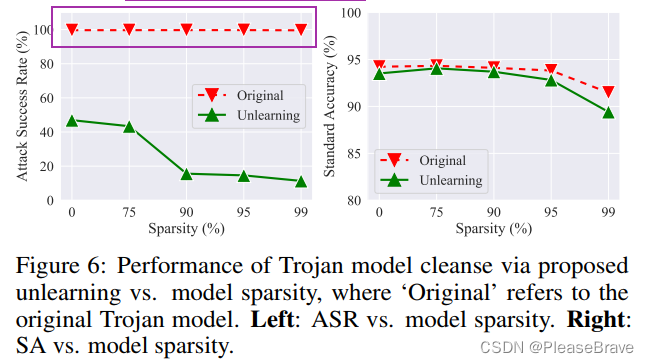
sparsity rate增加,unlearning后的model的ASR明显下降,同时standard accuracy降低不多。
Application: MU to improve transfer learning.
transfer learning是指在一个领域上学习好的较大的model,换一个领域的数据集微调最后分类相关的层就能继续用。但是原始的数据集,可能其中一些类对模型迁移影响是负面的,那么如果把这些类移除后训练的model迁移性更好。那么可以考虑用MU先将一些类的信息从model中移除,再transfer learning:
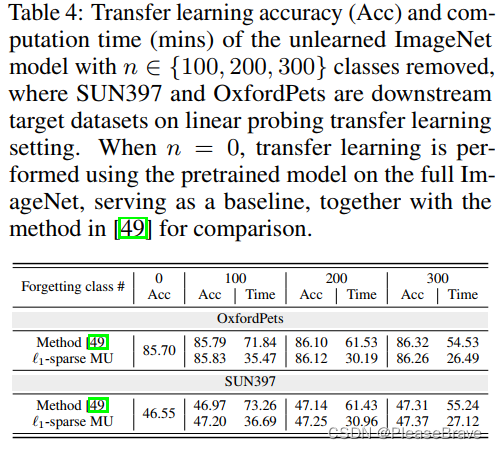
可见本文的方法,与参考方法相比,在两个数据集上的迁移Acc都有所增加,但是Time更少。
相关文章:
【论文阅读】 Model Sparsity Can Simplify Machine Unlearning
Model Sparsity Can Simplify Machine Unlearning 背景主要内容Contribution Ⅰ:对Machine Unlearning的一个全面的理解Contribution Ⅱ:说明model sparsity对Machine Unlearning的好处Pruning方法的选择sparse-aware的unlearning framework Experiments…...
Spring Clould 部署 - Docker
视频地址:微服务(SpringCloudRabbitMQDockerRedis搜索分布式) 初识Docker-什么是Docker(P42,P43) 微服务虽然具备各种各样的优势,但服务的拆分通用给部署带来了很大的麻烦。 分布式系统中&…...

linux--链表动态创建
头插法: 核心代码: s->next head->next; head->next s; 尾插法 核心代码: tail head; s->next NULL; tail->next s; tail s; 当用头插法依次插入值分别为1,2,3,4,5的结点后, 单链表顺序为: he…...

iBooker 布客技术评论 20230818
一、程序员自检手册 为了避免焦虑,你首先需要做的就是梳理你的业务: (1)你所在的行业是轻资产还是重资产? 重资产就是人绕着机器转,创业需要买一大堆设备。如果是重资产,赶紧换一个。 &…...

CK-A60180、CK-B1542、CK-L3095单向离合器
CK-A1542、CK-A1747、CK-A2052、CK-A2652、CK-A3072、CK-A3580、CK-A4090、CK-A45100、CK-A450110、CK-A60130、CK-A65140、CK-A70150、CK-A75160、CK-A80170、CK-A1250、CK-A1855、CK-A2060、CK-A2563、CK-A2563T、CK-A2870、CK-A3080T、CK-A3585、CK-A35100、CK-A35140、CK-A…...
单因素多变量方差分析
多变量方差分析:是对多个独立变量是否受单个或多个因素影响而进行的方差分析。它不仅能够分析多个因素对观测变量的独立影响,更能够分析多个因素的交互作用能否对观测变量产生影响。本章以单因素多变量分析为例,即一个分组变量和多个欲分析的…...

Python Web:Django、Flask和FastAPI框架对比
原文:百度安全验证 Django、Flask和FastAPI是Python Web框架中的三个主要代表。这些框架都有着各自的优点和缺点,适合不同类型和规模的应用程序。 1. Django: Django是一个全功能的Web框架,它提供了很多内置的应用程序和工具&am…...

【CI/CD】Rancher K8s
Rancher & K8s Rancher 和 K8s 的关系是什么?K8s 全称为 Kubernetes,它是一个开源的,用于管理云平台中多个主机上的容器化的应用。而 Rancher 是一个完全开源的企业级多集群 Kubernetes 管理平台,实现了 Kubernetes 集群在混合…...

nodejs 之 express 实现下载网络图片并上传到七牛云对象存储oss空间
为方便阅读,本文将所有逻辑放在一个函数里,可根据自己的情况拆分。 安装依赖 在项目根目录下运行以下命令安装依赖 npm install express qiniu axios业务逻辑 在项目根目录下创建一个名为 app.js 的文件,并添加以下内容 const express re…...

综合能源系统(7)——综合能源综合评估技术
综合能源系统关键技术与典型案例 何泽家,李德智主编 综合能源系统是多种能源系统非线性耦合的、多时间与空间尺度耦合的“源-网-荷一储”一体化系统,通过能源耦合、多能互补,能够实现能源的高效利用,并提高新能源的利用水平。对…...

【JS 线性代数算法之向量与矩阵】
线性代数算法 一、向量的加减乘除1. 向量加法2. 向量减法3. 向量数乘4. 向量点积5. 向量叉积 二、矩阵的加减乘除1. 矩阵加法2. 矩阵减法3. 矩阵数乘4. 矩阵乘法 常用数学库 线性代数是数学的一个分支,用于研究线性方程组及其解的性质、向量空间及其变换的性质等。在…...
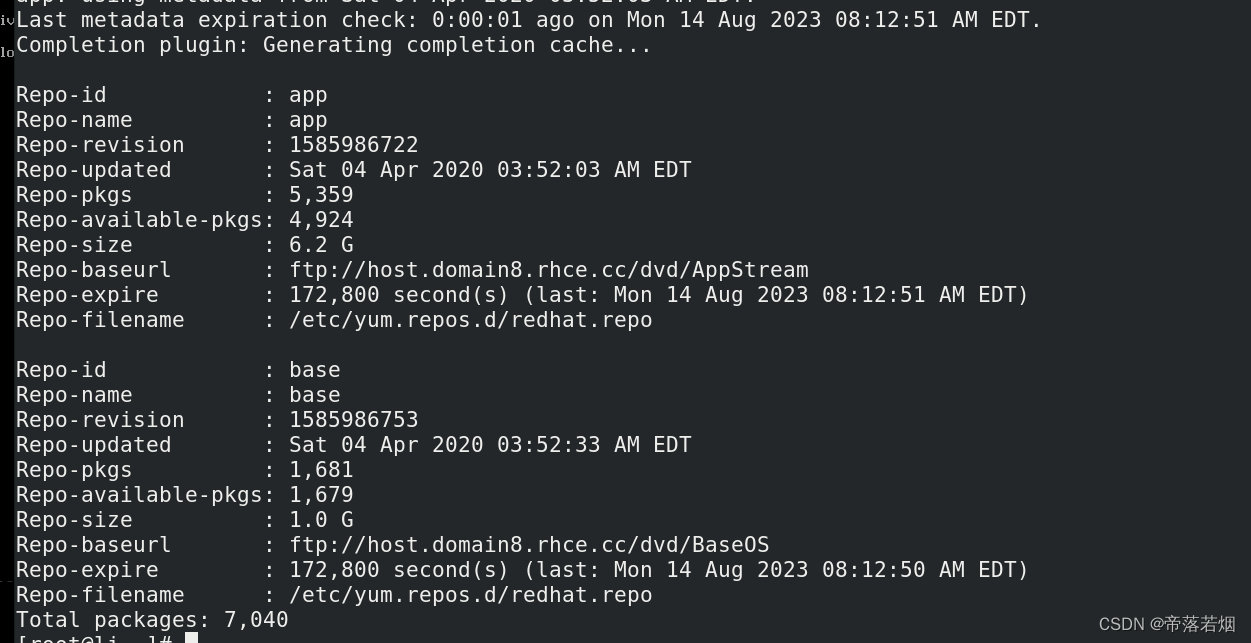
配置 yum/dnf 置您的系统以使用默认存储库
题目 给系统配置默认存储库,要求如下: YUM 的 两 个 存 储 库 的 地 址 分 别 是 : ftp://host.domain8.rhce.cc/dvd/BaseOS ftp://host.domain8.rhce.cc/dvd/AppStream vim /etc/yum.repos.d/redhat.repo [base] namebase baseurlftp:/…...
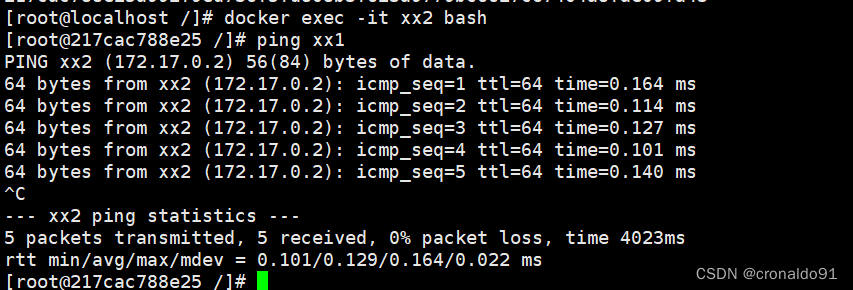
Docker容器与虚拟化技术:Docker资源控制、数据管理
目录 一、理论 1.资源控制 2.Docker数据管理 二、实验 1.Docker资源控制 2.Docker数据管理 三、问题 1.docker容器故障导致大量日志集满,造成磁盘空间满 2、当日志占满之后如何处理 四、总结 一、理论 1.资源控制 (1) CPU 资源控制 cgroups࿰…...
python生成器有几种写法,python生成器函数例子
大家好,小编来为大家解答以下问题,python生成器有几种写法,python生成器函数例子,今天让我们一起来看看吧! 本文部分参考:Python迭代器,生成器–精华中的精华 https://www.cnblogs.com/deeper/p…...

动态动画弹窗样式css
点击下载图片素材 html <div class"popWin"> </div> <div class"popPic"><div class"popWinBtn01">查看证书</div><div class"wintips01">恭喜您已完成训练营学习任务,荣誉证书已发放…...
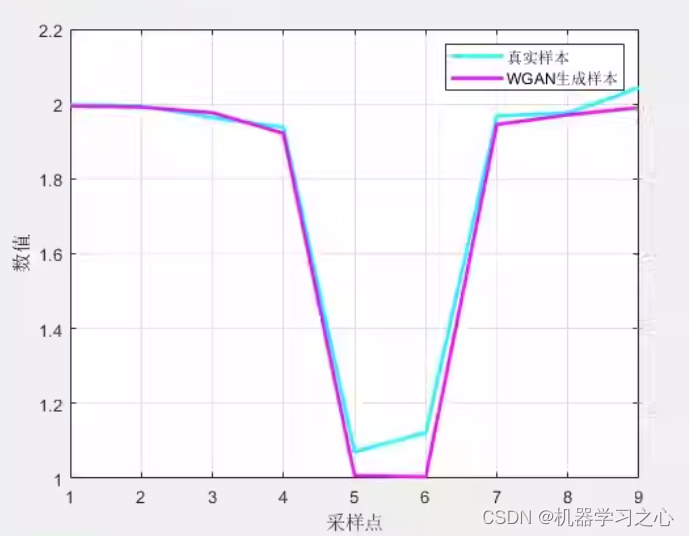
数据生成 | MATLAB实现WGAN生成对抗网络数据生成
数据生成 | MATLAB实现WGAN生成对抗网络数据生成 目录 数据生成 | MATLAB实现WGAN生成对抗网络数据生成生成效果基本描述程序设计参考资料 生成效果 基本描述 1.WGAN生成对抗网络,数据生成,样本生成程序,MATLAB程序; 2.适用于MATL…...
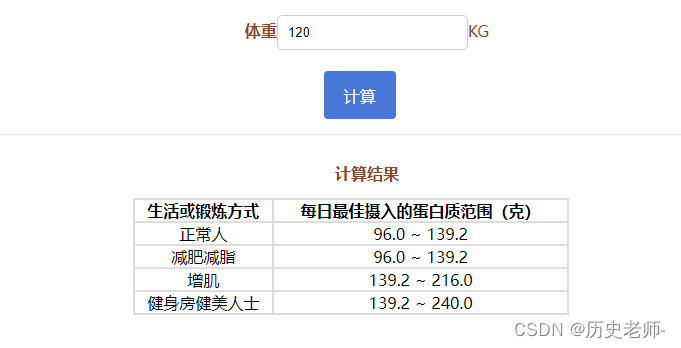
PHP实现每日蛋白质摄入量计算器
1.laravel 路由 //每日蛋白质摄入计算器Route::get(api/protein/intake, FormulaControllerproteinIntakeCal); 2.代码 /*** 每日蛋白质摄入计算器*/public function proteinIntakeCal(){$number intval($this->request(number));$goalFactor array(0.8, 1.16, 0.8, 1.16,…...

vue elment 表格内表单校验代码
<p v-if"scope.row.id">{{ scope.row.bidderCode }}</p><el-form-itemclass"formitem"v-else:prop"bidderCode scope.row.id":rules"getValidationRules(投标人/供应商代码, scope.row.id)"><el-input v-model&…...

如何在Stream流中分组统计
上面是今天碰到需求,之前就做过类似的分组统计,这个相对来说比较简单,统计的也少,序号和总预约人数这两部分交给前端了,不需要由后端统计,后端统计一下预约日期和检查项目和预约人数就行; Overridepublic List<ItemStatisticsVo> statistics(ItemStatisticsModel itemSta…...
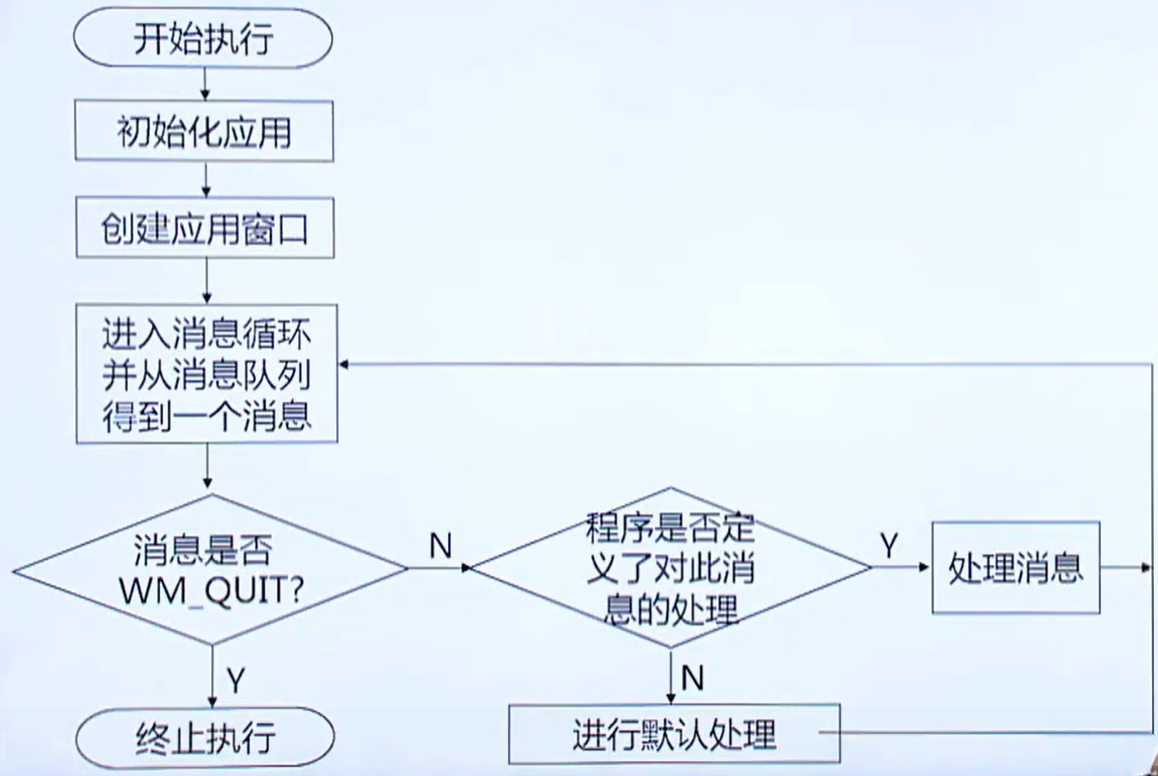
windows程序基础
一、windows程序基础 1. Windows程序的特点 1)用户界面统一、友好 2)支持多任务:允许用户同时运行多个应用程序(窗口) 3)独立于设备的图形操作 使用图形设备接口( GDI, Graphics Device Interface )屏蔽了不同硬件设备的差异&#…...

西门子S7-200 SMART PLC TCP通讯保姆级教程:从指令库配置到双机调试避坑
西门子S7-200 SMART PLC双机TCP通讯实战指南:从零搭建到故障排除 在工业自动化领域,PLC之间的可靠通讯是实现设备联动的关键技术。作为西门子经典的小型自动化解决方案,S7-200 SMART系列PLC凭借其性价比和易用性,在生产线控制、设…...

探索ReoGrid:在.NET应用中构建专业级数据可视化方案的三步法
探索ReoGrid:在.NET应用中构建专业级数据可视化方案的三步法 【免费下载链接】ReoGrid Fast and powerful .NET spreadsheet component, support data format, freeze, outline, formula calculation, chart, script execution and etc. Compatible with Excel 2007…...

光子KANs:电信组件构建的光学神经网络革命
1. 光子KANs:电信组件构建的光学神经网络革命 在AI算力需求爆炸式增长的今天,传统电子计算架构正面临带宽瓶颈和能耗墙的严峻挑战。当我第一次在实验室用示波器测量光学神经网络的响应时间时,23纳秒的延迟让我震惊——这比最好的GPU还要快三个…...

Aider:AI结对编程实战,从原理到项目级代码编辑
1. 项目概述:当AI成为你的结对编程伙伴如果你是一名开发者,大概率经历过这样的场景:面对一个需要修改的复杂函数,你清楚地知道要做什么,但就是不想动手去敲那一行行重复或繁琐的代码;或者,在深夜…...

Tinke:免费解锁NDS游戏资源的终极指南
Tinke:免费解锁NDS游戏资源的终极指南 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 你是否曾经好奇任天堂NDS游戏内部的神秘世界?想要提取游戏中的精美图片、动听音乐或…...

NCE外汇:平台稳定性与用户体验的全面观察
金融服务行业的复杂性决定了平台需要在多个维度上同时具备较高的水准。NCE外汇经过多年的发展,已经在合规、技术、服务、教育等方面形成了一套相互支撑的体系。本文从评测视角出发,对其综合实力进行多维度的解读,呈现一个具有结构感的平台画像…...

如何用本地AI技术实现视频硬字幕的高效提取:video-subtitle-extractor实战指南
如何用本地AI技术实现视频硬字幕的高效提取:video-subtitle-extractor实战指南 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包…...

Windows热键冲突终极解决方案:Hotkey Detective一键精准定位
Windows热键冲突终极解决方案:Hotkey Detective一键精准定位 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你…...

Android系统安全漏洞深度剖析:从Stagefright到权限提升攻击链
1. 从Stagefright到MediaServer:一场持续的安全风暴2015年的夏天,对于Android生态圈的安全工程师和开发者来说,绝对称得上是一个“多事之秋”。如果你当时正负责某个移动应用的安全审计,或者正在为自家公司的设备进行固件加固&…...

物联网隐私工程:从数据生命周期到安全设计实践
1. 物联网隐私困境:一个被误解的工程问题每次和同行聊起物联网项目,大家最头疼的往往是协议选型、功耗优化或者成本控制。至于隐私?那通常是产品经理或者法务部门在项目后期才想起来要填的“合规表格”。我自己在早期做智能家居网关时也犯过同…...