【Rust】Rust学习 第十四章进一步认识 Cargo 和 Crates.io
本章会讨论 Cargo 其他一些更为高级的功能,我们将展示如何:
- 使用发布配置来自定义构建
- 将库发布到 crates.io
- 使用工作空间来组织更大的项目
- 从 crates.io 安装二进制文件
- 使用自定义的命令来扩展 Cargo
Cargo 的功能不止本章所介绍的,关于其全部功能的详尽解释,请查看 文档
14.1 采用发布配置自定义构建
在 Rust 中 发布配置(release profiles)是预定义的、可定制的带有不同选项的配置,他们允许程序员更灵活地控制代码编译的多种选项。每一个配置都彼此相互独立。
Cargo 有两个主要的配置:运行 cargo build 时采用的 dev 配置和运行 cargo build --release 的 release 配置。dev 配置被定义为开发时的好的默认配置,release 配置则有着良好的发布构建的默认配置。
这些配置名称可能很眼熟,因为它们出现在构建的输出中:
$ cargo buildFinished dev [unoptimized + debuginfo] target(s) in 0.0 secs
$ cargo build --releaseFinished release [optimized] target(s) in 0.0 secs
构建输出中的 dev 和 release 表明编译器在使用不同的配置。
当项目的 Cargo.toml 文件中没有任何 [profile.*] 部分的时候,Cargo 会对每一个配置都采用默认设置。通过增加任何希望定制的配置对应的 [profile.*] 部分,我们可以选择覆盖任意默认设置的子集。例如,如下是 dev 和 release 配置的 opt-level 设置的默认值:
文件名: Cargo.toml
[profile.dev]
opt-level = 0[profile.release]
opt-level = 3
opt-level 设置控制 Rust 会对代码进行何种程度的优化。这个配置的值从 0 到 3。越高的优化级别需要更多的时间编译,所以如果你在进行开发并经常编译,可能会希望在牺牲一些代码性能的情况下编译得快一些。这就是为什么 dev 的 opt-level 默认为 0。当你准备发布时,花费更多时间在编译上则更好。只需要在发布模式编译一次,而编译出来的程序则会运行很多次,所以发布模式用更长的编译时间换取运行更快的代码。这正是为什么 release 配置的 opt-level 默认为 3。
对于每个配置的设置和其默认值的完整列表,请查看 Cargo 的文档。
14.2 将crate 发布到Crates.io
我们曾经在项目中使用 crates.io 上的包作为依赖,不过你也可以通过发布自己的包来向它人分享代码。crates.io 用来分发包的源代码,所以它主要托管开源代码。
Rust 和 Cargo 有一些帮助它人更方便找到和使用你发布的包的功能。我们将介绍一些这样的功能,接着讲到如何发布一个包。
编写有用的文档注释
准确的包文档有助于其他用户理解如何以及何时使用他们,所以花一些时间编写文档是值得的。第三章中我们讨论了如何使用两斜杠 // 注释 Rust 代码。Rust 也有特定的用于文档的注释类型,通常被称为 文档注释(documentation comments),他们会生成 HTML 文档。这些 HTML 展示公有 API 文档注释的内容,他们意在让对库感兴趣的程序员理解如何 使用 这个 crate,而不是它是如何被 实现 的。
文档注释使用三斜杠 /// 而不是两斜杆以支持 Markdown 注解来格式化文本。文档注释就位于需要文档的项的之前
/// 将给定的数字加一
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {x + 1
}
这里,我们提供了一个 add_one 函数工作的描述,接着开始了一个标题为 Examples 的部分,和展示如何使用 add_one 函数的代码。可以运行 cargo doc 来生成这个文档注释的 HTML 文档。这个命令运行由 Rust 分发的工具 rustdoc 并将生成的 HTML 文档放入 target/doc 目录。
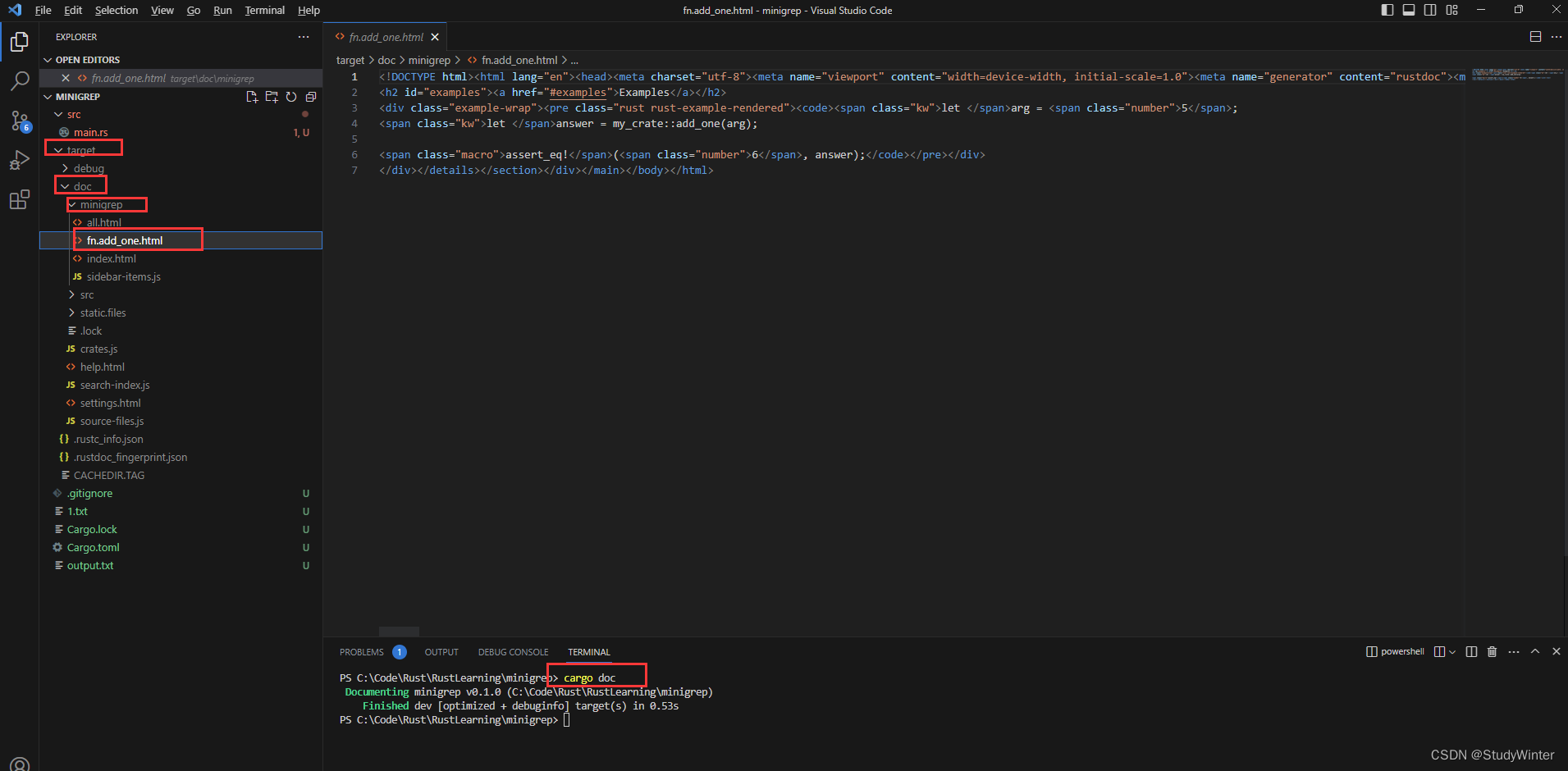
为了方便起见,运行 cargo doc --open 会构建当前 crate 文档(同时还有所有 crate 依赖的文档)的 HTML 并在浏览器中打开。导航到 add_one 函数将会发现文档注释的文本是如何渲染的,
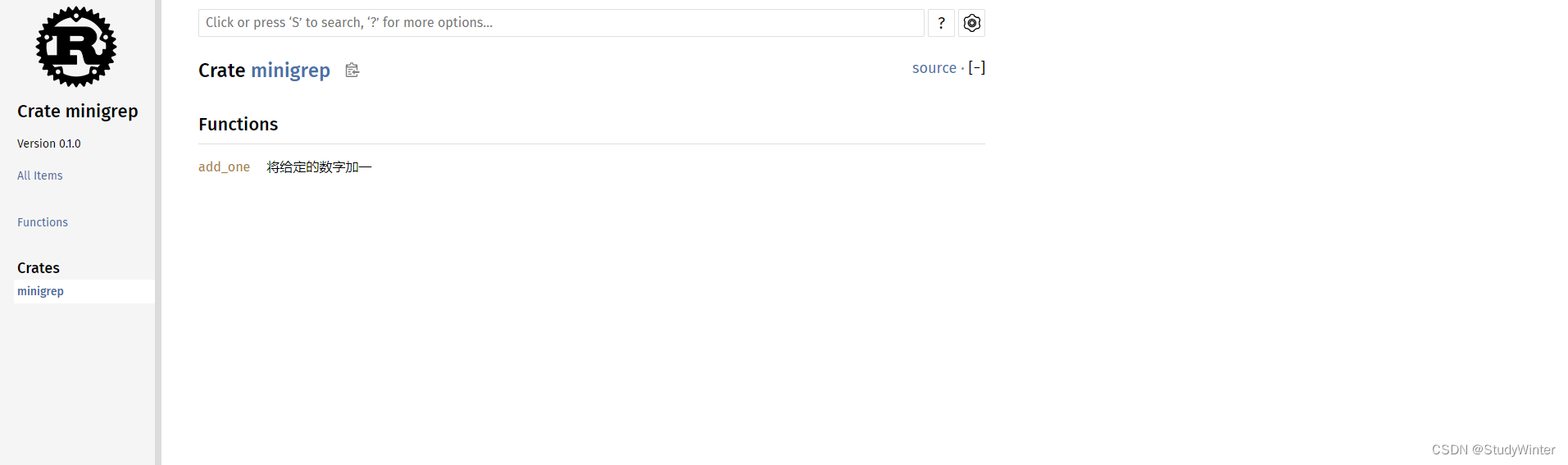
输入命令后,浏览器自动打开。
常用(文档注释)部分
其他一些 crate 作者经常在文档注释中使用的部分有:
- Panics:这个函数可能会
panic!的场景。并不希望程序崩溃的函数调用者应该确保他们不会在这些情况下调用此函数。 - Errors:如果这个函数返回
Result,此部分描述可能会出现何种错误以及什么情况会造成这些错误,这有助于调用者编写代码来采用不同的方式处理不同的错误。 - Safety:如果这个函数使用
unsafe代码(这会在第十九章讨论),这一部分应该会涉及到期望函数调用者支持的确保unsafe块中代码正常工作的不变条件(invariants)。
文档注释作为测试
在文档注释中增加示例代码块是一个清楚的表明如何使用库的方法,这么做还有一个额外的好处:cargo test 也会像测试那样运行文档中的示例代码!没有什么比有例子的文档更好的了!也没有什么比不能正常工作的例子更糟的了,因为代码在编写文档时已经改变。
注释包含项的结构
还有另一种风格的文档注释,//!,这为包含注释的项,而不是注释之后的项增加文档。这通常用于 crate 根文件(通常是 src/lib.rs)或模块的根文件为 crate 或模块整体提供文档。
作为一个例子,如果我们希望增加描述包含 add_one 函数的 my_crate crate 目的的文档,可以在 src/lib.rs 开头增加以 //! 开头的注释
//! # My Crate
//!
//! `my_crate` 是一个使得特定计算更方便的
//! 工具集合/// 将给定的数字加一。
// --snip--
注意 //! 的最后一行之后没有任何代码。因为他们以 //! 开头而不是 ///,这是属于包含此注释的项而不是注释之后项的文档。在这个情况中,包含这个注释的项是 src/lib.rs 文件,也就是 crate 根文件。这些注释描述了整个 crate。
使用pub use 导出合适的公有API
公有 API 的结构是你发布 crate 时主要需要考虑的。crate 用户没有你那么熟悉其结构,并且如果模块层级过大他们可能会难以找到所需的部分。
好消息是,即使文件结构对于用户来说 不是 很方便,你也无需重新安排内部组织:你可以选择使用 pub use 重导出(re-export)项来使公有结构不同于私有结构。重导出获取位于一个位置的公有项并将其公开到另一个位置,好像它就定义在这个新位置一样。
例如,假设我们创建了一个描述美术信息的库 art。这个库中包含了一个有两个枚举 PrimaryColor 和 SecondaryColor 的模块 kinds,以及一个包含函数 mix 的模块 utils(lib.rs)
//! # Art
//!
//! 一个描述美术信息的库。pub mod kinds {/// 采用 RGB 色彩模式的主要颜色。pub enum PrimaryColor {Red,Yellow,Blue,}/// 采用 RGB 色彩模式的次要颜色。pub enum SecondaryColor {Orange,Green,Purple,}
}pub mod utils {use crate::kinds::*;/// 等量的混合两个主要颜色/// 来创建一个次要颜色。pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {// --snip--SecondaryColor::Orange}
}
fn main() {}
cargo doc 所生成的 crate 文档
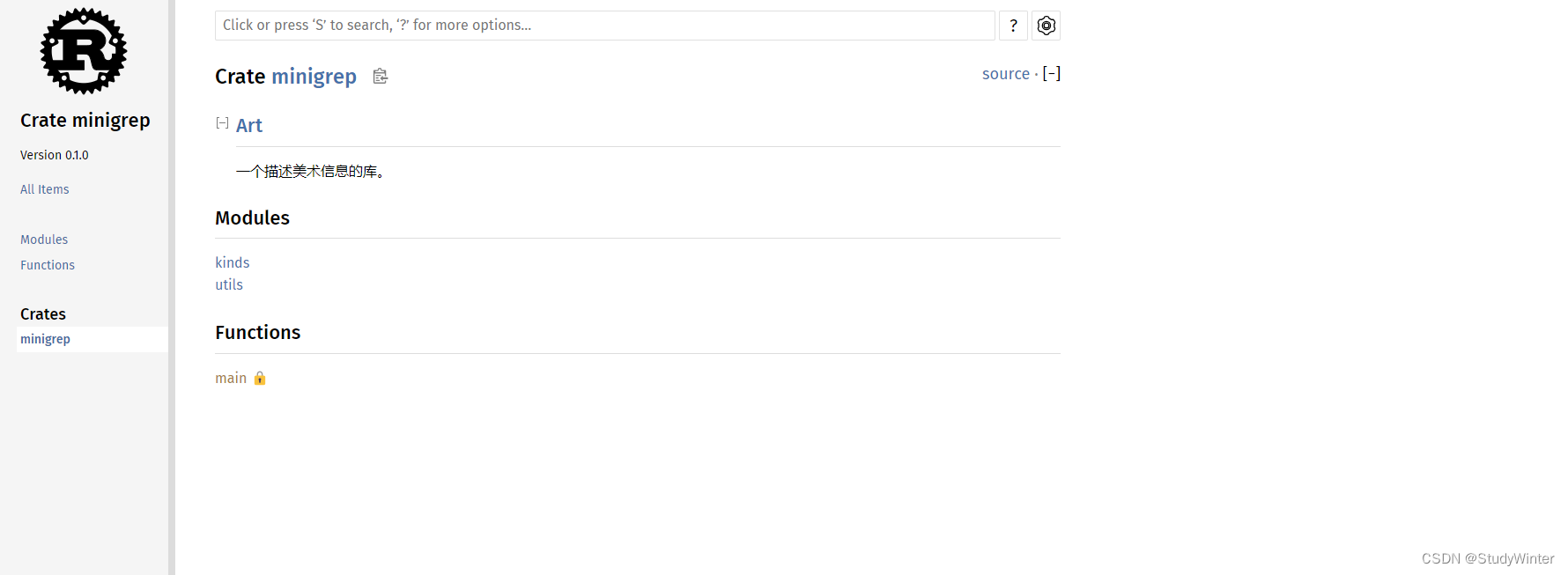
注意 PrimaryColor 和 SecondaryColor 类型、以及 mix 函数都没有在首页中列出。我们必须点击 kinds 或 utils 才能看到他们。
另一个依赖这个库的 crate 需要 use 语句来导入 art 中的项,这包含指定其当前定义的模块结构。示例展示了一个使用 art crate 中 PrimaryColor 和 mix 项的 crate 的例子:(main.rs)
use art::kinds::PrimaryColor;
use art::utils::mix;fn main() {let red = PrimaryColor::Red;let yellow = PrimaryColor::Yellow;mix(red, yellow);
}
示例中使用 art crate 代码的作者不得不搞清楚 PrimaryColor 位于 kinds 模块而 mix 位于 utils 模块。art crate 的模块结构相比使用它的开发者来说对编写它的开发者更有意义。其内部的 kinds 模块和 utils 模块的组织结构并没有对尝试理解如何使用它的人提供任何有价值的信息。art crate 的模块结构因不得不搞清楚所需的内容在何处和必须在 use 语句中指定模块名称而显得混乱和不便。
为了从公有 API 中去掉 crate 的内部组织,我们可以增加 pub use 语句来重导出项到顶层结构(lib.rs)
//! # Art
//!
//! 一个描述美术信息的库。pub use self::kinds::PrimaryColor;
pub use self::kinds::SecondaryColor;
pub use self::utils::mix;pub mod kinds {// --snip--
}pub mod utils {// --snip--
}

创建Crates.io账号
在你可以发布任何 crate 之前,需要在 crates.io 上注册账号并获取一个 API token。为此,访问位于 crates.io 的首页并使用 GitHub 账号登陆。(目前 GitHub 账号是必须的,不过将来该网站可能会支持其他创建账号的方法)一旦登陆之后,查看位于 https://crates.io/me/ 的账户设置页面并获取 API token。
发布新crate 之前
发布到Crates.io
使用cargo yank 从 Crates.io 撤回版本
14.3 Cargo工作空间
随着项目开发的深入,库 crate 持续增大,而你希望将其进一步拆分成多个库 crate。对于这种情况,Cargo 提供了一个叫 工作空间(workspaces)的功能,它可以帮助我们管理多个相关的协同开发的包。
创建工作空间
工作空间 是一系列共享同样的 Cargo.lock 和输出目录的包。让我们使用工作空间创建一个项目 —— 这里采用常见的代码以便可以关注工作空间的结构。有多种组织工作空间的方式;我们将展示一个常用方法。我们的工作空间有一个二进制项目和两个库。二进制项目会提供主要功能,并会依赖另两个库。一个库会提供 add_one 方法而第二个会提供 add_two 方法。这三个 crate 将会是相同工作空间的一部分。让我们以新建工作空间目录开始:
$ mkdir add
$ cd add
接着在 add* 目录中,创建 Cargo.toml 文件。这个 Cargo.toml 文件配置了整个工作空间。它不会包含 [package] 或其他我们在 Cargo.toml 中见过的元信息。相反,它以 [workspace] 部分作为开始,并通过指定 adder 的路径来为工作空间增加成员,如下会加入二进制 crate:
[workspace]members = ["adder",
]
接下来,在 add 目录运行 cargo new 新建 adder 二进制 crate:
$ cargo new adderCreated binary (application) `adder` project
到此为止,可以运行 cargo build 来构建工作空间。add 目录中的文件应该看起来像这样:

工作空间在顶级目录有一个 target 目录;adder 并没有自己的 target 目录。即使进入 adder 目录运行 cargo build,构建结果也位于 add/target 而不是 add/adder/target。工作空间中的 crate 之间相互依赖。如果每个 crate 有其自己的 target 目录,为了在自己的 target 目录中生成构建结果,工作空间中的每一个 crate 都不得不相互重新编译其他 crate。通过共享一个 target 目录,工作空间可以避免其他 crate 多余的重复构建。
在工作空间中创建第二个crate
接下来,让我们在工作空间中指定另一个成员 crate。这个 crate 位于 add-one 目录中,所以修改顶级 Cargo.toml 为也包含 add-one 路径:
[workspace]members = ["adder","add-one",
]
接着新生成一个叫做 add-one 的库:
$ cargo new add-one --libCreated library `add-one` project
现在 add 目录应该有如下目录和文件:
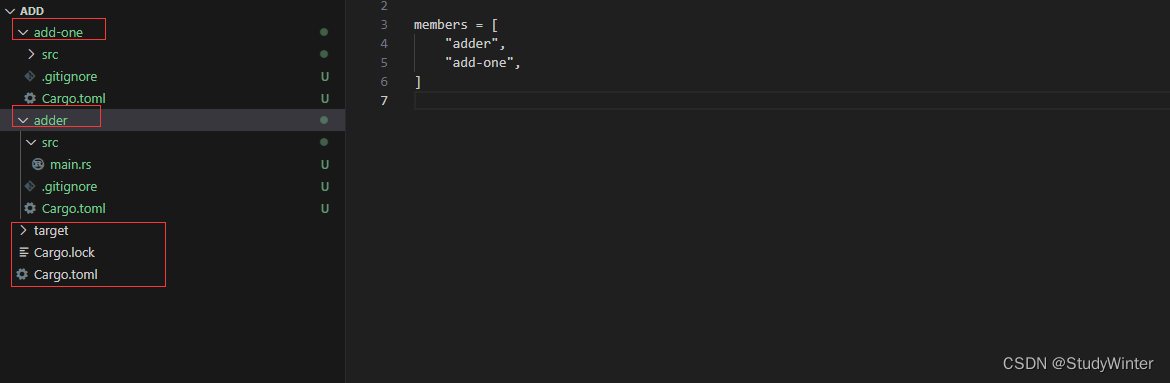
在 add-one/src/lib.rs 文件中,增加一个 add_one 函数:
文件名: add-one/src/lib.rs
pub fn add_one(x: i32) -> i32 {x + 1
}
现在工作空间中有了一个库 crate,让 adder 依赖库 crate add-one。首先需要在 adder/Cargo.toml 文件中增加 add-one 作为路径依赖:
文件名: adder/Cargo.toml
[dependencies]add-one = { path = "../add-one" }
cargo并不假定工作空间中的Crates会相互依赖,所以需要明确表明工作空间中 crate 的依赖关系。
接下来,在 adder crate 中使用 add-one crate 的函数 add_one。打开 adder/src/main.rs 在顶部增加一行 use 将新 add-one 库 crate 引入作用域。接着修改 main 函数来调用 add_one 函数
文件名: adder/src/main.rs
use add_one;fn main() {let num = 10;println!("Hello, world! {} plus one is {}!", num, add_one::add_one(num));
}
在 add 目录中运行 cargo build 来构建工作空间!
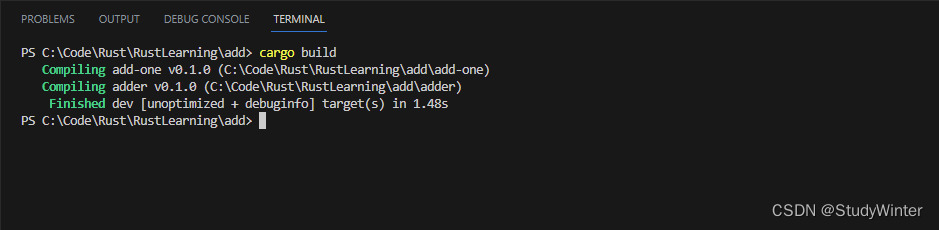
为了在顶层 add 目录运行二进制 crate,需要通过 -p 参数和包名称来运行 cargo run 指定工作空间中我们希望使用的包:

在工作空间中依赖外部crate
还需注意的是工作空间只在根目录有一个 Cargo.lock,而不是在每一个 crate 目录都有 Cargo.lock。这确保了所有的 crate 都使用完全相同版本的依赖。如果在 Cargo.toml 和 add-one/Cargo.toml 中都增加 rand crate,则 Cargo 会将其都解析为同一版本并记录到唯一的 Cargo.lock 中。使得工作空间中的所有 crate 都使用相同的依赖意味着其中的 crate 都是相互兼容的。让我们在 add-one/Cargo.toml 中的 [dependencies] 部分增加 rand crate 以便能够在 add-one crate 中使用 rand crate:
文件名: add-one/Cargo.toml
[dependencies]
rand = "0.5.5"
现在就可以在 add-one/src/lib.rs 中增加 use rand; 了,接着在 add 目录运行 cargo build 构建整个工作空间就会引入并编译 rand crate:
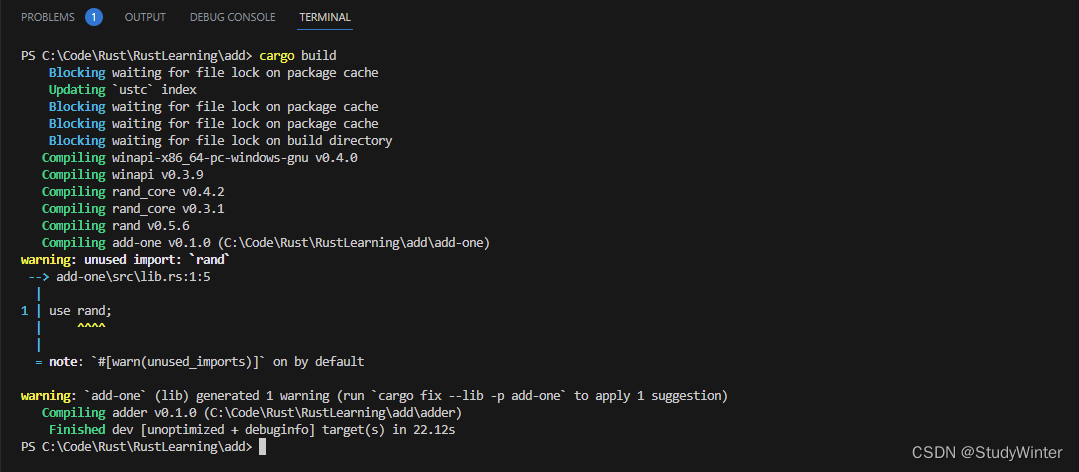
现在顶级的 Cargo.lock 包含了 add-one 的 rand 依赖的信息。然而,即使 rand 被用于工作空间的某处,也不能在其他 crate 中使用它,除非也在他们的 Cargo.toml 中加入 rand。
为工作空间增加测试
作为另一个提升,让我们为 add_one crate 中的 add_one::add_one 函数增加一个测试:
文件名: add-one/src/lib.rs
pub fn add_one(x: i32) -> i32 {x + 1
}#[cfg(test)]
mod tests {use super::*;#[test]fn it_works() {assert_eq!(3, add_one(2));}
}在顶级 add 目录运行 cargo test:
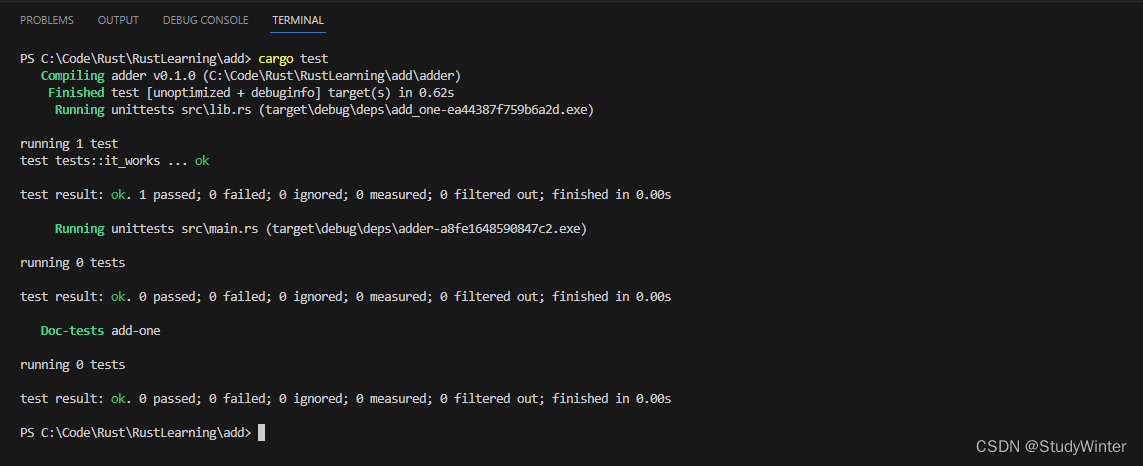
输出的第一部分显示 add-one crate 的 it_works 测试通过了。下一个部分显示 adder crate 中找到了 0 个测试,最后一部分显示 add-one crate 中有 0 个文档测试。在像这样的工作空间结构中运行 cargo test 会运行工作空间中所有 crate 的测试。
也可以选择运行工作空间中特定 crate 的测试,通过在根目录使用 -p 参数并指定希望测试的 crate 名称:
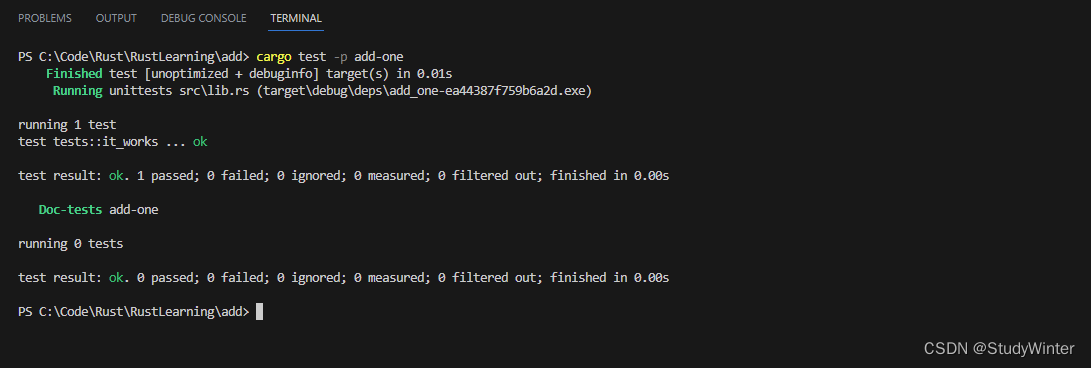
输出显示了 cargo test 只运行了 add-one crate 的测试而没有运行 adder crate 的测试。
如果你选择向 crates.io发布工作空间中的 crate,每一个工作空间中的 crate 需要单独发布。cargo publish 命令并没有 --all 或者 -p 参数,所以必须进入每一个 crate 的目录并运行 cargo publish 来发布工作空间中的每一个 crate
14.4 使用cargo install 从Crates.io安装二进制文件
cargo install 命令用于在本地安装和使用二进制 crate。它并不打算替换系统中的包;它意在作为一个方便 Rust 开发者们安装其他人已经在 crates.io 上共享的工具的手段。只有拥有二进制目标文件的包能够被安装。二进制目标 文件是在 crate 有 src/main.rs 或者其他指定为二进制文件时所创建的可执行程序,这不同于自身不能执行但适合包含在其他程序中的库目标文件。通常 crate 的 README 文件中有该 crate 是库、二进制目标还是两者都是的信息。
所有来自 cargo install 的二进制文件都安装到 Rust 安装根目录的 bin 文件夹中。如果你使用 rustup.rs 安装的 Rust 且没有自定义任何配置,这将是 $HOME/.cargo/bin。确保将这个目录添加到 $PATH 环境变量中就能够运行通过 cargo install 安装的程序了。
如果想要安装 ripgrep,可以运行如下:
$ cargo install ripgrep
Updating registry `https://github.com/rust-lang/crates.io-index`Downloading ripgrep v0.3.2--snip--Compiling ripgrep v0.3.2Finished release [optimized + debuginfo] target(s) in 97.91 secsInstalling ~/.cargo/bin/rg
最后一行输出展示了安装的二进制文件的位置和名称,在这里 ripgrep 被命名为 rg。只要你像上面提到的那样将安装目录加入 $PATH,就可以运行 rg --help 并开始使用一个更快更 Rust 的工具来搜索文件了!
14.5 Cargo自定义扩展命令
Cargo 的设计使得开发者可以通过新的子命令来对 Cargo 进行扩展,而无需修改 Cargo 本身。如果 $PATH 中有类似 cargo-something 的二进制文件,就可以通过 cargo something 来像 Cargo 子命令一样运行它。像这样的自定义命令也可以运行 cargo --list 来展示出来。能够通过 cargo install 向 Cargo 安装扩展并可以如内建 Cargo 工具那样运行他们是 Cargo 设计上的一个非常方便的优点!
参考:更多关于 Cargo 和 Crates.io 的内容 - Rust 程序设计语言 简体中文版 (bootcss.com)
相关文章:
【Rust】Rust学习 第十四章进一步认识 Cargo 和 Crates.io
本章会讨论 Cargo 其他一些更为高级的功能,我们将展示如何: 使用发布配置来自定义构建将库发布到 crates.io使用工作空间来组织更大的项目从 crates.io 安装二进制文件使用自定义的命令来扩展 Cargo Cargo 的功能不止本章所介绍的,关于其全…...

Android性能优化----执行时间优化
作者:lu人皆知 在APP做启动优化时,Application会做一些初始化的工作,但不要在Application中做耗时操作,然而有些初始化工作可能是很耗时的,那怎么办?初始化操作可以开启子线程来完成。 计算执行时间 常规…...
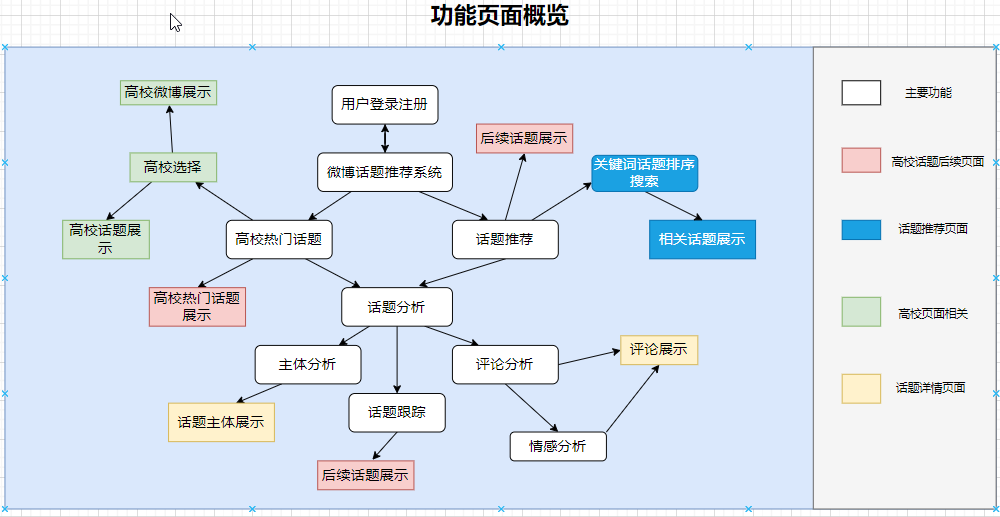
基于Python的微博大数据舆情分析,舆论情感分析可视化系统,可作为Python毕业设计
运行效果图 基于Python的微博大数据舆情分析,舆论情感分析可视化系统 系统介绍 微博舆情分析系统,项目后端分爬虫模块、数据分析模块、数据存储模块、业务逻辑模块组成。 先后进行了数据获取和筛选存储,对存储后的数据库数据进行提取分析处…...

被迫学习一波Linux命令
事情起因 部署一个服务,人家说了最低配置是3G,我没当回事,拿着个2G的服务器直接就上了,结果,哈哈,都能猜到结果:服务器内存爆了!!!而且最可气的是服务器还登…...

字符串变量拼接操作的底层原理
在java中,字符串变量拼接操作使用的是StringBuilder或StringBuffer类,这两个类都是可变的字符串缓冲区。java中的字符串是不可变的,因此在进行字符串拼接时需要使用可变的字符串缓冲区,以避免不必要的内存分配和复制。具体来说&am…...
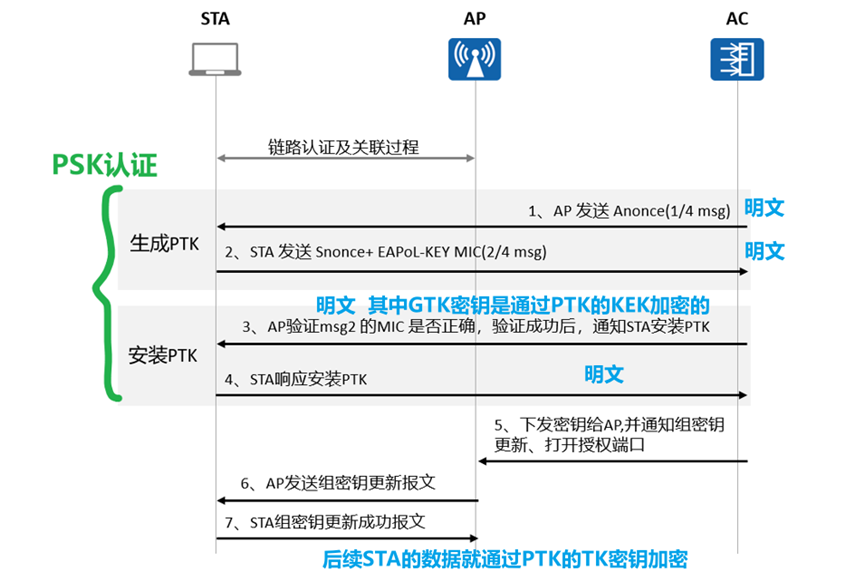
Wlan安全——认证与加密方式(WPA/WPA2)
目录 终端认证技术 WEP认证 PSK认证 802.1x认证与MAC认证 Portal认证 数据加密技术 WEP加密 TKIP加密 CCMP加密 TKIP和CCMP生成密钥所需要的密钥信息 802.11安全标准 WEP共享密钥认证、加密工作原理 WEP共享密钥认证 WEP加解密过程 PSK认证以及生成动态密钥的工…...

Leetcode-每日一题【剑指 Offer 31. 栈的压入、弹出序列】
题目 输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如,序列 {1,2,3,4,5} 是某栈的压栈序列,序列 {4,5,3,2,1} 是该压栈序列对应的一个弹出序列…...
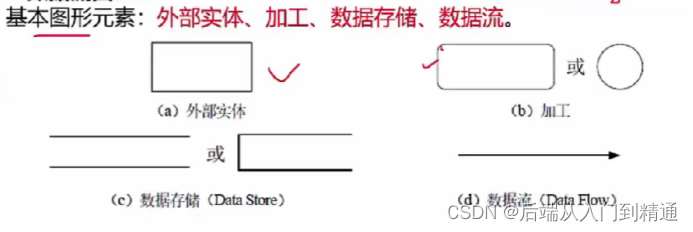
软件需求-架构师之路(五)
软件需求 软件需求: 指用户 对系统在功能、行为、性能、设计约束等方面的期望。 分为 需求开发 和 需求管理 两大过程。 需求开发: 需求获取需求分析需求定义(需求规格说明书)需求验证:拉客户一起评审,…...

Python自带的IDLE有什么用
在Python的官方解释器中,自带了一个名为IDLE(Interactive DeveLopment Environment)的集成开发环境。 一、简化代码调试过程 很多初学者在编写Python代码时,经常会遇到一些问题需要调试。而在IDLE中,我们可以通过设置断点、单步调试等方法&…...
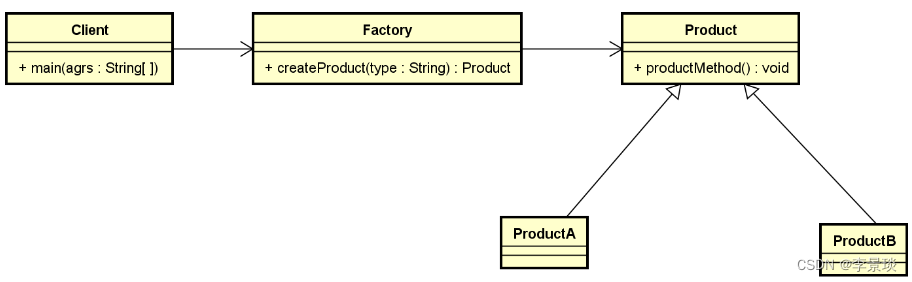
设计模式之简单工厂模式
一、概述 定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂模式使一个类的实例化延迟到其子类。 简单工厂模式:又叫做静态工厂方法模式,是由一个工厂对象决定创建出哪一种产品类的实例。 二、适用性 1.当一个类不知道它所必须…...

从SaaS到RPA,没有真正“完美”的解决方案!
众所周知,SaaS行业越来越卷,利润也越来越“薄”,这是传统软件厂商的悲哀,也是未来数字化行业不得不面对的冷峻现状之一。 随着基于aPaaS、低代码的解决方案之流行,SaaS行业变得越来越没有技术门槛,IT人员的…...
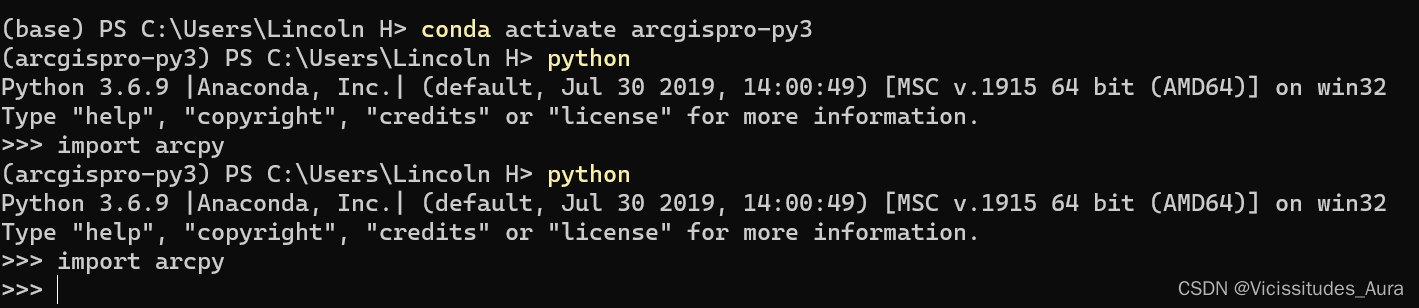
miniconda克隆arcpy
arcpy环境克隆 前言尝试思考到此结束 前言 最近遇到了一些问题,需要用到arcpy来处理一些东西,但众所周知,arcgis的arcpy是python 2.0的,我不是很喜欢;所以我安装了arcgis pro 2.8,我发现这也是个坑&#x…...

一万字关于java数据结构堆的讲解,让你从入门到精通
目录 java类和接口总览 队列(Queue) 1. 概念 2. 队列的使用 以下是一些常用的队列操作: 1.入队操作 2.出队操作 3.判断队列是否为空 4.获取队列大小 5.其它 优先级队列(堆) 1. 优先级队列概念 Java中的PriorityQueue具有以下特点 2.常用的PriorityQue…...

Java集合底层源码剖析-ArrayList和LinkedList
文章目录 ArrayList基本原理优缺点核心方法的原理数组扩容以及元素拷贝LinkedList基本原理优缺点双向链表数据结构插入元素的原理获取元素的原理删除元素的原理Vector和Stack栈数据结构的源码剖析ArrayList 基本原理 ArrayList是Java中的一个非常常用的数据结构,它实现了Lis…...

【数据分享】2006-2021年我国城市级别的市政公用设施建设固定资产投资相关指标(30多项指标)
《中国城市建设统计年鉴》中细致地统计了我国城市市政公用设施建设与发展情况,在之前的文章中,我们分享过基于2006-2021年《中国城市建设统计年鉴》整理的2006—2021年我国城市级别的市政设施水平相关指标(可查看之前的文章获悉详情ÿ…...
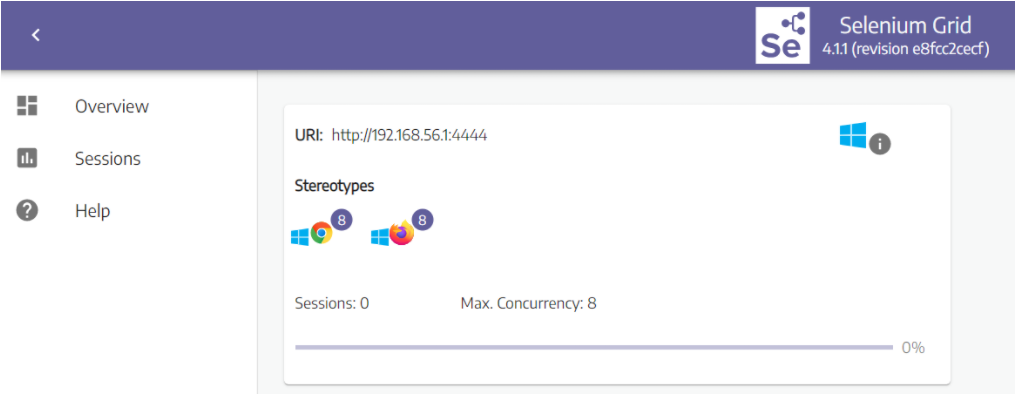
学点Selenium玩点新鲜~,让分布式测试有更多玩法
前 言 我们都知道 Selenium 是一款在 Web 应用测试领域使用的自动化测试工具,而 Selenium Grid 是 Selenium 中的一大组件,通过它能够实现分布式测试,能够帮助团队简单快速在不同的环境中测试他们的 Web 应用。 分布式执行测试其实并不是一…...
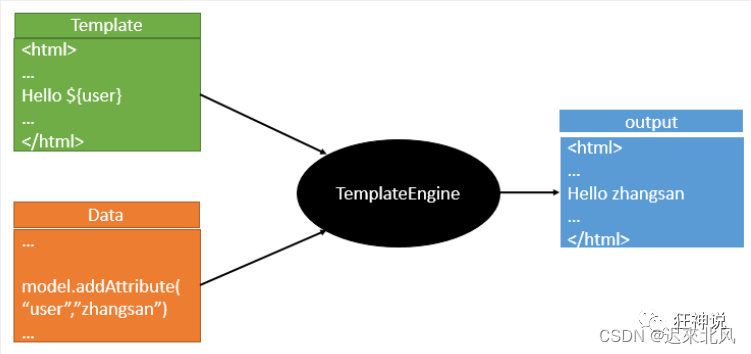
【SpringBoot学习笔记】04. Thymeleaf模板引擎
模板引擎 所有的html元素都可以被thymeleaf替换接管 th:元素名 templates下的只能通过Controller来跳转,templates前后端分离,需要模板引擎thymeleaf支持 模板引擎的作用就是我们来写一个页面模板,比如有些值呢,是动态的&#x…...

【uni-app】 .sync修饰符与$emit(update:xxx)实现数据双向绑定
最近在看uni-app文档,看到.sync修饰符的时候,觉得很有必要记录一下 其实uni-app是一个基于Vue.js和微信小程序开发框架的跨平台开发工具 所以经常会听到这样的说法,只要你会vue,uni-app就不难上手 在看文档的过程中,发…...
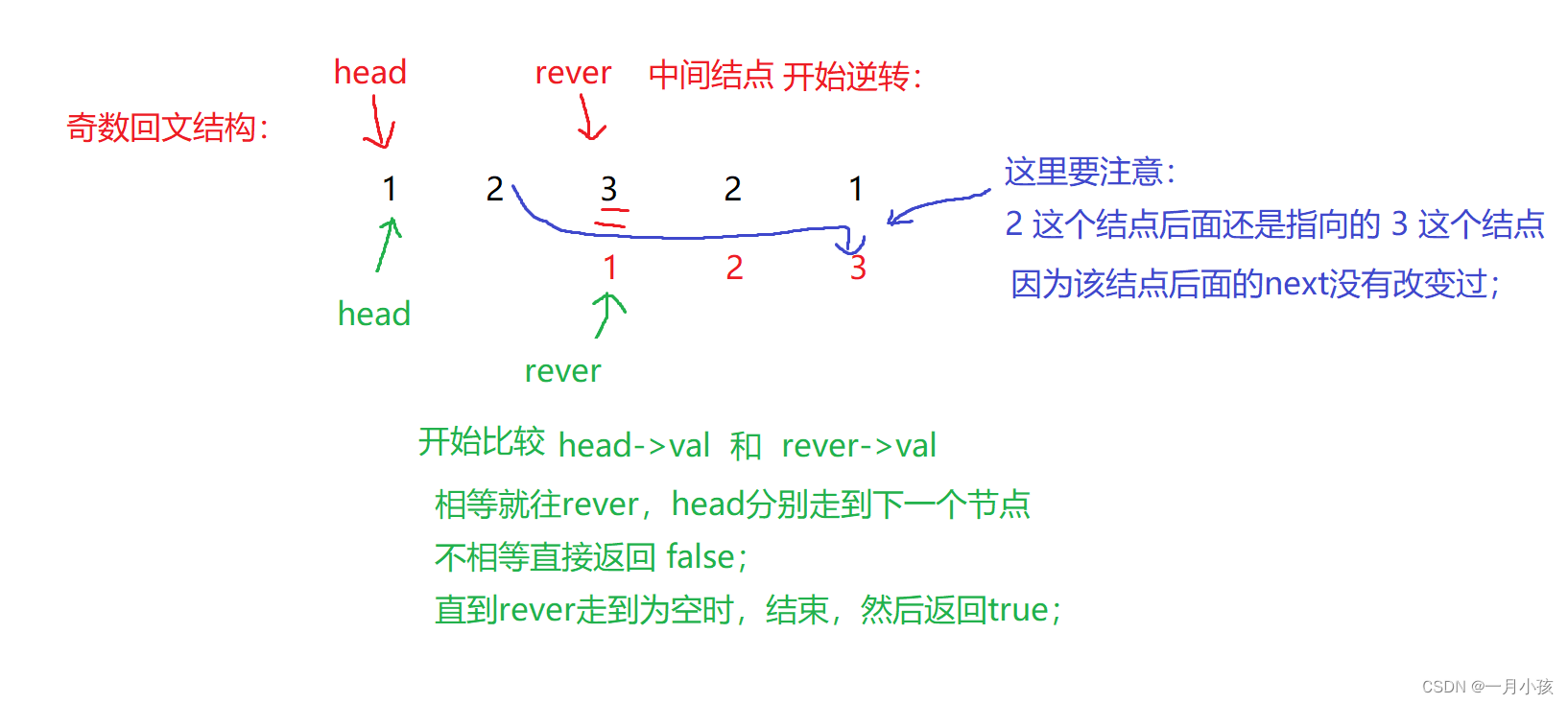
链表之第二回
欢迎来到我的:世界 该文章收入栏目:链表 希望作者的文章对你有所帮助,有不足的地方还请指正,大家一起学习交流 ! 目录 前言第一题:反转一个链表第二题:链表内指定区间反转第三题:判断一个链表…...

【sgDragSize】自定义拖拽修改DIV尺寸组件,适用于窗体大小调整
核心原理就是在四条边、四个顶点加上透明的div,给不同方向提供按下移动鼠标监听 ,对应计算宽度高度、坐标变化 特性: 支持设置拖拽的最小宽度、最小高度、最大宽度、最大高度可以双击某一条边,最大化对应方向的尺寸;再…...

基于Terraform与Ansible的OpenClaw私有化AI代理自动化部署实践
1. 项目概述如果你和我一样,对AI助手的能力有更高的期待,希望它能深度融入你的工作流,甚至能帮你处理一些自动化任务,那么OpenClaw这个项目绝对值得你花时间研究。它不是一个简单的聊天机器人,而是一个可以部署在你私有…...

如何用LDBlockShow高效绘制连锁不平衡热图:从入门到精通的完整指南
如何用LDBlockShow高效绘制连锁不平衡热图:从入门到精通的完整指南 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_…...

SM3国密算法实战:从原理到Java代码实现与数据完整性校验
1. SM3国密算法:你的数据安全守门人 第一次听说SM3算法时,我正在处理一个政府项目的投标文件加密需求。客户明确要求必须使用国密标准算法,当时我对这类算法还停留在"听说过但没用过"的阶段。经过两周的实战摸索,我发现…...
)
老笔记本焕发第二春:微星GT60升级GTX1060保姆级避坑指南(含硬件ID修改)
微星GT60笔记本升级GTX1060全流程实战:从硬件改造到驱动破解 当手头的微星GT60笔记本逐渐跟不上现代游戏需求时,许多玩家会考虑升级显卡来延续它的使用寿命。MXM接口的GTX1060显卡因其性价比和性能表现成为热门选择,但整个升级过程充满技术陷…...

解锁HexView自动化:Bat脚本驱动S19/HEX文件处理实战
1. 为什么需要自动化处理S19/HEX文件 在汽车电子开发领域,我们经常需要处理各种固件文件,比如S19、HEX等格式。这些文件包含了嵌入式系统的机器代码,是软件最终要烧录到芯片中的形态。每次软件更新时,开发人员都要对这些文件进行一…...

技术深度解析:5大核心要点掌握Sunshine开源游戏串流服务器实战部署
技术深度解析:5大核心要点掌握Sunshine开源游戏串流服务器实战部署 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款功能强大的自托管开源游戏串流服务器…...

AnyFlip下载器终极指南:3分钟快速将在线翻页书转为PDF
AnyFlip下载器终极指南:3分钟快速将在线翻页书转为PDF 【免费下载链接】anyflip-downloader Download anyflip books as PDF 项目地址: https://gitcode.com/gh_mirrors/an/anyflip-downloader 你是否在AnyFlip上发现了心仪的电子书,却苦于无法下…...

从CAD建模到游戏角色动画:深入浅出聊聊B样条曲线在工业与娱乐中的实战应用
从CAD建模到游戏角色动画:B样条曲线的跨领域实战解析 在工业设计与数字娱乐的交汇处,B样条曲线(B-spline Curves)正悄然重塑着两个行业的创作范式。当汽车设计师在Alias中推敲车身曲面时,游戏动画师正在Blender里调整…...

第13天:常用数据结构之字典
Python学习100天(从入门到精通系列文章) 文章目录 Python学习100天(从入门到精通系列文章) 前言 一、为什么需要字典? 1.1 列表、元组、集合的局限性 1.2 字典的优势 二、创建和使用字典 2.1 使用字面量语法创建字典 2.2 使用 dict 函数创建字典 三、字典的常用操作 3.1 访…...

革命性Figma中文插件:智能汉化让设计界面秒变母语
革命性Figma中文插件:智能汉化让设计界面秒变母语 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?FigmaCN是一款专为中文用户打造…...